1. Introduction
Photovoltaic (PV) solar array faults including soilage, shading, degradation, and short circuit faults can reduce solar array power efficiency by an estimated 22.34% to 27.58% [
1]. Several machine learning (ML) methods have been studied for solar fault detection, with most modern algorithms using some type of deep neural network solution [
2,
3,
4,
5] provide a thorough survey of current algorithms in the field and results are promising, however training the current state of the art deep learning algorithms is quite data intensive and requires large, labeled data sets. Collecting and labeling these large datasets is expensive and the data may be unique and sometimes must be at least partially re-collected for each PV solar array and location. In this paper, we develop and demonstrate a new fault detection algorithm that requires significantly less labeled training samples using positive and unlabeled learning (PU learning)—a family of newer semi-supervised positive unlabeled learning algorithms that has never, to our knowledge, previously been applied to PV fault detection. General semi-supervised learning algorithms use some labeled data but improve their models with additional unlabeled data [
6]. In recent years, some semi-supervised algorithms have been applied to PV fault detection [
7,
8,
9,
10] for the very reasons listed above. However, general semi-supervised learning algorithms require some labeled data from both the positive (in this case the solar fault) class and the negative (clean, non-faulty) class. PU learning is a binary semi-supervised classification process in which only a small quantity of labeled data from only one class (the positive class) is available, along with a quantity of inexpensive and unlabeled data [
11,
12]. This is useful as while PV faults may be noticeable, care must be taken not to miss a fault before declaring a datapoint as fault-free.
We start by adapting an existing algorithm called the modified logistic regression (MLR) PU learning algorithm developed by the authors of this paper [
13] for use in solar fault detection and similar problems. The resulting new algorithm is called the Feedback enhanced MLR (MLRf) algorithm and was designed for solar fault classification and related PU learning problems where there are limited features and labeled data. We compare these and other solar fault detection algorithms using the standardized NREL PVWatts [
4,
14] solar fault dataset (described later in this paper) for insight into the fault classification problem and to determine the number of labeled data required for effective solar fault classification. For each algorithm, excluding the oracle (a supervised learning algorithm that knows all and sees all—typically used as a best-case comparator), the percentage of known, labeled fault data is varied between 2% and 90% of the total positive data.
Solar fault detection algorithms compared in this paper (and explained in more depth in
Section 2) include:
- (1)
The MLR algorithm described in [
13].
- (2)
The MLRf algorithm proposed and described in this paper.
- (3)
A naïve PU implementation using a supervised learning algorithm and treating all unlabeled datapoints as negatives.
- (4)
An “oracle” supervised learning algorithm with all labels known.
- (5)
A “tiny” supervised learning algorithm (we used the term “tiny”, not to indicate a specific algorithm, but to indicate the process where the training is done with a small number of labels. Not to be confused with Tiny ML algorithms.) using the same number of labeled data as MLR or MLRf, but in this case balanced between positive and negative samples instead of only positive.
- (6)
An unsupervised kmeans clustering algorithm, mostly for curiosity and to illustrate the benefit of having some labels in all other cases.
We found that the PU learning algorithms, both the existing MLR and the new MLRf, were able to match and even outperform even the fully supervised oracle algorithm with only 5% of the data labeled. We additionally demonstrate that using the same number of labeled samples, the PU learning algorithms both outperform a smaller supervised learning algorithm that does not take advantage of the unlabeled samples. This, in addition to the fact that it is the nature of the problem that it is easier to label a faulty sample than to guarantee that a sample is not faulty, confirms that given a labeling budget, it is more effective to label only faulty samples than to attempt to label both faulty and non-faulty ones.
The main contributions of this paper are: (1) the use of a unique PU learning algorithm for solar array fault detection which has, to our knowledge, never been done before, (2) the adaptation of the MLR to work for solar fault detection, (3) the ability to effectively use significantly fewer labeled training data than most supervised learning algorithms by applying PU learning techniques to solar fault detection problems, (4) the introduction of a new PU learning algorithm, MLRf, designed to better detect and classify solar fault data, (5) the development of new comparative results demonstrating the effectiveness and robustness of the MLR and MLRf algorithms at detecting solar faults with very little labeled data, and (6) the demonstration that labeling positive samples is more effective than labeling total positive and negative samples. The novelty of this work lies most especially in the application of PU learning algorithms to solar fault detection and to the introduction of the MLRf algorithm.
