Structural Crack Detection and Recognition Based on Deep Learning

Abstract
:1. Introduction
2. Experimental Data Preparation
2.1. Image Acquisition
2.2. Crack Recognition Dataset Build
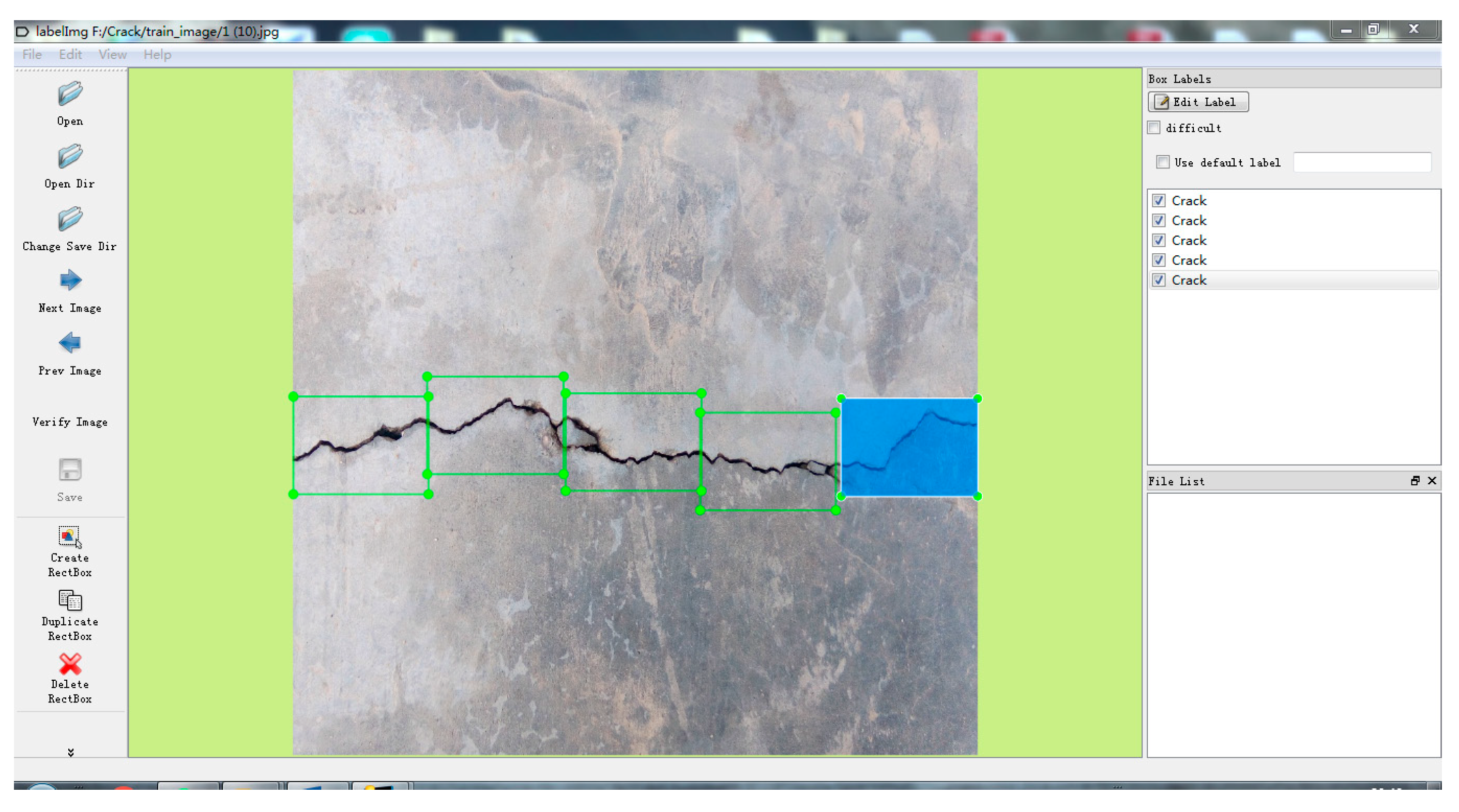
2.3. Crack Detection Dataset Build
3. Crack Recognition Based on Convolutional Neural Network
3.1. Model Building
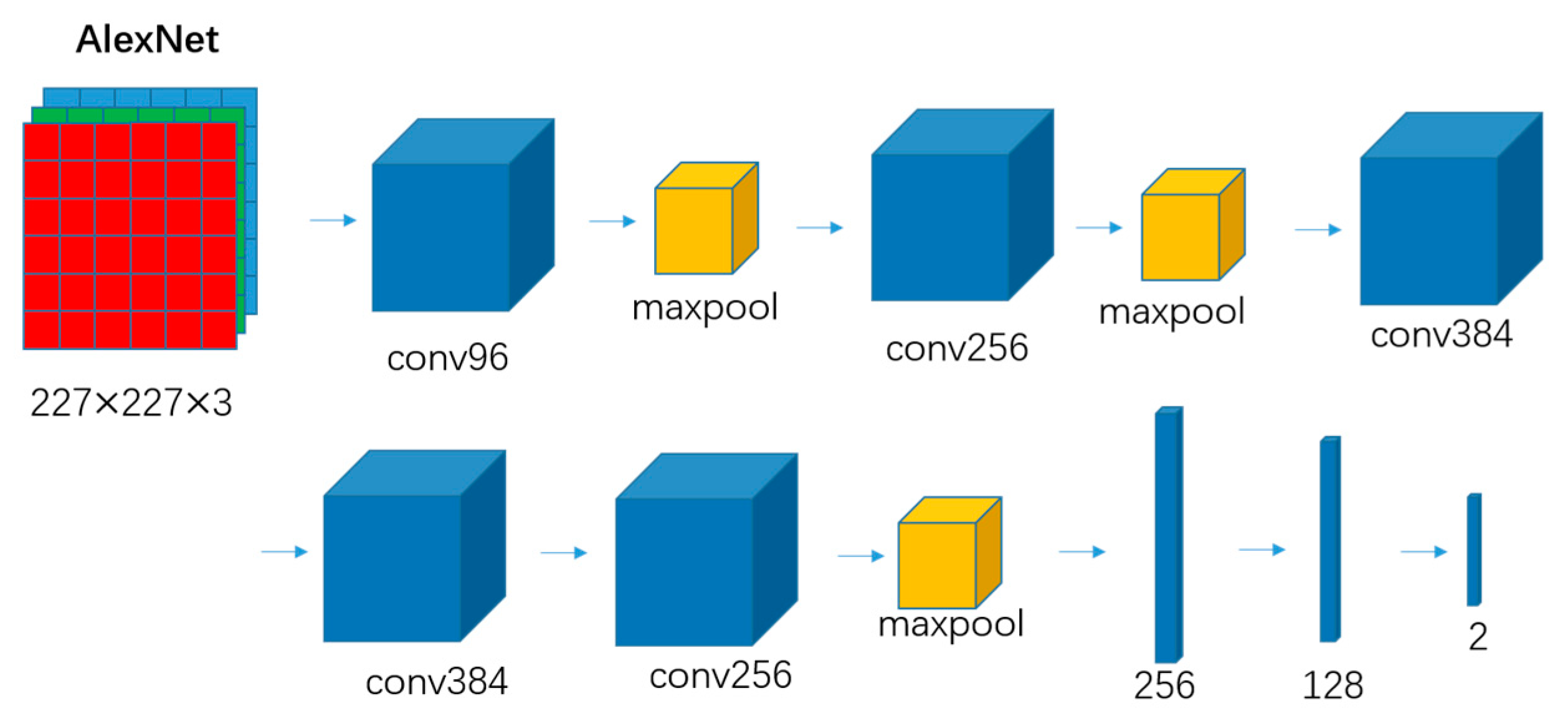
