
Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt

 , ,
, ,
Abstract
:1. Introduction
2. Principles and Methodology
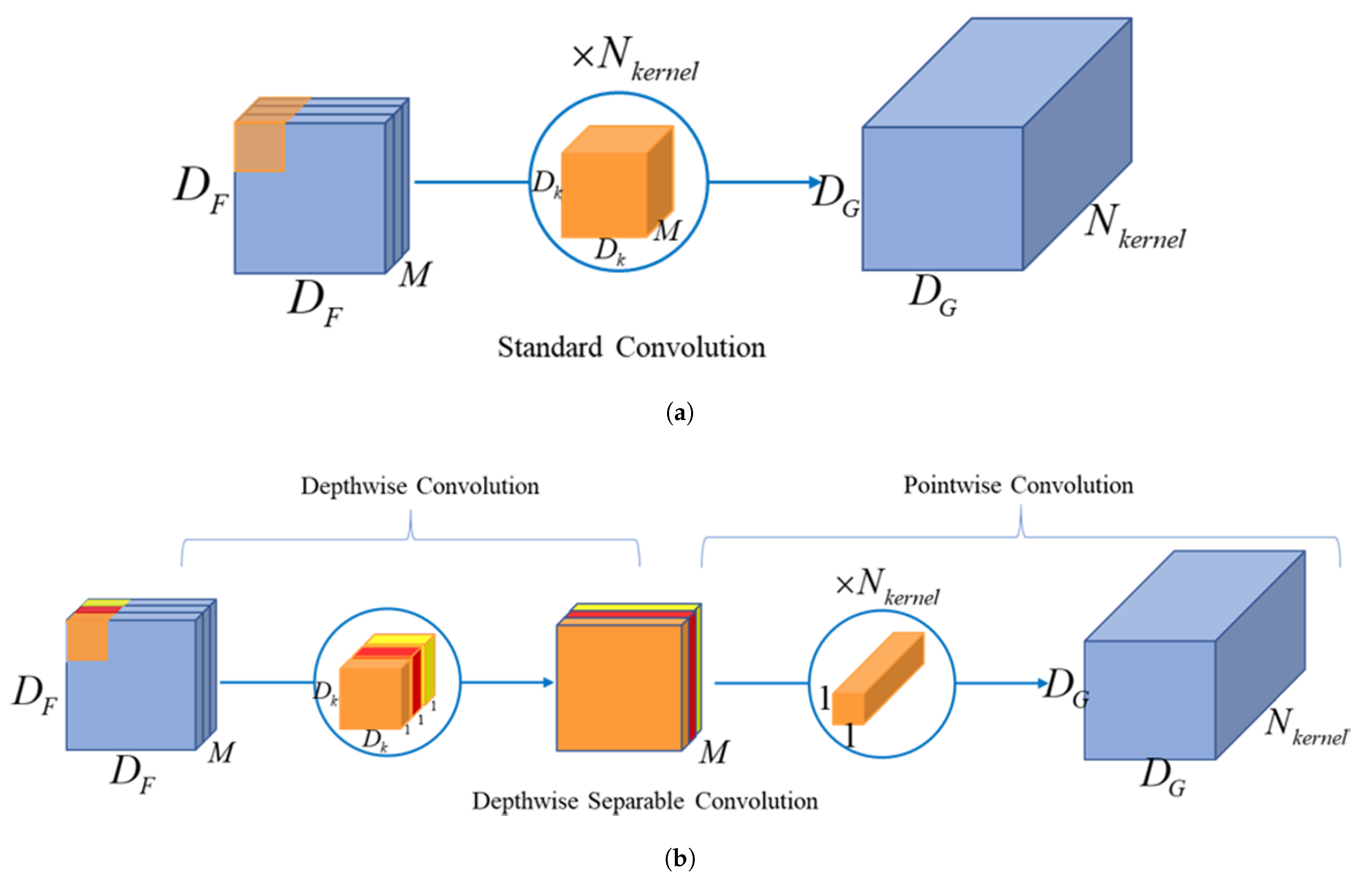
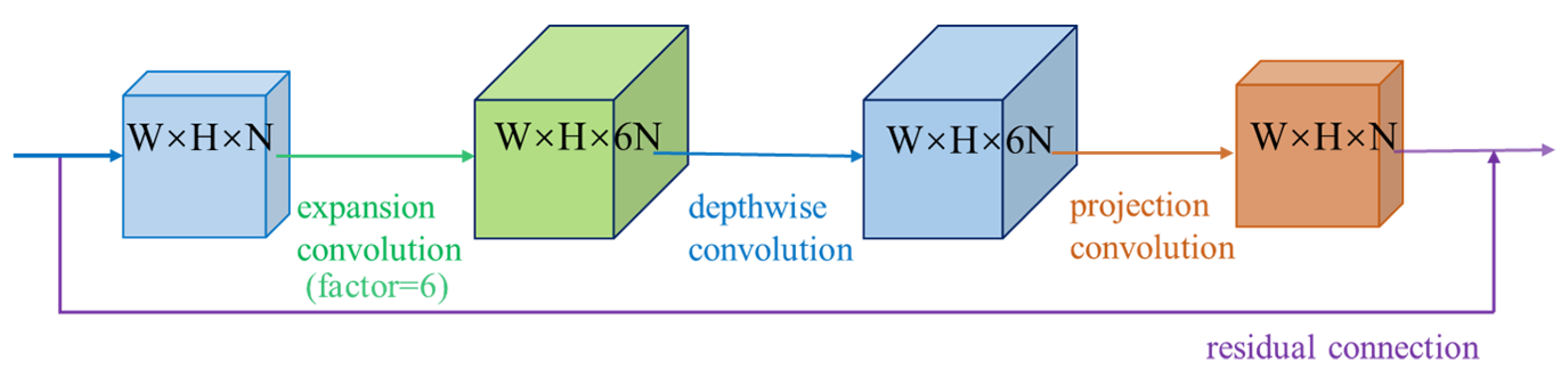
