
Human Action Recognition Based on Improved Two-Stream Convolution Network



Abstract
:1. Introduction
- (1)
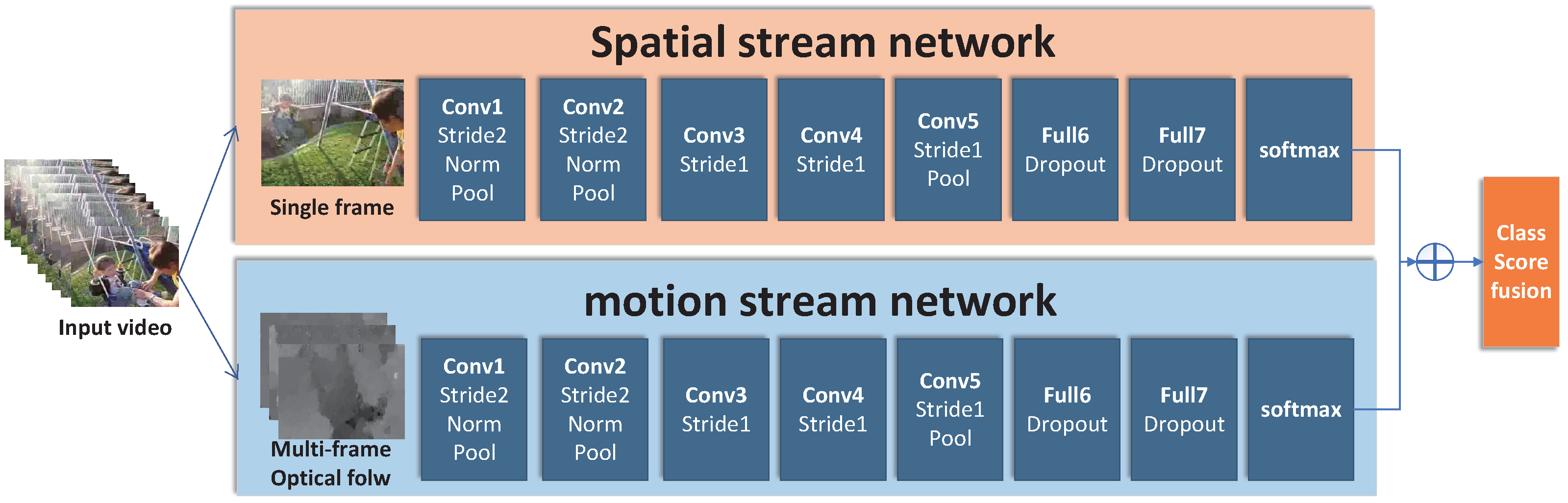
- The main task of a spatial stream network in the classical Two-Stream network model is to extract the appearance features of actions, and its feature extraction method is only single frame recognition (still frame). However, the appearance features of actions may have great differences in different stages. The way of single frame recognition will make the neural network unable to learn these coherence features of appearance.
- (2)
- At present, there is still room for improvement in the accuracy and stability of the classical two-stream network for action recognition. In addition, the classical Two-Stream network treats each pixel equally, which will lead the network to extract features weakly related to the action recognition task, such as video background. Therefore, a neural network needs a method to filter irrelevant information.
- (1)
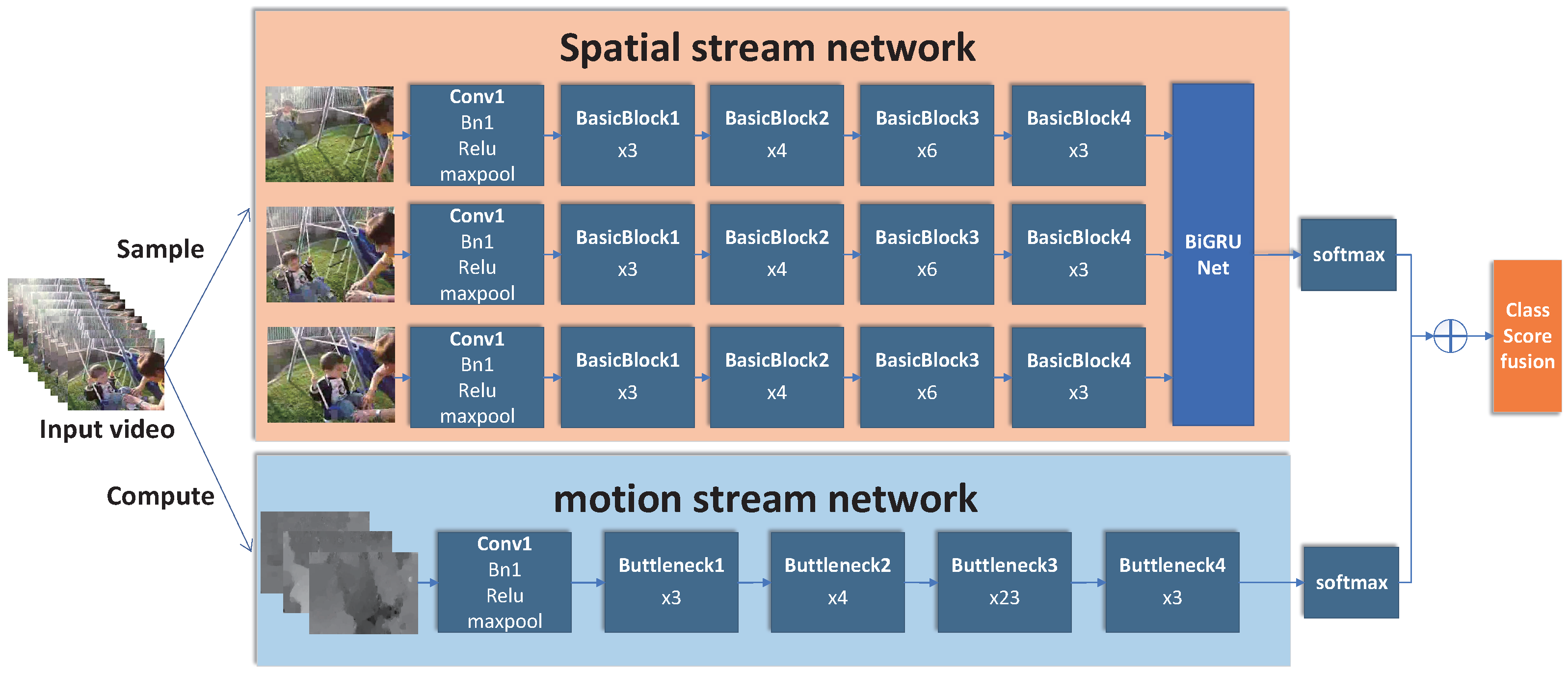
- Propose a new network structure based on the two-stream convolution network model and combined with a bidirectional gated recurrent unit. This network structure can well solve the shortcomings of the original neural network model in the perception of motion appearance coherence features.
- (2)
- Combine the SimAM attention mechanism, which is based on the spatial inhibition effect of neurons, with the ResNet network organically to improve the accuracy and stability of action recognition.
