1. Introduction
Image-based rendering is a technique of generating a rendering result of an unknown viewpoint by interpolating through the collected image dataset [
1]. One of its research motivations is the free-viewpoint rendering, i.e., to synthesize images at arbitrary viewpoints from discrete as well as sparse pre-captured images using appropriate transformations [
2,
3]. This kind of method does not require building three-dimensional (3D) mesh models of the scene in advance, and has broad application prospects in content generation, especially in the field of virtual reality and augmented reality (VR/AR). However, existing free-viewpoint rendering mainly adopts either the traditional image-based methods or the learning-based frameworks, and there are still many problems to be further studied.
One of the problems is the limited viewpoint freedom. The core of traditional image-based methods is the multidimensional representation of the light field [
4] which describes the intensities of light rays passing through any viewpoints and any directions in free space. Restricting the light field in different dimensions can derive different kinds of light field representations, thus limiting the freedom of viewpoint to varying extents. For example, the two-parallel-plane parameterized (2PP) four-dimensional (4D) light field
L(
u,
v,
s,
t) limits the viewpoints on a specific plane (camera plane) [
5,
6]. The 3D light field, such as the concentric mosaic, limits the viewpoints to a specific viewing circle (camera circle) [
7,
8,
9,
10]. The simplest 2D light field representation, i.e., the panorama limits the viewpoints to a single projection center [
11,
12,
13,
14]. The constraint on viewpoint freedom is helpful to simplify the dimensions of the light field model as well as reduce its data complexity. However, the free-viewpoint rendering pursues that the desired images can be rendered at arbitrary positions and orientations in the observation space. The above methods limit the degree of freedom (DoF) of the viewpoints so that the systems based on these methods only provide restricted viewpoints which does not satisfy the natural interaction between human and the real-world scenes.
Another problem is the poor time performance of novel view rendering. With the rapid progress of deep learning, some researchers use the learning-based frameworks to generate arbitrary views [
15,
16,
17,
18], trying to alleviate the restriction of the DoF of the viewpoints. However, this kind of method requires a complex training process, expensive network computation and takes a lot of time as well as memory for generating a high-resolution novel view, which cannot guarantee the real-time rendering performance. Both of these two issues have to be solved in the applications of free-viewpoint rendering in VR/AR. Only by providing a full viewpoint coverage in the observation space as well as the real-time rendering performance, can we meet the requirement of content generation in VR/AR [
19].
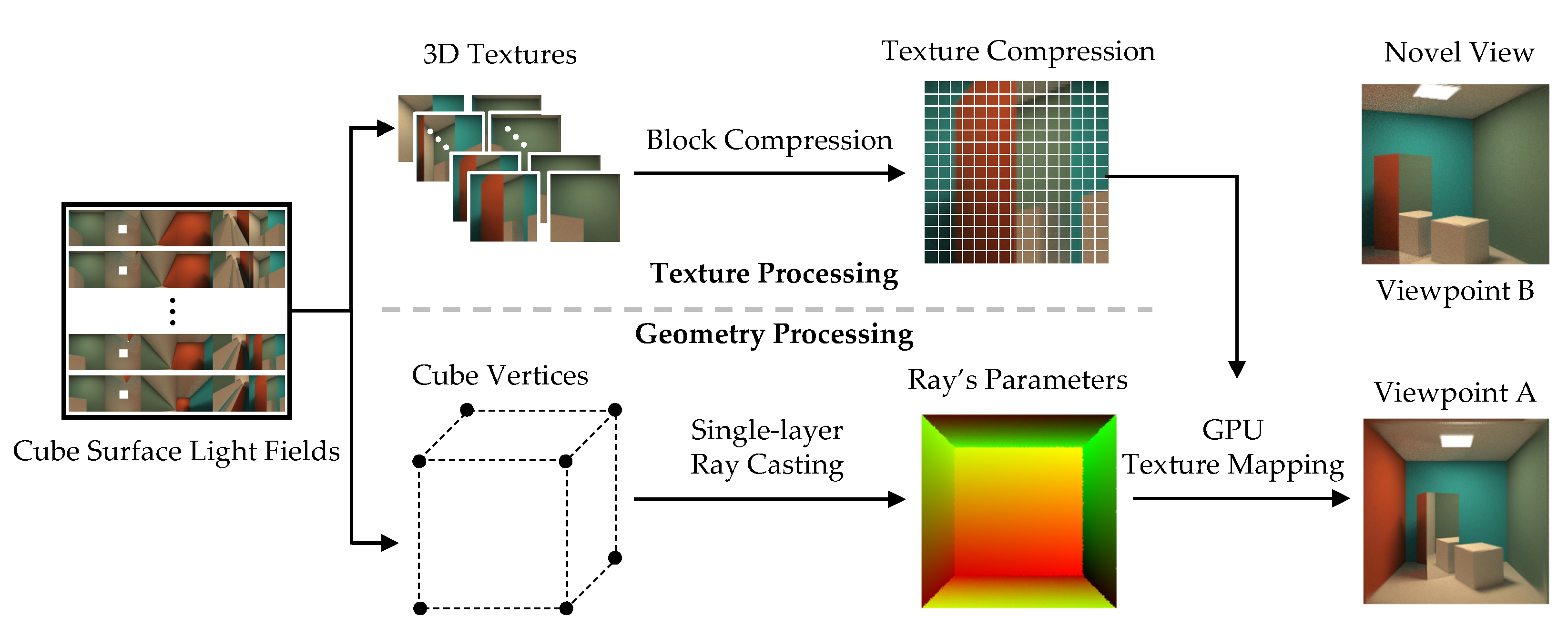
In this paper, we present an interactive free-viewpoint rendering method using the cube surface light field which is a pure light ray-based scene representation. The complexity of this representation is independent of the scene’s geometric structures, indicating its ability to represent anisotropic light fields in arbitrary scenes by a unified model. The basic pipeline of our method is shown as
