
An Empirical Study of a Trustworthy Cloud Common Data Model Using Decentralized Identifiers


Abstract
:Featured Application
Abstract
1. Introduction
- DID-based user-centric identification is the first to approach supporting researchers autonomously with the identity verification with a verified proof without a third parity having central authority in the cloud CDM.
- We propose and solve the service model that extends the DID basic model in order to solve the structural problem where it is difficult to participate in external researchers in the hospital situation related to IRB approval.
- We validate user access control by applying the DID service model in the safe data transfer process between hospitals in Korea.
- Our service model provides high interoperability by operating the prototype of identity proof using the standard messaging environment using DIDComm.
2. Related Works
2.1. CDM
2.2. Blockchain and Its Application in CDM
2.3. Decentralized Identifier (DID)
- It provides individuals with independent control over their personal data.
- It has to allow interoperability with other decentralized ledgers.
- It supports the attribute and claims schema system written to the ledger for dynamic discovery of claim types.
- Privacy and protection
- User control and consent
- Dependency
- Fault tolerance
- Usability
3. The Extended to Identify Management Scheme for Cloud CDM
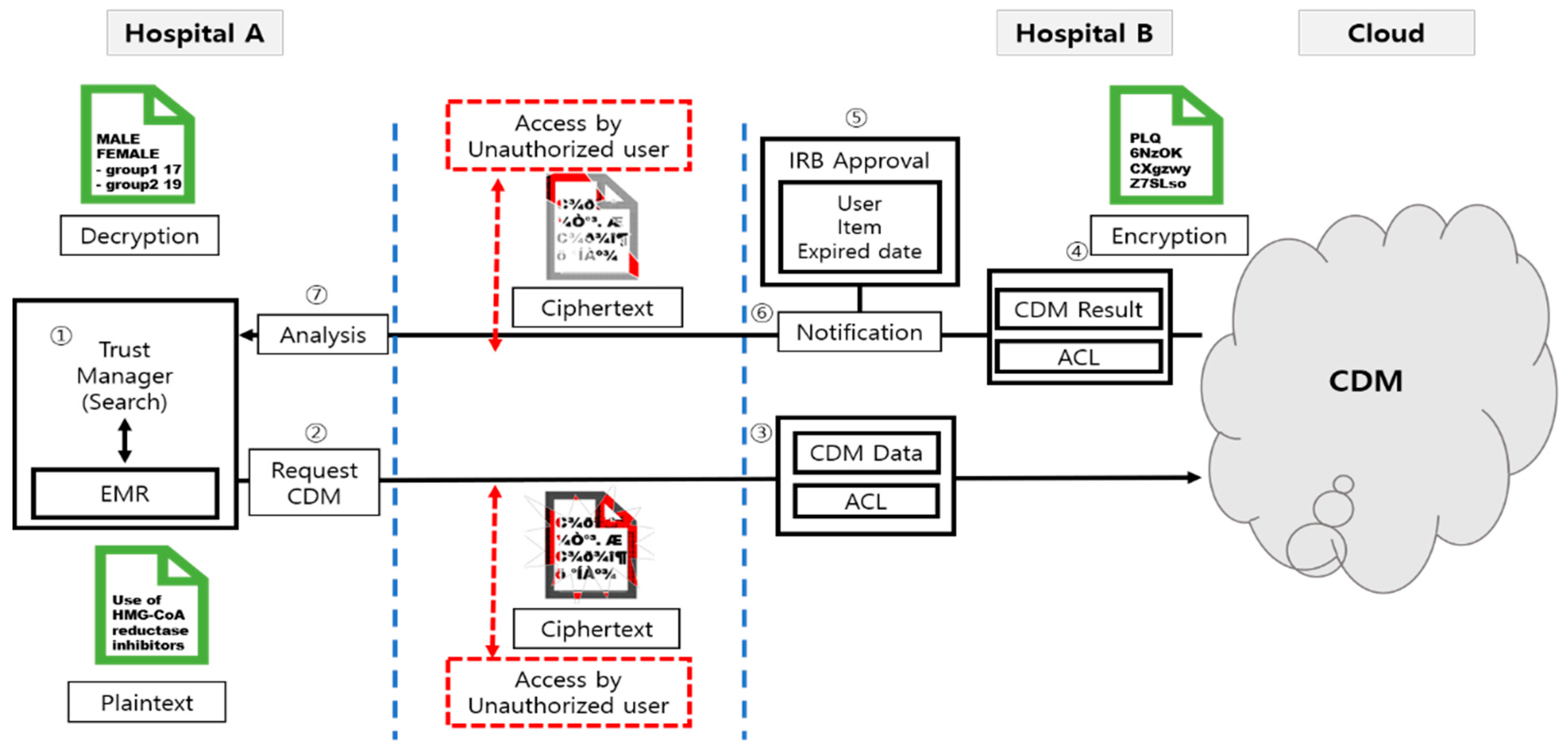
3.1. The Cloud CDM Model
- Cryptography can be used for protecting information, using a hash value to maintain management of large-capacity CDMs. Encryption can be used to protect information using symmetric and asymmetric keys to maintain the management of large-capacity CDMs.
