
Improving PM2.5 Concentration Forecast with the Identification of Temperature Inversion



Abstract
:1. Introduction
2. Literature Review
2.1. Analysis of PM2.5 Concentration in Taiwan
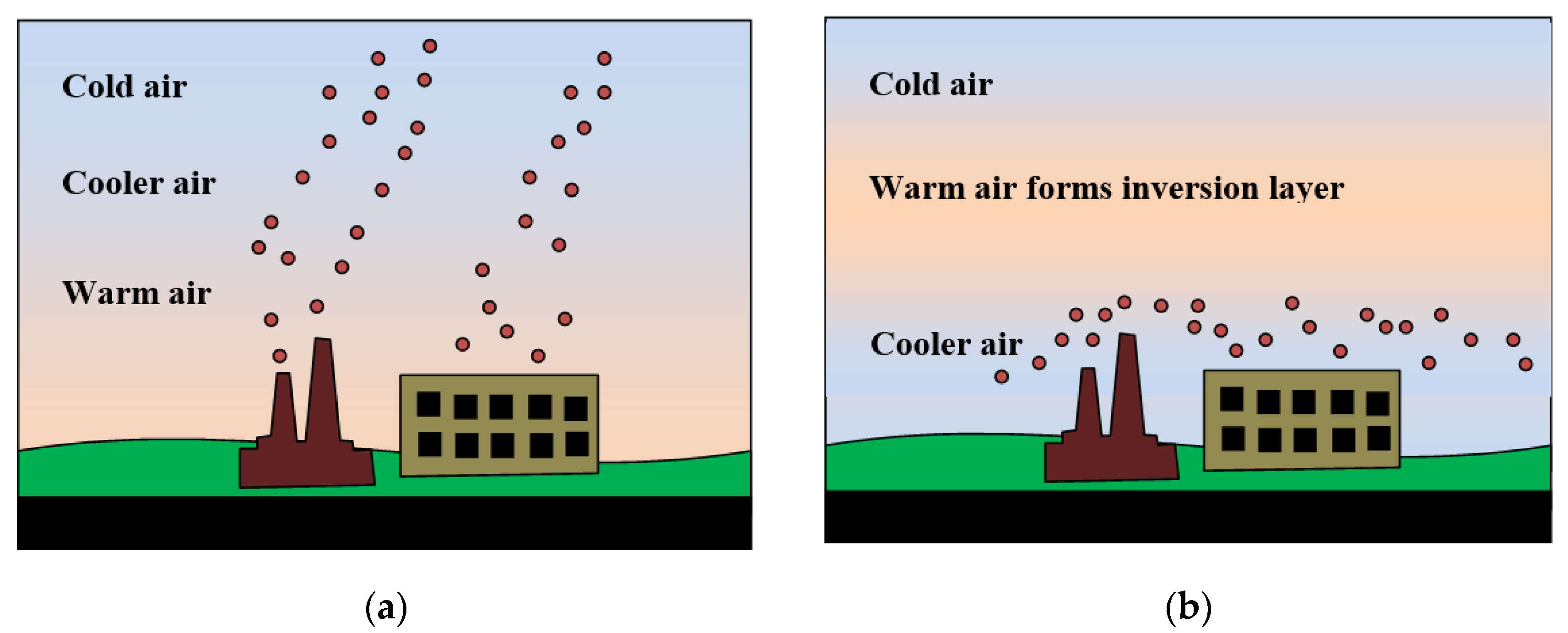
2.2. Temperature Inversion
2.3. PM2.5 Forecasting
3. Proposed Methods
3.1. Materials
3.2. Feature Engineering
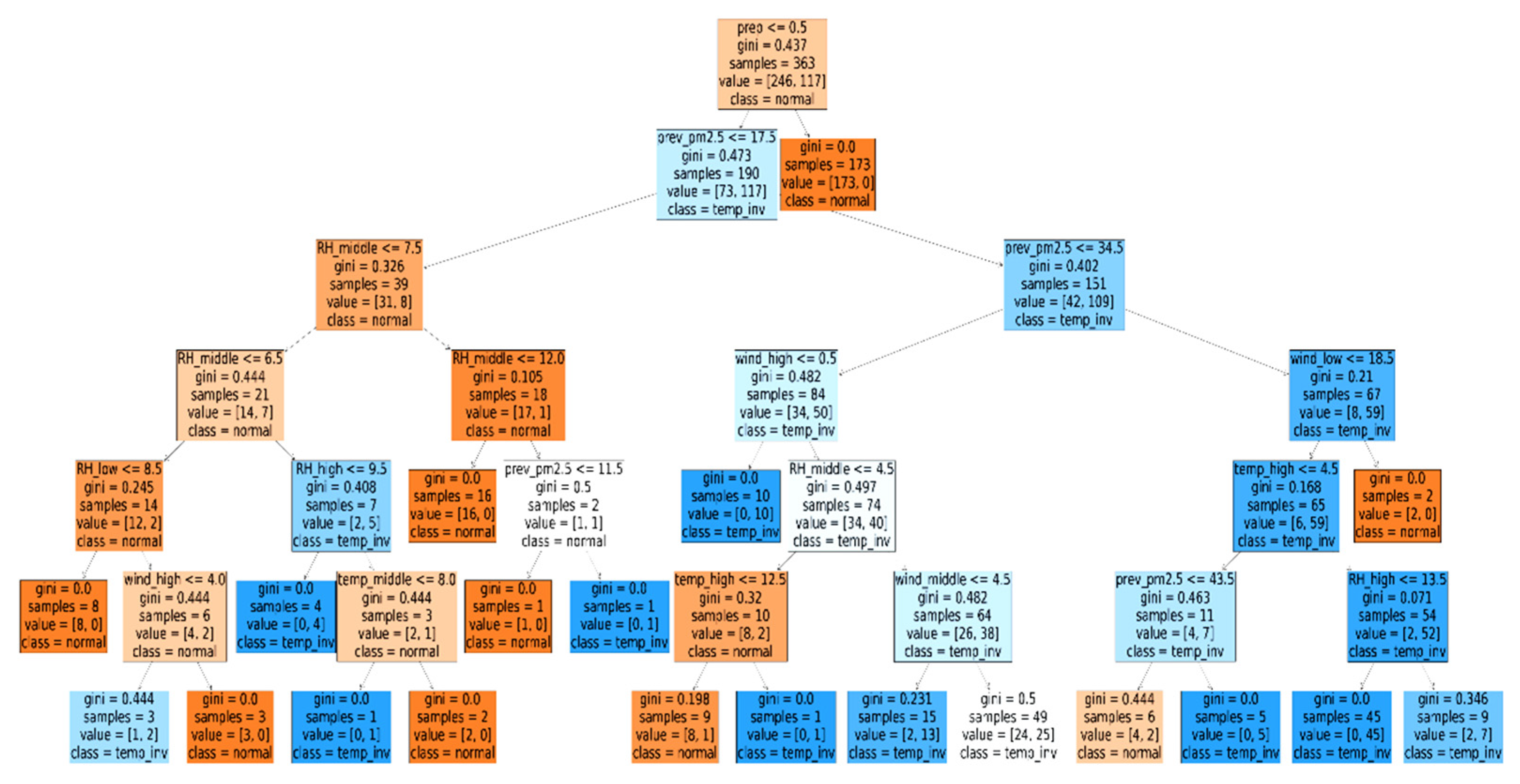
3.3. Temperature Inversion Classification
3.4. Multivariate Regression
4. Experimental Results and Comparative Performances
4.1. Temperature Inversion Classification
4.2. PM2.5 Concentration Estimation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Song, C.; He, J.; Wu, L.; Jin, T.; Chen, X.; Li, R.; Ren, P.; Zhang, L.; Mao, H. Health burden attributable to ambient PM2.5 in China. Environ. Pollut. 2017, 223, 575–586. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.C.; Chiang, H.C.; Hsu, C.Y.; Yang, T.T.; Lin, T.Y.; Chen, M.J.; Chen, N.T.; Wu, Y.S. Ambient PM2.5-bound polycyclic aromatic hydrocarbons (PAHs) in Changhua County, Central Taiwan: Seasonal variation, source apportionment and cancer risk assessment. Environ. Pollut. 2016, 218, 372–382. [Google Scholar] [CrossRef]
- WHO Media Centre, Ambient (Outdoor) Air Quality and Health. Available online: http://www.who.int/mediacentre/factsheets/fs313/en/ (accessed on 30 October 2019).