2. Related Works
2.1. Two-Stream Convolution Network

2.2. Attention Mechanism
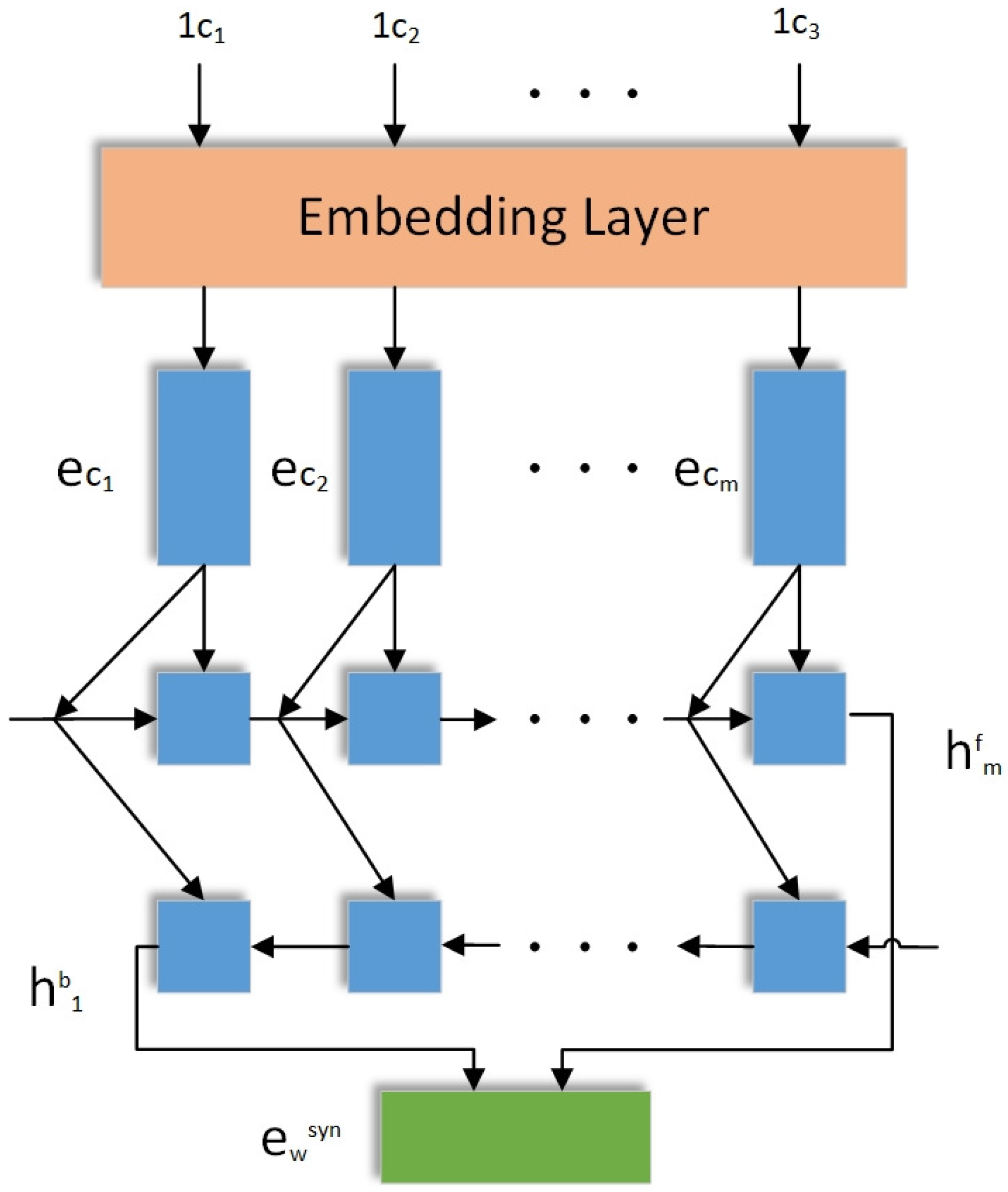
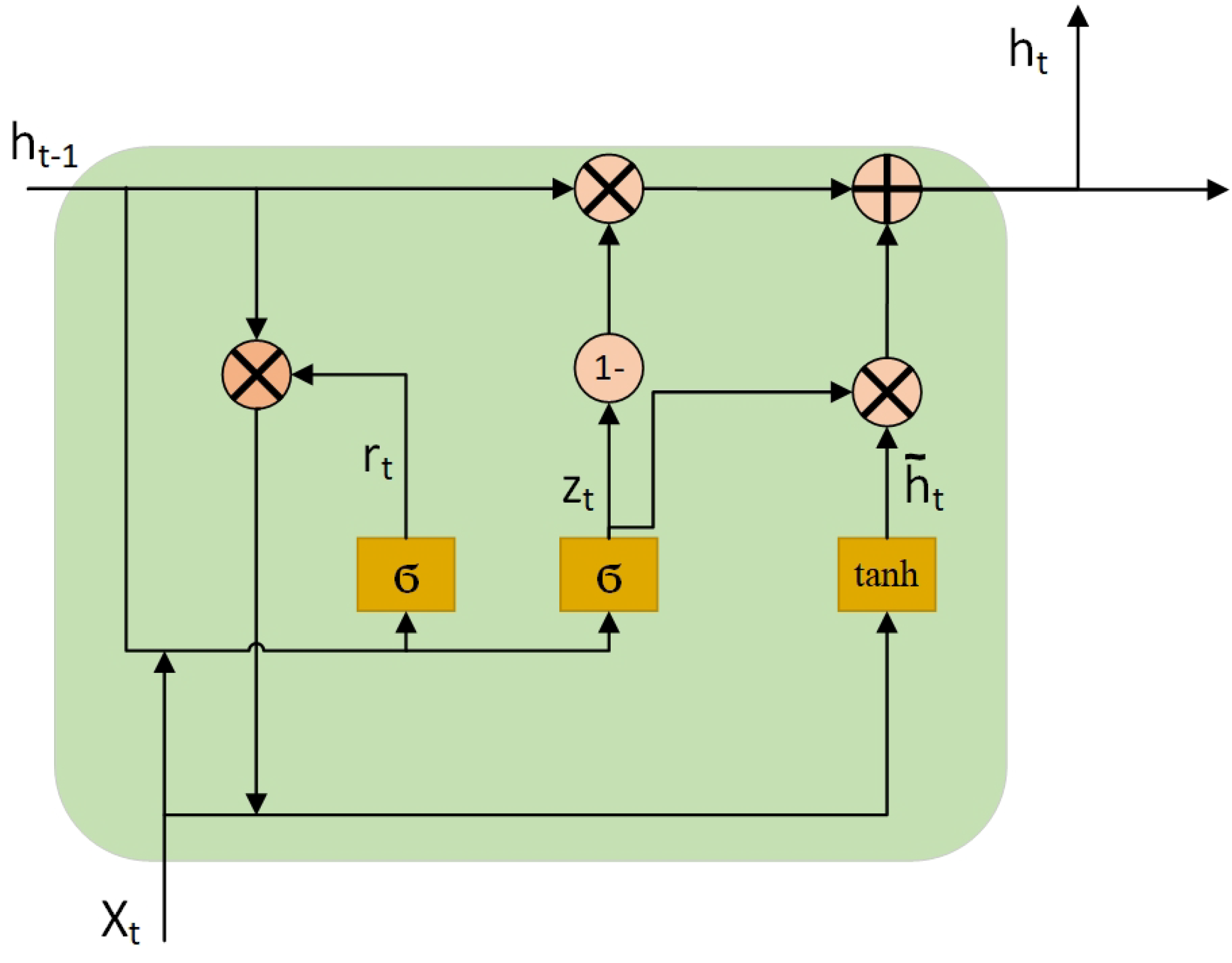
2.3. Neural Network With Memory
3. Improved Network Structure
3.1. General Network Structure
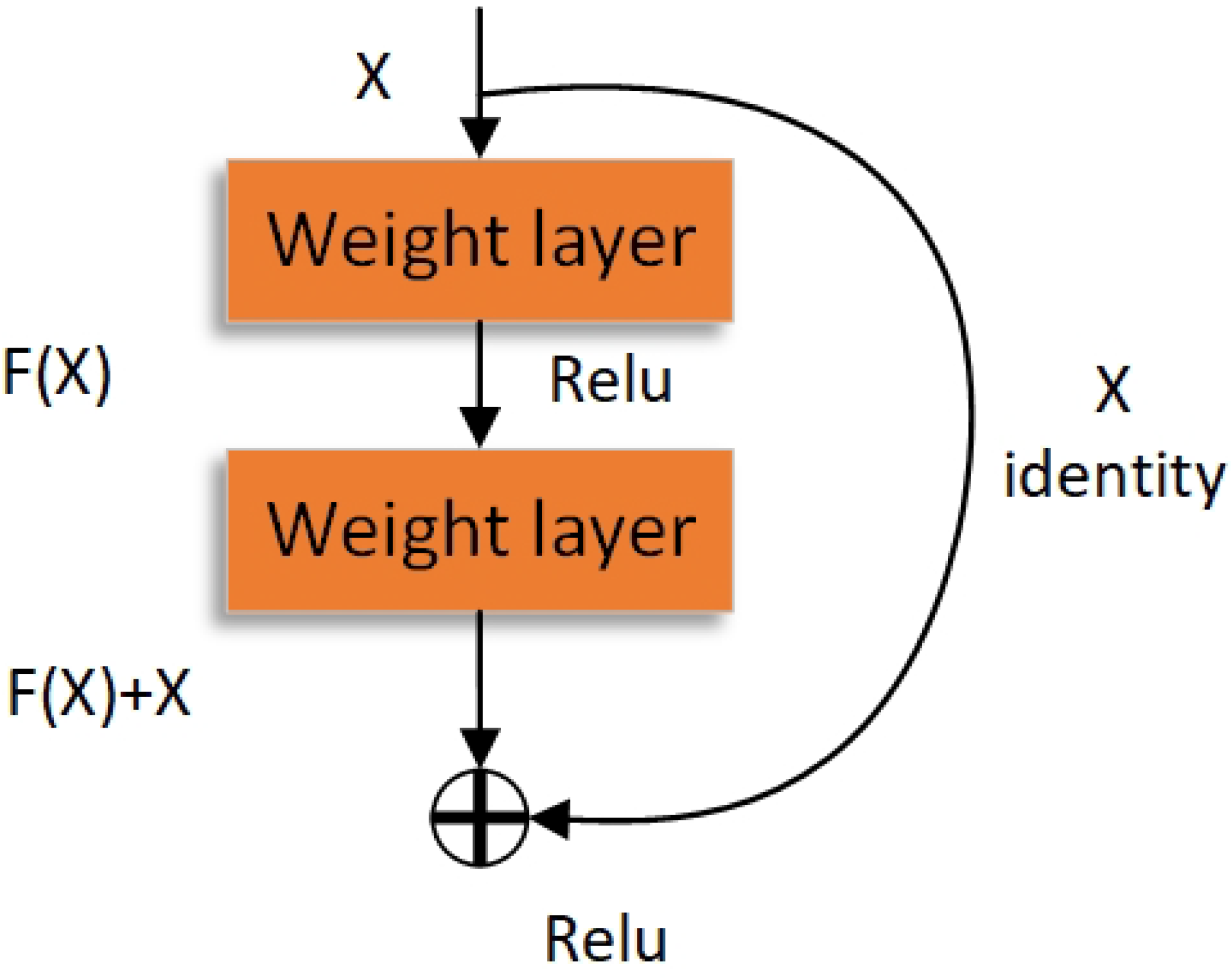
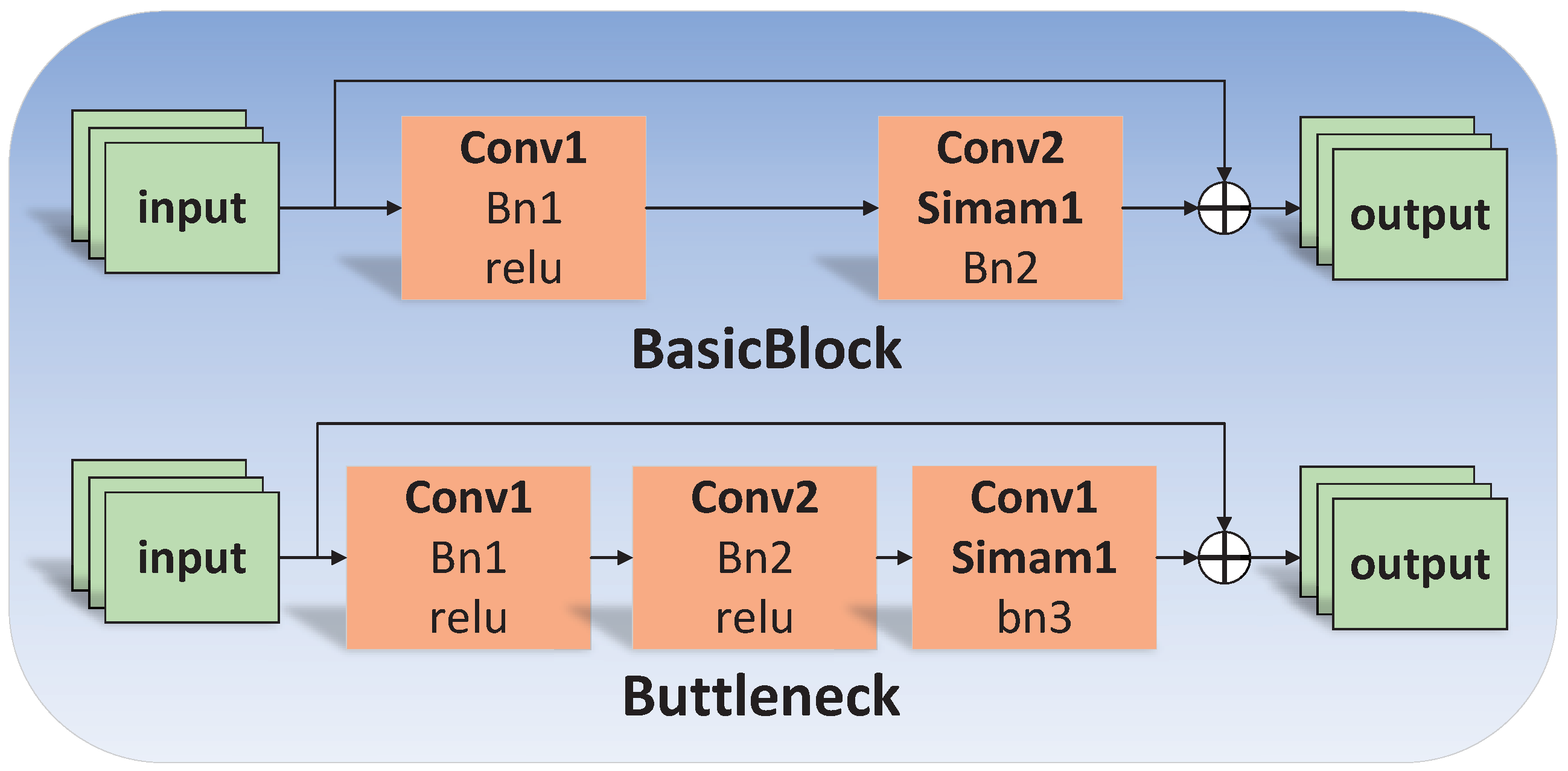
3.2. Network Structure of BasicBlock & Buttleneck
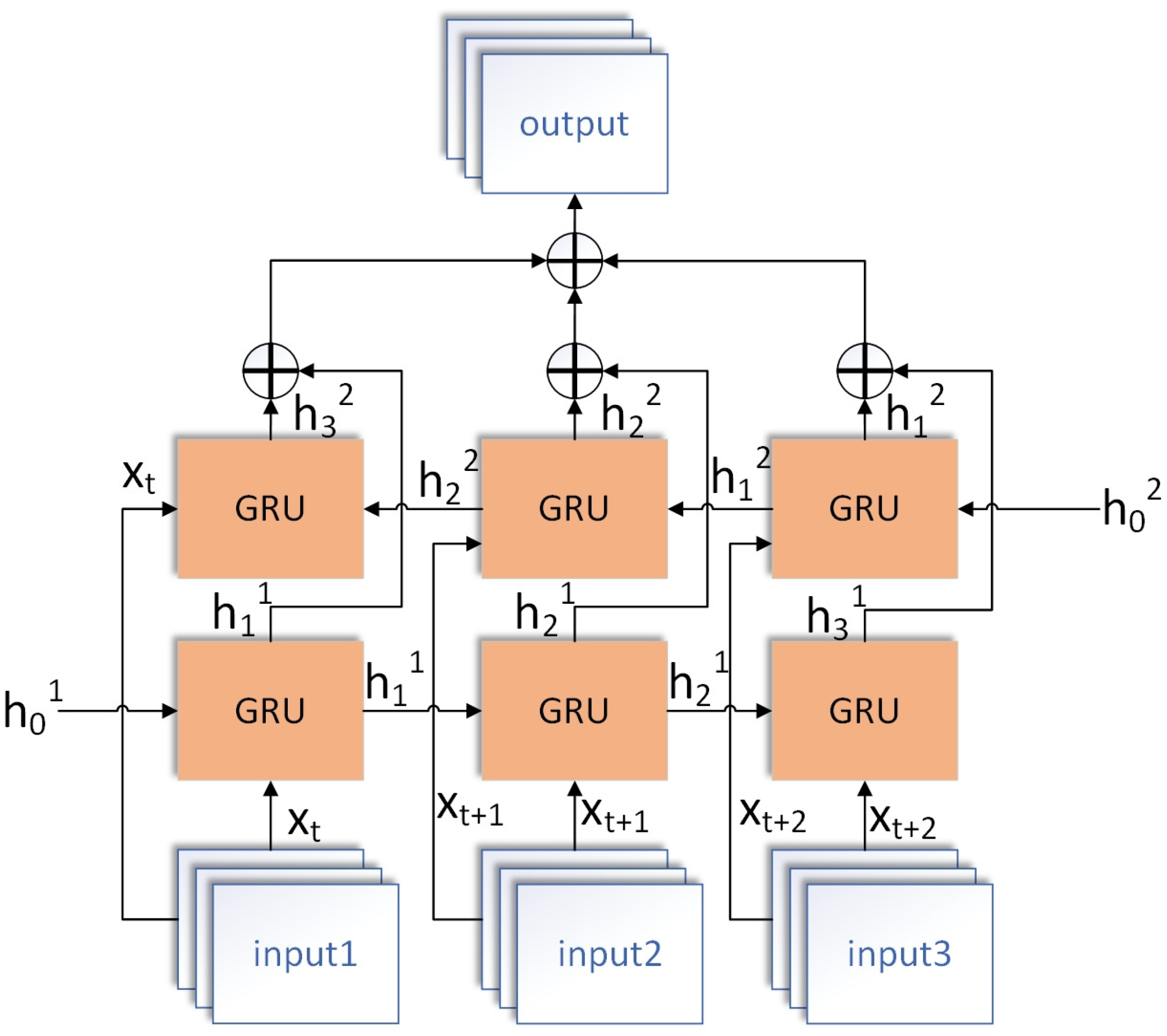
3.3. Network Structure of BiGRU
4. Experiments
4.1. Data Set
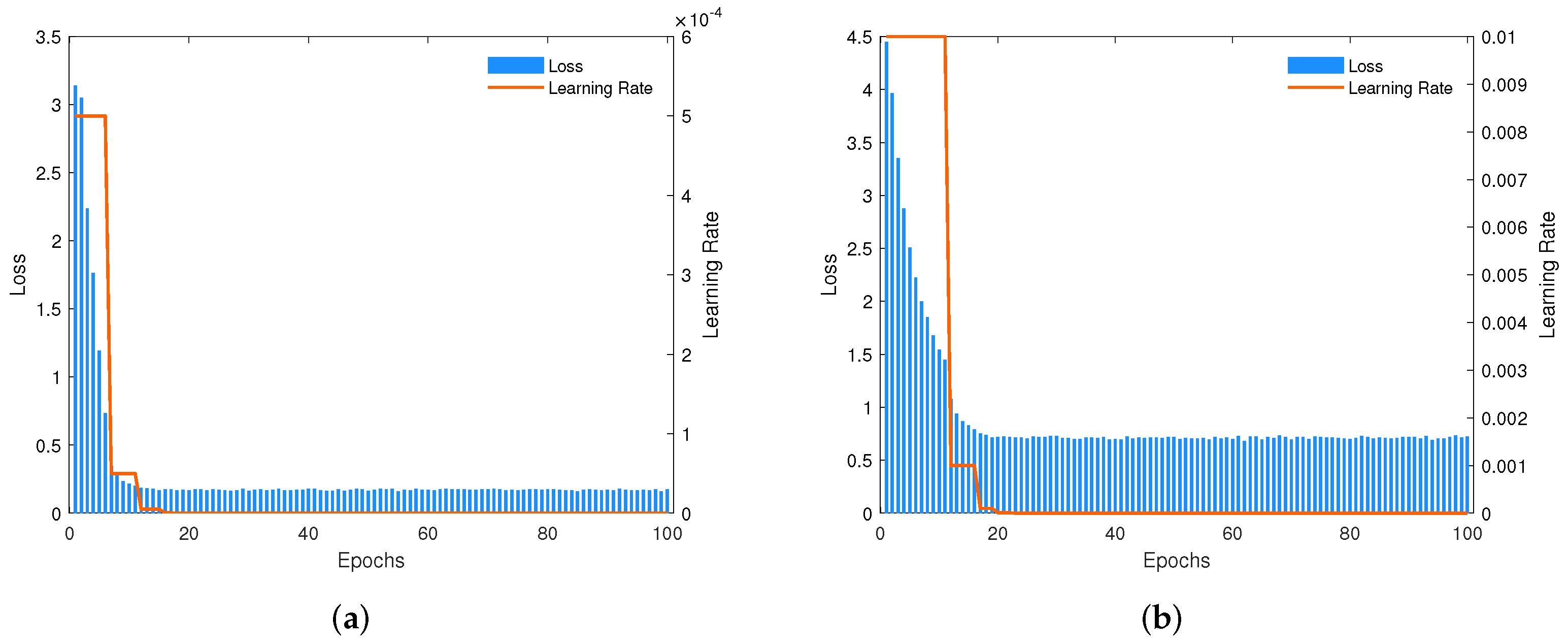
4.2. Details of Experiments
4.3. Results of Experiments and Analysis
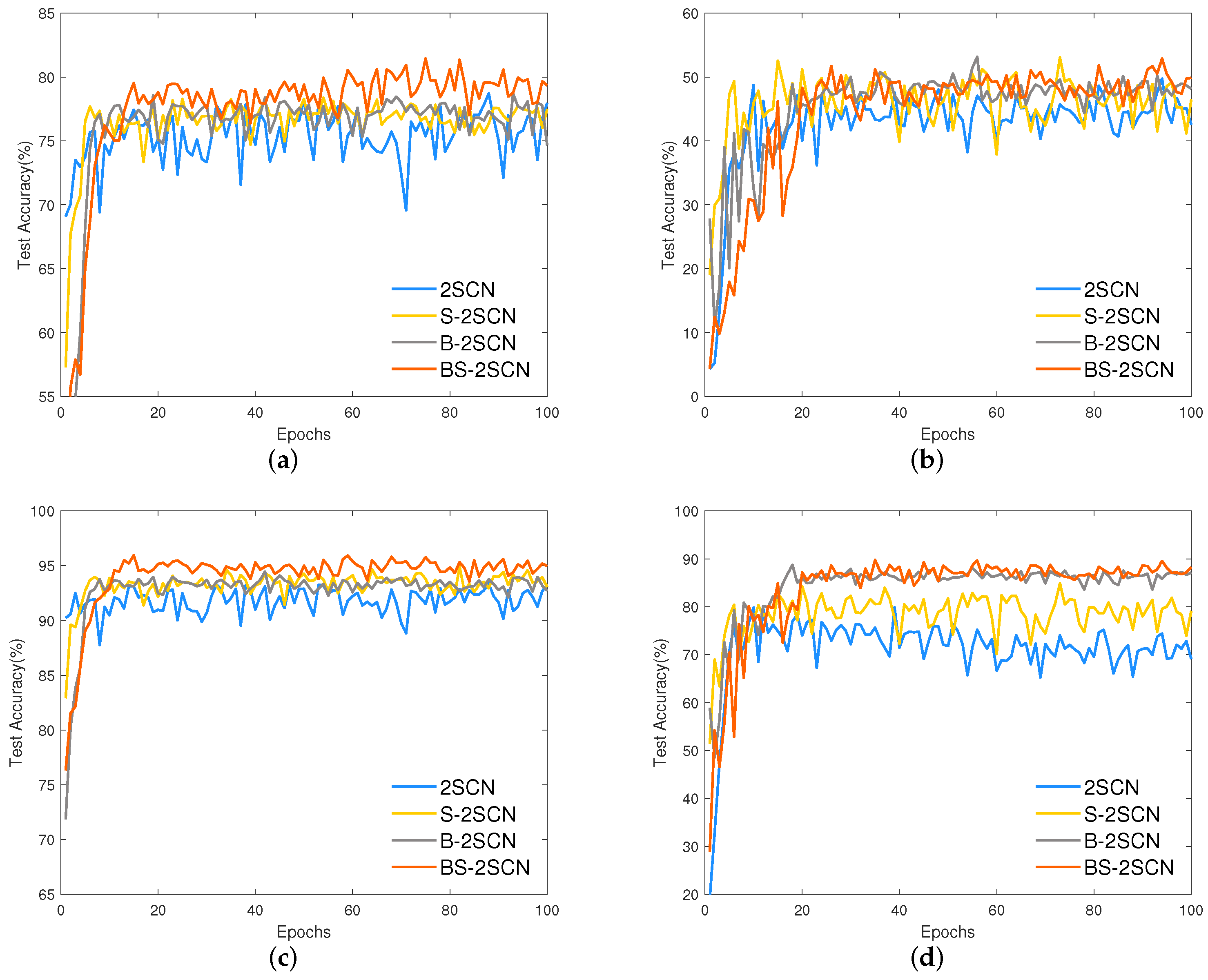
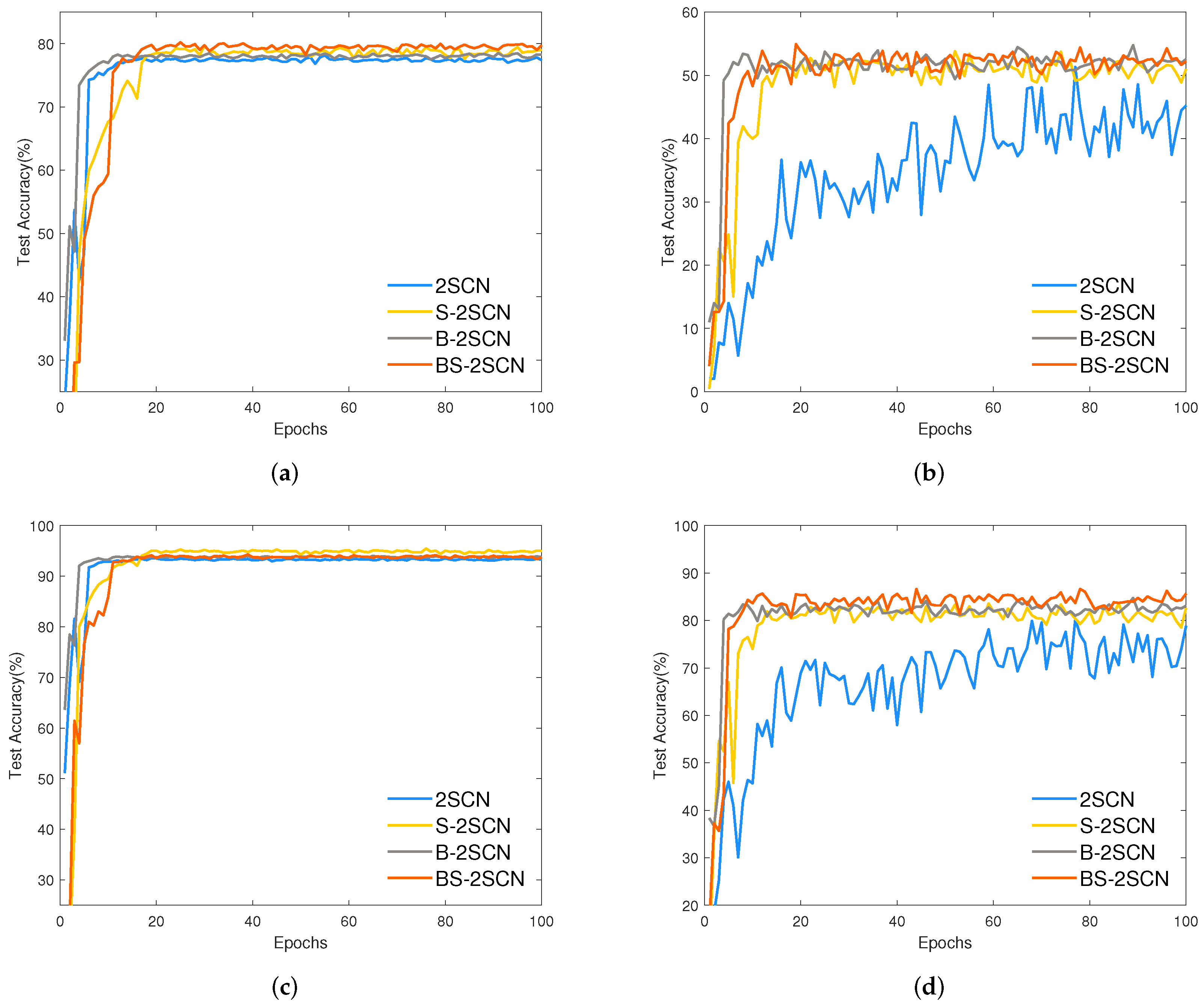
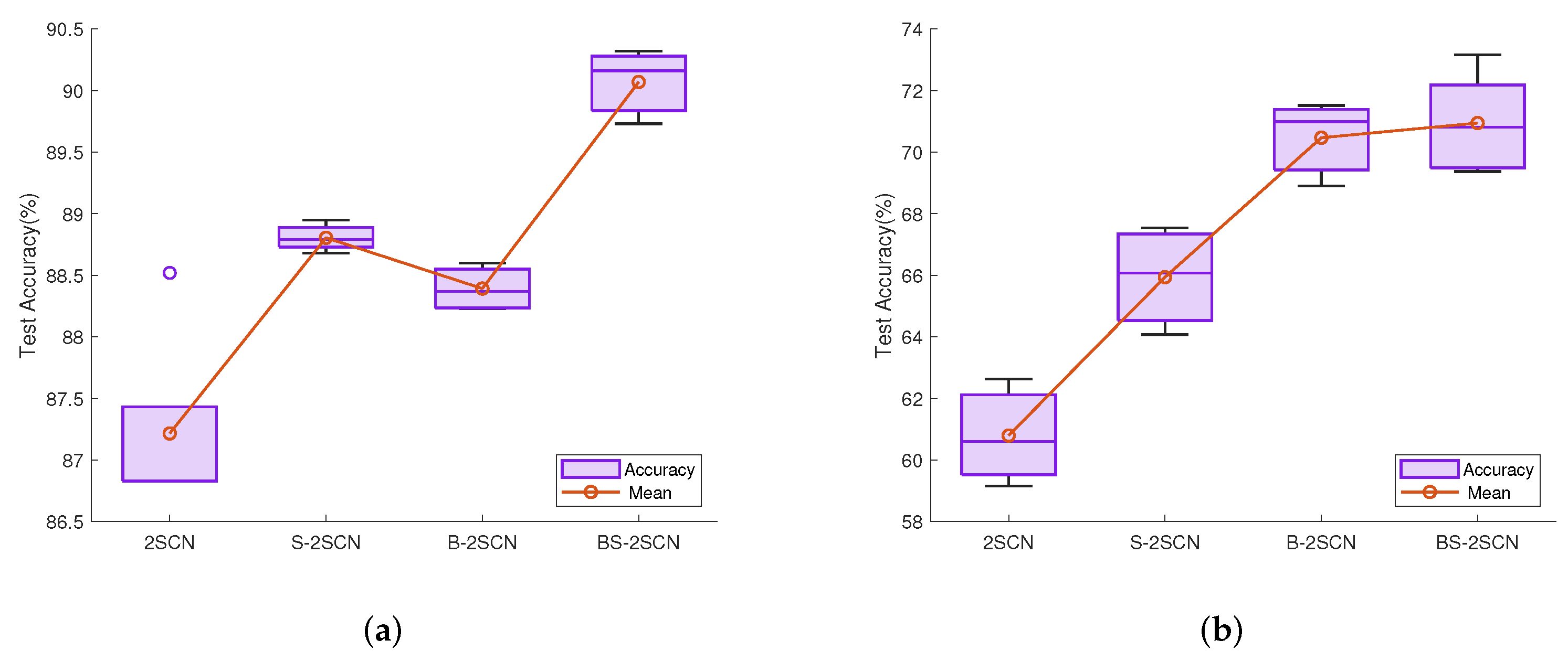
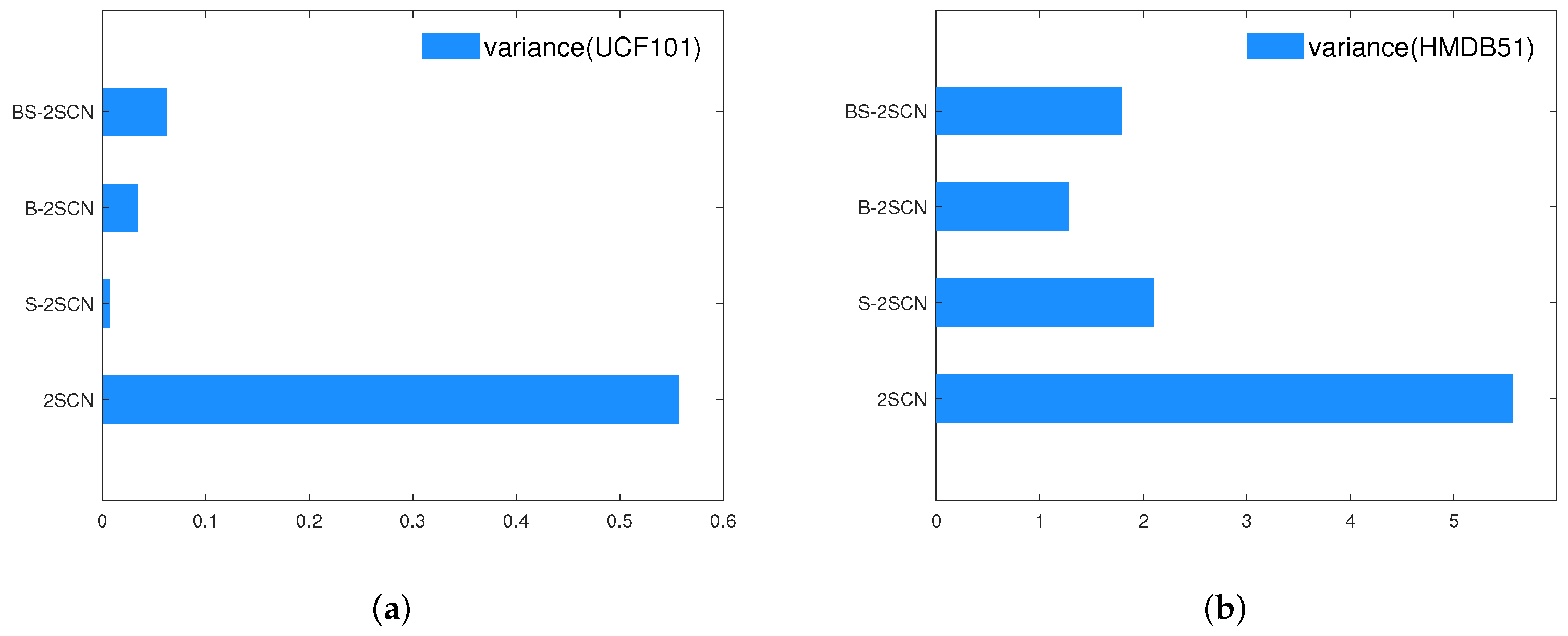
4.3.1. Ablation Experiments of Network Structure
4.3.2. Comparative Experiment and Analysis
4.3.3. Experimental Overall Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GRU | gated recurrent unit |
| BiGRU | bidirectional gated recurrent unit |
| 2SCN | Two-stream convolution network |
| S-2SCN | SimAM Two-stream convolution network |
| B-2SCN | BiGRU Two-stream convolution network |
| BS-2SCN | BiGRU-SimAM Two-stream convolution network |
| CNN | convlutional neural network |
Parameter symbols
| I | optial stream | Equation (1) |
| t | sign of a frame | |
| k | sign of a frame | |
| d | sign of differential | |
| u | abscissa of a frame | |
| v | Ordinate of a frame | |
| k | Ordinate of a frame | |
| w | input word of BiGRU | |
| m | length of a word | |
| c | characters of a sequence | |
| e | projection vectors | |
| h | state sequence | |
| syntactic structure | ||
| energy of each neuron | Equation (3) | |
| linear conversion of weight | ||
| b | linear conversion of offset | |
| r | target neuron in a signal input channel | |
| q | other neurons in a signal input channel | |
| i | serial number | |
| M | the number of other neurons | |
| y | variable | |
| coefficient | Equation (4) | |
| average value | Equation (6) | |
