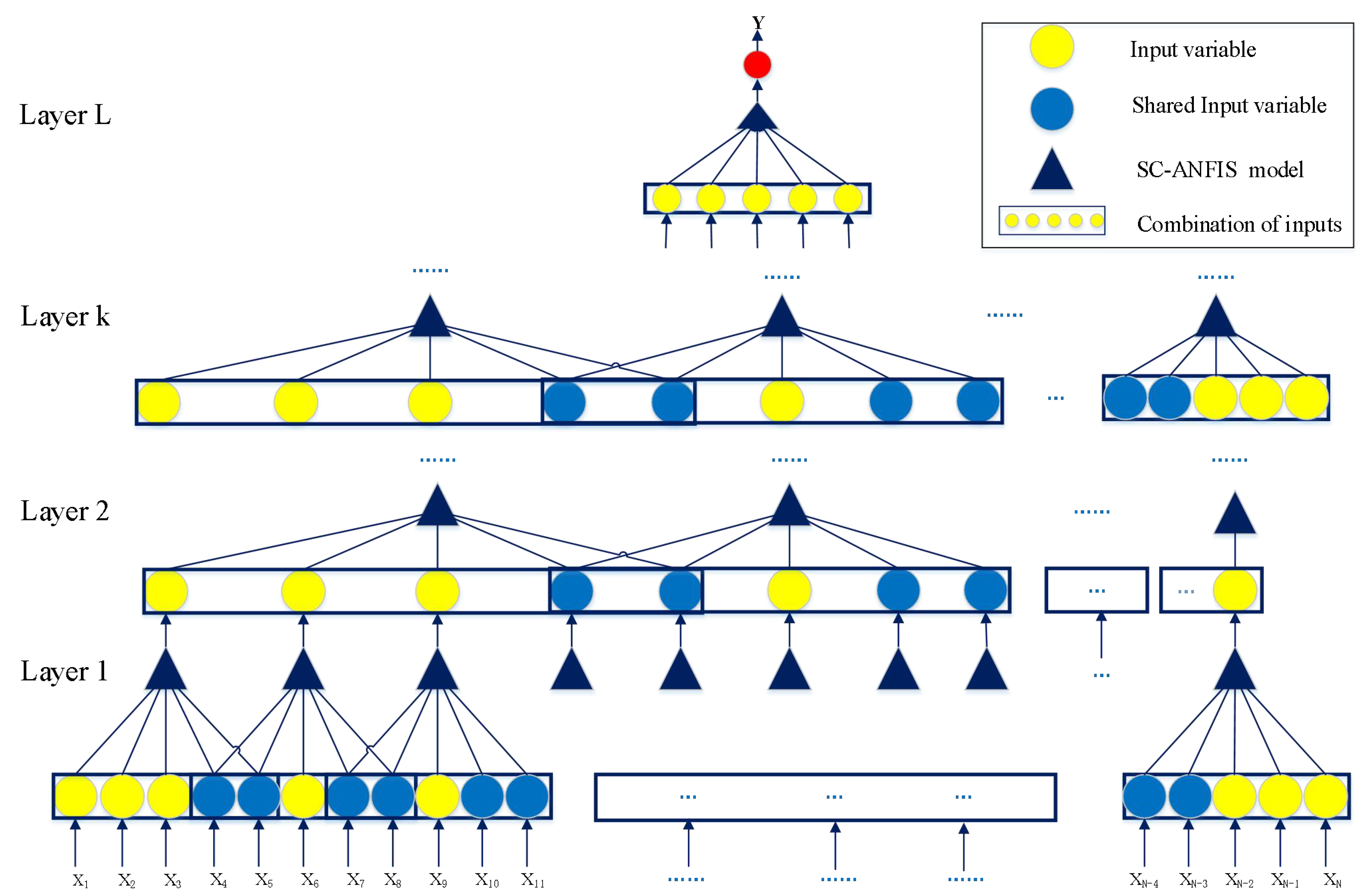
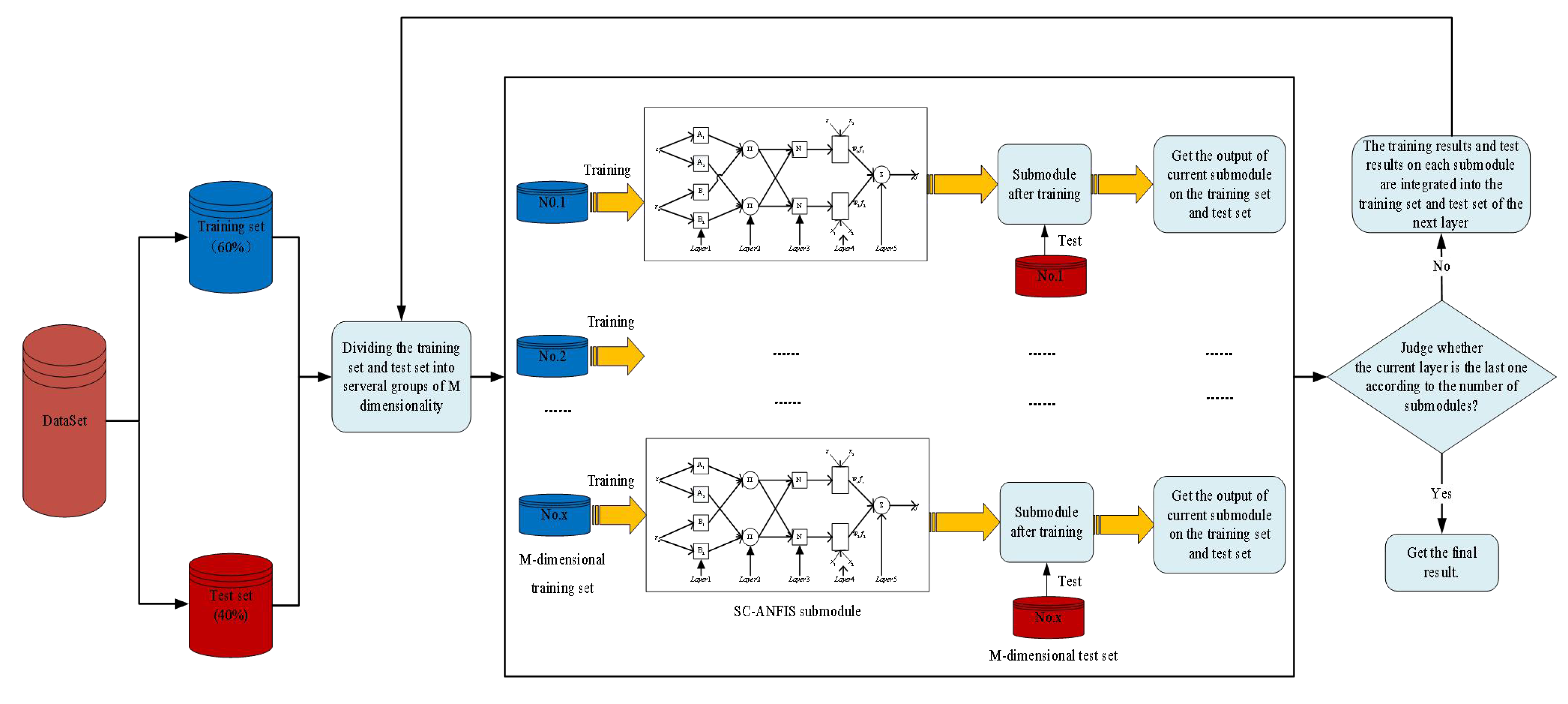
4.1. The Effect of the Number of Submodule Inputs on the DNFS
This section mainly focuses on the effect of the number of submodule inputs on the DNFS for the first three datasets. The corresponding DNFSs with 3, 4, and 5 submodule inputs are DNFS3-0, DNFS4-0, and DNFS5-0, respectively.