3.1.1. AlexNet Model
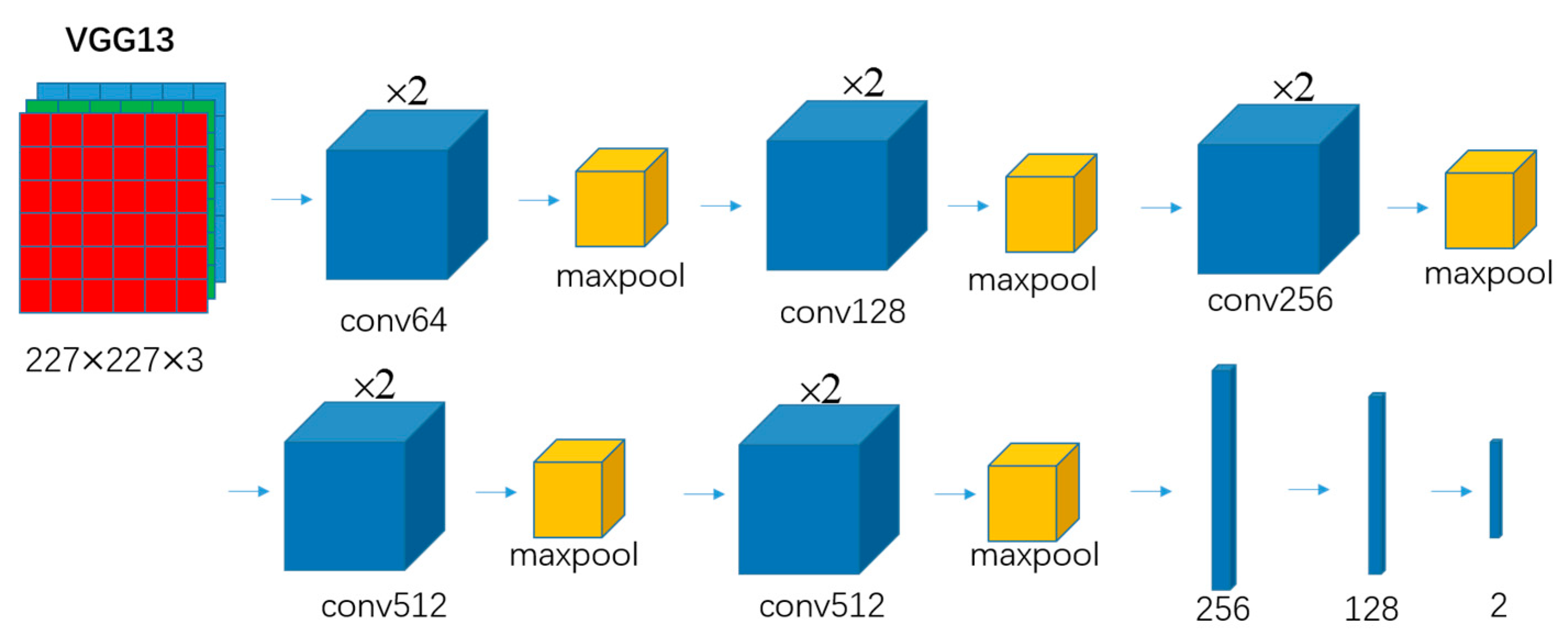
3.1.2. VGGNet13 Model
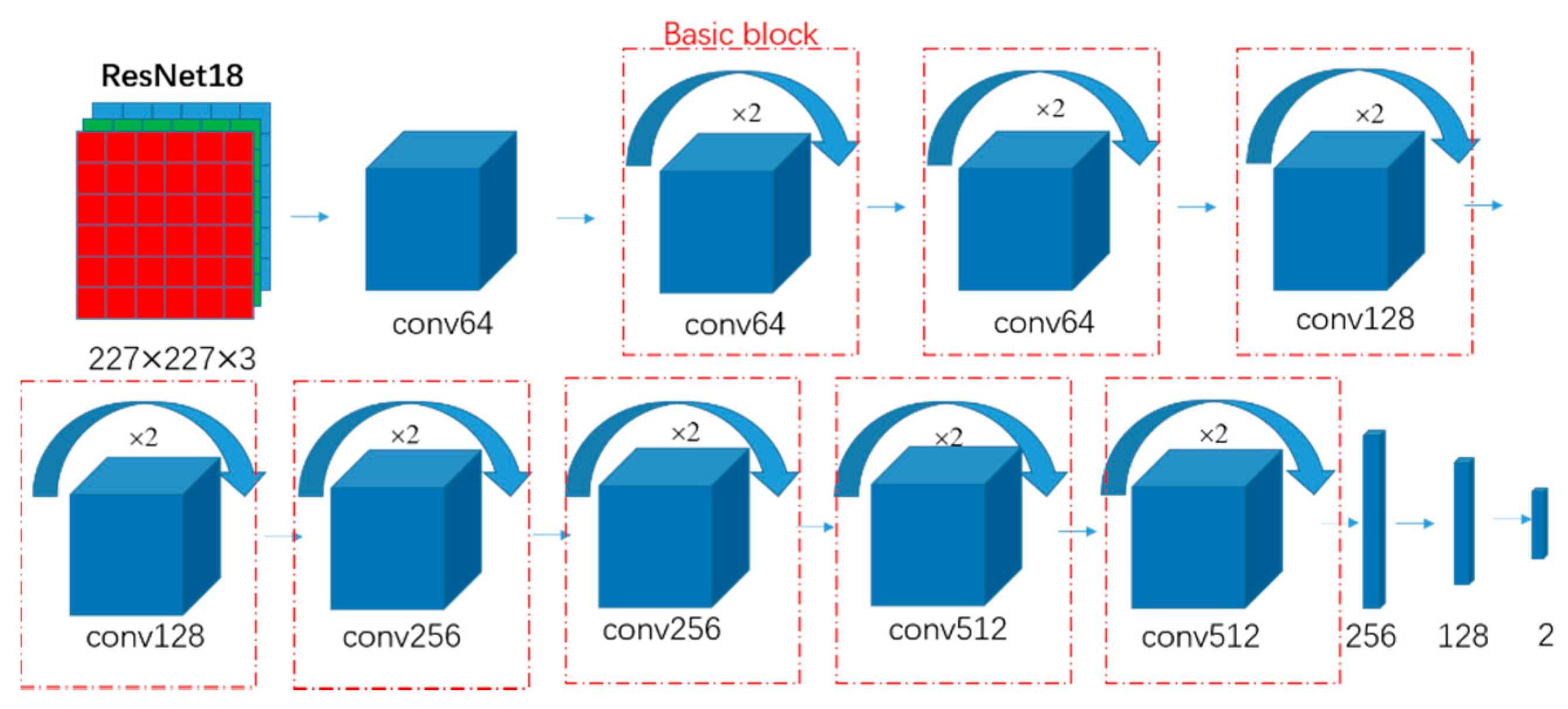
3.1.3. ResNet18 Model
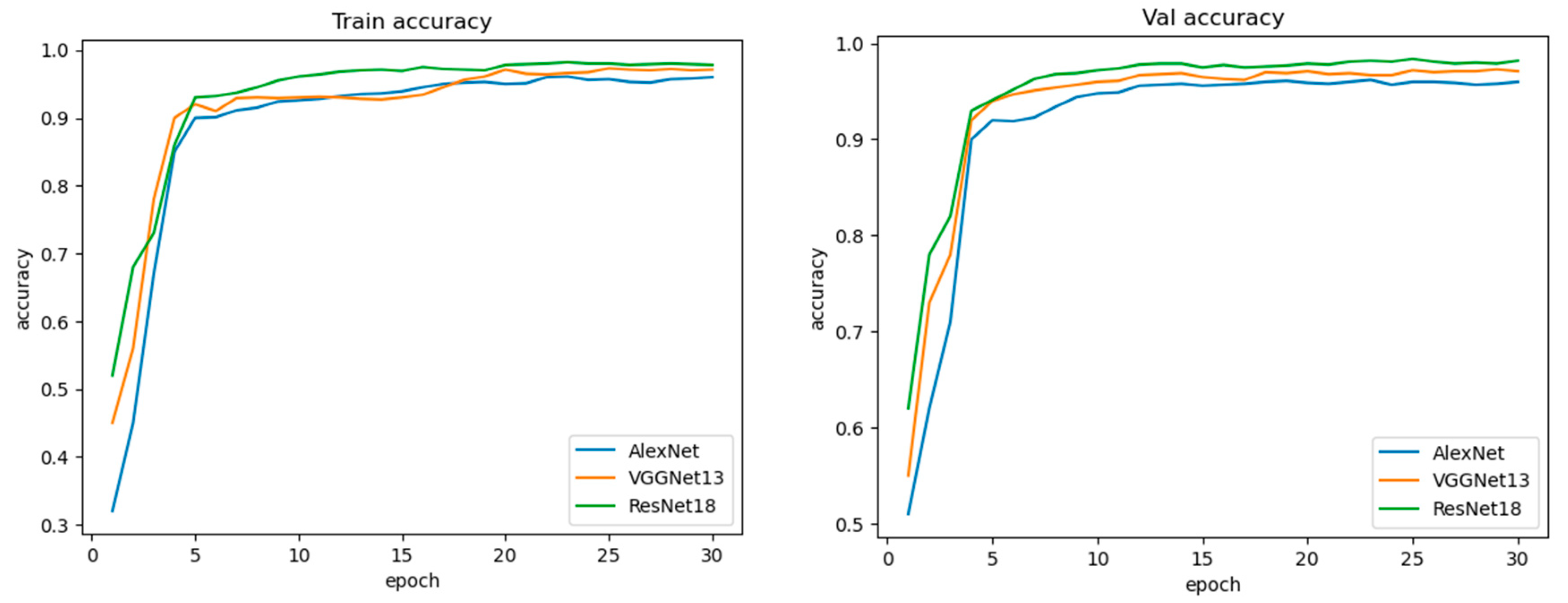
