Figure 1.
Sample images of RSSCN7 dataset: (1) grass, (2) field, (3) industrial area, (4) river/lake, (5) forest, (6) residential area, and (7) parking lot.
Figure 1.
Sample images of RSSCN7 dataset: (1) grass, (2) field, (3) industrial area, (4) river/lake, (5) forest, (6) residential area, and (7) parking lot.
Figure 2.
Sample images of WHU-RS19 dataset: (1) airport, (2) beach, (3) bridge, (4) commercial area, (5) desert, (6) farmland, (7) football field, (8) forest, (9) industrial area, (10) meadow, (11) mountain, (12) park, (13) parking lot, (14) pond, (15) port, (16) railway station, (17) residential area, (18) river, and (19) viaduct.
Figure 2.
Sample images of WHU-RS19 dataset: (1) airport, (2) beach, (3) bridge, (4) commercial area, (5) desert, (6) farmland, (7) football field, (8) forest, (9) industrial area, (10) meadow, (11) mountain, (12) park, (13) parking lot, (14) pond, (15) port, (16) railway station, (17) residential area, (18) river, and (19) viaduct.
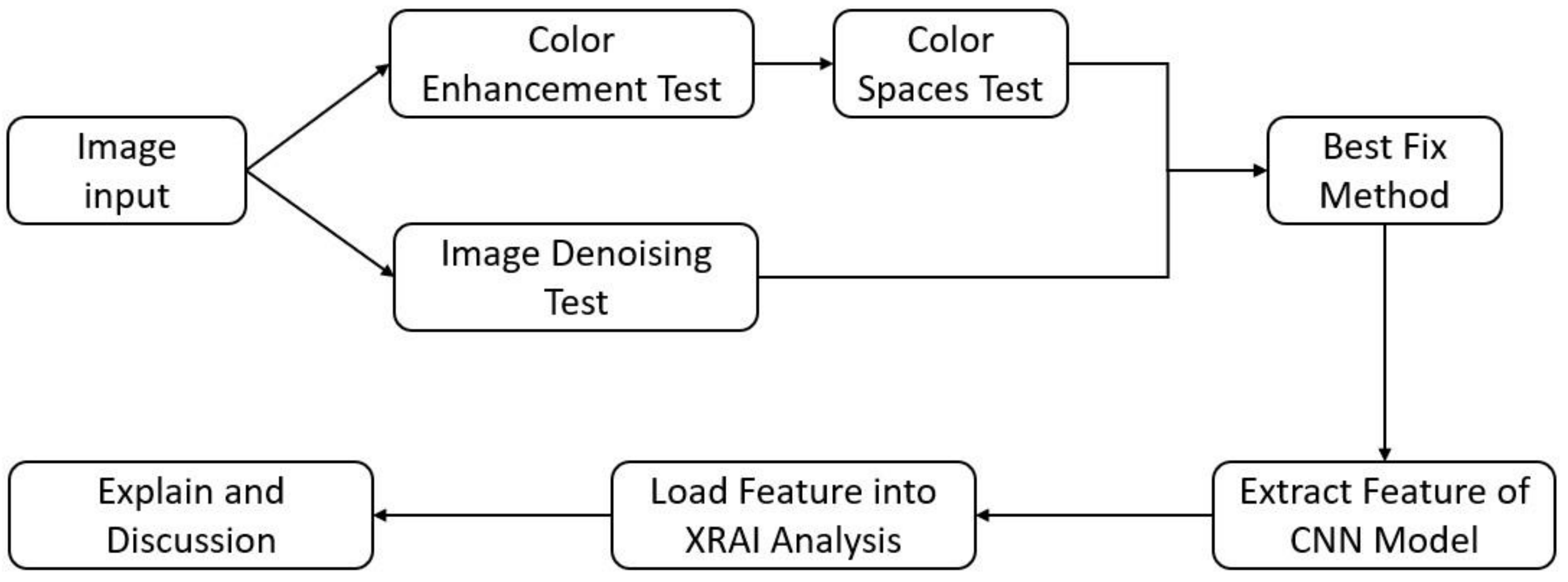
Figure 3.
Flowchart of the study design.
Figure 3.
Flowchart of the study design.
Figure 4.
(a) Original image. (b) Improved image using Gaussian Blur.
Figure 4.
(a) Original image. (b) Improved image using Gaussian Blur.
Figure 5.
(a) Original image. (b) Improved image using fastNlMeansDenoisingColored.
