
A Robust Face Recognition Algorithm Based on an Improved Generative Confrontation Network


Abstract
:1. Introduction
2. Related Theories
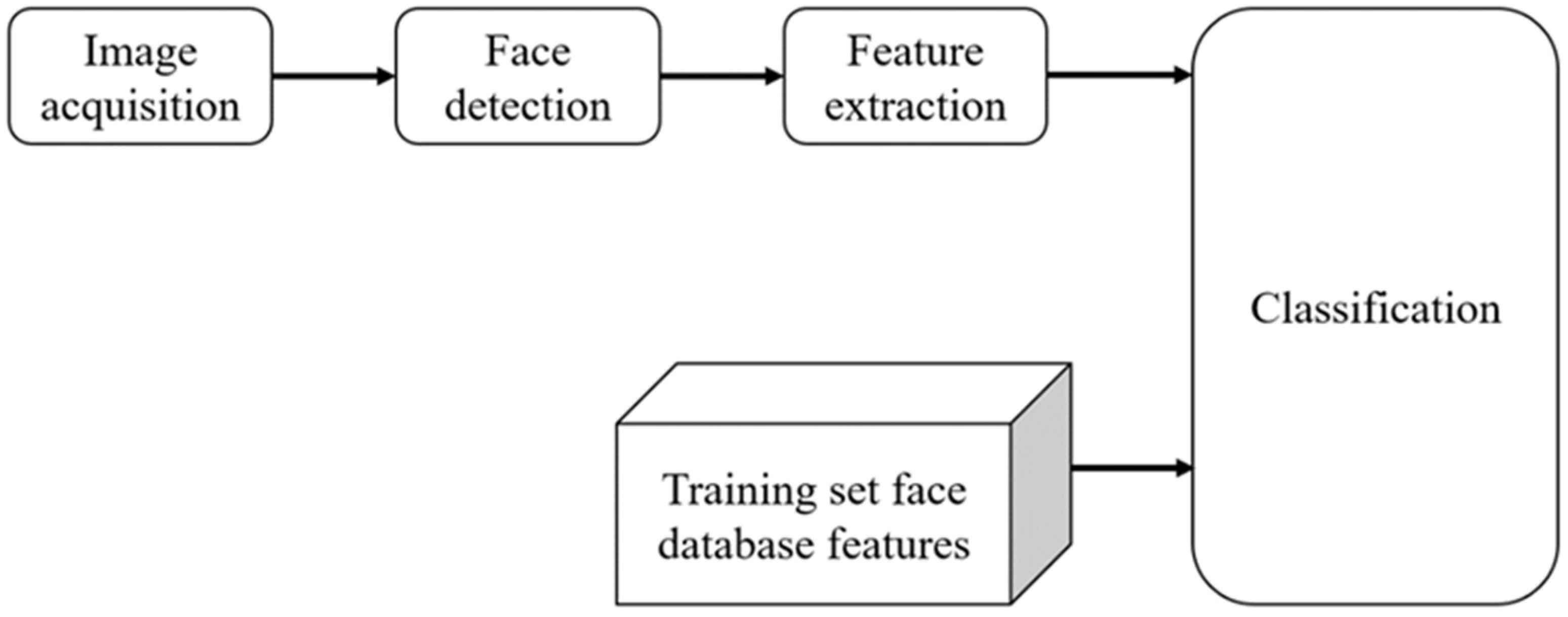
2.1. Face Recognition
2.2. Effective Use of Irrelevant Facial Features
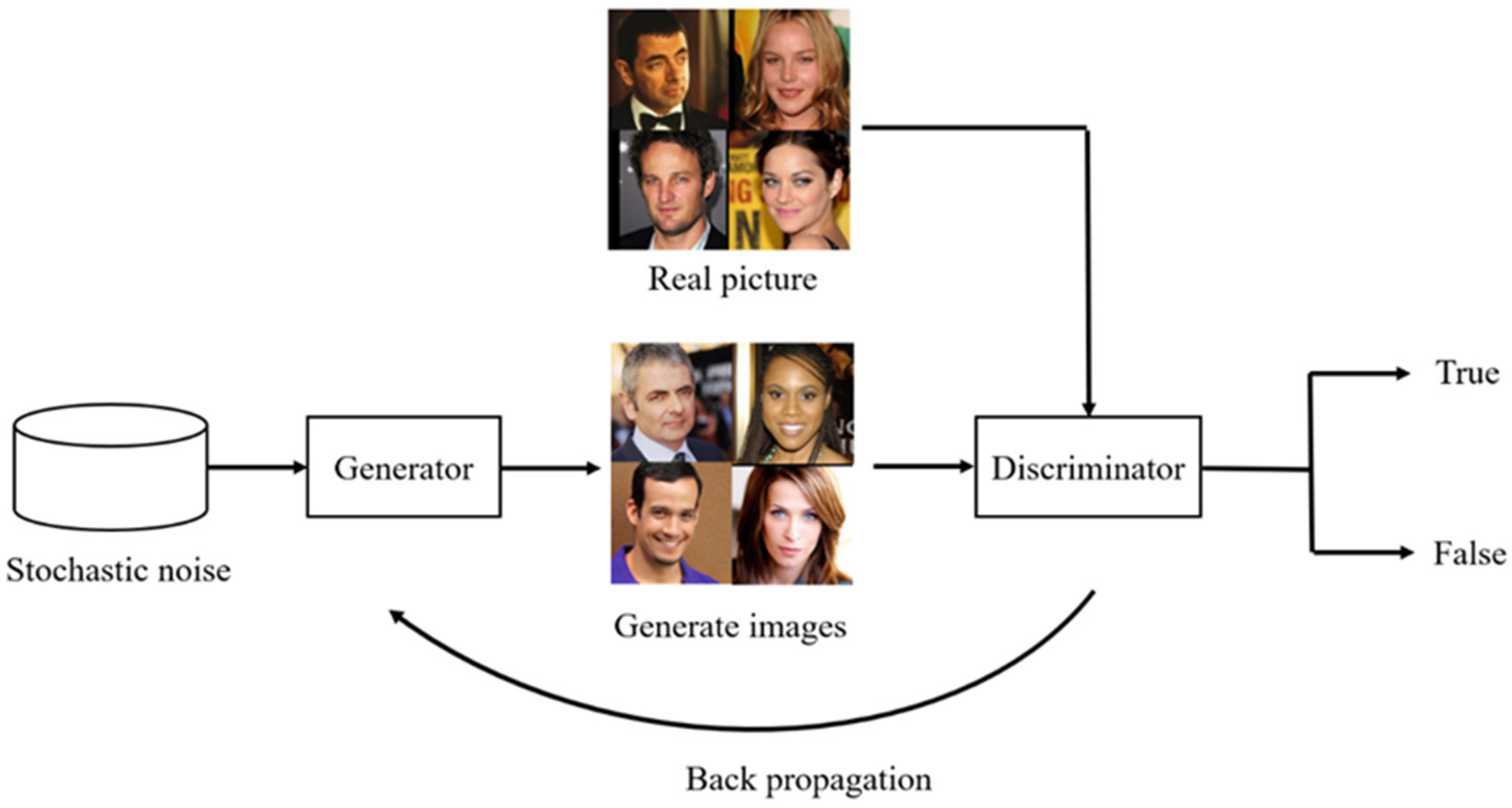
2.3. Generative Adversarial Network
3. Methods
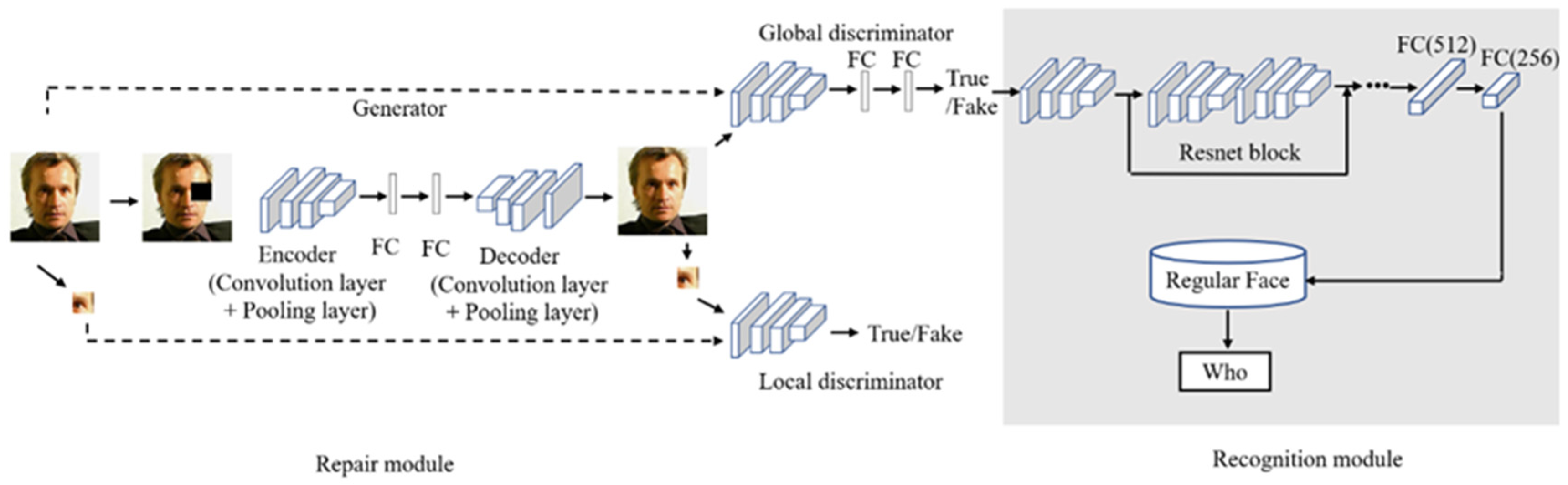
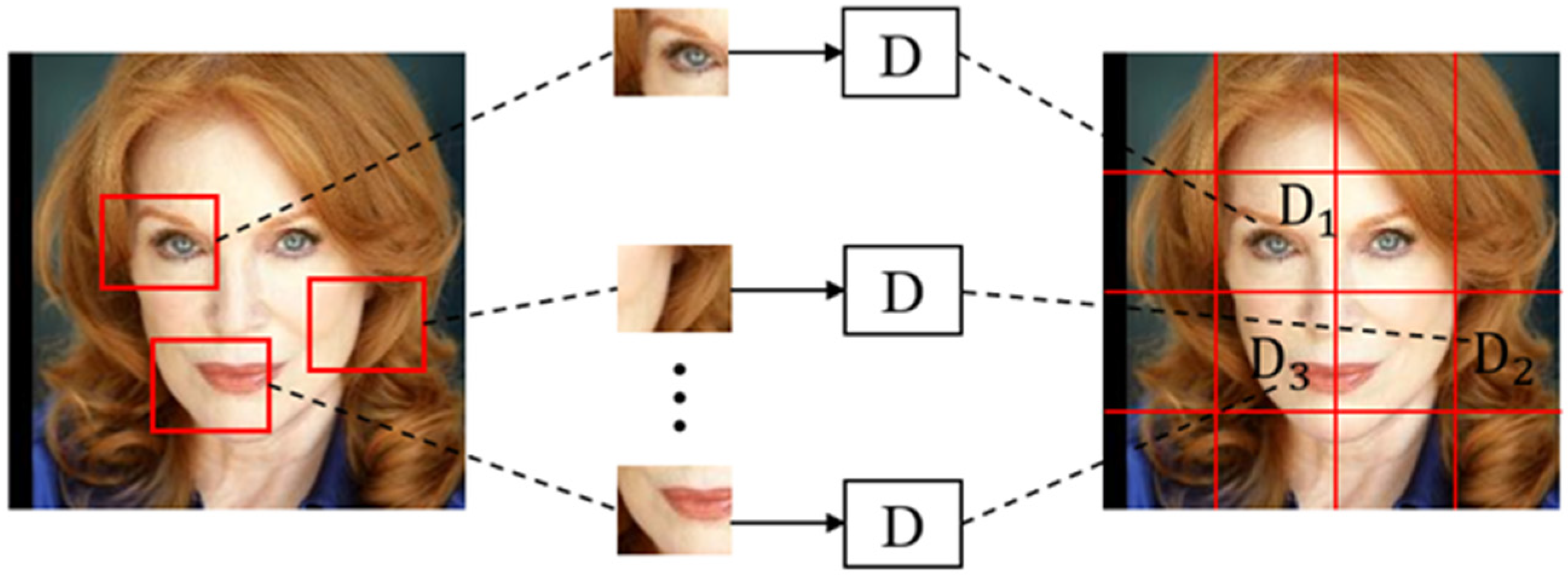
3.1. Face Recognition Model Based on Dual Discriminant Confrontation Network
3.2. Loss Function
4. Experiments
4.1. Simulation Experiment
4.2. Data Preprocessing
4.3. Model Training
5. Results and Discussion
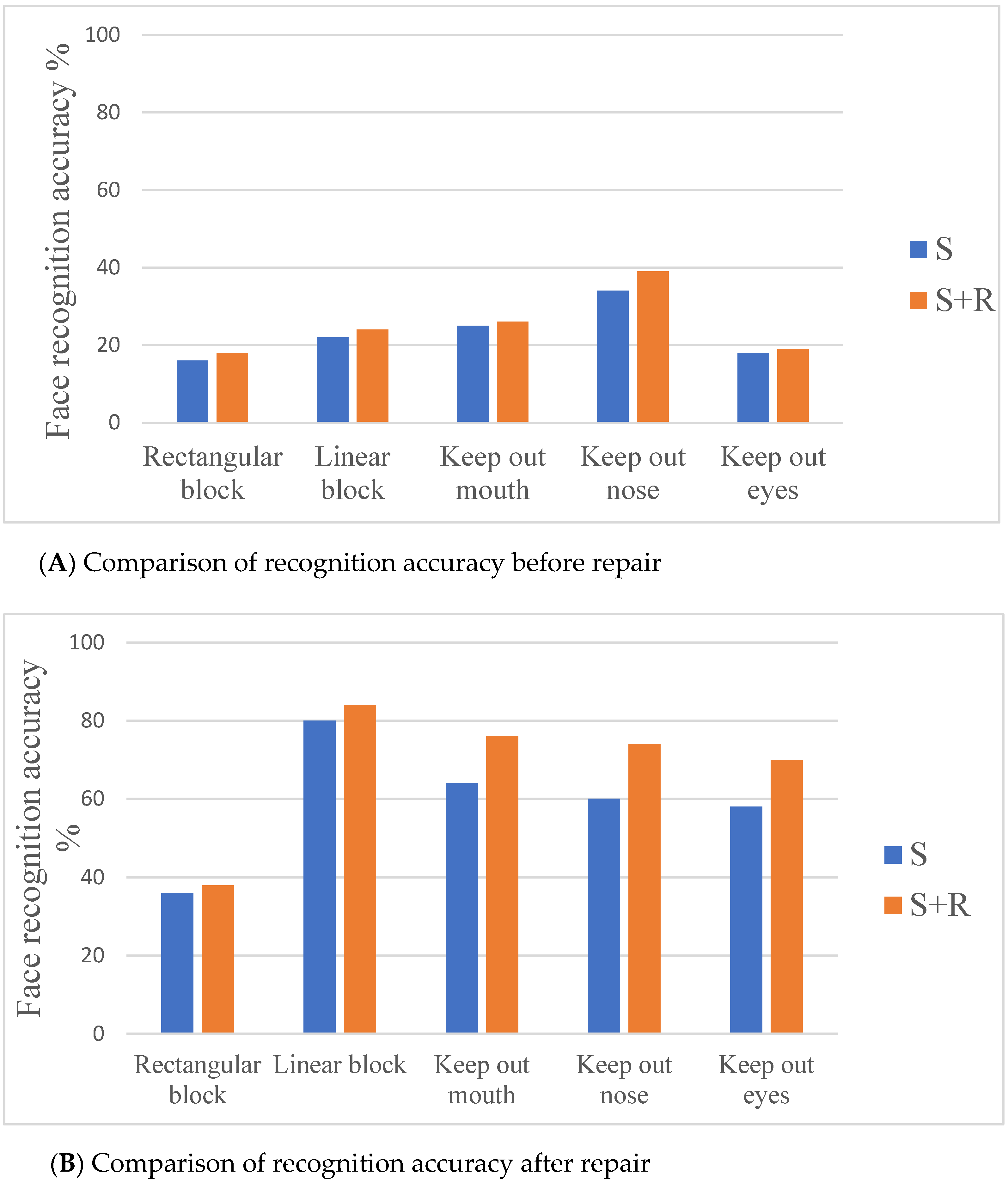
5.1. Image Restoration Results
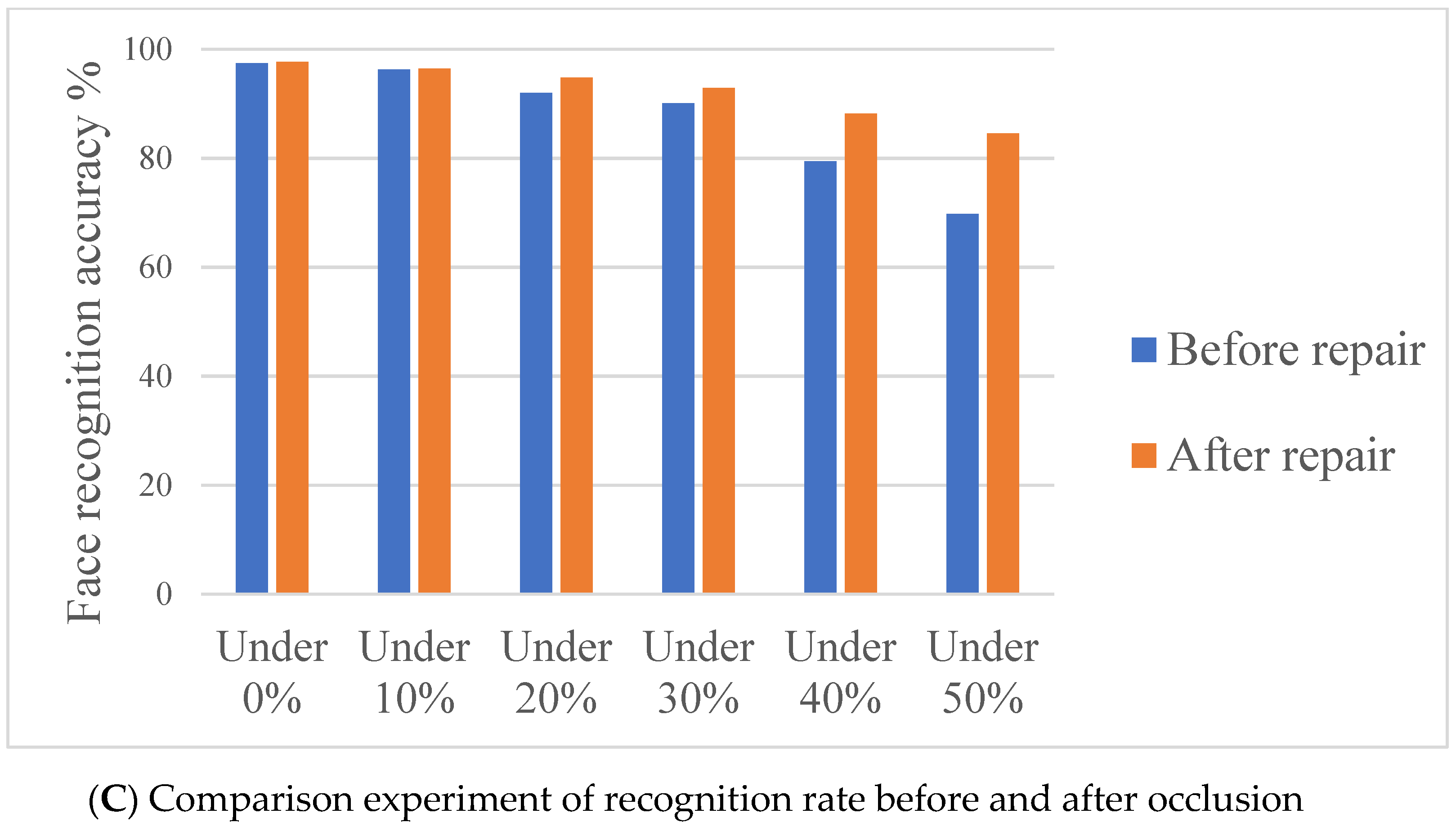
5.2. Network Performance Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, C. Overview of Face Recognition Technology. Intell. Comput. Appl. 2016, 6, 112–114. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-time Face Verification on Mobile Devices. In Proceeding of Chinese Conference on Biometric Recognition; Springer: Cham, Switzerland; Berlin, Germany, 2018; pp. 428–438. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Zhu, M.H.; Li, S.T.; Ye, H. Facial expression recognition method based on sparse representation. Pattern Recognit. Artif. Intell. 2014, 27, 708–712. [Google Scholar]
- Xue, Y.; Mao, X.; Catalin-Daniel, C.; Lv, S. Robust facial expression recognition method under occlusion conditions. J. Beijing Univ. Aeronaut. Astronaut. 2010, 36, 429–433. [Google Scholar]
- Tang, Z.; Li, Y.; Chai, X.; Zhang, H.; Cao, S. Adaptive Nonlinear Model Predictive Control of NOx Emissions under Load Constraints in Power Plant Boilers. J. Chem. Eng. Japan. 2020, 53, 36–44. [Google Scholar] [CrossRef] [Green Version]
- Ou, J. Classification Algorithms Research on Facial Expression Recognition. Phys. Procedia 2012, 25, 1241–1244. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Yang, J.; Xiao, J.; Li, S.; Zhou, D. Face Recognition Based on Deep Learning. In Proceeding of the International Conference on Human Centered Computing; Springer: Cham, Switzerland; Berlin, Germany, 2015; pp. 812–820. [Google Scholar]
- Grm, K.; Štruc, V.; Artiges, A.; Caron, M.; Ekenel, H.K. Strengths and weaknesses of deep learning models for face recognition against image degradations. IET Biom. 2018, 7, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Lv, Y.; Zhou, Z.; Cao, F. A novel deep learning algorithm for incomplete face recognition: Low-rank-recovery network. Neural Netw. 2017, 13, 94. [Google Scholar] [CrossRef]
- Yu, C.; Pei, H. Face recognition framework based on effective computing and adversarial neural network and its implementation in machine vision for social robots. Comput. Electr. Eng. 2021, 92, 107128. [Google Scholar] [CrossRef]
- Yu, Y.; Huang, F.H. Face Recognition with Noise Based on Fast PCA and Simplified PSO. J. Qinghai Univ. 2020, 38, 49–57. [Google Scholar]
- Zhang, Z.; Yang, Q. Target recognition method based on BP neural network and improved DS evidence theory. Comput. Appl. Softw. 2018, 35, 6151–6156. [Google Scholar]
- Tang, Z.; Zhao, G.; Ouyang, T. Two-phase deep learning model for short-term wind direction forecasting. Renew. Energy 2021, 173, 1005–1016. [Google Scholar] [CrossRef]
- Li, X.X.; Liang, R.H. An overview of occluded face recognition: from subspace back to depth learning. Chin. J. Comput. 2018, 41, 177–207. [Google Scholar]
