
WRNFS: Width Residual Neuro Fuzzy System, a Fast-Learning Algorithm with High Interpretability


1
School of Transportation, Fujian University of Technology, Fuzhou 350108, China
2
Intelligent Transportation System Research Center, Fujian University of Technology, Fuzhou 350108, China
3
School of Electrical and Control Engineering, North University of China, Taiyuan 030051, China
*
Authors to whom correspondence should be addressed.
Appl. Sci. 2022, 12(12), 5810; https://doi.org/10.3390/app12125810
Submission received: 16 April 2022
/
Revised: 23 May 2022
/
Accepted: 26 May 2022
/
Published: 8 June 2022
(This article belongs to the Topic Complex Systems and Artificial Intelligence)
Abstract
:Although the deep neural network has a strong fitting ability, it is difficult to be applied to safety-critical fields because of its poor interpretability. Based on the adaptive neuro-fuzzy inference system (ANFIS) and the concept of residual network, a width residual neuro-fuzzy system (WRNFS) is proposed to improve the interpretability performance in this paper. WRNFS is used to transform a regression problem of high-dimensional data into the sum of several low-dimensional neuro-fuzzy systems. The ANFIS model in the next layer is established based on the low dimensional data and the residual of the ANFIS model in the former layer. The performance of WRNFS is compared with traditional ANFIS on three data sets. The results showed that WRNFS has high interpretability (fewer layers, fewer fuzzy rules, and fewer adjustable parameters) on the premise of satisfying the fitting accuracy. The interpretability, complexity, time efficiency, and robustness of WRNFS are greatly improved when the input number of single low-dimensional systems decreases.
1. Introduction
Neural networking is an important method in the development of artificial intelligence and an effective tool in the research of brain-like intelligence [1]. Deep neural networks (DNN) have a large number of adjustable free parameters, and the model construction has high flexibility [2]. Alex applied a deep convolutional neural network in the ImageNet contest to solve the image classification task, which creatively implemented a GPU in the convolutional operation [3]; however, due to the excessive number of parameters, a large number of parameters do not have practical significance, resulting in poor interpretability of the model and lack of theoretical support for the process of adjusting parameters; thus, Rudin called for the innovation of building a fully-interpretable system rather than making the black box model meaningful [4].
A fuzzy system is a logical reasoning system based on natural language abstraction, which has a great advantage in interpretability [5]. Fuzzy system abstracts fuzzy practical problems into fuzzy functional problems. Membership functions is used to generate mappings based on IF-THEN rules in a fuzzy rule set, which can approximate any nonlinear function and effectively combine data information with expert beliefs [6]. Zadeh proposed the ‘fuzzy’ ideology, which gives math more capability to deal with a complex real system [7]. Combining with If-Then rules, the fuzzy interference system imitates the human language system better than many other learning algorithms. An artificial intelligence system with good interpretability has a few parameters, among which are mainly based on expert beliefs, and most parameters have practical meaning [8]. Interpretability means that human intelligence can reasonably explain the relationship between parameter values and structure, and efficiently gain experience in the form of natural language [9]. The fuzzy inference system is currently considered an interpretable system with good accuracy [10]; however, fuzzy systems cannot avoid the “dimension disaster” problem for high-dimensional problems, suffering from low efficiency and poor robustness [11]. The direct reason is the fuzzy inference system is based on a fuzzy rule set, which grows inevitably in an exponential scale when the input number grows [12]. A small improvement in accuracy usually sacrifices a lot of efficiency and interpretability, through which the system becomes big and lousy, and parameters proliferate rapidly. Current research on fuzzy systems tried to fix this problem using different cluster methods to reduce dimension in the input end, such as fuzzy c-means clustering (FCM), subtractive clustering (SC), and grid partitioning clustering (GPC), etc. [13]. FCM, SC and GPC-based ANFIS realized fuzzy interference systems which can handle high-dimensional problems. In the meantime, the cluster methods reduced the interpretability of the whole systems because the data lost information and their direct meanings in the process.
ANFIS is a widely used fuzzy system based on the T-S fuzzy model, which is proved able to approximate arbitrary nonlinear systems [14]. To deal with high-dimensional data sets, FCM-ANFIS, SC-ANFIS, and GPC-ANFIS are applied to many practical problems; however, after dimension reduction, the ANFIS system reduces the interpretability and greatly affects the utilization of input data, which are greatly affected.
Several linear functions can approximate an arbitrary nonlinear function [15]. During the approximation, the difference between the target function and the approximated function, called residual, will be the training target of the next generation. The residual network uses residual as the medium between small systems, making manipulating information flow easier, limiting the scale of error in each step, and leaving every small system nearly independent [16]. The idea of residual improves the stability of the whole system and reduces the accuracy requirement of a single layer. The time cost only increases linearly with the increase of network depth, and the accuracy improvement efficiency is higher than that of general deep networks.
In this paper, the residual network is used to improve the performance of ANFIS. We improved the ANFIS with the residual network to deal with high-dimensional data sets by increasing the width of the system. A large and deep system with many parameters is replaced with a combination of small and fast systems. In this way, ANFIS may process high-dimensional data while maintaining high interpretability, high robustness, and low complexity at the expense of local accuracy.
