
Inverse Design of Distributed Bragg Reflectors Using Deep Learning

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Generation
2.2. Feature Encoding
2.3. Simulation Neural Network
2.4. Tandem Neural Network
3. Results and Discussion
3.1. SNN Model Performance
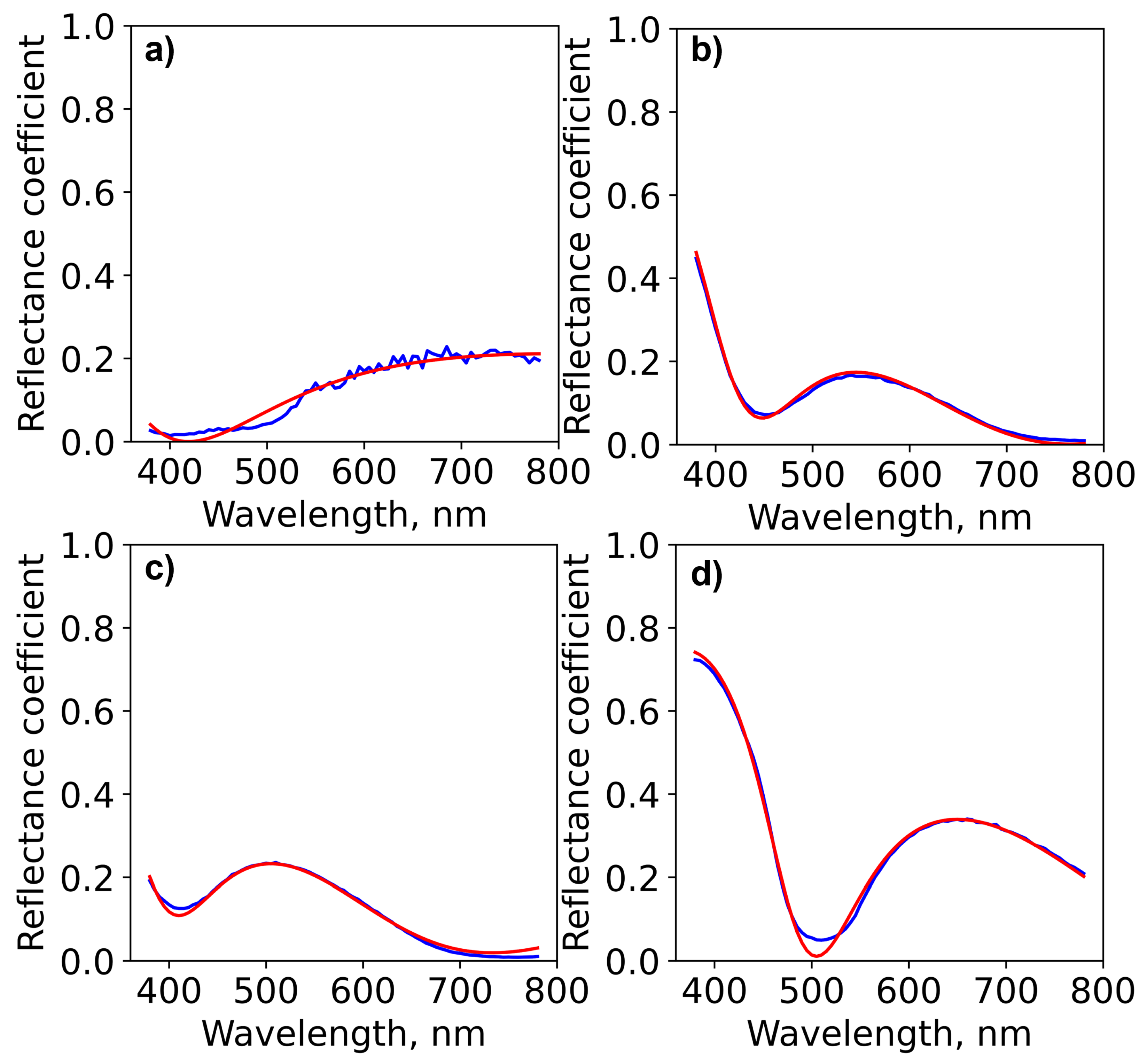
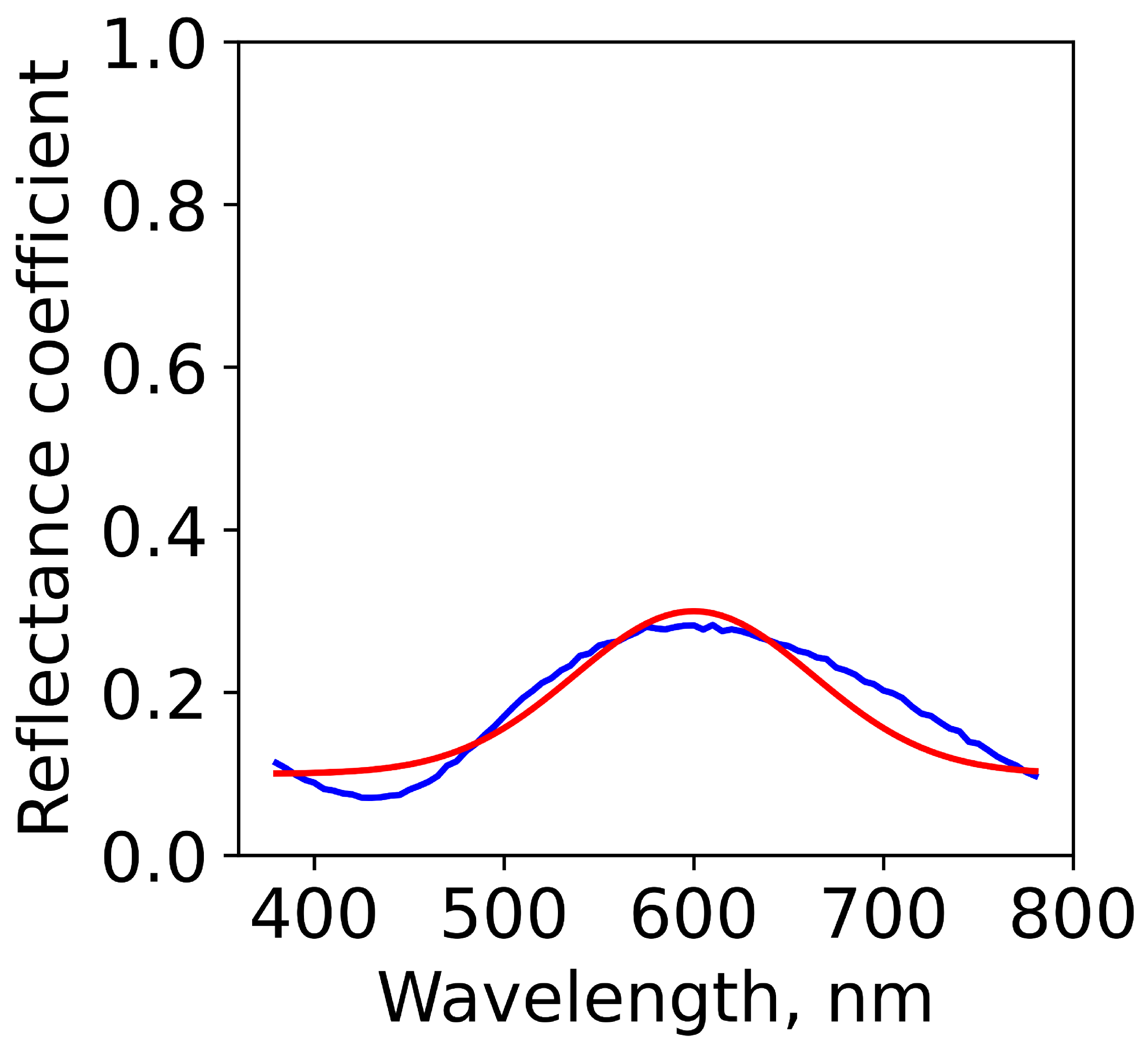
3.2. Tandem Model Performance
3.3. Colour Generation by Multilayers
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qu, Y.; Jing, L.; Shen, Y.; Qiu, M.; Soljačić, M. Migrating Knowledge between Physical Scenarios Based on Artificial Neural Networks. ACS Photonics 2019, 6, 1168–1174. [Google Scholar] [CrossRef] [Green Version]
- Schurig, D.; Mock, J.J.; Justice, B.; Cummer, S.A.; Pendry, J.B.; Starr, A.F.; Smith, D.R. Metamaterial electromagnetic cloak at microwave frequencies. Science 2006, 314, 977–980. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caligiuri, V.; Tedeschi, G.; Palei, M.; Miscuglio, M.; Martin-Garcia, B.; Guzman-Puyol, S.; Hedayati, M.K.; Kristensen, A.; Athanassiou, A.; Cingolani, R.; et al. Biodegradable and insoluble cellulose photonic crystals and metasurfaces. ACS Nano 2020, 14, 9502–9511. [Google Scholar] [CrossRef] [PubMed]
- Roberts, N.B.; Keshavarz Hedayati, M. A deep learning approach to the forward prediction and inverse design of plasmonic metasurface structural color. Appl. Phys. Lett. 2021, 119, 061101. [Google Scholar] [CrossRef]
