
Limited-Angle CT Reconstruction with Generative Adversarial Network Sinogram Inpainting and Unsupervised Artifact Removal

Abstract
:1. Introduction
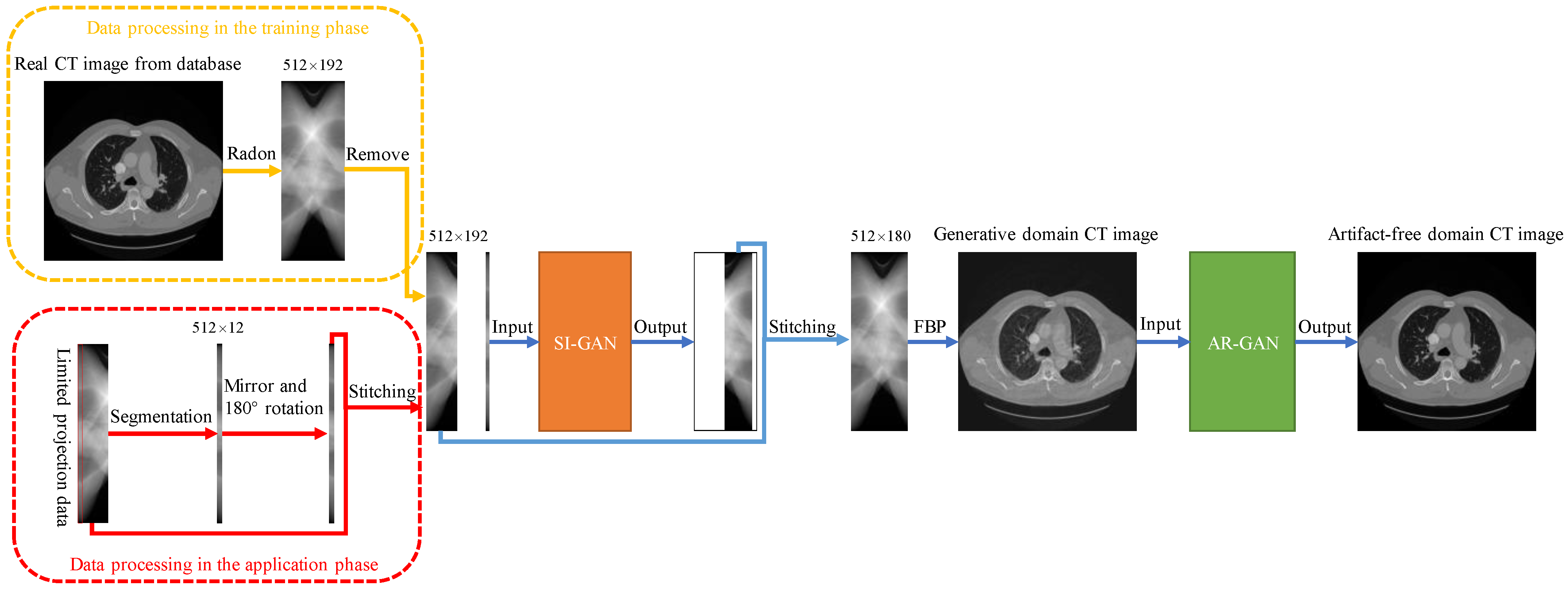
2. Materials and Methods
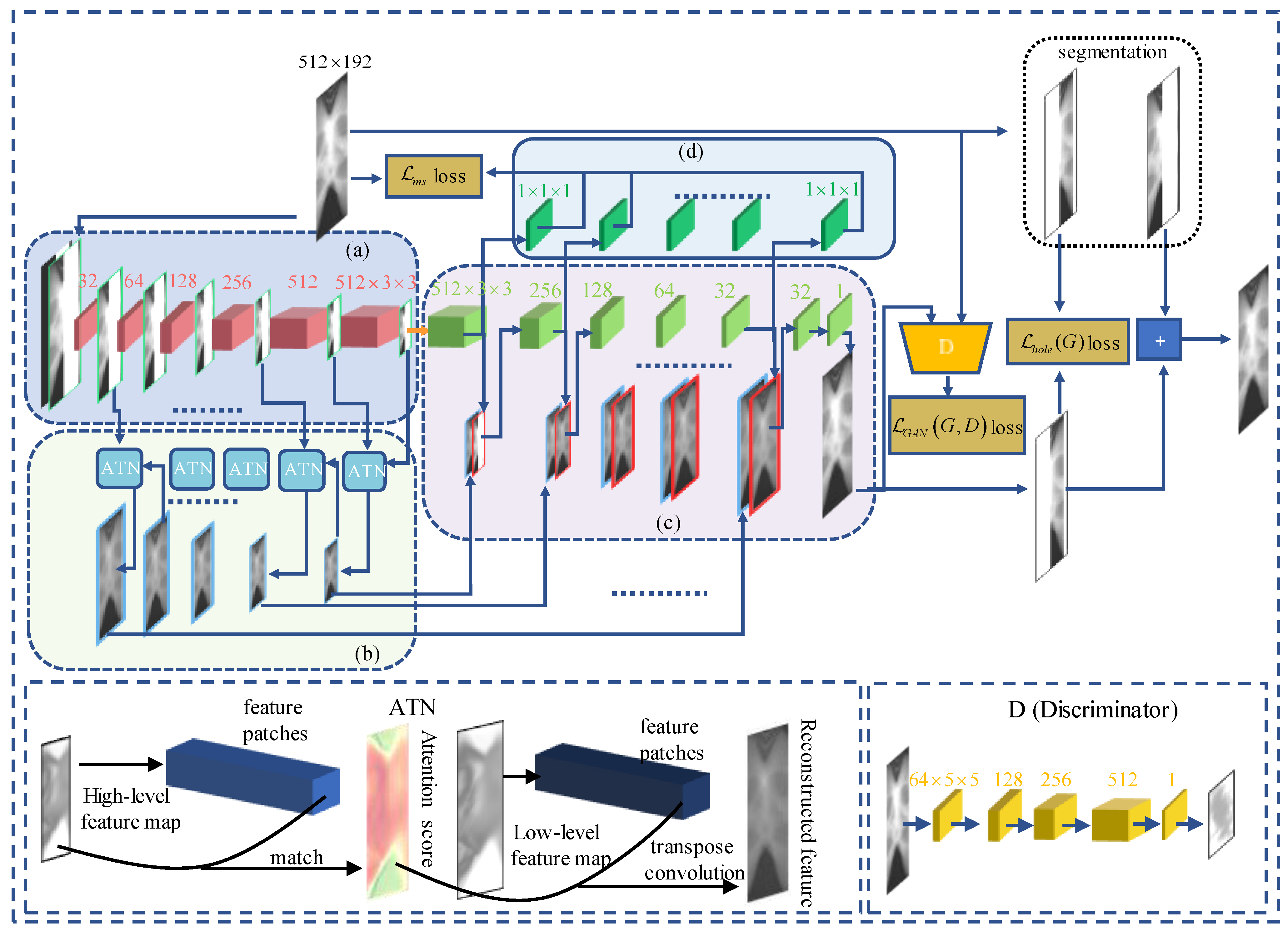
2.1. Sinogram Inpainting Generative Adversarial Network (SI-GAN)
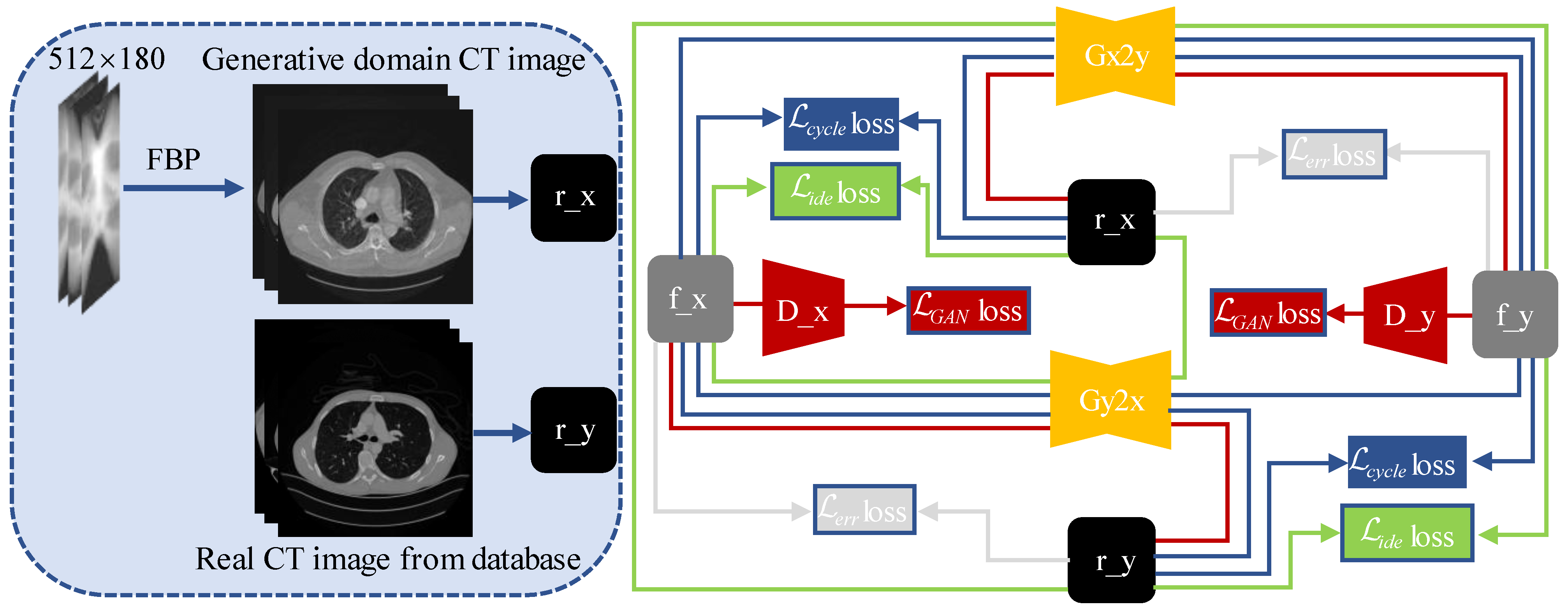
2.2. Artifact Removal Generative Adversarial Network (AR-GAN)
2.3. Comparison Methods and Evaluation Indicators
2.4. Data and Settings
3. Results
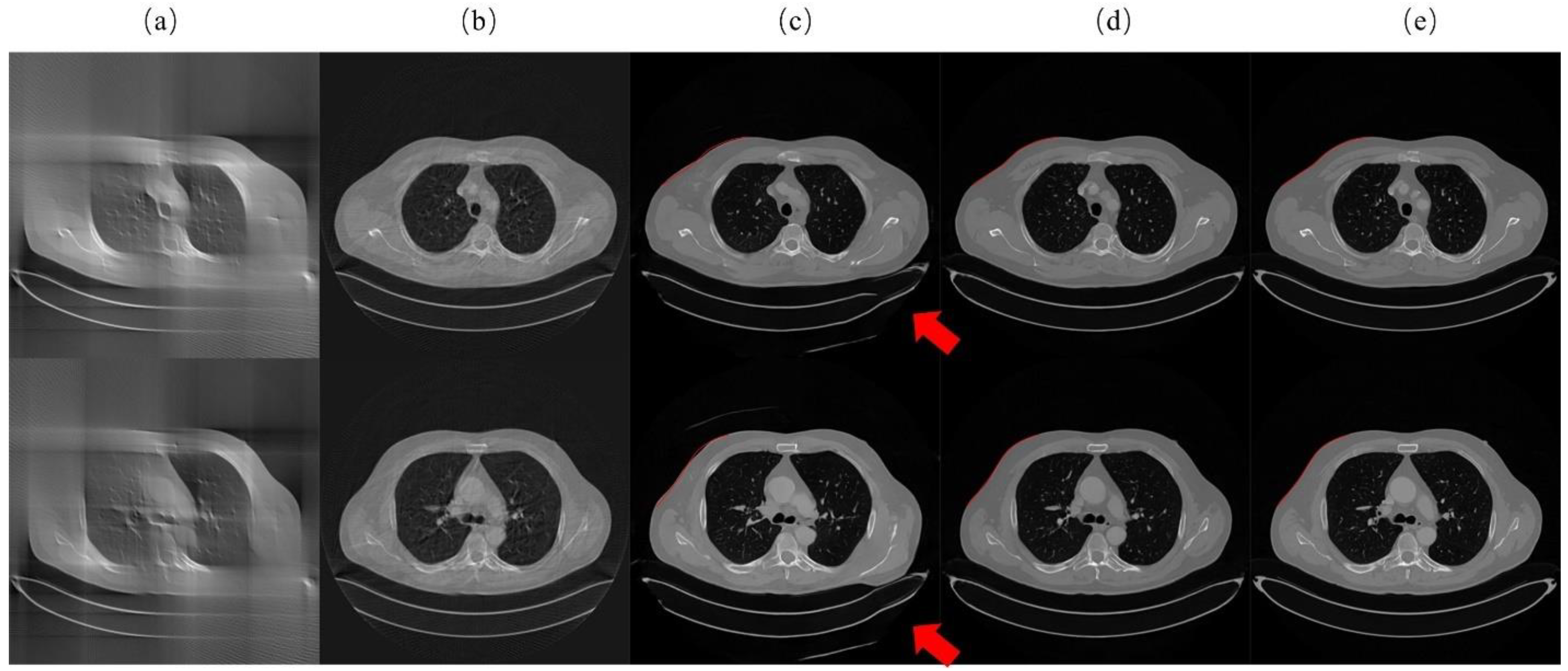
3.1. Comparison with Different Architecture
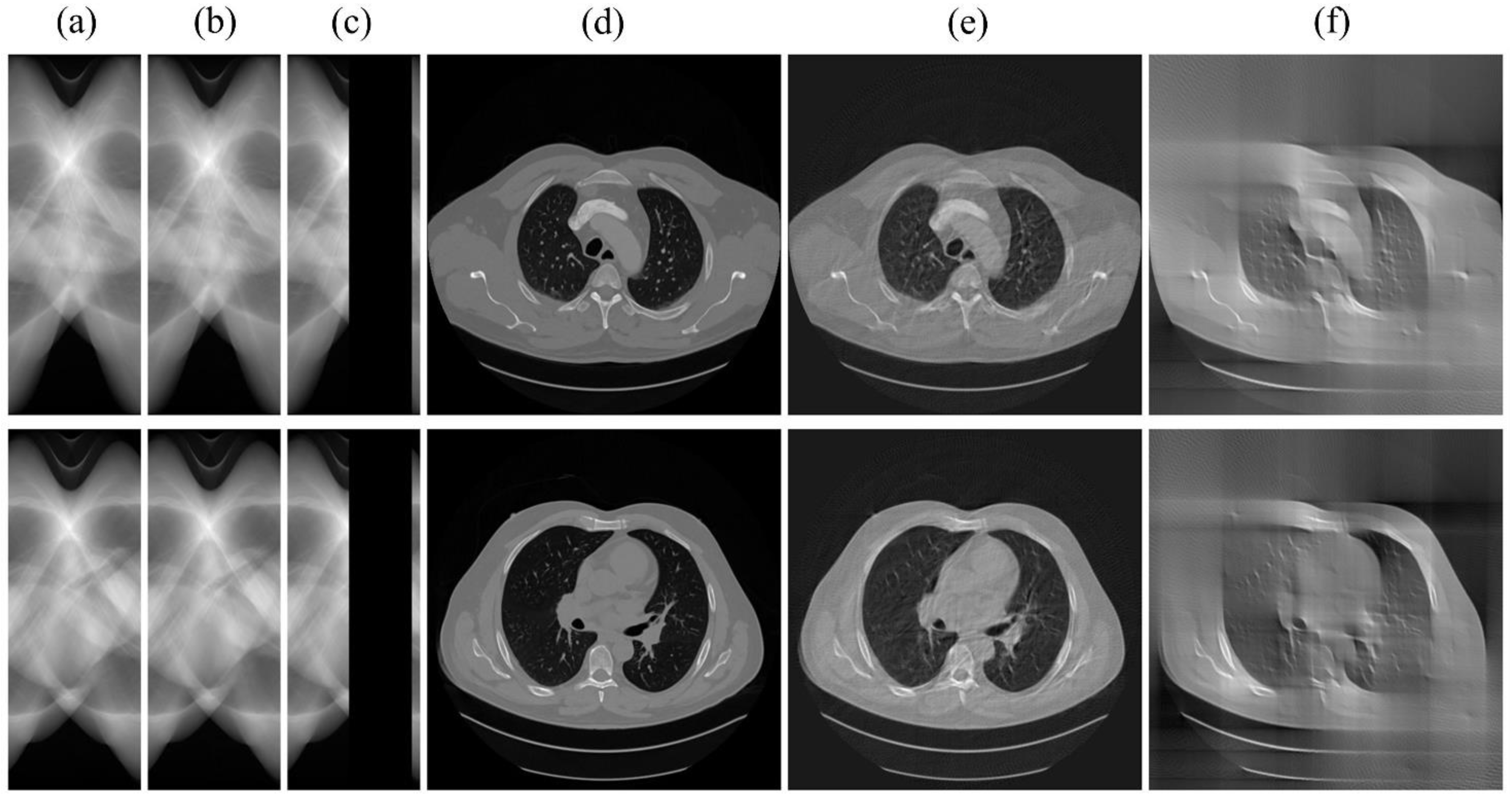
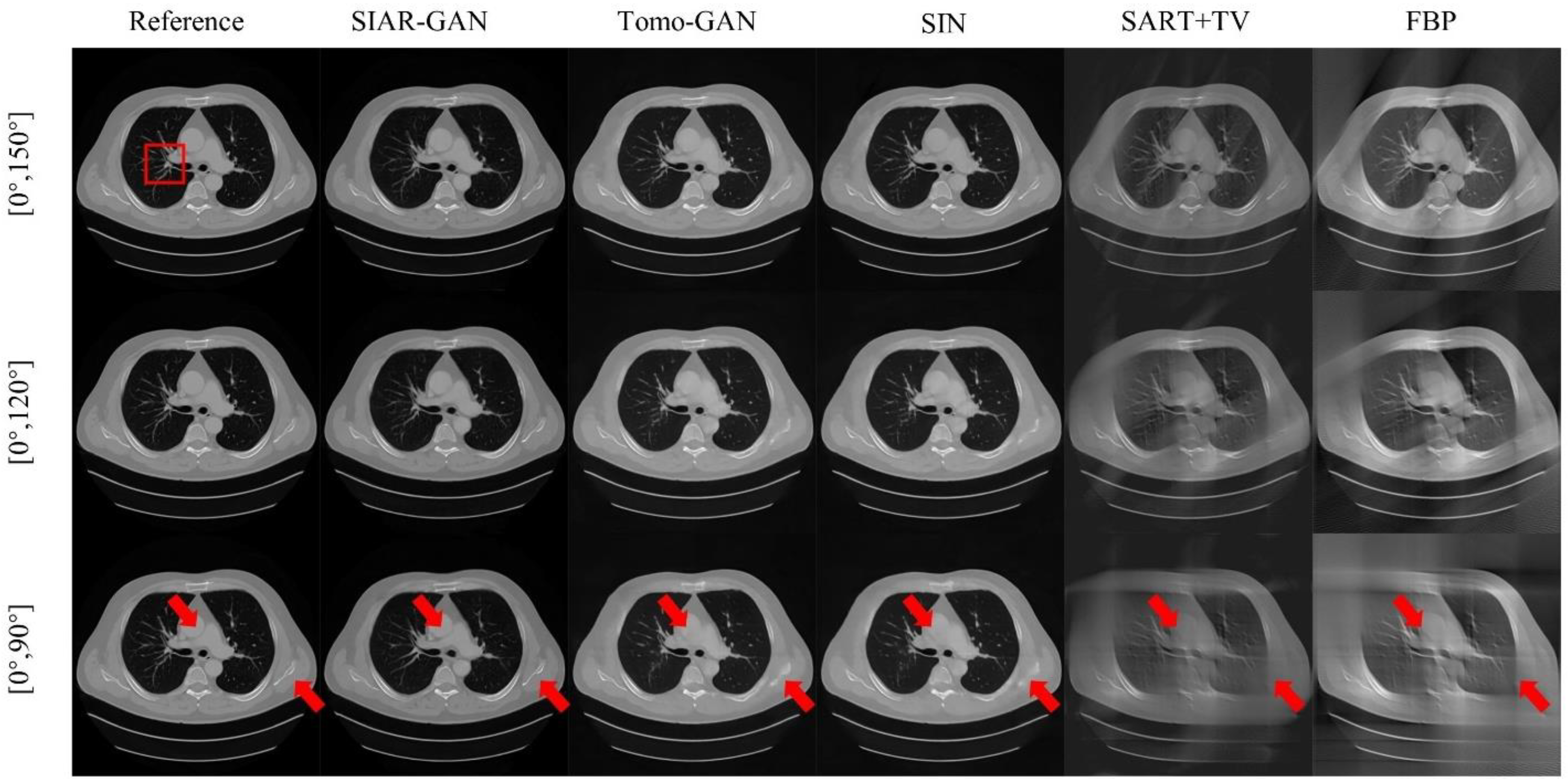
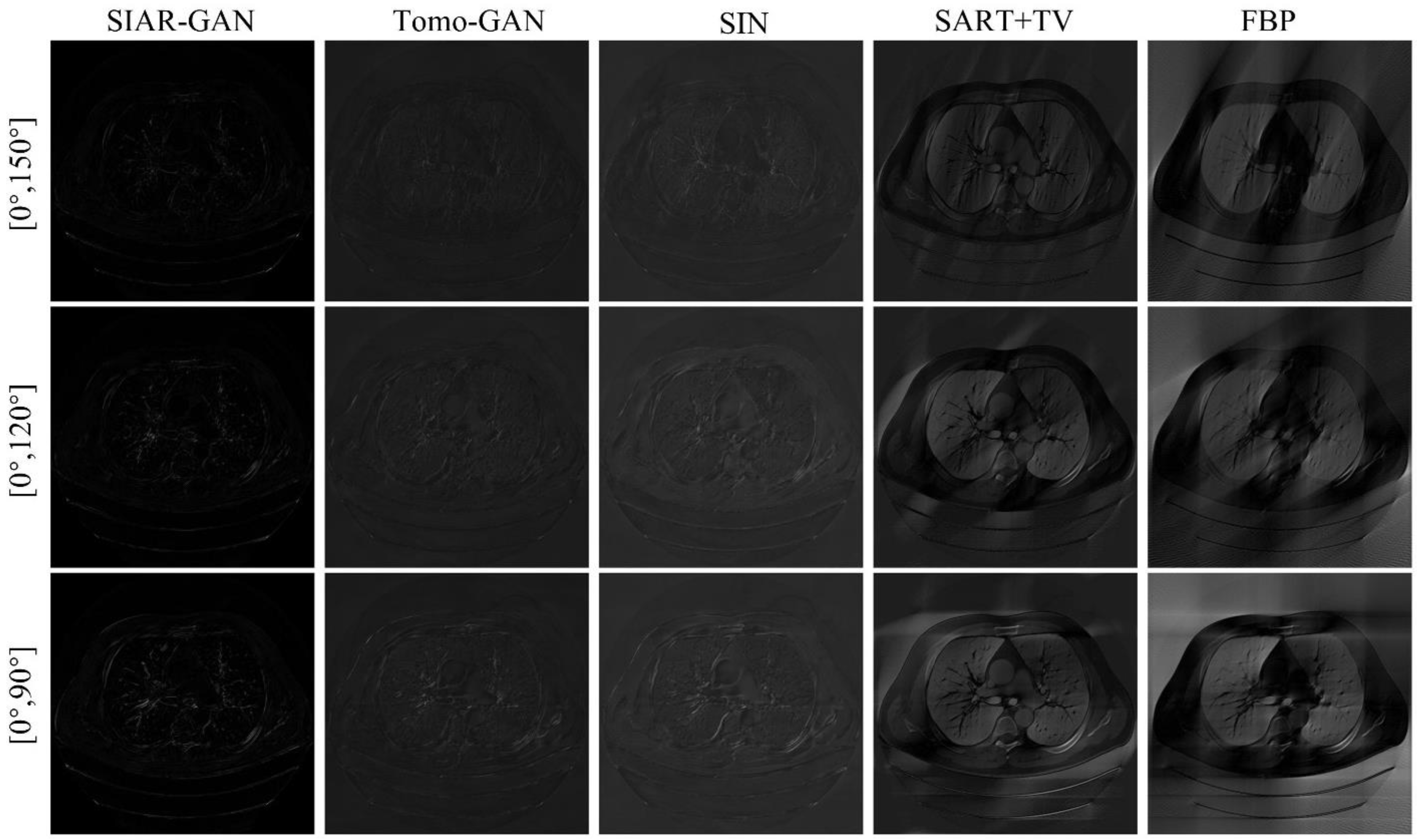
3.2. Qualitative Experimental Results for Lung Data
3.3. Quantitative Experimental Results for Lung Data
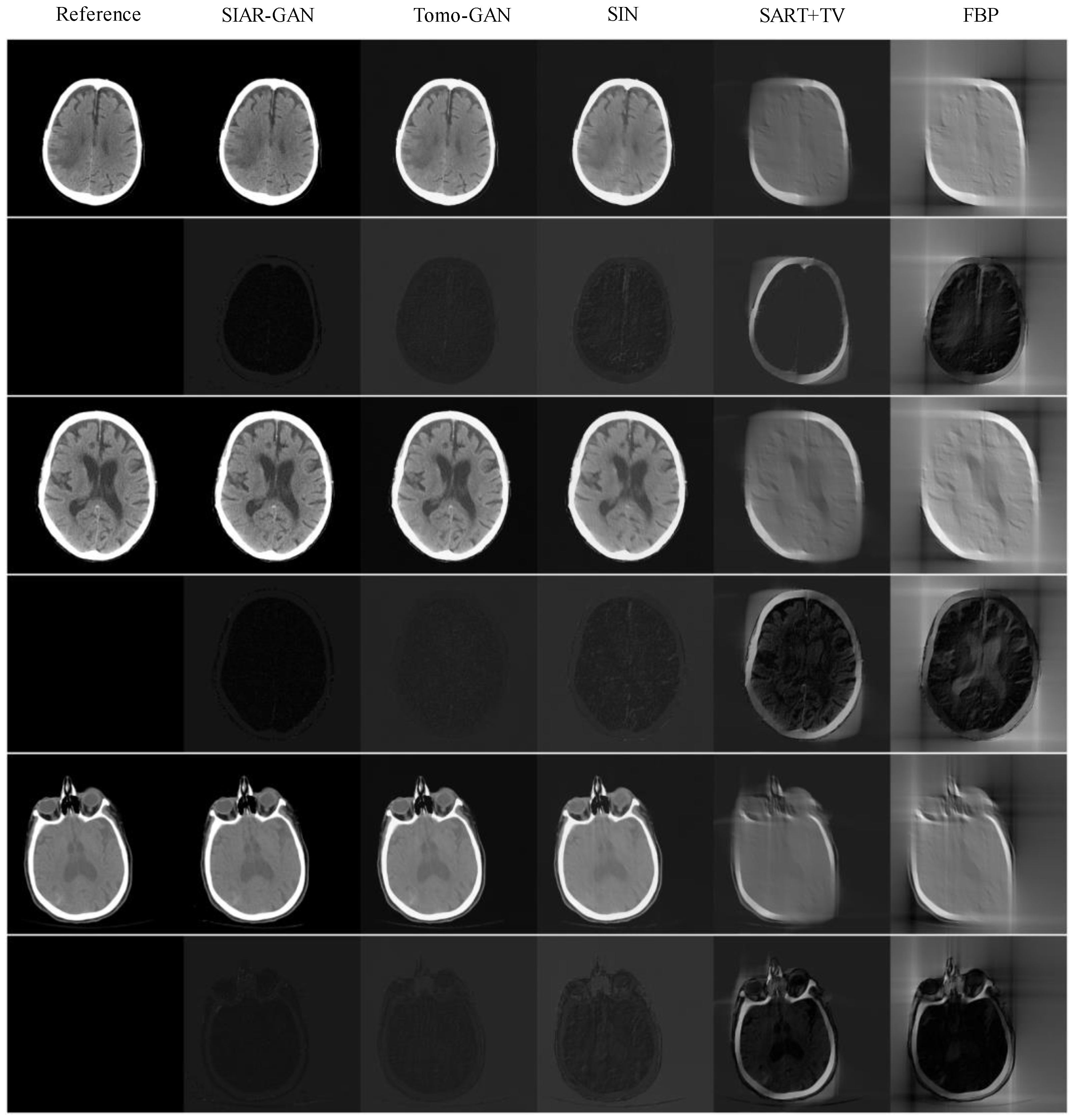
3.4. Qualitative and Quantitative Experimental Results of Head Data
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Quinto, E.T. Artifacts and Visible Singularities in Limited Data X-ray Tomography. Sens. Imaging 2017, 18, 9.1–9.14. [Google Scholar] [CrossRef] [Green Version]