The rest of this paper is organized as follows. The general structure of WRNFS algorithm and the performance index are proposed in Section 2. In Section 3, three data sets with different input numbers and different fields are used to illustrate the efficiency of the proposed WRNFS model by comparing it with the traditional ANFIS model. Conclusions are summarized in Section 4.
2. WRNFS Algorithm and Evaluating Indexes
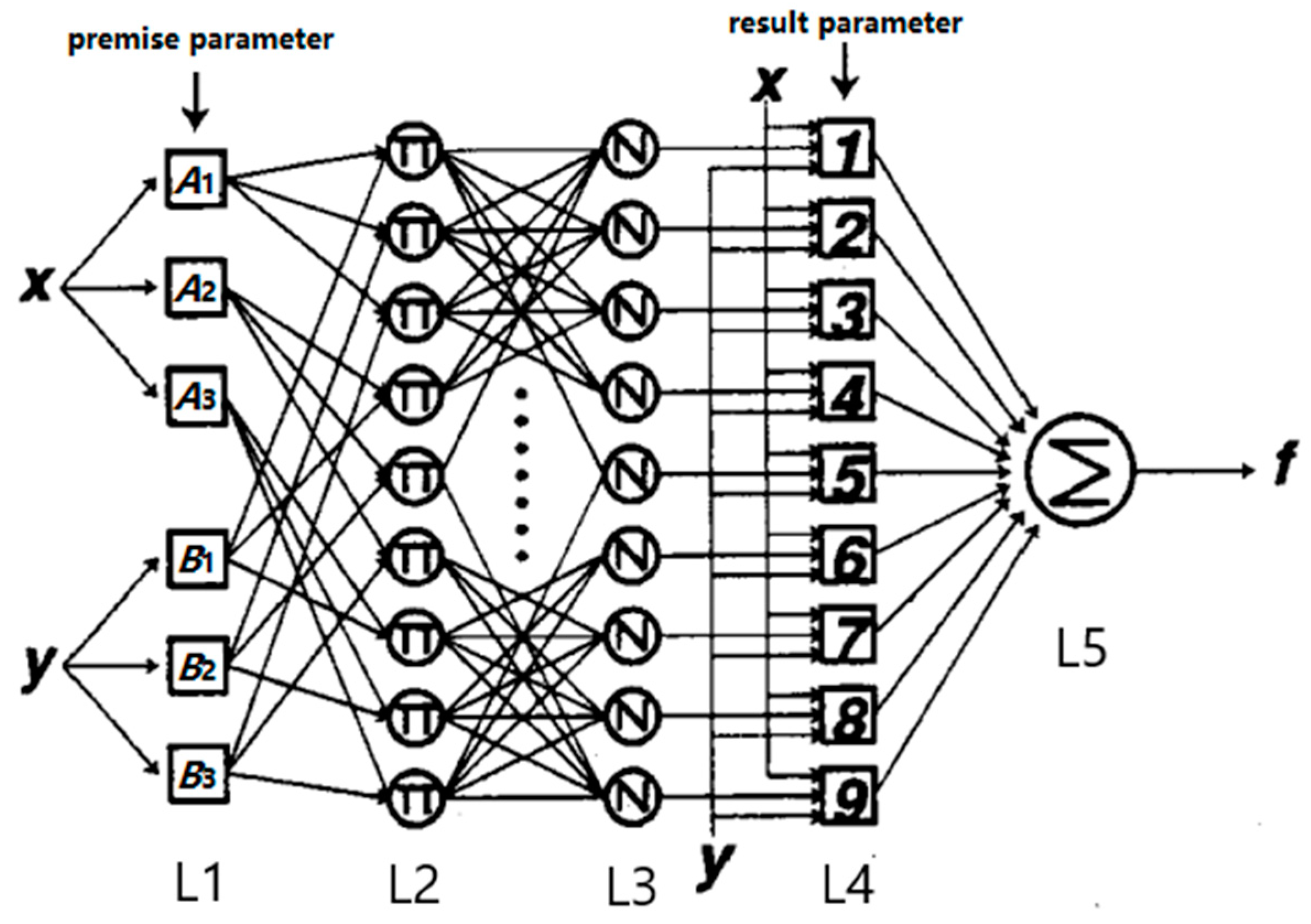
As shown in Figure 1, the traditional ANFIS model contains five layers. The output of the first layer (square nodes) is the membership corresponding to the established rules, and the parameters of this layer are called premise parameters; the second layer (round nodes marked with ∏) generates trigger strength; the third layer (round nodes marked with N) standardizes trigger strength; the fourth layer (square nodes) imports training sets to obtain output corresponding to rules, and the fifth layer sums to obtain the total output.
