
Bayesian Feature Fusion Using Factor Graph in Reduced Normal Form

 ,
, 
 ,
,
Abstract
:1. Introduction
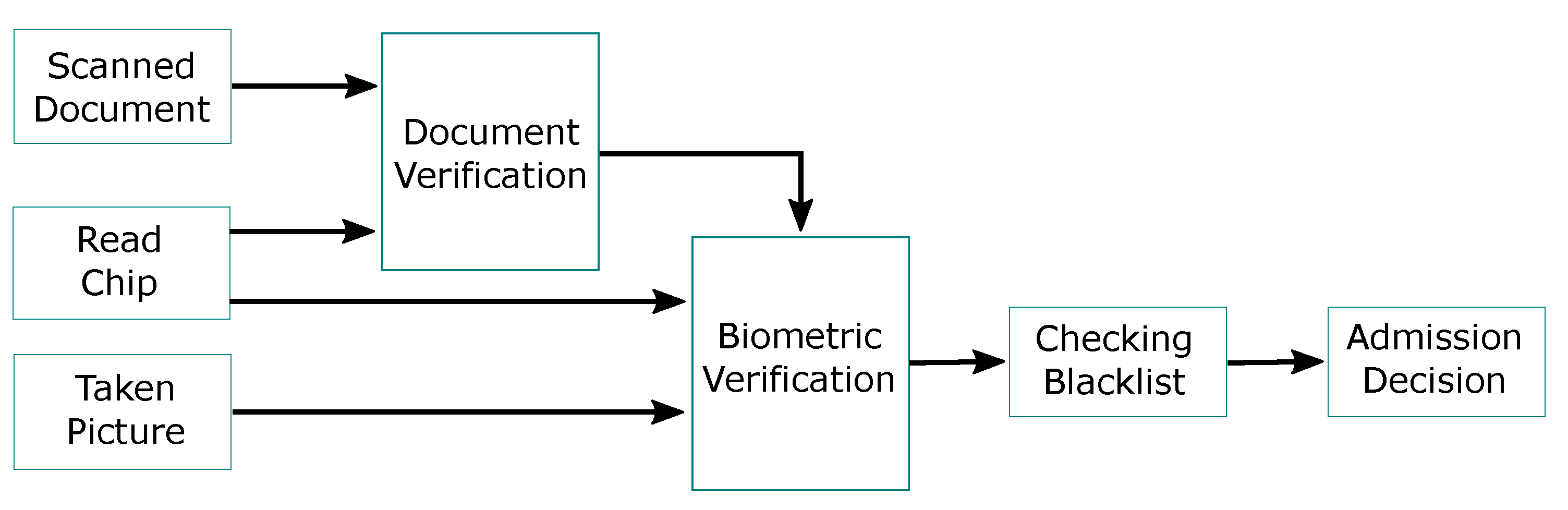
2. Materials and Methods
2.1. Model Architecture
2.1.1. Face Detector
2.1.2. Text Detector
2.1.3. Barcode Detector
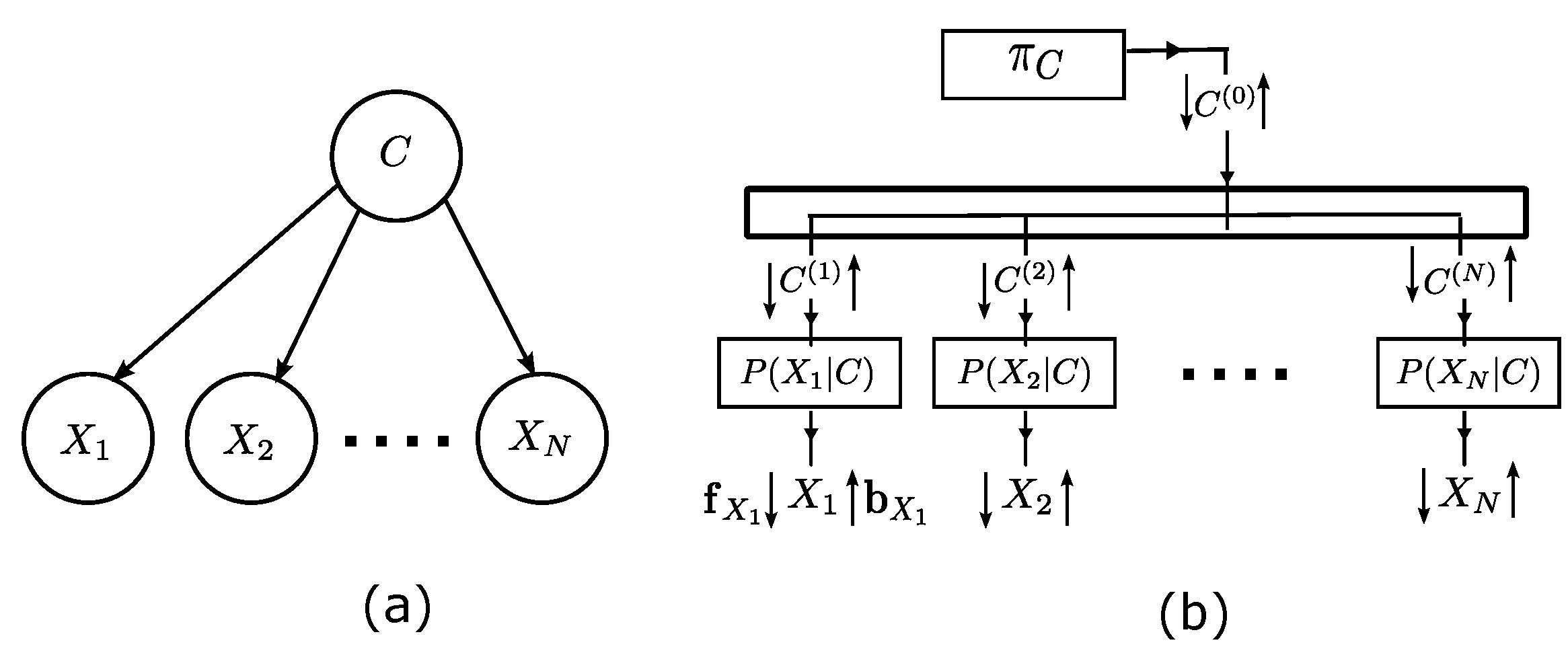
2.2. Feature Fusion Model
 |
2.3. Model Evaluation
2.3.1. Likelihood
2.3.2. Conditional Entropy
2.3.3. Jensen-Shannon Divergence
3. Results
3.1. Dataset Preparation
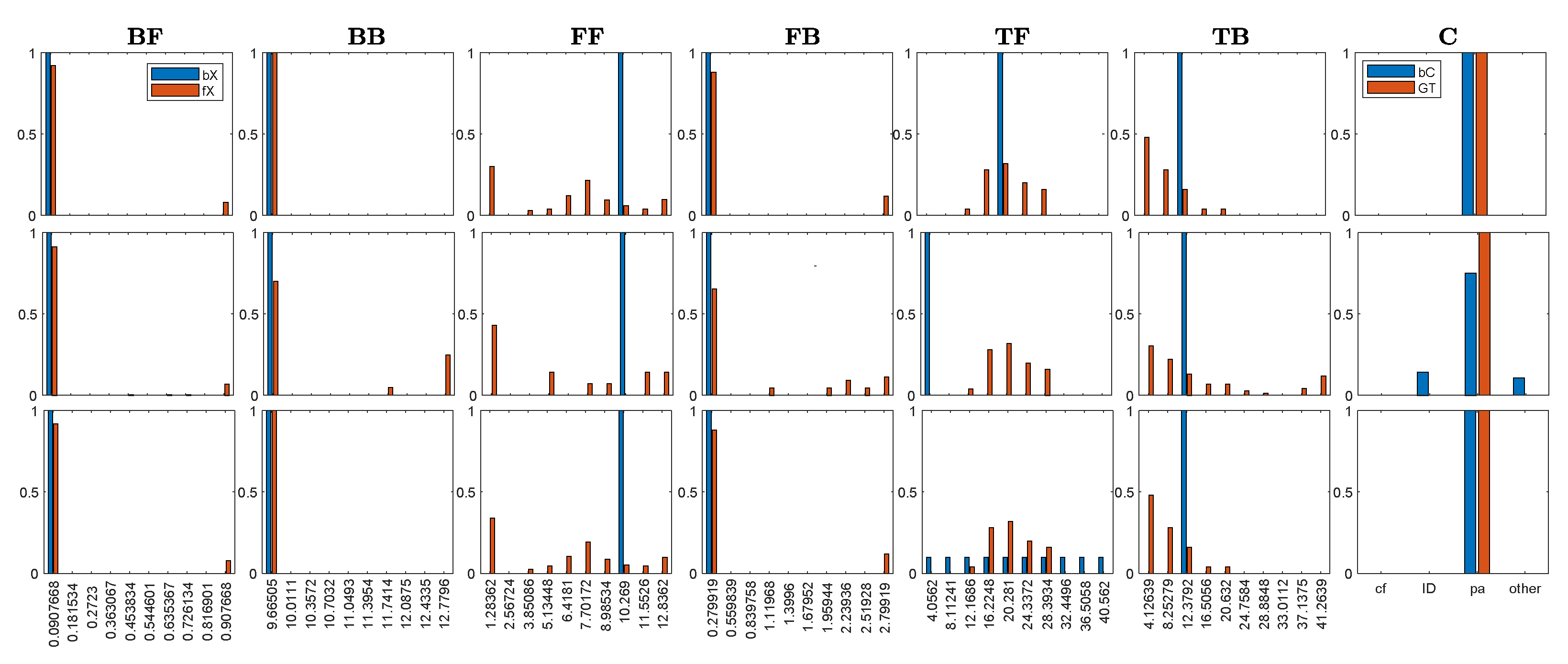
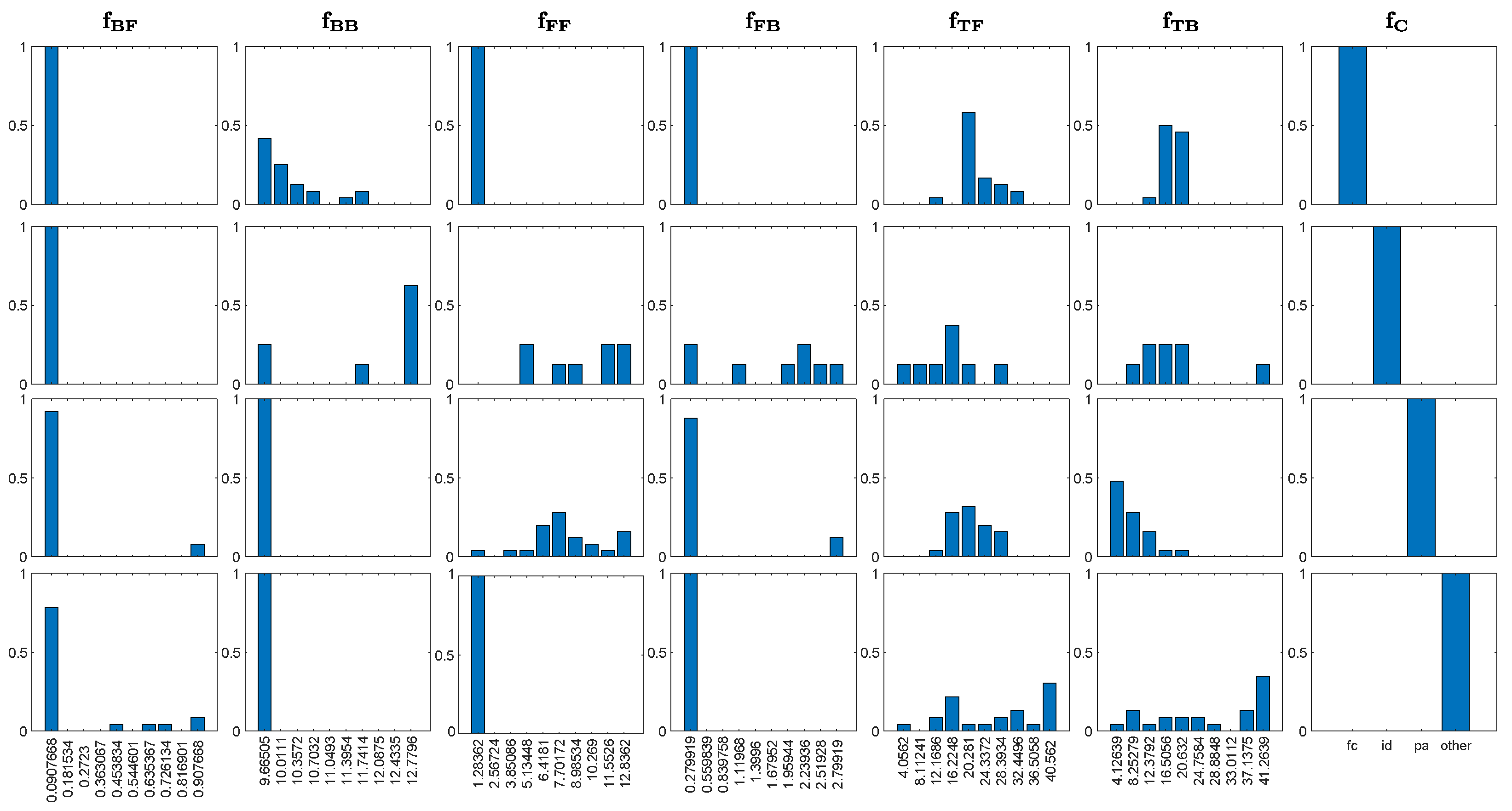
3.2. Inference
3.2.1. Measure’s Context
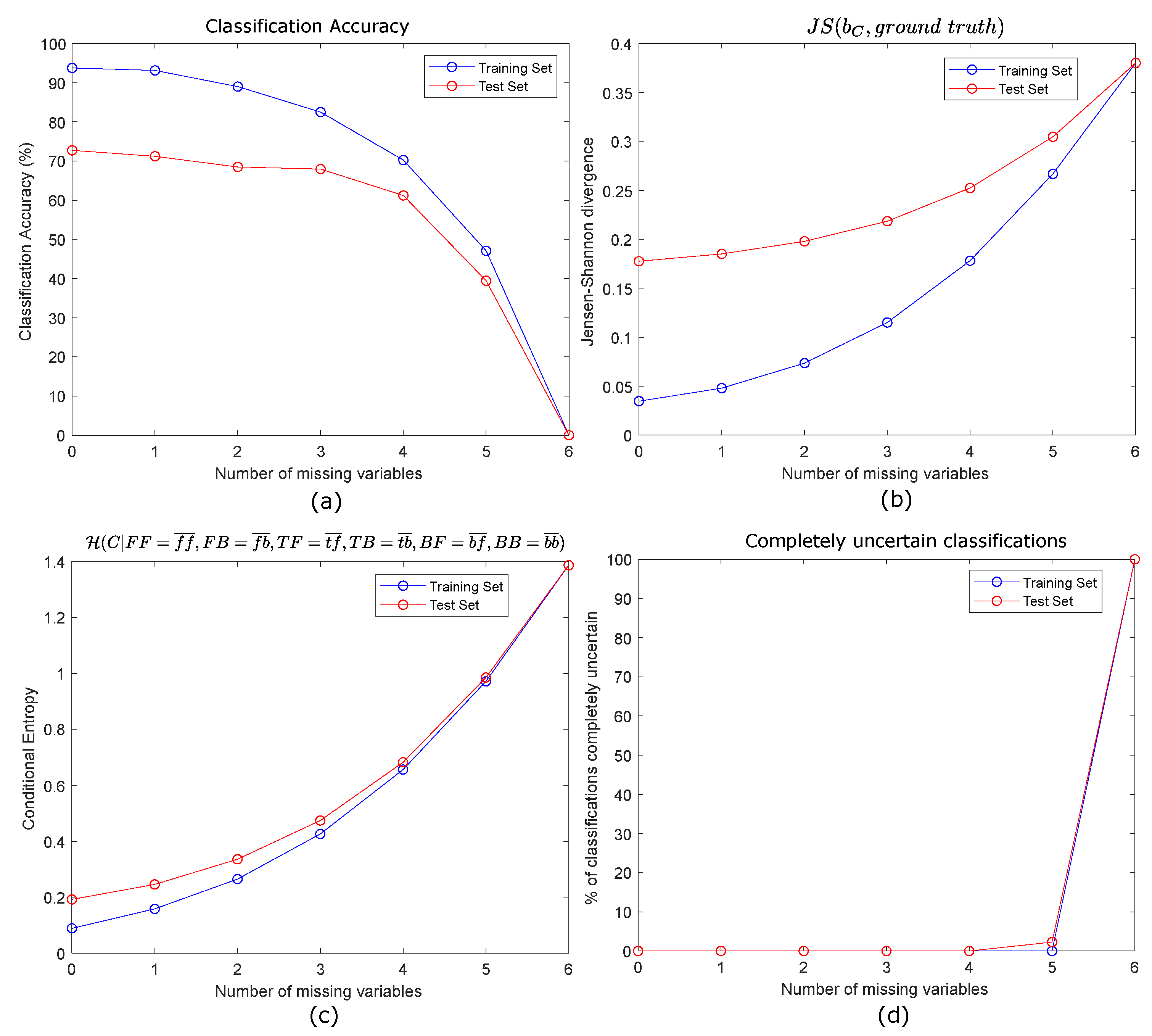
3.2.2. Missing Values’ Management
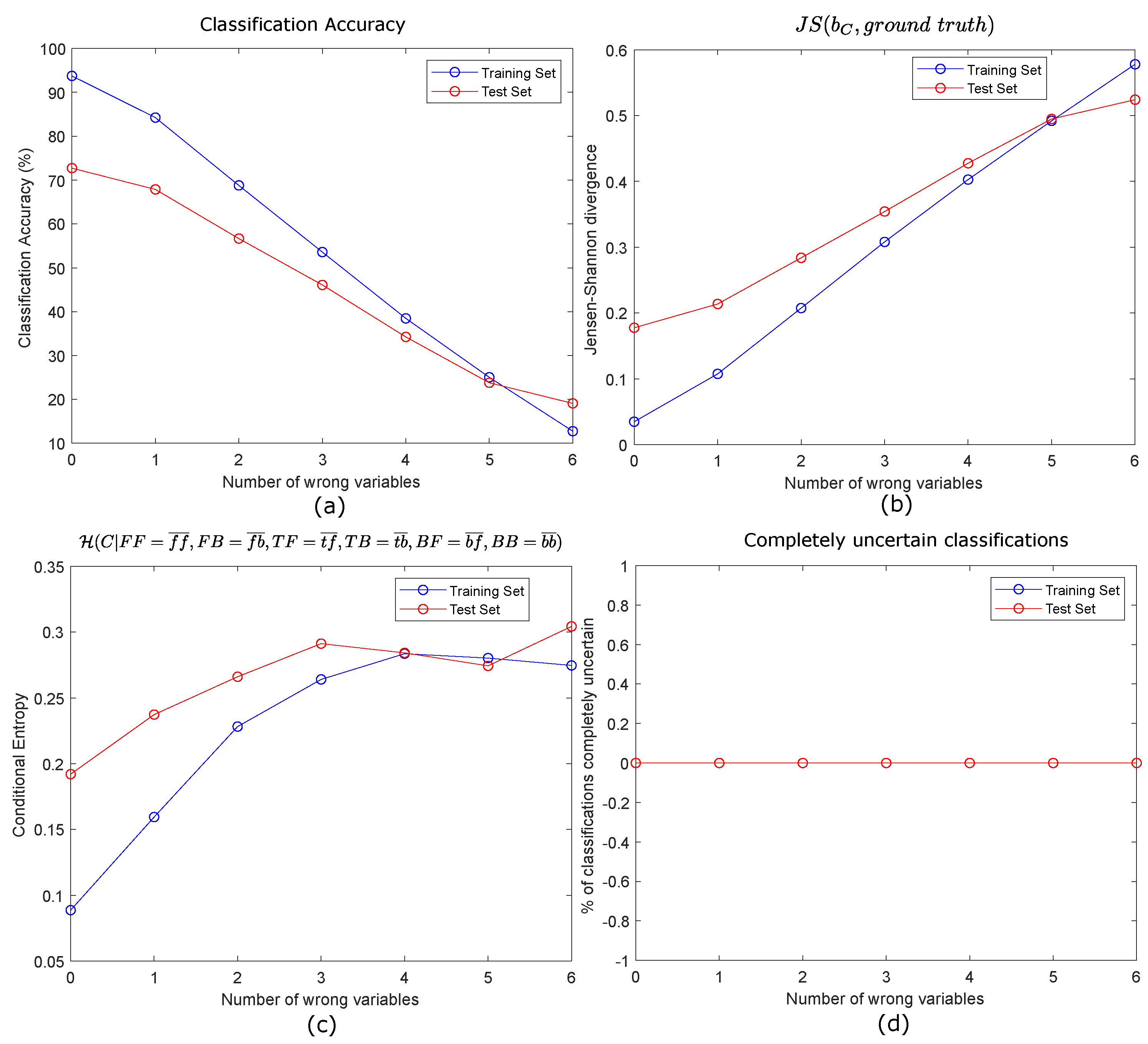
3.2.3. Errors Management
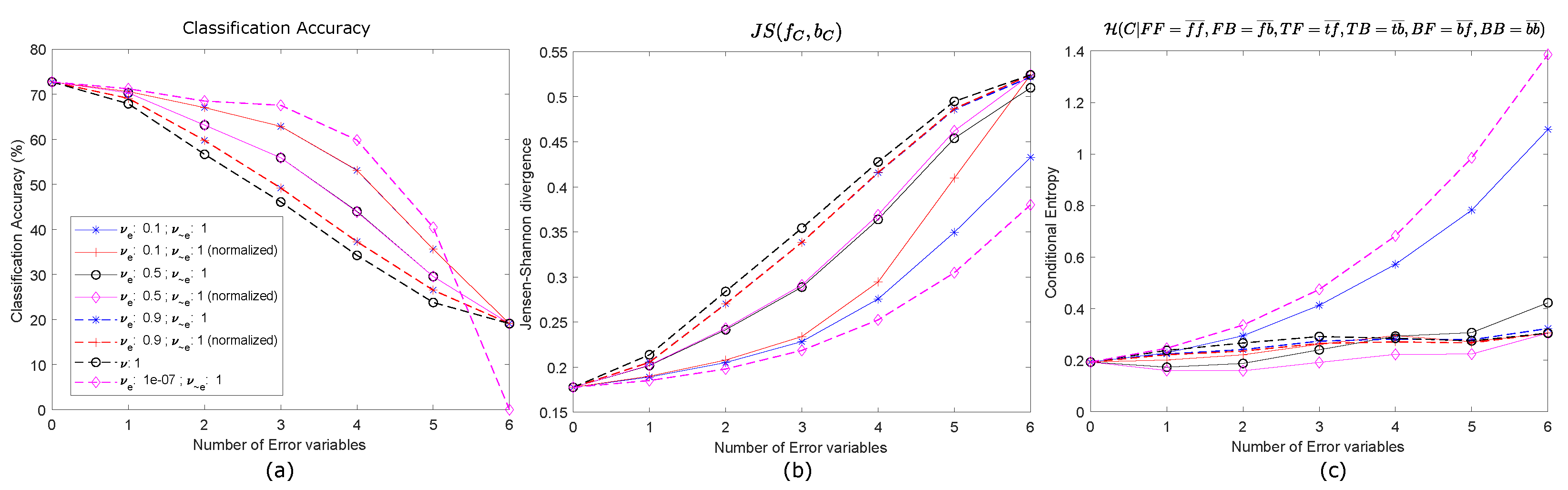