- Goel, T.; Murugan, R. Deep Convolutional—Optimized Kernel Extreme Learning Machine Based Classifier for Face Recognition. Comput. Electr. Eng. 2020, 85, 106640. [Google Scholar] [CrossRef]
- Jing, C.K.; Song, T.; Zhuang, L. A review of face recognition technology based on deep convolutional neural network. Comput. Appl. Softw. 2018, 35, 223–231. [Google Scholar]
- Yu, T.; Tong, Y.; Cao, X.H. An Occlusion Face Recognition Algorithm Based on Iterative Weighted Low-rank Decorption. Comput. Technol. Dev. 2019, 29, 42–46. [Google Scholar]
- Gou, J.; Song, J.; Ou, W.; Zeng, S.; Yuan, Y.; Du, L. Representation-based classification methods with enhanced linear reconstruction measures for face recognition. Comput. Electr. Eng. 2019, 79, 106451. [Google Scholar] [CrossRef]
- Wang, W.M.; Tang, Y.; Zhang, J.; Zhang, Y.Q. Face Recognition Algorithm Based on Convolutional Neural Network Feature Fusion. Comput. Digit. Eng. 2020, 1, 88–92. [Google Scholar]
- Sun, X.; Pan, T.; Ren, F.J. Facial Expression Recognition Based on ROI-KNN Convolutional Neural Network. Acta Autom. Sin. 2016, 42, 883–891. [Google Scholar]
