
A Deep Learning Architecture for 3D Mapping Urban Landscapes

 , , and
, , and
Abstract
:1. Introduction
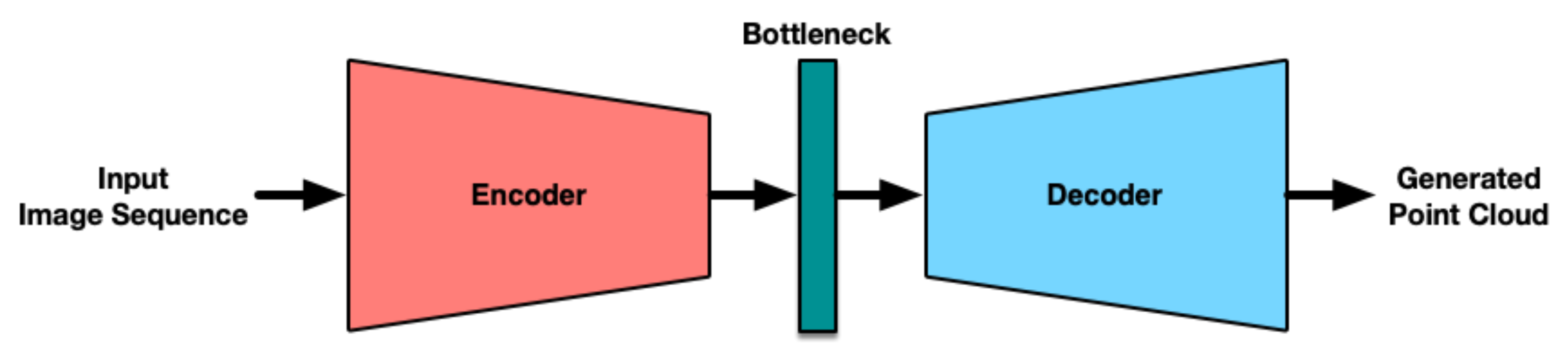
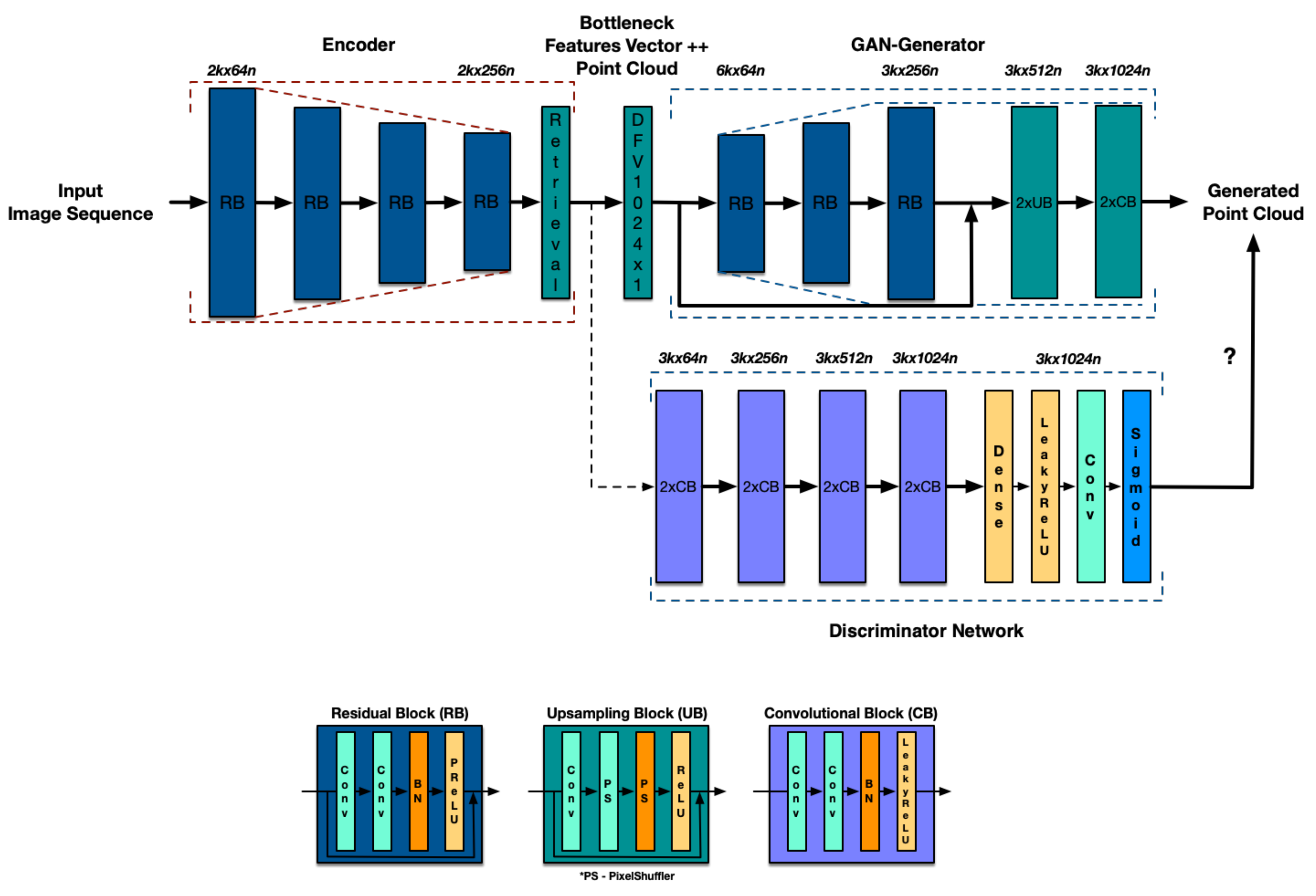
- Based on an Autoencoder architecture, we propose a deep residual neural network for the Encoder stage and a GAN network for the Decoder stage. This configuration generates a point cloud using a sequence of 2D aerial images as inputs. The proposed methodology does not need information from other sensors such as LiDARs to deliver reliable results similar to those of commercial software.
- This proposal works at different altitudes (100–400 m), at low overlapping percentages between each image (30–80%), and is independent of the flight path used to captured the image sequences of the target area.
2. Related Works
3. Network Architecture
3.1. Encoder
3.2. GAN-Decoder
3.2.1. Generator Network
3.2.2. Discriminator Network
3.3. Implementation Details
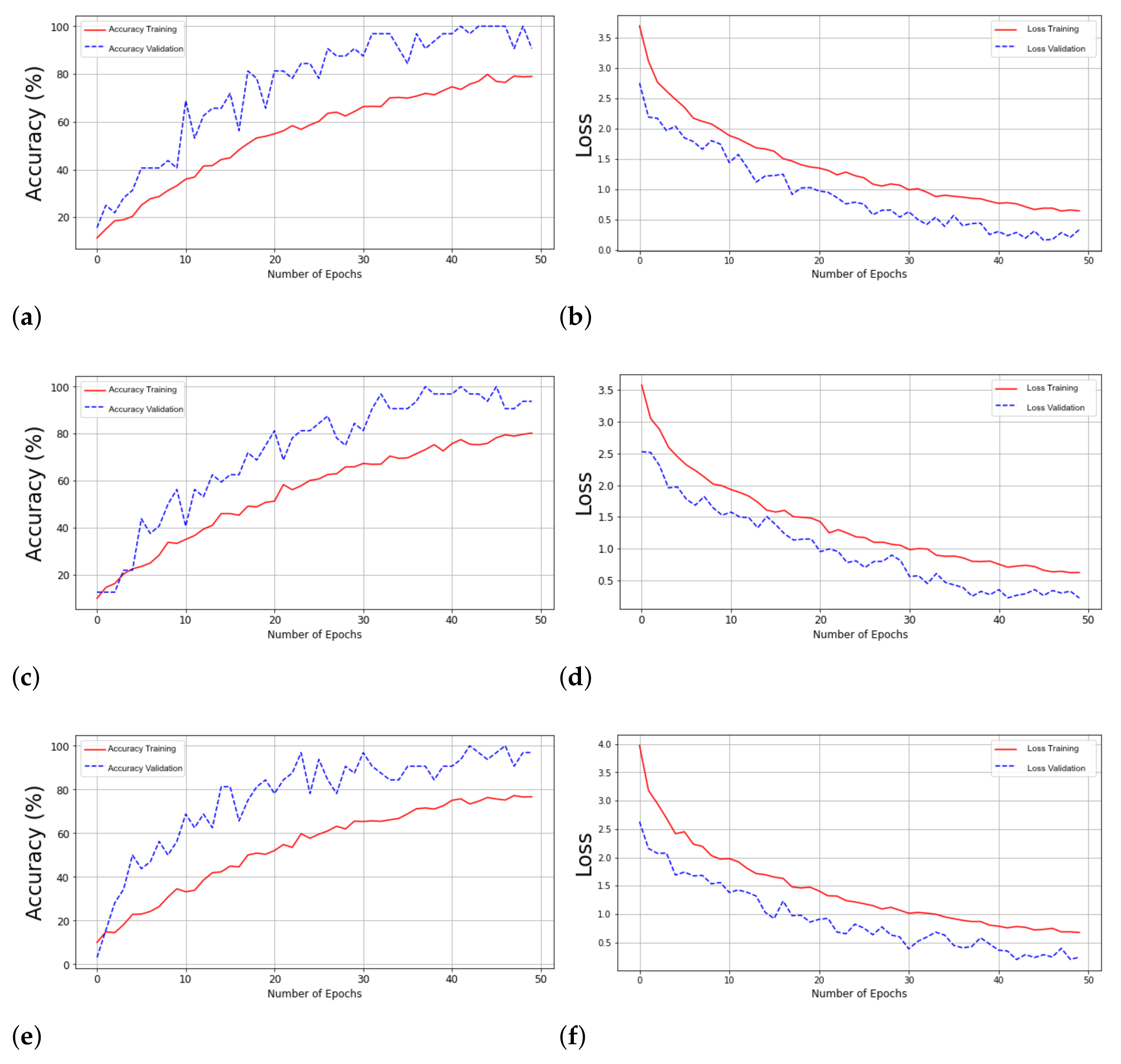
4. Experimental Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Beardsley, P.A.; Zisserman, A.; Murray, D.W. Sequential updating of projective and affine structure from motion. Int. J. Comput. Vis. 1997, 23, 235–259. [Google Scholar] [CrossRef]
- Molton, N.; Davison, A.J.; Reid, I. Locally Planar Patch Features for Real-Time Structure from Motion. In Proceedings of the British Machine Vision Conference, London, UK, 7–9 September 2004; pp. 1–10. [Google Scholar]
- Pollefeys, M.; Van Gool, L.; Vergauwen, M.; Verbiest, F.; Cornelis, K.; Tops, J.; Koch, R. Visual modeling with a hand-held camera. Int. J. Comput. Vis. 2004, 59, 207–232. [Google Scholar] [CrossRef]
- Akhter, I.; Sheikh, Y.; Khan, S.; Kanade, T. Nonrigid structure from motion in trajectory space. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, USA, 8–11 December 2008; pp. 41–48. [Google Scholar]
- Mouragnon, E.; Lhuillier, M.; Dhome, M.; Dekeyser, F.; Sayd, P. Generic and real-time structure from motion using local bundle adjustment. Image Vis. Comput. 2009, 27, 1178–1193. [Google Scholar] [CrossRef] [Green Version]
