
Multi-Label Classification and Explanation Methods for Students’ Learning Style Prediction and Interpretation



Abstract
:Featured Application
Abstract
1. Introduction
2. Methods
2.1. Systematic Review of the Literature
2.2. Supervised Learning Algorithms for Classification
- Binary classification;
- Multi-class classification;
- Multi-label classification;
- Imbalanced classification (this uses such techniques as: random oversampling/under-sampling; SMOTE oversampling; examples of algorithms, such as cost-sensitive logistic regression and cost-sensitive decision trees).
2.3. Multilayer Feedforward Neural Network
2.4. Model Interpretation and Shapley Additive Explanations Method (SHAP)
3. Results
3.1. Exploratory Data Analysis and the Preprocessing of Input Features
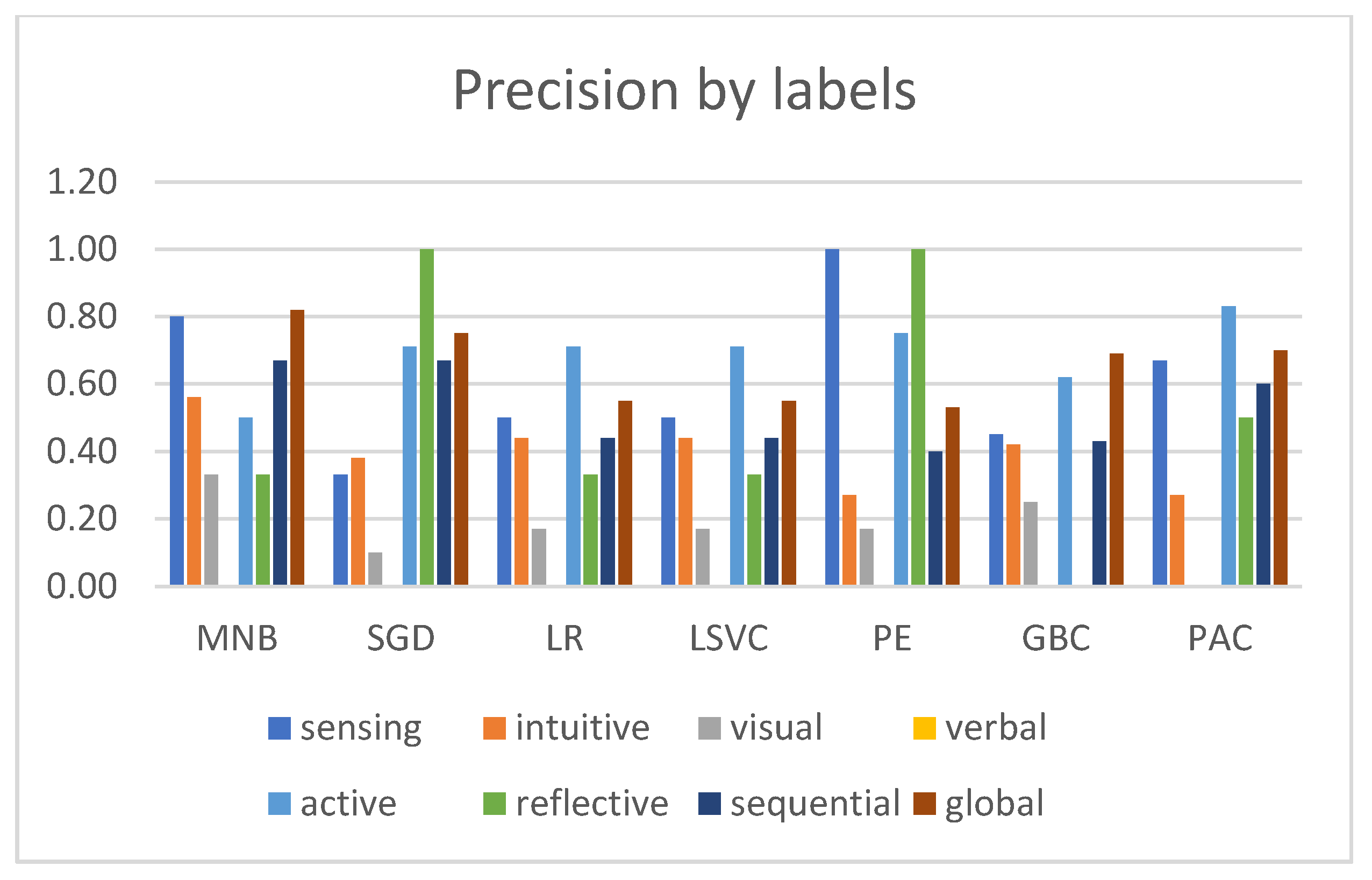
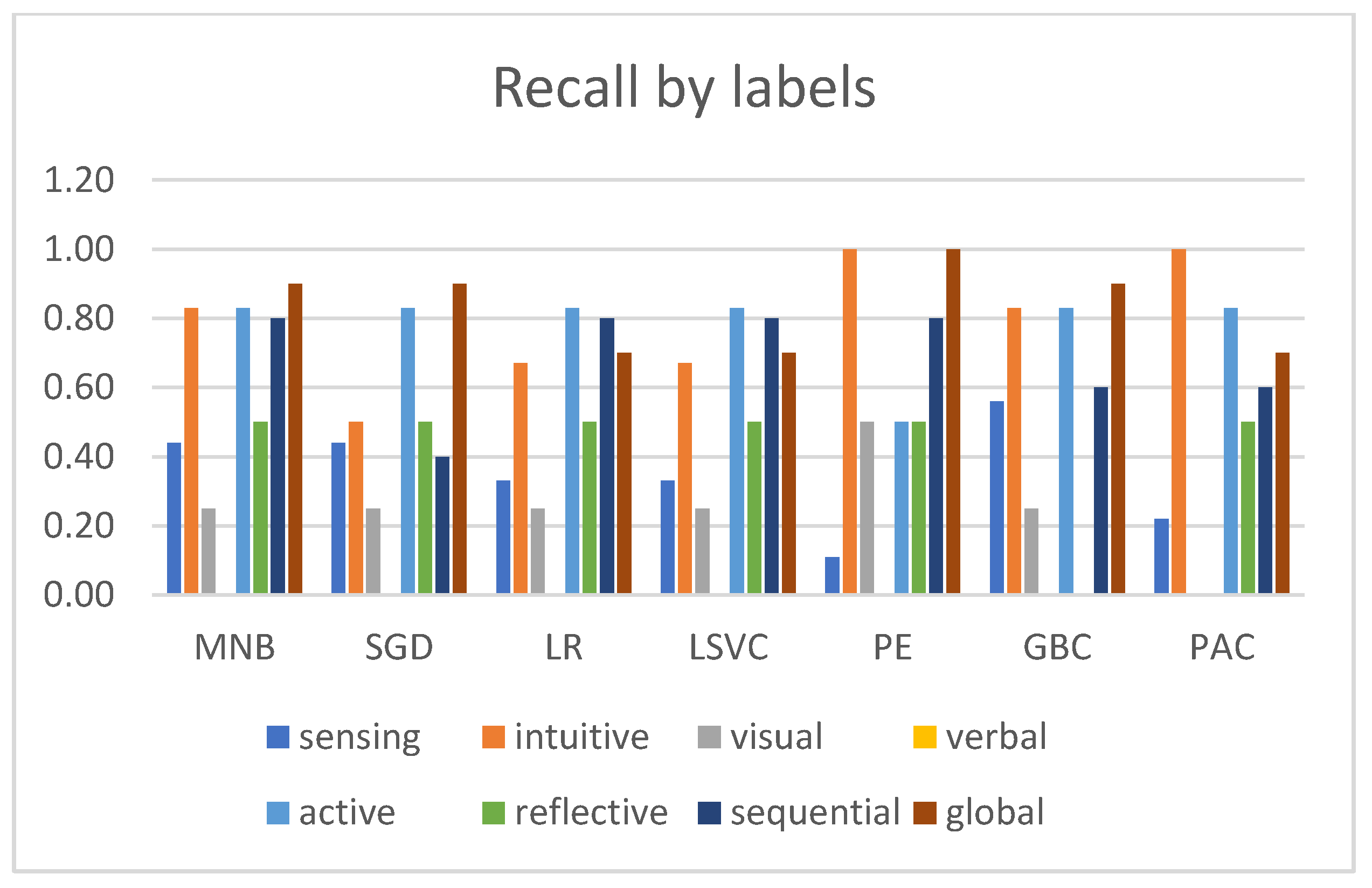
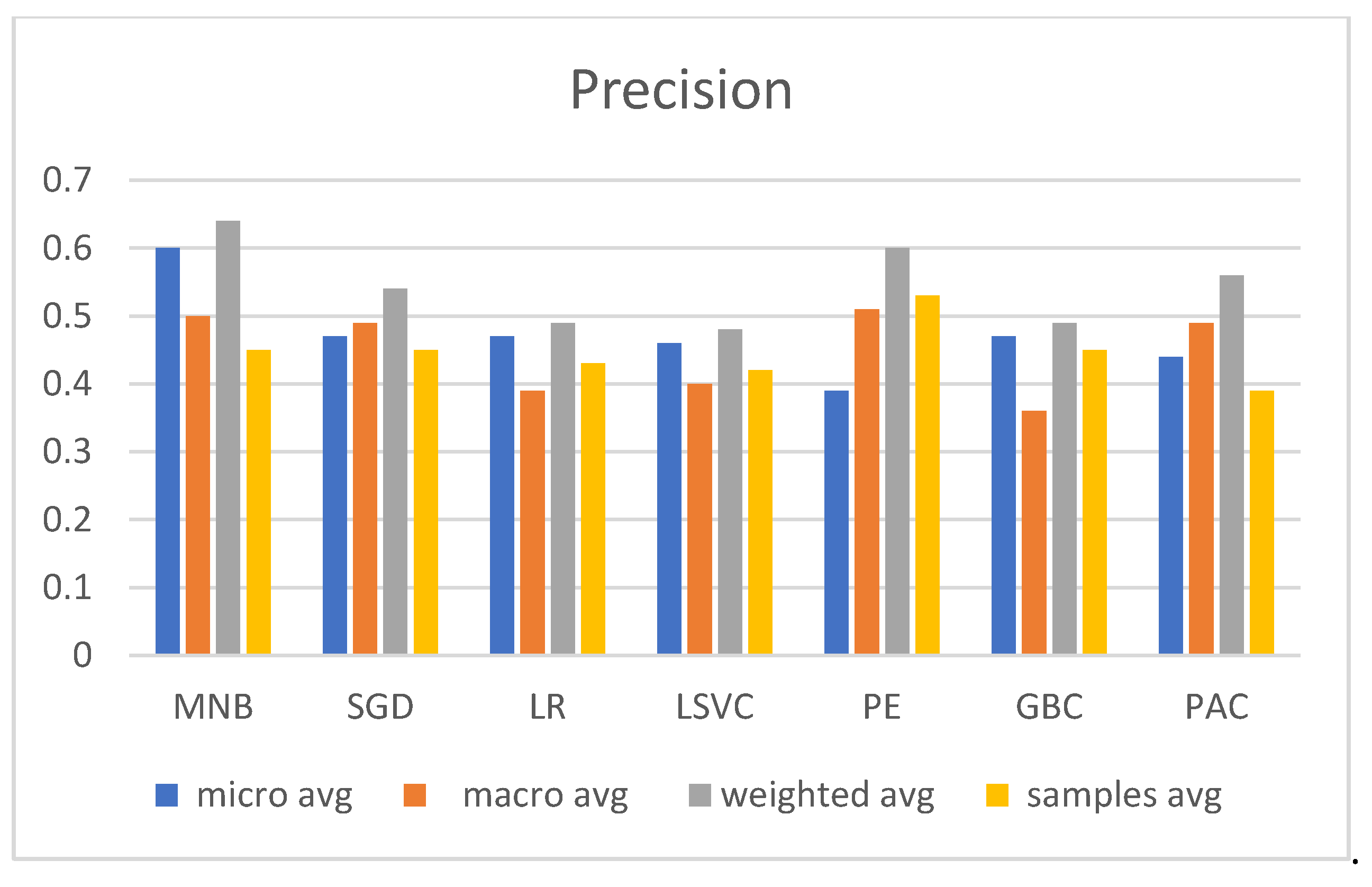
3.2. Experimental Evaluation and Comparative Analysis of Multi-Label Classifiers