- Keshavarz Hedayati, M.; Abdelaziz, M.; Etrich, C.; Homaeigohar, S.; Rockstuhl, C.; Elbahri, M. Broadband anti-reflective coating based on plasmonic nanocomposite. Materials 2016, 9, 636. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Keshavarz Hedayati, M.; Zhu, X.; Nielsen, F.; Levy, U.; Kristensen, A. Optofluidic sensor for inline hemolysis detection on whole blood. ACS Sens. 2018, 3, 784–791. [Google Scholar] [CrossRef] [PubMed]
- Gaio, M.; Saxena, D.; Bertolotti, J.; Pisignano, D.; Camposeo, A.; Sapienza, R. A nanophotonic laser on a graph. Nat. Commun. 2019, 10, 226. [Google Scholar] [CrossRef] [PubMed]
- Malekovic, M.; Bermúdez-Ureña, E.; Steiner, U.; Wilts, B.D. Distributed Bragg reflectors from colloidal trilayer flake solutions. APL Photonics 2021, 6, 026104. [Google Scholar] [CrossRef]
- Sugawara, H.; Itaya, K.; Hatakoshi, G. Characteristics of a distributed Bragg reflector for the visible-light spectral region using InGaAlP and GaAs: Comparison of transparent- and loss-type structures. J. Appl. Phys. 1993, 74, 3189–3193. [Google Scholar] [CrossRef]
- Schubert, M.F.; Xi, J.Q.; Kim, J.K.; Schubert, E.F. Distributed Bragg reflector consisting of high-and low-refractive-index thin film layers made of the same material. Appl. Phys. Lett. 2007, 90, 141115. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zhu, D.; Raju, L.; Cai, W. Tackling Photonic Inverse Design with Machine Learning. Adv. Sci. 2021, 8, 2002923. [Google Scholar] [CrossRef] [PubMed]
- Molesky, S.; Lin, Z.; Piggott, A.; Jin, W.; Vucković, J.; Rodriguez, A. Inverse design in nanophotonics. Nat. Photonics 2018, 12, 659–670. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Luo, Y.; Tao, Z.; You, J. Graphic-processable deep neural network for the efficient prediction of 2D diffractive chiral metamaterials. Appl. Opt. 2021, 60, 5691–5698. [Google Scholar] [CrossRef] [PubMed]