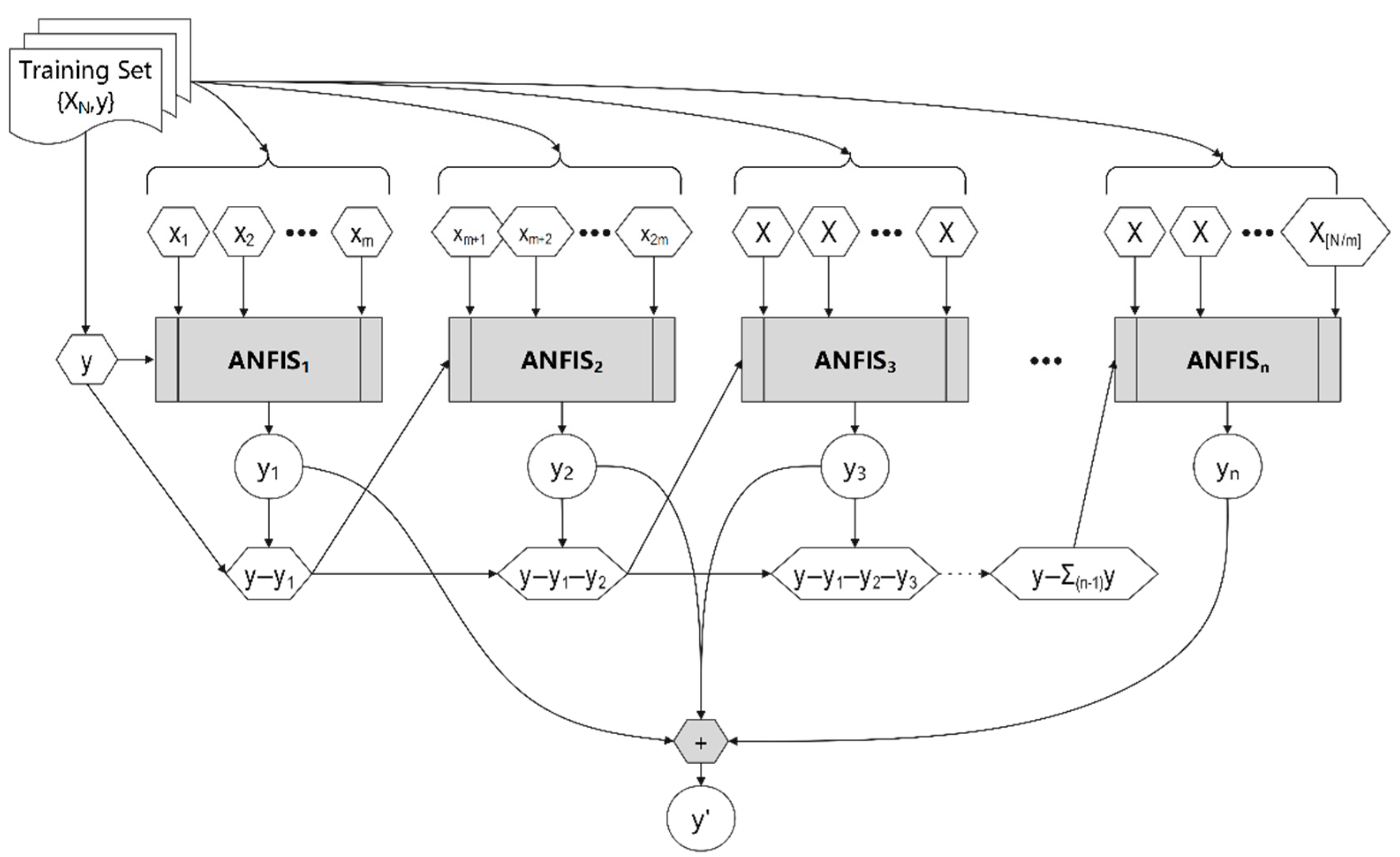
The basic idea of the width residual neural fuzzy system algorithm is the residual error learning algorithm based on ANFIS model. In other words, the original output is regarded as a signal with several levels of different energy instead of repeatedly using the original output as a learning target. For the first-layer of WRNFS, the total output signal is used to train ANFIS model and get the low-frequency signal. The training error of the first layer is passed to the later stage as the residual signal to get several higher-frequency signals. Finally, the signals at all levels are reintegrated in appropriate ways such as least square regression to get a reasonable prediction of the original signal.