Figure 5.
(a) Original image. (b) Improved image using fastNlMeansDenoisingColored.
Figure 6.
(a) Original image. (b) Improved image using CLAHE.
Figure 6.
(a) Original image. (b) Improved image using CLAHE.
Figure 7.
(a) Original image. (b) Improved image using MSRCR.
Figure 7.
(a) Original image. (b) Improved image using MSRCR.
Figure 8.
(a) Original image. (b) XRAI shows the image feature hot zone.
Figure 8.
(a) Original image. (b) XRAI shows the image feature hot zone.
Figure 9.
RSSCNet classifier network architecture.
Figure 9.
RSSCNet classifier network architecture.
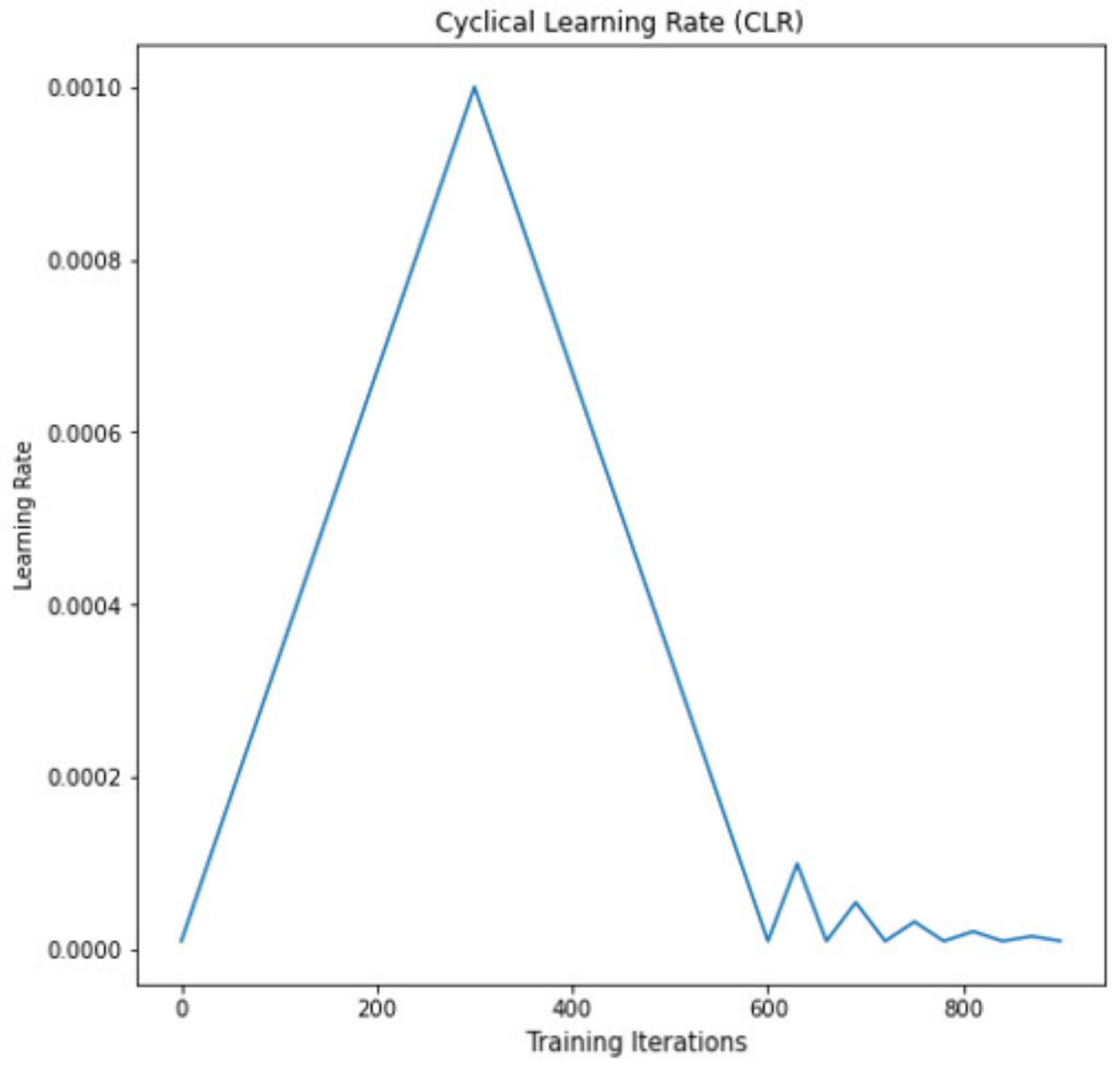
Figure 10.
