
Automatic Screening of the Eyes in a Deep-Learning–Based Ensemble Model Using Actual Eye Checkup Optical Coherence Tomography Images

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
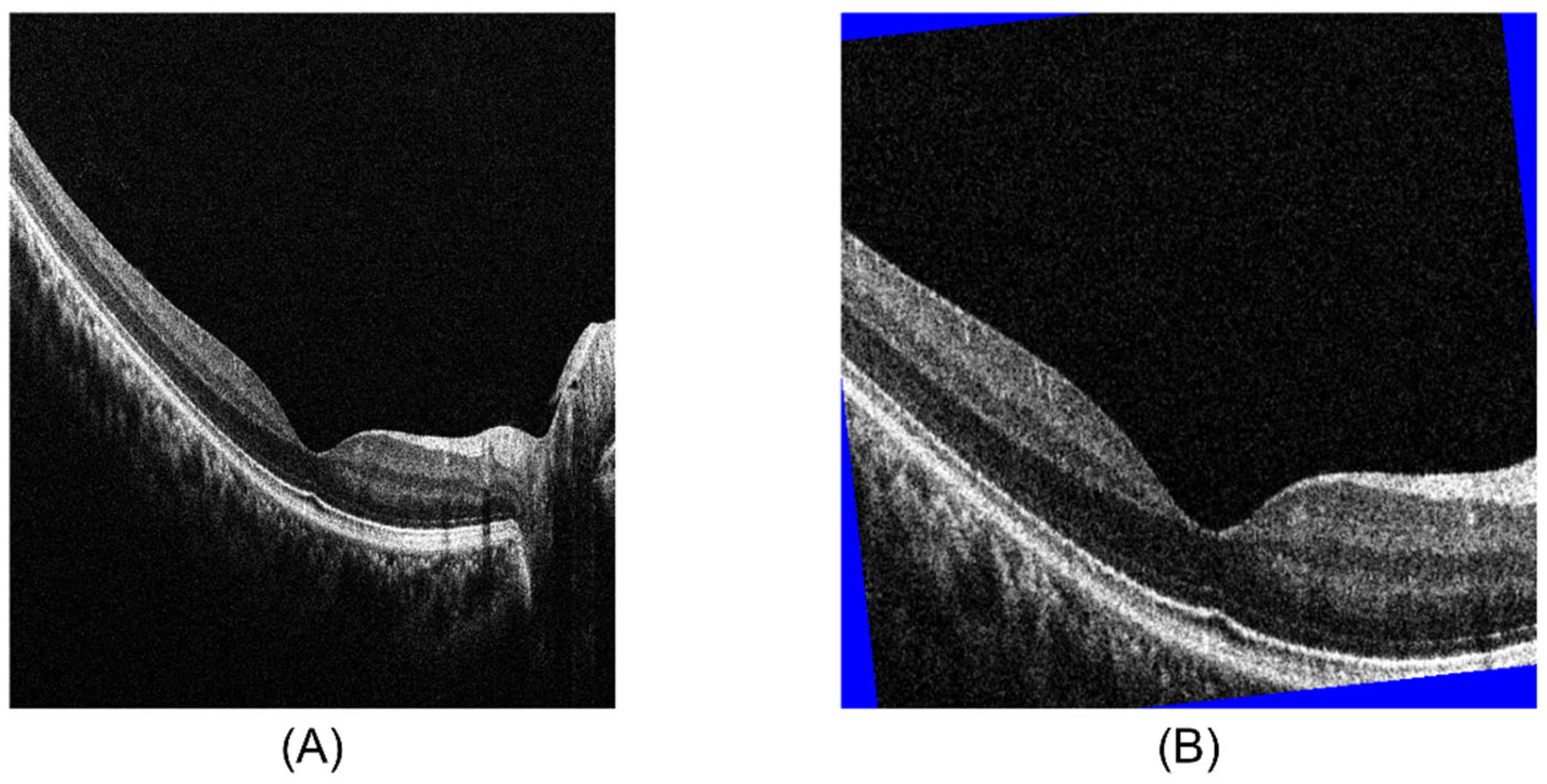
2.2. OCT Imaging
2.3. Datasets
Labeling of Abnormal and Normal Images
3. Experiment 1
3.1. Methods
3.1.1. Preprocessing
3.1.2. Network
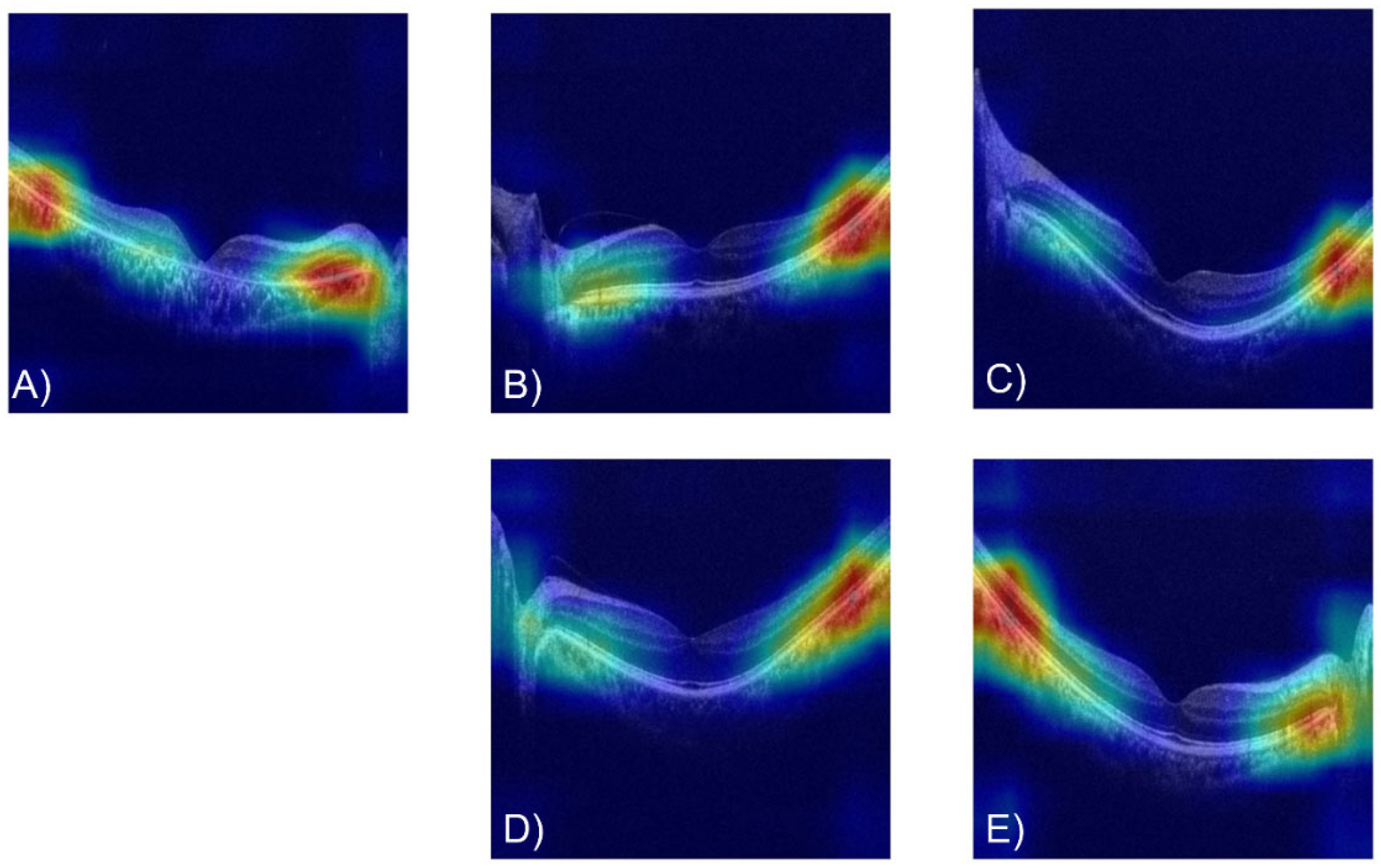
3.1.3. Data Visualization
3.1.4. Classification of Ocular Disease
3.1.5. Statistical Analysis
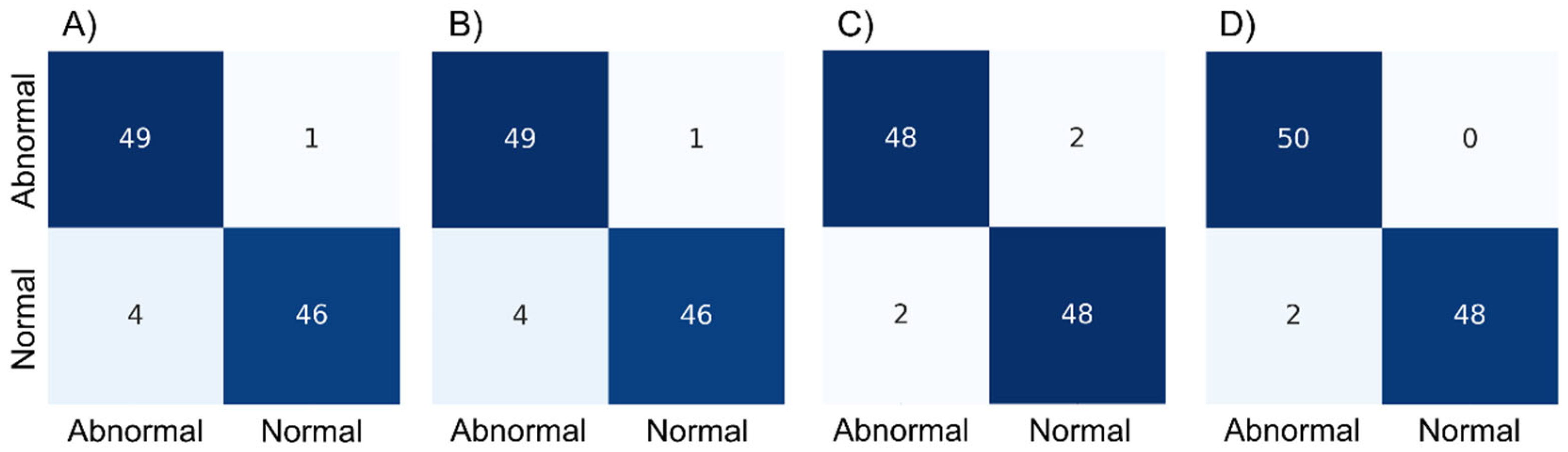
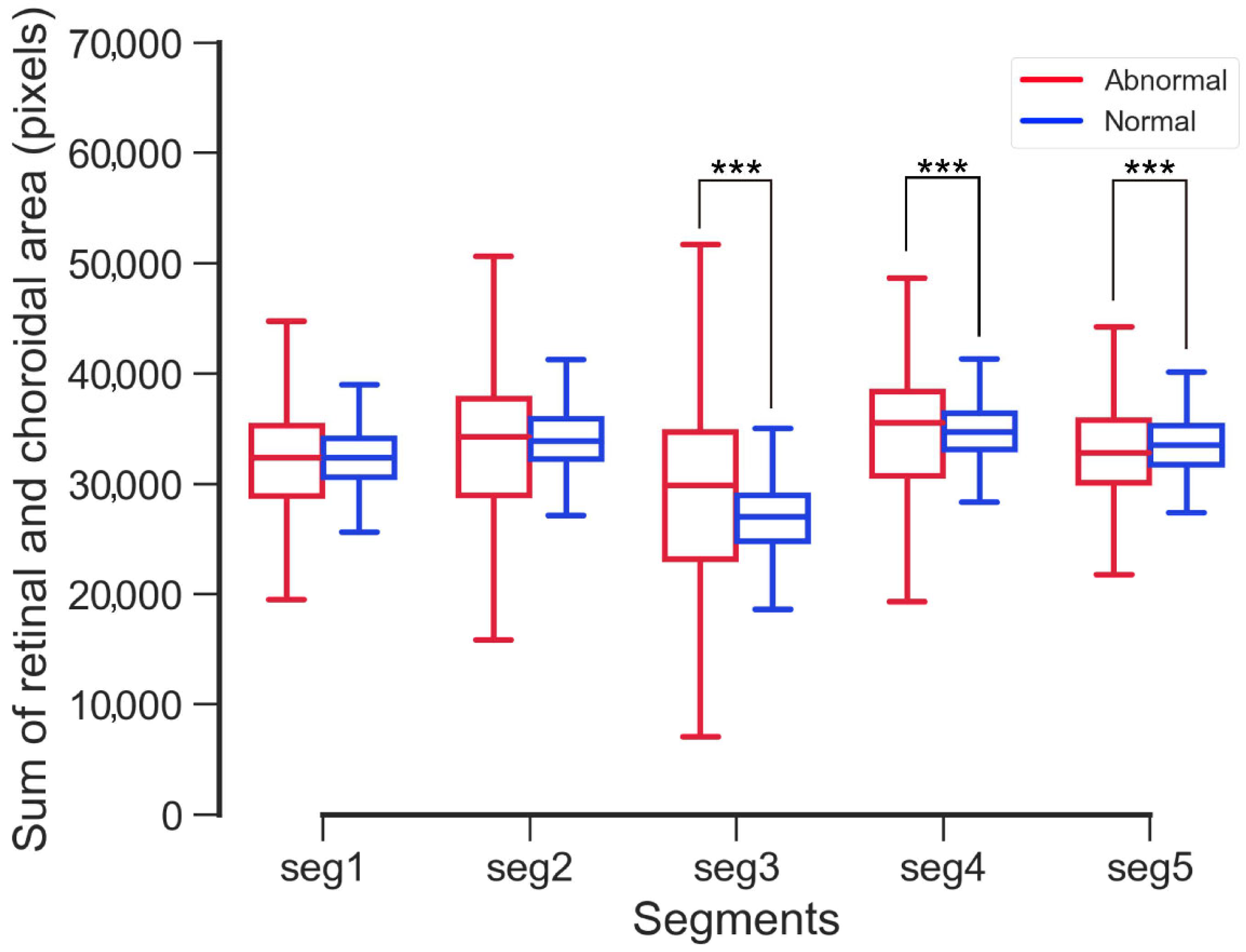
3.2. Results 1
4. Experiment 2
4.1. Methods
4.1.1. Preprocessing
4.1.2. Network
4.1.3. Statistical Analysis
4.2. Results
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thapa, R.; Khanal, S.; Tan, H.S.; Thapa, S.S.; van Rens, G. Prevalence, Pattern and Risk Factors of Retinal Diseases among an Elderly Population in Nepal: The Bhaktapur Retina Study. Clin. Ophthalmol. 2020, 14, 2109–2118. [Google Scholar] [CrossRef]
- Klein, R.; Klein, B.E.K. The Prevalence of Age-Related Eye Diseases and Visual Impairment in Aging: Current Estimates. Investig. Opthalmol. Vis. Sci. 2013, 54, ORSF5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roberts, C.B. Economic Cost of Visual Impairment in Japan. Arch. Ophthalmol. 