
Multi-Objective Optimization for High-Dimensional Maximal Frequent Itemset Mining

Abstract
:1. Introduction
2. Related Concepts
2.1. Association Rules
2.2. Frequent Itemset
2.3. Mathematical Description of Multi-Objective Optimization of Maximal Frequent Itemset Mining
3. Multi-Objective Optimization of Maximal Frequent Itemset Mining
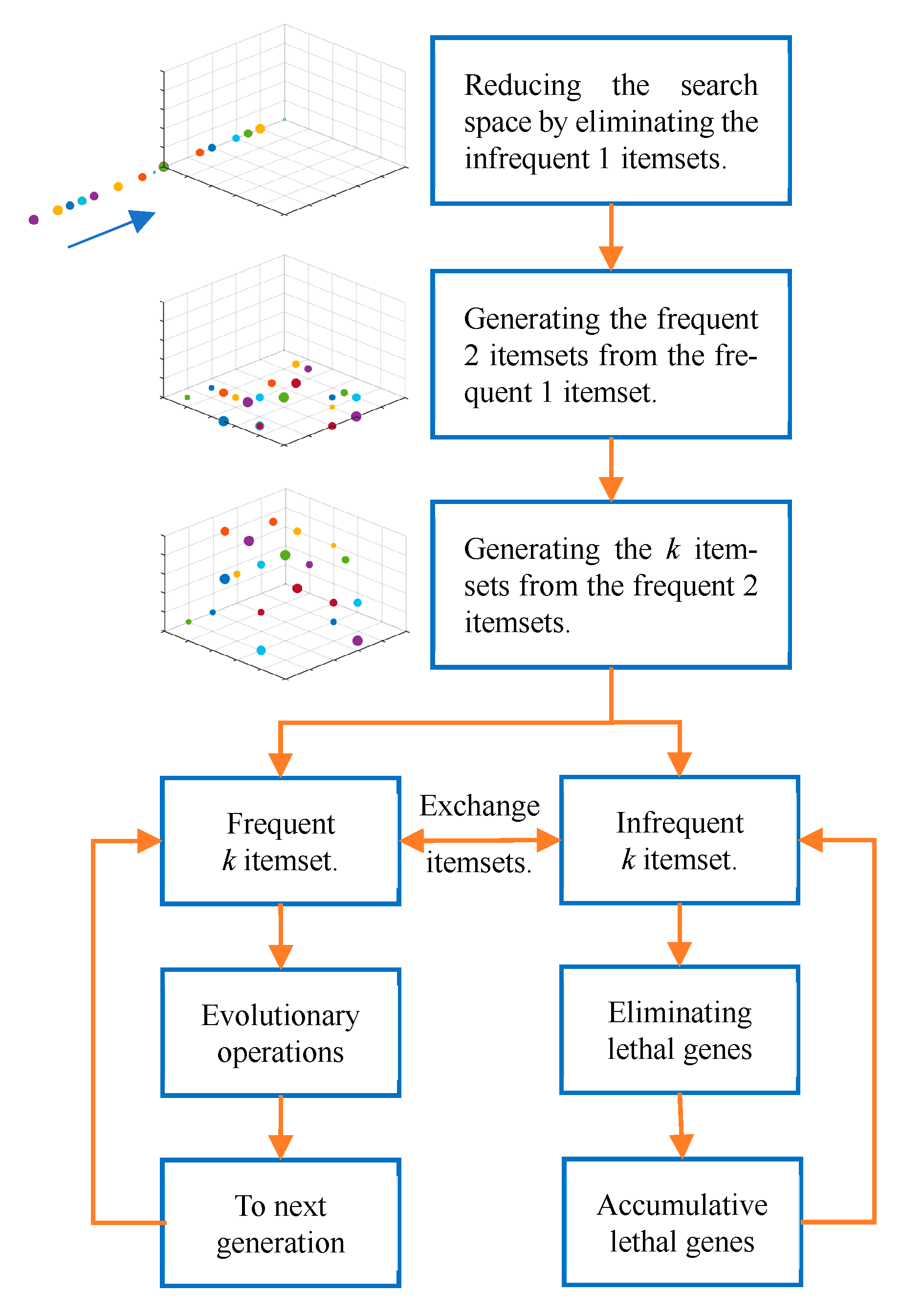
3.1. Working Diagram of MOO
3.2. Individual Gene Encoding
3.3. Using Reduced Transaction Sets
3.4. Fitness Function
| Algorithm 1 Giting fitness |
| Input: D = (T1, T2, …, Tn), X = (x1, x2, …, xm), A Output: A new X and it’s Fitness length = ; fitnesss = 0; f = 0; (r1, r2, …, rm) = (0, 0, …, 0); for i = 1: n do Continue with some probability; If A ⊆ Ti; then fitness = fitness + 1; for j = 1: m do rj = rj + tij; end end f = f + 1; end for j = 1: m do if ri/f > SupportThreshold then rj = 1; else rj = 0; end end if > length then select xk = 0 with rk/f > SupportThreshold; xk = 1; fitness = rk/f*(length + 1); else fitness = fitness/f*length; end Retrun fitness; |
3.5. Individual Gene Repair
| Algorithm 2 Repairing Operation |
| Input: X = (x1, x2, …, xm) with P(X) < threshold Output: Repaired X with P(X) >= threshold Select an item k with probability (1 − pi); while xk = 0 do Reselect an item as xk = 1 with probability (1 − pi); end xk = 0; |
4. Case Studies
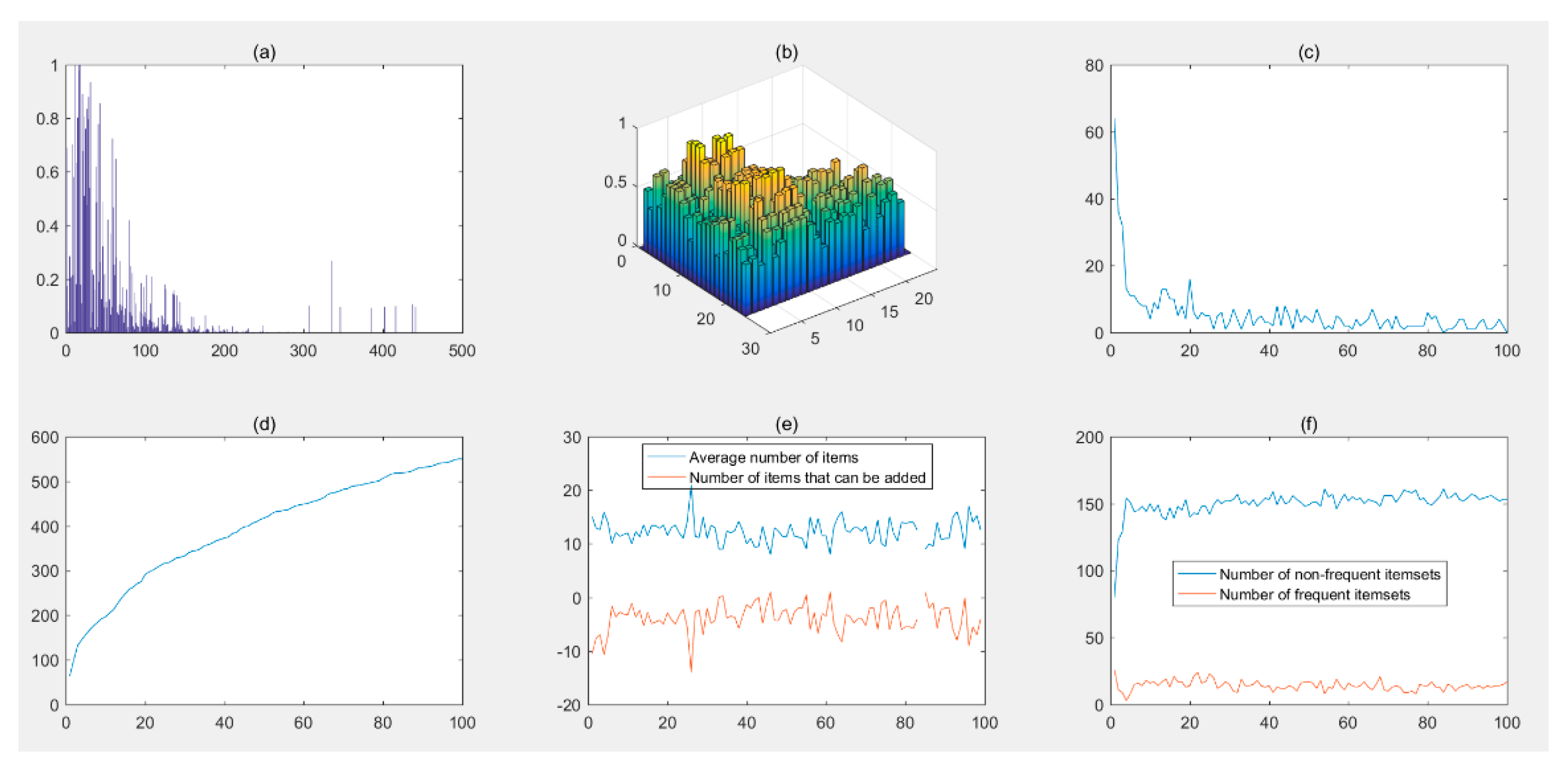
4.1. Accident Transaction Set Test
4.2. Supermarket Data Test
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hanirex, D.K. An Efficient TDTR Algorithm for Mining Frequent Itemsets. Int. J. Electron. Comput. Sci. Eng. 2013, 2, 251–256. [Google Scholar]
- Thomas, T.K.; Sudeep, K.S. An improved PageRank algorithm to handle polysemous queries. In Proceedings of the 2016 International Conference on Computing, Analytics and Security Trends (CAST) IEEE, Pune, India, 19–21 December 2016; pp. 106–111. [Google Scholar]
- Mohan, G.K. A Tabular Approach for Frequent itemset mining. Int. J. Adv. Res. Comput. Sci. 2011, 02, 191–197. [Google Scholar]