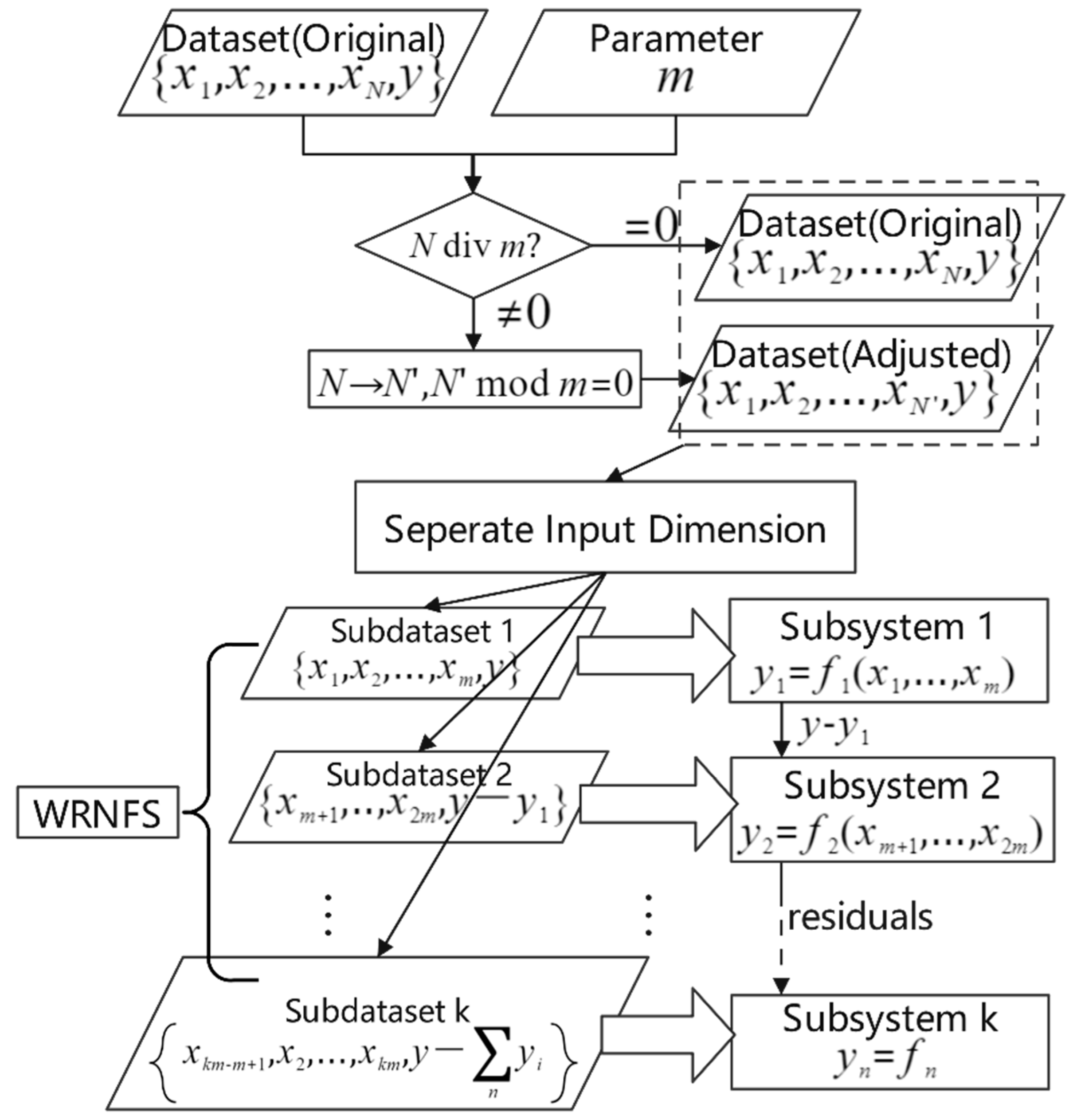
The WRNFS algorithm is described as follows: Firstly, the input variable set is divided into several groups. For example, the medium dimension input (6–20 dimension) is divided into several 2–6 dimension input groups. Then, these data groups are taken as the input of the corresponding layer ANFIS function module. For the first-layer ANFIS model, the data set is taken as the training data to establish ANFIS model. is the first group of the divided data set and is the expected value. The predicted value is obtained by taking as the input of the established ANFIS model. For the second-layer ANFIS model, the data set is taken as the training data to establish ANFIS model. is the second group of the divided data set and is the first-order residual between the expected value and the prediction value of the first-layer ANFIS model. Then, the second-order residual is obtained and will be used as the training data set of the third-layer ANFIS model. Repeat the above process until the input groups are used up, or the output and learning rate meet the target requirements. Finally, appropriate means such as least square regression are used to reconstruct the output signals of ANFIS at all levels to obtain reasonable prediction. As shown in Figure 2, multi-dimensional data can be fully utilized and learning accuracy can be continuously improved through step-by-step transmission of residuals. In the experiment of this article, we configure that , to make the performance of the system more controllable. Assume there is an -dimensional input data set The procedure of WRNFS is described in the following figure.
The WRNFS algorithm shown in Figure 3 can be used as an online learning mode in practical applications. On the one hand, the training data set is divided into several groups, which will greatly reduce the training time of the ANFIS model. On the other hand, after partitioning and learning the input of the current data set, only the last level of residual error is saved, without changing the previously trained levels. When the new input data enter the system, the residual of the last level is distributed with the new input data to train ANFIS model in the next layer. Because of the above reasons, the time efficiency and memory efficiency of the algorithm will be improved.
The above algorithm assumes that the influence of each set of input data on the output is regarded as almost the same and contains the information of each level. The possible training results are only , which is smaller than the possibility of exponential growth. Obviously, there is a certain gap between the naive algorithm and the actual data requirements. On the one hand, some input data may have a negative effect on ANFIS learning results, which may be corrected if other data are reused. On the other hand, if the space of training data are small, the flexibility of the algorithm will be reduced.
