1. Introduction
Association rule mining, a research hotspot in recent years, has been widely applied in the era of big data (e.g., cause analysis of traffic accidents [
1], association analysis of weather forecasting [
2], interest-based real-time news recommendation [
3], recommendation of bank marketing plan [
4], recommendation of e-commerce matching purchase and shopping basket analysis [
5]). In particular, it has been used to realize the data-driven optimization of complex systems in various industries [
6].
Association rule mining refers to finding implications such as A ⇒ B from the given transaction set, where A and B are itemsets. The former is called an association rule antecedent, while the latter is called an association rule consequent. If the probability for A and B to appear in the transaction set is greater than a certain threshold, it is then called a frequent itemset; otherwise, it is referred to as a non-frequent itemset. |A| or |B| represents the number of items in the itemset. If |A| = k, A is called k-itemset. Hence, any item can be independently called a frequent 1-itemset or non-frequent 1-itemset. However, the feature of big data association rule mining is that the transaction number of a given transaction set is massive, and the dimension of the transaction set is very high, so it is difficult to mine association rules from it.
I = {
I1,
I2, …,
Im} is the set of all items.
D = {
T1,
T2,
T3, …,
Tn} is the big data transaction set with association rules to be mined, where
m is the dimension of the transaction set and
n is the number of transactions in transaction set.
Ti ⊆
I,
Ti ≠ Ø, and
i = 1, 2, …,
m.
Ti = {
Ii1,
Ii2,
Ii3, …} is a transaction in the transaction set. If
A⇒
B is an association rule,
A ⊂
I,
B ⊂
I, and
A ∩
B = Ø. The support degree (
support) and confidence level (
confidence) are used in association rule mining to measure the weakness of one rule, which are defined as follows:
where
P (
X) is the probability (
support) for itemset
X to appear in given transaction set
D. Therefore, the corresponding support degree and confidence level of association rule
A ⇒
B can be calculated only if
P (
A ∪
B) and
P (
A) are obtained, and whether the two are strongly associated can be determined according to the threshold. For example, assume that
A is the itemset {1, 2} and
B is the itemset {2, 3, 4}. Then,
support (
A ⇒
B) is equal to the probability of the {1, 2, 3, 4} appearing in transaction set
D.
confidence (
A ⇒
B) is equal to the ratio of the probability of the {1, 2, 3, 4} to probability of the {1, 2} in transaction set
D. Hence, the association rule mining problem can be transformed into a mining problem of frequent itemsets.
As frequent itemsets have a very important property (i.e., the non-empty subsets of all frequent itemsets are also frequent itemsets, and the supersets of all non-frequent itemsets are also non-frequent itemsets), if an itemset is a frequent itemset but any of its superset is a non-frequent itemset, it contains most frequent itemsets with the maximum capacity. In this way, the algorithm is able to find all frequent itemsets with the least optimization objectives. The itemsets of this type are called maximal frequent itemsets (MFIs). Thus, the frequent itemset mining (FIM) problem can also be transformed into the problem of maximal frequent itemsets mining (MFIM).
For the purpose of association rule mining, MFIM has some advantages over FIM. Firstly, it makes the optimization problem have fewer targets to be searched. For a set of transactions with a given support threshold, the set of all MFIs is a subset of the set of all frequent itemsets. The number of elements in a subset is always less than the number of elements in the set, so there were fewer targets for optimization. This helps to speed up the running time of the algorithm. Secondly, not all frequent itemsets are useful in calculating association rules. The algorithm avoided reinventing the wheel. The disadvantage of MFIM is the theoretical addition of frequent itemsets generated by MFI. However, in fact, the long pattern MFIs found were not very long in practice, and it is very easy to generate the required frequent itemsets. This disadvantage is almost negligible compared with the benefits brought to the algorithm.
In addition, both MFIM and FIM can not only be used to calculate association rules such as (1) and (2), they also have many other applications. For example, they can be used for outlier detection [
7], which is a kind of data mining technique to detect rare events, deviant objects, and exceptions from data, which has been drawing increasing attention in recent years. MFIM and FIM can also be used for web clustering [
8]. A vast number of documents in the Web have duplicates, which is a challenge for developing efficient methods that would compute clusters of similar documents. Web clustering can be conducted through FIM. MFIM can also be used for partitional clustering. Dinh et al. [
9] took advantage of non-random initialization from the view of MFIM to improve clustering quality. Beyond this, MFIM may have more applications.
However, most of the present studies regarding the association rule mining aim at frequent itemset mining, while MFIs have been scarcely taken as the mining object. The current algorithms specific to frequent itemset mining are largely divided into two major types: exact algorithms and heuristic algorithms. The most classical exact algorithms are the Apriori algorithm [
10] and FP-Growth algorithm [
11], as well as many improved algorithms derived from the two algorithms [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26].
Faced with high-dimensional mass big data, the exact algorithm itself is almost of no practicability due to the temporal complexity and explosion of storage space. However, some calculation platforms that can realize the temporal and spatial decomposition of data mining tasks have emerged in order to process big data, so the exact algorithm becomes feasible [
12,
27,
28,
29]. The advantage of these calculation platforms lies in the fact that a big data analysis becomes feasible due to computer clusters, among which Spark reaches the highest rate at present.
Most of the heuristic algorithms have integrated evolutionary computation [
30,
31,
32], particle swarm optimization (PSO) [
33,
34,
35], and other artificial intelligence algorithms with exact algorithms [
36]. Bagui et al. [
31] applied a genetic algorithm (GA) to data flow to mine frequent itemsets, and the novelty of this work is in the use of frequent itemsets to determine the concept drift. As the object was partial data selected from the data flow using a sliding window, the dimension (number of items) and number of transactions of the processed dataset were small. Sizov et al. [
31] also designed a GA to acquire the frequent itemsets and large bite sets of the binary transaction set, and gave the application cases of 23-column 5712-row transaction sets, whose volumes were small. Ykhlef et al. [
32] used a quantum evolutionary computation to mine frequent itemsets from the nursery transaction set, comprising 12,960 transactions and a dimension of 32.