- Häming, K.; Peters, G. The structure-from-motion reconstruction pipeline—A survey with focus on short image sequences. Kybernetika 2010, 46, 926–937. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Carlone, L.; Tron, R.; Daniilidis, K.; Dellaert, F. Initialization techniques for 3D SLAM: A survey on rotation estimation and its use in pose graph optimization. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Washington, DC, USA, 26–30 May 2015; pp. 4597–4604. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Ren, R.; Fu, H.; Wu, M. Large-scale outdoor slam based on 2d lidar. Electronics 2019, 8, 613. [Google Scholar] [CrossRef] [Green Version]
- Golparvar-Fard, M.; Pena-Mora, F.; Savarese, S. Monitoring changes of 3D building elements from unordered photo collections. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 249–256. [Google Scholar]
- Rothermel, M.; Wenzel, K.; Fritsch, D.; Haala, N. SURE: Photogrammetric surface reconstruction from imagery. In Proceedings of the LC3D Workshop, Berlin, Germany, 4–5 December 2012; Volume 8. [Google Scholar]
- Nikolakopoulos, K.G.; Soura, K.; Koukouvelas, I.K.; Argyropoulos, N.G. UAV vs. classical aerial photogrammetry for archaeological studies. J. Archaeol. Sci. Rep. 2017, 14, 758–773. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, H.; Yang, W. Forests growth monitoring based on tree canopy 3D reconstruction using UAV aerial photogrammetry. Forests 2019, 10, 1052. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.H.; Hu, H.N.; Lin, C.H.; Tsai, Y.H.; Chiu, W.C.; Sun, M. 3D lidar and stereo fusion using stereo matching network with conditional cost volume normalization. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5895–5902. [Google Scholar]
- Cheng, X.; Wang, P.; Guan, C.; Yang, R. Cspn++: Learning context and resource aware convolutional spatial propagation networks for depth completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10615–10622. [Google Scholar]
- Choe, J.; Joo, K.; Imtiaz, T.; Kweon, I.S. Volumetric propagation network: Stereo-lidar fusion for long-range depth estimation. IEEE Robot. Autom. Lett. 2021, 6, 4672–4679. [Google Scholar] [CrossRef]
- Afifi, A.J.; Magnusson, J.; Soomro, T.A.; Hellwich, O. Pixel2Point: 3D object reconstruction from a single image using CNN and initial sphere. IEEE Access 2020, 9, 110–121. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Z.; Liu, T.; Peng, B.; Li, X. RealPoint3D: An efficient generation network for 3D object reconstruction from a single image. IEEE Access 2019, 7, 57539–57549. [Google Scholar] [CrossRef]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial Autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. arXiv 2019, arXiv:1906.02691. [Google Scholar]