| indicate variance | Equation (7) | |
| E | energy matrix | Equation (9) |
| weight matrix of attention | ||
| S | original feature map | Equation (10) |
| fused feature map | ||
| reset gate at time t | Equation (11) | |
| update gate at time t | Equation (12) | |
| state of candidate activation at time t | Equation (13) | |
| W | weight matrix of GRU | |
| input of GRU | ||
| forward hidden layer state | Equation (15) | |
| reverse hidden layer state | Equation (16) |
References
- Xiong, P.; He, K.; Wu, E.Q.; Zhu, L.-M.; Song, A.X.; Liu, P. Human-Exploratory-Procedure-Based Hybrid Measurement Fusion for Material Recognition. IEEEASME Trans. Mechatron. 2022, 27, 1093–1104. [Google Scholar] [CrossRef]
- Xiong, P.; Zhu, X.; Song, A.; Hu, L.; Liu, X.P.; Feng, L. A Target Grabbing Strategy for Telerobot Based on Improved Stiffness Display Device. IEEECAA J. Autom. Sin. 2017, 4, 661–667. [Google Scholar] [CrossRef]
- Bobick, A.; Davis, J. An Appearance-Based Representation of Action. In Proceedings of the 13th International Conference on Pattern Recognition, Washington, DC, USA, 25–29 August 1996; IEEE: Vienna, Austria, 1996; Volume 1, pp. 307–312. [Google Scholar]
- Weinland, D.; Ronfard, R.; Boyer, E. Free Viewpoint Action Recognition Using Motion History Volumes. Comput. Vis. Image Underst. 2006, 104, 249–257. [Google Scholar] [CrossRef] [Green Version]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning Realistic Human Actions from Movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.-L. Dense Trajectories and Motion Boundary Descriptors for Action Recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Schmid, C. Action Recognition with Improved Trajectories. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Hu, K.; Ding, Y.; Jin, J.; Weng, L.; Xia, M. Skeleton Motion Recognition Based on Multi-Scale Deep Spatio-Temporal Features. Appl. Sci. 2022, 12, 1028. [Google Scholar] [CrossRef]