Zhang et al. [
33] designed a binary PSO algorithm to mine frequent itemsets. This algorithm could realize dynamic pruning during the population initialization and evolution process to relieve the time pressure of memory and CPU, and it was applied to four different transaction sets. The number of transactions was small in all four transaction sets, among which three transaction sets contained 1000 transactions, and one contained 500 transactions. Chiu et al. [
34] used the PSO algorithm to mine frequent itemsets in a transaction set called FoodMart2000, which contained 12,100 transactions with a dimension of 34. Kabir et al. [
35] enhanced the random search performance of the PSO algorithm and mined frequent itemsets in a transaction set with 1000 transactions and a dimension of 5.
Paladhi et al. [
36] designed an artificial cell division algorithm, which was very successful in solving multipath search tasks involving search space and achieved superior effect when applied to small-scale transaction sets compared with the Apriori algorithm.
Although the abovementioned algorithms have not been applied to high-dimensional big data transaction sets, the heuristic algorithm is theoretically feasible in the face of high-dimensional mass big data. Nevertheless, the solution found is an optimized solution but not an exact solution. The exact solution can be found using the exact algorithm, which, however, decomposes a task based on special computing platforms when applied to big data (e.g., Spark). Moreover, exact algorithms are based on cluster computing, which requires multiple computers. Therefore, both algorithms have their respective advantages and disadvantages when solving the big data association rule mining problem.
For large-scale transactions set, parallel data mining is very promising, so a few algorithms for parallel mining association rules were proposed. The most well-known one of them is the Count Distribution (CD) algorithm [
37], which is a parallel version of the Apriori algorithm. In CD algorithm, databases are initially partitioned and distributed across multiple processing nodes.
The FPMAX algorithm [
38] based on FP-Tree was one of the most efficient and stable mining algorithms for maximum frequent itemsets. However, for mining in dense transaction sets, FPMAX would generate many redundant recursive procedures, resulting in an additional conditional FP-tree construction overhead. Additionally, when the support was low, FPMAX would degrade the performance of superset detection due to the large global MFI-tree used for superset detection.
The parallel max-miner (PMM) algorithm [
39] and the distributed max-miner (DMM) algorithm [
40], proposed by Soon M. Chung and Congnan Luo, are two excellent MFI mining algorithms for high-dimensional big data. Compared to most of existing mining algorithms, PMM looked ahead at each pass and prunes more candidate itemsets by checking the frequencies of their supersets. DMM has a local mining phase and global mining phase. During the local mining phase, each node mines the local database to discover the local maximal frequent itemsets, and then they formed a set of maximal candidate itemsets for the top–down search in the subsequent global mining phase. A new prefix tree data structure was developed in DMM to facilitate the storage and counting of the global candidate itemsets of different sizes. This global mining phase using the prefix tree can work with any local mining algorithm. Both PMM and DMM were implemented on a cluster of workstations, and they required very low communication and synchronization overhead in distributed computing systems.
From the above analysis, we propose an exact algorithm. This algorithm does not used any computing platform, nor does it required a cluster of computers, but it could find the exact solution—all MFIs of big data transaction set within an acceptable time range. In the other word, the motivation of the algorithm proposed in this paper is to realize the MFI mining in an acceptable time range without using cluster computers for the big data with high-dimensional attributes and massive transaction numbers.
The algorithm presented in this paper will contribute to the MFIM problem in the following ways. ① The reduced transaction set is generated and used without changing the mining results. In this way, the effective part of the transaction set can be loaded into the RAM to be accessed, which not only accelerates the algorithm speed, but also provides a basis for single-machine computing of high-dimensional big data with a massive transaction number. ② The Expanding Operation adopts the strategy of one-way search so that every MFI can be found and the path to be found is unique. In this way, the computational redundancy of the algorithm is avoided as much as possible.
2. Right-Hand Side Expanding Algorithm
In this study, the proposed algorithm was divided into three parts: ① First, the transaction set with mass data was preprocessed. A transverse and longitudinal data reduction was then performed according to the given support threshold. Thus, a simplified transaction set was obtained. The use of a simplified transaction set would not change the algorithm’s accuracy. Instead, it could significantly accelerate the computation. ② Second, an any frequent itemset-oriented operator, which could extend and add items from any given frequent itemset so as to find the MFIs, was designed. ③ The itemsets of starting points were reasonably organized and given for the Expanding Operation so that it could find all MFIs.
Above all, the notations, and functions to be used often in the text firstly are listed in
Table 1. They will be explained at first use in the text. However, the reader may find it more convenient to look up definitions in the table.
2.1. Transaction Set Preprocessing
The preprocessing of transaction set was conducted to obtain a reduced transaction set, and the original transaction set should be scanned twice. First, the appearance probability (support) of each 1-itemset was acquired. Next, all items with a probability smaller than the threshold were excluded. Thus, a new and reduced transaction set was obtained.
D = {T1, T2, T3, …, Tn} is the original big data transaction set, and n is the number of transactions in the transaction set, where Ti = {Ii1, Ii2, Ii3, …}, (i = 1, 2, …, n) represents the ith transactions of the transaction set, Iij represents the jth item of ith transactions. Each transaction is a set of items is also a subset of set of all items I = {I1, I2, …, Im}.
If
Iij is the
ID of one item and all of
ID are continuously numbered together from 1, then,
where
m is the maximum
ID of an item in original big data transaction set. By this way, the
m is also the dimension of the transaction set because the
ID is from 1, namely, the value of
m directly decides the dimension of the solution space in itemset mining. For example, we assume that the itemset {
I11,
I12,…} is {1, 2}, the itemset {
I21,
I22,…} is {2, 3, 4}, and the number of transaction
n is 2. Then,
m =
Max{2, 4} = 4, the dimension of the transaction set is 4. Under a given transaction set
D with the known dimension
m and support threshold (
Support_T), the pseudocode of transaction set preprocessing is expressed as seen in Algorithm 1.