- Lininger, A.; Hinczewski, M.; Strangi, G. General Inverse Design of Thin-Film Metamaterials with Convolutional Neural Networks. arXiv 2021, arXiv:2104.01952. [Google Scholar]
- Liu, D.; Tan, Y.; Khoram, E.; Yu, Z. Training Deep Neural Networks for the Inverse Design of Nanophotonic Structures. ACS Photonics 2018, 5, 1365–1369. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Sun, C.; Li, Y.; Zhao, J.; Han, J.; Huang, W. An improved tandem neural network for the inverse design of nanophotonics devices. Opt. Commun. 2021, 481, 126513. [Google Scholar] [CrossRef]
- Unni, R.; Yao, K.; Han, X.; Zhou, M.; Zheng, Y. A mixture-density-based tandem optimization network for on-demand inverse design of thin-film high reflectors. Nanophotonics 2021, 10, 4057–4065. [Google Scholar] [CrossRef]
- Polyanskiy, M.N. Refractive Index Database. Available online: https://refractiveindex.info (accessed on 14 November 2021).
- Lei, P.-H.; Wang, S.-H.; Juang, F.-S.; Tseng, Y.-H.; Chung, M.-J. Effect of SiO2/Si3N4 dielectric distributed Bragg reflectors (DDBRs) for Alq3/NPB thin-film resonant cavity organic light emitting diodes. Opt. Commun. 2010, 283, 1933–1937. [Google Scholar] [CrossRef]
- Rao, S. Transmittance and Reflectance Spectra of Multilayered Dielectric Stack Using Transfer Matrix Method. MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/47637-transmittance-and-reflectance-spectra-of-multilayered-dielectric-stack-using-transfer-matrix-method (accessed on 8 April 2022).