- A distributed ledger is used to provide data integrity and share information through a CDM signature.
- In the process of data creation and use, the distributed ledger guarantees data integrity, and transparently signed CDM can be accessed.
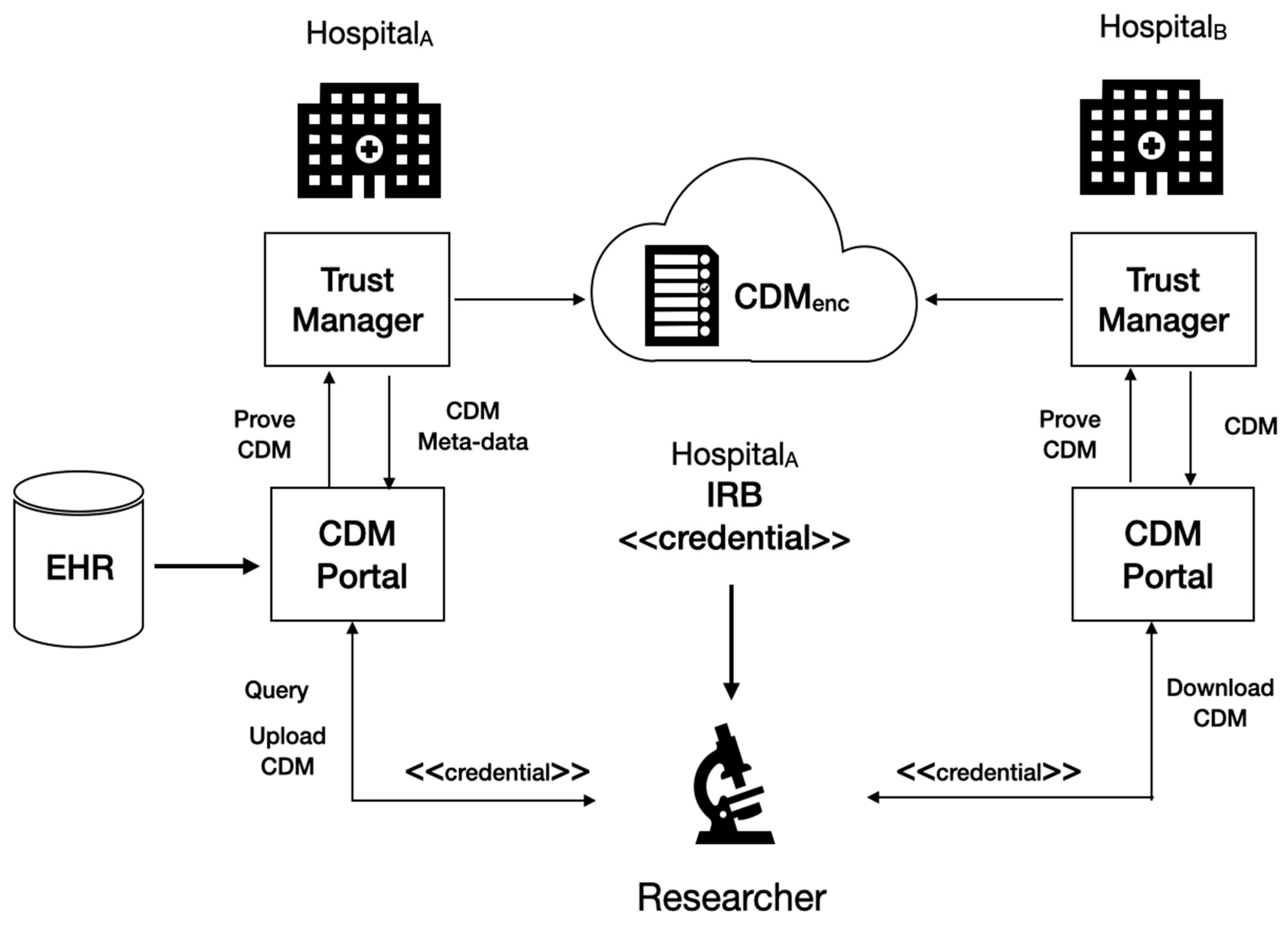
3.2. The Operation Scheme for Trustworthiness in CDM Cloud
- A researcher registered in a medical institution, Hospital B, sends a query to the EMR DB managed Hospital A.
- The researcher requests the trust manager of Hospital A for CDM to hold the cloud CDM based on the result of the query.
- The trust manager of Hospital A obtains the IRB’s approval for the request for the EMR data with the credential for identifying the researcher.
- The trust manager in Hospital A builds the approved EMR data into CDM data and its metadata associated with encryption keys and storing the CDM encrypted to distribute to a repository in cloud CDM.