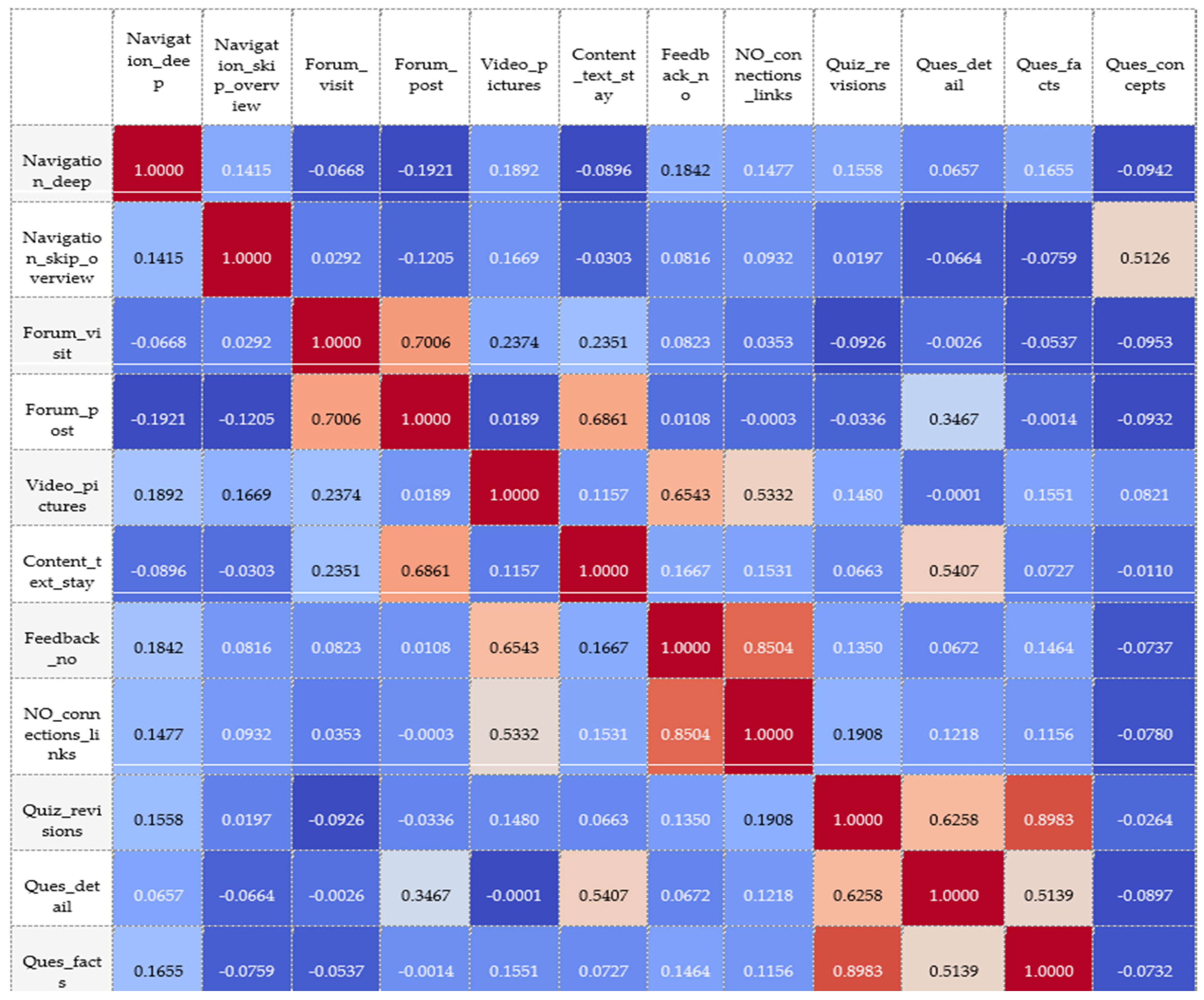
- Navigation_deep—the depth of navigation (how much depth);
- Navigation_skip_overview—the number of times that the student skips through the overview;
- Forum_visit—the number of times that the student visited the forum;
- Forum_post—the number of times that the student posted to the forum;
- Video_pictures—the number of times that the student watched videos/pictures;
- Content_text_stay—how long the student stayed on the content/topic;
- Feedback_no—the number of times that the student submitted feedback;
- NO_connections_links—the working time of the user with the weblinks tools—following a hyperlink to other learning material or web pages;
- Quiz_revision—the number of times that the student visited quiz revision pages;
- Ques_detail—the time spent on question details;
- Ques_facts—the time spent on questions of the type, “facts”;
- Ques_concepts—the time spent on questions of the type, “concepts”.