Schematic of the two-stage cyclic learning rate training.
Figure 10.
Schematic of the two-stage cyclic learning rate training.
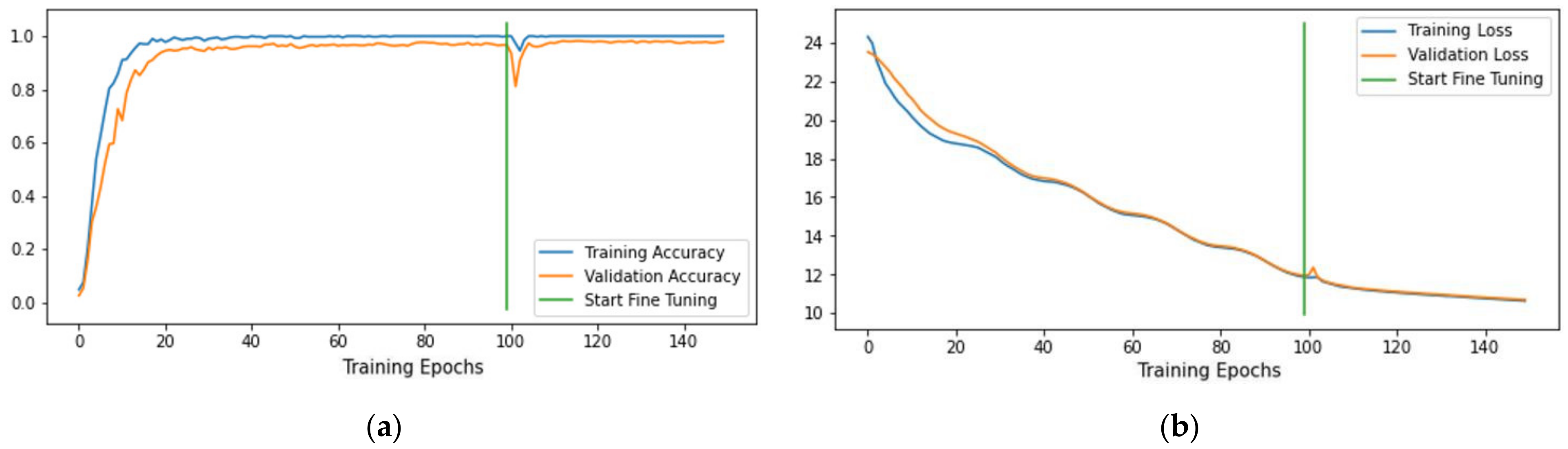
Figure 11.
Model training history of RSSCN7 dataset: (a) training and validation accuracy; (b) training and validation loss.
Figure 11.
Model training history of RSSCN7 dataset: (a) training and validation accuracy; (b) training and validation loss.
Figure 12.
Model training history of WHU-RS19 dataset: (a) training and validation accuracy; (b) training and validation loss.
Figure 12.
Model training history of WHU-RS19 dataset: (a) training and validation accuracy; (b) training and validation loss.
Figure 13.
Image (river/lakes category) with XRAI analysis. (a) Original image (predicted as Industry); (b) improved image.
Figure 13.
Image (river/lakes category) with XRAI analysis. (a) Original image (predicted as Industry); (b) improved image.
Figure 14.
Image (river/lakes category) with XRAI analysis. (a) Original image (predicted as field); (b) improved image.
Figure 14.
Image (river/lakes category) with XRAI analysis. (a) Original image (predicted as field); (b) improved image.