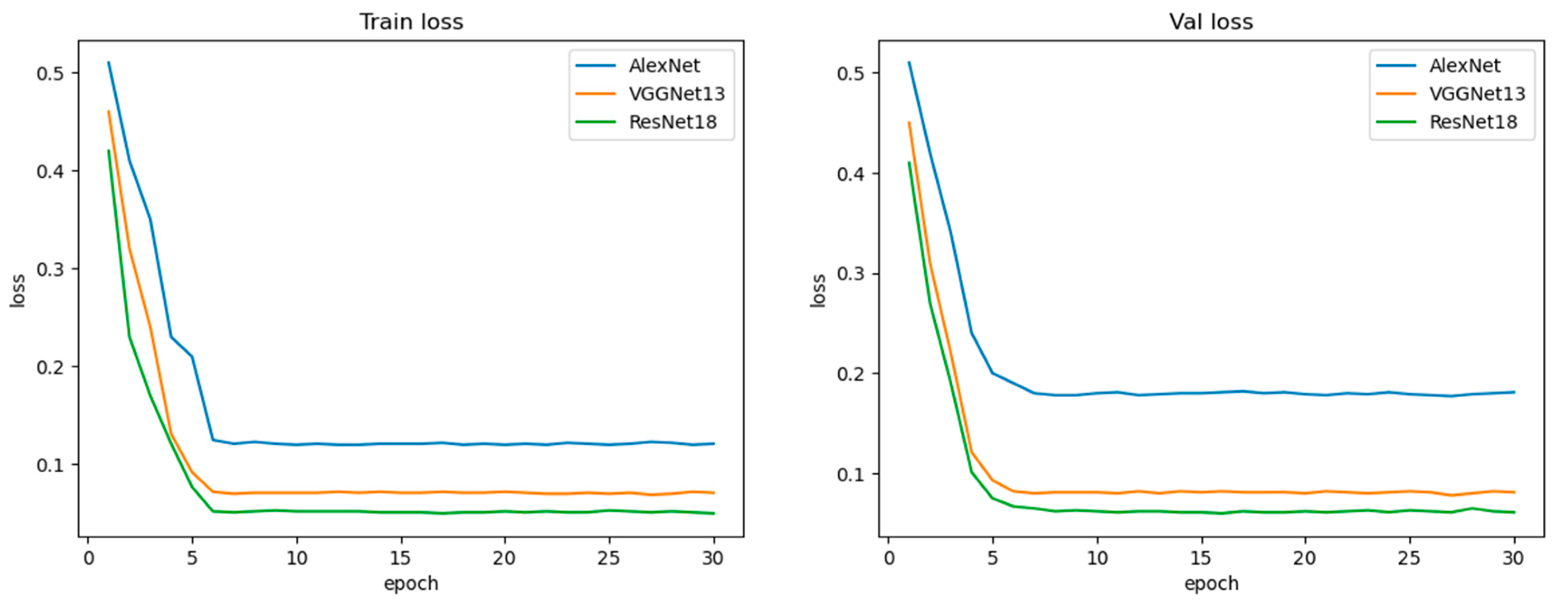
3.2. Experimental Results and Analysis
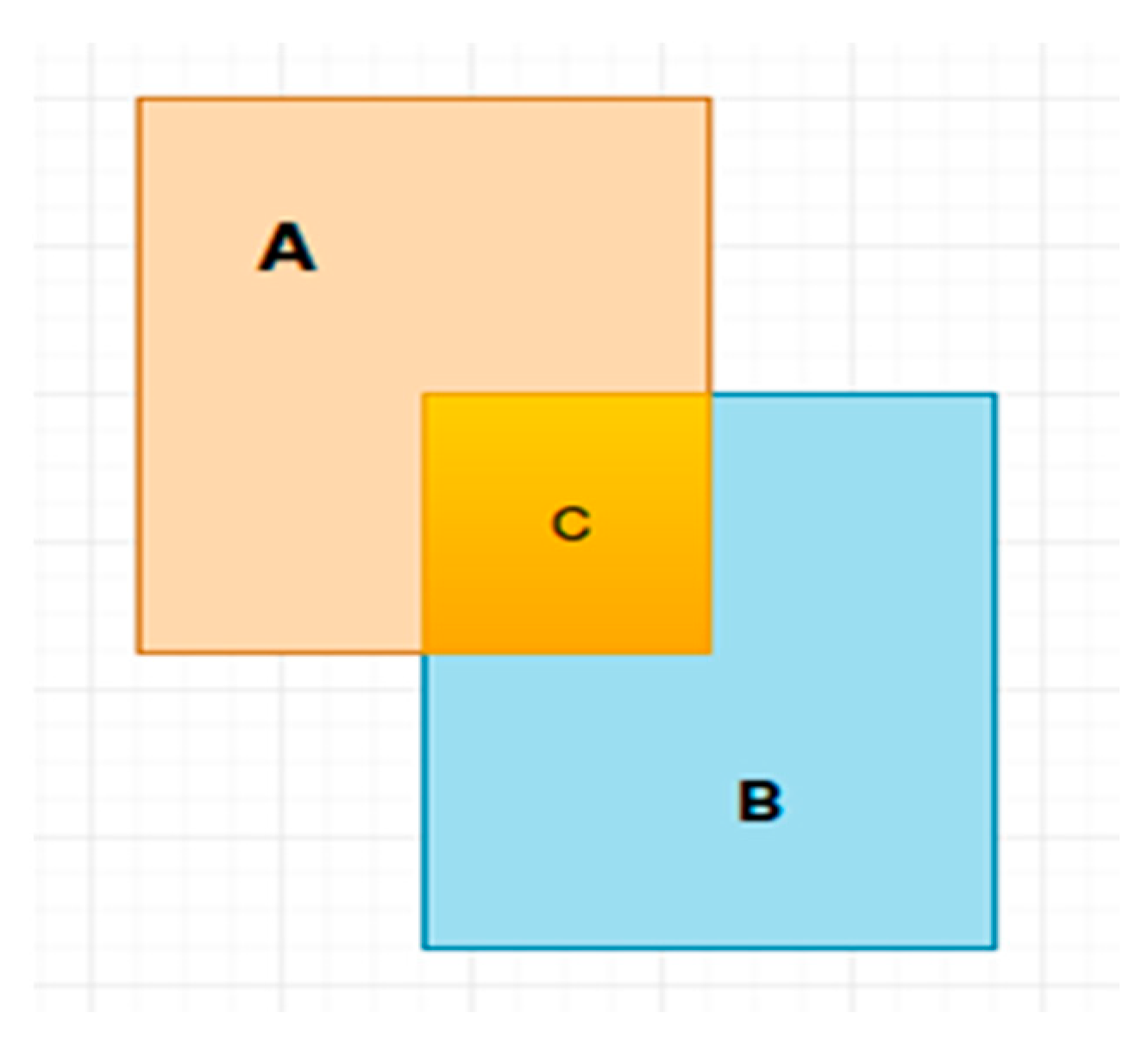
3.3. Evaluation Index
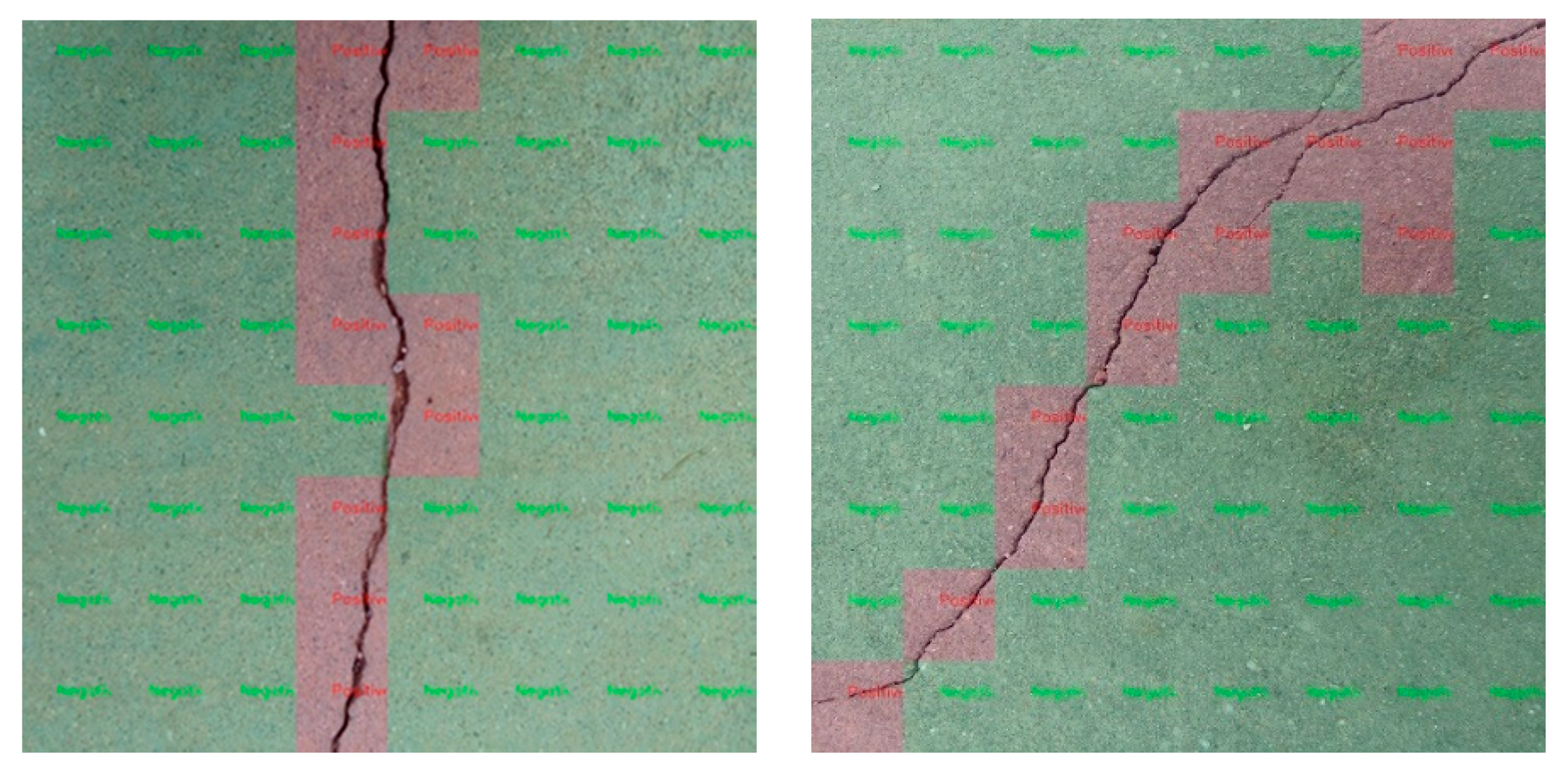