- Yang, X.; Tian, Y. Effective 3D Action Recognition Using EigenJoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Liu, X.; Chen, H.-X.; Liu, B.-Y. Dynamic Anchor: A Feature-Guided Anchor Strategy for Object Detection. Appl. Sci. 2022, 18, 4897. [Google Scholar] [CrossRef]
- Hu, K.; Tian, L.; Weng, C.; Weng, L.; Zang, Q.; Xia, M.; Qin, G. Data-Driven Control Algorithm for Snake Manipulator. Appl. Sci. 2021, 11, 8146. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Xia, M.; Wang, Z.; Lu, M.; Pan, L. MFAGCN: A New Framework for Identifying Power Grid Branch Parameters. Electr. Power Syst. Res. 2022, 207, 107855. [Google Scholar] [CrossRef]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel feature fusion lozenge network for land segmentation. J. Appl. Remote Sens. 2022, 16, 016513. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-Based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. 10. arXiv 2015, arXiv:1709.01507. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. ISBN 978-3-030-01233-5. [Google Scholar]
- Xia, M.; Qu, Y.; Lin, H. PADANet: Parallel asymmetric double attention network for clouds and its shadow detection. J. Appl. Remote Sens. 2021, 15, 046512. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth. Obs. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Elman, J.L. Distributed Representations, Simple Recurrent Networks, and Grammatical Structure. Mach. Learn. 1991, 7, 195–225. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter S; Schmidhuber J Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chakrabarty, A.; Pandit, O.A.; Garain, U. Context Sensitive Lemmatization Using Two Successive Bidirectional Gated Recurrent Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1481–1491. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Allport, A. Visual Attention. In Foundations of Cognitive Science; The MIT Press: Cambridge, MA, USA, 1989; pp. 631–682. ISBN 978-0-262-16112-1. [Google Scholar]
- Cheng, X.; Li, X.; Yang, J.; Tai, Y. SESR: Single Image Super Resolution with Recursive Squeeze and Excitation Networks. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 147–152. [Google Scholar]