3. Results and Discussion
3.1. Dataset 1: Mackey–Glass (MG) Time-Delay Differential Equation
Mackey and Glass (1977) established first-order differential delay dynamics equations for physiological system models. The equation is a nonlinear delay differential equation, one special form is described as follows:
When τ > 17, the whole sequence is chaotic, aperiodic, and does not converge or diverge. The Mackey–Glass time series is one of the benchmark problems of time series prediction in a neural network and fuzzy logic. In this section, 1000 data points are intercepted in the MG sequence. The first 500 data points are taken as the training set and the last 500 data points are taken as the test set. Using the common construction method of time series prediction problem, every five data points in the series are regarded as a group of four inputs and one output dataset. In addition, for each group, the first four data points are regarded as input and the fifth data point as output, and thus a learning task with four inputs and one output is constructed.
The obtained data set was used to test the performance of WRNFS after dimensionality reduction. In other words, four input ANFIS system were divided into two two-input ANFIS systems, and the residual error is used to transmit between ANFIS systems (WRNFS). The performance of the ANFIS and WRNFS is list in Table 1.
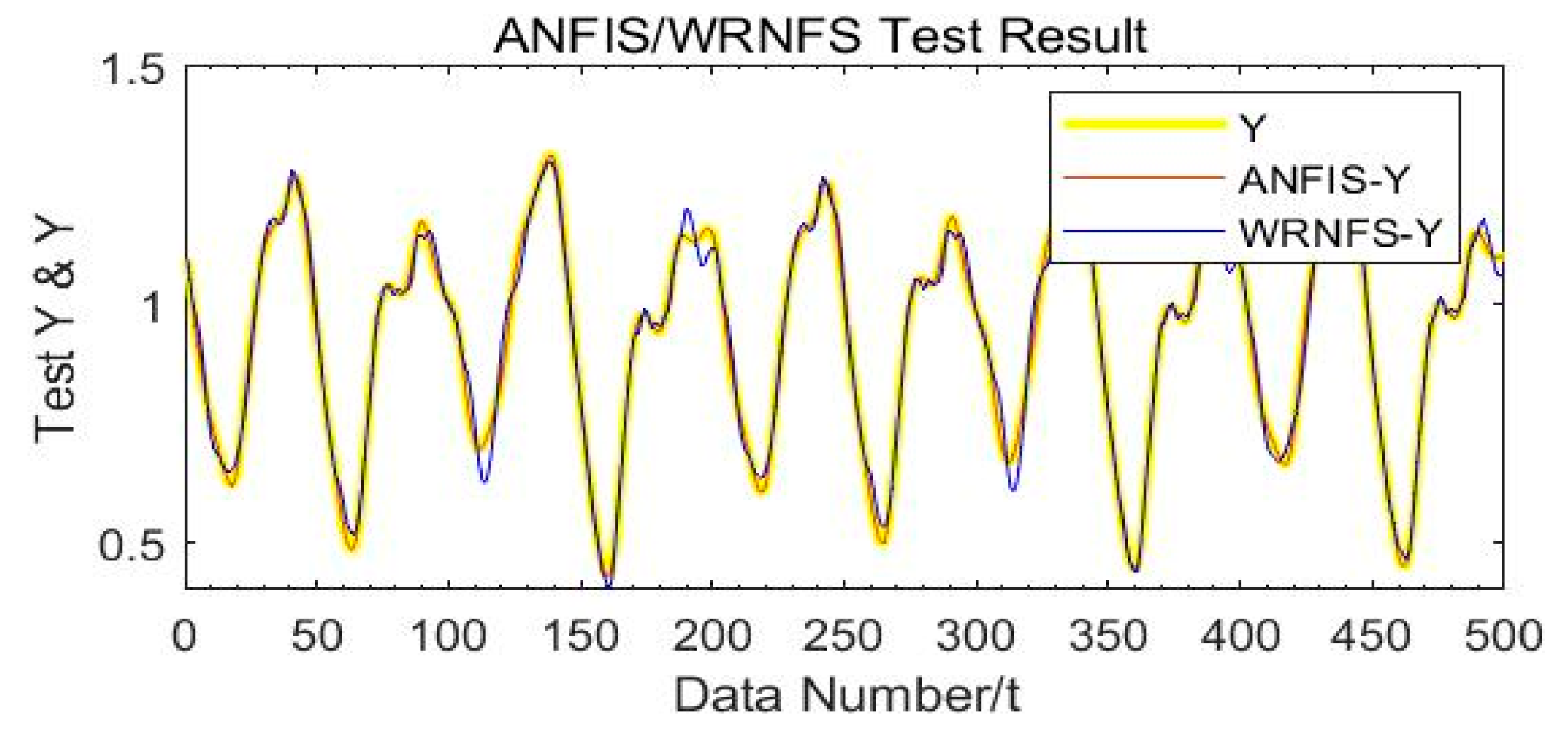
We used the first data set to show the differences between the original ANFIS and our WRNFS. From Table 1, although the accuracy decreased by using WRNFS, a better comprehensive performance is obtained. As shown in Figure 4 and Figure 5, the complexity of the entire system is notably simplified; we plotted a line-chart to compare the precision of ANFIS and WRNFS in Figure 6, in which the red line represents the ANFIS and the blue line represents the WRNFS. ANFIS fits the yellow base-line better, but WRNFS has enough precision, too.
