1. Introduction
Person re-identification refers to identifying a pedestrian of interest based on external information or characteristics of walking from a number of people captured in single or multi-camera environments. It is being regarded as an essential technique for the intelligent video surveillance systems such as tracking offenders or searching for missing persons [
1,
2]. Recent person re-identification methods use deep neural network to transform the person images of both a query and a gallery set into feature embedding. Then, the similarity between the feature embedding of the query and the ones in the gallery set is estimated to verify the identity of person of interest by selecting similar images from the gallery set.
However, in an actual environment, the identity of a person can be easily confused depending on the differences in the captured time, place, or viewpoint. Because a large difference in appearance of person such as an appearing color, pattern of clothing, belongings, or exposed skin such as face, arms, and legs can be caused by the change of such conditions. Therefore, an intra-class variation that phenomenon of identifying the same person differently or an inter-class variation that phenomenon of identifying the different person as the same can happen easily. Due to such variations, the similarity between the same person can be estimated low, or the similarity between the different person may show high.
As a method to solve such variations, recent studies [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12] have mainly used the following two types of methods. In the first method, a neural network uses additional meta-information such as time, place, and viewpoint at the time of photographing of the pedestrian with a person image [
3,
4]. Although this method has the advantage of improving the person re-identification accuracy, it is difficult to obtain such meta-information automatically from an actual environment. Moreover, additional considerations and resources are required to process acquired information into a data form that can be input into a neural network. Therefore, the second method, which only uses images as input data, has been mainly studied. To obtain the performance close to the first method without additional meta-information, this method utilizes various preprocessing techniques or utilizes a number of auxiliary neural networks or special modules to extract more discernable representative features from the input image while constructing a neural network [
5,
6,
7,
8,
9,
10,
11,
12]. Although this method has an advantage of achieving performance close to the first method, the model can become excessively complicated due to the requirement of several auxiliary neural networks within the neural network or an algorithm in addition to the neural network [
5,
6,
9]. Due to the limitations of the image segmentation method or filter shape used by the existing method, it is difficult to reflect the visual elements of various sizes and shapes appearing in the person image into the feature embedding [
5,
6,
7,
8,
9,
10,
11,
12].
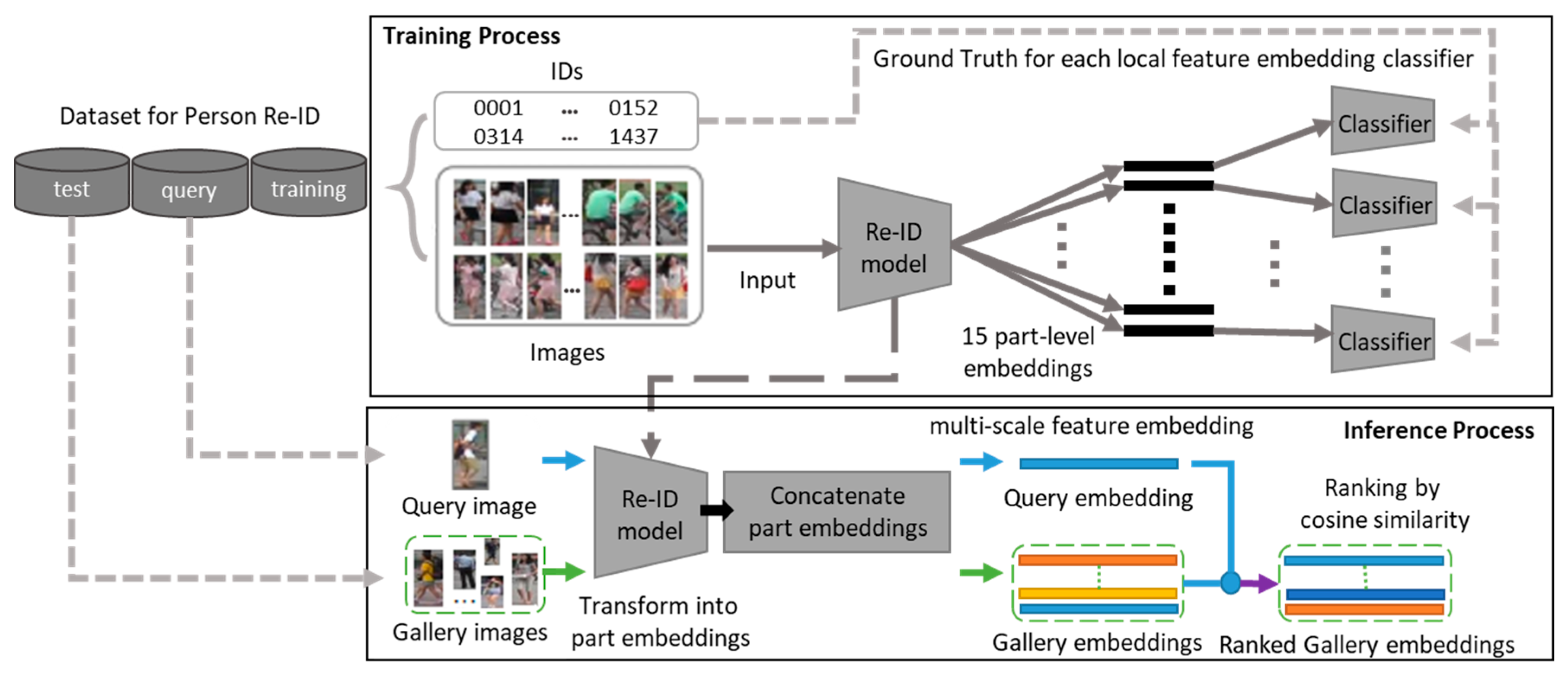
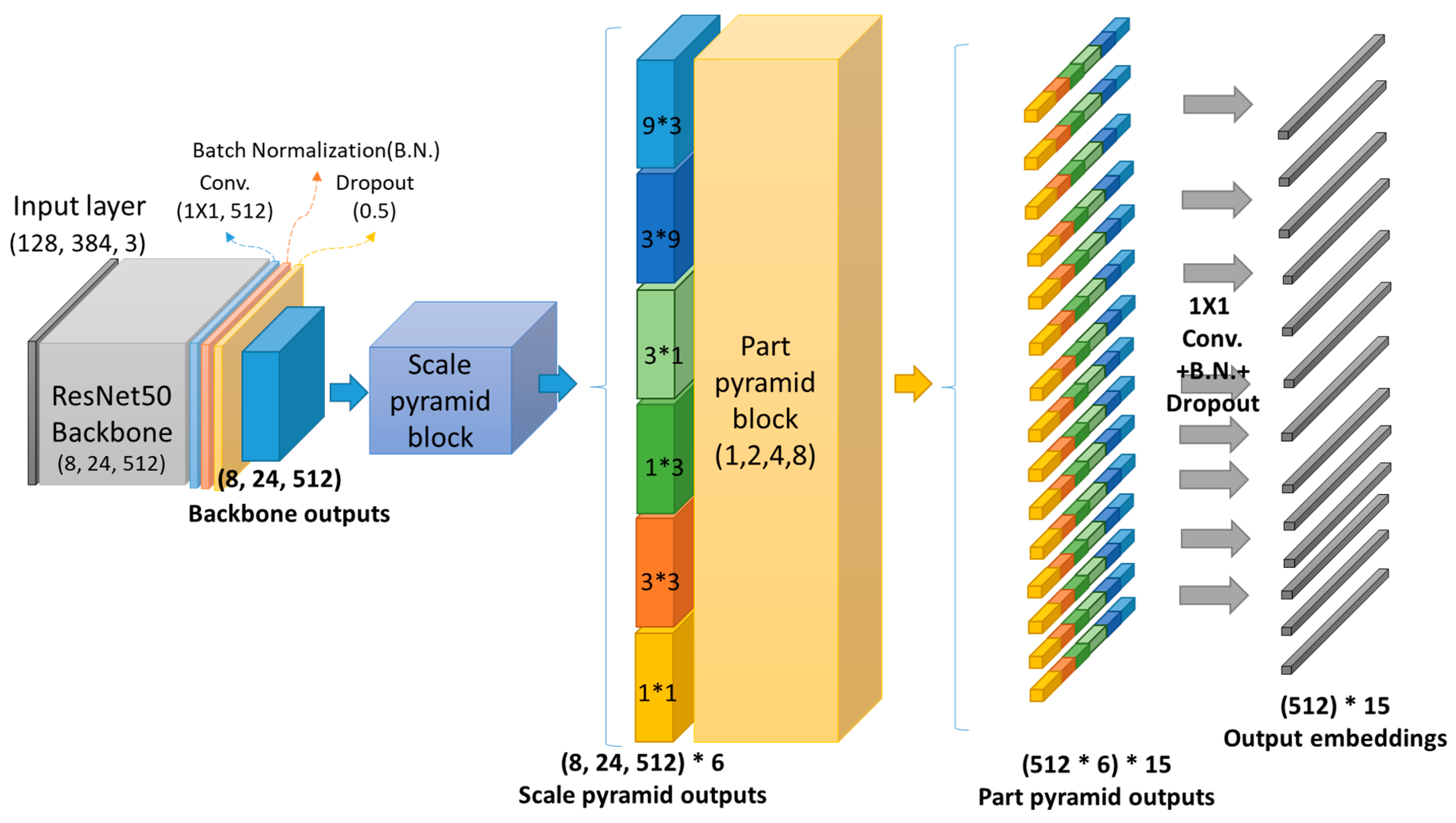
Therefore, in order to enable robust re-identification against the intra/inter-class variations using only the given person images without any other meta-information, a new person re-identification method with dual pyramids that extracts various visual feature elements scattered in various areas of a person image and reflects them in the feature embedding is proposed in this paper. In dual pyramids, a scale pyramid reflects the visual feature elements in various sizes and shapes, and then a part pyramid selects visual feature elements and differently combines them for the feature embedding per each region of the person image. For such purpose, a scale pyramid has different sized kernels that are arranged in serial and parallel fashions, and a part pyramid uses divided and combined feature maps extracted from the scale pyramid to compose feature embedding. Moreover, the proposed model can provide accurate re-identification results using multi-scale features from various regions on the input image.