- Jin, X.; Xie, Y.; Wei, X.-S.; Zhao, B.-R.; Chen, Z.-M.; Tan, X. Delving Deep into Spatial Pooling for Squeeze-and-Excitation Networks. Pattern Recognit. 2022, 121, 108159. [Google Scholar] [CrossRef]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. Interspeech 2020, 2020, 3830–3834. [Google Scholar] [CrossRef]
- Qiu, C.; Zhang, S.; Wang, C.; Yu, Z.; Zheng, H.; Zheng, B. Improving Transfer Learning and Squeeze- and-Excitation Networks for Small-Scale Fine-Grained Fish Image Classification. IEEE Access 2018, 6, 78503–78512. [Google Scholar] [CrossRef]
- Gong, L.; Jiang, S.; Yang, Z.; Zhang, G.; Wang, L. Automated Pulmonary Nodule Detection in CT Images Using 3D Deep Squeeze-and-Excitation Networks. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1969–1979. [Google Scholar] [CrossRef]
- Han, Y.; Wei, C.; Zhou, R.; Hong, Z.; Zhang, Y.; Yang, S. Combining 3D-CNN and Squeeze-and-Excitation Networks for Remote Sensing Sea Ice Image Classification. Math. Probl. Eng. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Wei, S.; Qu, Q.; Wu, Y.; Wang, M.; Shi, J. PRI Modulation Recognition Based on Squeeze-and-Excitation Networks. IEEE Commun. Lett. 2020, 24, 1047–1051. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Huang, G.; Gong, Y.; Xu, Q.; Wattanachote, K.; Zeng, K.; Luo, X. A Convolutional Attention Residual Network for Stereo Matching. IEEE Access 2020, 8, 50828–50842. [Google Scholar] [CrossRef]
- Ma, B.; Wang, X.; Zhang, H.; Li, F.; Dan, J. CBAM-GAN: Generative Adversarial Networks Based on Convolutional Block Attention Module. In Artificial Intelligence and Security; Lecture Notes in Computer Science; Sun, X., Pan, Z., Bertino, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11632, pp. 227–236. ISBN 978-3-030-24273-2. [Google Scholar]