- The trust manager in Hospital A uploads the encrypted data to the cloud CDM.
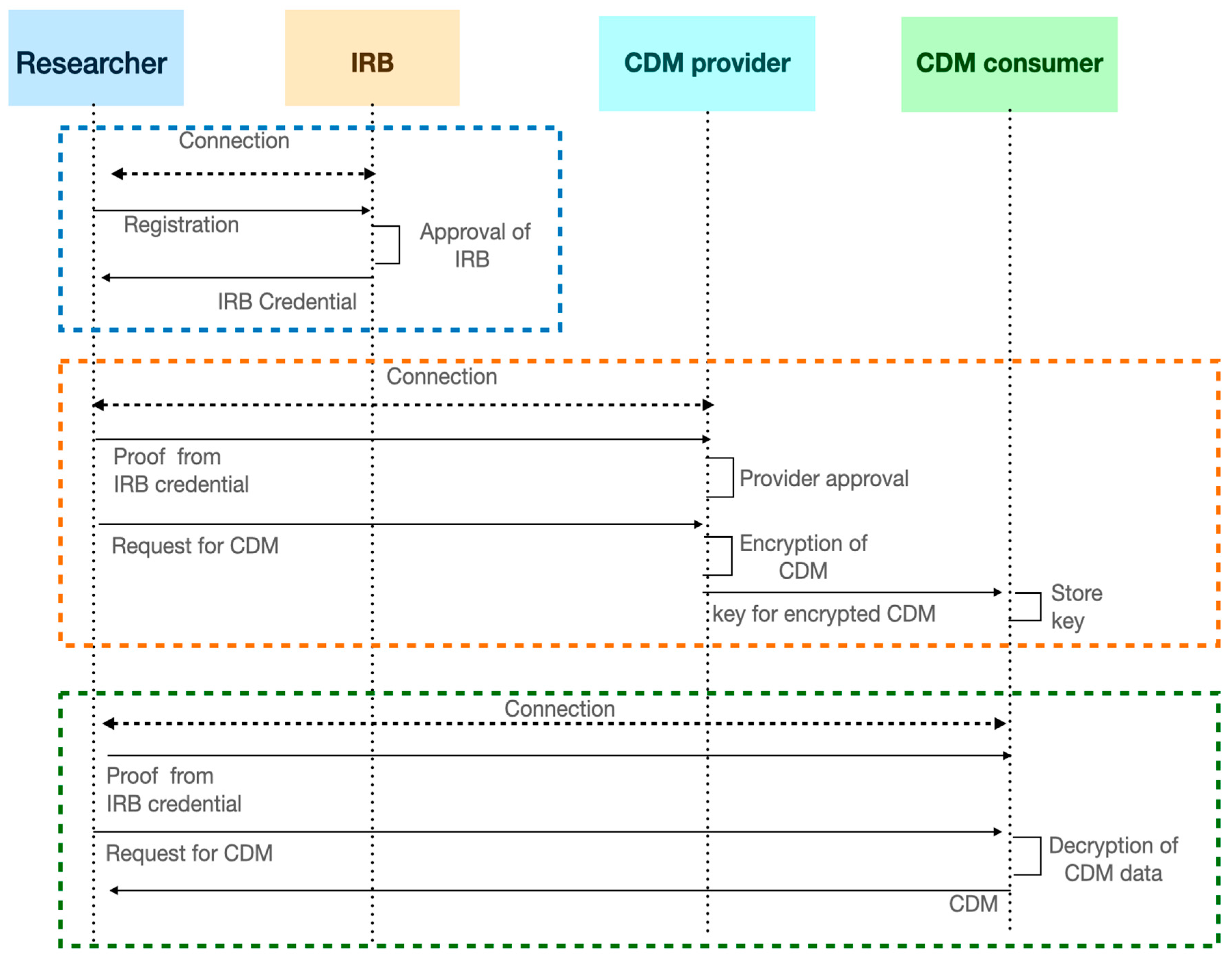
3.3. The Basic DID Model for Cloud CDM
- A researcher is a member of a group of researchers of a specific subject on which he or she wants to conduct research and is assigned a role as a research participant through IRB approval and is registered. Through the IRB, researchers are provided with a certificate of research participation (issuing research participation certificate through IRB).
- CDM users apply to the creation of CDM data, encryption of the generated CDM data, and proof of access service for use in distributed storage.
- CDM users apply for access service verification for decryption and distributed storage of CDM data in the process of accessing the created CDM data.
- For CDM use, researchers are registered with the CDM provider or user organization. Through the registration process, the researcher assumes that the mutual trust relationship of the cloud CDM participating organizations can be established, managed, and managed through the certificate authority (CA).
- IRB approval documents are used for the purpose of price proof for CDM provision and use (users who have received credentials in the IRB use DID to identify their identity).
- The researcher is provided with the ID of the CDM provider through the approval of the IRB.
- The CDM provider decides to provide the CDM through verification of the researcher’s identity certificate. After qualification verification, the CDM provider performs encryption and distributed storage of CDM data.
- CDM users access the encrypted and distributed CDM data through verification of the researcher’s identity certificate via the CDM consumer.
- The researcher’s research participation certificate maintains the research period as an attribute and allows access to CDM services and data limited to the valid period.