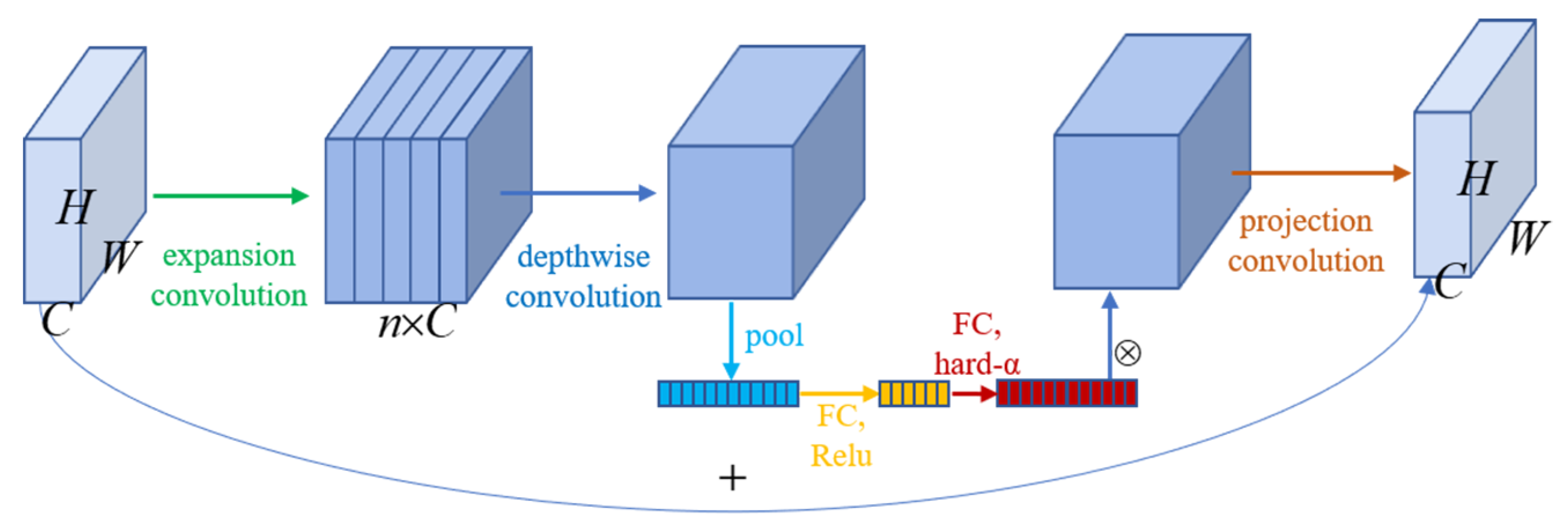
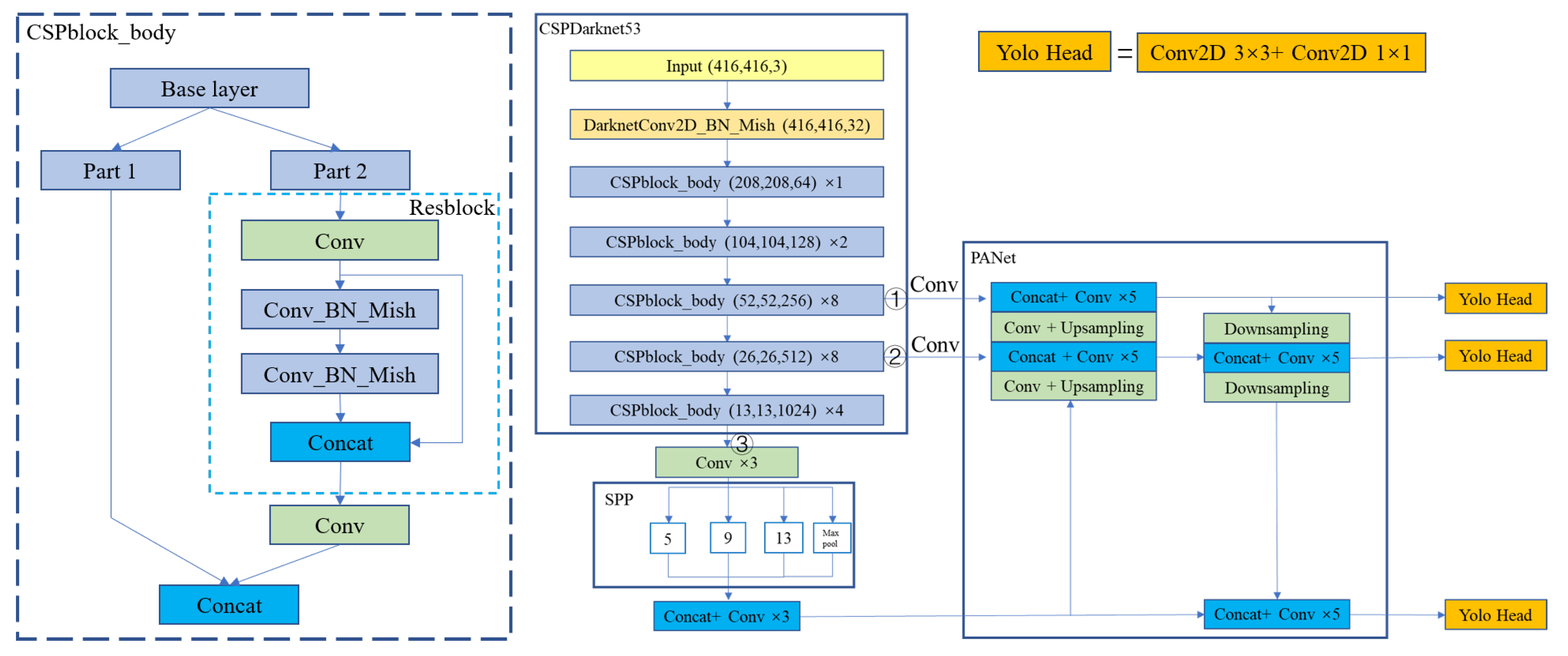
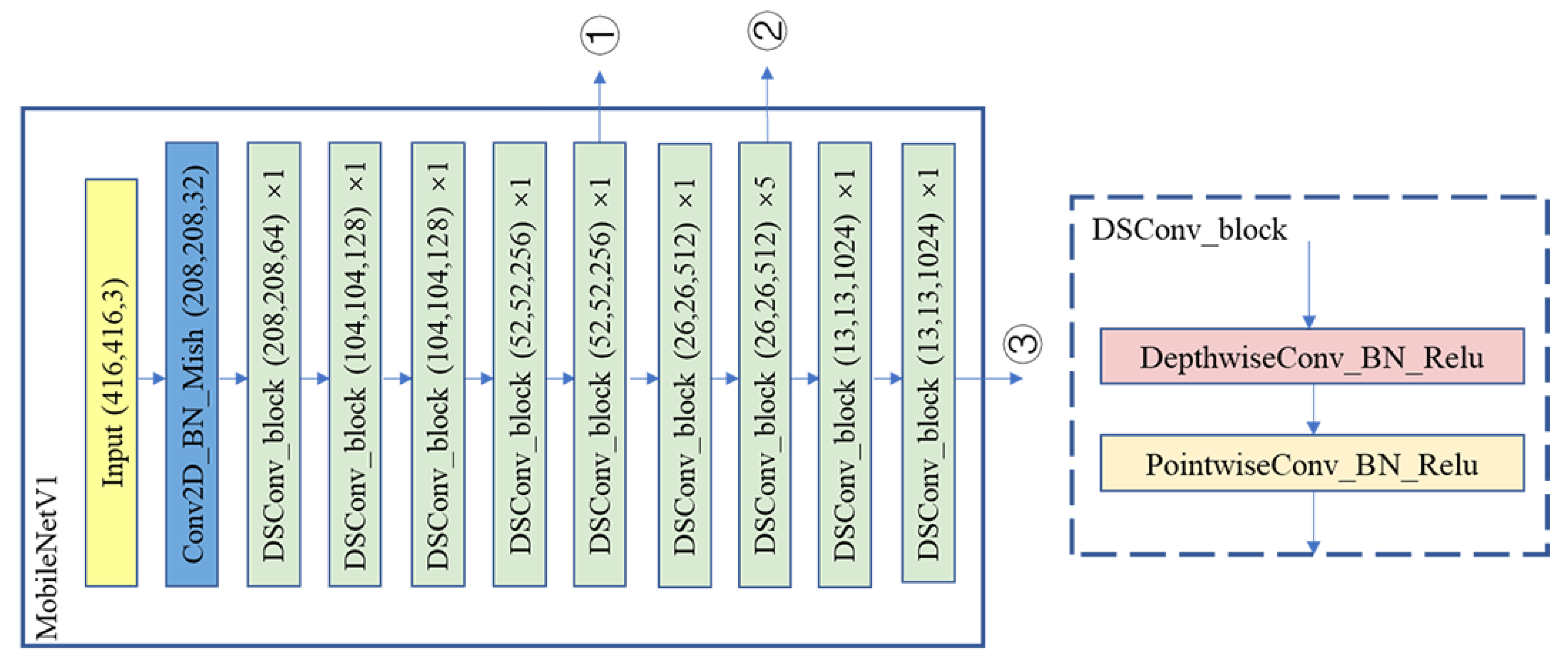
2.1. Network Structure and Improvement Methods
2.2. Calculation of Loss-Function