- Delaney, A.H.; Bresler, Y. Globally convergent edge-preserving regularized reconstruction: An application to limited-angle tomography. IEEE Trans. Image Process. 1998, 7, 204–221. [Google Scholar] [CrossRef] [PubMed]
- Nori, J.; Gill, M.K.; Vignoli, C.; Bicchierai, G.; De Benedetto, D.; Di Naro, F.; Vanzi, E.; Boeri, C.; Miele, V. Artefacts in contrast enhanced digital mammography: How can they affect diagnostic image quality and confuse clinical diagnosis? Insights Imaging 2020, 11, 16. [Google Scholar] [CrossRef] [PubMed]
- Geiser, W.R.; Einstein, S.A.; Yang, W.-T. Artifacts in Digital Breast Tomosynthesis. Am. J. Roentgenol. 2018, 211, 926–932. [Google Scholar] [CrossRef]
- Mohamed, A.A.H.; Myung Hye, C.; Soo Yeol, L. Half-scan artifact correction using generative adversarial network for dental CT. Comput. Biol. Med. 2021, 132, 104313. [Google Scholar] [CrossRef]
- Jerri, J.A. The Shannon sampling theorem—Its various extensions and applications: A tutorial review. Proc. IEEE 2005, 65, 1565–1596. [Google Scholar] [CrossRef]
- Frikel, J.; Quinto, E.T. Characterization and reduction of artifacts in limited angle tomography. Inverse Probl. 2013, 29, 125007. [Google Scholar] [CrossRef] [Green Version]
