
Ensemble Learning for Threat Classification in Network Intrusion Detection on a Security Monitoring System for Renewable Energy †


Abstract
:1. Introduction
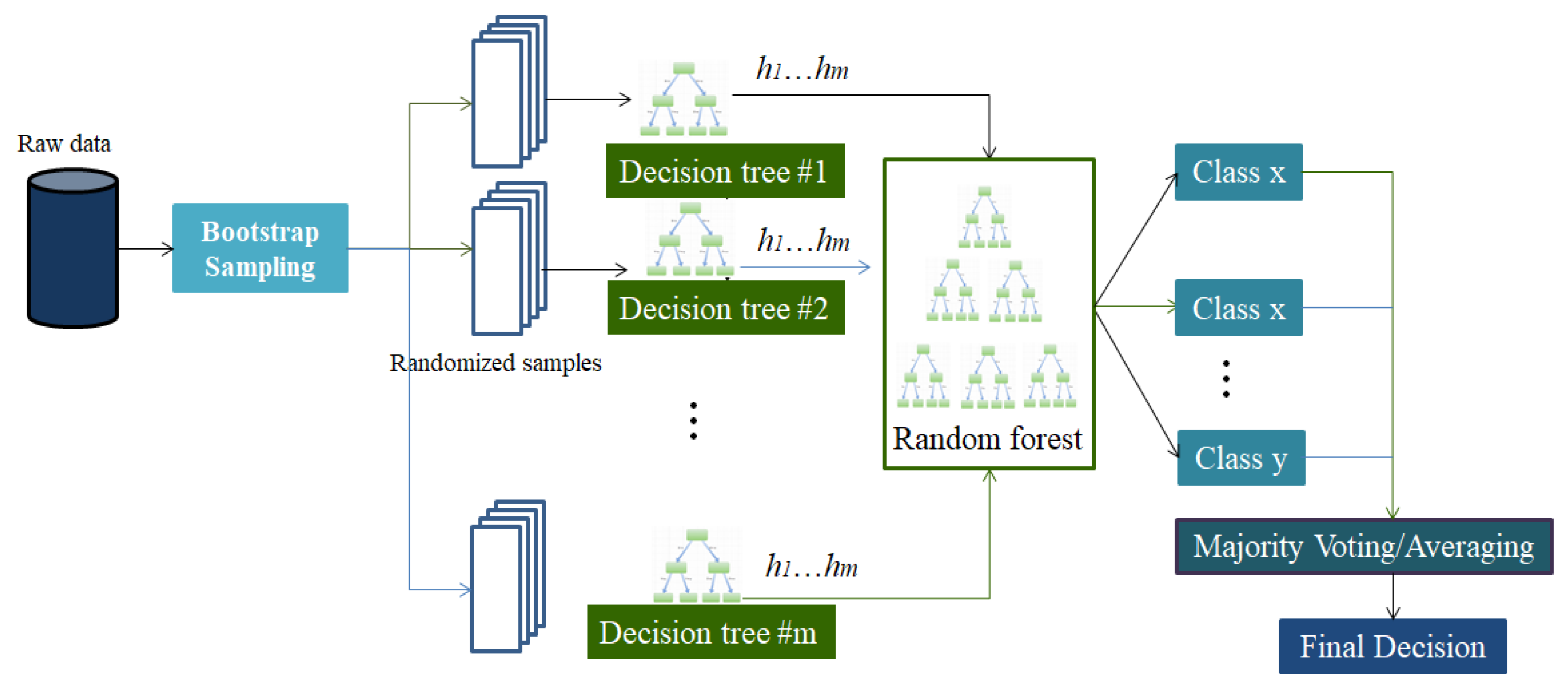
- Multiclass threat classification was achieved using the RF method. Moreover, sources of open intrusion attacks in the UNSW-NB15 and CSE-CIC-IDS 2018 data sets were accurately classified, indicating our method’s ability to classify threats as part of an NIDS;
- To improve the performance of random forests, the RF is incorporated with C4.5 algorithm to dimension reduction of training data that accelerates the training time of high-dimensional data in the model training;
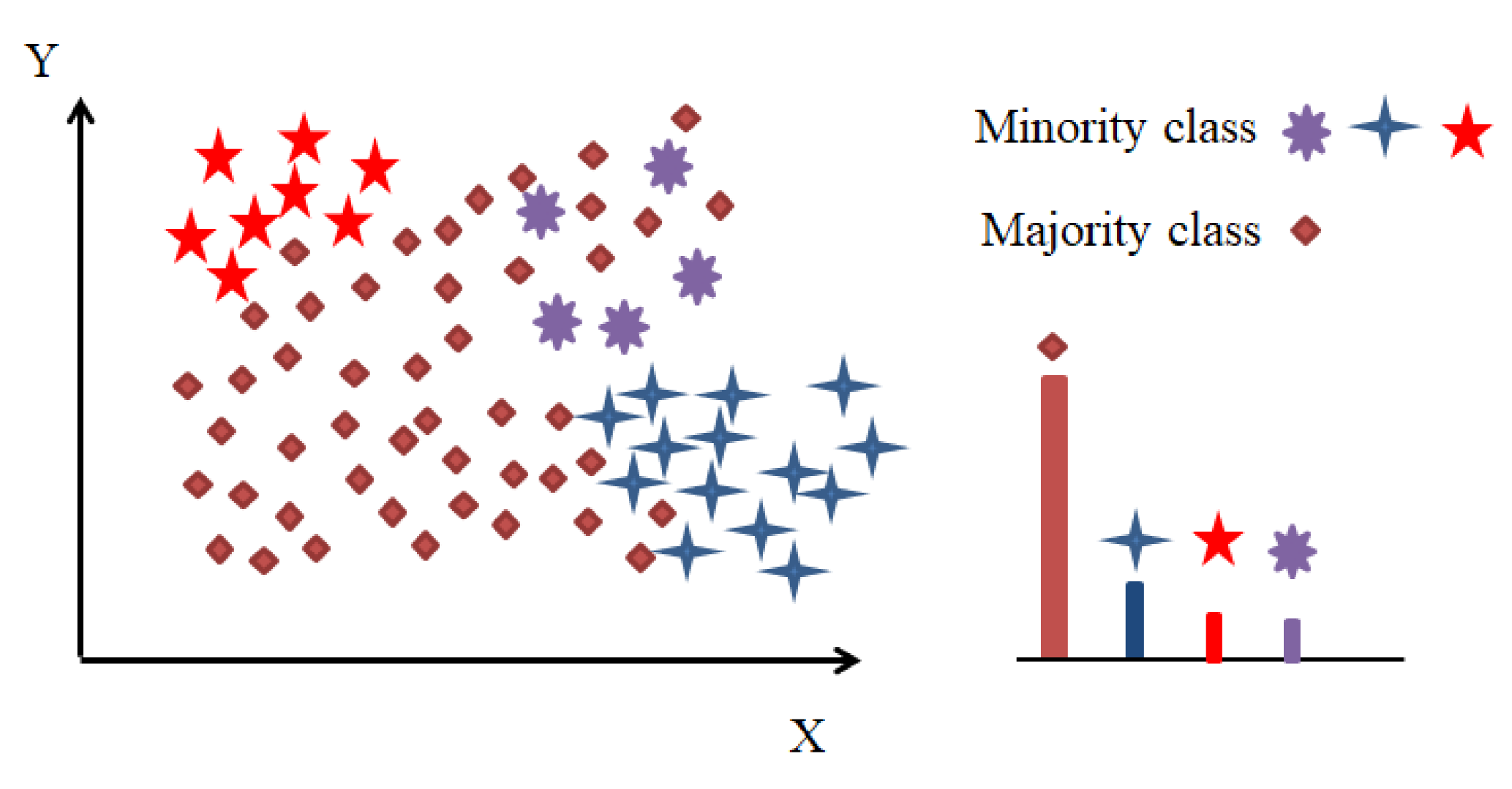
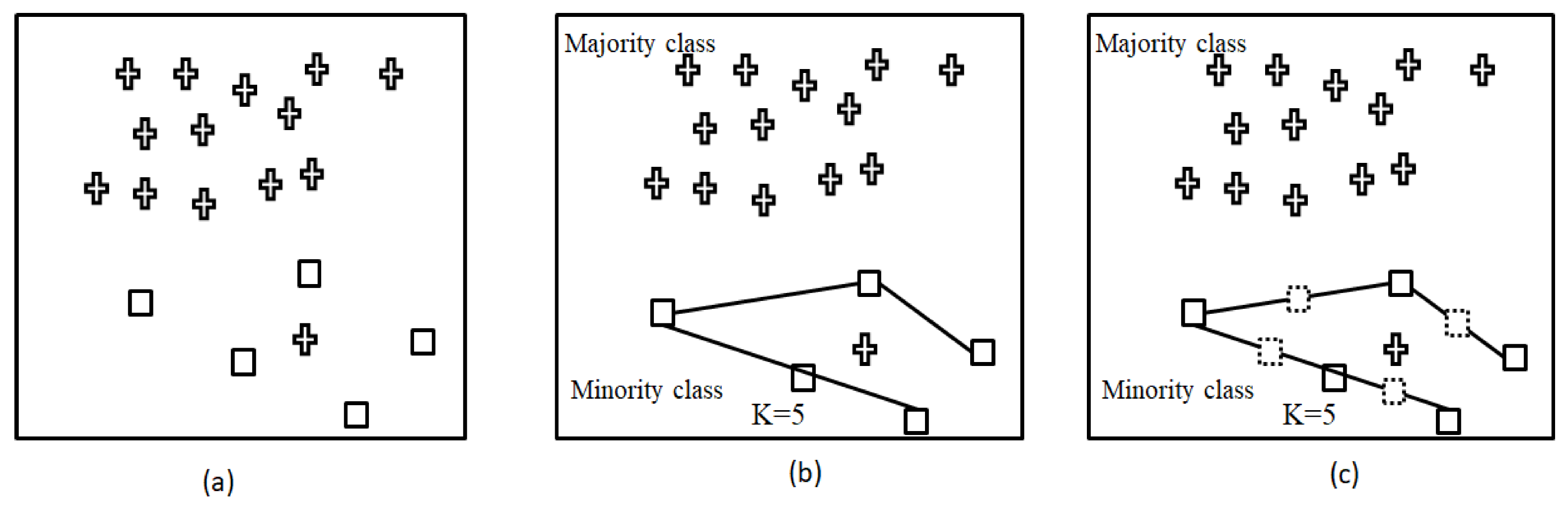
- To improve data imbalanced situation, the resampling process of the SMOTE algorithm is proposed to reduce the skew in the distributions of classes by modifying the number of instances for minority class;