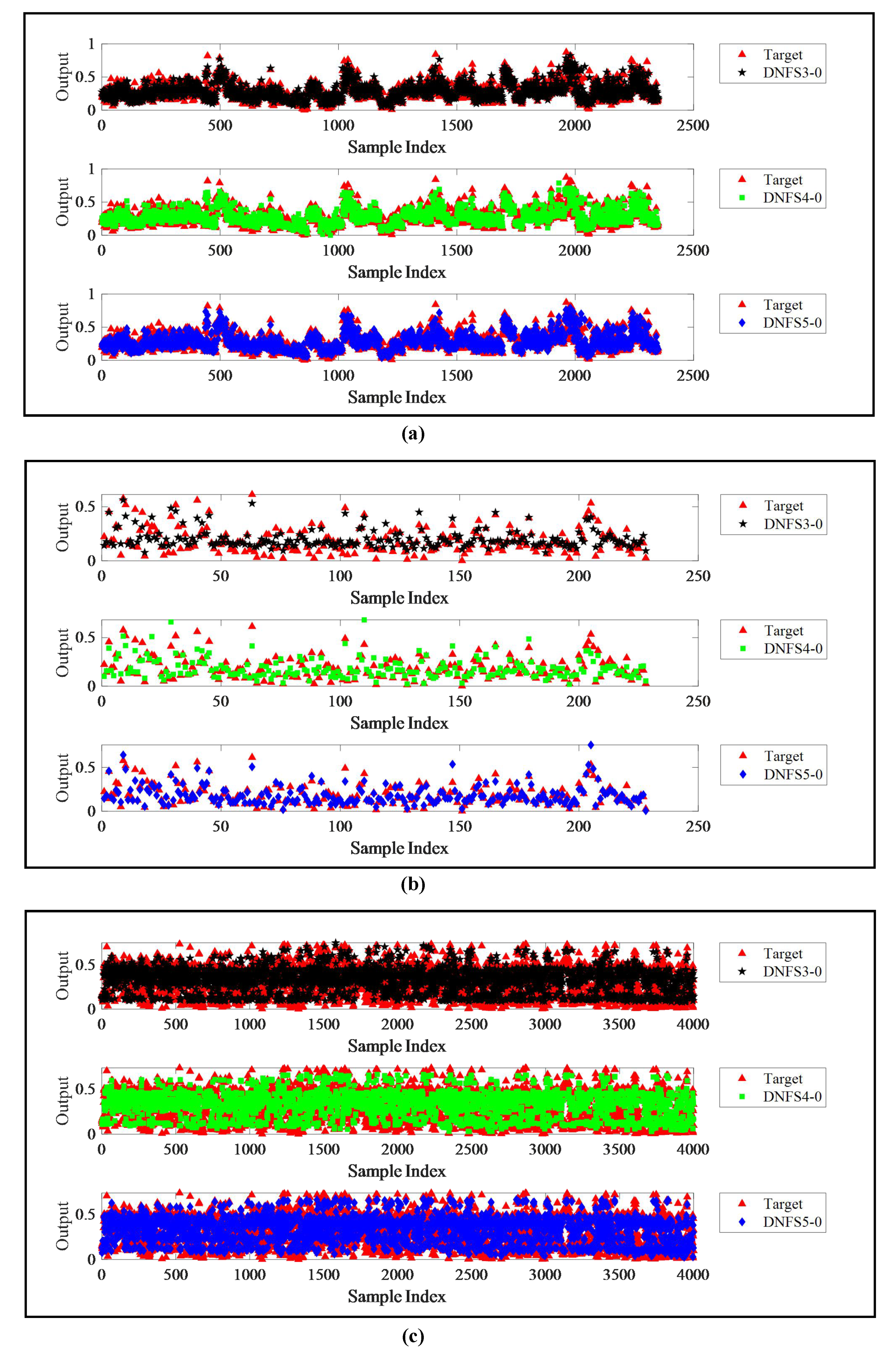
The performance comparison of DNFSs with different submodule inputs on the first three test datasets are shown in
Table 2,
Table 3 and
Table 4. The prediction charts performed by the three DNFSs on the first three test datasets are shown in
Figure 3. The analysis of the results obtained was as follows:
DNFS5-0 outperformed DNFS3-0 and DNFS4-0 in the prediction accuracy, which determined that its comprehensive score was always the highest among the three cases. The MAE, RMSE, and SMAPE of DNFS5-0 were smaller than the other two algorithms on the three datasets. As shown in
Figure 3, it also can be seen that DNFS5-0 achieved the best fitting effect, while the other two algorithms performed relatively poor.
In terms of model complexity, DNFS5-0 had the minimum layers and submodules, followed by DNFS4-0 and DNFS3-0. It can be concluded that more submodules and layers needed to be built to decompose the high-dimensional data with fewer submodule inputs. Meanwhile, DNFS5-0 had the most parameters and DNFS3-0 the least on average. The AIC of DNFS3-0 was the minimum for the first two datasets, while DNFS5-0 obtained the best AIC on Dataset No. 3.