- Frikel, J. A New Framework for Sparse Regularization in Limited Angle X-Ray Tomography. In Proceedings of the International Symposium on Biomedical Imaging, Rotterdam, The Netherlands, 14–17 April 2010; pp. 824–827. [Google Scholar] [CrossRef]
- Lee, S.H.; Yun, S.J.; Jo, H.H.; Song, J.G. Diagnosis of lumbar spinal fractures in emergency department: Low-dose versus standard-dose CT using model-based iterative reconstruction. Clin. Imaging 2018, 50, 216–222. [Google Scholar] [CrossRef]
- Sun, L.; Zhou, G.; Qin, Z.; Yuan, S.; Lin, Q.; Gui, Z.; Yang, M. A reconstruction method for cone-beam computed laminography based on projection transformation. Meas. Sci. Technol. 2021, 32, 045403. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, H.; Wang, L.; Cai, A.; Li, L.; Yan, B. Limited angle CT reconstruction by simultaneous spatial and Radon domain regularization based on TV and data-driven tight frame. Nucl. Instrum. Methods Phys. Res. Sect. A-Accel. Spectrom. Dect. Assoc. Equip. 2018, 880, 107–117. [Google Scholar] [CrossRef]
- Rao, J.; Ratassepp, M.; Fan, Z. Limited-view ultrasonic guided wave tomography using an adaptive regularization method. J. Appl. Phys. 2016, 120, 113–127. [Google Scholar] [CrossRef]
- Sidky, E.Y.; Kao, C.M.; Pan, X.C. Accurate image reconstruction from few-views and limited-angle data in divergent-beam CT. J. X-ray Sci. Technol. 2006, 14, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Sidky, E.Y.; Pan, X. Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization. Phys. Med. Biol. 2008, 53, 4777–4807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, A.; Wang, L.; Zhang, H.; Yan, B.; Li, L.; Xi, X.; Li, J. Edge guided image reconstruction in linear scan CT by weighted alternating direction TV minimization. J. X-ray Sci. Technol. 2014, 22, 335–349. [Google Scholar] [CrossRef]
- Xie, S.; Yang, T. Artifact Removal in Sparse-Angle CT Based on Feature Fusion Residual Network. IEEE Trans. Radiat. Plasma Med. Sci. 2021, 5, 261–271. [Google Scholar] [CrossRef]
- Higaki, T.; Nakamura, Y.; Zhou, J.; Yu, Z.; Nemoto, T.; Tatsugami, F.; Awai, K. Deep Learning Reconstruction at CT: Phantom Study of the Image Characteristics. Acad. Radiol. 2020, 27, 82–87. [Google Scholar] [CrossRef] [Green Version]