2.3. Operating Environment and Parameter Settings:
2.4. Data Preparation
3. Result and Discussion
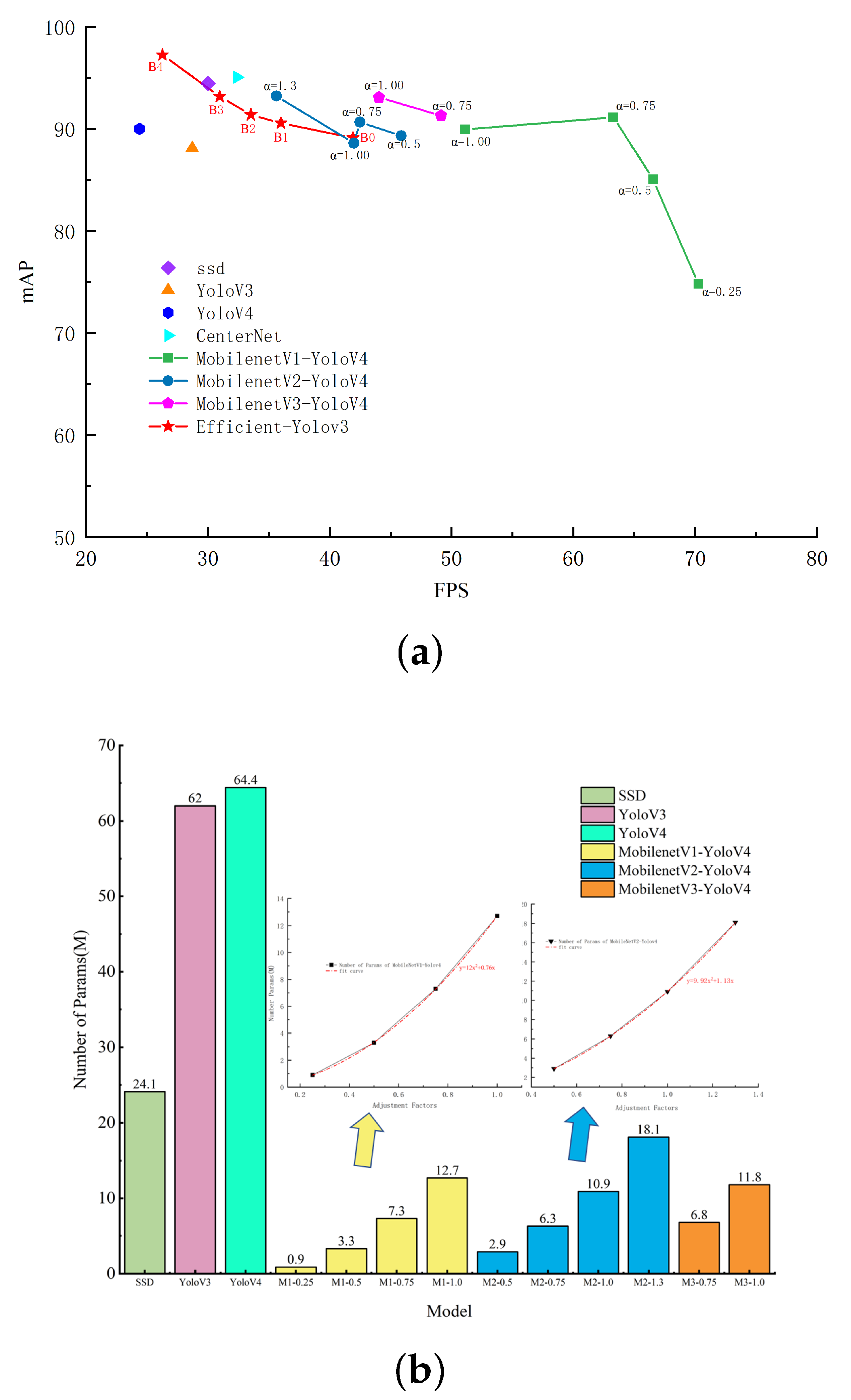
3.1. Detection Results of Unscaled Networks
3.2. Detection Results of Scaled Networks
3.3. Verification of Generalization Proficiency
4. Conclusions and Future Work
- (1)
- A lightweight Yolov4 network is realized through the effective combination of MobileNet and Yolov4 network.
- (2)
- A series of lightweight networks with different degrees of lightness are obtained by adjusting the number of channels, and their influence on detection speed and detection accuracy is explored.