- The accuracy of the proposed algorithm was 99.81% for two-class classification of UNSW-NB15 and 87.64% for multiclass classification;
- The classification accuracy of intrusion detection was 99.98%% for two subcategories of CSE-CIC-IDS 2018 and 96.53% for six subcategories of classification accuracy;
2. Overview of SMOTE Schemes and Ensemble Learning Schemes
2.1. SMOTE Techniques for Imbalanced Data
2.2. RF Algorithms
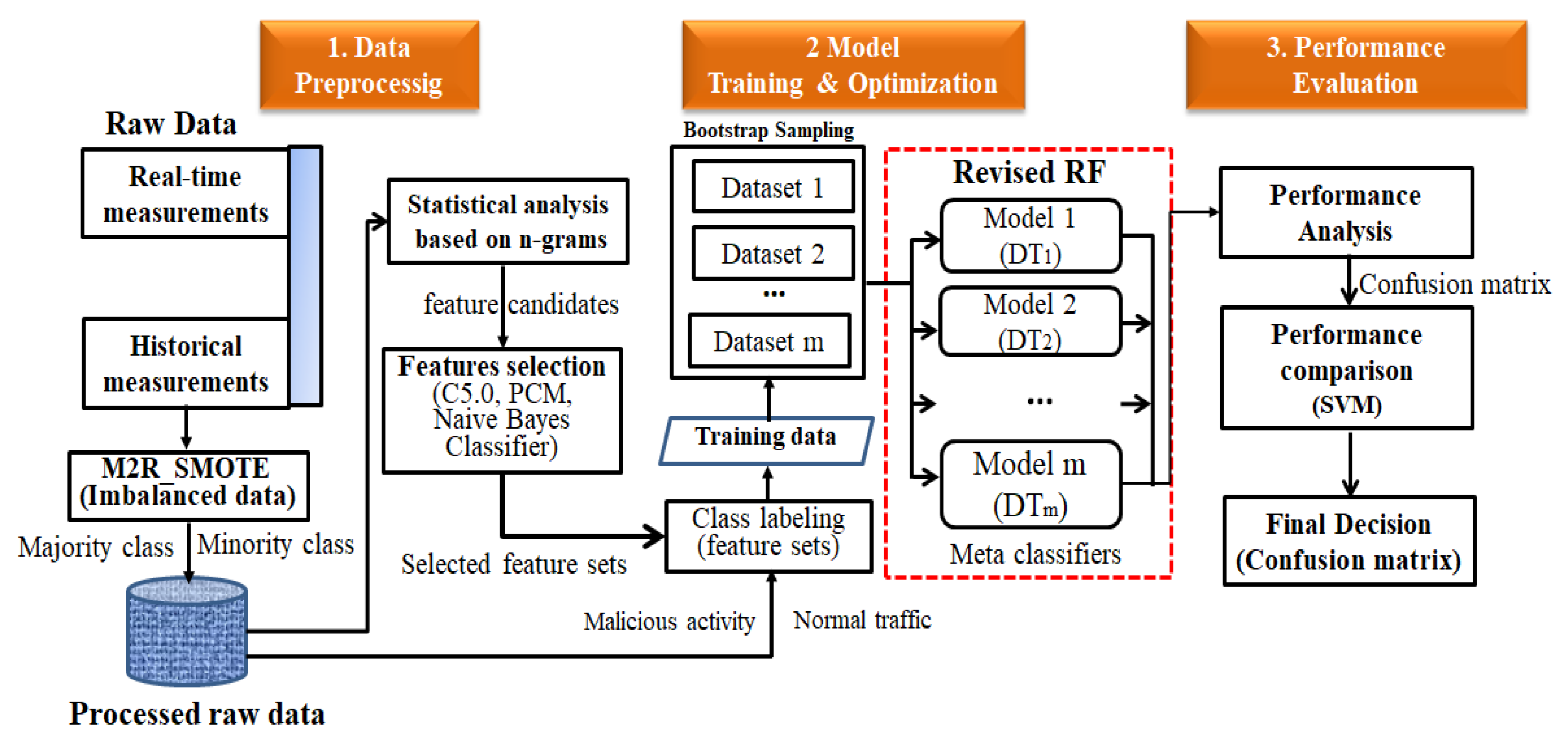
3. Application of Proposed RF Algorithm for Intrusion Detection
4. Results
4.1. Case I: Binary Classification and Multiclass Classification (UNSW-NB15)
4.2. Case II: Over-Sampling for Misclassification Class
class 4: 36,364, class 7: 20,982}.
4.3. Case III: Binary Classification and Multiclass Classification (CSE-CIC-IDS 2018)
4.4. Method Comaprison
4.4.1. Accuracy Comparison
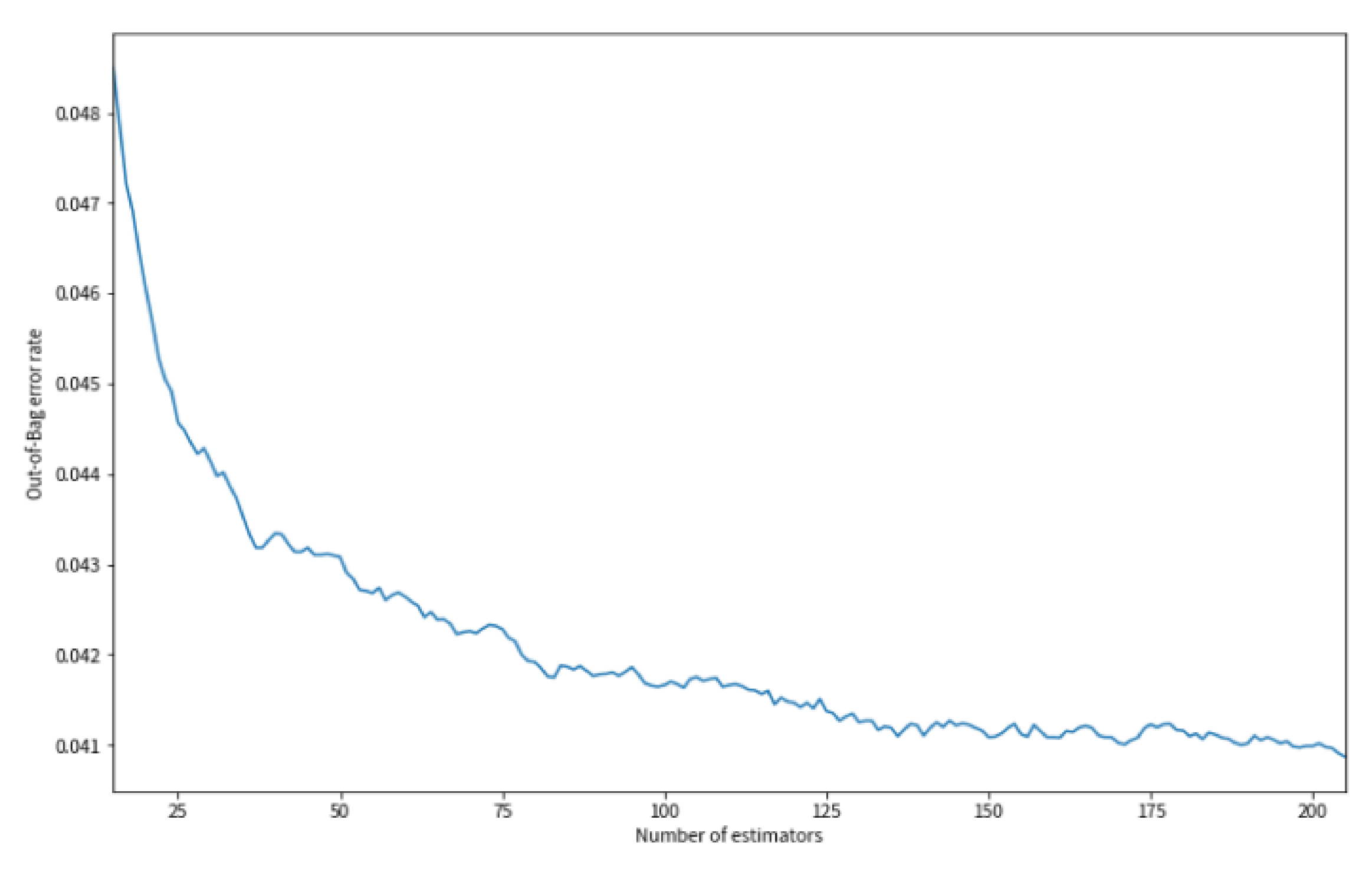
4.4.2. Robustness of Proposed Model
Imbalanced Data Handling
Removing Extra Features to Reduce the Risk of Overfitting