Algorithm 1 contains two two-level nested “for” loops. The first two-level nested loop records the number of occurrences of each item, the inner loop traversed the items of each transaction, and the outer loop traversed the entire transaction set. At the end of the first two-level nested loop, the m-dimensional vector (S1, S2, …, Sm) recorded the number of occurrences of each item in the transaction set. The second two-level nested loop was used to rebuild a new reduced transaction set. The inner loop was used to rebuild a new transaction that does not contain infrequent items. The outer loop added each new transaction to the newly created reduced transaction set.
The algorithm returned to a new transaction set ND, which consisted of new transactions NTi. When a new transaction was generated, it was first made empty, and only the items with a high support degree could join in the new transaction. It was possible that all items in some transactions in the original transaction set D were not frequent items, so they would not be added in the new transaction, and then the new transaction was an empty set before and after the third for loop. As a result, it would not be added into ND, the number of transactions in ND would be reduced, and the number of transactions in the pseudocode was turned from n into n−, and n− < n. The number of transactions in the new transaction set would be reduced to different degrees due to the change of the data sparsity in the original transaction set D.
When a new transaction
NTi was established, some items would be given up, and the quantity of all different items appearing in the new transaction set would be reduced, and so would the dimension of the reduced transaction set. The decreased amplitude of dimension varied with the given support threshold after the reduction. The dimension of the original transaction set is expressed as
m, and that of the reduced transaction set as
m−, and
m− < m. The optimization space of the algorithm was greatly reduced due to the dimension reduction, thus elevating the operating rate to a great extent.
| Algorithm 1: Transaction Set Reduction |
Input: D = (T1,T2,…,Tn), Ti = (Ii1,Ii2,…)
Output: ND = (NT1,NT2,…,NTn-)
(S1,S2,…,Sm) = (0,0,…,0);
n− = 0;
for i = 1: n do
for j = 1: |Ti| do
S(Iij) = S(Iij) + 1;
end
end
ND = Ø;
for i = 1: n do
NTi = Ø;
for j = 1: |Ti| do
if S(Iij)/n > Support_T then
NTi = NTi ∪ {Iij};
end
end
if NTi ≠ Ø then
ND =ND ∪ {NTi};
n− = n− +1;
end
end
Return ND; |
2.2. Expanding Operation
The expanding operator adds items to frequent itemsets according to certain rules and finds the supersets of some frequent itemsets, all of which are MFIs. The expanding operator has two features: First, the given initial itemsets must be frequent because all supersets of non-frequent itemsets cannot be MFIs. Second, what the Expanding Operation finds are not all MFI supersets corresponding to the given frequent itemsets but partial MFIs. As any MFI can be obtained by expanding different frequent itemsets, the Expanding Operation only finds the partial MFIs corresponding to the given frequent itemsets, and the remaining part is obtained through the other frequent itemsets using the Expanding Operation. This ensures that each FMI is found only once.
The initial frequent itemset T = {I1, I2, I3, …} was given, an integer p (0 < p<m−, where m− is the dimension of the reduced transaction set, namely, the total number of different items) as the reference position for the added items, and then the pseudocode of Expanding Operation was expressed as in Algorithm 2, where ND = {NT1, NT2, NT3, …, NTn−} is the reduced transaction set, NTi = {NIi1, NIi2, NIi3, …} and i = 1, 2, …, n− are the transactions in the transaction set, and n− is the number of transactions in the reduced transaction set (n− < n).
The operation contained four “for” loops (nested loops excluded). In the first “for” loop, a frequent itemset
T was expressed by a decision variable (
x1,
x2, …,
xm−).
xi = 0 means that the item
i was not a member of the itemset. If
xi = 1, the item
i is a member of the itemset. The second “for” loop acquired all single items that could be added into the given frequent itemset, and after the addition, the itemset was still a frequent itemset. In the third “for” loop, the number of single items was calculated. If it was equal to the number of items in the frequent itemset, the given frequent itemset was namely an MFI, and then this itemset was returned. Otherwise, the fourth “for” loop should be executed: An addable single item was added rightward from point
P by turns. The values of the given initial frequent itemset
T and base point
P were reset once a single item was added, followed by the recursive invocation of Expanding Operation itself. After all recursive nested structures were returned, all MFIs corresponding to the original given frequent itemset were found. As the operator only added the items at the right-hand side of point
P (items with
ID value greater than the
p value) each time, the algorithm was named right-hand side expanding (RHSE) algorithm.
| Algorithm 2: Expanding Operation (T, P) |
Input: T = (I1,I2,…), P
Output: A group of maximal frequent itemsets
(x1,x2,…,xm−) = (0,0,…,0);
(e1,e2,…,em−) = (0,0,…,0);
for i = 1: |T| do
x(Ii) = 1;
end
for i = 1: n− do
if T ⊆ NTi then
for j = 1: |NTi| do
e(NIij) = e(NIij) + 1;
end
end
end
e_item_number = 0;
for i = 1: m− do
if e(i)/(n−) > Support_T then
ei = 1;
e_item_number = e_item_number + 1;
else
ei = 0;
end
end
if e_item_number = |T| then
Adds T into group of maximal frequent itemset;
else
for i = P + 1: m− do
if (xi = 0)&(ei ≠ 0) then
Expanding Operation (T ∪ {i}. P = i);
end
end
end |
2.3. Overall Framework of Algorithm Running
With this Expanding Operation, it is only necessary to reasonably organize and alternately give the initial frequent itemset of the Expanding Operation, which is then invocated. Thereafter, all MFIs of the given support threshold can be found. Under the overall framework of algorithm running, a reduced transaction set was first obtained after the preprocessing. During the preprocessing, all frequent 1-itemsets were acquired, which were set as the initial itemset alternately. Items were added by invocating the Expanding Operation, and then a group of MFIs corresponding to each frequent 1-itemset could be found. When placed together, these groups were the set of MFIs discovered by the algorithm. These MFIs were neither repeated nor omitted, being the exact solution but not the optimized solution to the problem.