- Higaki, T.; Nakamura, Y.; Tatsugami, F.; Nakaura, T.; Awai, K. Improvement of image quality at CT and MRI using deep learning. Jpn. J. Radiol. 2019, 37, 73–80. [Google Scholar] [CrossRef]
- Zhang, H.; Li, L.; Qiao, K.; Wang, L.; Yan, B.; Li, L.; Hu, G. Image Prediction for Limited-angle Tomography via Deep Learning with Convolutional Neural Network. arXiv 2016, arXiv:1607.08707. [Google Scholar]
- Jin, S.C.; Hsieh, C.J.; Chen, J.C.; Tu, S.H.; Chen, Y.C.; Hsiao, T.C.; Liu, A.; Chou, W.H.; Chu, W.C.; Kuo, C.W. Development of Limited-Angle Iterative Reconstruction Algorithms with Context Encoder-Based Sinogram Completion for Micro-CT Applications. Sensors 2018, 18, 4458. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Hu, Z.; Jiang, C.; Zheng, H.; Ge, Y.; Liang, D. Artifact removal using a hybrid-domain convolutional neural network for limited-angle computed tomography imaging. Phys. Med. Biol. 2020, 65, 155010. [Google Scholar] [CrossRef]
- Li, Z.H.; Cai, A.L.; Wang, L.Y.; Zhang, W.K.; Tang, C.; Li, L.; Liang, N.N.; Yan, B. Promising Generative Adversarial Network Based Sinogram Inpainting Method for Ultra-Limited-Angle Computed Tomography Imaging. Sensors 2019, 19, 3941. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, J.; Chen, Z.; Zhang, L.; Jin, X. Unsupervised Learnable Sinogram Inpainting Network (SIN) for Limited Angle CT reconstruction. arXiv 2018, arXiv:1811.03911. [Google Scholar]
- Yu, H.; Wang, G. Compressed sensing based interior tomography. Phys. Med. Biol. 2009, 54, 2791–2805. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Lin, X.Y.; Eck, B. Limited Angle Tomography Reconstruction: Synthetic Reconstruction via Unsupervised Sinogram Adaptation. In Proceedings of the Information Processing in Medical Imaging, IPMI 2019, Hong Kong, China, 2–7 June 2019; pp. 141–152. [Google Scholar] [CrossRef]
- Yu, J.H.; Lin, Z.; Yang, J.M.; Shen, X.H.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Yan, K.; Wang, X.; Lu, L.; Summers, R.M. DeepLesion: Automated mining of large-scale lesion annotations and universal lesion detection with deep learning. J. Med. Imaging 2018, 5, 036501. [Google Scholar] [CrossRef] [PubMed]
- Moen, T.R.; Chen, B.Y.; Holmes, D.R.; Duan, X.H.; Yu, Z.C.; Yu, L.F.; Leng, S.; Fletcher, J.G.; McCollough, C.H. Low dose CT image and projection dataset. Med. Phys. 2021, 48, 902–911. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Angle | FBP | SART-TV | SIN | Tomo-GAN | SIAR-GAN |