3.4. Credential Definition of Identity
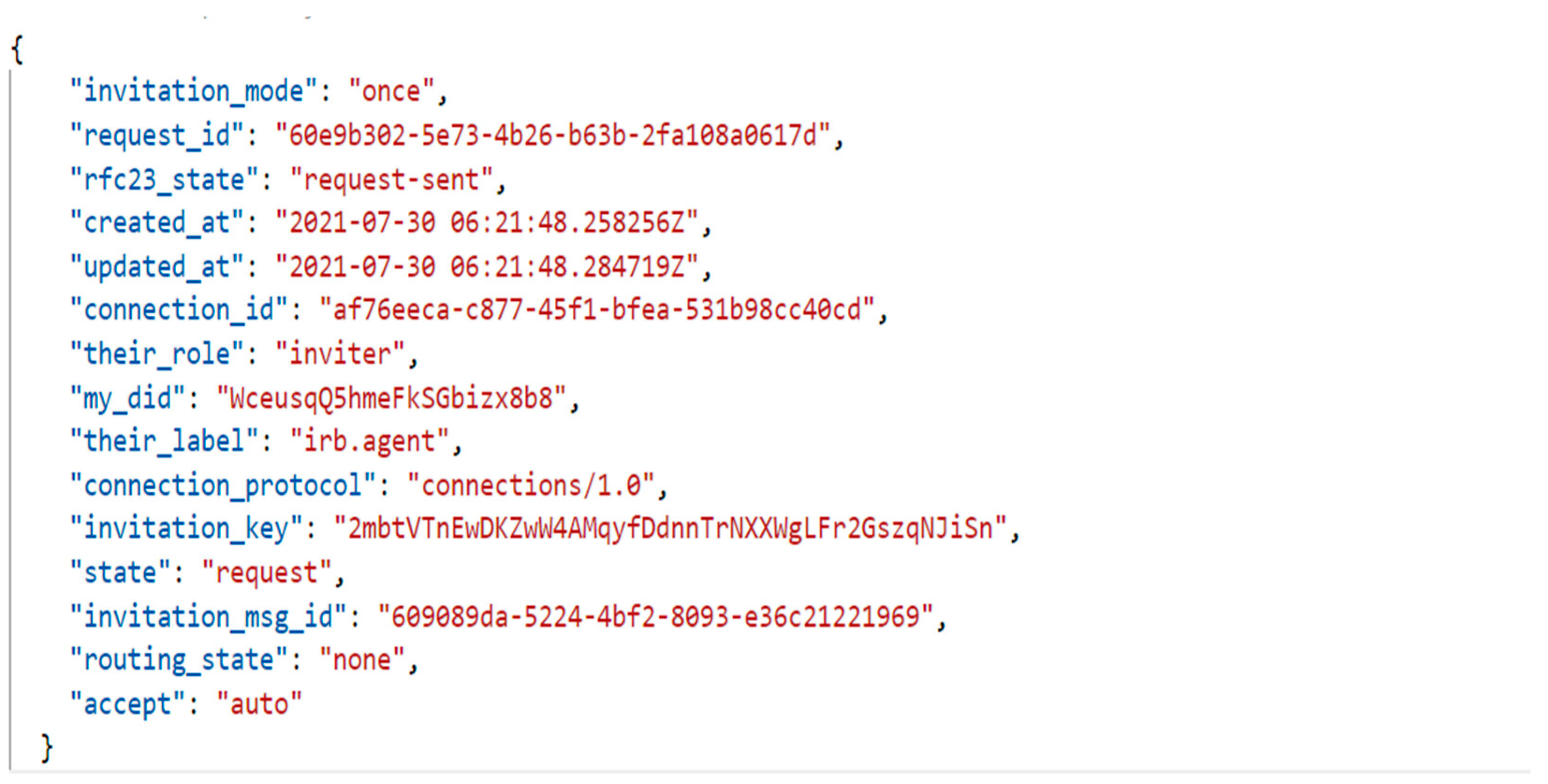
- Schema ID: T8j4DNmf7Us8tTzpvoK6No:2:IRB schema:51.1.53
- Cred def ID: T8j4DNmf7Us8tTzpvoK6No:3:CL:38:irb.agent.IRB_schema
- Type: CRED_DEF
- Reference: 38
- Signature type: CL
- Tag: irb.agent.IRB_schema
- Attributes: affiliation, approved_date, gcp, irb_no, master_secret, name, role, timestamp
| Algorithm 1 Establishing Trusted Connections |
| 1: Researcher agent exchanges DIDs with the IRB agent to establish a DIDComm channel. |
| 2: IRB offers an audited researcher credential over this channel. |
| 3: Researcher accepts and stores the credential in their wallet. |
| † Audited researcher credential is specified by IRB. |
3.5. Issuing IRB Credential
- The issuer sends the holder an offer message.
- The holder responds with a request message.
- The issuer completes the exchange by sending the holder an issue message containing the verifiable credential.
- The holder sends a proposal to the issuer (issuer receives proposal). When the holder starts with sending a proposal, it uses the/issue-credential-2.0/send-proposal endpoint.
- The issuer sends an offer to the holder based on the proposal (holder receives offer). The issuer receives the proposal and can respond with an offer using the/issue-credential-2.0/records/{id}/send-offer endpoint. After this offer, the flow continues with the holder responding with a request.