The overall framework of algorithm running was expressed by a block diagram in
Figure 1, where
I1,
I2, …,
Im− are the
m− frequent 1-itemsets acquired in the preprocessing of the transaction set, which aimed to obtain a reduced transaction set, and
m− is the dimension of the reduced transaction set. As the dimension of the original transaction set is
m, the dimension of the reduced transaction set is expressed by
m−, and
m− <
m. The
m− frequent 1-itemsets were set as the initial itemset of Expanding Operation, namely,
Ii, and the base point
P =
i, (
i = 1.2, …,
m−) was given in turn. The Expanding Operation was then invocated. Subsequently, several MFIs were acquired and called the group of MFIs, and these groups of MFIs finally formed a larger pool of MFIs. This larger pool of MFIs was an exact solution to the problem, and it was a set of MFIs.
2.4. Complexity Analysis
The time complexity of the proposed algorithm RHSE was analyzed with respect to Algorithms 1 and 2. Algorithm 1 was used to generate the reduced transaction set, which requires scanning the transaction set twice.
n is the number of transactions in transaction set, and let
Li be the average number of items in the transaction (itemsets). Thus, the time complexity of this task is
O (
n ×
Li). Algorithm 2 is the
Expanding Operation with an initial itemset and position point. Each
Expanding Operation contained (
m− − (
P + 1)) branch recursions, where
m− is the dimension of the reduced transaction set (
m− <
m), and
P is the base point at which the expanding operation adds item. Thus, the time complexity of Algorithm 2,
Expanding Operation, is
O ((
m− − (
P + 1))!). In comparison, the solution space of the problem is 2
m and the time complexity of the enumeration method is
O (2
m). We will learn in
Section 4.3 that the time complexity of Algorithm 2 is much lower than that of enumeration.
3. Proof of Algorithm Accuracy
The solution to the optimization problem is divided into two types: an exact solution and optimized solution, both of which are feasible solutions. The corresponding algorithms can also be classified according to the solution type. For instance, in the introduction part, the algorithm acquiring the exact solution was called the exact algorithm, and the algorithm acquiring the optimized solution was called the heuristic algorithm. The exact solution refers to the optimal solution to the problem, and this solution or set of solutions is unique. Here, the solutions may be a set of feasible solutions with equivalent excellence, and the uniqueness means that this set is unique. The optimized solution may not certainly be the optimal solution, but it may also be the optimal, and its excellence is pursued as much as possible. If the solution is a set, this set may have a missing element.
The exact solution to MFI mining is the set of all MFIs found by the algorithm. The itemsets in this set should not be estimates. Instead, this set is the well-determined set consisting of itemsets. The proof of algorithm accuracy aims to prove that under the given transaction set and support threshold, all MFIs will be found (lack of any itemset is not allowed), and each MFI is found only once (repetition is not allowed). Given this, two problems remain to be proven: ① any MFI can be found, which is called integrity; ② any MFI can be found only once. The MFIs found from the pool of MFIs are not the same; this is referred to as uniqueness.
3.1. Integrity Proof
Assuming that {
I1,
I2, …,
Ik} is a random MFI, the corresponding decision variable is
X = (
x1,
x2, …,
xm−), and
xi∈{0,1}.
xi = 0 means that the item
i is not a member of itemset, and
xi = 1 means that it is a member of itemset. Then,
The above is called frequent item
k-itemset.
xa,
xb, …,
xk are set as the first, second, …, and the
kth non-zero items from the left to right in (
x1,
x2, …,
xm−), namely, 1 ≤
a <
b <≤
k. According to the overall algorithm flow in
Section 2.3, the Expanding Operation will be invocated for
m− times (the number of nested invocation times not included), where it will be invocated in the form of Expanding Operation ({
a},
P =
a) for the
ath time.
As shown in
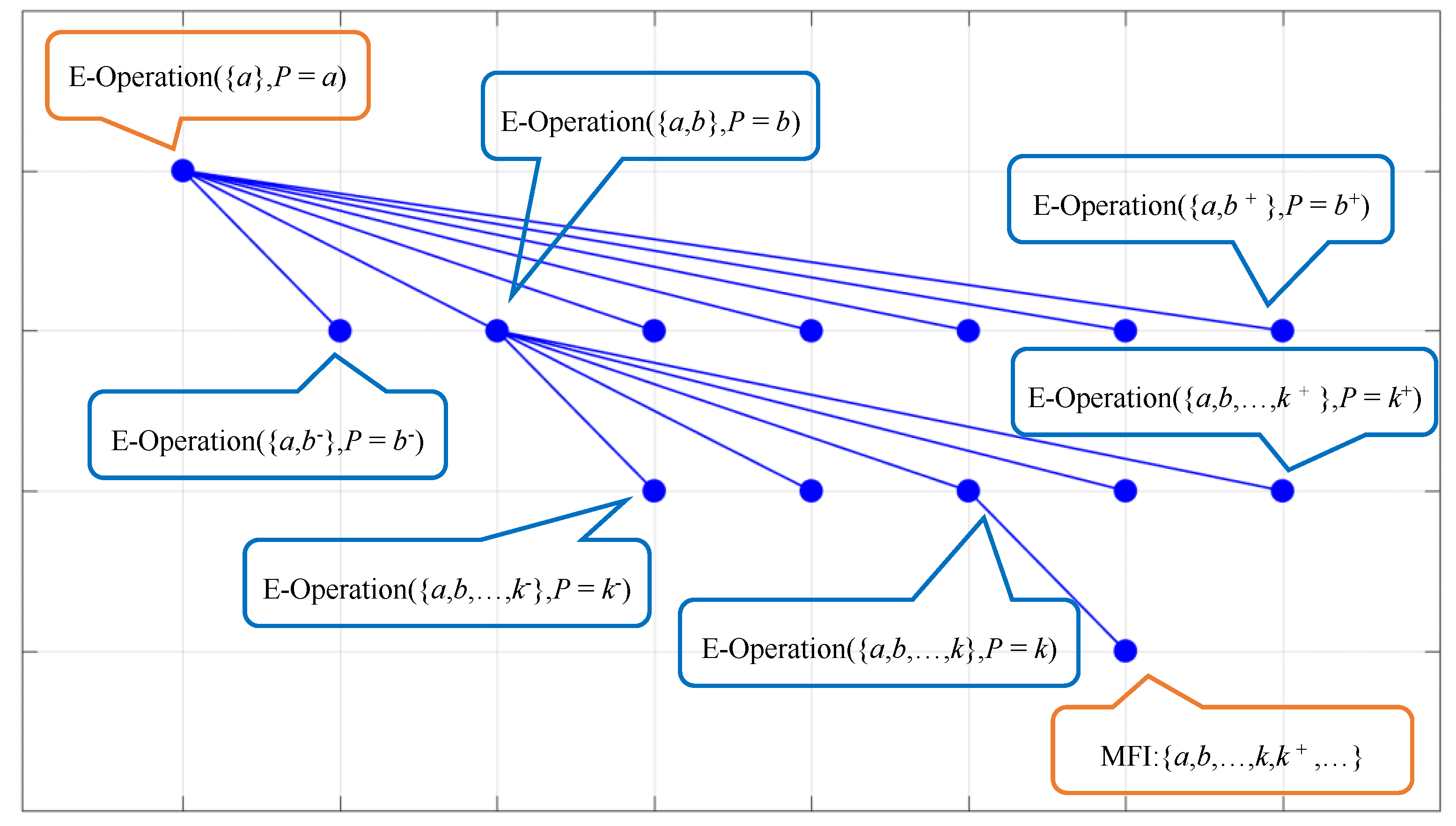
Figure 2,
a <
b− <
b <
b+ < … <
k−<
k <
k+, E-Operation ( ) represents the function of Expanding Operation. According to the principle of Expanding Operation stated in
Section 2.2, the Expanding Operation is invocated by
m− times. When it is invocated for the
ath time, it is certainly judged that items
b and
c can be added into the itemset. In one step, item