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 193–208. [Google Scholar]
- Tolooshams, B.; Dey, S.; Ba, D. Deep residual autoencoders for expectation maximization-inspired dictionary learning. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 2415–2429. [Google Scholar] [CrossRef]
- Zamorski, M.; Zięba, M.; Klukowski, P.; Nowak, R.; Kurach, K.; Stokowiec, W.; Trzciński, T. Adversarial autoencoders for compact representations of 3D point clouds. Comput. Vis. Image Underst. 2020, 193, 102921. [Google Scholar] [CrossRef] [Green Version]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled Generative Adversarial Networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Makhzani, A.; Frey, B. PixelGAN Autoencoders. arXiv 2017, arXiv:1706.00531. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mo, S.; Zabaras, N.; Shi, X.; Wu, J. Integration of adversarial autoencoders with residual dense convolutional networks for estimation of non-Gaussian hydraulic conductivities. Water Resour. Res. 2020, 56, e2019WR026082. [Google Scholar] [CrossRef] [Green Version]
- Bresson, G.; Alsayed, Z.; Yu, L.; Glaser, S. Simultaneous localization and mapping: A survey of current trends in autonomous driving. IEEE Trans. Intell. Veh. 2017, 2, 194–220. [Google Scholar] [CrossRef] [Green Version]
- Nüchter, A.; Lingemann, K.; Hertzberg, J.; Surmann, H. 6D SLAM—3D mapping outdoor environments. J. Field Robot. 2007, 24, 699–722. [Google Scholar] [CrossRef] [Green Version]
- Suzuki, T.; Amano, Y.; Hashizume, T.; Suzuki, S. 3D terrain reconstruction by small unmanned aerial vehicle using SIFT-based monocular SLAM. J. Robot. Mechatronics 2011, 23, 292–301. [Google Scholar] [CrossRef]
- Shang, Z.; Shen, Z. Real-time 3D Reconstruction on Construction Site using Visual SLAM and UAV. arXiv 2017, arXiv:1712.07122. [Google Scholar]
- Kurenkov, A.; Ji, J.; Garg, A.; Mehta, V.; Gwak, J.; Choy, C.; Savarese, S. Deformnet: Free-form deformation network for 3d shape reconstruction from a single image. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 858–866. [Google Scholar]
- Mandikal, P.; Navaneet, K.L.; Agarwal, M.; Venkatesh Babu, R. 3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image. arXiv 2018, arXiv:1807.07796. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2mesh: Generating 3d mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 52–67. [Google Scholar]