The average computational time that DNFS3-0, DNFS4-0, and DNFS5-0 spent on the three datasets was 31.21 s, 36.44 s, and 58.32 s respectively. It can be concluded that DNFS3-0 is the most efficient method for the three cases.
Based on the analysis above, DNFS5-0 can ensure the optimal performance with less complexity. The advantage of DNFS5-0 was further revealed with the increase of dimensionality, by which the high-dimensional data could be divided into submodules more rapidly. Therefore, the DNFS algorithm with five submodule inputs was researched further.
4.2. The Effect of the Number of Inputs Shared by Adjacent Submodules on the DNFS
The target of this section is to explore the performance of the DNFS with different shared inputs on the first three datasets.
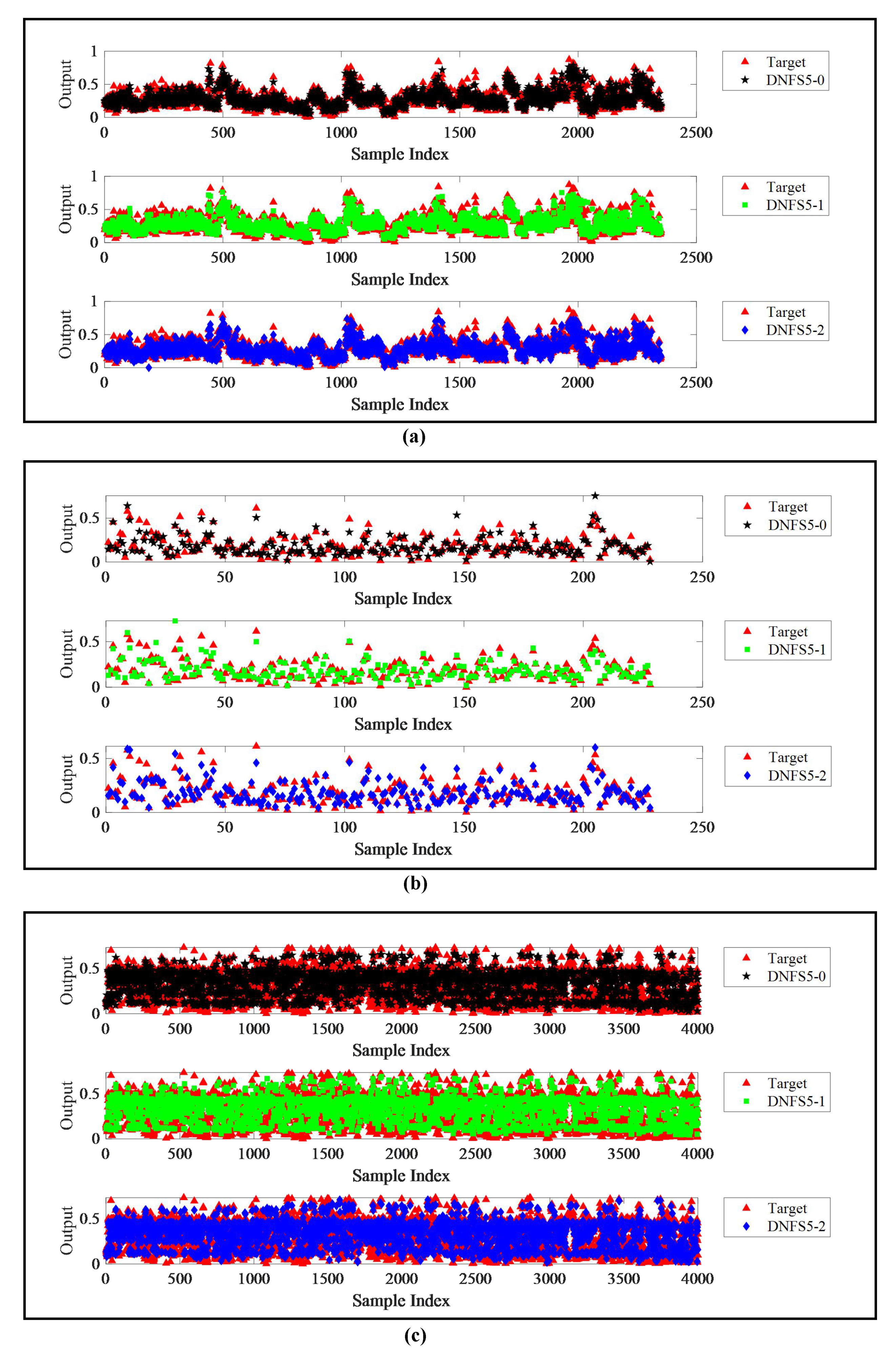
As shown in
Table 5,
Table 6 and
Table 7, DNFS5-2 had the minimum MAE, RMSE, and SMAPE on the three test datasets, which indicated that the best prediction accuracy can be achieved by DNFS5-2. As shown in
Figure 4, it can be seen obviously that DNFS5-2 achieved the best fitting effect on the three test datasets among the three cases.
Based on the experimental results obtained, it also can be found that the structures of DNFS5-0 and DNFS5-1 were simpler than DNFS5-2. There is no doubt that the more shared inputs there are, the more layers and submodules will be under the same submodule inputs. Consequently, DNFS5-2 had the most layers, submodules, and parameters on average, which led to its poor AIC value.
On average, DNFS5-0, DNFS5-1, and DNFS5-2 spent 60.02 s, 49.93 s, and 70.84 s on the three test datasets. Therefore, DNFS5-1 is the most efficient method, followed by DNFS5-0 and DNFS5-2.
As the comprehensive performance was taken into consideration, the superiority of DNFS5-2 is shown obviously. The score of DNFS5-2 was the highest among the three DNFSs, which can resolve the high-dimensional data within a valid period of time. On the whole, DNFS without shared input had a simpler structure, and that with two shared inputs had better prediction accuracy.
4.3. The Effect of the Combination of Submodule Inputs on the DNFS
To reveal the effect of the combination of submodule inputs on the DNFS, this paper introduced DNFS5-2-Random. The implementation steps of DNFS5-2-Random are as follows: each time DNFS5-2 is executed, the input of each layer is randomly scrambled. After DNFS5-2 is executed in this way 10 times, the optimal input order is taken as the final order of DNFS5-2, and the corresponding results are obtained.