3.2.4. Reliability Test
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Raol, J.R. Data Fusion Mathematics: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Dasarathy, B.V. Sensor fusion potential exploitation-innovative architectures and illustrative applications. Proc. IEEE 1997, 85, 24–38. [Google Scholar] [CrossRef]
- Frontex. Best Practice Operational Guidelines for Automated Border Control (ABC) Systems; European Agency for the Management of Operational Cooperation at the External Borders of the Member States of the European Union; European Agency, 2012; Available online: https://www.scribd.com/document/169819829/Best-Practice-Operational-Guidelines-for-Automated-Border-Control (accessed on 1 November 2020). [CrossRef]
- Xu, Y.; Xu, Y.; Lv, T.; Cui, L.; Wei, F.; Wang, G.; Lu, Y.; Florencio, D.; Zhang, C.; Che, W.; et al. LayoutLMv2: Multi-Modal Pre-Training for Visually-Rich Document Understanding. arXiv 2020, arXiv:2012.14740. [Google Scholar]
- Bakkali, S.; Ming, Z.; Coustaty, M.; Rusiñol, M. Cross-Modal Deep Networks For Document Image Classification. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2556–2560. [Google Scholar]
- Wang, Z.; Wang, C.; Zhang, H.; Duan, Z.; Zhou, M.; Chen, B. Learning Dynamic Hierarchical Topic Graph with Graph Convolutional Network for Document Classification. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTAT) 2020, Online. 26–28 August 2020. [Google Scholar]
- Ullah, I.; Manzo, M.; Shah, M.; Madden, M. Graph Convolutional Networks: analysis, improvements and results. arXiv 2019, arXiv:1912.09592. [Google Scholar]