2. Materials and Methods
In this section we describe the NREL PVWatts [
4,
14] solar fault dataset that we use in our experiments as well as a more detailed description of the new or unusual algorithms from the introduction: the MLR [
13], MLRf, naïve PU, oracle, and “tiny” supervised learning algorithms.
But first, a quick note on notation. In addition to the standard classification notation of using
and
to represent a data sample and its label respectively, a new random variable
is introduced to represent if that sample is labeled or unlabeled. The PU problem can then be formally stated as:
Our classification goal can be thought of as the creation of a probabilistic function
such that
2.1. Dataset
For this study, a solar fault dataset described in [
4] was used, derived, and modified from data generated by the PVWatts calculator at the National Renewable Energy Laboratory (NREL) [
14]. The dataset contains 21,485 solar measurements including equal parts (of 4297 each) clean, “no fault” or “standard conditions” data (STC), shaded, soiled, degraded, and short circuit solar data. Each measurement has ten features—the DC output, the open circuit voltage (
), short circuit current (
), max power point voltage (
), max current (
), fill factor, temperature, irradiance, gamma ratio, and max power. The dataset was labeled based on these feature measurements as described in [
4]. A measurement was considered
no fault or STC if the irradiance, temperature, and power were at the maximum values for that day. Data was labeled shaded if the measured irradiance was lower than the STC by 25% or more. Soilage was labeled as present if the irradiance was high while the power was low, while a short circuit was identified when the irradiance and temperature were standard but the maximum current, (
), was low. A solar panel was labeled as degraded if the open circuit voltage, (
), or short circuit current, (
), were more than 25% below the rating of the PV module.
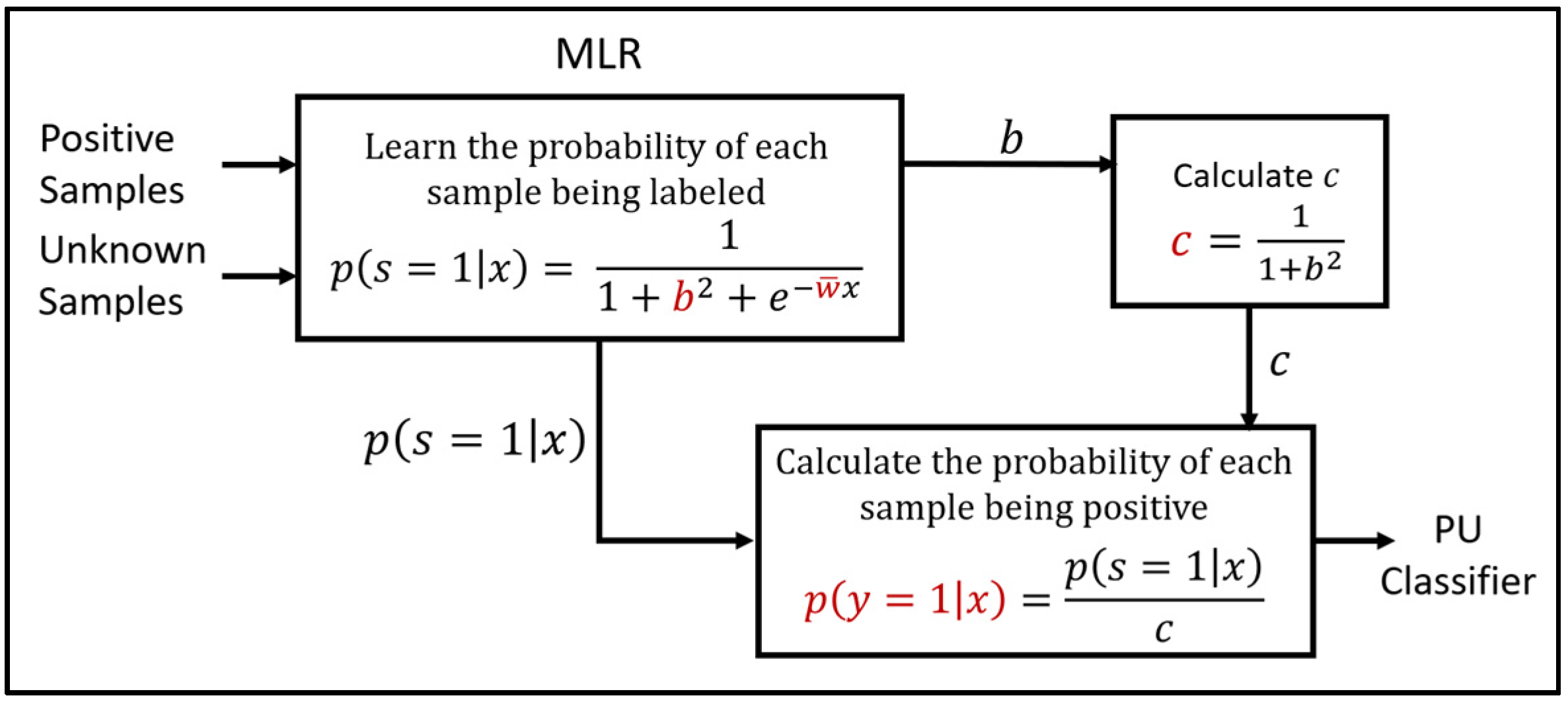
2.2. The MLR Algorithm
While the MLR algorithm is described in detail in [
13], we will provide a summary here for clarity. As first described and proved in the foundational positive unlabeled learning paper [