- (3)
- The application of lightweight neural networks in conveyor belt damage detection is further explored. The results show that lightweight neural networks can bring significant improvement in detection speed with certain loss of accuracy compared to the original neural networks, but when the number of channels of lightweight neural networks is further expanded, their backbone feature extraction capability is further enhanced and their prediction accuracy even catches up with the original Yolov4.
- (4)
- The generalization capability of the target detection model is further validated by comparing the conveyor belt damage data in the existing literature.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lodewijks, P.D.I.G.; Ottjes, D.I.J.A.; Pang, D.I.Y. Intelligent belt conveyor monitoring and control. Des. Eng. 2010. Available online: http://resolver.tudelft.nl/uuid:585579aa-7406-4e57-af8e-66c7df9b83bd (accessed on 24 July 2021).
- Li, Z.; Chen, J.; Li, H.; Zhao, W. Research on Intelligent Monitoring and Warning Method of Belt Conveyor. J. Graph. 2017, 38. [Google Scholar]
- Zhang, M.; Shi, H.; Zhang, Y.; Yu, Y.; Zhou, M. Deep learning-based damage detection of mining conveyor belt. Measurement 2021, 175, 109130. [Google Scholar] [CrossRef]
- Research status and development trend ofintelligenttechnologies for mine transportation equipment. J. Intell. 2020, 1, 78–88.
- Zhang, S.; Xia, X. Modeling and energy efficiency optimization of belt conveyors. Appl. Energy 2011, 88, 3061–3071. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Xia, X. Optimal control of operation efficiency of belt conveyor systems. Appl. Energy 2010, 87, 1929–1937. [Google Scholar] [CrossRef]
- Zhang, M.; Chauhan, V.; Zhou, M. A machine vision based smart conveyor system. In Proceedings of the Thirteenth International Conference on Machine Vision. International Society for Optics and Photonics, Rome, Italy, 2–6 November 2021; p. 11605. [Google Scholar]
- Ji, J.; Miao, C.; Li, X. Research on the energy-saving control strategy of a belt conveyor with variable belt speed based on the material flow rate. PLoS ONE 2020, 15, e0227992. [Google Scholar] [CrossRef]
- He, D.; Pang, Y.; Lodewijks, G. Green operations of belt conveyors by means of speed control. Appl. Energy 2017, 188, 330–341. [Google Scholar] [CrossRef]
- He, D.; Liu, X.; Zhong, B. Sustainable belt conveyor operation by active speed control. Measurement 2020, 154, 107458. [Google Scholar] [CrossRef]
- He, D.; Pang, Y.; Lodewijks, G. Speed control of belt conveyors during transient operation. Powder Technol. 2016, 301, 622–631. [Google Scholar] [CrossRef]
- Yang, M.; Zhou, W.; Song, T. Audio-based fault diagnosis for belt conveyor rollers. Neurocomputing 2020, 397, 447–456. [Google Scholar] [CrossRef]