This paper is structured as follows.
Section 2 introduces the existing studies that performed person re-identification based only on images of persons as related studies. In
Section 3, the novel method for person re-identification proposed in this study is described. The feature embedding extracted from the neural network uses a dual pyramid structure to reflect various sizes and shapes of the visual feature elements shown in the image in the suggested method.
Section 4 shows the experimental results related to each module and corresponding combinations to verify the structural validity of the proposed model and also describes the accuracy of the proposed person re-identification scheme with the publicly available data sets.
Section 5 describes the qualitative and quantitative comparisons of the proposed scheme with other state-of-the-art methods. Finally, the conclusion of this paper and future research is described in
Section 6.
2. Related Work
Existing methods that perform re-identification based only on person images [
5,
6,
7,
8,
9,
10,
11,
12] use neural networks with unique structures to construct more discriminating feature embedding by extracting as much information as possible from the given image. These methods can be classified into two broad categories depending on how the neural network selects the region of an image reflected in the feature embedding. The first method constitutes feature embedding that reflects all visual feature elements that exist in the entire image [
5,
6,
7,
8], and such feature embedding is called the global feature embedding [
5,
6,
7,
8]. Conversely, when multiple feature embedding is formed based on the visual elements of corresponding small area images and the small area images are considered as a combination of multiple area images when given an image, the embedding is referred to as local feature embedding [
9,
10,
11,
12].
First, the neural networks of the studies using global feature embedding [
5,
6,
7,
8] mostly focus on the generation of discriminative feature embedding, which denotes visual elements that are randomly distributed throughout the image. For example, in [
5,
6], the input person images were reconstructed into different sizes. For example, variously sized copies with different resolutions were initially made [
5], or small patch images with various sizes were separated from the pre-determined points of the foreground [
6]. Subsequently, the reconstructed images were provided to the sub-networks that accept inputs suitable for differently sized images and then used to form feature embedding representing the corresponding person. This method has an advantage in that a neural network can extract and utilize a large amount of information from images of various sizes created based on a person image. This leads to exhibition of excellent performance without separate meta-information such as shooting time and location. However, as the sizes of the images used as inputs vary, several neural networks are required to accommodate images of different sizes. For example, two or more InceptionV3 networks [
13] with 23.5 million in weight were used in [
5], and 21 self-designed affiliated neural networks were used in [
6], leading to excessively complex neural networks. In addition, adjusting previously determined resolution [
5] or the separation point of the patches [
6] becomes inevitable when applied to an actual environment for optimal performance. On the other hand, in [
7,
8], only one image was used as an input to the single neural network. Instead of any other preprocessing or auxiliary network, in [
7] a unique module composed of a series of layer sets that consisted of a parallel connection of a series of one or two convolution layers was used, and in [
8] one to four serially connected convolutional layers with kernels sized 3*3 each and arranged in parallel were placed within the neural network to provide a square-shaped receptive field of various sizes and reflect visual feature elements in the feature embedding. However, the important visual feature elements that can be used in identifying the person such as the person’s arms, legs, and feet, clothing or patterns on it, and the person’s belongings are mostly shown as rectangular shapes at various regions of the input image. Therefore, when the receptive fields of a neural network that can be given to the input image are limited to square shapes [
7,
8], properly reflecting visual elements of other shapes such as rectangular shapes with either longer horizontal or vertical direction can be problematic in the input embedding.