Figure 1. Firstly, based on the pure light ray-based scene representation, the input of our method is the cube surface light fields consisting of a certain number of pre-collected images. Then, our method is divided into two independent steps: texture processing and geometry processing. In texture processing, we use the 3D texture compression algorithm to process the cube surface light field images, making its data amount acceptable to personal computers. In geometric processing, we adopt the programmable rendering pipeline from cube vertices to frame buffer and use a fast single-layer ray casting algorithm to render a unit cube mesh as well as computing the parameters of the desired light rays that are finally used for GPU texture mapping, converting a group of light rays to a novel view. Given different target viewpoints, our method can render the corresponding novel views such as viewpoint A and B in
Figure 1.
Compared with the mesh-based rendering, our rendering method is not affected by the specific geometric structures of the scenes and can be extended to arbitrary scenes using a unified model, i.e., the cube surface light field representation. Moreover, our method does not need to solve the integral of the rendering equation for each frame, which greatly reduces the computational consumption during the rendering. Compared with the traditional image-based rendering, the proposed method greatly improves the DoF of the viewpoints, which can render the novel views at arbitrary positions and viewing directions outside the cube surface. Compared with the learning-based methods, the proposed method can achieve interactive rendering (IR), and the average frame rate for rendering a novel view with a resolution of 2048 × 2048 on a personal computer can reach more than 75 FPS. In summary, the main contributions of this paper are as follows:
a pure light ray-based representation that supports implicitly encoding the scenes to a unified model,
a free-viewpoint rendering method based on compressed texture mapping and ray casting, which supports rendering the novel views without any explicit geometry structures of the scenes, significantly improving the DoF as well as the time performance of novel view light field rendering with high resolution.
3. Cube Surface Light Field Representation
The core idea of the cube surface light field representation is to parameterize the light rays on the two intersections with the cube surface and use the color value at the first intersection of the light ray and the object’s surface to be the color of this light ray, constructing a pure ray-based 4D light field representation of the scenes, as shown in
Figure 2.
The light rays in free space can be divided into two categories. The first category of light ray does not intersect with the objects in the scene, and almost does not influence the objects’ appearance. The second category of light ray intersects with the scene’s objects and has a significant impact on the objects’ appearance, resulting in light and dark effects on the objects’ surfaces. The origination of such light rays either can be from one or more light sources or can be the reflected light rays on the surface of an adjacent object. In particular, the images captured by a camera have already encoded the final impact of the light rays from these two originations on the appearance of the scene. Therefore, only the second category of light ray is concerned in the study of free-viewpoint rendering, and we do not distinguish whether the light ray is from the light source or the reflection from the adjacent objects’ surface.