- Skoczylas, A.; Stefaniak, P.; Anufriiev, S.; Jachnik, B. Belt Conveyors Rollers Diagnostics Based on Acoustic Signal Collected Using Autonomous Legged Inspection Robot. Appl. Sci. 2021, 11, 2299. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, H.; Yu, Y.; Zhou, M. A computer vision based conveyor deviation detection system. Appl. Sci. 2020, 10, 2402. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Qiao, T.; Zhang, H.; Yang, Y.; Pang, Y.; Wei, H. A contactless measuring speed system of belt conveyor based on machine vision and machine learning. Measurement 2019, 139, 127–133. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, M.; Shi, H. A Computer Vision-Based Real-Time Load Perception Method for Belt Conveyors. Math. Probl. Eng. 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Dang, L. Video detection of foreign objects on the surface of belt conveyor underground coal mine based on improved SSD. J. Ambient. Intell. Humaniz. Comput. 2020, 1–10. [Google Scholar] [CrossRef]
- Liu, X.; Pang, Y.; Lodewijks, G.; He, D. Experimental research on condition monitoring of belt conveyor idlers. Measurement 2018, 127, 277–282. [Google Scholar] [CrossRef]
- Sakharwade, S.G.; Nagpal, S. Analysis of transient belt stretch for horizontal and inclined belt conveyor system. Int. J. Math. Eng. Manag. Sci. 2019, 4, 1169–1179. [Google Scholar] [CrossRef]
- Qiao, T.; Lu, X.; Yan, L. Research on the Signal Feature Extraction Method in Steel-Cord Conveyor Belt with Metal Magnetic Memory Testing. Adv. Sci. Lett. 2012, 11, 489–492. [Google Scholar] [CrossRef]
- Pang, Y.; Lodewijks, G. A novel embedded conductive detection system for intelligent conveyor belt monitoring. In Proceedings of the 2006 IEEE International Conference on Service Operations and Logistics, and Informatics, Shanghai, China, 21–23 June 2006; pp. 803–808. [Google Scholar]
- Hou, C.; Qiao, T.; Zhang, H.; Pang, Y.; Xiong, X. Multispectral visual detection method for conveyor belt longitudinal tear. Measurement 2019, 143, 246–257. [Google Scholar] [CrossRef]
- Qiao, T.; Liu, W.; Pang, Y.; Yan, G. Research on visible light and infrared vision real-time detection system for conveyor belt longitudinal tear. IET Sci. Meas. Technol. 2016, 10, 577–584. [Google Scholar] [CrossRef]
- Gao, R.; Miao, C.; Li, X. Adaptive Multi-View Image Mosaic Method for Conveyor Belt Surface Fault Online Detection. Appl. Sci. 2021, 11, 2564. [Google Scholar] [CrossRef]
- Hao, X.; Liang, H. A multi-class support vector machine real-time detection system for surface damage of conveyor belts based on visual saliency. Measurement 2019, 146, 125–132. [Google Scholar] [CrossRef]
- Xianguo, L.; Lifang, S.; Zixu, M.; Can, Z.; Hangqi, J. Laser-based on-line machine vision detection for longitudinal rip of conveyor belt. Optik 2018, 168, 360–369. [Google Scholar] [CrossRef]
- Yang, Y.; Hou, C.; Qiao, T.; Zhang, H.; Ma, L. Longitudinal tear early-warning method for conveyor belt based on infrared vision. Measurement 2019, 147, 106817. [Google Scholar] [CrossRef]
- Qiao, T.; Chen, L.; Pang, Y.; Yan, G.; Miao, C. Integrative binocular vision detection method based on infrared and visible light fusion for conveyor belts longitudinal tear. Measurement 2017, 110, 192–201. [Google Scholar] [CrossRef]
- Yang, R.; Qiao, T.; Pang, Y.; Yang, Y.; Zhang, H.; Yan, G. Infrared spectrum analysis method for detection and early warning of longitudinal tear of mine conveyor belt. Measurement 2020, 165, 107856. [Google Scholar] [CrossRef]