- Liao, Y.L.; Wang, X.G.; Zhan, X.G. Network services of personalized recommendation based on association rules. J. Anshan Univ. Sci. Technol. 2004, 27, 432–435. [Google Scholar]
- Hidayanto, B.C.; Muhammad, R.F.; Kusumawardani, R.P.; Syafaat, A. Network Intrusion Detection Systems Analysis using Frequent Item Set Mining Algorithm FP-Max and Apriori. Procedia Comput. Sci. 2017, 124, 751–758. [Google Scholar] [CrossRef]
- Srikant, R.; Agraw, R. Mining Quantitative Association Rules in Large Relational Tables. ACM Sigmod Rec. 1996, 25, 1–12. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach. Data Min. Knowl. Discov. 2004, 8, 53–87. [Google Scholar] [CrossRef]
- Heaton, J. Comparing dataset characteristics that favor the Apriori, Eclat or FP-Growth frequent itemset mining algorithms. In Proceedings of the SoutheastCon 2016, Norfolk, VA, USA, 30 March–3 April 2016; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Siahaan, A.P.U.; Aan, M.; Lubis, A.H.; Ikhwan, A.; Supiyandi, S. Association Rules Analysis on FP-Growth Method in Predicting Sales. Int. J. Recent Trends Eng. Res. (IJRTER) 2017, 03, 58–65. [Google Scholar]
- Anand, R.V.; Dinakaran, M. Handling stakeholder conflict by agile requirement prioritization using Apriori technique. Comput. Electr. Eng. 2017, 61, 126–136. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, H.; Sun, Z.; Dong, W.; Dong, Y.; Gong, S. Reliability Assessment of Wind Power Converter Considering SCADA Multistate Parameters Prediction Using FP-Growth, WPT, K-Means and LSTM Network. IEEE Access 2020, 8, 84455–84466. [Google Scholar] [CrossRef]
- Dong, D.; Ye, Z.; Cao, Y.; Xie, S.; Wang, F.; Ming, W. An Improved Association Rule Mining Algorithm Based on Ant Lion Optimizer Algorithm and FP-Growth. In Proceedings of the 2019 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; pp. 458–463. [Google Scholar]
- Hossain, M.; Sattar, A.S.; Paul, M.K. Market Basket Analysis Using Apriori and FP Growth Algorithm. In Proceedings of the 2019 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2019; pp. 1–6. [Google Scholar]