Meanwhile, in order to validate the effectiveness and superiority of DNFS, MBGD-RDA, which is the latest training algorithm for TSK FSs, was introduced to be compared with DNFS. MBGD-RDA was implemented by the MATLAB implementation given in [
26], and its initial learning parameters were consistent with [
26], which proved to be the optimal one. Besides, the radial basis function (RBF) [
38], generalized regression neural network (GRNN) [
39], and long-short term memory (LSTM) [
40] were also introduced to further reveal the superiority of the DNFS, which represent general machine learning models. Their implementation were mainly realized by calling the
newrb,
newgrnn, and
trainNetwork functions of the deep learning toolbox in MATLAB 2020a, whose learning parameters were mainly selected as the default values of the functions.
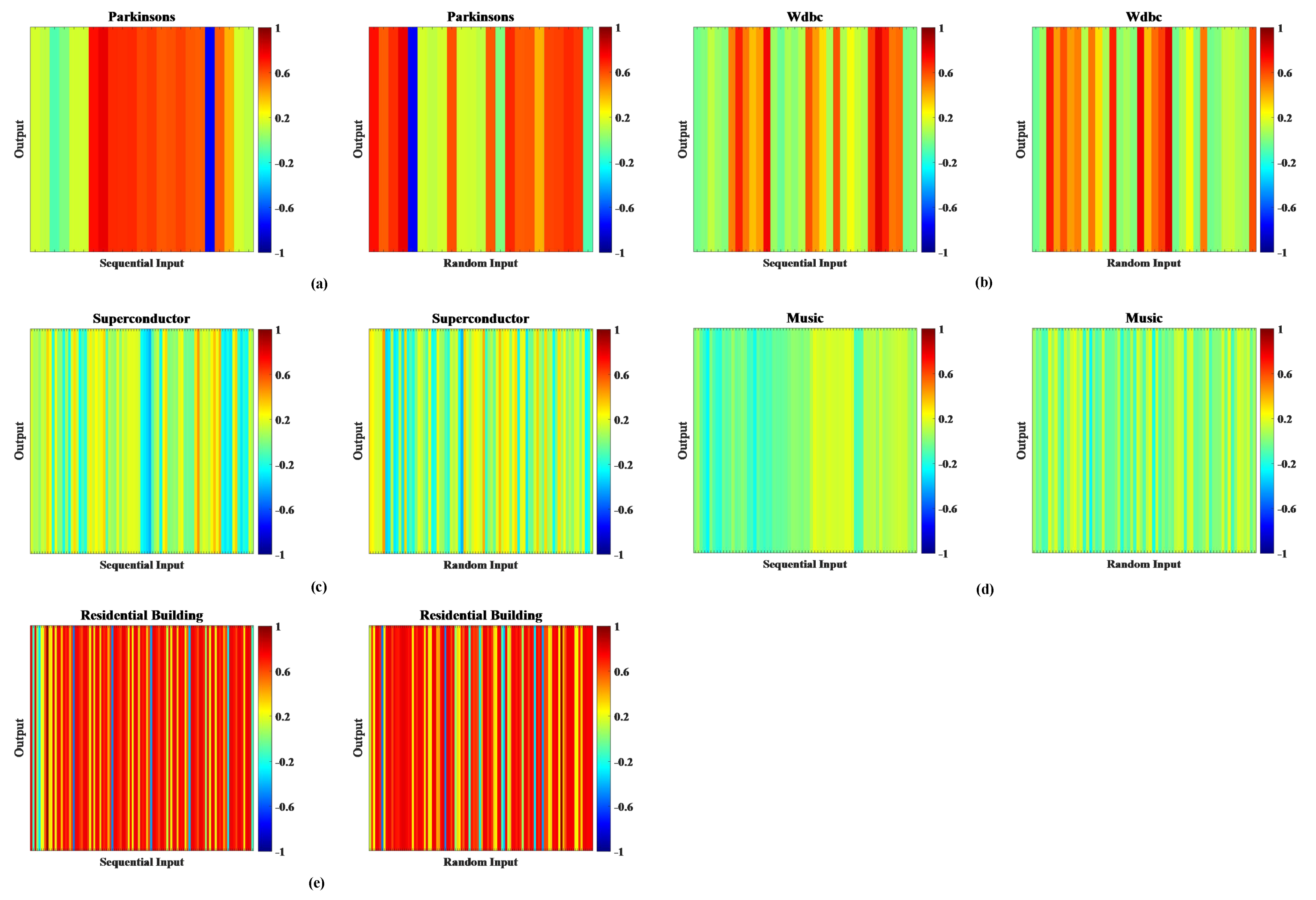
The analysis of the effect of different combinations of submodule inputs: By analyzing the structure of the DNFS, the combination of inputs for each submodule of the first layer played a key role in improving the performance of the DNFS. Therefore, we performed the Pearson correlation analysis on the confusion inputs of the first layer obtained in the experiments with the output variable.
Figure 5 shows the correlation analysis diagram between the output and inputs sequentially and randomly on the five datasets. It can be seen obviously that the input variables with high correlation values were relatively concentrated both sequentially and in the random cases on Dataset No. 1 and No. 3. On the contrary, the inputs with high correlation values were more scattered in the random case than that of the sequential case on Dataset No.2, No. 4, and No. 5.
Meanwhile, the results of
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 indicate that DNFS5-2-Random achieved better performance than DNFS5-2 on Dataset No. 2, No. 4, and No. 5. Compared with DNFS5- 2, DNFS5-2-Random decreased by 38.8%, 27.7%, and 38.5% the MAE, RMSE, and SMAPE for Test Dataset No. 2, while it decreased them by 19.9%, 16.7%, and 18.9% for Test Dataset No. 4, and by 72.4%, 71.8%, and 57.7% for Test Dataset No. 5, respectively. However, their performance was not significantly differences on the other two datasets.
Through the analysis of the results obtained, it can be concluded that the features that had a higher correlation with the output should be dispersed into each submodule, so that the performance of each submodule can be balanced and the overall performance improved.