- Simon, M.; Rodner, E.; Denzler, J. Fine-grained classification of identity document types with only one example. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 126–129. [Google Scholar] [CrossRef]
- Sicre, R.; Montaser Awal, A.; Furon, T. Identity documents classification as an image classification problem. In Proceedings of the ICIAP 2017—19th International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017; pp. 602–613. [Google Scholar] [CrossRef] [Green Version]
- Awal, A.M.; Ghanmi, N.; Sicre, R.; Furon, T. Complex Document Classification and Localization Application on Identity Document Images. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 426–431. [Google Scholar]
- Vilàs Mari, P. Classification of Identity Documents Using a Deep Convolutional Neural Network. Master’s Thesis, Universitat Oberta de Catalunya, Barcelona, Spain, 2018. Available online: http://hdl.handle.net/10609/73186 (accessed on 4 December 2020).
- Ellena, F. Deep Convolutional Neural Networks for Document Classification. Master’s Thesis, Politecnico di Torino, Turin, Italy, 2018. Available online: http://webthesis.biblio.polito.it/id/eprint/7603 (accessed on 4 December 2020).
- Palmieri, F.A.N. A Comparison of Algorithms for Learning Hidden Variables in Bayesian Factor Graphs in Reduced Normal Form. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2242–2255. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Manduchi, R. A Study on Bayes Feature Fusion for Image Classification. In Proceedings of the 