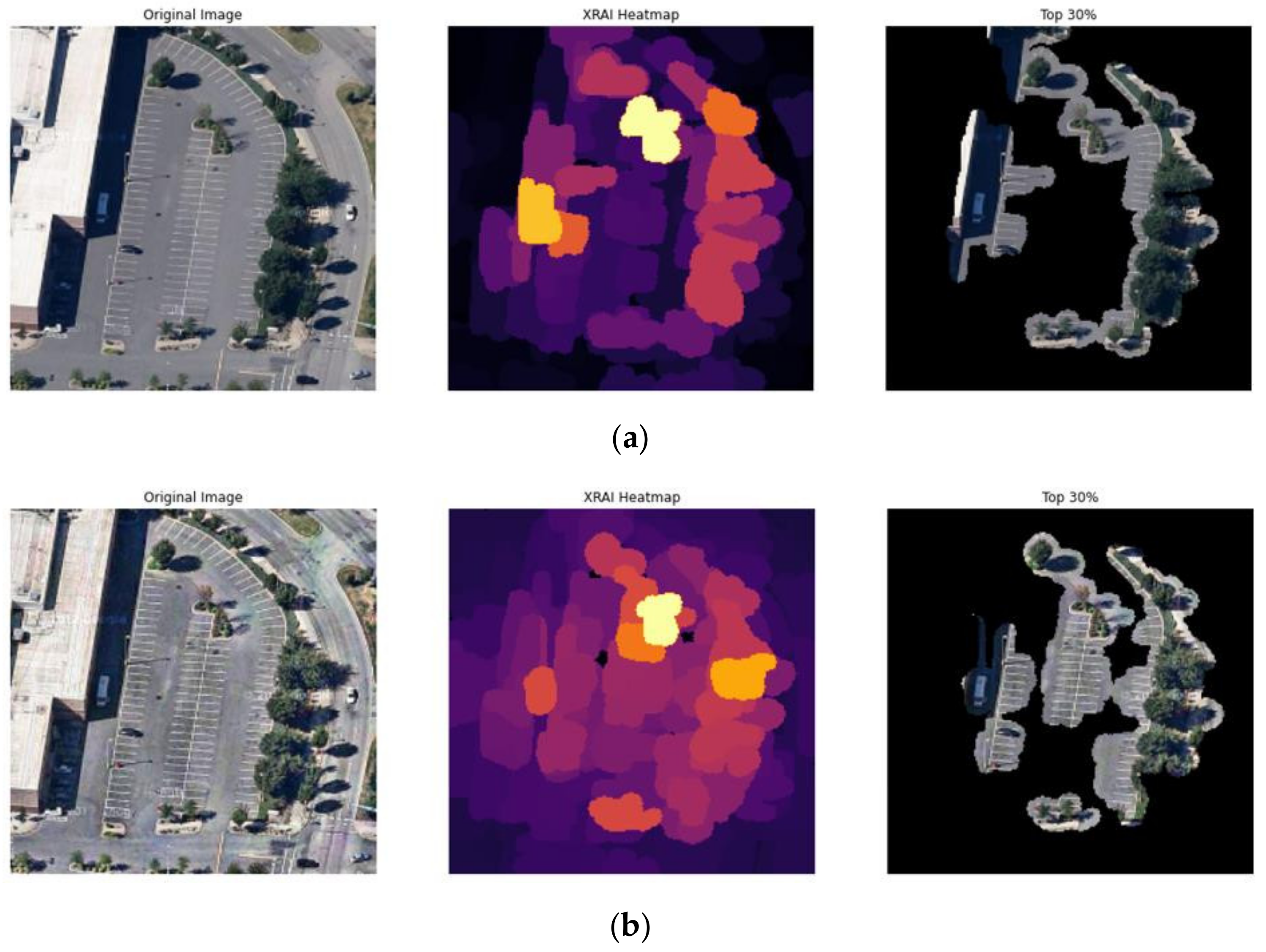
Figure 15.
Parking lot image with XRAI analysis. (a) Original image (predicted as industry); (b) improved image.
Figure 15.
Parking lot image with XRAI analysis. (a) Original image (predicted as industry); (b) improved image.
Table 1.
The main characteristics of the applied databases.
Table 1.
The main characteristics of the applied databases.
| Datasets | Images per Class | Classes | Total Images | Image Sizes | Year |
|---|
| RSSCN7 | 400 | 7 | 2800 | 400 × 400 | 2015 |
| WHU-RS19 | ~50 | 19 | 1005 | 600 × 600 | 2012 |
Table 2.
Effect of image denoising methods on RSSCN7 dataset.
Table 2.
Effect of image denoising methods on RSSCN7 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.9500 | 1330 |
| Blur Sharpen | 1.0 | 0.9536 | 1335 |
| Denoising | 1.0 | 0.9479 | 1327 |
| Denoising Sharpen | 1.0 | 0.9586 | 1342 |
| Blur Denoising Sharpen | 1.0 | 0.9550 | 1337 |
Table 3.
Effect of image denoising methods on WHU-RS19 dataset.
Table 3.