15], if we make a strong, but common assumption called the SCAR assumption and assume that the labeled positive (fault) data is selected at random from the set of all positive (fault) data, then we can create a non-traditional classifier
that can be used to obtain our final PU classifier
. By assuming that the labeled positive data is selected at random from all positive data, the probability of being labeled is no longer dependent on the feature vector
, but only on the sample’s positive status
as shown in Equation (3). This results in a constant labeling frequency named
in the literature:
This final PU classifier based on a non-traditional classifier is derived in [
15] and reproduced as follows:
therefore:
In [
13], we were able to demonstrate using both real-world and simulated datasets that the modified logistic regression (MLR) algorithm was an effective non-traditional classifier and produced better estimates of both
and
than existing algorithms. The MLR is defined by the expression:
where
and
are variables that are learned in the training process. From this MLR algorithm and its learned parameter
, we are able to estimate the label frequency
as the upper asymptote of Equation (6) as:
and from this construct a final PU classifier
using Equation (6). After all data values have been mean normalized, a stochastic gradient ascent algorithm is used to maximize the likelihood of the MLR. The MLR algorithm details and block diagram are available in
Appendix A Algorithm A1 and
Figure A1.
The MLR algorithm provides an effective, general purpose PU learning algorithm, but like traditional logistic regression, on which it is based, the model it creates it is mostly linear in terms of the feature values of the inputs. When the feature set is small, additional feature engineering and enhancement is useful.
2.3. The MLRf Algorithm
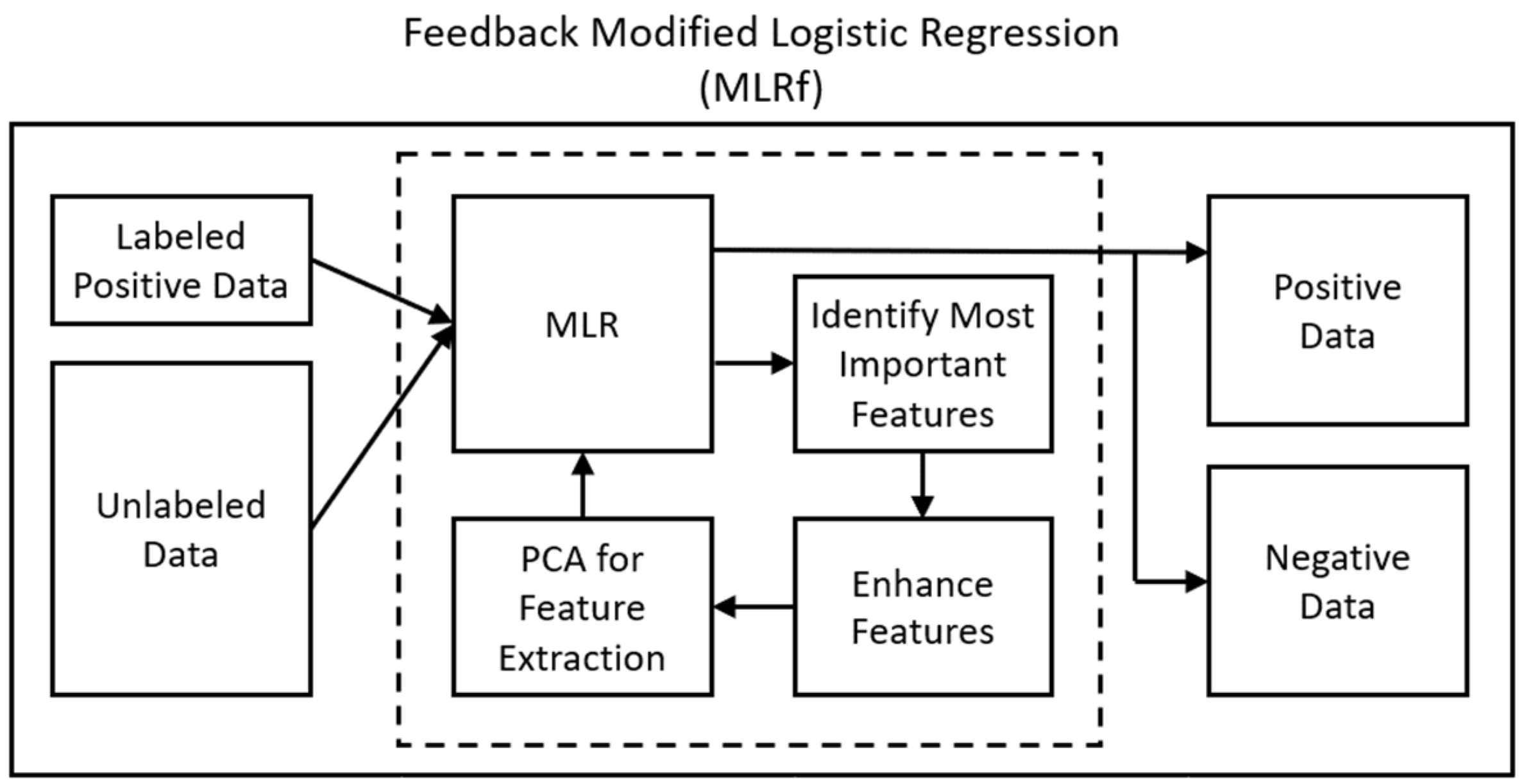
PV fault detection and classification are different from typical classification problems as the feature set is typically small, while vast quantities of unlabeled data can be generated automatically. Our dataset has thousands of measurements but only 10 features, and some of those features such as the gamma ratio are calculated as combinations of other features.