- Zhang, F.Y.; Wang, X.; Xu, X.Z. Structured Occlusion Coding and Extreme Learning Machine Local occlusion face recognition. Comput. Appl. 2019, 39, 2893–2898. [Google Scholar]
- Cao, Z.; Yang, Y.; Qi, Y. Image restoration method based on multi-loss constraint and attention block. J. Shaanxi Univ. Sci. Technol. 2020, 38, 158–165. [Google Scholar]
- Chen, J.Z.; Wang, J.; Gong, X. Face map based on cascading generation adversarial network. J. Univ. Electron. Sci. Technol. China 2019, 48, 910–917. [Google Scholar]
- Feng, X.R.; Hui, K.H.; Liu, Z.D. Face recognition based on convolution feature and Bayesian classifier. J. Intell. Syst. 2018, 73, 101–107. [Google Scholar]
- Qiu, D.; Zheng, L.; Zhu, J.; Huang, D. Multiple improved residual networks for medical image super-resolution. Futur. Gener. Comput. Syst. 2020, 116, 200–208. [Google Scholar] [CrossRef]
- Zhao, S.W.; Zhang, R.X.; Wang, Y.M. Review of biometric identification technology. China Secur. 2015, 7, 79–86. [Google Scholar]
- Hu, L.Q. Research on Feature Extraction Algorithm of Face Recognition under Complex Conditions. Master’s Thesis, Donghua University, Shanghai, China, 2016. [Google Scholar]