3.4. Real Image Test
4. Crack Detection Based on YOLOv3
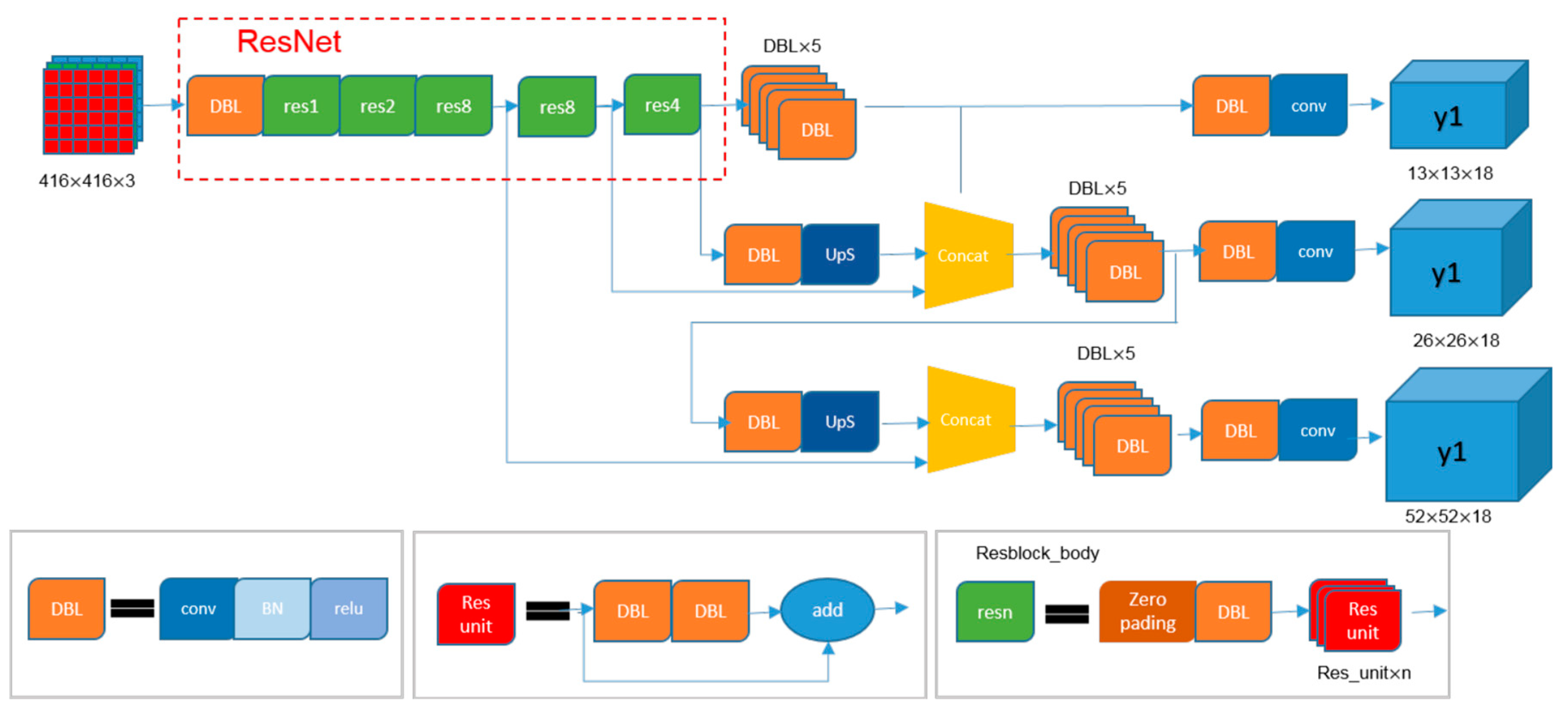
4.1. Model Building
- DBL represents the combination of convolution, BN and leaky ReLU. In YOLOv3, the convolutional layer appears as such components and constitutes the basic unit of DarkNet. The number after DBL indicates that there are several DBL modules.