- The holder sends a request to the issuer (issuer receives request). If the holder automatically accepts offers and turns them into requests, then the issuing of credentials would be completely automated. That improves privacy—making the user in control of when and whom to share information with.
- The issuer sends credentials to the holder (holder receives credentials). The issue credential protocol is used to enable an issuer to provide a holder with a verifiable credential. In this protocol:
- There are two participants (issuer, holder).
- There are four message types (propose, offer, request, and issue).
- There are four states (proposed, offered, requested, and issued).
- The holder stores credentials and sends acknowledgement to the issuer. Verifiable credentials are issued to the user and stored in his/her digital wallet, and the user decides when and where to use them.
- The issuer receives acknowledgement.
| Algorithm 2 Issuing credential |
| 1: for each Researcher agent do |
| 2: Initiate DID Exchange with CDM provider agent to establish DIDComm channel. |
| 3: Researcher agent delivers the CDM selected to CDM provider agent via DIDComm channel. |
| 4: CDM provider offers Verified CDM token credential over DIDComm. |
| 5: Researcher agent accepts and stores the credential |
| 6: CDM provider encrypts the CDM and delivers the cipher CDM to CDM consumer agent with the IRB number approved by IRB |
| 7: end for |
| The CDM is derived from the EMR of in CDM provider |
| Verified CDM token credential is specified by PROVIDER |
3.6. Proof the Credential
4. Implementation
4.1. Experimental Setup
4.2. Experimental Result
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Shivade, C.; Raghavan, P.; Fosler-Lussier, E.; Embi, P.J.; Elhadad, N.; Johnson, S.B.; Lai, A.M. A review of approaches to identifying patient phenotype cohorts using electronic health records. J. Am. Med. Inform. Assoc. 2014, 21, 221–230. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, J.C.; Ferreira da Silva, C.; Martins, J.P. Roaming service for electric vehicle charging using blockchain-based digital identity. Energies 2021, 14, 1686. [Google Scholar] [CrossRef]
- Liu, B.; Yuan, X.-T.; Yu, Y.; Liu, Q.; Metaxas, D. Decentralized Robust Subspace Clustering. Proc. AAAI Conf. Artif. Intell. 2016, 30, 3539–3545. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/10473 (accessed on 1 July 2021).
- Xia, S.; Zheng, S.; Wang, G.; Gao, X.; Wang, B. Granular ball sampling for noisy label classification or imbalanced classification. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- You, S.C.; Lee, S.; Cho, S.Y.; Park, H.; Jung, S.; Cho, J.; Yoon, D.; Park, R.W. Conversion of National Health Insurance Service-National Sample Cohort (NHIS-NSC) database into observational medical outcomes partnership-common data model (OMOP-CDM). Stud. Health Technol. Inf. 2017, 245, 467–470. [Google Scholar]
- Chadwick, D.W. Federated identity management. Foundations of security analysis and design v. Lect. Notes Comput. Sci. 2009, 5705, 96–120. [Google Scholar]
- Jayaraman, I.; Mohammed, M. Secure Privacy Conserving Provable Data Possession (SPC-PDP) framework. Inf. Syst. E-Bus. Manag. 2019, 1–27. [Google Scholar] [CrossRef]
- Xiong, L.; Li, F.G.; Zeng, S.K.; Peng, T.; Liu, Z.C. A Blockchain-based privacy-awareness authentication scheme with efficient revocation for multi-server architectures. IEEE Access 2019, 7, 125840–125853. [Google Scholar] [CrossRef]
- Cho, J.H.; Kang, Y.; Park, Y.B. Secure delivery scheme of common data model for decentralized cloud platforms. Appl. Sci. 2020, 10, 7134. [Google Scholar] [CrossRef]
- Pãnescu, A.T.; Manta, V. Smart contracts for research data rights management over the ethereum blockchain network. Sci. Technol. Libr. 2018, 37, 235–245. [Google Scholar] [CrossRef]
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; de Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger fabric: A distributed operating system for permissioned blockchains. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018; ACM: New York, NY, USA, 2018; p. 30. [Google Scholar]
- Dagher, G.G.; Mohler, J.; Milojkovic, M.; Marella, P.B. Ancile: Privacy-preserving framework for access control and interoperability of electronic health records using blockchain technology. Sustain. Cities Soc. 2018, 39, 283–297. [Google Scholar] [CrossRef]
- Silberschatz, A.; Korth, H.F.; Sudarshan, S. Database System Concepts; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Hyperledger/Aries-Cloudagent-Python. Available online: https://github.com/hyperledger/aries-cloudagent-python (accessed on 1 April 2021).