- Wang, S.-H.; Fernandes, S.; Zhu, Z.; Zhang, Y.-D. AVNC: Attention-Based VGG-Style Network for COVID-19 Diagnosis by CBAM. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Li, Y.; Guo, K.; Lu, Y.; Liu, L. Cropping and Attention Based Approach for Masked Face Recognition. Appl. Intell. 2021, 51, 3012–3025. [Google Scholar] [CrossRef]
- Cao, W.; Feng, Z.; Zhang, D.; Huang, Y. Facial Expression Recognition via a CBAM Embedded Network. Procedia Comput. Sci. 2020, 174, 463–477. [Google Scholar] [CrossRef]
- Fu, H.; Song, G.; Wang, Y. Improved YOLOv4 Marine Target Detection Combined with CBAM. Symmetry 2021, 13, 623. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Z.; Feng, L.; Ma, Y.; Du, Q. A New Attention-Based CNN Approach for Crop Mapping Using Time Series Sentinel-2 Images. Comput. Electron. Agric. 2021, 184, 106090. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention Receptive Pyramid Network for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Carrasco, M. Visual Attention: The Past 25 Years. Vision Res. 2011, 51, 1484–1525. [Google Scholar] [CrossRef] [Green Version]
- IL-MCAM: An Interactive Learning and Multi-Channel Attention Mechanism-Based Weakly Supervised Colorectal Histopathology Image Classification Approach. Comput. Biol. Med. 2022, 143, 105265. [CrossRef]
- Xie, J.; Wu, Z.; Zhu, R.; Zhu, H. Melanoma Detection Based on Swin Transformer and SimAM. In Proceedings of the 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Xi’an, China, 15 October 2021; pp. 1517–1521. [Google Scholar]
- Zhang, J.; Zeng, S.; Wang, Y.; Wang, J.; Chen, H. An Efficient Extreme-Exposure Image Fusion Method. J. Phys. Conf. Ser. 2021, 2137, 012061. [Google Scholar] [CrossRef]
- Hu, K.; Zheng, F.; Weng, L.; Ding, Y.; Jin, J. Action Recognition Algorithm of Spatio–Temporal Differential LSTM Based on Feature Enhancement. Appl. Sci. 2021, 11, 7876. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/shadow segmentation based on multi-level feature enhanced network for remote sensing imagery. Int. J. Remote Sens. 2022, 1–21. [Google Scholar] [CrossRef]