- Res: Res in the figure represents the residual module, which is essentially a residual network. The number after Res represents several residual modules connected in series.
- Up-sampling: up-sampling uses up-pooling, that is, the method of element replication and expansion makes the feature size expand, and without learning parameters.
- Concat: after up-sampling, the deep and shallow feature maps are subjected to the Concat operation, that is, channel-wise splicing.
- Residual idea: DarkNet-53 draws on ResNet’s residual idea and uses a large number of residual connections in the basic network, so the network structure can be designed very deep, and the gradient can be transmitted farther and relieved when the gradient is back propagated. The problem of gradient disappearance during training is solved, which makes the model easier to converge.
- Multi-layer feature maps: Through up-sampling and Concat operations, deep and shallow features are merged, and finally, feature maps of three sizes are output for subsequent prediction. Multi-layer feature maps have obvious advantages when detecting multi-scale objects or small objects.
- Without the pooling layer: The previous YOLO network has five maximum pooling layers to reduce the size of the feature map, but YOLO v3 down sampling achieves the same effect of reducing the size. The number of down-sampling is also five, and the overall sampling frequency is 32.
4.2. Loss Function
4.3. Evaluation Index
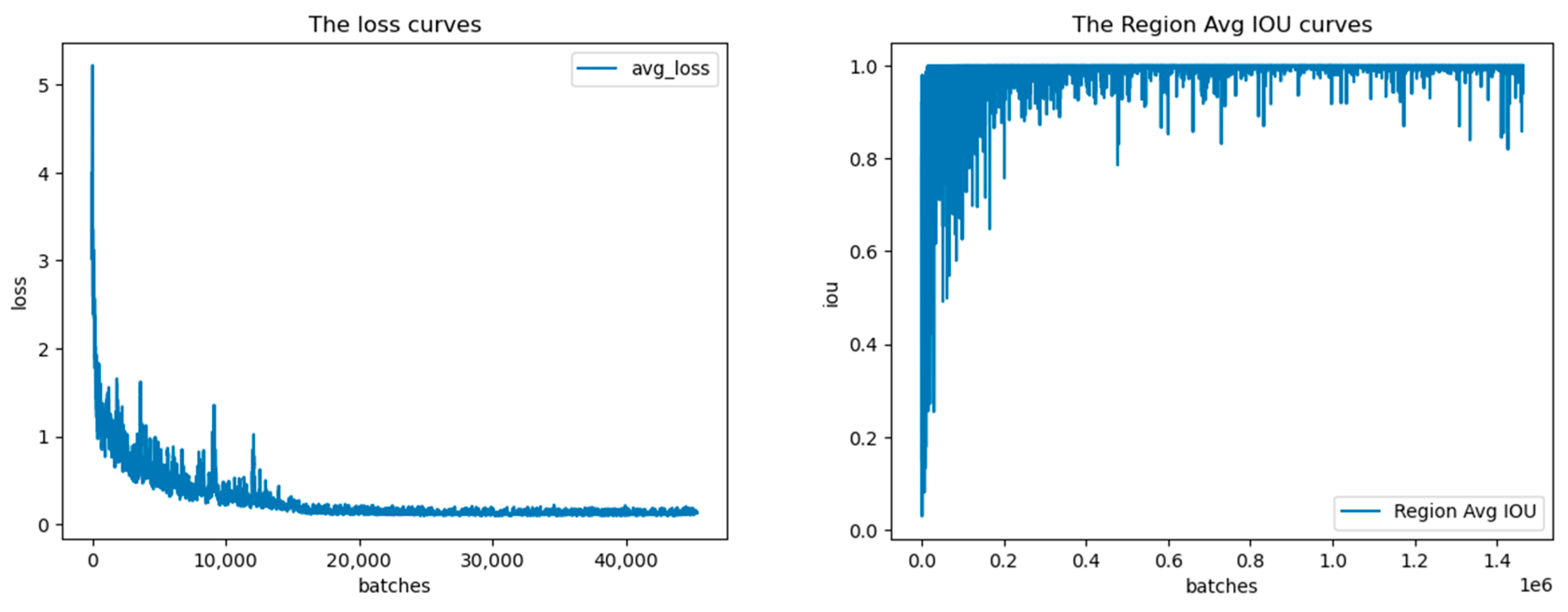
4.4. Experimental Results and Analysis
4.5. Real Image and Video Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Albishi, A.M.; Ramahi, O.M. Surface crack detection in metallic materials using sensitive microwave-based sensors. In Proceedings of the 2016 IEEE Annual Wireless and Microwave Technology Conference, Clearwater, FL, USA, 11–13 April 2016. [Google Scholar]
- Lacidogna, G.; Piana, G.; Accornero, F.; Carpinteri, A. Multi-technique damage monitoring of concrete beams: Acoustic Emission, Digital Image Correlation, Dynamic Identification. Constr. Build. Mater. 2020, 242, 118114. [Google Scholar] [CrossRef]
- Liu, P.; Lim, H.; Yang, S.; Sohn, H. Development of a “stick-and-detect” wireless sensor node for fatigue crack detection. Struct. Health Monit. 2016, 16, 153–163. [Google Scholar] [CrossRef]
- Zhao, S.; Sun, L.; Gao, J.; Wang, J. Uniaxial ACFM detection system for metal crack size estimation using magnetic signature waveform analysis. Measurement 2020, 164, 108090. [Google Scholar] [CrossRef]
- Yang, X.; Zhou, Z. Design of crack detection system. In Proceedings of the 2017 International Conference on Network and Information Systems for Computers, Shanghai, China, 14–16 April 2017. [Google Scholar]
- Zhang, X.; Wang, K.; Wang, Y.; Shen, Y.; Hu, H. Rail crack detection using acoustic emission technique by joint optimization noise clustering and time window feature detection. Appl. Acoust. 2020, 160, 107141. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Jerome, I. Automatic Crack Detection on Two-Dimensional Pavement Images: An Algorithm Based on Minimal Path Selection. Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef] [Green Version]
- Amhaz, R.; Chambon, S.; Jerome, I.; Baltazart, V. A new minimal path selection algorithm for automatic crack detection on pavement images. In Proceedings of the 2014 International Conference on Image Processing, Paris, France, 27–30 January 2014. [Google Scholar]
- Yang, L.C.; Vincent, B.; Rabih, A.; Peilin, J. A new A-star algorithm adapted to the semi-automatic detection of cracks within grey level pavement images. In Proceedings of the 2016 International Conference on Digital Image Processing, Chengdu, China, 20–22 May 2016. [Google Scholar]