Previous studies using the local feature embedding also applied auxiliary network or similar techniques to find areas of body parts as a basic position for feature embedding extraction such as arms, legs, and torso [
9]. However, this method was problematic because the performance of the person re-identification could be greatly varied depending on the body part detection result. Therefore, recent studies [
10,
11,
12] simplified the meaning of a local area as a patch of a horizontally divided person image. The feature map extracted from the backbone such as ResNet50 [
14] or VGG16 [
15] is simply divided horizontally, and each region becomes an origin area of each local feature embedding. Accordingly, previous study [
10] divides the feature map from ResNet50 [
14] backbone into six regions horizontally and construct local feature embeddings representing each region by global average pooling. When each feature embedding is configured on the divided regions with fixed size, the visual feature elements that exist over two or more neighboring regions that are larger than the fixed size are difficult to be reflected in the feature embedding. Therefore, other studies [
11,
12] tried to solve this problem using a so-called feature pyramid. In [
11,
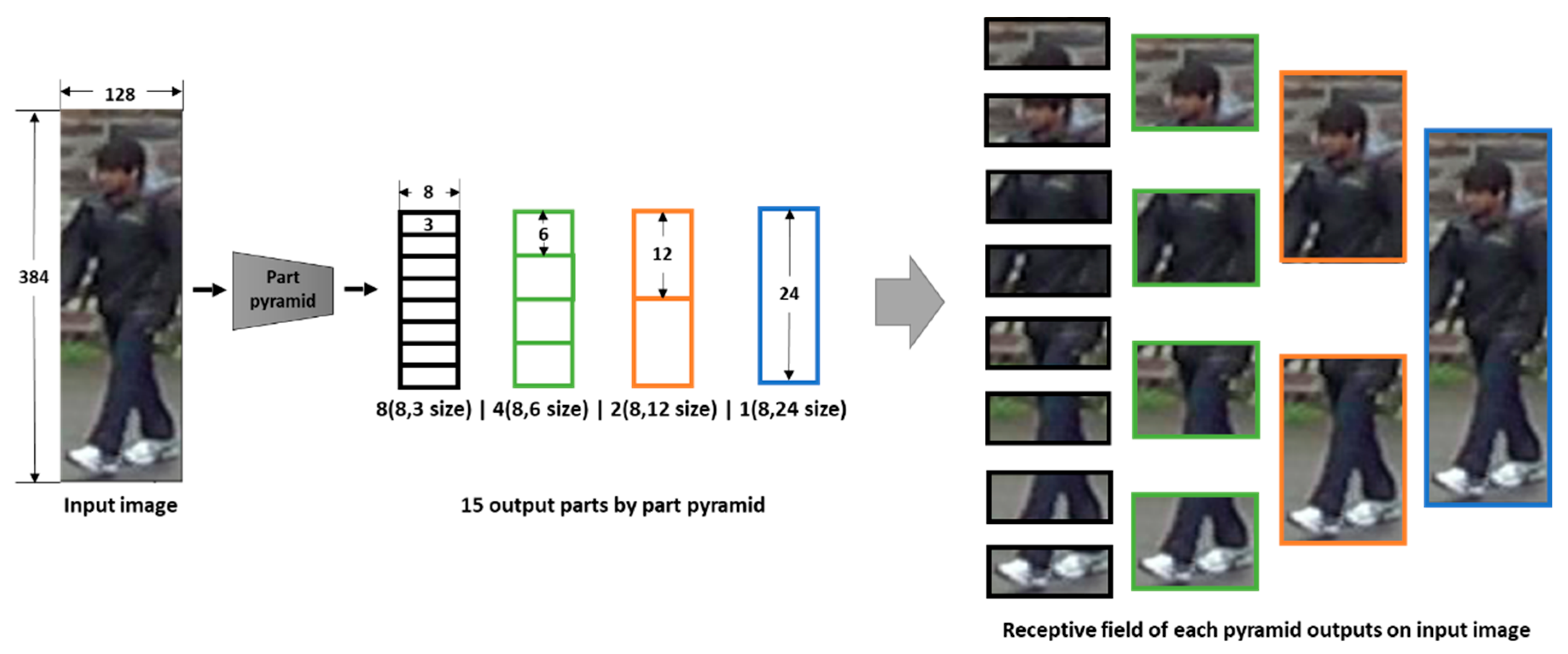
12], a feature pyramid was configured by combining six horizontally divided basic regions first, and then overlapping and tying between the successive neighboring regions, with a total of one to six in each group, creating a total of 21 combined regions. The study [
12] also used a similar feature pyramid, which is configured by combining horizontally divided eight basic regions first, and then tying between the adjacent neighboring regions without overlapping, with a total of eight, four, two, and one in each group to create a total of 15 combined regions. These combined regions are converted into local feature embedding through the adding up of vectors created by global average pooling and global max pooling. However, in the case of constructing a pyramid with multiple combination of regions that overlap each other, each basic region is used to configure multiple combination of the regions. In particular, the basic region located in the center is used more often than the basic regions outside the center region. For this reason, regardless of the actual importance of each basic region, more regions located in the center of the image are more often unconditionally utilized to configure the combination of regions. This is a problem since the crucial visual feature elements such as shoes, hair color, and exposed facial features are difficult to use as important sources. In addition, when the sum of the maximum pooling and the average pooling is used for the construction of the feature embedding, the value in the embedding eventually becomes an ambiguous value rather than an average or maximum, which may result in a deterioration in the discrimination of embedding.