- Webb, B.S. Early and Late Mechanisms of Surround Suppression in Striate Cortex of Macaque. J. Neurosci. 2005, 25, 11666–11675. [Google Scholar] [CrossRef]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action MACH a Spatio-Temporal Maximum Average Correlation Height Filter for Action Recognition. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Liu, J.; Luo, J.; Shah, M. Recognizing Realistic Actions from Videos “in the Wild”. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009; pp. 1996–2003. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A Large Video Database for Human Motion Recognition. In Proceedings of the 2011 International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Reddy, K.K.; Shah, M. Recognizing 50 Human Action Categories of Web Videos. Mach. Vis. Appl. 2013, 24, 971–981. [Google Scholar] [CrossRef] [Green Version]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar] [CrossRef]
- Xia, M.; Zhang, X.; Weng, L.; Xu, Y. Multi-stage feature constraints learning for age estimation. IEEE T. Inf. Foren. Sect. 2020, 15, 2417–2428. [Google Scholar] [CrossRef]
- Diba, A.; Sharma, V.; Van Gool, L. Deep Temporal Linear Encoding Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1541–1550. [Google Scholar]
- Zhou, Y.; Sun, X.; Zha, Z.-J.; Zeng, W. MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 449–458. [Google Scholar]
- Wang, X.; Farhadi, A.; Gupta, A. Actions Transformations. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2658–2667. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 23–28 June 2014. [Google Scholar]
- Marszalek, M.; Laptev, I.; Schmid, C. Actions in Context. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2929–2936. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar]
- Ng, J.Y.-H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond Short Snippets: Deep Networks for Video Classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Zhu, Y.; Lan, Z.; Newsam, S.; Hauptmann, A.G. Hidden Two-Stream Convolutional Networks for Action Recognition. arXiv 2018, arXiv:17040.0389. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Data Set | |