- Liang, C.S.; Duan, F.K.; He, K.B.; Ma, Y.L. Review on recent progress in observations, source identifications and countermeasures of PM2.5. Environ. Int. 2016, 86, 150–170. [Google Scholar] [CrossRef]
- Singh, N.; Murari, V.; Kumar, M.; Barman, S.C.; Banerjee, T. Fine particulates over South Asia: Review and meta-analysis of PM2.5 source apportionment through receptor model. Environ. Pollut. 2017, 223, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.H.; Cheng, F.Y. Classification of weather patterns to study the influence of meteorological characteristics on PM2.5 concentrations in Yunlin County, Taiwan. Atmos. Environ. 2016, 144, 397–408. [Google Scholar] [CrossRef]
- Chen, M.L.; Mao, I.F.; Lin, I.K. The PM2.5 and PM10 particles in urban areas of Taiwan. Sci. Total Environ. 1999, 226, 227–235. [Google Scholar] [CrossRef]
- Hsu, C.Y.; Chiang, H.C.; Lin, S.L.; Chen, M.J.; Lin, T.Y.; Chen, Y.C. Elemental characterization and source apportionment of PM10 and PM2.5 in the western coastal area of central Taiwan. Sci. Total Environ. 2016, 541, 1139–1150. [Google Scholar] [CrossRef]
- Kuo, Y.M.; Wang, S.W.; Jang, C.S.; Yeh, N.; Yu, H.L. Identifying the factors influencing PM2.5 in southern Taiwan using dynamic factor analysis. Atmos. Environ. 2011, 45, 7276–7285. [Google Scholar] [CrossRef]
- Hwang, S.L.; Lin, Y.C.; Guo, S.E.; Chi, M.C.; Chou, C.T.; Lin, C.M. Emergency room visits for respiratory diseases associated with ambient fine particulate matter in Taiwan in 2012: A population-based study. Atmos. Pollut. Res. 2017, 8, 465–473. [Google Scholar] [CrossRef]
- Chen, L.J.; Ho, Y.H.; Lee, H.C.; Wu, H.C.; Liu, H.M.; Hsieh, H.H.; Huang, Y.T.; Lung, S.C. An open framework for participatory PM2.5 monitoring in smart cities. IEEE Access 2017, 5, 14441–14454. [Google Scholar] [CrossRef]
- Tsai, Y.I.; Sopajaree, K.; Kuo, S.C.; Yu, S.P. Potential PM2.5 impacts of festival-related burning and other inputs on air quality in an urban area of southern Taiwan. Sci. Total Environ. 2015, 527, 65–79. [Google Scholar] [CrossRef]
- Chuang, M.T.; Chang, S.C.; Lin, N.H.; Wang, J.L.; Sheu, G.R.; Chang, Y.J.; Lee, C.T. Aerosol chemical properties and related pollutants measured in Dongsha Island in the northern South China Sea during 7-SEAS/Dongsha experiment. Atmos. Environ. 2013, 78, 82–92. [Google Scholar] [CrossRef]
- Yu, H.L.; Chien, L.C.; Yang, C.H. Asian dust storm elevates children’s respiratory health risks: A spatiotemporal analysis of children’s clinic visits across Taipei (Taiwan). PLoS ONE 2012, 7, e41317. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Yu, Y.; Yu, J.; Chen, J.; Niu, Z.; Yin, L.; Zhang, F.; Liao, X.; Chen, Y. Spatial distribution and sources identification of elements in PM2.5 among the coastal city group in the western Taiwan Strait region, China. Sci. Total Environ. 2013, 442, 77–85. [Google Scholar]
- Triantafyllou, A.G.; Kiros, E.S.; Evagelopoulos, V.G. Respirable particulate matter at an urban and nearby industrial location: Concentrations and variability and synoptic weather conditions during high pollution episodes. J. Air Waste Manag. Assoc. 2002, 52, 287–296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gramsch, E.; Cáceres, D.; Oyola, P.; Reyes, F.; Vásquez, Y.; Rubio, M.A.; Sánchez, G. Influence of surface and subsidence thermal inversion on PM2.5 and black carbon concentration. Atmos. Environ. 2014, 98, 290–298. [Google Scholar] [CrossRef]