2010, 128, 766. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hiratsuka, Y.; Ono, K.; Nakano, T.; Tamura, H.; Goto, R.; Kawasaki, R.; Kawashima, M.; Yamada, M. Current status of eye examinations for adults and local government initiatives. J. Jpn. Ophthalmol. Assoc. 2017, 88, 3–22. [Google Scholar]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical Coherence Tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [Green Version]
- Jaffe, G.J.; Caprioli, J. Optical coherence tomography to detect and manage retinal disease and glaucoma. Am. J. Ophthalmol. 2004, 137, 156–169. [Google Scholar] [CrossRef]
- Gibson, D.M. The geographic distribution of eye care providers in the United States: Implications for a national strategy to improve vision health. Prev. Med. 2015, 73, 30–36. [Google Scholar] [CrossRef]
- Center for Disease Control and Prevention. National Diabetes Statistics Report 2020. Available online: https://www.cdc.gov/diabetes/pdfs/data/statistics/national-diabetes-statistics-report.pdf (accessed on 28 May 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Lee, C.S.; Baughman, D.M.; Lee, A.Y. Deep Learning Is Effective for Classifying Normal versus Age-Related Macular Degeneration OCT Images. Ophthalmol. Retin. 2017, 1, 322–327. [Google Scholar] [CrossRef]