b is added, followed by the recursive invocation of Expanding Operation ({
a,
b},
P =
b). Similarly, the recursive invocation of Expanding Operation ({
a,
b,
c},
P =
c) is carried out after the addition of item
c inside the Expanding Operation ({
a,
b},
P =
b). By parity of reasoning, the recursive nesting at the deepest layer is implemented by invocating the Expanding Operation ({
a,
b,
c, …,
k},
P =
k), and {
a,
b,
c, …,
k} is determined as the MFI. Hence, the MFI {
I1,
I2, …,
Ik} = {
a,
b,
c, …,
k} will be certainly found. If any MFI without loss of generality can be found, all MFIs can be too, so this algorithm ensures the high integrity of the solution set.
Of course, not only Expanding Operation ({a, b}, P = b) will be invocated inside Expanding Operation ({a}, P = a), but Expanding Operation ({a, c}, P = c) may also be parallelly invocated. Therefore, the finally found MFI after the ending of Expanding Operation ({a, c}, P = c) will contain a and c but not b, which is another MFI, but this is not contradictory with the hypothetical proposition to be proven.
3.2. Uniqueness Proof
According to the overall algorithm framework and item addition rules of Expanding Operation, each time the Expanding Operation adds one item since one frequent 1-itemset, it will be recursively invocated by itself once again or find the other items that can be added. The discovery process of an MFI is as shown in
Figure 3a. The top–down sequence of nodes in the figure denotes the sequential order of item addition, the left or right position of each node represents the
ID value of item, and the left-to-right direction is the increasing direction of
ID value. Given this, the root nodes are located at the upper left corner and leaf nodes at the lower right corner, and this path forms a branch. The set of
ID values of all nodes on one branch corresponds to one frequent itemset, which may be maximal or not.
At each root node, multiple branches may grow, so as to form a tree, as shown in
Figure 3b. The
ID values of all nodes on one branch from root nodes to leaf nodes constitute a frequent itemset, and all MFIs on one tree form a group of MFIs, as mentioned in
Section 2.3.
As stated in
Section 2.3, each frequent 1-itemset can serve as the root node to grow a tree. In
Figure 3c, all green nodes can be root nodes to grow a tree. For the conciseness of this diagram, the tree growing out of green nodes was not drawn. Many trees form a forest, corresponding to the pool of MFIs in
Section 2.3. Therefore, to prove that all MFIs are different in the pool of MFIs, it is only necessary to prove that only one branch, but not a second branch, corresponds to each itemset.
This proposition was proven through the reduction to absurdity. Assume that an MFI (MFI1) is determined for a branch (Branch1), and this MFI has a corresponding relation with another branch (Branch2).
According to the right-hand side item addition rules of Expanding Operation, only items with greater ID values are added, and then the difference (difference value of x-coordinates) of ID values between two nodes connected by any edge in Branch1 is certainly greater than 1, while the difference value of y-coordinates is bound to be 1.
In order for Branch2 and Branch1 to correspond to the same itemset, the nodes of Branch2 should be different from those of Branch1 only in y-coordinates; otherwise, their horizontal projections will be different, so will the corresponding itemsets.
If the nodes of Branch2 are different from those of Branch1 only in the upper or lower position, there will certainly be such an edge in Branch2 that the difference value of y-coordinates of two nodes it connects is equal to zero or greater than 1 because the difference of ID values between two nodes connected by the edge in Branch1 is certainly greater than 1, the difference value in y-coordinates is equal to 1, and the two branches must share the same root nodes. If the difference value is equal to zero, the Expanding Operation adds two items once. If it is greater than 1, the Expanding Operation enters recursive invocation without adding any item.
Obviously, this contradicts with the rules of Expanding Operation. Then, the hypothesis does not hold true, and the proposition of path uniqueness is proven. In other words, the pool of MFIs does not contain the same itemsets. According to the proposition proven in
Section 3.1 (i.e., there are no MFIs missing in the pool of MFIs), the integrity and path uniqueness indicate that the algorithm is accurate without complexity or redundancy in the path optimization.