The analysis of the performances of the DNFS and the other algorithms: The performance comparison of the DNFS with the other algorithms on the five test datasets is shown in
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12. The prediction charts for different algorithms are shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10. Through observation and analysis, the following information can be obtained:
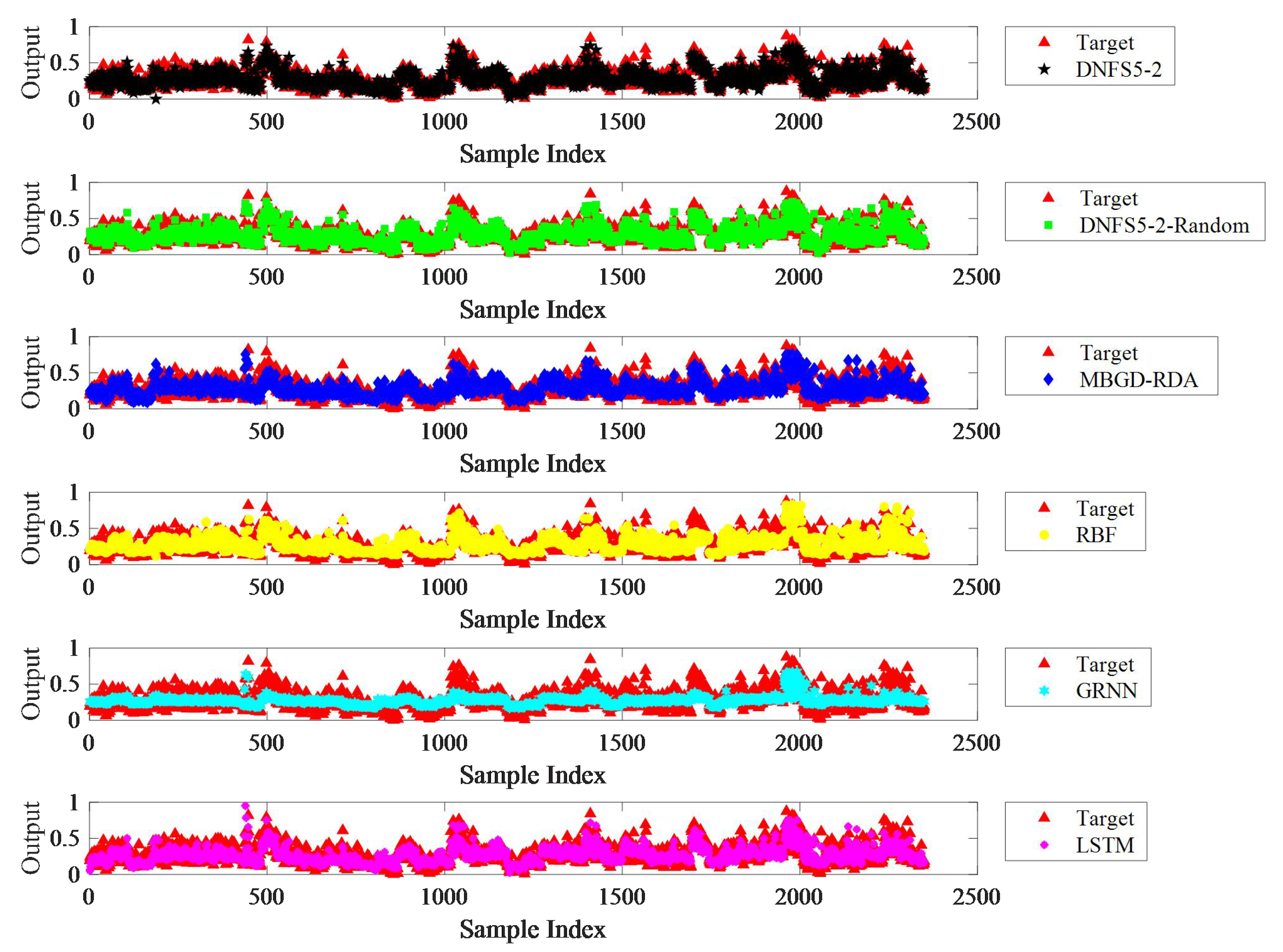
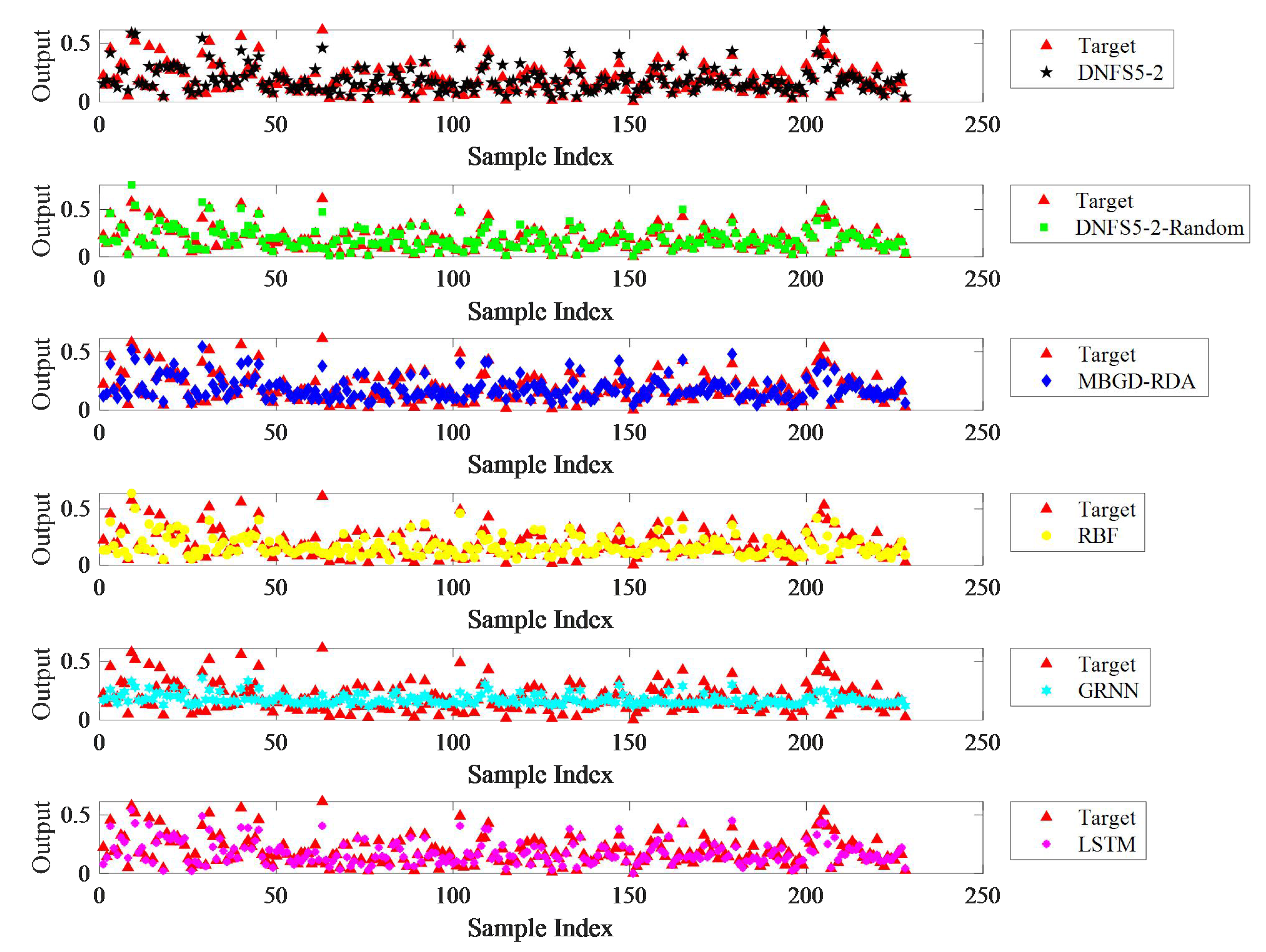