- Lu, Q.; Lu, Y.; Xiao, M.; Yuan, X.; Jia, W. 3D-FHNet: Three-dimensional fusion hierarchical reconstruction method for any number of views. IEEE Access 2019, 7, 172902–172912. [Google Scholar] [CrossRef]
- Lu, Q.; Xiao, M.; Lu, Y.; Yuan, X.; Yu, Y. Attention-based dense point cloud reconstruction from a single image. IEEE Access 2019, 7, 137420–137431. [Google Scholar] [CrossRef]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Data-driven 3d voxel patterns for object category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1903–1911. [Google Scholar]
- Tang, J.; Folkesson, J.; Jensfelt, P. Geometric Correspondence Network for Camera Motion Estimation. IEEE Robot. Autom. Lett. 2018, 3, 1010–1017. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Lu, P.; Chen, Y.; Wang, G. Large-scale structure from motion with semantic constraints of aerial images. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 347–359. [Google Scholar]
- Dissegna, M.A.; Yin, T.; Wei, S.; Richards, D.; Grêt-Regamey, A. 3-D reconstruction of an urban landscape to assess the influence of vegetation in the radiative budget. Forests 2019, 10, 700. [Google Scholar] [CrossRef] [Green Version]
- Özdemir, E.; Toschi, I.; Remondino, F. A multi-purpose benchmark for photogrammetric urban 3D reconstruction in a controlled environment. In Proceedings of the Evaluation and Benchmarking Sensors, Systems and Geospatial Data in Photogrammetry and Remote Sensing, Warsaw, Poland, 16–17 September 2019; Volume 42, pp. 53–60. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. (NIPS) 2014, 27, 2672–2680. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.; Ba, J. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar] [CrossRef] [Green Version]
- Ni, D.; Nee, A.; Ong, S.; Li, H.; Zhu, C.; Song, A. Point cloud augmented virtual reality environment with haptic constraints for teleoperation. Trans. Inst. Meas. Control 2018, 40, 4091–4104. [Google Scholar] [CrossRef]
- Hui, Z.; Jin, S.; Cheng, P.; Ziggah, Y.Y.; Wang, L.; Wang, Y.; Hu, H.; Hu, Y. An Active Learning Method for DEM Extraction from Airborne LiDAR Point Clouds. IEEE Access 2019, 7, 89366–89378. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, Z.; Yi, L.; Mo, K.; Su, H.; Guibas, L.J. Rethinking Sampling in 3D Point Cloud Generative Adversarial Networks. arXiv 2020, arXiv:2006.07029. [Google Scholar]