- Yoon, J.; Han, J.; Park, J.I.; Hwang, J.S.; Han, J.M.; Sohn, J.; Park, K.H.; Hwang, D.D.-J. Optical coherence tomography-based deep-learning model for detecting central serous chorioretinopathy. Sci. Rep. 2020, 10, 18852. [Google Scholar] [CrossRef]
- De Fauw, J.; Ledsam, J.R.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D.; et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef]
- Yoo, T.K.; Choi, J.Y.; Seo, J.G.; Ramasubramanian, B.; Selvaperumal, S.; Kim, D.W. The possibility of the combination of OCT and fundus images for improving the diagnostic accuracy of deep learning for age-related macular degeneration: A preliminary experiment. Med. Biol. Eng. Comput. 2019, 57, 677–687. [Google Scholar] [CrossRef] [PubMed]
- Awais, M.; Müller, H.; Tang, T.B.; Meriaudeau, F. Classification of SD-OCT images using a Deep learning approach. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 489–492. [Google Scholar]
- Wang, J.; Deng, G.; Li, W.; Chen, Y.; Gao, F.; Liu, H.; He, Y.; Shi, G. Deep learning for quality assessment of retinal OCT images. Biomed. Opt. Express 2019, 10, 6057–6072. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993v5. [Google Scholar]
- Tan, M.; Quoc. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Roy, K.; Chaudhuri, S.S.; Roy, P.; Chatterjee, S.; Banerjee, S. Transfer Learning Coupled Convolution Neural Networks in Detecting Retinal Diseases Using OCT Images. In Intelligent Computing: Image Processing Based Applications; Mandal, J., Banerjee, S., Eds.; Springer: Singapore, 2020; Volume 1157, pp. 153–173. [Google Scholar]
- Van Der Heijden, A.A.; Abramoff, M.D.; Verbraak, F.; Van Hecke, M.V.; Liem, A.; Nijpels, G. Validation of automated screening for referable diabetic retinopathy with the IDx-DR device in the Hoorn Diabetes Care System. Acta Ophthalmol. 2018, 96, 63–68. [Google Scholar] [CrossRef]
- Abràmoff, M.D.; Lavin, P.T.; Birch, M.; Shah, N.; Folk, J.C. Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices. NPJ Digit. Med. 2018, 1, 39. [Google Scholar] [CrossRef]
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.V.; Lakshminarayanan, B.; Snoek, J. Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift. arXiv 2019, arXiv:1906.02530. [Google Scholar]