The cube surface light field uses a unified cube geometry to parameterize the set of the second category of light ray in free space and uses the pairs of intersected points on the cube surface to be the parameters of light rays. We define that the center of the cube geometry is located at the origination of the 3D Cartesian coordinate system (CCS), and the edge length is the same as the size of the scene’s bounding box. According to the twelve edges of the cube geometry, its surface can be divided into six sub-planes, corresponding to +X, +Y, +Z, −X, −Y, −Z planes, respectively. Therefore, the cube surface can be defined by a 2D function composed of six sub-planes, as shown in Equation (
1), in which (x, y) refers to the 2D coordinates of the interior points on each sub-plane.
On the cube surface, the origination of each light ray is defined by the 2D coordinates at the first intersections with the light rays and the cube surface, and the directions of the light rays are defined by the 2D coordinate at the second intersections with the light rays and the cube surface. The color values of each light ray are defined as the color at the first intersections with the light rays and the scenes, which are described by the RGB color representation. Consequently, the cube surface light field can be defined as a set of RGB color values of the light rays parameterized by the intersection pairs with a specific cube surface, as shown in Equation (
2), in which
m and
n refer to the serial number of the sub-plane where the originations and directions of the light rays are parameterized. Similarly, (
u,
v) and (
s,
t) refer to the 2D coordinates of arbitrary interior points on the
m-th sub-plane and on the
n-th sub-plane, respectively.
Obviously, for all the light rays that intersect with the scene, the two intersections with the cube surface cannot be on the same sub-plane of the cube surface. Therefore,
m and
n must not get the same value at the same time in the cube surface light field. According to Equation (
2), each light ray has been defined as a six-tuple (
m,
u,
v,
n,
s, and
t) so far. Since
m and
n are both enumeration values, their definition domains are integers between [1, 6]. To facilitate the parametric representation of the light field, the cube surface, as shown in
Figure 3a can be expanded along any of its twelve edges, producing different cube map layouts, such as vertical and horizontal cross layouts, as shown in
Figure 3b. We use the horizontal layout as shown in
Figure 3c to present each sub-view of the cube surface light field.
Intuitively, the texture coordinates can be used to further simplify Equation (
2), resulting in the final representation of the cube surface light field denoted by Equation (
3). Seeing from the dimension of
u and
v, each coordinate (
u,
v) represents a set of light rays from a fixed position, which can be described as a light field sub-view like in the traditional 2PP light field representation. Meanwhile, seeing from the dimension of
s and
t, each coordinate (
s,
t) represents a set of light rays from a fixed direction, which can be described as a sub-aperture image like in the 2PP light field representation.
One advantage of the cube surface parameterization is that it is easy to sample the light field. The two adjacent edges of each sub-plane are divided into several segments uniformly or non-uniformly. By connecting the endpoints of the two opposite segments, the sub-plane can be subdivided into several small square or rectangular blocks. The barycentric coordinates of each square or rectangular can be selected as the sampling points of the cube surface light field. This representation also helps to compress the light field images at each sampling point. The images generated by the sampling points on the same sub-plane have only translational transformation in both horizontal and vertical directions. If the equidistant sampling strategy is adopted in the sampling stage, the relationship between the image pixels of these viewpoints is easy to be quantitatively described by parallax, which facilitates the prediction and compression of adjacent views. It is also conducive to subsequent rendering, i.e., the light field rendering of an arbitrary scene only requires drawing a simple unit cube geometric. By intersecting the desired light rays with the cube surface, the light ray’s parameters can be computed and used to query the color value of the novel viewpoint pixels. The computational consumption for testing intersection with the light rays and cube surface is relatively low, which makes the cube surface light field rendering possible to achieve real-time performance.