To further certify the result, besides three membership systems, we also experimented with four membership systems. The results are also listed in Table 1.
From data set 1, we can draw two conclusions:
- The training error and the test error of the same system are basically the same, which showed that WRNFS and ANFIS have similar robustness in the four-dimensional input system.
- When other system parameters are set to be the same, dividing the input dimensions will reduce the accuracy of WRNFS compared with the original ANFIS; however, the interpretability and system complexity will be significantly reduced, and thus the comprehensive performance will be improved.
3.2. Dataset 2: Miles Per Galon
The prediction of miles per gallon of motor vehicles is a typical nonlinear regression problem, in which several characteristic data of motor vehicles are used for prediction. In this case training data are publicly available in the Irving Machine Learning Library (UCI) of the University of California and includes various brands and models of motor vehicles. There are seven numerical parameters in this data set: miles per gallon, number of cylinders, displacement, horsepower, weight, acceleration, and model year. The regression model is constructed by taking miles per gallon as the output and other six parameters as the input variables.
We used the second data set to show the robustness and the flexibility in application of WRNFS. When the ANFIS system with 3-dimensional input is exhausted, RMSE between training set and test set has a large deviation value, and the over-fitting phenomenon occurs. It indicates that when the traditional ANFIS system is used to train this data set, increasing the number of inputs and the complexity of the model cannot reasonably improve the accuracy of the model when the dimension of the training set is fixed. In contrast, WRNFS can improve model training accuracy by increasing the total number of inputs without encountering over-fitting. According to the different input dimensions of low-dimensional system, two WRNFS of two-input and three-input of ANFIS model are established, respectively. The results are shown in Table 2. From Table 2, it can be seen that the over-fitting phenomenon of the WRNFS model with three inputs is much more serious than that with two inputs. Thus, reducing the input dimension of low-dimensional system can solve the over-fitting problem of traditional ANFIS model.
3.3. Dataset 3: Electroencephalogram
In this case, training data are publicly available in the Irving Machine Learning Library (UCI) of the University of California and includes 13-dimensional EEG data. EEG (Electroencephalogram) is a 12-input and 1-output brain wave data, instead of using biomedical formula to calculate, we use WRNFS to learn the characteristic of the evaluating system.
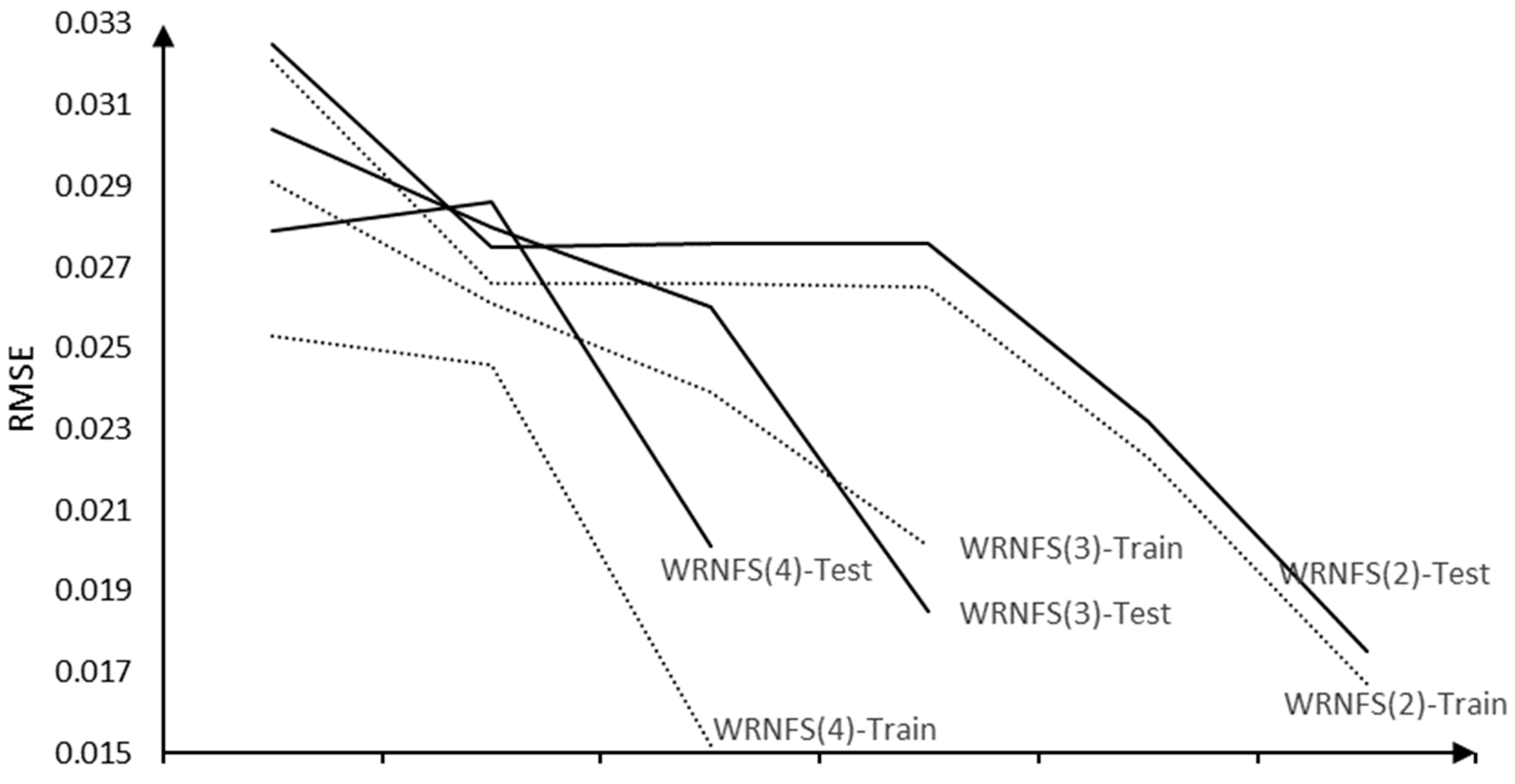
We used the third data set to show the importance of using small subsystems and the sustained effect of WRNFS. Taking the first 12-dimensional input data as input and the 13th-dimensional stability as output, the regression model of 12-dimensional input and 1-dimensional output is obtained. A single ANFIS system can no longer solve this problem, so it must carry out dimension reduction in advance or use methods like WRNFS that is capable of solving the data sets in medium scale. According to the different input dimensions of low-dimensional systems, WRNFS with two inputs, three inputs, four inputs, and six inputs are established, respectively. The training results of each system are compared and shown in Table 3. From Table 3, when the input dimension of the low-dimensional system is reduced, the overall performance of the system is greatly improved, although the accuracy is slightly decreased.
In Figure 7, the error figure of 12-input-WRNFS below shows that through the transmission of residual between low dimension systems, the error gradually decreases and seldomly becomes larger, which indicates the robustness and the sustained effect of the designed WRNFS.
4. Conclusions