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Damien, R.; Gilles, G.; Michaël, H. Large-scale coordinated attacks: Impact on the cloud security. In Proceedings of the 6th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (IMIS 2012), Palermo, Italy, 4–6 July 2012; pp. 558–563. [Google Scholar]
- Al-Jarrah, O.; Arafat, A. Network intrusion detection system using attack behavior classification. In Proceedings of the 5th International Conference on Information and Communication Systems, ICICS2014, Irbid, Jordan, 1–3 April 2014; pp. 1–6. [Google Scholar]
- Bernhard, E.B.; Isabelle, M.G.; Vapnik, V.; Vladimir, N. A Training algorithm for optimal margin classifiers. In Proceedings of the 5th Annual ACM Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Guan, X.; Guo, H.; Chen, L. Network intrusion detection based on agent and SVM. In Proceedings of the 2nd IEEE International Conference on Information Management and Engineering (ICIME), Chengdu, China, 16–18 April 2010; pp. 16–18. [Google Scholar]
- Li, L.; Gao, Z.P.; Ding, W.Y. Fuzzy multi-class support vector machine based on binary tree in network intrusion detection. In Proceedings of the 2010 International Conference on Electrical and Control Engineering (ICECE), Wuhan, China, 25–27 June 2010; pp. 25–27. [Google Scholar]
- Kausar, N.; Samir, B.B.; Sulaiman, S.B.; Ahmad, I.; Hussain, M. An approach towards intrusion detection using PCA feature subsets and SVM. In Proceedings of the 2012 International Conference on Computer & Information Science (ICCIS), Shanghai, China, 12–14 June 2012; pp. 569–574. [Google Scholar]
- Singh, S.; Singh, J.P.; Shrivastva, G. A Hybrid Artificial Immune System for IDS based on SVM and Belief Function. In Proceedings of the Fourth IEEE International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–6. [Google Scholar]
- Ho, T.K. Random decision forest. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QB, Canada, 14–18 August 1995; pp. 278–282. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Zhang, J.; Zulkernin, M.; Haque, A. Random-forests-based Network Intrusion Detection Systems. IEEE Trans. Syst. Man Cybern. Part C 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: Boca Raton, FL, USA, 2012; p. 23. ISBN 978-1439830031. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems, NIPS 2017, Long Beach, CA, USA, 2–9 December 2017; pp. 1–9. [Google Scholar]
- Rocca, J. Ensemble Methods: Bagging, Boosting and Stacking. 23 April 2019. Available online: https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205 (accessed on 12 September 2021).
- Zong, W.; Chow, Y.; Susilo, W.A. Two-stage classifier approach for network intrusion detection. Lect. Notes Comput. Sci. 2018, 11125, 329–340. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Canadian Institute for Cybersecurity. CSE-CIC-IDS2018 on AWS. Available online: https://www.unb.ca/cic/datasets/ids-2018.html (accessed on 18 November 2021).