- Chollet, F. Deep Learning with Python, 2nd ed.; Manning Publications: New York, NY, USA, 2018. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reiley: Springfield, MO, USA, 2019. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Bottura Scardina, S. Colour Converter—Reflectance Spectra to CIE1964 Space. 2022. Available online: https://www.mathworks.com/matlabcentral/fileexchange/87467-colour-converter-reflectance-spectra-to-cie1964-space (accessed on 8 April 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Details | Drawbacks |
|---|---|---|
| Systematic | By making intuitive design decisions based on photonics theory and existing structures, a starting structure is chosen and parameters are systematically cycled through until a desirable response is happened upon. | The links between structures and spectra are not always intuitive, making this method computationally costly and extremely slow. |
| Removal of non-unique instances followed by DL | Lininger et al. implement a feedforward neural network to design a 1–5-layer system using up to 5 different materials, with a user-imposed ‘similarity metric’ [14]. This is used to filter out training instances deemed as non-unique, effectively reducing the design challenge to a one-to-one problem. | The ‘similarity threshold’ chosen by the user is arbitrary and may not catch all similar spectra, which could prevent model convergence. |
| DL tandem model | Works by Liu et al. and Xiaopeng et al. use a Tandem Neural Network to address non-uniqueness [15,16]. This is composed of two networks: the first designing a reflector to produce a target spectra, while the second pretrained network determines how well the target and predicted spectra match, regardless of the intermediate structural predictions. | Struggles with classification design problems, as the intermediate network output needs to be in an acceptable form to be fed into the secondary network. |
| DL mixture-density model | Unni et al. also use two networks, the second again being pretrained to map structural components to spectral response [17]. However, the two are not connected, and instead the first network outputs the probability of a number of structures, and a separate optimisation process evaluates each possibility with reference to its performance in the second network. | Requires an optimisation process on top of a second pretrained network, and multiple possible designs must be tested and verified for each design case. |
| Hidden Layer Sizes | Dropout | Mean Absolute Error |
|---|---|---|
| 500, 500, 500, 500 | None | 0.0047 |
| 500, 500, 500, 1000 | None | 0.0039 |
| 500, 500, 1000, 1000 | None | 0.0039 |
| 500, 500, 500, 1000 | 2%, 2%, 1%, 0 | 0.0041 |
| 500, 500, 500, 1000 | 2%, 1%, 1%, 0 | 0.0044 |
| 500, 500, 500, 1000 | 5%, 2%, 1%, 0 | 0.0040 |
| 500, 500, 500, 1000 | 2%, 1%, 0, 0 | 0.0037 |
| Layer | Details | Number of Parameters |
|---|---|---|
| Input shape | Output shape = 6 | 0 |
| Dense layer | Output shape = 500 | 3500 |
| Dropout layer | 2% dropout | 0 |
| Dense layer | Output shape = 500 | 250,500 |
| Dropout layer | 1% dropout | 0 |
| Dense layer | Output shape = 500 | 250,500 |
| Dense layer | Output shape = 1000 | 501,000 |
| Dense layer | Output shape = 81 | 81,081 |
| Layer | Details | Number of Parameters |
|---|---|---|
| Input shape | Output shape = 81 | 0 |
| Dense layer | Output shape = 1000 | 82,000 |
| Dense layer | Output shape = 1000 | 1,001,000 |
| Dense layer | Output shape = 1000 | 1,001,000 |
| Dropout layer | 2% dropout | 0 |
| Dense layer | Output shape = 500 | 500,500 |
| Dropout layer | 1% dropout | 0 |
| Dense layer | Output shape = 500 | 250,500 |
| Dense layer | Output shape = 500 | 250,500 |
| Dense layer | Output shape = 6 | 3006 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Head, S.; Keshavarz Hedayati, M. Inverse Design of Distributed Bragg Reflectors Using Deep Learning. Appl. Sci. 2022, 12, 4877. https://doi.org/10.3390/app12104877
Head S, Keshavarz Hedayati M. Inverse Design of Distributed Bragg Reflectors Using Deep Learning. Applied Sciences. 2022; 12(10):4877. https://doi.org/10.3390/app12104877
Chicago/Turabian StyleHead, Sarah, and Mehdi Keshavarz Hedayati. 2022. "Inverse Design of Distributed Bragg Reflectors Using Deep Learning" Applied Sciences 12, no. 10: 4877. https://doi.org/10.3390/app12104877