- Lin, Z.M. Research on Improved PSO Face Recognition Algorithm. J. Nat. Sci. Harbin Norm. Univ. 2020, 36, 51–55. [Google Scholar]
- Zhang, D.F.; Gao, N.H.; Wang, H.; Feng, X.H.; Huo, J.W.; Zhang, J. Based on block LBP fusion feature And SVM face recognition algorithm. Transducers Microsyst. 2019, 38, 154–156. [Google Scholar]
- Liu, L.; Li, D. Patents Analysis of Face Recognition Technology in Surveillance System. Sci. Technol. Innov. Appl. 2021, 2, 46–47. [Google Scholar]
- Duan, J.W. Research on face recognition technology in big data environment. Electron. World 2019, 1, 185–187. [Google Scholar]
- Chen, K.; Xing, X.Y.; Tian, X.Y.; Wang, S. Design of face recognition access control system based on CNN. J. Xuzhou Inst. Technol. (Nat. Sci. Ed.) 2018, 33, 89–92. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optimization | G Learning Rate | D Learning Rate | Number of Batches | Number of Iterations |
|---|---|---|---|---|
| Adam | 0.0002 | 0.0002 | 250 | 300 |
| Optimization | G Learning Rate | D Learning Rate | Number of Batches | Number of Iterations | Balance Parameter λ |
|---|---|---|---|---|---|
| Adam | 0.0005 | 1 × 10−8 | 128 | 100 | 1 |