Because our feature set is small and the problem complex, linear classifiers may underfit the data, yet because a PU dataset has many missing labels, most non-PU non-linear classifiers such as neural networks will overfit the data to the few labeled datapoints. The MLR algorithm by itself is a powerful general-purpose PU learning algorithm, analogous to standard classification algorithms such as logistic regression, support vector machines, or artificial neural networks for fully labeled data and by itself includes no feature enhancement or engineering. To better handle the small solar fault detection feature set, we introduce the MLRf algorithm in this paper. The MLRf algorithm shown in
Figure 1 uses the MLR algorithm, but also incorporates a feedback loop to perform custom feature engineering—enhancing the feature set to enable non-linear classification that does not overfit or underfit the data. This automates some of the preprocessing steps that are manually required by other algorithms.
The proposed MLRf algorithm consists of the following five steps.
- (1)
An initial classification model is learned using the original MLR algorithm from [
13] and described in
Section 2.2.
- (2)
The MLR model produced in Step 1 above is a weighted combination of feature variables. As the original feature data were mean normalized as part of training, the most influential features in the model are those with the highest magnitude weights. This allows us to sort the features by importance to the model. The MLRf algorithm selects the top most important features by magnitude for enhancement.
- (3)
Feature enhancement is performed by adding -level polynomial combinations of the selected features. For example, if an enhancement of any two pairs of original features and would return the enhanced feature space . If , enhancement would include cubic values and combinations such as , and so forth. The purpose of this expansion is to increase the dimensionality of the dataset to allow for a more flexible non-linear decision boundary that is better able to accommodate the complexity of the solar fault data space. A linear decision boundary in this higher dimensional space is equivalent to a non-linear decision boundary in the original feature space.