- Hamming loss—the fraction of labels that are incorrectly predicted, i.e., the fraction of the wrong labels compared to the total number of labels; this measures how well the classifier predicts each of the labels, averaged over samples, then over all labels;
- Precision—this measures the fraction of relevant instances among the retrieved instances;
- Recall—this measures the fraction of relevant instances that were retrieved;
- The F1 score measures a weighted average of precision and recall, where both have the same impact on the score.
4. Discussion and the Methodology Proposed
4.1. Mechanisms to Select the Appropriate Machine Learning Methods for Student Learning-Style Prediction and Interpretation
4.2. Threats to Validity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NN | Neural network |
| BCM | Bayesian case model |
| BPNN | Backpropagation neural network |
| SHAP | Shapley additive explanations |
| MLC | Multi-label classification |
| SVM | Support vector machines |
| ML-kNN | Multi-label k-nearest neighbor |
| PS | Pruned sets |
| EPS | Ensembles of pruned sets |
| BR | Binary relevance |
| RAKEL | Random k-label sets |
| LP (LC) | Label powerset (label combination) |
| NB | Naïve Bayes |
References
- Gambo, Y.; Shakir, M.Z. An Artificial Neural Network (ANN)-Based Learning Agent for Classifying Learning Styles in Self-Regulated Smart Learning Environment. Int. J. Emerg. Technol. Learn. (IJET) 2021, 16, 185–199. [Google Scholar] [CrossRef]
- Gomede, E.; Miranda de Barros, R.; de Souza Mendes, L. Use of Deep Multi-Target Prediction to Identify Learning Styles. Appl. Sci. 2020, 10, 1756. [Google Scholar] [CrossRef] [Green Version]
- Nasiri, J.; Mir, A.M.; Fatahi, S. Classification of learning styles using behavioral features and twin support vector machine. Technol. Educ. J. (TEJ) 2008, 13, 316–326. [Google Scholar] [CrossRef]
- Sasidhar, R.C.; Arunachalam, A. Personalization of Learning Management System using VARK. Turk. J. Comput. Math. Educ. 2021, 12. [Google Scholar] [CrossRef]
- Zhang, Y.; Dai, H.; Yun, Y.; Liu, S.; Lan, A.; Shang, X. Meta-knowledge dictionary learning on 1-bit response data for student knowledge diagnosis. Knowl. Based Syst. 2020, 205, 106290. [Google Scholar] [CrossRef]
- Zhang, Y.; An, R.; Liu, S.; Cui, J.; Shang, X. Predicting and Understanding Student Learning Performance Using Multi-sourse Sparse Attention Convolutional Neural Networks. IEEE Trans. Big Data 2021, 1. [Google Scholar] [CrossRef]
- Lwande, C.; Muchemi, L.; Oboko, R. Identifying learning styles and cognitive traits in a learning management system. Heliyon 2021, 7, e07701. [Google Scholar] [CrossRef]
- Dung, P.Q.; Florea, A.M. An approach for detecting learning styles in learning management systems based on learners’ behaviours. Int. Conf. Educ. Manag. Innov. 2012, 30, 171–177. [Google Scholar]
- Preidys, S.; Sakalauskas, L. Possibilities of integrating of smart modules into VMA Moodle: From theory to practice [Capabilities for Intelligent Modules Integration into the Moodle VLE: From Theory to Practice]. Mokslo taikomųjų tyrimų įtaka šiuolaikiniųn studijų kokybei 2012, 1, 77–82. [Google Scholar]
- Wang, J.; Mendori, T. The reliability and validity of Felder-Silverman Index of learning styles in Mandarin version. Int. J. Inf. Eng. Express 2015, 1, 1–8. [Google Scholar] [CrossRef]
- Brownlee, J. Tour of Evaluation Metrics for Imbalanced Classification. Machine Learning Mastery. Imbalanced Classification. 2020. Available online: https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/ (accessed on 23 May 2022).