4. Experiment
The algorithm proposed in this study aimed to find all MFIs, being different from most of the present algorithms aiming at frequent itemsets. The second objective was to realize standalone operations specific to big data and mass transaction sets and get rid of limitations of special computing platforms (it was thought in this study that special platforms only targeted at task decomposition to make big data computation feasible, while the computational complexity was not changed). On this basis, no horizontal comparison was made with the existing algorithms. The standalone test of only 10 open transaction sets was implemented to demonstrate the feasibility and practicability of standalone computation for big data. In the end, the detailed computation results were given, and the details of MFI with the maximum support searched by the algorithm were expounded. Readers may verify according to the results and compare with their own algorithm results. These open transaction sets are available on
http://fimi.uantwerpen.be/data/ for free (accessed on 28 February 2020). The algorithm source code in this study may also be acquired from the corresponding author.
The standalone operation was implemented using the following hardware: Intel® Core™ i7-8550U CPU @ 1.80 GHz (8 CPUs) and 16,384 MB RAM, Timi Personal Computing Limited, Beijing, China. The programming language of the algorithm is Python. The advantage of using Python is that the programming environment is lightweight and easy to popularize.
4.1. Brief Description of Transaction Sets
The 10 transaction sets varied in volume and features. The number of transactions might reach as many as 990,000, the maximum length of transaction was 2498, and the maximum dimension was 41,270. The experimental results were given separately in two tables, where
Table 2 lists the test results of small-scale transaction sets and
Table 3 presents the test results of slightly larger-scale transaction sets. The results in
Table 2 demonstrated the integrity of calculation results for the 10 transaction sets. Moreover, the calculation results of small-scale problem were convenient for readers to verify their algorithm accuracy. The results in
Table 3 manifested the feasibility of the algorithm in the standalone operations for big data and high-dimensional transaction sets. A proper support threshold was used for each transaction set. As the data sparsity varied among the different transaction sets, they were different in the intensity of data association, and the support thresholds given in the experiment might also be greatly different.
4.2. Mining Results
Table 2 and
Table 3 were of the same structure. The eighth row (Support threshold) divided each table into two parts: the upper part and lower part, where the former presented the parameters of the original transaction set and the latter gave the results after the preprocessing and algorithm operation.
The name of each transaction set is given in the first row, and the dimension of each transaction set is listed in the second row, namely, the number of all different items in each transaction set. During the itemset mining process, the acceptance or rejection of these different items in the itemset constituted a solution space of the algorithm, so it was called dimension. The number of transactions in each transaction set and average length of overall transactions are presented in the third and fourthth rows, respectively, and their product could reflect the volume of each transaction set, with a direct impact on the time spent by the algorithm in traversing the CPU of the transaction set. The fifth and sixth rows list the lengths of shortest and longest transactions in each transaction set, respectively. The seventh row shows the maximum probability of single item to appear in each transaction set, which was also called the maximum support of frequent 1-itemset, reflecting the data sparsity of the transaction set.
In the eighth row, the parameters of the reduced transaction set obtained by preprocessing the original transaction set are displayed. The 9th row shows the dimension of the reduced transaction set. This dimension was decided by the given support threshold: the greater the threshold, the less the intercepted frequent 1-itemsets, the smaller the dimension, and the smaller the solution space after the reduction, which was better for the optimization. However, fewer MFIs were found, so this was contradictory. However,
Table 3 shows that the dimensions of transaction sets reduced from the two largest transaction sets were taken as 545 and 431, respectively, and the algorithm running time was also acceptable. The number of transactions in each reduced transaction set and the average length of overall transactions are given in the 10th and 11th rows. If the two figures were reduced, the volume of each transaction set was also shrunk. The shrinkage rate (12th row) was acquired by dividing two figures, where the divisor was the product between the number of transactions in the original transaction set and the average transaction length, and the dividend was the product between the number of transactions in the reduced transaction set and the average transaction length. Although the shrinkage degree of the transaction set was also decided by the given support threshold, individual transactions in each transaction set had different properties, so the shrinkage rate would differ even under the same threshold. The minimum and maximum transaction lengths of reduced transaction sets are given in the 13th and 14th rows.
The preprocessing time of transaction (15th row) was the time spent on acquiring a reduced transaction set from the original one, including the time needed to acquire the parameters of the original transaction set, generate files of the reduced transaction set, and establish a memory data matrix. The time(s) needed to mine all MFIs is presented in the 16th row.
Table 3 shows that the number of transactions in the largest transaction set
kosarak reached nearly million class, where its original dimension was 41,270. When the dimension was reduced to 431, it took the algorithm less than 4 h to find all MFIs. The quantity of MFIs found was 1265, which, theoretically, was accurate (i.e., the sets were of integrity and uniqueness). Therefore, the standalone big data association rule mining was feasible. If the transaction sets came from practical production and life, the algorithm would be pragmatic.
The 17th–19th rows list the number of MFIs found, item details in the MFI with the maximum support, and the corresponding support degree, respectively, aiming to facilitate readers in verifying and comparing this information.
4.3. Comparison of Algorithm Running Time with Solution Space Size
From the above experiment, a reduced transaction set was acquired from each original transaction set after the support threshold was given, and the dimension was also reduced. Therefore, the reduced dimension would vary with the support threshold, and so would the algorithm running time. The algorithm was proposed to implement the standalone operation of big data transaction sets. For the same transaction set, the reduced dimension would be increased if the support threshold was reduced, and as a result, the solution space would present an exponential (base number: 2) increase. If the algorithm running time was also increased according to an exponent with a base number of 2, the algorithm running time would experience explosive growth with the increase in dimension, which, obviously, deviated from the intention of this study.
To this end, the largest transaction set
kosarak was experimented under different thresholds for five times. The dimension reduced grew from 42, reaching as high as 431, and the acquired number of MFIs and algorithm running time are as seen in
Table 4. The data showed that the algorithm running time did not present exponential growth with the increase in dimension.