2003 Conference on Computer Vision and Pattern Recognition Workshop, Madison, WI, USA, 16–22 June 2003; Volume 8, p. 95. [Google Scholar] [CrossRef] [Green Version]
- Olascoaga, L.I.G.; Meert, W.; Bruyninckx, H.; Verhelst, M. Extending Naive Bayes with Precision-Tunable Feature Variables for Resource-Efficient Sensor Fusion. In Proceedings of the 2nd Workshop on Artificial Intelligence and Internet of Things, Hague, The Netherlands, 30 August 2016; Volume 1724, pp. 23–30, AI-IoT@ECAI: 2016. [Google Scholar]
- Jin, Y.; Geman, S. Context and Hierarchy in a Probabilistic Image Model. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2145–2152. [Google Scholar] [CrossRef]
- Choi, M.J.; Torralba, A.; Willsky, A.S. A Tree-Based Context Model for Object Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 240–252. [Google Scholar] [CrossRef] [Green Version]
- Buonanno, A.; Iadicicco, P.; Di Gennaro, G.; Palmieri, F.A.N. Context Analysis Using a Bayesian Normal Graph. In Neural Advances in Processing Nonlinear Dynamic Signals; Esposito, A., Faundez-Zanuy, M., Morabito, F.C., Pasero, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 85–96. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. WIDER FACE: A Face Detection Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Nguyen, T. Yoloface. 2019. Available online: https://github.com/sthanhng/yoloface (accessed on 4 December 2020).
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Argman. East. 2019. Available online: https://github.com/argman/EAST (accessed on 4 December 2020).