- Yu, B.; Qiao, T.; Zhang, H.; Yan, G. Dual band infrared detection method based on mid-infrared and long infrared vision for conveyor belts longitudinal tear. Measurement 2018, 120, 140–149. [Google Scholar] [CrossRef]
- Che, J.; Qiao, T.; Yang, Y.; Zhang, H.; Pang, Y. Longitudinal Tear Detection Method of Conveyor Belt Based on Audio-visual Fusion. Measurement 2021, 109152. [Google Scholar] [CrossRef]
- Qu, D.; Qiao, T.; Pang, Y.; Yang, Y.; Zhang, H. Research On ADCN Method for Damage Detection of Mining Conveyor Belt. IEEE Sens. J. 2020, 21, 8662–8669. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. Comput. Sci. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–February 2019; pp. 9259–9266. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OS | CPU | GPU | Tensorflow-gpu | Keras | Python |
|---|---|---|---|---|---|
| Windows10 | E5-2620V3*2 | RTX2060S | 1.13.1 | 2.1.5 | 3.6.10 |
| Model-Name | Backbone | mAP/% | FPS | Wear | Damage | Breakdown | Tear |
|---|---|---|---|---|---|---|---|
| Faster R-CNN [41] | Resnet50 | 91.10 | 3.68 | 0.96 | 0.98 | 0.82 | 0.88 |
| SSD [42] | VGG16 | 94.45 | 30.00 | 1.00 | 1.00 | 0.93 | 0.87 |
| RFBnet [47] | VGG16 | 83.36 | 30.42 | 0.98 | 0.77 | 0.85 | 0.75 |
| M2det [48] | VGG16 | 92.47 | 24.47 | 1.00 | 0.98 | 0.80 | 0.92 |
| Centernet [49] | Resnet50 | 95.05 | 32.4 | 1.00 | 0.94 | 0.94 | 0.93 |
| Yolov3 [43] | Darknet53 | 88.12 | 28.72 | 1.00 | 0.81 | 0.83 | 0.88 |
| Yolov4 [44] | CSP-Darknet53 | 90.00 | 24.39 | 1.00 | 0.81 | 0.96 | 0.87 |
| EfficientNetB0 | 89.12 | 41.91 | 1.00 | 0.81 | 0.82 | 0.94 | |
| EfficientNetB1 | 90.57 | 36.00 | 1.00 | 0.83 | 0.85 | 0.94 | |
| EfficientNet-Yolov3 [3] | EfficientNetB2 | 91.38 | 33.53 | 1.00 | 0.85 | 0.85 | 0.95 |
| EfficientNetB3 | 93.16 | 30.97 | 1.00 | 0.89 | 0.89 | 0.95 | |
| EfficientNetB4 | 97.26 | 26.28 | 1.00 | 0.99 | 0.93 | 0.96 | |
| MobilenetV1-YoloV4*(ours) | MobilenetV1 | 89.95 | 51.12 | 0.98 | 0.86 | 0.91 | 0.98 |
| MobilenetV2-YoloV4*(ours) | MobilenetV2 | 88.60 | 41.98 | 0.98 | 0.89 | 0.90 | 0.77 |
| MobilenetV3-YoloV4*(ours) | MobilenetV3 | 93.08 | 44.04 | 0.98 | 0.87 | 0.91 | 0.94 |
| Model | mAP/% | FPS | |
|---|---|---|---|
| MobilenetV1-YoloV4 | 0.25 | 74.49 | 70.26 |
| MobilenetV1-YoloV4 | 0.5 | 85.07 | 66.54 |
| MobilenetV1-YoloV4 | 0.75 | 91.12 | 63.28 |
| MobilenetV1-YoloV4 | 1 | 89.95 | 51.12 |
| MobilenetV2-YoloV4 | 0.5 | 89.32 | 45.87 |
| MobilenetV2-YoloV4 | 0.75 | 90.67 | 42.47 |
| MobilenetV2-YoloV4 | 1 | 88.60 | 42.00 |
| MobilenetV2-YoloV4 | 1.3 | 93.22 | 35.62 |
| MobilenetV3-YoloV4 | 0.75 | 91.30 | 49.14 |
| MobilenetV3-YoloV4 | 1 | 92.41 | 44.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Zhang, Y.; Zhou, M.; Jiang, K.; Shi, H.; Yu, Y.; Hao, N. Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt. Appl. Sci. 2021, 11, 7282. https://doi.org/10.3390/app11167282
Zhang M, Zhang Y, Zhou M, Jiang K, Shi H, Yu Y, Hao N. Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt. Applied Sciences. 2021; 11(16):7282. https://doi.org/10.3390/app11167282
Chicago/Turabian StyleZhang, Mengchao, Yuan Zhang, Manshan Zhou, Kai Jiang, Hao Shi, Yan Yu, and Nini Hao. 2021. "Application of Lightweight Convolutional Neural Network for Damage Detection of Conveyor Belt" Applied Sciences 11, no. 16: 7282. https://doi.org/10.3390/app11167282