5. Results and Discussion
We use OpenGL and GLSL to implement the proposed rendering method on a personal computer with Intel Xeon(R) CPU E5-1650v4 @3.60 GHz CPU, 16 GB RAM, and Nvidia Quadro P4000 GPU. In this section, we first analyze the DoF of renderable viewpoints in ray space. Then, we study the time performance of our method and compare it with the path tracing rendering. The quality of images rendered by various interpolations and path tracing are evaluated finally.
5.1. Ray Space Analysis
The cube surface light field is presented by a set of cube maps arranged by the texture coordinates, i.e., the sampling points. Each sampling point in the viewpoint space represents all the light rays starting from this point to the whole image space. All the sampling points in the viewpoint space amalgamated to form a viewpoint cube map. Therefore, the coverage of the viewpoint cube map has an important impact on the DoF of the subsequent rendering.
Considering that it is easier to understand the light ray’s distribution in ray space, we convert the light rays in 3D space (Cartesian coordinate system, CCS) to ray space (Polar coordinate system, PCS). Without losing generality, the light ray’s projection on the XOY plane is taken as an example to analyze the ray space distributions. Given an arbitrary light ray R in 3D space, its projection on the XOY plane can be marked as
Figure 6a. The angle with the +X axis is denoted as
and the distance between this projection line to the origin of CCS is denoted as
r. Taking
and
r to be the two coordinate axes of the new coordinate system, this light ray R is converted from CCS to PCS, as shown in
Figure 6b. We define the domain of
as from
to
. When a light ray intersects with the positive of the X-axis in CCS,
r is positive. On the contrary,
r is negative. Each light ray is marked by a black dot and all the light rays constitute the shaded area in PCS.
The traditional 2PP light field has been widely studied, and its light ray’s spatial distributions are shown in
Figure 6c,d. It can be seen that the 2PP light field can only represent a subset of light rays, and cannot completely describe the light rays in the whole observation space. Therefore, only a part of viewpoint images can be provided in the rendering stage.
Figure 6f shows the light ray’s distribution of the cube surface light field in ray space. It can be seen that the angular domain
is symmetric in (
,
), which covers the whole observation space outside the cube surface. The domain of the light ray’s distance
r is symmetric on (
,
a) where
a is half of the square of the diagonal length, and the light rays are uniformly distributed in the closed area composed of
and
r.
5.2. Time Performance
To evaluate the time performance of the proposed method, we use a cube surface light field of the Cornell Box with a resolution of
for all of our experiments. The under-sampled light rays are all processed by the CBSI, and the images with the resolutions of
,
,
,
are rendered for this evaluation. We count the frame rate of generating 100 novel views using our interactive rendering as well as the path tracing rendering with the corresponding resolutions. The comparisons of these two kinds of frame rates are shown in
Figure 7. It is worth noting that the frame rate of the path tracing rendering refers to the time consumption when each pixel represents by only one light ray. Although the configuration in the path tracing rendering will lead to aliasing artifacts, this evaluation only considers the time performance of different methods.
It can be seen that different rendering resolutions have little influence on the frame rate. With the improvement of rendering resolution, the frame rate does not decrease or increase significantly. This is because 3D texture mapping is implemented in GPU with parallel acceleration. Under the same rendering resolution, our method can get a higher frame rate than the path tracing rendering, and the highest frame rate reaches more than 250 FPS. In contrast, the average frame rate of the path tracing rendering is about 30 FPS, indicating that our method gets better time performance. This is because our rendering only requires querying light rays from the pre-sampled cube surface light field, and the complexity for the light ray query is O(1) by using compressed 3D texture mapping.
At the same time, we also count the frame rate when using different interpolation methods (NNI, LI, BLI, BCI, and CBSI) to render novel views with a fixed image resolution of
pixels. As can be seen from
Figure 8, different interpolation methods have an obvious influence on the rendering frame rate, and more complex interpolation methods will appropriately reduce the frame rate of interactive novel view rendering. This is because the complex interpolation algorithm requires blending more light rays, which increases the computation consumption. When the CBSI is used for processing the under-sampled light rays, the average frame rate of the proposed method is about 75 FPS (the lowest average frame rate), i.e., the worst-case can still meet the real-time requirement for human eyes. This is due to the simplicity of our single-layer ray casting algorithm and the GPU parallel acceleration of the light ray query, making the rendering in real-time.