- Reed, D.; Sporny, M.; Longley, D.; Allen, C.; Grant, R.; Sabadell, M. Decentralized Identifiers (DIDs) v1.0—Core Architecture, Data Model, and Representations. IT Security and Privacy—A Framework for Identity Management (ISO/IEC 24760-1). Available online: https://www.w3.org/TR/did-core/ (accessed on 1 March 2021).
- Blumenthal, D.; Tavenner, M. The “meaningful use” regulation for electronic health records. N. Engl. J. Med. 2010, 363, 501–504. [Google Scholar] [CrossRef]
- Jensen, P.B.; Jensen, L.J.; Brunak, S. Mining electronic health records: Towards better research applications and clinical care. Nat. Rev. Genet. 2012, 13, 395–405. [Google Scholar] [CrossRef] [PubMed]
- Glicksberg, B.S.; Oskotsky, B.; Giangreco, N.; Thangaraj, P.M.; Rudrapatna, V.; Datta, D.; Butte, A.J. ROMOP: A light-weight R package for interfacing with OMOP-formatted electronic health record data. JAMIA Open 2019, 2, 10–14. [Google Scholar] [CrossRef] [PubMed]
- Reps, J.M.; Schuemie, M.J.; Suchard, M.A.; Ryan, P.B.; Rijnbeek, P.R. Design and implementation of a standardized framework to generate and evaluate patient-level prediction models using observational healthcare data. J. Am. Med. Inf. Assoc. 2018, 25, 969–975. [Google Scholar] [CrossRef] [PubMed]
- Voss, E.A.; Makadia, R.; Matcho, A.; Ma, Q.; Knoll, C.; Schuemie, M.; Ryan, P.B. Feasibility and utility of applications of the common data model to multiple, disparate observational health databases. J. Am. Med. Inf. Assoc. 2015, 22, 553–564. [Google Scholar] [CrossRef] [Green Version]
- Garza, M.; Del Fiol, G.; Tenenbaum, J.; Walden, A.; Zozus, M.N. Evaluating common data models for use with a longitudinal community registry. J. Biomed. Inform. 2016, 64, 333–341. [Google Scholar] [CrossRef]
- Hripcsak, G.; Duke, J.D.; Shah, N.H.; Reich, C.G.; Huser, V.; Schuemie, M.J.; Ryan, P.B. Observational Health Data Sciences and Informatics (OHDSI): Opportunities for observational researchers. Stud. Health Technol. Inform. 2015, 216, 574. [Google Scholar]
- Yoon, D.; Ahn, E.K.; Park, M.Y.; Cho, S.Y.; Ryan, P.; Schuemie, M.J.; Park, R.W. Conversion and data quality assessment of electronic health record data at a Korean tertiary teaching hospital to a common data model for distributed network research. Healthc. Inform. Res. 2016, 22, 54–58. [Google Scholar] [CrossRef] [PubMed]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decent. Bus. Rev. 2008, 21260–21268. [Google Scholar]
- Alamri, B.; Javed, I.T.; Margaria, T. A GDPR-compliant framework for IoT-based personal health records using blockchain. In Proceedings of the 2021 11th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 19–21 April 2021; pp. 1–5. [Google Scholar]
- Simply Vital Health. Available online: https://www.simplyvitalhealth.com/ (accessed on 29 December 2018).
