
Predicting Student Academic Performance by Means of Associative Classification



Abstract
:1. Introduction
- RQ(1)
- Are associative models as accurate as the best performing classifiers in predicting the exam success rates of university-level students?
- RQ(2)
- What are the most discriminating features to forecast the exam success rates at different time points?
- RQ(3)
- Which combinations of feature values have frequently been used to assign the exam success rates?
2. Literature Review
- (A)
- What are the most discriminating features to forecast the exam success rates?
- (B)
- From which time point can classifier predictions be deemed as reliable?
- (C)
- What are the most effective classification techniques?
- (D)
- Can we make Learning Analytics solutions interpretable and transparent to the end-users?
3. Materials and Methods
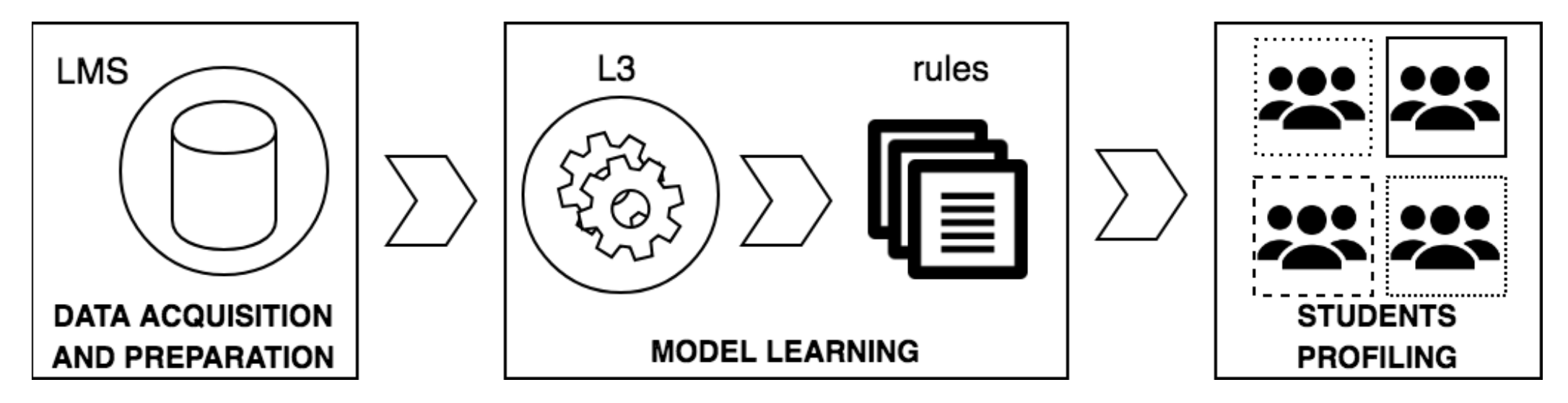
- Data acquisition and preparation: Student-related data are acquired over the whole academic year by the Learning Management Systems (LMS) adopted by the university, collected into a unified repository, and prepared for the classification process.
- Associative model learning: Multiple associative classifiers, consisting of a selection of association rules [37], are trained from the prepared data at different time points (e.g., before student enrollment, before the beginning of the course, before the beginning of the examination session). Each classifier describes the most significant correlations between a combination of data features and the success rate of the upcoming exam.
- Model interpretation: The associative model is manually explored to identify at-risk/successful student profiles based on the extracted rules and to validate the per-student rate predictions based on the associated profile.
3.1. Data Acquisition and Preparation
- Student-specific characteristics, e.g., gender, age, ethnicity, high school type, standardized scores, current credit load.
- Student’s engagement indicators customized to the course under analysis, e.g., course satisfaction, frequency of logins to online portals, frequency of course materials’ accesses and downloads, frequency of video lectures’ accesses and downloads, number of discussions posted.
- Assessment scores: result of the entry test, grade earned in the previous exams.
3.2. Associative Model Learning
High-Quality Rules
3.3. Profile Extraction and Ranking
- Single-feature profiles are profiles characterized by a single feature category. According to the feature categorization reported in Section 3.1, they can be further classified as profiles on student-specific characteristics (SSC profiles, in short), profiles on student’s engagement indicators (SEI profiles), or profiles on assessment scores (AS profiles) depending on the category of the reference feature.
- Mixed-feature profiles are profiles that are modeled on multiple data feature categories. They extend single-feature profiles by combining features of different categories.