| Method | Unobstructed | Random Occlusion 10% | Random Occlusion 20% | Random Occlusion 30% | Random Occlusion 40% | Random Occlusion 50% |
|---|---|---|---|---|---|---|
| PCA + SVM | 91.24 | 89.41 | 85.94 | 84.13 | 79.23 | 68.88 |
| SRC | 92.56 | 90.34 | 87.95 | 95.23 | 79.82 | 55.82 |
| CNN | 97.65 | 94.92 | 92.75 | 88.96 | 78.11 | 67.57 |
| DCGAN + CNN | 97.65 | 92.76 | 89.95 | 82.45 | 78.82 | 70.24 |
| Paper model | 97.65 | 96.45 | 94.78 | 92.89 | 92.23 | 84.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, H.; Dai, Y.; Zhu, Z.; Wang, B. A Robust Face Recognition Algorithm Based on an Improved Generative Confrontation Network. Appl. Sci. 2021, 11, 11588. https://doi.org/10.3390/app112411588
Ge H, Dai Y, Zhu Z, Wang B. A Robust Face Recognition Algorithm Based on an Improved Generative Confrontation Network. Applied Sciences. 2021; 11(24):11588. https://doi.org/10.3390/app112411588
Chicago/Turabian StyleGe, Huilin, Yuewei Dai, Zhiyu Zhu, and Biao Wang. 2021. "A Robust Face Recognition Algorithm Based on an Improved Generative Confrontation Network" Applied Sciences 11, no. 24: 11588. https://doi.org/10.3390/app112411588