- Tufail, A.; Kapetanakis, V.V.; Salas-Vega, S.; Egan, C.; Rudisill, C.; Owen, C.G.; Lee, A.; Louw, V.; Anderson, J.; Liew, G.; et al. An observational study to assess if automated diabetic retinopathy image assessment software can replace one or more steps of manual imaging grading and to determine their cost-effectiveness. Health Technol. Assess. 2016, 20, 1–72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Z.; Ayton, L.N.; Guymer, R.H.; Luu, C.D. Second reflective band intensity in age-related macular degeneration. Ophthalmology 2013, 120, 1307–1308.e1. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.W.; Wu, Z.; Guymer, R.H.; Luu, C.D. Ellipsoid zone on optical coherence tomography: A review. Clin. Exp. Ophthalmol. 2016, 44, 422–430. [Google Scholar] [CrossRef]
- Wu, Z.; Ayton, L.N.; Guymer, R.H.; Luu, C.D. Relationship Between the Second Reflective Band on Optical Coherence Tomography and Multifocal Electroretinography in Age-Related Macular Degeneration. Investig. Opthalmol. Vis. Sci. 2013, 54, 2800. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gomes, N.L.; Greenstein, V.C.; Carlson, J.N.; Tsang, S.H.; Smith, R.T.; Carr, R.E.; Hood, D.C.; Chang, S. A Comparison of Fundus Autofluorescence and Retinal Structure in Patients with Stargardt Disease. Investig. Opthalmol. Vis. Sci. 2009, 50, 3953. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Selvaraju, R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2017, arXiv:1610.02391v02393. [Google Scholar]
- Louppe, G. Understanding Random Forests: From Theory to Practice. arXiv 2015, arXiv:1407.7502. [Google Scholar]
- Ranstam, J. Multiple p-values and Bonferroni correction. Osteoarthr. Cartil. 2016, 24, 763–764. [Google Scholar] [CrossRef] [Green Version]
- Russakoff, D.B.; Lamin, A.; Oakley, J.D.; Dubis, A.M.; Sivaprasad, S. Deep Learning for Prediction of AMD Progression: A Pilot Study. Investig. Opthalmol. Vis. Sci. 2019, 60, 712. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
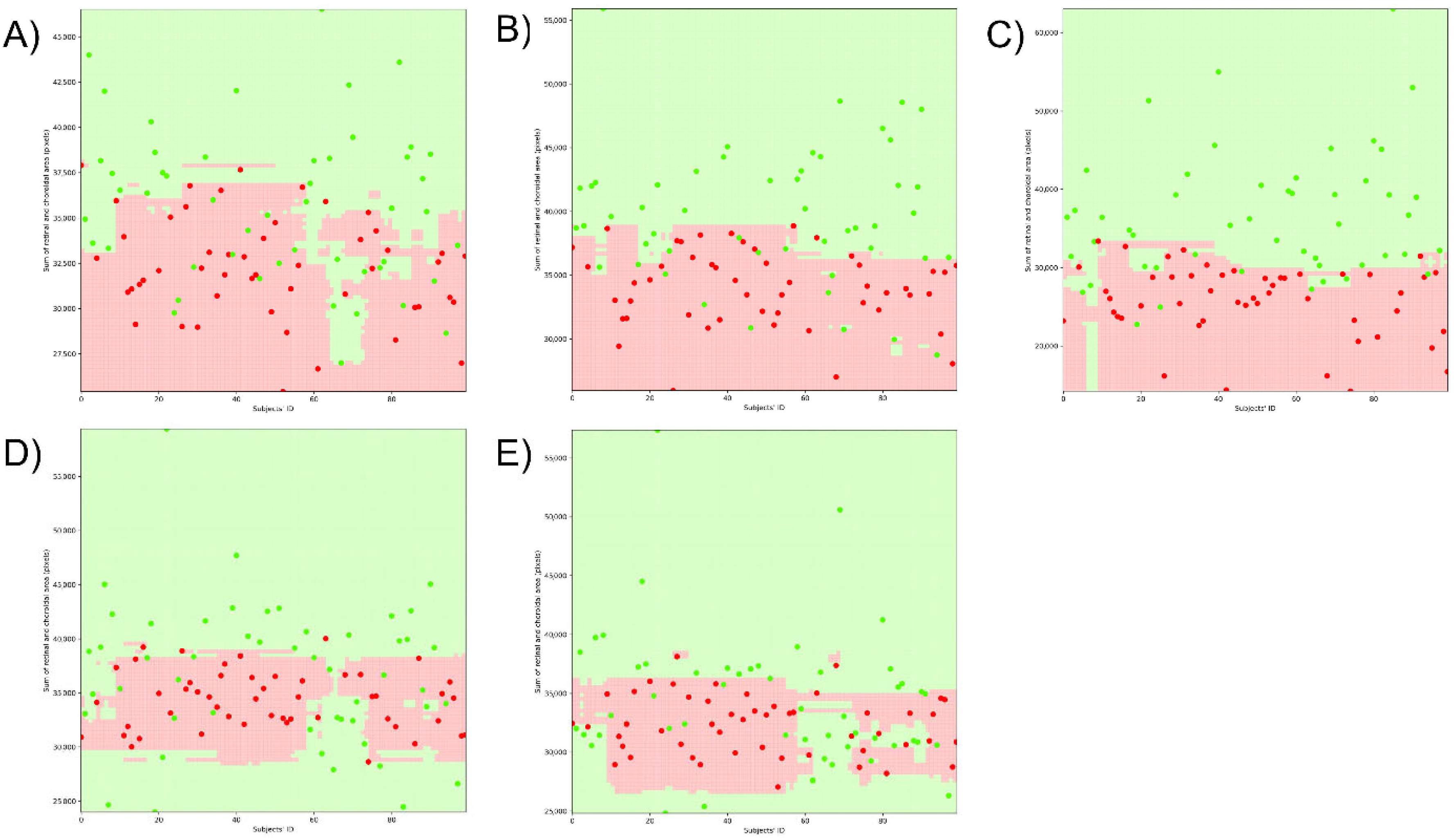{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease | Test Data | ResNet Failure | DenseNet Failure | EfficientNet Failure |
|---|---|---|---|---|
| AMD | 5 | 1 | ||
| CSC | 1 | |||
| ERM | 6 | 1 | ||
| Macular edema | 14 | |||
| Macular hole | 3 | |||
| High myopia | 5 | |||
| Post-operation | 2 | |||
| RP | 12 | 1 | 1 | |
| RRD | 1 | |||
| VMTS | 1 | |||
| Total | 50 | 1 | 1 |
| Disease | Test Data | Random Forest Failure |