- Kasongo, M.S.; Sun, Y. Performance analysis of intrusion detection systems using a feature selection method on the UNSW-NB15 Dataset. J. Big Data 2020, 7, 105. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowye, K.W.; Hal, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Karatas, G.; Demir, O.; Sahingoz, O.K. Increasing the performance of machine learning-based IDSs on an imbalanced and up-to-date Dataset. IEEE Access 2020, 8, 32150–32162. [Google Scholar] [CrossRef]
- Hui, J.; He, Z.; Ye, G.; Zhang, H. Network intrusion detection based on PSO-XGBoost model. IEEE Access 2020, 8, 58392–58401. [Google Scholar]
- Tan, X.; Su, S.; Huang, Z.; Guo, X.; Zuo, Z.; Sun, Z.; Li, L. Wireless sensor networks intrusion detection based on SMOTE and the random forest algorithm. Sensors 2019, 19, 203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blagus, R.; Lusa, L. SMOTE for High-dimensional Class-imbalanced Data. BMC Bioinform. 2013, 14, 106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Das, T.; Khan, A.; Saha, G. Classification of imbalanced big data using SMOTE with rough random forest. Int. J. Eng. Adv. Technol. 2019, 9, 5174–5184. [Google Scholar]
- Jun, Y.; Sheng, Y.; Wang, J. A GBDT-paralleled quadratic ensemble learning for intrusion detection system. IEEE Access 2000, 8, 175467–175482. [Google Scholar]
- Wu, T.; Fan, H.; Zhu, H.J.; You, C.Z.; Zhou, H.Y.; Huang, X.Z. Intrusion detection system combined enhanced random forest with SMOTE algorithm. J. Adv. Signal Process. 2021. [Google Scholar] [CrossRef]
- Luyao, T.; Lu, Y. An intrusion detection model based on SMOTE and convolutional neural network ensemble. J. Phys. Conf. Ser. 2021, 1828, 012024. [Google Scholar]
- Kotsiantis, S.B. Supervised machine learning: A review of classification techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Kononenko, I. On biases in estimating multi-valued attributes. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QB, Canada, 20–25 August 1995; pp. 1034–1040. [Google Scholar]
- Abdulhammed, R.; Musafer, H.; Alessa, A.; Faezipour, M.; Abuzneid, A. Features dimensionality reduction approaches for machine learning based network intrusion detection. Electronics 2019, 8, 322. [Google Scholar] [CrossRef] [Green Version]
- Cyber Range Lab of the Australian Centre. UNSW-NB15 Data Set. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 25 March 2021).
- Ramon, J. Comment on: How to Determine the Number of Trees to be Generated in Random Forest Algorithm. Available online: https://www.researchgate.net/post/How_to_determine_the_number_of_trees_to_be_generated_in_Random_Forest_algorithm (accessed on 12 September 2021).
- Huancayo Ramos, K.S.; Sotelo Monge, M.A.; Maestre Vidal, J. Benchmark-based reference model for evaluating botnet detection tools driven by traffic-flow analytics. Sensors 2020, 20, 4501. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Contributions and Experimental Results | |
|---|---|---|
| SVM Guan et al. [4] | Four support vector machine (SVM) classifiers are used to categorize network data into five classes: denial of service, probe, U2R, R2L, and normal. | The agent and SVM were used to improve the detection precision of intrusive attacks for network intrusion detection (NID). |
| Fuzzy multiclass SVM Li et al. [5] | A decision tree (DT) is constructed using fuzzy multiclass SVM in which each data class is assigned a fuzzy membership during training to reduce the effects of outliers and response time. | The combined fuzzy theory and multiclass SVM improved detection accuracy and reduced training time. |