4. Results
4.1. Learning Context and Related Data
Details on the Source Data
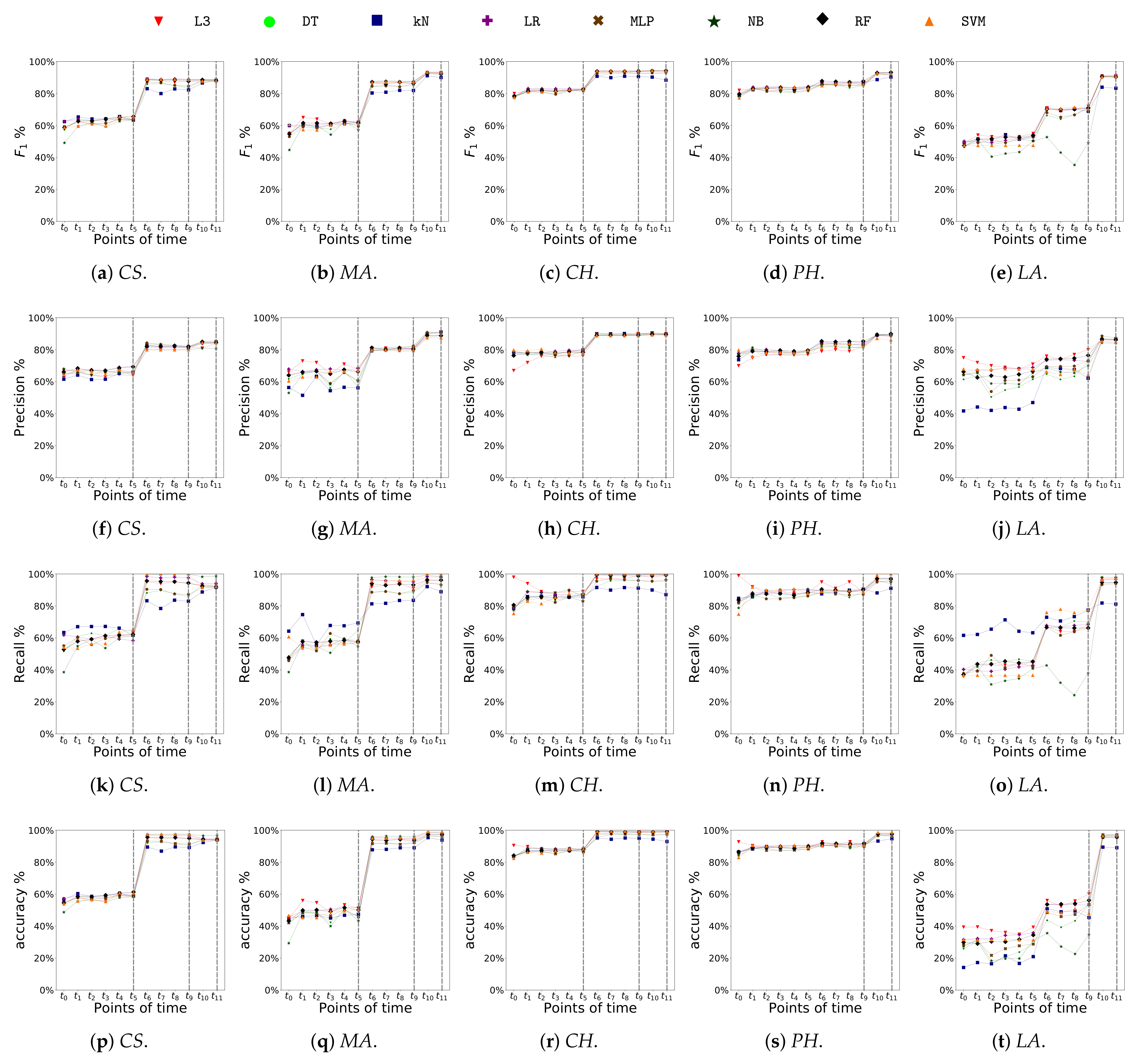
4.2. Performance Comparison between Different Algorithms
- The Live and Let Live () classifier [15]: a state-of-the-art associative classifier.
- C4.5 (DT): popular decision tree-based classifiers.
- Multi-Layer Perceptron (MLP): a popular single-layer Neural Networks model.
- LIBSVM (SVM): an established Support Vector Machines model.
- Multinomial naive Bayes (NB): an established multiclass Bayesian classifier.
- k-Nearest Neighbor (kNN): a lazy distance-based classifier (lazy classifiers do not create models, but on-the-fly compute the distances between a test record and each of the training records).
- Random Forest (RF): ensemble method.
- Precision of class fail: It is the ratio between number of students who have been correctly labeled as belonging to class fail () divided by the total number of students assigned to class fail ().
- Recall of class fail: It is the ratio between number of students who have been correctly labeled as belonging to class fail () divided by the total number of students who actually belong to class fail ().
- F1-score of class fail: It is the harmonic mean of precision and recall of class fail.