The WRNFS we proposed in this paper is a new system structure based on ANFIS, which is established by using several low dimensional ANFISs and connecting these systems through residuals. Through the experiments, we concluded that WRNFS has better performance than ANFIS and the application fields of WRNFS are more variable than ANFIS. The proposed WRNFS has obtained good accuracy and performance only based on ANFIS. The program in this article is easy for researchers to write even if they are not algorithm practitioners.
Unlike the parameter number of ANFIS grows exponentially, the parameter number of WRNFS almost grows on a linear scale. When the total dimension of the input is divisible by the input dimension of the ANFIS model at each layer, there is no need to reuse the input data. In this case, the WRNFS system complexity increases discretely and linearly. When the total dimension of the input is not divisible by the input dimension of the ANFIS model at each layer, the data of some dimensions need to be reused. In this case, the complexity of the WRNFS system should increase as a step function along the upper edge of the linear growth curve described above.
The WRNFS we proposed has a great potential of further promotion because of its simple structure. There are several places can be optimized. First, the connection between subsystems is established by addition; it can be replaced by methods such as linear least square regression. Second, we did not discuss how to arrange the distribution of each input dimension; we made every subsystem have the same input dimension for the convenience of discussion and assigned the inputs to subsystems only by one random plan. In fact, if the arrangement of dimensions is based on some interpretable algorithms, WRNFS may have better precision. Third, the WRNFS is now short of pre-processing methods, or in other words, short of forestage systems. With the help of other interpretable algorithms, WRNFS will have more possibilities in application.
Author Contributions
Conceptualization, L.K. and D.C.; methodology, D.C.; software, L.K.; validation, L.K.; formal analysis, L.K., D.C. and R.C.; investigation, L.K.; resources, D.C.; data curation, L.K.; writing—original draft preparation, L.K.; writing—review and editing, D.C. and R.C.; visualization, L.K. and R.C.; supervision, D.C. and R.C.; project administration, D.C.; funding acquisition, D.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant 61976055, the special fund for education and scientific research of Fujian Provincial Department of Finance under Grant GY-Z21001 and the open project of State Key Laboratory of Management and Control for Complex Systems under Grant 20210116.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Chen, R.; Sensale-Rodriguez, B.; Gao, W.; Yu, C. Real-time multi-task diffractive deep neural networks via hardware-software co-design. Sci. Rep. 2021, 11, 11013. [Google Scholar] [CrossRef] [PubMed]
- Alex, K.; Ilya, S.; Hg, E. Imagenet classification with deep convolutional neural networks. Proc. NIPS Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic and approximate reasoning—In memory of Grigore Moisil. Synthese 1975, 30, 407–428. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Monte-Serrat, D.M.; Cattani, C. Interpretability in neural networks towards universal consistency. Int. J. Cogn. Comput. Eng. 2021, 2, 30–39. [Google Scholar] [CrossRef]
- Alonso, J.M.; Magdalena, L.; González-Rodríguez, G. Looking for a good fuzzy system interpretability index: An experimental approach. Int. J. Approx. Reason. 2009, 51, 115–134. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Bai, Y. A New Rule Reduction Method for Fuzzy Modeling. IEEE Trans. Fuzzy Syst. 2020, 28, 3023–3031. [Google Scholar] [CrossRef]
- Giiven, M.K.; Passino, K.M. Avoiding exponential parameter growth in fuzzy systems. IEEE Trans. Fuzzy Syst. 2001, 9, 194–199. [Google Scholar] [CrossRef] [Green Version]
- Mola, M.; Amiri-Ahouee, R. ANFIS model based on fuzzy C-mean, grid partitioning and subtractive clustering to detection of stator winding inter-turn fault for PM synchronous motor. Int. Trans. Electr. Energy Syst. 2021, 31, e12770. [Google Scholar] [CrossRef]
- Wang, L.X. Universal approximator by hierarchical fuzzy systems. Fuzzy Sets Syst. 1998, 93, 223–230. [Google Scholar] [CrossRef]
- Chen, T.; Chen, H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Trans. Neural Netw. 1995, 6, 911–917. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
Figure 1.