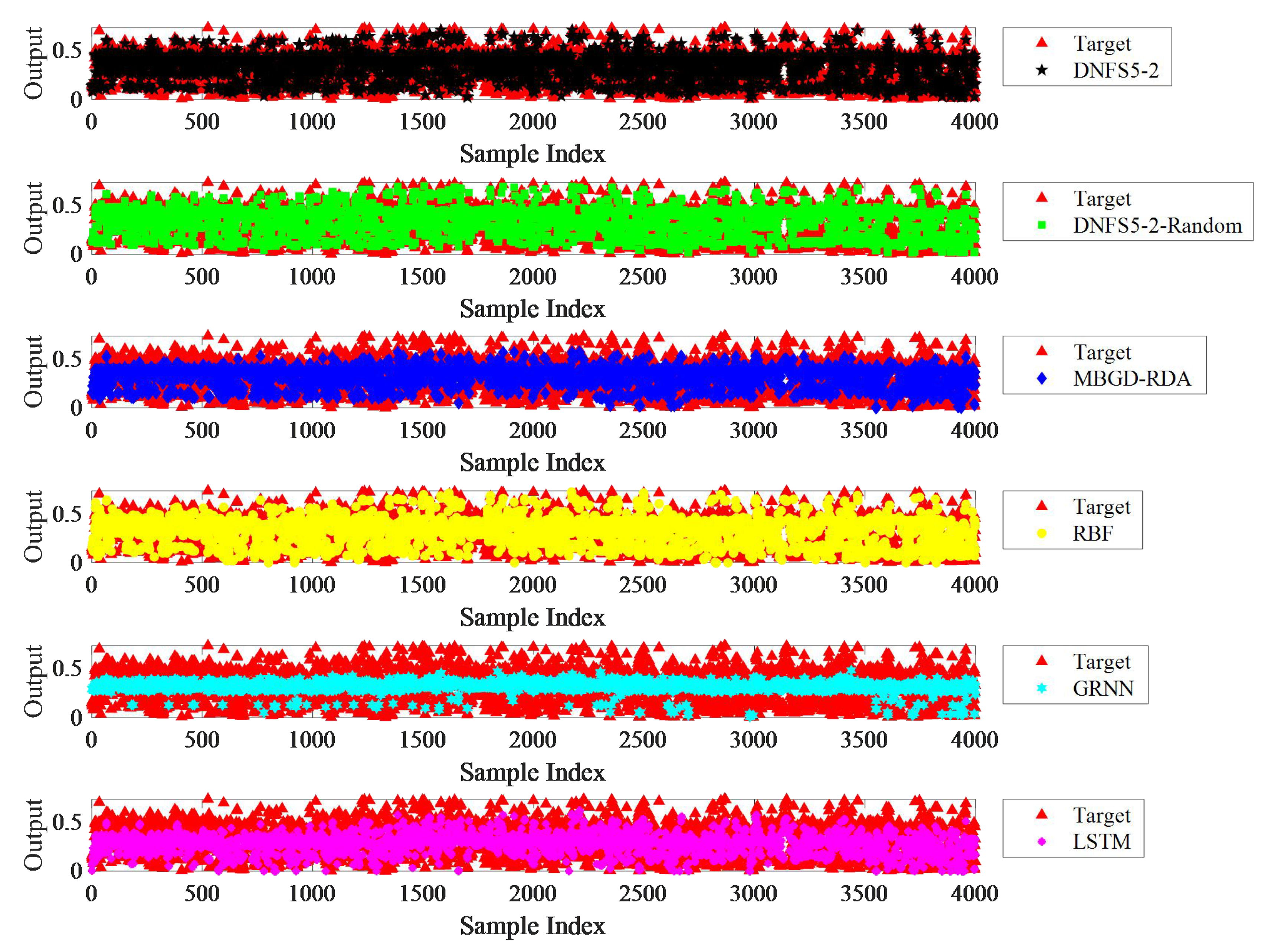
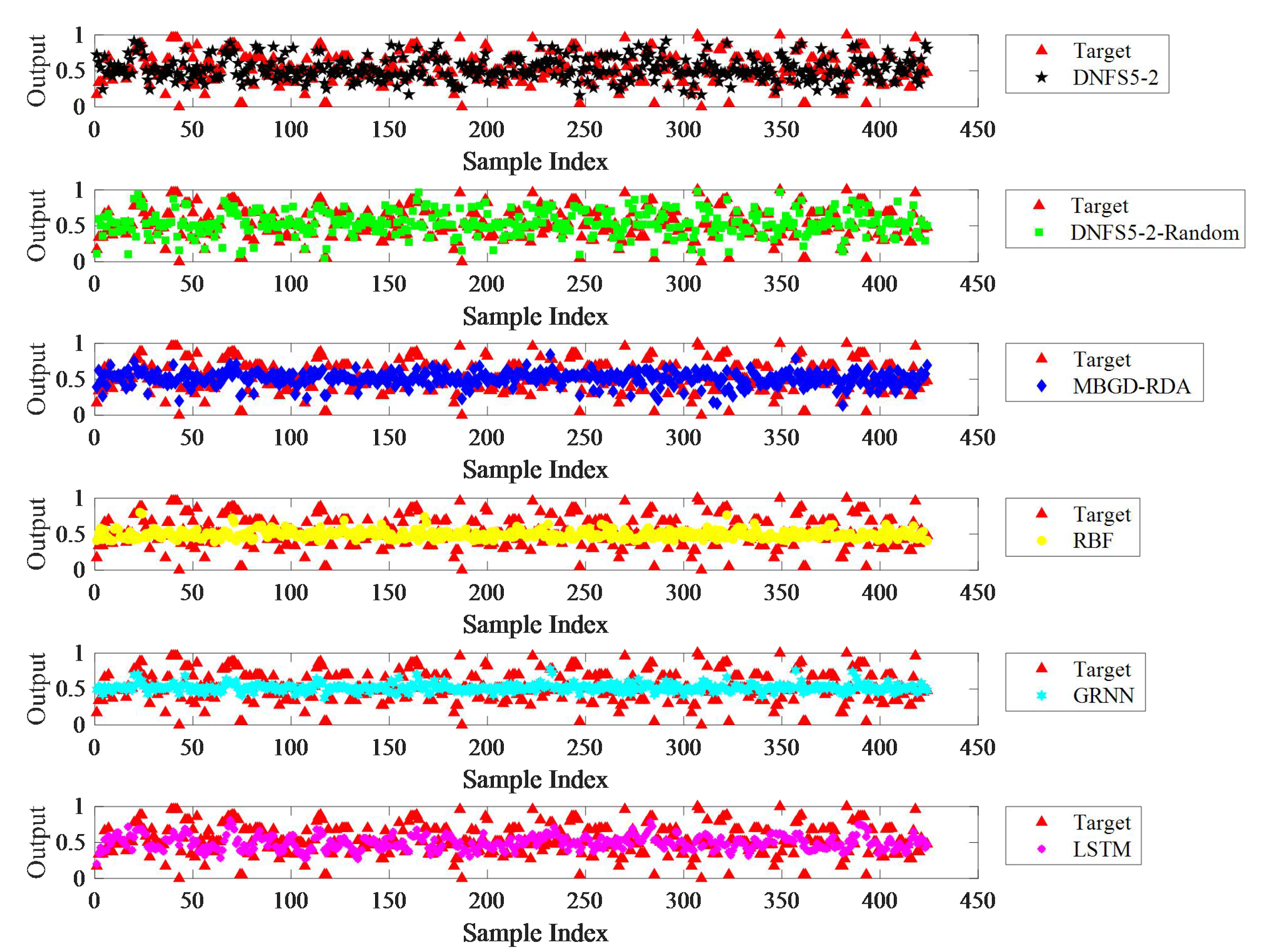
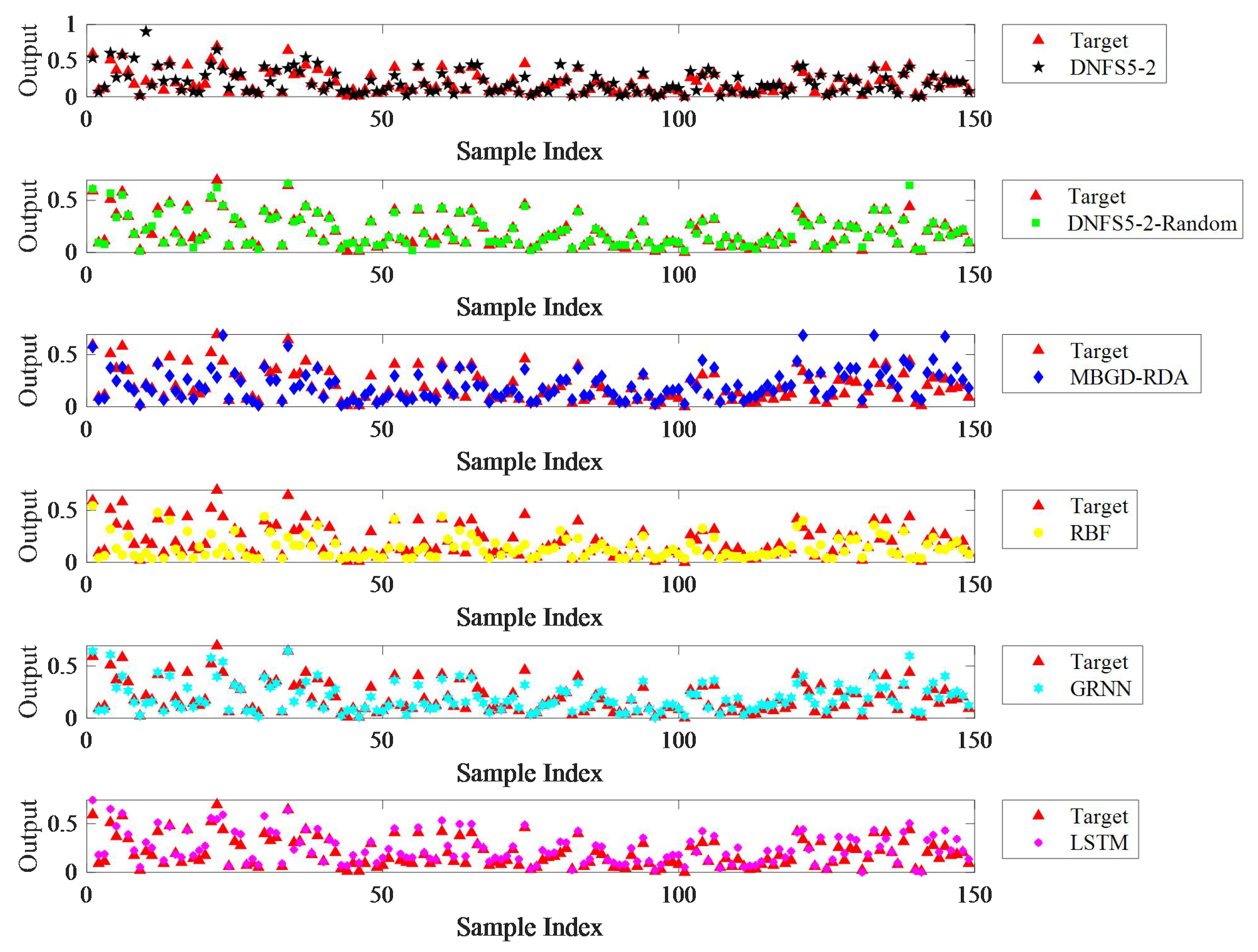
As shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10, DNFS5-2-Random achieved the highest prediction accuracy among the six algorithms on the five datasets. Compared to MBGD-RDA, RBF, GRNN, and LSTM, the average MAE decreased by 40.1%, 36.7%, 43.3%, and 35.8%, respectively, the average RMSE decreased by 34.1%, 36.4%, 36.8%, and 27.7%, respectively, and the average SMAPE decreased by 40.4%, 39.2%, 43.9%, and 36.8% respectively. The performance of DNFS5-2 was second only to DNFS5-2-Random. Compared to MBGD-RDA, RBF, GRNN, and LSTM, the average MAE of DNFS5-2 was reduced by 21.4%, 16.8%, 25.6%, and 15.6%, respectively, the average RMSE decreased by 14.1%, 17.2%, 17.6%, and 5.8%, respectively, and the average SMAPE decreased by 18.9%, 17.3%, 23.7%, and 14.1%, respectively. Hence, there is no doubt that the DNFS outperformed the other algorithms in prediction accuracy.