- Preidys, S.; Sakalauskas, L. Analysis of students’ study activities in virtual learning environments using data mining methods. Technol. Econ. Dev. 2010, 16, 94–108. [Google Scholar] [CrossRef]
- Ghamrawi, N.; McCallum, A. Collective multi-label classification. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, ACM, Atlanta, GA, USA, 17–22 October 2005. [Google Scholar]
- Godbole, S.; Sunita, S. Discriminative methods for multi-labeled classification. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Goštautaitė, D. Dynamic learning style modelling using probabilistic Bayesian network. Edulearn 2019, 2921–2932. [Google Scholar] [CrossRef]
- Bogatinovski, J.; Todorovski, L.; Džeroski, S.; Kocev, D. Comprehensive Comparative Study of Multi-Label Classification Methods. Comput. Sci. 2021, 203. [Google Scholar] [CrossRef]
- Kravcik, M.; Angelova, G.; Ceri, S.; Cristea, A.; Damjanović, V.; Devedžić, V.; Dimitrova, V.; Dolog, P.; Đurić, D.; Ga Ević, D.; et al. Requirements and Solutions for Personalized Adaptive Learning. 2005. Available online: https://hal.archives-ouvertes.fr/hal-00590961/ (accessed on 23 May 2022).
- Scikit-Learn. Multiclass and Multioutput Algorithms. Available online: https://scikit-learn.org/stable/modules/multiclass.html (accessed on 23 May 2022).
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef] [Green Version]
- Bernard, J.; Chang, T.; Popescu, E.; Graf, S. Learning style Identifier: Improving the precision of learning style identification through computational intelligence algorithms. Expert Syst. Aapli. 2017, 75, 94–108. [Google Scholar] [CrossRef]
- Wikipedia: Earning Styles. 2022. Available online: https://en.wikipedia.org/wiki/Learning_styles (accessed on 23 May 2022).
- Pushpa, M.; Karpagavalli, S. Multi-label Classification: Problem Transformation methods in Tamil Phoneme classification. Procedia Comput. Sci. 2017, 115, 572–579. [Google Scholar] [CrossRef]
- Sawsan, K. Learning methods for multi-label classification. In Machine Learning [stat.ML]; Université de technologie de Compiègne: Compiègne, France; Université Libanaise: Beirut, Liban, 2013. [Google Scholar]
- Mohammad, S. A literature survey on algorithms for multi-label learning. Comput. Sci. 2021, 18, 1–25. [Google Scholar]
- Al-Otaibi, R.; Flach, P.; Kull, M. Multi-label Classification: A Comparative Study on Threshold Selection Methods. In Proceedings of the First International Workshop on Learning over Multiple Contexts (LMCE) at ECML-PKDD as Part of the 7th European Machine Learning and Data Mining Conference (ECML-PKDD 2014), Nancy, France, 14–18 September 2014. [Google Scholar]
- Rasheed, F.; Wahid, A. Learning style detection in E-learning systems using machine learning techniques. Expert Syst. Appl. 2021, 74, 114774. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, Z. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Madjarov, G.; Kocev, D.; Gjorgjevikj, D.; Džeroski, S. An extensive experimental comparison of methods for multi-label learning. Pattern Recognit. 2012, 45, 3084–3104. [Google Scholar] [CrossRef]
- Nooney, K. Deep dive into multi-label classification..! (With detailed Case Study). Available online: https://towardsdatasciencecom/journey-to-the-center-of-multi-label-classification-384c40229bff (accessed on 23 May 2022).