- Balanced Accuracy: It is the average of the recall computed over the two classes and is given by [45]. It evaluates the ability of the classifier to correctly assign both class labels. It is especially useful when the classes are imbalanced in the test sample since it rewards the correct predictions on the minority class. When the test samples are balanced over the two classes, it corresponds to the conventional accuracy measure (i.e., percentage of correct predictions).
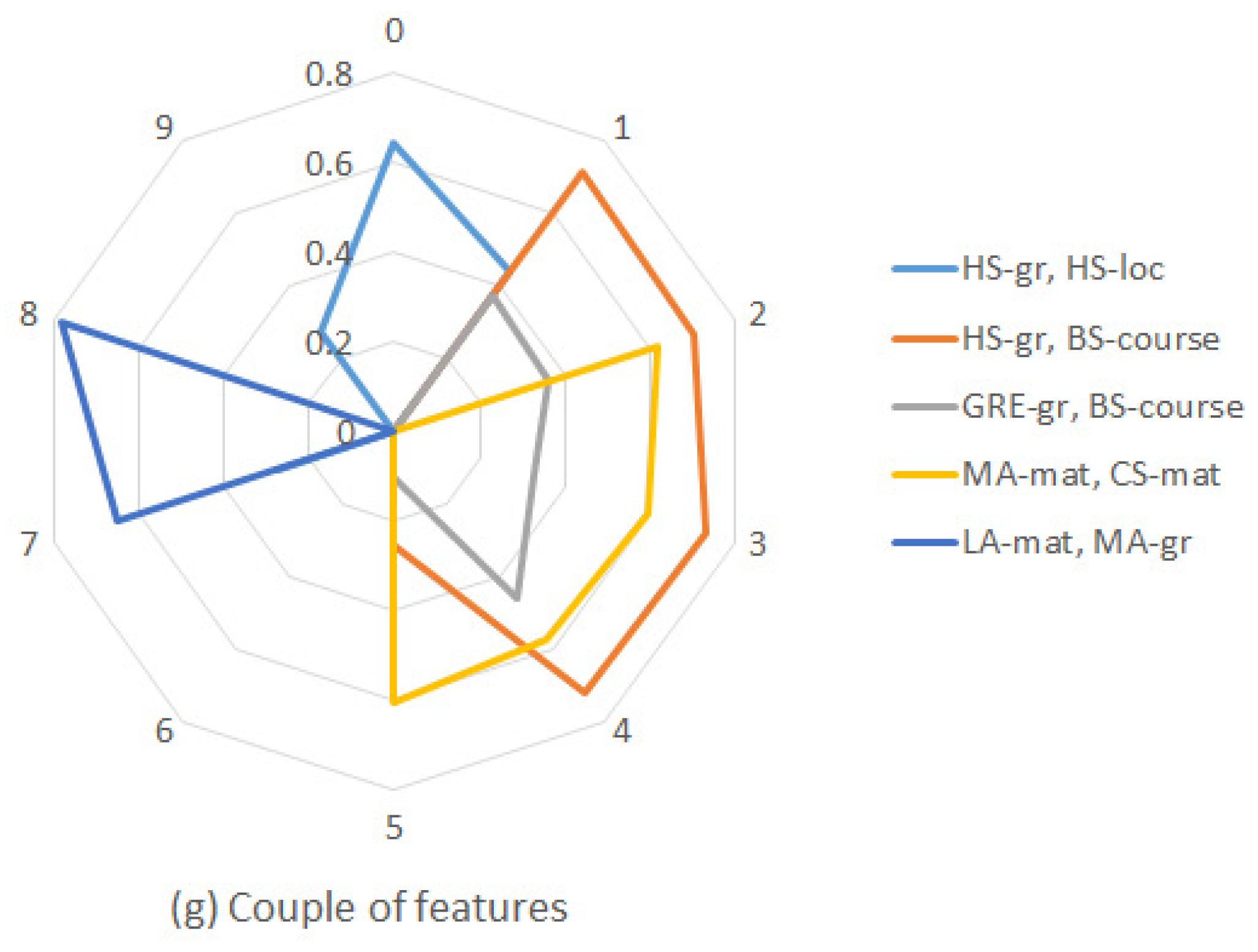
4.3. Model Exploration
4.4. Takeaways
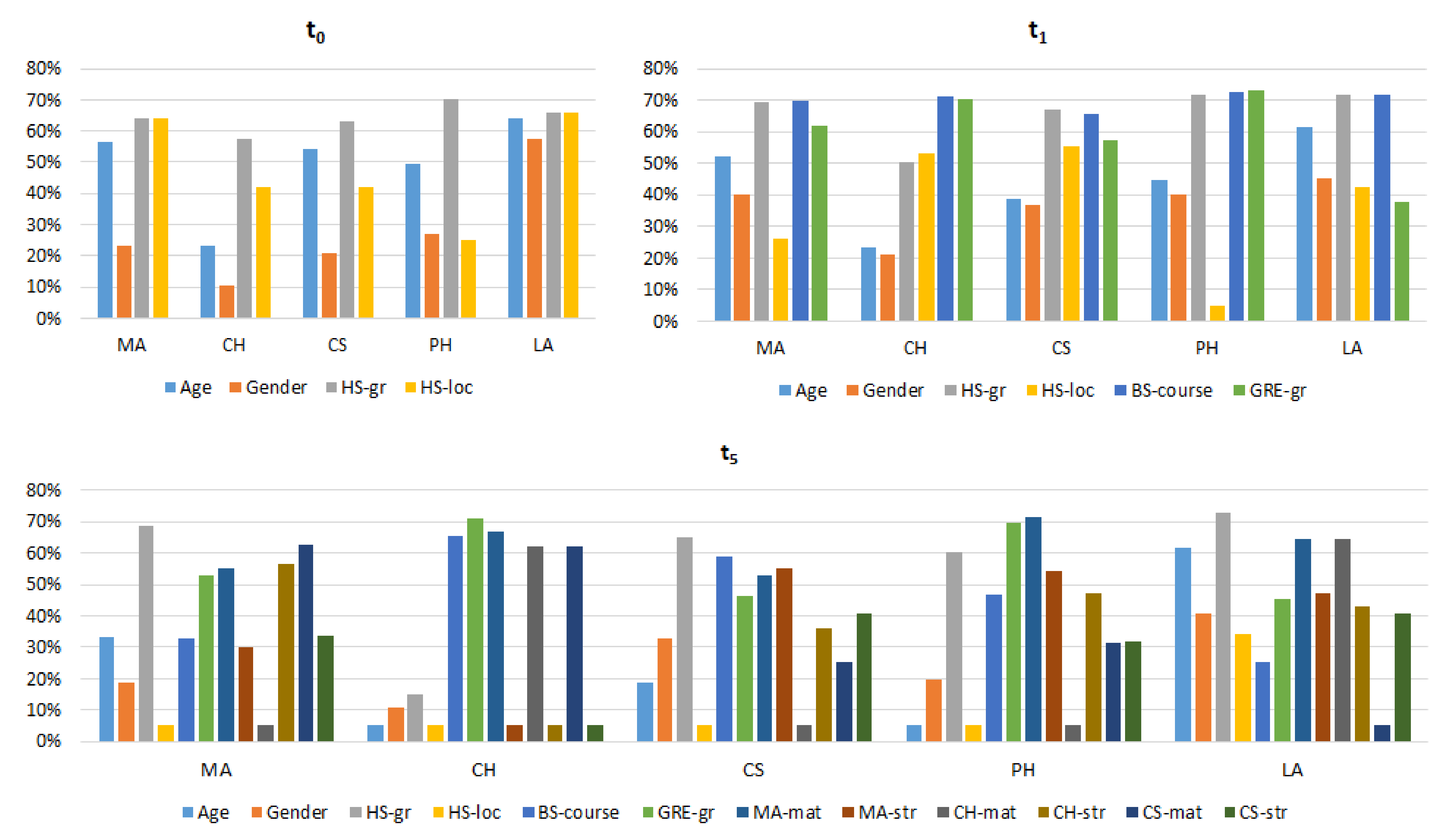
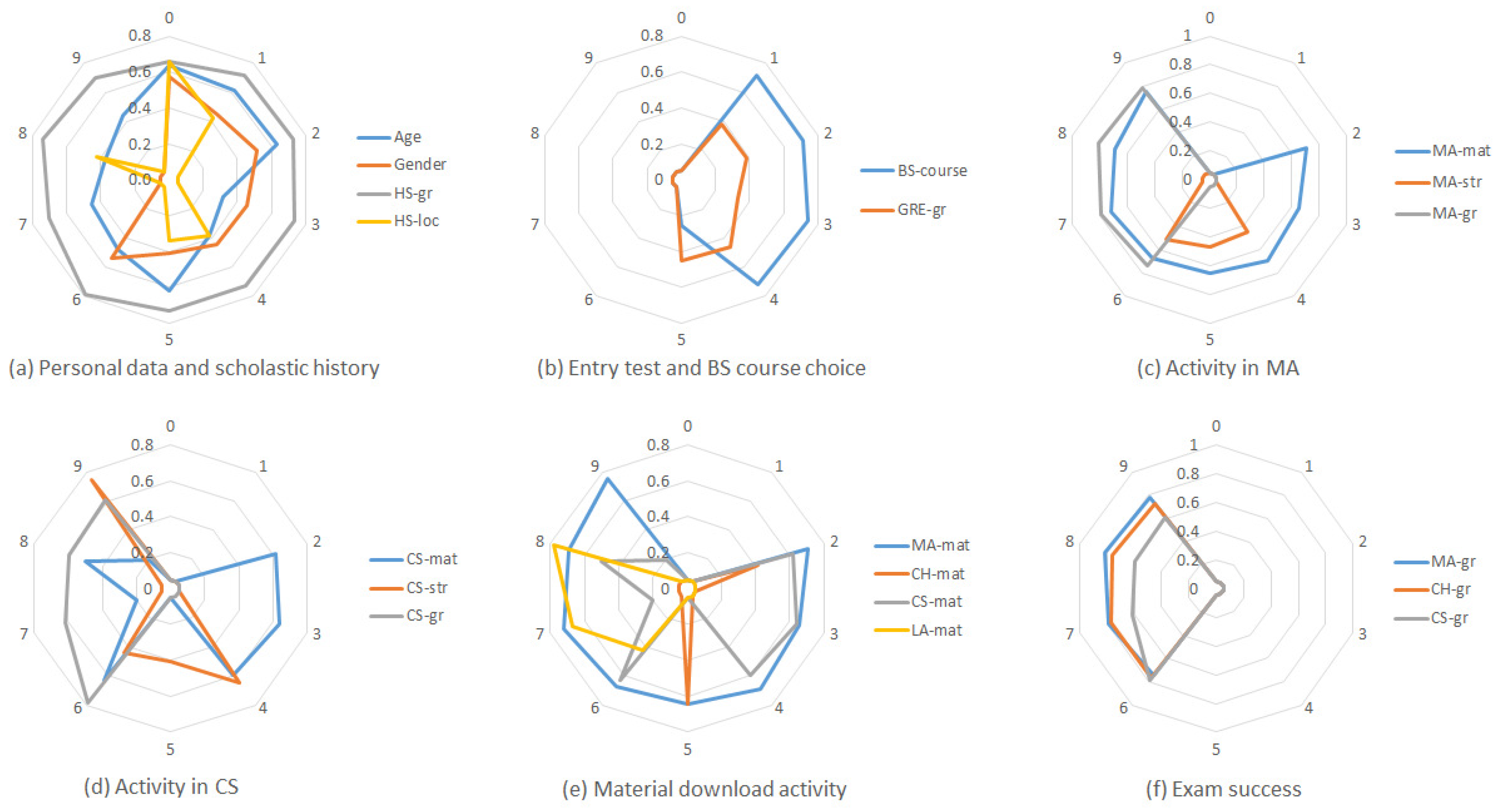
- The high school degree heavily influence students’ performance. In the example rules, this is already evident at (see Table 6) for the MA course, but the feature is very relevant during the whole academic year (see (a) in Figure 4) and the result is valid for all the courses (see Figure 3). Planning ad hoc remedial courses for students with low high school grade is therefore a suitable action to prevent student drop-out.
- Age has also a significant impact. This is not surprising because students that are older than the average likely had below average results during high school or are part-time workers. Rules 3, 4 and 5 in Table 6 confirm this statement for the MA course, but the feature is always relevant, especially in the first part of the academic year (see (a) in Figure 4) and the result is valid for the majority of the courses (see Figure 3). The fact that the influence of this feature decreases during the semester shows that motivated students learn to react putting extra effort in the study. Awareness actions toward this category of student can have a positive effect.
- Inactivity as regards educational material download is strongly related to failure. Rules 9, 13, and 16 reported in Table 7 for the MA course show that this holds during the whole semester. A proactive, reiterated invitation to use available educational materials could help students.
- It is very important to start the study activity very soon.Table 7 shows that a limited number of downloads of the MA educational materials is enough at the beginning of the semester (rule 6), but it is not later on (rules 12 and 15). This result is coherent with graph (e) in Figure 4: the educational material download activity has a strong influence on student performance already at the beginning of the semester. This is a useful recommendation for the students who want to improve their academic performance.