In this evaluation, the memory usage of our method is about 384 MB for the cube surface light field images, while the memory usage of the path tracing rendering is almost negligible because of the geometric simplicity of the Cornell Box scene. Our method uses the cube surface light field to encode the whole scene’s geometry and appearance. In contrast to traditional mesh-based methods, our method does not depend on the geometric complexity of the scene, i.e., the geometric complexity of the scene can hardly influence the rendering efficiency. However, the traditional mesh-based methods must consider the rendering overhead caused by various scenes’ geometric structures. Moreover, mesh-based large scene rendering is still a problem to be further studied. Compared with the learning-based methods, our method can achieve interactive free-viewpoint rendering. For example, the local light field fusion [
6] limits the viewpoints of the light field in a local small range, while the viewpoint of our method is arbitrary in arbitrary positions and directions outside the cube surface. NeRF [
15] takes a lot of time to render a single image while our method can reach more than 75 FPS on a personal computer with moderate configurations.
In addition, the proposed method is compared with a related method, i.e., 2PP light field to study its performance. To ensure the fairness of this experiment, we use the same approach, i.e., CBSI to render the 2PP light field. The difference is that the input data is no longer the cube surface light field images of the Cornell Box scene but the 2PP light field images which viewpoints are co-planar and imaging planes are also located on a common plane. We report the average frame rate and memory usage of our method and 2PP method when rendering 100 novel views with a resolution of
pixels, as shown in
Table 1. The similar results should be extended to other resolutions and interpolations.
As can be seen from
Table 1, the average frame rate of 2PP light field rendering is basically the same as our method, but the memory usage is less than the proposed method. This is because 2PP light field only represent a subset of light rays in the scene, which reduces the total light field data amount but also limits the DOF of rendering viewpoints. On the contrary, by sampling all the light rays on the cube surface, our method can provide free-viewpoint rendering, even though the data amount is greater than the 2PP light field.
5.3. Rendering Quality
To evaluate the quality of images rendered by our method, we use the cube surface light field with a resolution of
and compare the images rendered by several light field interpolation methods with the images rendered by the path tracing. Partial images rendered with a resolution of 2048 × 2048 pixels are shown in
Figure 9.
As can be seen from
Figure 9, the rendering results by the cube surface light field can reconstruct the global illumination effect of the scene. Especially, a more accurate global illumination effect can be rendered when a more appropriate interpolation method is used. For example, the NNI rendering produces aliasing artifacts, while the CBSI rendering produces smoother images. It also proves from another aspect that our method can be used to accelerate the path tracing rendering. This is because our method records the light rays generated by the path tracing rendering in advance, and only a light ray query is needed in the rendering stage.
To further illustrate the quality of rendered images, we use the non-reference image evaluation indexes, BRISQUE [
36] and NIQE [
37] to evaluate all images in viewpoint A and report the results in
Table 2. The lower the values of BRISQUE and NIQE are, the better the image quality is. As can be seen from
Table 2, the best BRISQUE and NIQE are achieved by the path tracing rendering and the CBSI rendering, respectively. Moreover, the CBSI rendering gets the second higher BRISQUE score. This is because each pixel is represented by no more than 16 rays in the cube surface light field rendering while more than 100 rays are blended for each pixel in the path tracing rendering which makes the rendered images smoother. Different interpolation rendering can produce different visual effects, indicating that the more correlated light rays are selected, the more accurate the results are for the under-sampled light rays.
We compare the images rendered by our method with the reference images rendered by the path tracing when 1000 rays are sampled from each pixel and report the SSIM and PSNR in
Figure 10. The CBSI rendering and the NNI rendering get the highest SSIM and PSNR, respectively. This is because the CBSI rendering produces smoother images that are closer to the images rendered by the path tracing rendering. However, the CBSI rendering will blur the edges in the rendered images, making its PSNR lower than others.
5.4. Limitations
All the light field data used in our experiments are synthesized by the path tracing rendering and thus one of our future works is to construct the cube surface light field from the real-captured images and achieve interactive free-viewpoint rendering. Moreover, various vision tasks, such as image relighting and refocusing that benefit from the cube surface light field representation, will also be further investigated.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}