- Prathibhamol, C.P.; Jyothy, K.V.; Noora, B. Multi label classification based on logistic regression (MLC-LR). In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016. [Google Scholar]
- Goštautaitė, D.; Kurilov, J. Comparative Analysis of Exemplar-Based Approaches for Students’ Learning Style Diagnosis Purposes. Appl. Sci. 2021, 11, 7083. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Ioannis, K. Multi-label classification: An overview. Comput. Sci. 2006. [Google Scholar] [CrossRef] [Green Version]
- Aas, K.; Jullum, M.; Løland, A. Explaining individual predictions when features are dependent: More accurate approximations to Shapley values. Artif. Intell. 2021, 298, 103502. [Google Scholar] [CrossRef]
- Molnar, C. A Guide for Making Black Box Models Explainable. Available online: https://christophm.github.io/interpretable-ml-book/index.html#summary (accessed on 23 May 2022).
- Carvalho, V.; Pereira, M.; Cardoso, S. Machine Learning Interpretability. A Survey onMethods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Mase, M.; Owen, A.; Seiler, B. Explaining Black Box Decisions by Shapley Cohort Refinement. 2019. Available online: https://arxiv.org/abs/1911.00467 (accessed on 23 May 2022).
- Basu, I.; Maji, S. Multicollinearity Correction and Combined Feature Effect in Shapley Values. arXiv 2020, arXiv:2011.01661. [Google Scholar]
- Maaliw, I.; Renato, R.; Ballera, M.; Ambat, S.; Dumlao, M. Comparative Analysis of Data Mining Techniques for Classification of Student’s Learning Styles. In Proceedings of the 5th International Conference on Advances in Science, Engineering and Technology (ICASET-17), Manila, Philippines, 18–19 September 2017. [Google Scholar]
- Bogatinovski, J.; Todorovski, L.; Džeroski, S.; Kocev, D. Explaining the Performance of Multi-label Classification Methods with Data Set Properties. Int. J. Intell. Sytems 2021. [Google Scholar] [CrossRef]
- Sharat, C. Hamming Score for Multi-Label Classification. 2021. Available online: https://www.linkedin.com/pulse/hamming-score-multi-label-classification-chandra-sharat (accessed on 23 May 2022).
- Wu, G.; Zhu, J. Multi-label classification: Do Hamming loss and subset accuracy really conflict with each other? In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020. [Google Scholar]
- Winata, G.I.; Khodra, M.L. Handling Imbalanced Dataset in Multi-label Text Categorization using Bagging and Adaptive Boosting. Int. Conf. Electr. Eng. Inform. 2015, 500–505. [Google Scholar] [CrossRef] [Green Version]
- Dembczyński, K.; Waegeman, W.; Cheng, W.; Hüllermeier, E. On label dependence and loss minimization in multi-label classification. Mach. Learn. 2012, 88, 5–45. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Wang j Wang, Z.; Ji, Q. Enhancing multi-label classification by modeling dependencies among labels. Comput. Sci. Pattern Recognit 2014, 47, 3405–3413. [Google Scholar] [CrossRef]
- Cooper, A. Ideas, Explorations and Musings on Data. 2021. Available online: https://www.aidancooper.co.uk/a-non-technical-guide-to-interpreting-shap-analyses/ (accessed on 23 May 2022).
- Comparision of Four Multilabel-Classification Methods. 2019. Available online: https://www.causeweb.org/usproc/sites/default/files/usclap/2019-1/Comparison%20of%20Four%20Multi-Label%20Classification%20Methods.pdf (accessed on 23 May 2022).
- Aldrees, A.; Chikh, A.; Berri, J. Comparative evaluation of four multilabel classification algorithms in classifying learning objects. Comput. Sci. Inf. Technol. (CS IT) 2016, 24, 651–660. [Google Scholar]
- Elkafrawy, P.; Mousad, A. Experimental comparision of methods for multi-label classification in different application domains. Int. J. Comput. Appl. 2015, 114, 1–9. [Google Scholar]
- Tawiah, C.A.; Sheng, V.S. Empirical comparision of multilabel-classification algorythms. In Proceedings of the Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Cherman, E.A.; Monard, M.C.; Metz, J. Multi-label Problem Transformation Methods: A Case Study. CLEI Electron. J. 2011, 14, 4. [Google Scholar] [CrossRef] [Green Version]
- Modi, H.; Panchal, M. Experimental Comparison of Different Problem Transformation Methods for Multi-Label Classification using MEKA. Int. J. Comput. Appl. 2012, 59, 10–15. [Google Scholar] [CrossRef]
- Nareshpalsingh, J.; Modi, H. Multi-label classification methods: A comparative study. Int. Res. J. Eng. Technol. 2017, 4, 263–270. [Google Scholar]
- Maheswari, J.P. Breaking the Curse Of Small Data Sets In Machine Learning. Why the Size of Data Matters and How to Work with Smalll Data. 2018. Available online: https://towardsdatascience.com/breaking-the-curse-of-small-datasets-in-machine-learning-part-1-36f28b0c044d (accessed on 23 May 2022).