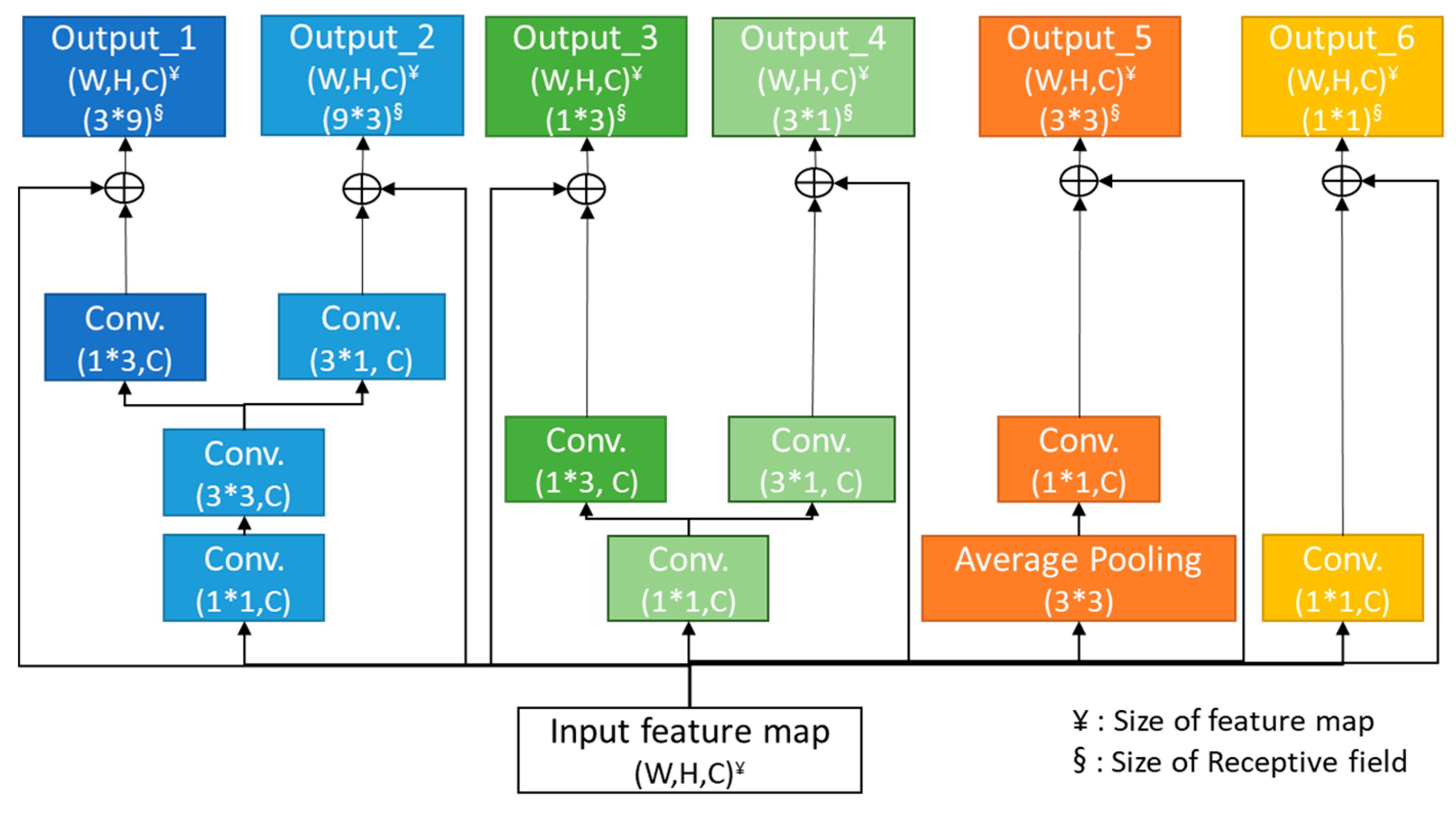
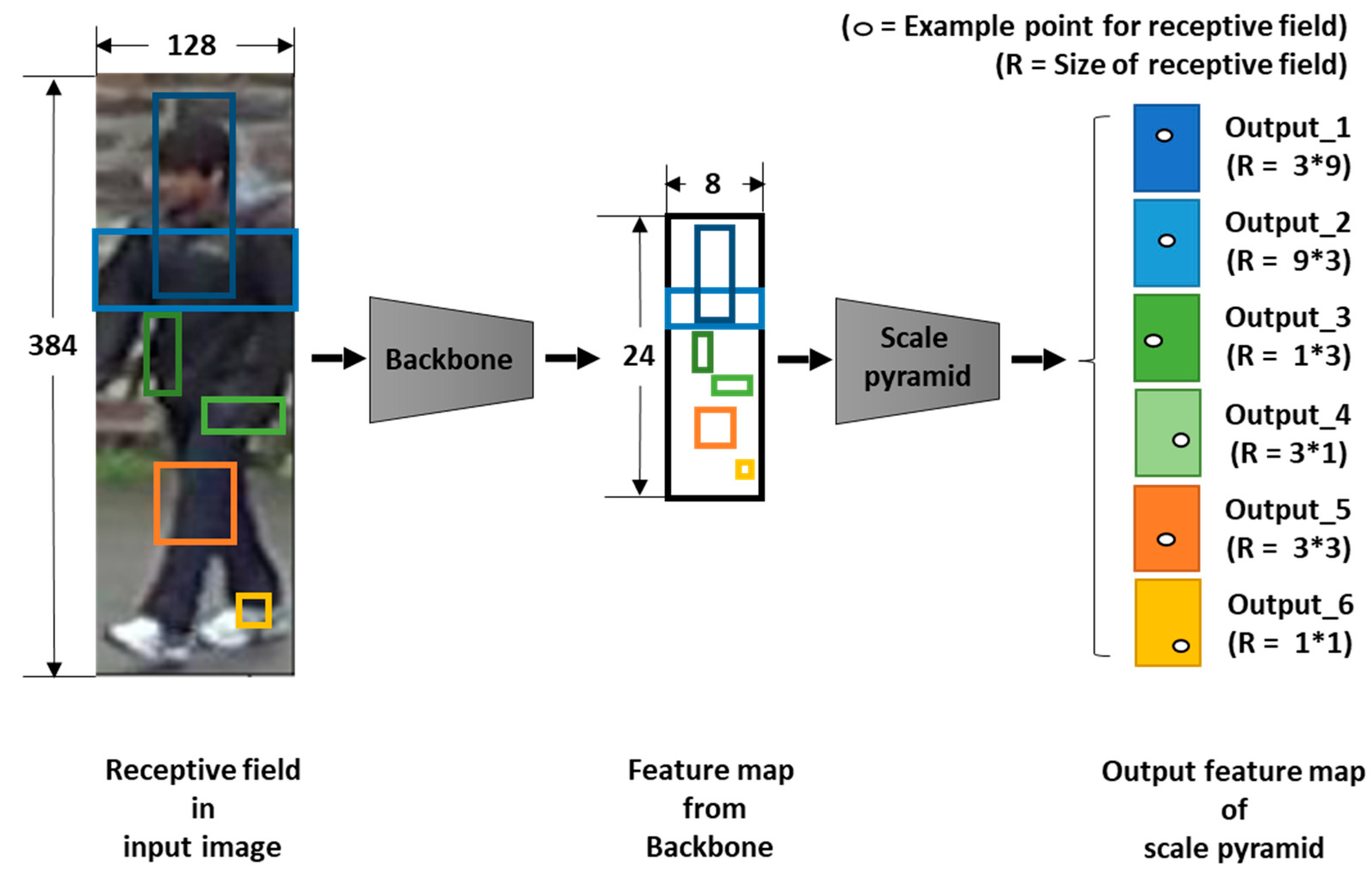
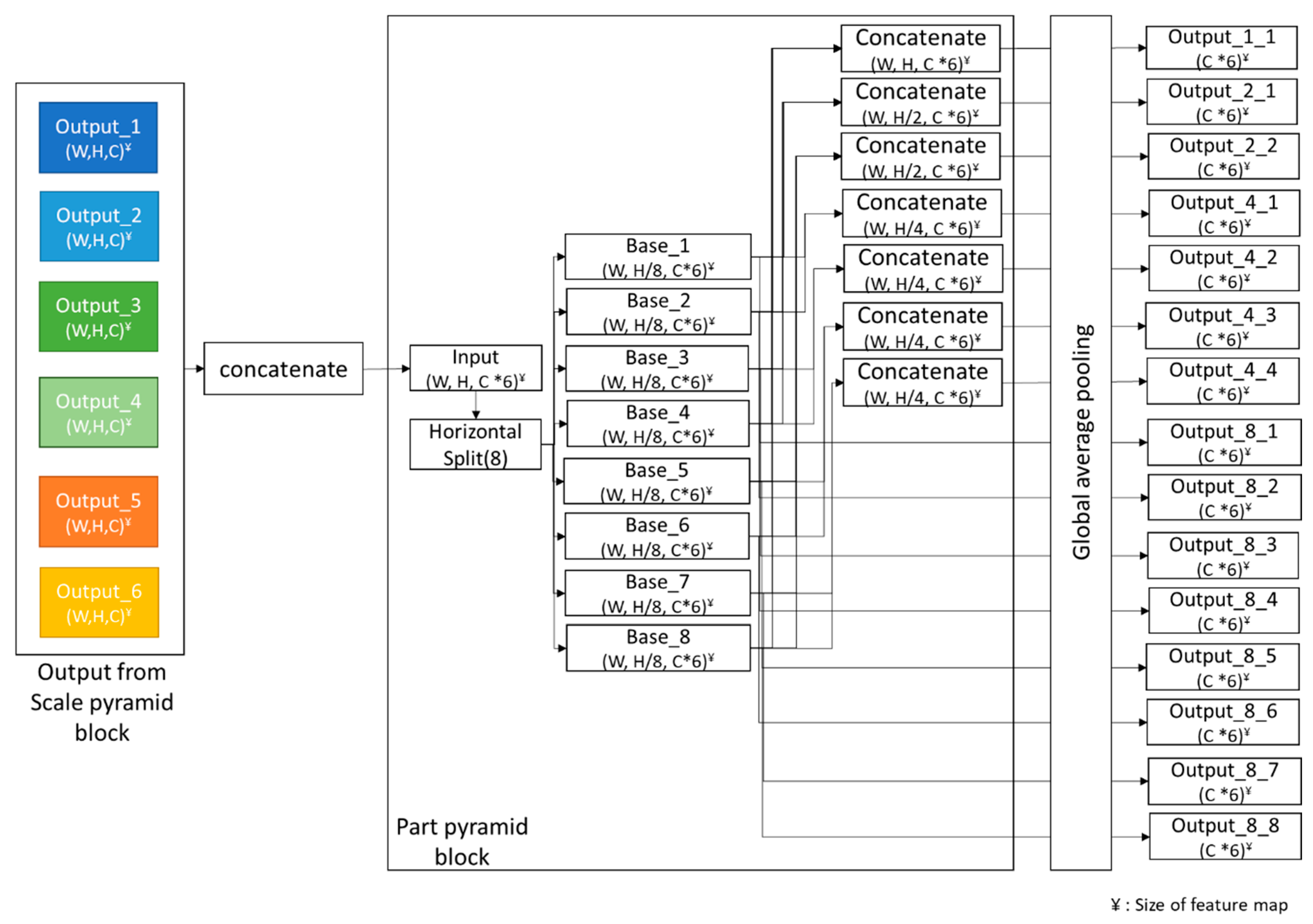
Therefore, this study proposes a person re-identification method that applies a scale pyramid module that allows the neural network to extract visual feature elements that appear in various sizes and shapes in the input person image and a part pyramid module that allows configuration of more accurate feature embedding by appropriately reflecting extracting features according to each region. The scale pyramid module used in the proposed method is designed by connecting the convolutional layers with kernels of different sizes and shapes in series and a parallel manner, so the receptive fields of various sizes including square and rectangular shapes can be acquired from the input image. In addition, to construct discriminative feature embedding that evenly reflects visual feature elements that exist across either narrow or wide areas within the input image, a part pyramid module is horizontally divided into eight segments and then serially connected by regions, a total of eight, four, two, and one in each group, without a mutual overlap to produce a total of 15 regions to configure feature embedding in each region. Each region is converted into local feature embedding by using only global average pooling instead of the complex summation of maximum pooling and average pooling. This proposed method can form the feature embedding that independently reflects the visual feature elements of various sizes and shapes that exist on each region of the input person image. Based on this, preferable person re-identification without additional information on the person can be achieved.