- Navaneet, K.; Mandikal, P.; Agarwal, M.; Babu, R.V. Capnet: Continuous approximation projection for 3d point cloud reconstruction using 2d supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8819–8826. [Google Scholar]
- Nacken, P.F. Chamfer metrics in mathematical morphology. J. Math. Imaging Vis. 1994, 4, 233–253. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhang, Y.; Zhao, X.; Gao, Y. EMD Metric Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Mandikal, P.; Radhakrishnan, V.B. Dense 3d point cloud reconstruction using a deep pyramid network. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1052–1060. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Height\Overlapping | 30% × 30% | 50% × 50% | ||
|---|---|---|---|---|
| 100 m. | 300 | 700 | ||
| 150 m. | 300 | 700 | ||
| Total | 600 | 1400 |
| Selected Area | ||||
|---|---|---|---|---|
| Overlapping = | ||||
| Main courtyard | 11.99 | 18.51 | 50 min | 90 min |
| Laboratory buildings | 18.56 | 20.15 | 98 min | 180 min |
| Institute buildings | 21.56 | 32.15 | 120 min | 180 min |
| Classroom buildings | 18.79 | 20.23 | 80 min | 120 min |
| Overlapping = | ||||
| Main courtyard | 41.99 | 48.51 | 30 min | 50 min |
| Laboratory buildings | 58.56 | 50.15 | 60 min | 80 min |
| Institute buildings | 41.56 | 62.15 | 80 min | 70 min |
| Classroom buildings | 58.79 | 40.23 | 50 min | 70 min |
| Overlapping = | ||||
| Main courtyard | 51.99 | 45.51 | 30 min | 60 min |
| Laboratory buildings | – | – | 30 min | 60 min |
| Institute buildings | 61.56 | 62.15 | 40 min | 60 min |
| Classroom buildings | – | – | 30 min | 60 min |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Santiago, A.L.; Arias-Aguilar, J.A.; Takemura, H.; Petrilli-Barceló, A.E. A Deep Learning Architecture for 3D Mapping Urban Landscapes. Appl. Sci. 2021, 11, 11551. https://doi.org/10.3390/app112311551
Rodríguez-Santiago AL, Arias-Aguilar JA, Takemura H, Petrilli-Barceló AE. A Deep Learning Architecture for 3D Mapping Urban Landscapes. Applied Sciences. 2021; 11(23):11551. https://doi.org/10.3390/app112311551
Chicago/Turabian StyleRodríguez-Santiago, Armando Levid, José Aníbal Arias-Aguilar, Hiroshi Takemura, and Alberto Elías Petrilli-Barceló. 2021. "A Deep Learning Architecture for 3D Mapping Urban Landscapes" Applied Sciences 11, no. 23: 11551. https://doi.org/10.3390/app112311551