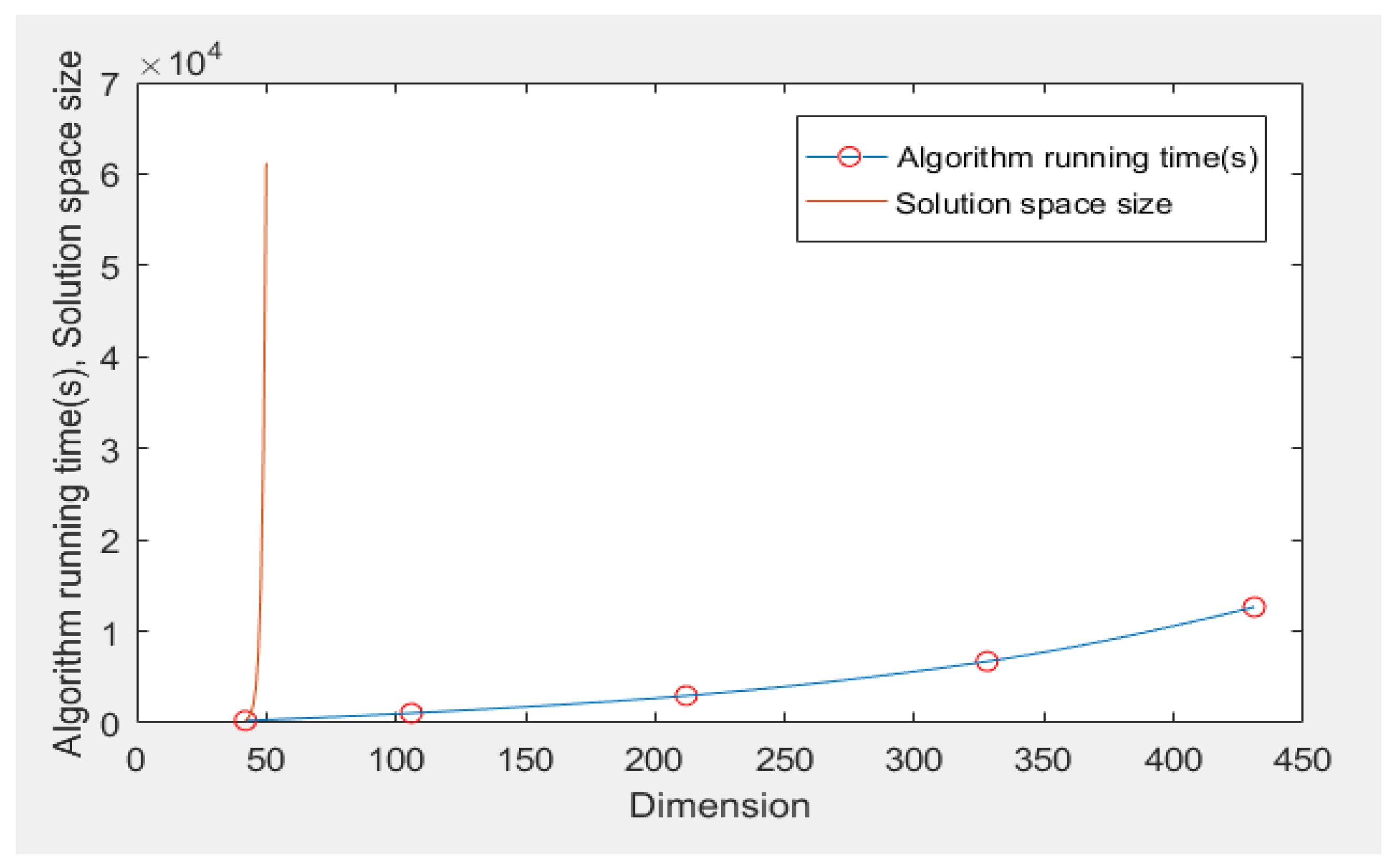
The solution space size was incomparable to the algorithm running time in dimension. As the algorithm ran for 238.9 s under the dimension of 42, the dimension-dependent exponential growth curve of solution space took the point (42, 238.9) in the plane as the starting point, and the fitted curvilinear contrast relation between the growth curve of solution space and actual algorithm running time is as shown in
Figure 4. Obviously, when the solution space showed exponential explosive growth (red line in the figure) with the dimension, the algorithm running time was under a slow growth trend (blue line with red circle, the experimental data are shown at the red circles). As the algorithm running time did not present exponential growth with the dimension (i.e., it did not experience explosive growth), the algorithm was feasible for the standalone calculation of high-dimensional properties of big data transaction sets.
4.4. Comparison of Algorithm Running Time with Traditional Exact Algorithm
The Apriori and FP-Growth algorithms were the two most classical accurate algorithms for mining association rules. PF-Growth was recognized to be faster than Apriori. However, PF-Growth was sensitive to the dimensions of the transaction set. Even the running time is unacceptable for mining the small transactions set listed in
Table 2, but the smallest dimension of the transaction set listed in
Table 2 is only 75.
In order to investigate quantitatively the running time of the algorithm, we extracted a small part of the Accident transaction set on average, such as 100, or 200, or 300 transactions, etc. Each transaction captures only 10%, or 20%, or 30% at the beginning of each transaction. In this way, small transaction sets with different transaction numbers and dimensions are used to test the running time of the PF-Growth algorithm. The dimensions of each transaction set are listed in
Table 5. The rows represent the different number of transactions, and the columns represent the percentage of each transaction captured. These transaction sets were used to test the PF-Growth algorithm, and the running time of PF-Growth is shown in
Table 6.
Since FP-Growth algorithm mined frequent itemsets and proposed algorithm mined maximal frequent itemsets, it had been verified that the results of FP-Growth were indeed subsets of the maximal frequent itemsets mined by proposed algorithm.