- Roehrs, A.; da Costa, C.A.; da Rosa Righi, R. OmniPHR: A distributed architecture model to integrate personal health records. J. Biomed. Inform. 2017, 71, 70–81. [Google Scholar] [CrossRef]
- Landau, S.; Le van Gong, H.; Wilton, R. Achieving privacy in a federated identity management system. In Financial Cryptography and Data; Dingledine, R., Golle, P., Eds.; Security 2009. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5628. [Google Scholar] [CrossRef]
- Allen, C. The Path to Self-Sovereign Identity. Life with Alacrity. Available online: http://www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html (accessed on 1 July 2021).
- Hardjono, T.; Pentland, A. Verifiable anonymous identities and access control in permissioned blockchains. arXiv 2019, arXiv:1903.04584. [Google Scholar]
- Shrestha, A.K.; Vassileva, J. Blockchain-based research data sharing framework for incentivizing the data owners. In Proceedings of the International Conference on Blockchain, Seattle, WA, USA, 25–30 June 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 10974, pp. 259–266. [Google Scholar]
- Augot, D.; Chabanne, H.; Chenevier, T.; George, W.; Lambert, L.; Augot, D.; Chabanne, H.; Chenevier, T.; George, W.; Lambert, L. A user-centric system for verified identities on the Bitcoin blockchain. In Data Privacy Management, Cryptocurrencies and Blockchain Technology; Springer: Oslo, Norway, 2017; Volume 10436, pp. 390–407. [Google Scholar]
- Halpin, H. NEXTLEAP: Decentralizing identity with privacy for secure messaging. In Proceedings of the 12th International Conference on Availability, Reliability and Security, Reggio Calabria, Italy, 29 August–1 September 2017; pp. 1–10. [Google Scholar]
- Babkin, S.; Epishkina, A. Authentication protocols based on one-time passwords. In Proceedings of the 2019 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg, Russia, 28–31 January 2019; pp. 1794–1798. [Google Scholar]
- Zhang, R.; Xue, R.; Liu, L. Security and privacy on blockchain. ACM Comput. Surv. 2019, 52, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Taking the Sovrin Foundation to a Higher Level: Introducing SSI as a Universal Service. Available online: https://sovrin.org/taking-the-sovrin-foundation-to-a-higher-level-introducing-ssi-as-a-universal-service/ (accessed on 10 August 2020).
- Meralli, S. Privacy-preserving analytics for the securitization market: A zero-knowledge distributed ledger technology application. Financ. Innov. 2020, 6, 1–20. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traditional Identity Management | DID | |||
|---|---|---|---|---|
| Isolated | Centralized | Federated | ||
| Privacy and protection | Low | Low | Low | High |
| User control and consent | Low | Low | Moderate | High |
| Dependency | Moderate | High | High | Low |
| Fault tolerance | High | High | Moderate | Low |
| Usability | Low | Low | Moderate | High |
| Item | Model |
|---|---|
| CPU | Intel(R) Xeon(R) E-2134 |
| RAM | 16 Gbyte |
| OS | Linux 3.1.0 |
| Docker | 19.03.8 |
| Docker-compose | 1.21.0 |
| Name | HTTP Port | Admin API Port | Webhook Port |
|---|---|---|---|
| Researcher | 8030 | 8031 | 8032 |
| IRB | 8010 | 8011 | 8012 |
| CDM Provider | 8050 | 8051 | 8052 |
| CDM Consumer | 8060 | 8061 | 8062 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Y.; Cho, J.; Park, Y.B. An Empirical Study of a Trustworthy Cloud Common Data Model Using Decentralized Identifiers. Appl. Sci. 2021, 11, 8984. https://doi.org/10.3390/app11198984
Kang Y, Cho J, Park YB. An Empirical Study of a Trustworthy Cloud Common Data Model Using Decentralized Identifiers. Applied Sciences. 2021; 11(19):8984. https://doi.org/10.3390/app11198984
Chicago/Turabian StyleKang, Yunhee, Jaehyuk Cho, and Young B. Park. 2021. "An Empirical Study of a Trustworthy Cloud Common Data Model Using Decentralized Identifiers" Applied Sciences 11, no. 19: 8984. https://doi.org/10.3390/app11198984