|---|---|---|---|---|---|
| 16.3457 ± 1.6106 | 19.2531 ± 0.5965 | 26.7125 ± 1.7880 | 28.9774 ± 1.6971 | 31.1028 ± 1.5224 | |
| 15.7783 ± 0.9374 | 18.1774 ± 0.4456 | 25.3332 ± 1.5566 | 27.5112 ± 1.6104 | 30.2231 ± 1.3819 | |
| 13.0208 ± 0.5416 | 16.7119 ± 0.3335 | 23.2377 ± 1.1701 | 25.6884 ± 1.6570 | 29. 2011 ± 1.3703 |
| Angle | FBP | SART-TV | SIN | Tomo-GAN | SIAR-GAN |
|---|---|---|---|---|---|
| 0.5065 ± 0.0521 | 0.5321 ± 0.0332 | 0.8611 ± 0.0356 | 0.9077 ± 0.0327 | 0.9390 ± 0.0277 | |
| 0.4503 ± 0.0423 | 0.4697 ± 0.0271 | 0.8153 ± 0.0423 | 0.8803 ± 0.0327 | 0.9255 ± 0.0304 | |
| 0.3093 ± 0.0316 | 0.3501 ± 0.0194 | 0.7013 ± 0.0272 | 0.8102 ± 0.0524 | 0.9102 ± 0.0240 |
| Angle | FBP | SART-TV | SIN | Tomo-GAN | SIAR-GAN |
|---|---|---|---|---|---|
| 39.4962 5.0869 | 28.2127 0.9706 | 13.0721 2.1081 | 11.0954 2.6180 | 7.3066 1.4727 | |
| 41.6998 4.4619 | 31.7996 1.6256 | 15.8862 2.3972 | 13.7782 2.6471 | 7.9773 1.4524 | |
| 57.0615 3.5469 | 37.0192 1.4280 | 19.5390 1.8999 | 15.5744 3.0219 | 8.8614 1.6025 |