|---|---|---|
| UCF101 | HMDB51 | |
| Slow Fusion [69] | 65.4 | - |
| BiLSTM [70] | 70.0 | 39.8 |
| ST-D LSTM [55] | 75.7 | 44.4 |
| P3D ResNet [71] | 88.6 | - |
| Transformations [68] | 92.4 | 62.0 |
| MiCT-Net [67] | 94.7 | 70.5 |
| TLE [67] | 95.6 | 71.1 |
| Method based on Two Stream Convolutional Networks (2SCN) | ||
| 2SCN (VGG) [20] | 86.9 | 58.0 |
| 2SCN (ResNet) | 87.5 | 59.6 |
| 2SCN (Conv Pooling) [72] | 88.2 | - |
| 2SCN (LSTM) [72] | 88.6 | - |
| 2SCN (Fusion) [73] | 89.6 | 57.6 |
| 2SCN (Hidden) [74] | 89.8 | - |
| BS-2SCN (proposed) | 90.1 | 71.3 |
| Data Set | Network | Accuracy | Model | |||
|---|---|---|---|---|---|---|
| 2SCN | S-2SCN | B-2SCN | BS-2SCN | |||
| UCF101 | Spatial | Average | 78.75 | 78.90 | 78.70 | 80.52 |
| Best | 78.80 | 79.34 | 78.70 | 81.47 | ||
| Motion | Average | 78.99 | 78.18 | 78.33 | 80.00 | |
| Best | 79.83 | 79.67 | 78.51 | 80.21 | ||
| Fusion | Average | 87.47 | 88.83 | 88.45 | 90.07 | |
| Best | 88.52 | 88.95 | 88.68 | 90.32 | ||
| HMDB51 | Spatial | Average | 78.75 | 78.90 | 78.70 | 80.52 |
| Best | 78.80 | 79.34 | 78.70 | 81.47 | ||
| Motion | Average | 78.99 | 78.18 | 78.33 | 80.00 | |
| Best | 79.83 | 79.67 | 78.51 | 80.21 | ||
| Fusion | Average | 87.47 | 88.83 | 88.45 | 90.07 | |
| Best | 88.52 | 88.95 | 88.68 | 90.32 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Lu, H.; Jin, J.; Hu, K. Human Action Recognition Based on Improved Two-Stream Convolution Network. Appl. Sci. 2022, 12, 5784. https://doi.org/10.3390/app12125784
Wang Z, Lu H, Jin J, Hu K. Human Action Recognition Based on Improved Two-Stream Convolution Network. Applied Sciences. 2022; 12(12):5784. https://doi.org/10.3390/app12125784
Chicago/Turabian StyleWang, Zhongwen, Haozhu Lu, Junlan Jin, and Kai Hu. 2022. "Human Action Recognition Based on Improved Two-Stream Convolution Network" Applied Sciences 12, no. 12: 5784. https://doi.org/10.3390/app12125784