- Cheon, M.H.; Hong, D.G.; Lee, D.H. Surface crack detection in concrete structures using image processing. In Proceedings of the 2017 International Conference on Robot Intelligence Technology and Applications, Daejeon, Korea, 14–15 December 2017. [Google Scholar]
- Tedeschi, A.; Benedetto, F. A real-time automatic pavement crack and pothole recognition system for mobile Android-based devices. Adv. Eng. Inform. 2017, 32, 11–25. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhang, H. Research on Surface Crack Detection Technology Based on Digital Image Processing. In Proceedings of the 2019 International Workshop on Advanced Algorithms and Control Engineering, Shenzhen, China, 21–22 February 2020. [Google Scholar]
- Sun, H.; Liu, Q.; Fang, L. Research on Fatigue Crack Growth Detection of M(T) Specimen Based on Image Processing Technology. J. Fail. Anal. Prev. 2018, 18, 1010–1016. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, Y.; Huang, W. Crack junction detection in pavement image using correlation structure analysis and iterative tensor voting. IEEE Access 2019, 7, 138094–138109. [Google Scholar] [CrossRef]
- Li, W.; Ju, H.; Susan, L.; Ren, Q. Three-dimensional pavement crack detection algorithm based on two-dimensional empirical mode decomposition. J. Transp. Eng. Part B Pavements 2017, 143, 2573–5438. [Google Scholar] [CrossRef]
- Wang, S.; Yang, F.; Cheng, Y.; Yang, Y.; Wang, Y. Adaboost-based Crack Detection Method for Pavement. In Proceedings of the 2018 International Conference on Civil and Hydraulic Engineering, Qingdao, China, 23–25 November 2018. [Google Scholar]
- Freund, Y.; Schapire, R. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1996, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Gupta, N.K. A Genetic Approach to Segment and Detect Crack in Rail Track. In Proceedings of the 2019 International Conference on Computing Methodologies and Communication, Erode, India, 27–29 March 2019. [Google Scholar]
- Yusof, N.; Osman, M.; Hussain, Z.; Noor, M. Automated Asphalt Pavement Crack Detection and Classification using Deep Convolution Neural Network. In Proceedings of the 2019 International Conference on Control System, Penang, Malaysia, 29 November–1 December 2019. [Google Scholar]
- Gaith, M.; Sedaghat, A.; Assad, H.; Hiyasat, M. Neural Network usage in structural crack detection. In Proceedings of the 2015 International Conference on Industrial Engineering and Operations Management, Dubai, United Arab Emirates, 3–5 March 2015. [Google Scholar]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the 2012 International Conference on Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 2016 International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, Netherlands, 11–14 October 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 2010 Conference on Computational Statistics, Paris, France, 22–27 August 2010. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Real | Predict | |
|---|---|---|
| I | II | |
| I | TP( True Positive) | FN (False Negative) |
| II | FP (False Positive) | TN (True Negative) |
| Categories | Acc | P | R | |
|---|---|---|---|---|
| AlexNet | 97.6% | 97.9% | 97.3% | 97.6% |
| VGG13 | 98.3% | 98.6% | 98% | 98.3% |
| ResNet18 | 98.8% | 98.9% | 98.6% | 98.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Chen, J.; Li, Z.; Huang, Y. Structural Crack Detection and Recognition Based on Deep Learning. Appl. Sci. 2021, 11, 2868. https://doi.org/10.3390/app11062868
Yang C, Chen J, Li Z, Huang Y. Structural Crack Detection and Recognition Based on Deep Learning. Applied Sciences. 2021; 11(6):2868. https://doi.org/10.3390/app11062868
Chicago/Turabian StyleYang, Cheng, Jingjie Chen, Zhiyuan Li, and Yi Huang. 2021. "Structural Crack Detection and Recognition Based on Deep Learning" Applied Sciences 11, no. 6: 2868. https://doi.org/10.3390/app11062868