4. Experiment and Analysis
The dataset of DukeMTMC-reID [
18] which is widely used for the development of person re-identification models, was used for this study. The DukeMTMC-reID [
18] dataset composed of the images of 702 persons include 16,522 training images, 17,661 gallery images, and 2228 query images. In addition, the Market-1501 [
19] dataset, which is widely used in the field of person re-identification, was used in the experiment to evaluate the performance of the model and increase the evaluation objectivity by examining the dependency of the model on a specific dataset. The Market-1501 [
19] dataset, which is composed of images of 750 persons, consists of 12,936 learning images, 13,115 gallery images, and 3368 query images.
Prior to the model training, all training images went through the data augmentation process consisting of horizontal flip, random erase, and normalization, and accordingly, 66,088 images for DukeMTMC-reID [
18] and 51,744 images for Market-1501 [
19] were used during actual training. As the ground truth label for each training image, one-hot encoding vector with corresponding ID value set at 1 for the person on a given image and 0 for all others was used in general. The Adam optimization function [
20] was also used during a total of 80 epochs. At this time, the starting training rate was set at 0.001 and was reduced by 0.1-fold for every 30 epochs elapsed. In addition, as the validation data that verified the overfitting status during the training process, randomly selected 6609 images consisting of 10 percent of all training data were utilized. If the calculated validation loss based on the validation data was the smallest, it was saved and used as the weight of the model. Moreover, the zero paddings that filled the remaining part with zero value were set to allow for the inputs during the usage of the kernels by all convolutional layers, and the ReLU [
21] function was allowed for all functions to activate the outputs of the layers for the neural network construction.
As a method to evaluate the performance of the model, the Rank-1 accuracy which decides on the equivalency based on the query image ID and first rank among the gallery embedding that are aligned based on the cosine similarity was used. Because of the special characteristic of the person re-identification among the intelligent video security schemes that require accuracy in identification such as tracking abnormal behaviors or searching for missing persons, the superior accuracy of the Rank-1 identification result is a critical performance indicator of the proposed method.
The first experiment was conducted by switching among ResNet50 [
14], VGG 16 [
15], and SeResnet101 [
22], which were used in by previous person re-identification experiments as the backbone neural network to set the optimal structure of the neural network constituting the re-identification model.
In the experimental results shown in (
Table 1), ResNet50 [
14] showed the best performance among the three backbones. The shallow neural network VGG16 [
15] showed difficulty in constructing the feature embedding that sufficiently reflected the visual elements and discriminated person ID with the neural network. On the other hand, the excessively deep neural network SeResNet101 [
22] showed decreased performance since unnecessary visual elements as well as the valid visual elements were reflected in the feature embedding.