- Wallace, J.; Kanaroglou, P. The effect of temperature inversions on ground-level nitrogen dioxide (NO2) and fine particulate matter (PM2.5) using temperature profiles from the Atmospheric Infrared Sounder (AIRS). Sci. Total Environ. 2009, 407, 5085–5095. [Google Scholar] [CrossRef]
- Tran, H.N.Q.; Mölders, N. Investigations on meteorological conditions for elevated PM2.5 in Fairbanks, Alaska. Atmos. Res. 2011, 99, 39–49. [Google Scholar] [CrossRef]
- Vlachogianni, A.; Kassomenos, P.; Karppinen, A.; Karakitsios, S.; Kukkonen, J. Evaluation of a multiple regression model for the forecasting of the concentrations of NOx and PM10 in Athens and Helsinki. Sci. Total Environ. 2011, 409, 1559–1571. [Google Scholar] [CrossRef] [PubMed]
- Moisan, S.; Herrera, R.; Clements, A. A dynamic multiple equation approach for forecasting PM2.5 pollution in Santiago, Chile. Int. J. Forecast. 2018, 34, 566–581. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Liu, P.; Sun, X.; Zhang, C.; Wang, M.; Xu, J.; Pu, S.; Huang, L. Application of an advanced spatiotemporal model for PM2.5 prediction in Jiangsu Province, China. Chemosphere 2020, 246, 125563. [Google Scholar] [CrossRef] [PubMed]
- Cobourn, W.G. An enhanced PM2.5 air quality forecast model based on nonlinear regression and back-trajectory concentrations. Atmos. Environ. 2010, 44, 3015–3023. [Google Scholar] [CrossRef]
- Baker, K.R.; Foley, K.M. A nonlinear regression model estimating single source concentrations of primary and secondarily formed PM2.5. Atmos. Environ. 2011, 45, 3758–3767. [Google Scholar] [CrossRef]
- Yin, Q.; Wang, J.; Hu, M.; Wong, H. Estimation of daily PM2.5 concentration and its relationship with meteorological conditions in Beijing. J. Environ. Sci. 2016, 48, 161–168. [Google Scholar] [CrossRef]
- Ni, X.Y.; Huang, H.; Du, W.P. Relevance analysis and short-term prediction of PM2.5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Qin, Z.; Zhang, G. A novel hybrid-Garch model based on ARIMA and SVM for PM2.5 concentrations forecasting. Atmos. Pollut. Res. 2017, 8, 850–860. [Google Scholar] [CrossRef]
- Mogollón-Sotelo, C.; Casallas, A.; Vidal, S. A support vector machine model to forecast ground-level PM2.5 in a highly populated city with a complex terrain. Air Qual. Atmos. Health 2021, 14, 399–409. [Google Scholar] [CrossRef]
- Liu, W.; Guo, G.; Chen, F.; Chen, Y. Meteorological pattern analysis assisted daily PM2.5 grades prediction using SVM optimized by PSO algorithm. Atmos. Pollut. Res. 2019, 10, 1482–1491. [Google Scholar] [CrossRef]
- Mao, X.; Shen, T.; Feng, X. Prediction of hourly ground level PM2.5 concentrations 3 days in advance using neural networks with satellite data in eastern China. Atmos. Pollut. Res. 2017, 8, 1005–1015. [Google Scholar] [CrossRef]
- Di, Q.; Amini, H.; Shi, L.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapusting, A.; et al. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 2019, 130, 104909. [Google Scholar] [CrossRef]
- Xiao, F.; Yang, M.; Fan, H.; Fan, G.; Al-qaness, M.A.A. An improved deep learning model for predicting daily PM2.5 concentration. Sci. Rep. 2020, 10, 20988. [Google Scholar] [CrossRef] [PubMed]