- Putting effort on many courses at the same time is a strategy that pays at the beginning of the semester but not close to the exam session. Rules 8 in Table 7 show that working on more that one course at increases the chance to pass the MA course, while rule 17 shows that the same kind of behaviour at yields opposite effects. Students should therefore be invited to work hard since the beginning of the semester, but they should also be warned that they should focus on a specific course when they are close to the exam.
- The use of the video-lecture streaming service is always positive.Table 8 shows that video-lecture streaming activity, even if limited, has a positive impact on passing the MA exam. This is valid for the use of MA video-lectures (rules 18, 20 and 22), but also for the use other course video-lectures (rules 19, 21 and 23), because this activity likely identifies active and motivated students. Rule 24 in Table 9 adds that streaming is positive even without downloading educational material. This outcome is very positive for our institution, since it proves that the video-lecture service is valuable, besides being appreciated by the students. Encouraging students to actively use the service is another fruitful action to prevent failure and drop-out.
- Downloading video-lectures is not enough. Rule 25 in Table 9 shows that video-lectures download without use of educational material is not enough to pass the MA exam. This rule identifies the students that simply download all the video-lectures for a later use, but that very likely (since they do not download the accompanying educational material) do not actually watch them. This result is supported by what is evident in graphs (c) and (d) of Figure 4. Video-lecture streaming activity and educational material download activity are shown to be indicators for exam success, while this is not the case for the video-lectures download activity.
5. Conclusions
- Is the associative model effective in predictive exams’ outcomes in other learning contexts (e.g., higher level courses, university-level M.S. courses)?
- Could associative models be integrated into an automated decision support systems that triggers personalized alerts based on the outcomes of the early prediction process?
- How can student profiles be effectively processed and visualized in order to continuously monitor the advances in the students’ learning process?
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siemens, G.; Baker, R.S.J.d. Learning Analytics and Educational Data Mining: Towards Communication and Collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge; ACM: New York, NY, USA, 2012; LAK ’12; pp. 252–254. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Guest Editorial: Special Issue on Early Prediction and Supporting of Learning Performance. IEEE Trans. Learn. Technol. 2019, 12, 145–147. [Google Scholar] [CrossRef]
- Conijn, R.; Snijders, C.; Kleingeld, A.; Matzat, U. Predicting Student Performance from LMS Data: A Comparison of 17 Blended Courses Using Moodle LMS. IEEE Trans. Learn. Technol. 2017, 10, 17–29. [Google Scholar] [CrossRef]
- Adejo, O.W.; Connolly, T. Predicting student academic performance using multi-model heterogeneous ensemble approach. J. Appl. Res. High. Educ. 2018, 10, 61–75. [Google Scholar] [CrossRef]
- Yang, T.Y.; Brinton, C.G.; Joe-Wong, C.; Chiang, M. Behavior-Based Grade Prediction for MOOCs Via Time Series Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 716–728. [Google Scholar] [CrossRef]
- Hung, J.; Wang, M.C.; Wang, S.; Abdelrasoul, M.; Li, Y.; He, W. Identifying At-Risk Students for Early Interventions—A Time-Series Clustering Approach. IEEE Trans. Emerg. Top. Comput. 2017, 5, 45–55. [Google Scholar] [CrossRef]
- Tempelaar, D.T.; Rienties, B.; Giesbers, B. In search for the most informative data for feedback generation: Learning analytics in a data-rich context. Comput. Hum. Behav. 2015, 47, 157–167. [Google Scholar] [CrossRef] [Green Version]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar] [CrossRef]
- Alonso, J.M.; Casalino, G. Explainable Artificial Intelligence for Human-Centric Data Analysis in Virtual Learning Environments. In Higher Education Learning Methodologies and Technologies Online; Burgos, D., Cimitile, M., Ducange, P., Pecori, R., Picerno, P., Raviolo, P., Stracke, C.M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 125–138. [Google Scholar]
- Guerrero-Higueras, Á.M.; DeCastro-García, N.; Rodriguez-Lera, F.J.; Matellán, V.; Ángel Conde, M. Predicting academic success through students’ interaction with Version Control Systems. Open Comput. Sci. 2019, 9, 243–251. [Google Scholar] [CrossRef]
- Hellas, A.; Ihantola, P.; Petersen, A.; Ajanovski, V.V.; Gutica, M.; Hynninen, T.; Knutas, A.; Leinonen, J.; Messom, C.; Liao, S.N. Predicting Academic Performance: A Systematic Literature Review. In Proceedings of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education; ACM: New York, NY, USA, 2018; ITiCSE 2018 Companion; pp. 175–199. [Google Scholar] [CrossRef] [Green Version]
- Liu, B. Classification by Association Rule Analysis. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 335–340. [Google Scholar] [CrossRef]
- Liu, B.; Hsu, W.; Ma, Y. Integrating Classification and Association Rule Mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998; KDD’98. pp. 80–86. [Google Scholar]
- Baralis, E.; Cagliero, L.; Farinetti, L.; Mezzalama, M.; Venuto, E. Experimental Validation of a Massive Educational Service in a Blended Learning Environment. In Proceedings of the 41st IEEE Annual Computer Software and Applications Conference, COMPSAC 2017, Turin, Italy, 4–8 July 2017; Volume 1, pp. 381–390. [Google Scholar] [CrossRef] [Green Version]