In the second experiment, performance evaluation was conducted by applying different sized pyramids with five configurations composed of the outputs of variously sized receptive fields that included 1*1, 3*3, and 9*9 sized square shapes and 1*3, 3*1, 9*3, and 3*9 sized rectangular shapes on the output feature maps extracted from a backbone as suggested in (
Table 2). In (
Table 2), the receptive field included in each configuration is marked with “O”, and the receptive field that is not included is marked with “X”.
As the results of the experiment, better performance was shown for the cases with both shaped receptive fields instead of the cases with only the square-shaped receptive fields sized (1*1, 3*3) or (1*1, 3*3, 9*9). Moreover, the performance increased with the increased number of available receptive fields and showed optimal performance in the configurations with six outputs sized (1*1, 3*3, 1*3, 3*1, 3*9, 9*3). However, the performance decreased whenever a pyramid branch with a receptive field sized (9*9) was added. It is estimated that a receptive field sized (9*9) with the input feature map sized (8, 24) may be too large to extract local features properly. Through this experiment, it was shown that having shapes of receptive fields close to the visual feature elements that appear in the person image in the neural network in addition to square-shaped receptive fields commonly used in neural networks is more effective in constructing more discerning feature embedding.
In the third experiment, the performance evaluation experiment was conducted on the 15 feature vectors extracted from the part pyramid based on six feature maps from the scale pyramid by changing the composition of the global pooling mechanism for local feature embedding that constitutes the output of part pyramid as suggested in (
Table 3).
As the results of the experiment, better performance was shown for the case with only the global average pooling used compared to only the global max pooling used or the sum of global average pooling and global max pooling used. Especially, the lowest performance was produced when the sum of the global max pooling and global average pooling was used. This can be interpreted as meaning that when these values are used together, the value becomes ambiguous, and the performance may decrease compared to when using each alone.
Therefore, as shown in the previous experiments, the model composed of the scale pyramid with six outputs sized (1*1, 3*3, 1*3, 3*1, 3*9, 9*3) based on the backbone of ResNet50 [
14] and the part pyramid with 15 outputs of 0, 2, 4, and 8 divisions with global average pooling can be said to have the optimal configurations for the person re-identification based on the method proposed in this study. Considering the weight constituting this model is 43 million and the weight of neural networks used as the backbone is 47 million in the model of [
5], the number of auxiliary neural networks is 21 for the model of [
6], and the model of [
10] uses all of ResNet50 [
14] as the backbone and more complex composite local feature embedding than current study, the complexity of the neural networks of the proposed method is considered to be less than or similar to previous studies.
As the final experiment, the proposed model was trained by the datasets of DukeMTMC-reID [
18] and Market-1501 [
19], and the performance of the proposed model was evaluated and showed in (
Table 4).
As the results, the proposed model showed the best performance in terms of the Rank-1 accuracy of 94.79% based on the DukeMTMC-reID [
18] dataset. The excellent performance of 99.25% in terms of the Rank-1 accuracy was also observed with the Market-1501 [
19] dataset. The results suggest that the proposed method can show a robust performance regardless of the shooting environments or the type of person composition of the dataset used for training and evaluation.
5. Discussion
The main aim of this study was to develop a dual pyramid structure with more discriminative feature embedding for a person re-identification. To accurately detect the gallery that is the same as the query, discriminative feature embedding was used, which is the connection of 15 local feature embedding by the proposed scheme using scale and part pyramid structure. According to the analysis of the experimental results in (
Table 5), the performance rates of the proposed scheme based on Rank-1 accuracy are 94.79% and 99.25% for the DukeMTMC-reID [
18] dataset and the Market-1501 [
19] dataset, respectively.
In recent years, many studies have reported high performance in person re-identification using various deep learning approaches [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12]. Among the studies, some used additional meta-information [
3,
4], multi-scale features [
5,
8], or localized features [
10,
11,
12] as useful elements to determine the identity of the person in the image.
To compare the performance results of these approaches, the approaches of [
3] and [
4] with the Rank-1 accuracy rate of 94.0% and 91.61% based on the DukeMTMC-reID [
18] dataset and the Rank-1 accuracy rate of 98.00% and 96.79% based on the Market-1501 [
19] dataset, which is a lower performance than proposed scheme, are shown. These results suggest that only the person image can be used for re-identification without additional meta-information such as shooting time, location, and viewpoint for a comparatively superior performance. The approaches of [
5] and [
8] with the Rank-1 accuracy rate of 79.2% and 88.6% based on the DukeMTMC-reID [
18] dataset and the Rank-1 accuracy rate of 88.9% and 94.8% based on the Market-1501 [
19] dataset are also shown. Moreover, the approaches of [
10], [
11], and [
12] with the Rank-1 accuracy rate of 83.3%, 89.0%, and 86.6% based on the DukeMTMC-reID [
18] dataset and the Rank-1 accuracy rate of 92.3%, 95.7%, and 94.2% based on the Market-1501 [
19] dataset are shown. All of them have a lower performance than the proposed scheme, which suggests that using multi-scale features and localized features together can make better performance than using them separately.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}