- Cherman, E.; Metz, J.; Monard, M. A Simple Approach to Incorporate Label Dependency in Multi-label Classification. In Proceedings of the 9th Mexican International Conference on Artificial Intelligence Conference on Advances in Soft Computing: Part II, Pachuca, Mexico, 8 November 2010. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Navigation Deep | Navigation Skip Overview | Forum Visit | Forum Post | Video, Pictures | Content Text Stay | Feedback No. | No. of _Connections or Links | Quiz Revision | Question Details | |
|---|---|---|---|---|---|---|---|---|---|---|
| mean | 7.3737 | 8.5858 | 8.2727 | 10.7272 | 4.6868 | 8.8585 | 5.3737 | 5.3333 | 8.0808 | 10.7373 |
| std | 5.7792 | 6.0170 | 6.1125 | 7.0230 | 3.7297 | 7.1070 | 4.6016 | 4.7787 | 5.7011 | 6.3576 |
| min | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 25% | 2.0000 | 3.0000 | 3.0000 | 4.0000 | 2.0000 | 2.0000 | 2.0000 | 2.0000 | 3.0000 | 4.0000 |
| 50% | 6.0000 | 8. 0000 | 7.0000 | 9.0000 | 4.0000 | 70.000 | 4.0000 | 4.0000 | 6.0000 | 11.0000 |
| 75% | 11.5000 | 14.5000 | 12.5000 | 18.0000 | 7.5000 | 17.0000 | 8.0000 | 7.5000 | 14.0000 | 16.0000 |
| max | 20.0000 | 20.0000 | 20.0000 | 20.0000 | 20.0000 | 20.0000 | 20.0000 | 20.0000 | 20.0000 | 20.0000 |
| Learning Style | Precision | Recall | F1 Score | Support |
|---|---|---|---|---|
| sensing | 0.86 | 0.81 | 0.83 | 31 |
| intuitive | 0.84 | 0.88 | 0.86 | 42 |
| visual | 0.00 | 0.00 | 0.00 | 1 |
| verbal | 0.97 | 0.93 | 0.95 | 30 |
| active | 0.93 | 0.72 | 0.81 | 18 |
| reflective | 0.00 | 0.00 | 0.00 | 8 |
| sequential | 0.73 | 0.35 | 0.47 | 23 |
| global | 0.85 | 0.71 | 0.77 | 31 |
| Micro avg. | 0.86 | 0.72 | 0.79 | 184 |
| Macro avg. | 0.65 | 0.55 | 0.59 | 184 |
| Weighted avg. | 0.82 | 0.72 | 0.76 | 184 |
| Samples avg. | 0.71 | 0.64 | 0.66 | 184 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goštautaitė, D.; Sakalauskas, L. Multi-Label Classification and Explanation Methods for Students’ Learning Style Prediction and Interpretation. Appl. Sci. 2022, 12, 5396. https://doi.org/10.3390/app12115396
Goštautaitė D, Sakalauskas L. Multi-Label Classification and Explanation Methods for Students’ Learning Style Prediction and Interpretation. Applied Sciences. 2022; 12(11):5396. https://doi.org/10.3390/app12115396
Chicago/Turabian StyleGoštautaitė, Daiva, and Leonidas Sakalauskas. 2022. "Multi-Label Classification and Explanation Methods for Students’ Learning Style Prediction and Interpretation" Applied Sciences 12, no. 11: 5396. https://doi.org/10.3390/app12115396