- (4)
Once the feature space has been expanded, regularization methods or additional feature manipulation can be performed using a dimensionality reduction algorithm such as PCA (Principal Component Analysis) to capture the dimensionality of the enhanced feature set that incorporates more than 95–99% of the variability of the space. This eliminates or minimizes any enhanced features that do not substantially contribute to the final classification.
- (5)
Finally, the newly expanded feature space is sent back through the original MLR classifier for final classification with a now potentially non-linear classification boundary.
In addition to the standard hyperparameters such as the learning rate and number of epochs in the MLR algorithm, the MLRf introduces , the number or percentage of important features to be enhanced, and , the level of polynomial enhancement described in step 2 above. If PCA is used in step 4, then the number of retained components becomes an additional hyperparameter. Regularization may be preferred for this reason. Once the model has been created, it can be applied to new data in real time. To capture possible changing conditions, offline training and model updates can be performed periodically.
2.4. The Naïve PU Algorithm
In practice, data with no detected faults is often labeled as negative, or not faulty. This strategy is replicated in this naïve PU algorithm which treats all unlabeled data samples as negative and performs a standard supervised classification (in this case a traditional logistic regression).
2.5. The Oracle
In computer science, an oracle is the name given to an algorithm that “knows all and sees all”. In the context of this semi-supervised learning algorithm, an oracle is a fully supervised learning algorithm that has access to all the true data labels. As the two algorithms of interest, MLR and MLRf, are both fundamentally related to the traditional logistic regression algorithm, the oracle algorithm (and indeed all other comparative algorithms) use traditional, or standard logistic regression (SLR) in this paper to provide a better measure of comparison. In all algorithms but k-means, a simple unoptimized stochastic gradient ascent algorithm was used to fit the data. We recognize that it is likely that other more complex supervised learning algorithms or other more advanced solvers could improve these algorithm’s performance, but our objective in this paper is to assess the MLR and MLRf algorithms against others in their same class. As these algorithms are still being researched and have not yet been optimized, we compare them to algorithms created in a similar manner. It is likely that with optimization (regularization, batch processing, more complex solvers, and so on) that eventual results will be substantially higher than they are now.
2.6. The “Tiny” Supervised Learning Algorithm
To compare the effect of having a small labeling budget more equitably, we create this supervised learning algorithm that only trains with the same number of data points that the MLR and MLRf algorithm have labeled. If MLR and MLRf have positive labeled and samples available to them, this “tiny” supervised learning algorithm has total samples available—half positive and half negative. No unlabeled data is used. This is intended to simulate an assumed preference for supervised learning given a limited labeling budget and to compare this with the PU learning algorithm.
2.7. The K-Means Algorithm
We include in our algorithm comparison a simple unsupervised learning algorithm, more as a matter of curiosity than as a true comparison with the MLR and MLRf algorithms. K-means was performed using clusters representing the five known classes in the data: shaded, soiled, degraded, short circuit, and no faults. After clustering, the individual cluster, or clusters (when performing general fault classification), were chosen to be labeled positive that contained the most samples belonging to the PU labeled positive class.