| Indicator | FBP | SART-TV | SIN | Tomo-GAN | SIAR-GAN |
|---|---|---|---|---|---|
| PSNR | 10.1629 ± 0.6996 | 14.7071 ± 0.6204 | 23.1279 ± 1.6591 | 25.7152 ± 2.4894 | 28.7140 ± 1.5467 |
| SSIM | 0.2812 ± 0.0339 | 0.2973 ± 0.0348 | 0.7249 ± 0.0548 | 0.7886 ± 0.0597 | 0.8814 ± 0.0496 |
| RMSE | 79.3923 ± 6.2318 | 47.0200 ± 2.3155 | 18.1147 ± 3.4723 | 13.8080 ± 4.5798 | 9.4966 ± 1.9533 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, E.; Ni, P.; Zhang, R.; Li, X. Limited-Angle CT Reconstruction with Generative Adversarial Network Sinogram Inpainting and Unsupervised Artifact Removal. Appl. Sci. 2022, 12, 6268. https://doi.org/10.3390/app12126268
Xie E, Ni P, Zhang R, Li X. Limited-Angle CT Reconstruction with Generative Adversarial Network Sinogram Inpainting and Unsupervised Artifact Removal. Applied Sciences. 2022; 12(12):6268. https://doi.org/10.3390/app12126268
Chicago/Turabian StyleXie, En, Peijun Ni, Rongfan Zhang, and Xiongbing Li. 2022. "Limited-Angle CT Reconstruction with Generative Adversarial Network Sinogram Inpainting and Unsupervised Artifact Removal" Applied Sciences 12, no. 12: 6268. https://doi.org/10.3390/app12126268