- Qin, D.; Yun, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A novel combined prediction scheme based on CNN and LSTM for urban PM25 concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Zhang, B.; Li, X.; Zhao, Y.; Li, Y.; Wang, X. Air quality PM2.5 prediction based on multi-model fusion. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth & Brooks/Cole Advanced Books & Software: Monterey, CA, USA, 1984. [Google Scholar]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1681. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Clerc, M.; Kennedy, J. The particle swarm explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2017 | 2018 | 2019 | ||||
|---|---|---|---|---|---|---|
| CART | CNN | CART | CNN | CART | CNN | |
| TP | 10 | 11 | 10 | 6 | 9 | 7 |
| FP | 0 | 2 | 2 | 1 | 0 | 1 |
| TN | 9 | 7 | 9 | 10 | 12 | 12 |
| FN | 5 | 4 | 3 | 7 | 3 | 4 |
| Precision | 1.00 | 0.85 | 0.83 | 0.86 | 1.00 | 0.88 |
| Recall | 0.67 | 0.73 | 0.77 | 0.46 | 0.75 | 0.64 |
| Accuracy | 0.79 | 0.75 | 0.79 | 0.67 | 0.88 | 0.79 |
| F1-Score | 0.80 | 0.79 | 0.80 | 0.60 | 0.86 | 0.74 |
| Expert | CART | CNN | AllNormal | AllTemp | ||
|---|---|---|---|---|---|---|
| 2017 | RMSE | 16.42 | 16.13 | 16.32 | 16.37 | 16.23 |
| MAE | 12.36 | 12.29 | 12.34 | 12.35 | 12.4 | |
| 2018 | RMSE | 9.01 | 9.21 | 9.74 | 10.37 | 11.97 |
| MAE | 6.56 | 6.88 | 6.87 | 7.34 | 8.58 | |
| 2019 | RMSE | 7.8 | 8.59 | 8.59 | 8.95 | 9.7 |
| MAE | 6.05 | 6.48 | 6.74 | 6.77 | 7.21 |
| Expert | CART | CNN | AllNormal | AllTemp | ||
|---|---|---|---|---|---|---|
| 2017 | RMSE | 15.68 | 15.63 | 15.18 | 16.02 | 16.08 |
| MAE | 11.78 | 11.77 | 11.39 | 11.89 | 12.14 | |
| 2018 | RMSE | 8.74 | 8.99 | 9.22 | 10.52 | 11.59 |
| MAE | 6.65 | 6.87 | 6.61 | 7.77 | 8.44 | |
| 2019 | RMSE | 7.77 | 8.64 | 8.61 | 9.32 | 8.92 |
| MAE | 5.93 | 6.55 | 6.73 | 7.05 | 7.21 |
| Expert | CART | CNN | AllNormal | AllTemp | ||
|---|---|---|---|---|---|---|
| 2017 | RMSE | 15.01 | 14.97 | 14.01 | 15.32 | 16.63 |
| MAE | 11.42 | 11.56 | 10.63 | 11.43 | 13.08 | |
| 2018 | RMSE | 7.68 | 8.18 | 8.34 | 8.92 | 11.24 |
| MAE | 6.33 | 6.66 | 7.09 | 7.16 | 8.64 | |
| 2019 | RMSE | 7.65 | 7.74 | 7.56 | 8.32 | 8.45 |
| MAE | 5.8 | 6.27 | 6.89 | 6.78 | 6.85 |
| Hour | Puli PM2.5 | Lunbei PM2.5 | Wind Speed | Wind Direction |
|---|---|---|---|---|
| 0 | 51 | 68 | 0.0 | 0 |
| 1 | 53 | 76 | 0.6 | 39 |
| 2 | 48 | 79 | 0.9 | 67 |
| 3 | 46 | 90 | 0.3 | 112 |
| 4 | 44 | 88 | 1.2 | 117 |
| 5 | 41 | 91 | 1.2 | 126 |
| 6 | 41 | 93 | 0.0 | 0 |
| 7 | 44 | 100 | 0.0 | 0 |
| 8 | 46 | 114 | 0.4 | 76 |
| 9 | 48 | 119 | 1.0 | 69 |
| 10 | 56 | 118 | 0.9 | 183 |
| 11 | 53 | 103 | 2.2 | 167 |
| 12 | 46 | 84 | 2.0 | 204 |
| 13 | 41 | 75 | 2.5 | 311 |
| 14 | 33 | 94 | 2.4 | 316 |
| 15 | 33 | 85 | 1.8 | 341 |
| 16 | 54 | 62 | 3.1 | 20 |
| 17 | 96 | 27 | 2.7 | 1 |
| 18 | 123 | 19 | 3.3 | 6 |
| 19 | 126 | 22 | 4.0 | 17 |
| 20 | 127 | 18 | 3.6 | 14 |
| 21 | 127 | 12 | 4.1 | 19 |
| 22 | 124 | 16 | 3.6 | 19 |
| 23 | 116 | 12 | 2.8 | 31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, P.-Y.; Chang, R.-I.; Day, R.-F.; Lin, Y.-C.; Hu, C.-Y. Improving PM2.5 Concentration Forecast with the Identification of Temperature Inversion. Appl. Sci. 2022, 12, 71. https://doi.org/10.3390/app12010071
Yin P-Y, Chang R-I, Day R-F, Lin Y-C, Hu C-Y. Improving PM2.5 Concentration Forecast with the Identification of Temperature Inversion. Applied Sciences. 2022; 12(1):71. https://doi.org/10.3390/app12010071
Chicago/Turabian StyleYin, Peng-Yeng, Ray-I Chang, Rong-Fuh Day, Yen-Cheng Lin, and Ching-Yuan Hu. 2022. "Improving PM2.5 Concentration Forecast with the Identification of Temperature Inversion" Applied Sciences 12, no. 1: 71. https://doi.org/10.3390/app12010071