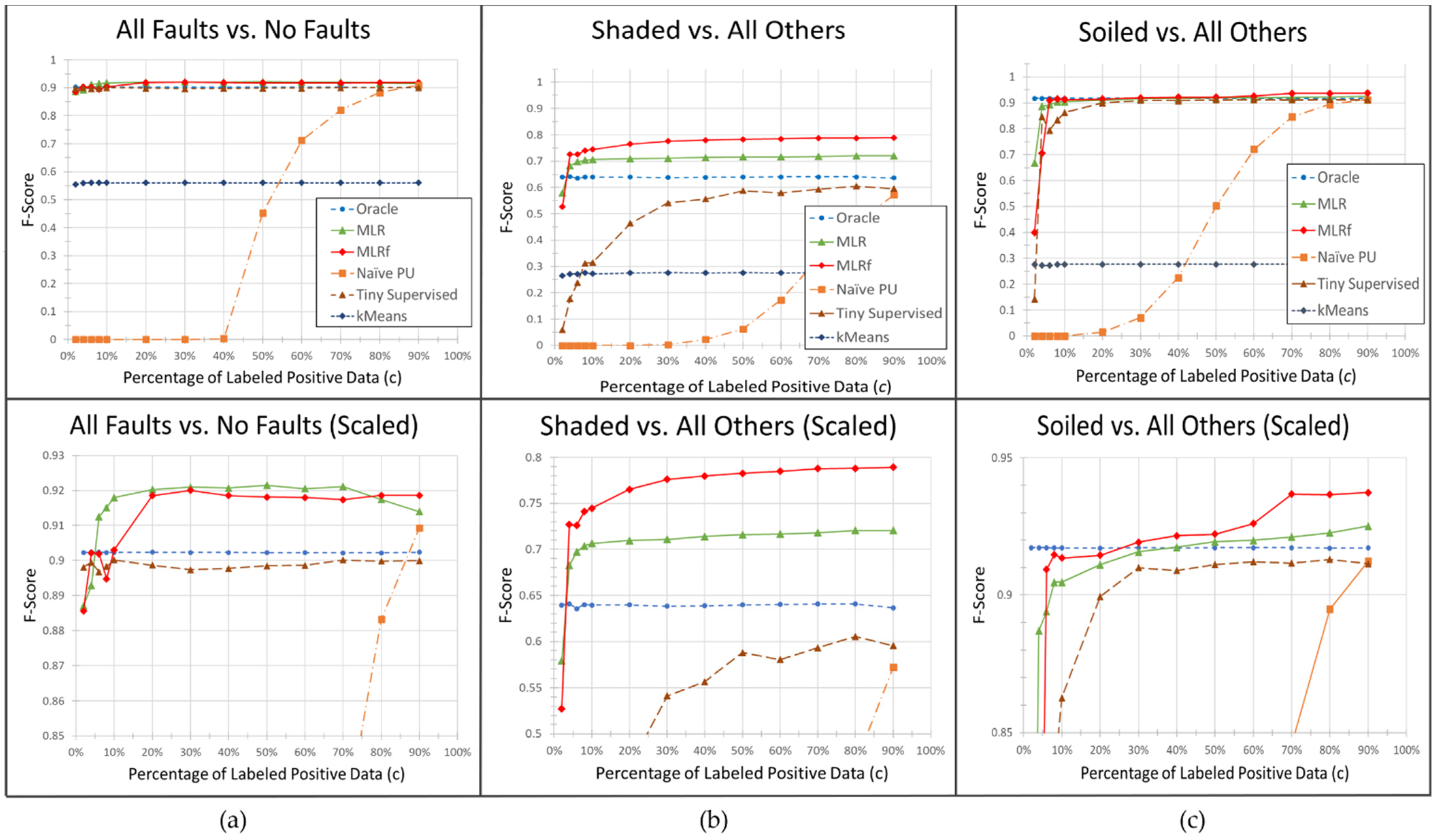
4. Discussion
In this section, we discuss the results provided in
Section 3 in some depth. As each graph in
Figure 2 provides results for a different fault type and model, we break these results down separately and scrutinize each individually.
In the top graph in
Figure 2a, we see that all algorithms including the MLR, MLRf, and “tiny” supervised learning algorithm behaved well and provided similar results, even with only 2% of total fault data labeled. As illustrated in
Table 2, 344 datapoints out of 21,485 total datapoints were labeled at this lowest
value. It should be noted that treating unlabeled samples as negatives, as illustrated by the naïve PU algorithm, is ineffective unless nearly all faulty points (17,188 total) are labeled. In the bottom graph, it is clear that both the MLR and MLRf algorithms slightly and consistently outperform the oracle and the “tiny” supervised learning algorithms when at least 10% of the positive samples are labeled. We believe this may be due in part to the non-linear classification capabilities of both algorithms. This is discussed further in the next bullet point.
Figure 2b demonstrates a situation where the nonlinear nature of the MLRf algorithm provides a clear advantage. The poor results of the supervised linear oracle model (with an F-Score of approximately 0.64) indicate that the faulty and non-faulty data for this problem are non-separable in the given feature space. The oracle model is underfitting the data. The improvement gained by the MLRf algorithm with its much higher feature dimensionality confirms this. If the decision boundary is substantially nonlinear, this could explain the noticeable F-score improvement of the non-linear MLRf classifier. A future test should be performed against a nonlinear oracle model for confirmation.