Effect of image denoising methods on WHU-RS19 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.9768 | 589 |
| Blur Sharpen | 1.0 | 0.9768 | 589 |
| Denoising | 1.0 | 0.9768 | 589 |
| Denoising Sharpen | 1.0 | 0.9801 | 591 |
| Blur Denoising Sharpen | 1.0 | 0.9801 | 591 |
Table 4.
Effects of image enhancement methods on RSSCN7 dataset.
Table 4.
Effects of image enhancement methods on RSSCN7 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.9500 | 1330 |
| CLAHE | 1.0 | 0.9586 | 1342 |
| MSRCP | 1.0 | 0.9429 | 1320 |
| Automated MSRCR | 1.0 | 0.9500 | 1330 |
Table 5.
Effects of image enhancement methods on WHU-RS19 dataset.
Table 5.
Effects of image enhancement methods on WHU-RS19 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.9768 | 589 |
| CLAHE | 1.0 | 0.9784 | 590 |
| MSRCP | 1.0 | 0.9619 | 580 |
| Automated MSRCR | 1.0 | 0.9635 | 581 |
Table 6.
Effects of color spaces on RSSCN7 dataset.
Table 6.
Effects of color spaces on RSSCN7 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.9500 | 1330 |
| RGB CLAHE | 1.0 | 0.9586 | 1342 |
| LAB CLAHE | 1.0 | 0.9514 | 1332 |
| HSV CLAHE | 1.0 | 0.9507 | 1331 |
Table 7.
Effect of the proposed method on RSSCN7 dataset.
Table 7.
Effect of the proposed method on RSSCN7 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.950 | 1330 |
| Denoising Sharpen with CLAHE | 1.0 | 0.965 | 1351 |
Table 8.
Effect of the proposed method on WHU-RS19 dataset.
Table 8.
Effect of the proposed method on WHU-RS19 dataset.
| Method | Training Accuracy | Test Accuracy | Test Correct Cases |
|---|
| Original Image | 1.0 | 0.9768 | 589 |
| Denoising Sharpen with CLAHE | 1.0 | 0.9801 | 591 |
Table 9.
Comparison of the overall accuracy on the RSSCN7 dataset.
Table 9.
Comparison of the overall accuracy on the RSSCN7 dataset.
| Method | Year | Training Ratio |
|---|
| 20% | 50% |
|---|
| DBN [10] | 2015 | NA | 77.00 |
| GoogLeNet [20] | 2016 | 82.55 ± 1.11 | 85.84 ± 0.92 |
| CaffNet [20] | 2016 | 85.57 ± 0.95 | 88.25 ± 0.62 |
| VGG-16 [20] | 2016 | 83.98 ± 0.87 | 87.18 ± 0.94 |
| Deep Filter Banks [21] | 2016 | NA | 90.4 ± 0.6 |
| GCFs+LOFs [22] | 2018 | 92.47 ± 0.29 | 95.59 ± 0.49 |
| RSSCNet [8] | 2020 | 93.51 ± 0.51 | 97.41 ± 0.27 |
| EfficientNetB3-Attn-2 [23] | 2021 | 93.30 ± 0.19 | 96.17 ± 0.23 |
| RSSCNet w/improved image (our) | 2021 | 93.76 ± 0.25 | 97.94 ± 0.18 |
Table 10.
Comparison of the overall accuracy on WHU-RS19 dataset.
Table 10.
Comparison of the overall accuracy on WHU-RS19 dataset.
| Method | Year | Training Ratio |
|---|
| 40% | 60% |
|---|
| GoogeNet [20] | 2015 | 93.12 ± 0.82 | 94.71 ± 1.33 |
| CaffNet [20] | 2016 | 95.11 ± 1.20 | 96.24 ± 0.56 |
| VGG-16 [20] | 2016 | 95.44 ± 0.60 | 96.05 ± 0.91 |
| TEX-Net-LF [24] | 2018 | 97.61 ± 0.36 | 98.00 ± 0.52 |
| Two-Stream Fusion [25] | 2019 | 98.23 ± 0.56 | 98.92 ± 0.52 |
| SE-MDPMNet [26] | 2019 | 98.46 ± 0.21 | 98.97 ± 0.24 |
| RSSCNet [8] | 2020 | 98.54 ± 0.37 | 99.46 ± 0.21 |
| EfficientNetB3-Attn-2 [23] | 2021 | 98.60 ± 0.40 | 98.68 ± 0.93 |
| RSSCNet w/improved image (our) | 2021 | 98.71 ± 0.23 | 99.58 ± 0.07 |





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}