|---|---|---|
| AMD | 5 | |
| CSC | 1 | |
| ERM | 6 | 1 |
| Macular edema | 14 | 2 |
| Macular hole | 3 | |
| High myopia | 5 | |
| Post-operation | 2 | |
| RP | 12 | 2 |
| RRD | 1 | |
| VMTS | 1 | |
| Total | 50 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirota, M.; Ueno, S.; Inooka, T.; Ito, Y.; Takeyama, H.; Inoue, Y.; Watanabe, E.; Mizota, A. Automatic Screening of the Eyes in a Deep-Learning–Based Ensemble Model Using Actual Eye Checkup Optical Coherence Tomography Images. Appl. Sci. 2022, 12, 6872. https://doi.org/10.3390/app12146872
Hirota M, Ueno S, Inooka T, Ito Y, Takeyama H, Inoue Y, Watanabe E, Mizota A. Automatic Screening of the Eyes in a Deep-Learning–Based Ensemble Model Using Actual Eye Checkup Optical Coherence Tomography Images. Applied Sciences. 2022; 12(14):6872. https://doi.org/10.3390/app12146872
Chicago/Turabian StyleHirota, Masakazu, Shinji Ueno, Taiga Inooka, Yasuki Ito, Hideo Takeyama, Yuji Inoue, Emiko Watanabe, and Atsushi Mizota. 2022. "Automatic Screening of the Eyes in a Deep-Learning–Based Ensemble Model Using Actual Eye Checkup Optical Coherence Tomography Images" Applied Sciences 12, no. 14: 6872. https://doi.org/10.3390/app12146872