The more surprising result in this graph is the improvement made possible by the simpler MLR algorithm. The MLR algorithm has one additional variable over the oracle (the
variable described in
Section 2.2), and we surmise that this slight nonlinearity may be contributing to its success. It is remarkable that these high scores are possible even when only 4% of the faulty data is labeled, or 172 datapoints.
The soilage detection models in
Figure 2c act similarly to those in
Figure 2a in that the MLR, MLRf, and the “tiny” supervised algorithm are similar to that of the Oracle except at low values of
. Unlike the other graphs in
Figure 2, MLRf performance increases noticeably above the Oracle only when the label frequency
is around 70%—much higher than in other graphs. However, the actual difference is slight and may simply indicate an upward trend like that of the MLR algorithm. Due to the small number (five) of runs that we were able to do for this algorithm on this problem at that
value, the jump at
may be a random outlier. Additional simulations would need to be performed to test this hypothesis.
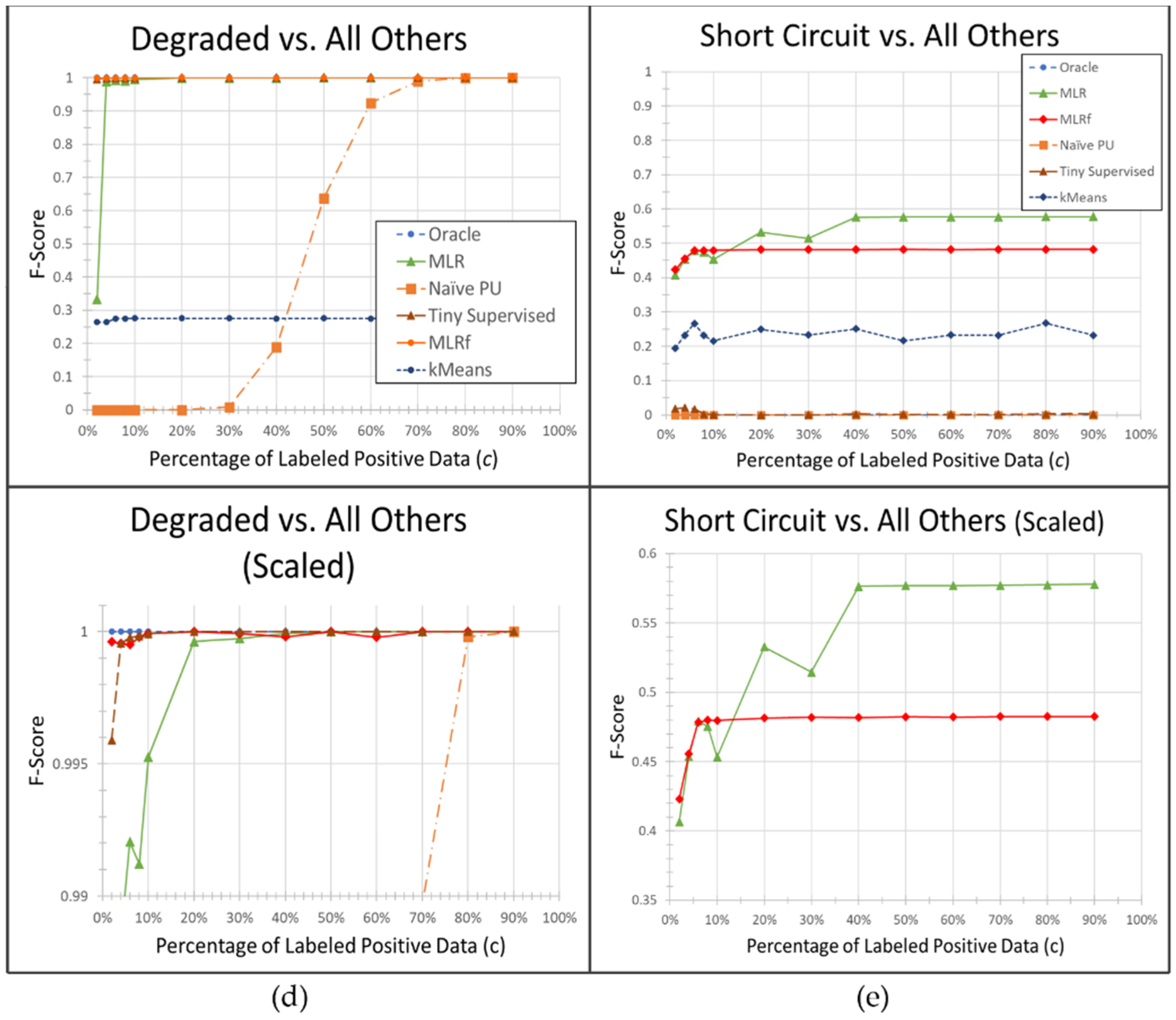
The degraded fault detection problem illustrated in
Figure 2d is the “simplest” of all problems to solve in
Figure 2. The oracle was able to achieve perfect classification (F-score = 1) in the given feature space for this problem. The MLR, MLRf, and “tiny” supervised algorithm also performed at or near this level for all but the very smallest of
values. Notice that the lower graph had to be substantially scaled to see any variability between algorithms at all. Despite the obvious separability of this problem, neither the naïve PU algorithm nor the unsupervised k-means algorithm were useful.