Meanwhile,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 show that DNFS5-2 had fewer parameters and a simpler structure than RBF, GRNN, and LSTM, which validated that DNFS5-2 has less complexity and higher interpretability. On the contrary, the parameters of the three machine learning models increased exponentially with the dimensionality of the input, which led to their interpretability being very poor. In addition, MBGD-RDA constrained the maximum input dimensionality five, so that its parameters were equal to 212 (5 ∗ 2 ∗ 2 +
∗ (5 + 1) = 212), while the MF was Gaussian and the number for each input domain was two. On all five datasets, the parameters of MBGD-RDA were far fewer than the other algorithms, resulting in the AIC being minimum. However, the prediction accuracy of MBGD-RDA was not optimal, which was probably because of the loss of important features due to PCA, so the performance was greatly affected.
The average computational time that DNFS5-2, MBGD-RDA, RBF, GRNN, and LSTM spent on the five datasets was 52.99 s, 50.39 s, 13.31 s, 1.23 s, and 18.22 s respectively. Obviously, GRNN was the most efficient method among all the algorithms. Although the efficiency of DNFS5-2 was relatively poor, it could achieve the best performance within a valid period of time, which could not be achieved by previous FSs. Additionally, the computational cost for each algorithm increased with the features and samples based on
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12.
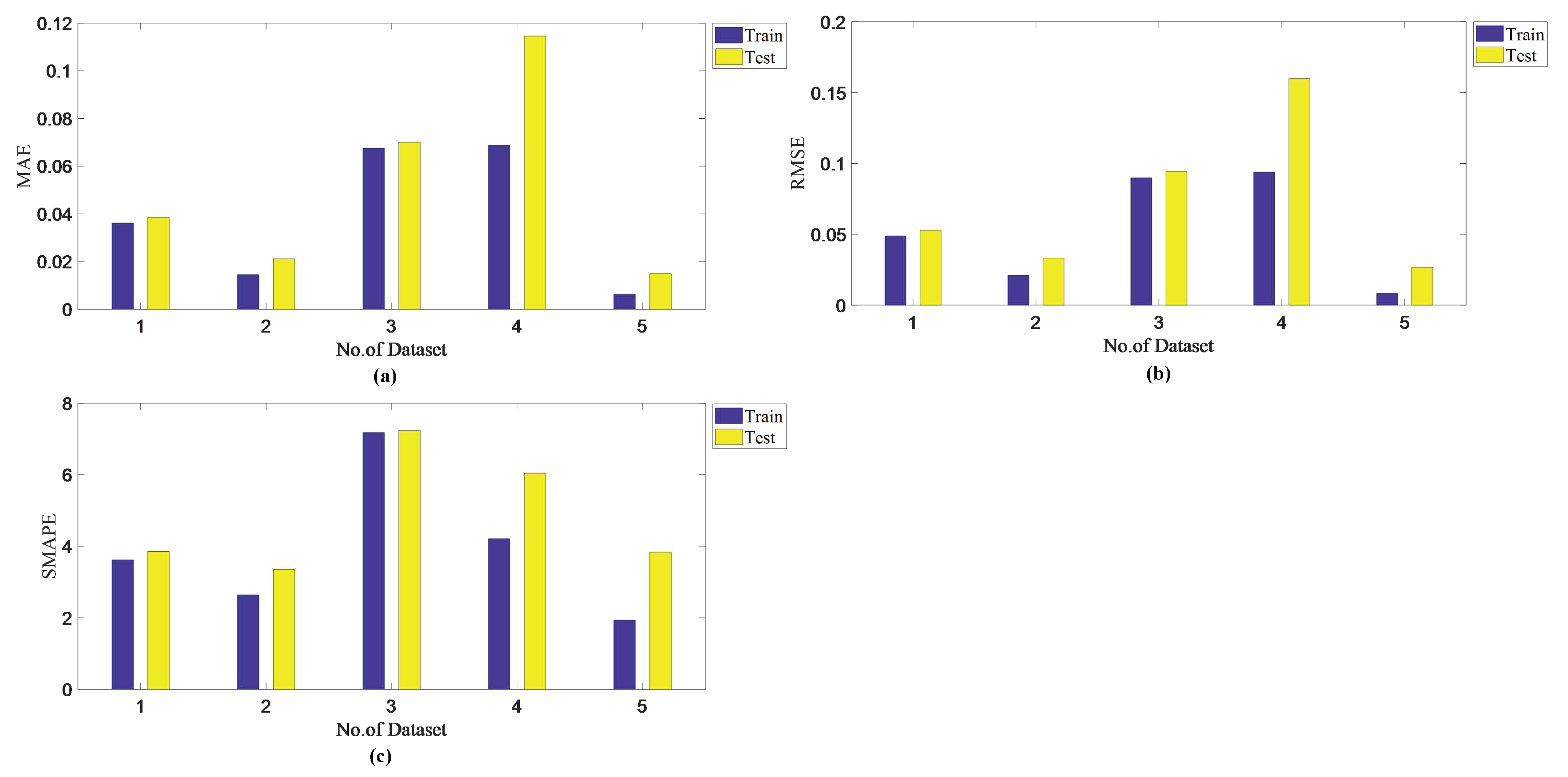
The analysis of the generalization ability of the DNFS: The performance comparison of the DNFS on the five datasets for the training and the testing is shown in
Figure 11.
Figure 11a shows the test MAE comparison of the DNFS on the training level with the testing level, while
Figure 11b,c shows the test RMSE and SMAPE comparison, respectively. It can be seen that the DNFS could achieve excellent performance both on the training level and testing level. The DNFS had similar performance on the training level and testing level, in particular for Dataset No. 1 and No. 3. It is obvious that the DNFS had excellent generalization performance with enough samples. However, the test performance would be slightly worse than that on the training level due to fewer samples. Therefore, the regularization method will be introduced in the future research to enhance the generalization ability of the DNFS.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}