| SVM with PCA Kausar et al. [6] | The method is used for feature transformation into higher dimensions for determining the feature subset, after which the performance (in terms of detection rate and rate of false alarms) can be determined during testing. | The use of reduced features in training the support vector classifier accelerated the learning of normal and intrusive patterns. Improved accuracy (99.465%) and false alarm rate (0.525%) were observed for a subset of 10 features. |
| SVM with Belief theory Singh et al. [7] | This method is a hybrid one wherein intrusive behavior is detected using the Dempster belief algorithm (DCA) and Dendritic Cell Algorithm and where data are classified with the SVM. | The detection rate from the joint use of DCA and SVM was less than 92% (by contrast, the method proposed in the present paper reached 96%). |
| Threat Category | Record No. of Training Data | Record No. of Test Data |
|---|---|---|
| Normal | 56,000 (31.94%) | 7000 (44.94%) |
| Generic | 40,000 (22.81%) | 8871 (22.92%) |
| Exploits | 33,393 (19.04%) | 1132 (13.52%) |
| Fuzzers | 18,184 (10.37%) | 6062 (7.36%) |
| DoS | 12,264 (6.99%) | 4089 (4.97%) |
| Reconnaissance | 10,491 (5.98%) | 3496 (4.25%) |
| Analysis | 2000 (1.14%) | 667 (0.81%) |
| Backdoors | 1746 (1.00%) | 583 (0.71%) |
| Shellcode | 1133 (0.65%) | 387 (0.47%) |
| Worms | 130 (0.07%) | 44 (0.05%) |
| Study | Features | Contributions and Experimental Results |
|---|---|---|
| Chawla, Bowyer, Hall, Kegelmeyer (2002) [18] |
|
|
| Blagus and Lusa (2013) [22] |
|
|
| Zong, Chow, Susilo (2018) [14] |
|
|
| Das, Khan, Saha (2019) [23] |
|
|
| Tan et al. (2019) [21] |
|
|
| Karatas, Demir, Sahingoz (2020) [19] |
|
|
| Hui, He, Ye, Zhang (2020) [20] |
|
|
| Jun, Sheng, Wang (2020) [24] |
|
|
| Kasongo, Sun.(2020) [17] |
|
|
| Wu et al. (2021) [25] |
|
|
| Luyao, Lu (2021) [26] |
|
|
| Numerical and Machine Learning Library | |
|---|---|
| Python 3.8.10 | scikit-learn |
| imbalanced-learn | |
| numpy | |
| scipy | |
| pandas | |
| Feature | Weighting | Rank | Feature | Weighting | Rank |
|---|---|---|---|---|---|
| Sttl | 0.1543 | 1 | Dmean | 0.0271 | 13 |
| ct_state_ttl | 0.0694 | 2 | Sinpkt | 0.0267 | 14 |
| Dload | 0.0578 | 3 | dbytes | 0.0250 | 15 |
| Dttl | 0.0527 | 4 | ct_dst_src_ltm | 0.0248 | 16 |
| Tcprtt | 0.0412 | 5 | smean | 0.0246 | 17 |
| Dur | 0.0378 | 6 | state_INT’ | 0.0219 | 18 |
| Sload | 0.0366 | 7 | ct_srv_src | 0.0212 | 19 |
| Ackdat | 0.0351 | 8 | spkts | 0.0165 | 20 |
| Rate | 0.0306 | 9 | djit | 0.0145 | 21 |
| ct_srv_dst | 0.0305 | 10 | dloss | 0.0133 | 22 |
| Synack | 0.0303 | 11 | ct_dst_sport_ltm | 0.0125 | 23 |
| Parameter | n-Estimators | Max-Features | Max-Depth | Criterion Tree Split | |
|---|---|---|---|---|---|
| Model | |||||
| RF | [50,100,150,200,500,1000] | Auto, sqrt | [4,5,6,7,8] | Gini | |
| Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) | ROC AUC (%) | Training Time (s) | |
|---|---|---|---|---|---|---|
| n = 50 | 78.63 | 69.67 | 42.05 | 40.23 | 90.05 | 12.62 |
| n = 100 | 79.19 | 79.67 | 42.22 | 40.48 | 95.70 | 26.97 |
| n = 150 | 79.17 | 69.61 | 42.21 | 40.47 | 95.71 | 35.73 |
| n = 200 | 79.23 | 69.75 | 42.26 | 40.54 | 95.72 | 37.23 |
| 42 Features (Training/Testing) | 23 Features (Training/Testing) | |
|---|---|---|
| RF | 99.82% and 83.51% | 99.65%, and 83.51% |
| SVC | 93.64% and 81.69% | 93.70% and 81.60% |
| 42 Features (Training/Testing) | 23 Features (Training/Testing) | |
|---|---|---|
| RF | 86.04% and 54.71% | 84.01% and 42.07% |
| SVC | 79.18% and 71.37% | 77.86% and 62.80% |
| SMOTE(Training/Testing) | Without SMOTE(Training/Testing) | |