- Baralis, E.; Chiusano, S.; Garza, P. A Lazy Approach to Associative Classification. IEEE Trans. Knowl. Data Eng. 2008, 20, 156–171. [Google Scholar] [CrossRef]
- Moore, M.G. Editorial: Three types of interaction. Am. J. Distance Educ. 1989, 3, 1–7. [Google Scholar] [CrossRef]
- Joksimović, S.; Gašević, D.; Loughin, T.M.; Kovanović, V.; Hatala, M. Learning at distance: Effects of interaction traces on academic achievement. Comput. Educ. 2015, 87, 204–217. [Google Scholar] [CrossRef] [Green Version]
- Agudo-Peregrina, A.F.; Iglesias-Pradas, S.; Conde-Gonzalez, M.A.; Hernandez-García, A. Can we predict success from log data in VLEs? Classification of interactions for learning analytics and their relation with performance in VLE-supported F2F and online learning. Comput. Hum. Behav. 2014, 31, 542–550. [Google Scholar] [CrossRef]
- Gitinabard, N.; Xu, Y.; Heckman, S.; Barnes, T.; Lynch, C.F. How Widely Can Prediction Models Be Generalized? Performance Prediction in Blended Courses. IEEE Trans. Learn. Technol. 2019, 12, 184–197. [Google Scholar] [CrossRef] [Green Version]
- Zacharis, N.Z. A multivariate approach to predicting student outcomes in web-enabled blended learning courses. Internet High. Educ. 2015, 27, 44–53. [Google Scholar] [CrossRef]
- Macfadyen, L.P.; Dawson, S. Mining LMS data to develop an “early warning system” for educators: A proof of concept. Comput. Educ. 2010, 54, 588–599. [Google Scholar] [CrossRef]
- Hung, J.; Shelton, B.E.; Yang, J.; Du, X. Improving Predictive Modeling for At-Risk Student Identification: A Multistage Approach. IEEE Trans. Learn. Technol. 2019, 12, 148–157. [Google Scholar] [CrossRef]
- Carson, A. Predicting student success from the LASSI for learning online (LLO). J. Educ. Comput. Res. 2011, 45, 399–414. [Google Scholar] [CrossRef]
- Hu, Y.H.; Lo, C.L.; Shih, S.P. Developing early warning systems to predict students’ online learning performance. Comput. Hum. Behav. 2014, 36, 469–478. [Google Scholar] [CrossRef]
- Jokhan, A.; Sharma, B.; Singh, S. Early warning system as a predictor for student performance in higher education blended courses. Stud. High. Educ. 2018, 1–12. [Google Scholar] [CrossRef]
- Polyzou, A.; Karypis, G. Feature Extraction for Next-Term Prediction of Poor Student Performance. IEEE Trans. Learn. Technol. 2019, 12, 237–248. [Google Scholar] [CrossRef]
- Livieris, I.; Drakopoulou, K.; Tampakas, V.; Mikropoulos, T.; Pintelas, P. Predicting Secondary School Students’ Performance Utilizing a Semi-supervised Learning Approach. J. Educ. Comput. Res. 2017, 57. [Google Scholar] [CrossRef]
- Al-Sudani, S.; Palaniappan, R. Predicting students’ final degree classification using an extended profile. Educ. Inf. Technol. 2019, 24, 2357–2369. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Xiong, X.; Zhao, S.; Botelho, A.; Heffernan, N.T. Incorporating Rich Features into Deep Knowledge Tracing. In Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale; ACM: New York, NY, USA, 2017; L@S ’17; pp. 169–172. [Google Scholar] [CrossRef] [Green Version]
- Asogbon, M.; Samuel, O.; Omisore, M.; Ojokoh, B. A Multi-class Support Vector Machine Approach for Students Academic Performance Prediction. Int. J. Multidiscip. Curr. Res. 2016, 4, 210–215. [Google Scholar]
- Al-Shehri, H.; Al-Qarni, A.; Al-Saati, L.; Batoaq, A.; Badukhen, H.; Alrashed, S.; Alhiyafi, J.; Olatunji, S.O. Student performance prediction using Support Vector Machine and K-Nearest Neighbor. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017; pp. 1–4. [Google Scholar]
- Amrieh, E.; Hamtini, T.; Aljarah, I. Mining Educational Data to Predict Student’s academic Performance using Ensemble Methods. Int. J. Database Theory Appl. 2016, 9, 119–136. [Google Scholar] [CrossRef]
- Cukurova, M.; Zhou, Q.; Spikol, D.; Landolfi, L. Modelling Collaborative Problem-Solving Competence with Transparent Learning Analytics: Is Video Data Enough? In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge; Association for Computing Machinery: New York, NY, USA, 2020; LAK ’20; pp. 270–275. [Google Scholar] [CrossRef] [Green Version]
- Kumar, V.; Boulanger, D. Explainable Automated Essay Scoring: Deep Learning Really Has Pedagogical Value. Front. Educ. 2020, 5. [Google Scholar] [CrossRef]
- Lundberg, S.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From Local Explanations to Global Understanding with Explainable AI for Trees. Nat. Mach. Intell. 2020, 2. [Google Scholar] [CrossRef] [PubMed]
- Guggemos, J. On the predictors of computational thinking and its growth at the high-school level. Comput. Educ. 2021, 161, 104060. [Google Scholar] [CrossRef]
- Agrawal, R.; Imielinski, T.; Swami. Mining Association Rules between Sets of Items in Large Databases; ACM SIGMOD: Washington, DC, USA, 1993; pp. 207–216. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; KDD ’16; pp. 1135–1144. [Google Scholar] [CrossRef]
- Aggarwal, C.C. An Introduction to Data Classification. In Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014; pp. 1–36. [Google Scholar]
- Veloso, A.; Meira, W., Jr.; Zaki, M.J. Lazy Associative Classification. In Proceedings of the Sixth International Conference on Data Mining; IEEE Computer Society: New York, NY, USA, 2006; ICDM ’06; pp. 645–654. [Google Scholar] [CrossRef]
- Padillo, F.; Luna, J.M.; Ventura, S. Evaluating associative classification algorithms for Big Data. Big Data Anal. 2019, 4, 2. [Google Scholar] [CrossRef]
- Tan, P.N.; Kumar, V. Interestingness Measures for Association Patterns: A Perspective. In KDD 2000 Workshop on Postprocessing in Machine Learning and Data Mining. 2000. Available online: https://www.kdd.org/exploration_files/KDD2000PostWkshp.pdf (accessed on 27 January 2021).