Table 6 reflects that the FP-Growth algorithm was not sensitive to transaction number but sensitive to dimension. When the dimension grown from 15 to 29, the FP-Growth had a longer running time than the exponential growth. By comparison, the proposed algorithm mined the full size set of incident transactions in only 8530.40 s. Of course, the proposed algorithm had fewer optimization targets, while FP-Growth had more optimization targets. The former was the maximal frequent itemsets, while the latter is the frequent itemsets, and the number of maximal frequent itemsets was less than the number of frequent itemsets.
4.5. Comparison with FPMax, CD, and DMM
Since parallel algorithms were very promising in solving big data mining, we make a simple comparison between the proposed algorithm and several well-known parallel algorithms, which are FPMax algorithm [
38], Count Distribution algorithm [
37], and DMM algorithm [
40]. Although PMM algorithm [
39] was also an excellent parallel algorithm and DMM was better than PMM algorithm overall, we do not compare with PMM.
In
Section 4.2, we present some experimental results on 10 public datasets. Some of these datasets have also been reported in the literature [
37,
38,
40]. We picked the experimental results data to the same dataset as
Table 7. Some figures were estimated from reported graphs, which gave a rough idea of algorithm performance.
With regard to the
Chess dataset and
Mushroom dataset, the experimental results of FPMax and our algorithm had the same support thresholds of 0.95 and 0.52. The running time of the algorithm is listed in
Table 7. FPMax is faster than the proposed algorithm, but the former was conducted using a cluster of computers, while the latter was carried out by a single computer. Of course, the hardware of the computer is also different, and the small data set leaded the running time to be haphazard.
The Pumsb dataset with the same support threshold 0.8 to three algorithms, CPU-time of CD algorithm was approximately 35,000 s, our algorithm was 46591.14 s. CD is great in that it executed the Pumsb * dataset, which is eight times larger than the Pumsb dataset. However, CD was executed on an eight-node cluster calculation. The DMM execution time under the same conditions was 9000 s, which was faster than CD algorithm. Additionally, DMM was executed on an 8-node cluster calculation.
The Accidents * dataset is four times larger than Accidents. To Accidents dataset and Accidents * with the different support threshold, CD and DMM for Accidents * with 0.4 and our algorithm for Accidents with 0.5. All three algorithms use single machine, that is, the number of nodes is 1. DMM was the fastest, CD was the slowest and our algorithm was in middle. However, the support thresholds they used were different. If the threshold value was small, more MFIs would be mined and it would take a longer time.
To sum up, the running time is basically an order of magnitude, and each algorithm has its own advantages and disadvantages. Some are suitable for dense datasets, while others are for long transaction data sets. Under the limitation of computer hardware, it is feasible to select the proposed algorithm which was executed on single notebook computer.
5. Discussion, Conclusion, and Expectation
According to the algorithm theory stated in this study, the transaction sets should be visited during the MFI searching. Therefore, the larger the volume of transaction sets, the longer the time needed by the algorithm running. The volume of the transaction set is the product between the quantity of transactions and average transaction length. As the Expanding Operation needs to add items, the greater the dimension of the transaction set, the longer the time needed by the algorithm running.
However, in the experiment on the 10 transaction sets, the reduced dimensions of both pumsb_star and pumsb are no more than 63, which are small compared with those of other transaction sets in the table, but the two transaction sets take the longest time (at least 12 h). The reduced dimension of T40I10D100K is the maximum (545), but it takes the least time, about 10 min. Moreover, the quantity of transactions and average transaction length in T40I10D100K are greater than those in pumsb_star and pumsb, and the quantity of transactions is even more than twice of those in pumsb_star and pumsb.
This is just like picking fruits in an orchard: the larger the orchard, the longer the time needed to search it once, but the experimental data show that this is not the case. Then, is it the case that the more the fruits, the longer the time needed? However, the experimental data in
Table 3 show that the quantity of MFIs found in
T40I10D100K is larger than those found in
pumsb_star and
pumsb. Is this related to the length of MFIs found? Even if the average length of MFIs found in
T40I10D100K is multiplied by 10 in order that it is equivalent to the average length of MFIs found in
pumsb_star and
pumsb, the calculation time will also be tenfold. Even so, the time spent is less than 1/10 of the time spent by
pumsb_star and
pumsb.
On the basis of the above analysis, there should be only one possibility: the main factor influencing the algorithm running time is neither the volume of transaction set nor the quantity of MFIs found, but it is correlated with the complexity of MFIs found. The complexity of MFIs does not have a linear relation with their length. Instead, the two present a growth relation greater than the linear growth relation. Whether this relation is an exponential relation and what the exponential relation (base number) remains to be further explored.
From another side, this indicates that the algorithm running time is not sensitive to the volume of the transaction set, so the algorithm is practical for big data.
Given this, can we understand it that the algorithm spends the time mainly in “picking fruits” but not “finding fruits”? From this angle, does it mean that the algorithm spends most of the time in acquiring the optimal solution with the excellent optimization path? The long algorithm running time is ascribed to the large quantity of MFIs but not to the large volume of transaction set or the great dimension of the reduced transaction set. The practical experimental data also verify that the algorithm is feasible, and even superior, for the standalone operation of high-dimensional big data transaction sets.
The algorithm is feasible and accurate for the MFI mining of high-dimensional transaction sets. However, it has a disadvantage in the association rule analysis based on frequent itemset mining. It can be known from the dimension of the reduced transaction set under the given support threshold that the time needed to search all MFIs subsequently is unpredictable. At times, the acceptable time is limited, and it is unnecessary to find all MFIs. Instead, the MFI with the maximum support should be first found within the limited time, followed by the MFI with the second largest support, and so on. In this way, the algorithm practicability will be higher.
Therefore, the subsequent study of this algorithm should focus on MFI mining under an adaptive support threshold in the following way: no support threshold is given in the algorithm running. Instead, as the time passes by, the algorithm finds the thresholds of all MFIs and sort them in a descending order. Within given time, the algorithm returns the minimum support threshold and the corresponding MFI.







{kind=link}
{kind=link}
{kind=link}
{kind=link}