- Rosebrock, A. Detecting Barcodes in Images with Python and OpenCV. 2014. Available online: https://www.pyimagesearch.com/2014/11/24/detecting-barcodes-images-python-opencv/ (accessed on 4 December 2020).
- Buonanno, A.; Palmieri, F.A.N. Simulink Implementation of Belief Propagation in Normal Factor Graphs. In Advances in Neural Networks: Computational and Theoretical Issues; Bassis, S., Esposito, A., Morabito, F.C., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 11–20. [Google Scholar] [CrossRef]
- Buonanno, A.; Palmieri, F.A.N. Two-Dimensional Multi-layer Factor Graphs in Reduced Normal Form. In Proceedings of the International Joint Conference on Neural Networks, IJCNN2015, Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques—Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Di Gennaro, G.; Buonanno, A.; Palmieri, F.A.N. Computational Optimization for Normal Form Realization of Bayesian Model Graphs. In Proceedings of the 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), Aalborg, Denmark, 17–20 September 2018; pp. 1–6. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Arlazarov, V.; Bulatov, K.; Chernov, T.; Arlazarov, V. MIDV-500: a dataset for identity document analysis and recognition on mobile devices in video stream. Comput. Opt. 2019, 43, 818–824. [Google Scholar] [CrossRef]
- Harley, A.W.; Ufkes, A.; Derpanis, K.G. Evaluation of deep convolutional nets for document image classification and retrieval. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Nancy, France, 23–26 August 2015; pp. 991–995. [Google Scholar] [CrossRef] [Green Version]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Images: 412 | Only front: 298 | fc: 1.0% |
| id: 26.2% | ||
| pa: 17.4% | ||
| other: 55.4% | ||
| Front and back: 114 | fc: 29.8% | |
| id: 9.6% | ||
| pa: 32.5% | ||
| other: 28.1% |
| Predicted | ||||||||
|---|---|---|---|---|---|---|---|---|
| fc | id | pa | Other | Precision | Recall | F1-Score | ||
| Actual | fc | 95.0% | 0 | 0 | 5.0% | 0.8636 | 0.9500 | 0.9048 |
| id | 0 | 63.6% | 36.4% | 0 | 0.6364 | 0.6364 | 0.6364 | |
| pa | 3.5% | 13.8% | 79.3% | 3.4% | 0.8214 | 0.7931 | 0.8070 | |
| other | 9.5% | 0 | 4.8% | 85.7% | 0.9000 | 0.8571 | 0.8780 | |
| Predicted | ||||||||
|---|---|---|---|---|---|---|---|---|
| fc | id | pa | Other | Precision | Recall | F1-Score | ||
| Actual | fc | 78.9% | 0 | 0 | 21.1% | 0.8333 | 0.7895 | 0.8108 |
| id | 0 | 54.5% | 36.4% | 9.1% | 0.5455 | 0.5455 | 0.5455 | |
| pa | 2.1% | 20.8% | 77.1% | 0 | 0.7872 | 0.7708 | 0.7789 | |
| other | 6.1% | 0 | 6.1% | 87.8% | 0.8286 | 0.8788 | 0.8529 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buonanno, A.; Nogarotto, A.; Cacace, G.; Di Gennaro, G.; Palmieri, F.A.N.; Valenti, M.; Graditi, G. Bayesian Feature Fusion Using Factor Graph in Reduced Normal Form. Appl. Sci. 2021, 11, 1934. https://doi.org/10.3390/app11041934
Buonanno A, Nogarotto A, Cacace G, Di Gennaro G, Palmieri FAN, Valenti M, Graditi G. Bayesian Feature Fusion Using Factor Graph in Reduced Normal Form. Applied Sciences. 2021; 11(4):1934. https://doi.org/10.3390/app11041934
Chicago/Turabian StyleBuonanno, Amedeo, Antonio Nogarotto, Giuseppe Cacace, Giovanni Di Gennaro, Francesco A. N. Palmieri, Maria Valenti, and Giorgio Graditi. 2021. "Bayesian Feature Fusion Using Factor Graph in Reduced Normal Form" Applied Sciences 11, no. 4: 1934. https://doi.org/10.3390/app11041934