Basic Structure of ANFIS.

Figure 2.
Basic Structure of WRNFS.

Figure 3.
The Algorithm of WRNFS.

Figure 4.
4 input ANFIS(3 MF).

Figure 5.
4 input WRNFS(3 MF).

Figure 6.
Test results of WRNFS.

Figure 7.
The Error Decrease Curve of WRNFS.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
ANFIS and WRNFS in the 4-input system(3 MF).
| Algorithm | ANFIS | WRNFS | ||||||
|---|---|---|---|---|---|---|---|---|
| Total Input numbers | 4 | |||||||
| Membership Functions | 3 | 4 | 3 | 4 | ||||
| Group | Train | Test | Train | Test | Train | Test | Train | Test |
| RMSE I | 0.0014 | 0.0013 | 0.0006 | 0.0006 | 0.0268 | 0.0260 | 0.0245 | 0.0237 |
| Parameter Numbers II | 441 | 1328 | 90 | 144 | ||||
| Time Efficiency III | 4.5469 | >27 | 0.6719 | 1.0469 | ||||
| Performance IV | 2.81 | 21.5 | 1.62 | 3.69 | ||||
I: RMSE: Root-Mean-Square Error. II: Parameter Numbers: The total parameter number of the system. III: Time Efficiency: The time used to train the whole system. The unit of this quantity is seconds. IV: Performance: The comprehensive performance of the system.
Table 2.
WRNFS in the 6-input system(3 MF).
| WRNFS | ||||
|---|---|---|---|---|
| System Configuration | Total Input Numbers: 6 | Membership Functions: 3 | ||
| Low-D-ANFIS Input Numbers | 2 | 3 | ||
| Number of Low-D-ANFIS | 3 | 2 | ||
| Group | Train | Test | Train | Test |
| RMSE | 0.5227 | 2.0980 | 0.2683 | 167.1314 |
| MRPE V | 7.47 | 20.95 | 3.78 | 196.45 |
| Parameter Numbers | 135 | 270 | ||
| Rule Numbers | 27 | 54 | ||
V: MRPE: Mean Relative Percentage Error.
Table 3.
WRNFS in the 12-input system (3 MF).
| WRNFS | ||||||||
|---|---|---|---|---|---|---|---|---|
| System Configuration | Total Input Number: 12 | Membership Functions: 3 | ||||||
| Inputs of Low-D-ANFIS | 2 | 3 | 4 | 6 | ||||
| Number of Low-D-ANFIS | 6 | 4 | 3 | 2 | ||||
| Group | Train | Test | Train | Test | Train | Test | Train | Test |
| RMSE | 0.0167 | 0.0175 | 0.0164 | 0.0312 | 0.0152 | 0.0201 | 0.0035 | 0.3863 |
| MRPE | 6.4036 | 2.7321 | 7.5228 | 2.8870 | 10.4399 | 3.5540 | 7.8706 | 31.2332 |
| Parameter Numbers | 270 | 540 | 1323 | 10,314 | ||||
| Rule Numbers | 54 | 108 | 243 | 1458 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kong, L.; Chen, D.; Cheng, R. WRNFS: Width Residual Neuro Fuzzy System, a Fast-Learning Algorithm with High Interpretability. Appl. Sci. 2022, 12, 5810. https://doi.org/10.3390/app12125810
AMA Style
Kong L, Chen D, Cheng R. WRNFS: Width Residual Neuro Fuzzy System, a Fast-Learning Algorithm with High Interpretability. Applied Sciences. 2022; 12(12):5810. https://doi.org/10.3390/app12125810
Chicago/Turabian StyleKong, Lingkun, Dewang Chen, and Ruijun Cheng. 2022. "WRNFS: Width Residual Neuro Fuzzy System, a Fast-Learning Algorithm with High Interpretability" Applied Sciences 12, no. 12: 5810. https://doi.org/10.3390/app12125810
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.