- Cagliero, L.; Farinetti, L.; Mezzalama, M.; Venuto, E.; Baralis, E. Educational video services in universities: A systematic effectiveness analysis. In Proceedings of the 2017 IEEE Frontiers in Education Conference, FIE 2017, Indianapolis, IN, USA, 18–21 October 2017; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Brodersen, K.; Ong, C.S.; Stephan, K.; Buhmann, J. The Balanced Accuracy and Its Posterior Distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Guo, S.; Bocklitz, T.; Neugebauer, U.; Popp, J. Common mistakes in cross-validating classification models. Anal. Methods 2017, 9, 4410–4417. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Student | Entry Test | Accessed Video | Success Rate |
|---|---|---|---|
| Id | Grade | Lectures (%) | (Class) |
| 101010 | [60, 70] | <5 | fail |
| 202020 | [80, 95] | [10, 20] | pass |
| 303030 | [60, 70] | <5 | fail |
| 404040 | [70, 85] | [30, 40] | pass |
| 505050 | [60, 70] | [30, 40] | fail |
| 606060 | [70, 85] | [80, 90] | pass |
| Id | Time Point | Description |
|---|---|---|
| 31 August 2018 | Before entry test | |
| 7 September 2018 | After entry test | |
| 30 October 2018 | Early 1st semester | |
| 31 November 2018 | Mid-way 1st semester | |
| 15 January 2019 | Close to 1st semester exams | |
| 22 January 2019 | Start of 1st semester exam session | |
| 28 February 2019 | End of 1st semester exam session | |
| 31 March 2019 | Early 2nd semester | |
| 30 April 019 | Mid-way 2nd semester | |
| 15 June 2019 | Start of 2nd semester exam session | |
| 22 July 2019 | End of 2nd semester exam session | |
| 31 August 2019 | After summer break |
| Attribute | Description | Data Type | Domain |
|---|---|---|---|
| Student Id | student identifier | categorical | {1,2......} |
| Gender | gender | categorical | {M = male, F = female} |
| Age | student’s age—average students’ age | ordinal | {−1,1,2,3} |
| BH-loc | country of birth identifier | categorical | {AF, AL,...} |
| HM-loc | home country identifier | categorical | {AF, AL,...} |
| HS-loc | high school country identifier | categorical | {AF, AL,...,} |
| HS-gr | high school grade band | ordinal | {1 = low, 2 = low average, 3 = average, 4 = average high, 5 = high} |
| GRE-gr | entry test grade | ordinal | {1 = low, 2 = low average, 3 = average, 4 = average high, 5 = high} |
| BS course | bachelor’s degree track | categorical | {mechanical engineering, computer enginnering...} |
| Attribute | Description | Data Type | Domain |
|---|---|---|---|
| Student Id | student identifier | categorical | {1,2......} |
| Course Id | course identifier | categorical | {1,2......} |
| Time point | time point identifier | ordinal | {0,1,...,12} |
| MA-mat | discretized frequency of video lectures’ downloads normalized to the maximum number of downloads made up to that point in time | categorical | {H = high, F = average, L = little, N = no use} |
| MA-str | discretized frequency of video lectures’ accesses normalized to the maximum number of accesses up to that point in time | categorical | {H = high, F = average, L = little, N = no use} |
| Pass | Fail | Pass | Fail | Pass | Fail | |
| MA | 1515 | 2577 | 1183 | 332 | 1035 | 148 |
| CS | 1786 | 2307 | 1427 | 359 | 1127 | 300 |
| CH | 2697 | 1394 | 2397 | 300 | 2135 | 262 |
| PH | 2823 | 1270 | 2823 | 1270 | 2431 | 392 |
| LA | 1245 | 2848 | 1245 | 2848 | 1018 | 227 |
| Num | Time ID | Body | Head | Support (%) | Confidence (%) | Lift | Description |
|---|---|---|---|---|---|---|---|
| Pre-test | |||||||
| 1 | HS-loc = Italy, HS-gr = 5, gender = F | pass | 10.0 ± 0.3 | 86.5 ± 0.7 | 7 | Very good high school grade, high school in Italy, female (independently of age) | |
| 2 | HS-loc = Italy, HS-gr = 4, age = 0 | pass | 30.4 ± 0.2 | 79.2 ± 1.3 | 8 | Good high school grade, high school in Italy, average age | |
| 3 | HS-gr = 5, gender = M, age = −1 | pass | 14.1 ± 0.2 | 87.9 ± 1.0 | 4 | Good high school grade, male, younger than average (independently of the high school country) | |
| 4 | HS-gr = 1, gender = M, age = 3 | fail | 3.0 ± 0.1 | 90.7 ± 1.2 | 3 | Very low high school grade, male, much older than average | |
| 5 | HS-gr = 2, age = 1 | fail | 3.9 ± 0.1 | 89.7 ± 1.3 | 8 | Low grade, older than average (independently of gender and high school country) | |
| Num | Time ID | Body | Head | Support (%) | Confidence (%) | Lift | Description | Similar Rules |