- Kaysar, M.S.; Khaled, M.A.B.; Hasan, M.; Khan, M.I. Word Sense Disambiguation of Bengali Words using FP-Growth Algorithm. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–5. [Google Scholar]
- Gao, X.; Wang, Y.; Sun, M.; He, C.; Jia, Y. Assisted analysis of acne metagenomics sequencing data based on FP-Growth method. In Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), Xiamen, China, 18–20 October 2019; pp. 1711–1714. [Google Scholar]
- Miao, Y.; Lin, J.; Xu, N. An improved parallel FP-growth algorithm based on Spark and its application. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3793–3797. [Google Scholar]
- Ginting, P.L.; Dengen, N.; Taruk, M. Comparison of Priori and FP-Growth Algorithms in Determining Association Rules. In Proceedings of the 2019 International Conference on Electrical, Electronics and Information Engineering (ICEEIE), Denpasar, Indonesia, 3–4 October 2019; pp. 320–323. [Google Scholar]
- Liu, F.; Su, Y.; Wang, T.; Fu, J.; Chen, S.; Ju, C. Research on FP-Growth algorithm for agricultural major courses recommendation in China Open University system. In Proceedings of the 2019 12th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 14–15 December 2019; pp. 167–170. [Google Scholar]
- Wang, Z.Z.; Cao, S. Power Load Association Rules Mining Method Based on Improved FP-Growth Algorithm. In Proceedings of the 2018 China International Conference on Electricity Distribution (CICED), Tianjin, China, 17–19 September 2018; pp. 2833–2837. [Google Scholar]
- Jia, Y.; Liu, L.; Chen, H. An Unknown Words Recognition Method for Micro-blog Short Text Based on Improved FP-Growth. In Proceedings of the 2018 14th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Huangshan, China, 28–30 July 2018; pp. 1–7. [Google Scholar]
- Zhang, Z.; Huang, J.; Wei, Y. Frequent item sets mining from high-dimensional dataset based on a novel binary particle swarm optimization. J. Cent. South Univ. 2016, 23, 1700–1708. [Google Scholar] [CrossRef]
- Bagui, S.; Stanley, P. Mining frequent itemsets from streaming transaction data using genetic algorithms. J. Big Data 2020, 7, 54. [Google Scholar] [CrossRef]