|---|---|---|
| RF | 87.35% and 46.34% | 84.01% and 42.07% |
| SVC | 72.87% and 61.40% | 77.86% and 62.80% |
| Feature | Weighting | Rank | Feature | Weighting | Rank |
|---|---|---|---|---|---|
| Fwd Seg Size Min | 0.0777 | 1 | Pkt Size Avg | 0.0189 | 19 |
| Init Fwd Win Byts | 0.0746 | 2 | Tot Fwd Pkts | 0.0178 | 20 |
| Fwd Pkt Len Max | 0.0503 | 3 | Bwd Seg Size Avg | 0.0170 | 21 |
| TotLen Fwd Pkts | 0.0467 | 4 | Fwd IAT Max | 0.0153 | 22 |
| Subflow Fwd Byts | 0.0453 | 5 | Fwd Pkt Len Std | 0.0149 | 23 |
| Fwd Header Len | 0.0425 | 6 | Bwd Pkt Len Mean | 0.0145 | 24 |
| Flow Pkts/s | 0.0393 | 7 | Bwd Header Len | 0.0144 | 25 |
| Fwd Pkts/s | 0.0337 | 8 | Pkt Len Max | 0.0144 | 26 |
| Init Bwd Win Byts | 0.0318 | 9 | Bwd Pkt Len Std | 0.0135 | 27 |
| Fwd Seg Size Avg | 0.0309 | 10 | Subflow Bwd Byts | 0.0131 | 28 |
| Bwd Pkts/s | 0.0299 | 11 | Flow IAT Max | 0.0130 | 29 |
| Fwd Pkt Len Mean | 0.0279 | 12 | Fwd IAT Mean | 0.0130 | 30 |
| Subflow Fwd Pkts | 0.0236 | 13 | Bwd Pkt Len Max | 0.0113 | 31 |
| Flow Duration | 0.0208 | 14 | Subflow Bwd Pkts | 0.0104 | 32 |
| Pkt Len Var | 0.0203 | 15 | Flow IAT Mea | 0.0098 | 33 |
| Fwd IAT Tot | 0.0201 | 16 | Pkt Len Mean | 0.0097 | 34 |
| Pkt Len Std | 0.0193 | 17 | TotLen Bwd Pkts | 0.0088 | 35 |
| Tot Bwd Pkts | 0.0189 | 18 | PSH Flag Cnt | 0.0084 | 36 |
| 76 Features (Training/Testing) | 36 Features (Training/Testing) | |
|---|---|---|
| RF | 100.00%/100.00% | 99.98%/97.05% |
| SVC | 97.86%/97.90% | 96.68%/94.72% |
| 76 Features (Training/Testing) | 36 Features (Training/Testing) | |
|---|---|---|
| RF | 96.87%/88.16% | 96.53%/89.38% |
| SVC | 94.28%/84.38% | 92.46%/81.58% |
| Author | Experiment Scheme/(Dataset) | Accuracy Type | Classification Accuracy |
|---|---|---|---|
| Zong, Chow, Susilo (2018) [14] | Six ML algorithms +SMOTE (UNSW-NB15) | Multi-classification (10 categories) | 85.78% |
| Tan et al. (2019) [21] | RF+SMOTE (KDDCup99) | Multi-classification (4 categories) | 92.57% |
| Karatas, Demir, Sahingoz (2020) [19] | Six ML algorithms +SMOTE (CIC-IDS 2018) | Multi-classification (6 categories) | Total: 99.34% 99.21% (original data) 99.35% (re-sampled data) for RF learner |
| Huancayo Ramos et al. (2020) [32] | Five ML algorithms (CIC-IDS 2018) | 2-class (Benign or Bot) |
|
| Kasongo, Sun. (2020) [17] | Five ML algorithms +XGBoost (UNSW- NB15) | 2-class/Multi-classification (10 categories) |
|
| Wu et al. (2021) [25] | GBDT+SMOTE (NSK-KDD) | Multi-classification (4 categories) | 99.72%(training set) 78.47%(testing set) |
| Proposed model | RF+SMOTE+C4.5 (UNSW-NB15) | 2-class | 99.65% |
| Multi-classification (10 categories) | 87.35% | ||
| RF+SMOTE+C4.5 (CIC-IDS 2018) | 2-class | 99.98% | |
| Multi-classification (6 categories) | 96.53% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.-C.; Wang, P.; Chao, K.-M.; Lin, W.-H.; Yang, Z.-Y. Ensemble Learning for Threat Classification in Network Intrusion Detection on a Security Monitoring System for Renewable Energy. Appl. Sci. 2021, 11, 11283. https://doi.org/10.3390/app112311283
Lin H-C, Wang P, Chao K-M, Lin W-H, Yang Z-Y. Ensemble Learning for Threat Classification in Network Intrusion Detection on a Security Monitoring System for Renewable Energy. Applied Sciences. 2021; 11(23):11283. https://doi.org/10.3390/app112311283
Chicago/Turabian StyleLin, Hsiao-Chung, Ping Wang, Kuo-Ming Chao, Wen-Hui Lin, and Zong-Yu Yang. 2021. "Ensemble Learning for Threat Classification in Network Intrusion Detection on a Security Monitoring System for Renewable Energy" Applied Sciences 11, no. 23: 11283. https://doi.org/10.3390/app112311283