|---|---|---|---|---|---|---|---|---|
| Early 1st semester | ||||||||
| 6 | MA-mat = L | pass | 31.8 ± 0.2 | 68 ± 0.6 | 7 | Little use of MA material, but already at the beginning of the semester | CH (with fail) | |
| 7 | MA-mat = F | pass | 14.9 ± 0.3 | 75.2 ± 0.7 | 8 | Average use of MA material | CH | |
| 8 | CS-mat = L, CH-mat = L | pass | 14.9 ± 0.1 | 68.3 ± 0.7 | 9 | Little use of other courses material | CS | |
| 9 | MA-mat = N, CS-mat = N, CH-mat = N | fail | 65.4 ± 0.1 | 65.5 ± 0.7 | 6 | No use of material (inactive) | CH, CS | |
| Mid-way 1st semester | ||||||||
| 10 | MA-mat = H | pass | 7.5 ± 0.3 | 78.9 ± 1.3 | 7 | High use of MA material | CH | |
| 11 | MA-mat = F | pass | 21.1 ± 0.2 | 76.1 ± 0.8 | 7 | Average use of MA materials, confirms | ||
| 12 | MA-mat = L | fail | 25.2 ± 0.2 | 64.4 ± 0.5 | 7 | Little use of MA material is not enough now (cfr ) | CH, CS | |
| 13 | MA-mat = N, CS-mat = N, CH-mat = N | fail | 17.2 ± 0.2 | 87.4 ± 1.3 | 8 | No use of material (inactive), confirms | CH, CS | |
| Close to 1st semester exams | ||||||||
| 14 | MA-mat = F | pass | 25.9 ± 0.1 | 78.2 ± 1.1 | 7 | Average use of MA material, confirms and | CH, CS | |
| 15 | MA-mat = L | fail | 25.2 ± 0.1 | 73.9 ± 0.8 | 8 | Little use of MA material, confirms | CH, CS | |
| 16 | MA-mat = N, CS-mat = N, CH-mat = N | fail | 13.2 ± 0.1 | 95.7 ± 0.6 | 7 | No use of material (inactive), confirms and | CH, CS | |
| 17 | CH-mat = H | fail | 3.9 ± 0.1 | 78.8 ± 0.8 | 8 | High use of another course material | CS (with pass) | |
| Num | Time ID | Body | Head | Support (%) | Confidence (%) | Lift | Description | Similar Rules |
|---|---|---|---|---|---|---|---|---|
| Early 1st semester | ||||||||
| 18 | MA-str=L | pass | 24.2 ± 0.2 | 70.0 ± 0.7 | 6 | Little use of MA videos, but soon (october), coherent with MA material | CH (with fail), CS (with fail) | |
| 19 | CH-str = L | pass | 20.1 ± 0.2 | 71.7 ± 1.2 | 4 | Streaming of other courses has positive impact even if no MA videos (shows students’ engagement) | CS, CH (with fail) | |
| CS-str = L | 12.4 ± 0.1 | 69.1 ± 0.7 | 6 | |||||
| MA-str = N, CH-str = L | 7.6 ± 0.3 | 72.5 ± 0.3 | 5 | |||||
| MA-str = N, CS-str = L | 5.5 ± 0.2 | 70.9 ± 0.9 | 8 | |||||
| Mid-way 1st semester | ||||||||
| 20 | MA-str = L | pass | 29.1 | 69 | 6 | Little of MA videos is enough, with or without other courses. Different from MA material: just-enough approach for video streaming | not CS (fail) | |
| MA-str = L, CH-str = L | 15.2 ± 0.1 | 70.6 ± 0.9 | 7 | |||||
| MA-str = L, CS-str = L, CH-str = N | 10.4 ± 0.1 | 70.2 ± 0.2 | 7 | |||||
| 21 | CH-str = L | pass | 24.9 ± 0.3 | 70.6 ± 1.3 | 4 | Streaming of other courses has positive impact, confirms | CS, CH (with fail) | |
| CS-str = L, MA-str = N, CH-str = N | 18.4 ± 0.2 | 68.2 ± 0.7 | 6 | |||||
| Close to 1st semester exams | ||||||||
| 22 | MA-str = L, CH-str = L | pass | 18.6 ± 0.2 | 69.9 ± 0.7 | 7 | Little of MA videos is enough, confirms | CS (with fail) | |
| 23 | MA-str = F, CH-str = F | pass | 28.9 ± 0.2 | 70.2 ± 0.7 | 4 | Streaming of other courses has positive impact, confirms and | CS, CH (with fail) | |
| MA-str = F, CS-str = F | 10.7 ± 0.2 | 69.6 ± 0.9 | 7 | |||||
| Num | Time ID | Body | Head | Support (%) | Confidence (%) | Lift | Description |
|---|---|---|---|---|---|---|---|
| Early 1st semester | |||||||
| 24 | MA-mat = N, MA-str = L | pass | 7.5 ± 0.1 | 90.2 ± 0.9 | 45 | Streaming is effective even without access to material | |
| 25 | MA-mat = N, MA-down = L | fail | 4.0 ± 0.1 | 65.2 ± 1.2 | 41 | Download is not effective without access to material | |
| Mid-way 1st semester—same rules | |||||||
| Close to 1st semester exams—same rules | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cagliero, L.; Canale, L.; Farinetti, L.; Baralis, E.; Venuto, E. Predicting Student Academic Performance by Means of Associative Classification. Appl. Sci. 2021, 11, 1420. https://doi.org/10.3390/app11041420
Cagliero L, Canale L, Farinetti L, Baralis E, Venuto E. Predicting Student Academic Performance by Means of Associative Classification. Applied Sciences. 2021; 11(4):1420. https://doi.org/10.3390/app11041420
Chicago/Turabian StyleCagliero, Luca, Lorenzo Canale, Laura Farinetti, Elena Baralis, and Enrico Venuto. 2021. "Predicting Student Academic Performance by Means of Associative Classification" Applied Sciences 11, no. 4: 1420. https://doi.org/10.3390/app11041420