- Paladhi, S.; Chatterjee, S.; Goto, T.; Sen, S. AFARTICA: A Frequent Item-Set Mining Method Using Artificial Cell Division Algorithm. J. Database Manag. 2019, 30, 71–93. [Google Scholar] [CrossRef]
- Kuo, R.J.; Chao, C.M.; Chiu, Y.T. Application of particle swarm optimization to association rule mining. Appl. Soft Comput. 2011, 11, 326–336. [Google Scholar] [CrossRef]
- Ykhlef, M. A Quantum Swarm Evolutionary Algorithm for mining association rules in large databases. J. King Saud Univ. Comput. Inf. Sci. 2011, 23, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kabir, M.M.J.; Xu, S.; Kang, B.H.; Zhao, Z. Association Rule Mining for Both Frequent and Infrequent Items Using Particle Swarm Optimization Algorithm. Int. J. Comput. Sci. Eng. 2014, 6, 221–231. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, Third Edition (The Morgan Kaufmann Series in Data Management Systems). Acm Sigmod Rec. 2011, 31, 76–77. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Sanchez, L.; Garcia, S.; del Jesus, M.J.; Ventura, S.; Garrell, J.M.; Otero, J.; Romero, C.; Bacardit, J.; Rivas, V.M.; et al. KEEL: A software tool to assess evolutionary algorithms for data mining problems. Soft Comput. A Fusion Found. Methodol. Appl. 2008, 13, 307–318. [Google Scholar] [CrossRef]
- Caruccio, L.; Deufemia, V.; Naumann, F.; Polese, G. Discovering Relaxed Functional Dependencies Based on Multi-Attribute Dominance. IEEE Trans. Knowl. Data Eng. 2021, 33, 3212–3228. [Google Scholar] [CrossRef]
- Caruccio, L.; Deufemia, V.; Polese, G. Mining relaxed functional dependencies from data. Data Min. Knowl. Dis. 2020, 34, 443–477. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| 100 | 200 | 300 | 400 | 500 | |
|---|---|---|---|---|---|
| 10% | 13.916395 s | 26.744861 s | 25.966303 s | 33.145599 s | 46.008133 s |
| 20% | 488.286400 s | 771.563331 s | 872.430373 s | 919.101463 s | 979.192209 s |
| 30% | 8292.354528 s | >2.3 h | >2.3 h | >2.3 h | >2.3 h |
| Total number of items | 5547 |
| Number of transactions | 18,548 |
| Minimum transaction length | 1 |
| Maximum transaction length | 49 |
| Average transaction length | 3.527874 |
| Minimum support of item | 0.000054 |
| Maximum support of item | 0.165894 |
| Support threshold | 0.001000 |
| Number of items reduced | 360 |
| Number of transactions reduced | 16,701 |
| Minimum transaction length reduced | 1 |
| Maximum transaction length reduced | 25 |
| Average transaction length reduced | 2.923058 |
| Pretreatment CPU time | 9.146987 s |
| CPU time | 90.853013 s |
| Number of maximal frequent itemsets | 1010 |
| Itemset | Support | List of Items |
|---|---|---|
| Top 10 1-itemsets | 0.008465 | Caramel treats in bulk |
| 0.007171 | Fresh grade breast | |
| 0.007171 | Homemade candy | |
| 0.006901 | Garlic peanuts | |
| 0.006739 | Wine cake | |
| 0.006631 | Caterpillar vegetable | |
| 0.006631 | Daliyuan small bread | |
| 0.006631 | Ham butt | |
| 0.006524 | Northeast crystal rice in bulk | |
| 0.006362 | Crown pear | |
| Top 5 2-itemsets | 0.005230 | Chinese cabbage, chopped ribs |
| 0.004744 | Garlic, mature ginger | |
| 0.004691 | Chinese cabbage, garlic | |
| 0.004691 | Chinese cabbage, meteor cabbage | |
| 0.004637 | Chinese cabbage, broccoli | |
| Top 3 3-itemsets | 0.003612 | Chinese cabbage, needle mushroom, domestic banana |
| 0.002480 | Chinese cabbage, domestic banana, winter bamboo shoots | |
| 0.002103 | Chinese cabbage, domestic banana, chili pepper |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yu, W.; Ma, X.; Ogura, H.; Ye, D. Multi-Objective Optimization for High-Dimensional Maximal Frequent Itemset Mining. Appl. Sci. 2021, 11, 8971. https://doi.org/10.3390/app11198971
Zhang Y, Yu W, Ma X, Ogura H, Ye D. Multi-Objective Optimization for High-Dimensional Maximal Frequent Itemset Mining. Applied Sciences. 2021; 11(19):8971. https://doi.org/10.3390/app11198971
Chicago/Turabian StyleZhang, Yalong, Wei Yu, Xuan Ma, Hisakazu Ogura, and Dongfen Ye. 2021. "Multi-Objective Optimization for High-Dimensional Maximal Frequent Itemset Mining" Applied Sciences 11, no. 19: 8971. https://doi.org/10.3390/app11198971