Figure 2e illustrates our most interesting and enigmatic result. The oracle algorithm and related “tiny” supervised algorithm are unable to classify short circuit faults in the given feature space. The MLR and MLRf algorithms, while performing poorly with an F-score between 0.4 and 0.6, are nevertheless substantially more effective. Unlike the Shaded problem shown in
Figure 2b, higher feature dimensionality alone is not sufficient to explain this discrepancy as the lower dimensional MLR algorithm performed better than the higher dimensional MLRf algorithm. One thought is that the MLRf algorithm with
and
expanded features may be overfitting the problem while the slight increase in dimensionality provided by the MLR algorithm may be preferable, though this conclusion is not particularly satisfying. Other authors such as [
16] suggest that there are theoretical situations where PU learning can surpass supervised classification. It would be interesting to investigate if this is such a case. Either way, further research is warranted.
In addition to the increased dimensionality and non-linear models described above, one other possible improvement due to PU learning is possible. With noisy data, it may be that because of the reduction in labeled data in the positive class, outliers are likely to be excluded, simplifying the model, and improving overall performance. This does not seem likely to have played a large role in the given datasets however as the MLR and MLRf algorithm performance does not trend towards the oracle with higher values of
Instead, we believe that the non-linear aspects of the MLR and MLRf algorithms are more likely to explain this discrepancy as described in the bullets above. It is likely that this non-linear boundary can capture nuances that a fully linear boundary such as used in the simple supervised oracle algorithm used in this paper is unable to capture. feature engineering of the oracle algorithm or selection of a more advanced algorithm would likely improve this. Additionally, it may be worth investigating more theoretical explanations for these phenomena in future work as described in [
16].
Due to the encouraging results, it is worth investigating these and other PU learning algorithms on additional solar fault datasets. The improvements in classification, with few labeled data samples, especially in the case of hazardous faults such as short circuits, bring significant value in terms of improved detection.
5. Conclusions
To the best of our knowledge, this is the first time PU learning has been used for solar fault detection and classification. This, along with the introduction of the MLRf algorithm in
Section 2.3, comprise the novel contributions in this paper. PU learning has the advantage over standard supervised and semi-supervised learning in that it does not require any labeled data from the “good” or STC class. This allows seemingly faultless data to avoid additional expensive scrutiny to confirm faultless status. Mistaking a low-level fault for STC or treating unlabeled data as negative can confuse a learning algorithm and create a poor learning model, as shown by the poor results of the naïve PU algorithm in
Figure 2 at lower values of
. At the same time, PU learning algorithms such as MLR and MLRf are extremely effective, essentially matching the quality of a fully supervised model at all but the very lowest possible percentage of labels. With a small amount of labeled fault data, PU learning can accurately label the large amount of unknown data as well as creating an effective model for future data. Comparisons with a “tiny” supervised learning algorithm in
Figure 2a–c,e with the same number of labeled samples split between the positive and negative classes illustrate the benefit of PU learning and the advantage found in using the unlabeled data as stated in [
17].
In addition to demonstrating the MLR algorithm on solar fault data, we proposed and evaluated a new MLRf algorithm developed for PU learning with application to solar fault datasets and other large datasets with few features. The MLRf algorithm has several components including feedback, feature enhancement, and feature pruning. These elements significantly increase the flexibility of the algorithm, though they do require additional hyperparameter tuning. They also raise the potential of overfitting concerns, though we did not see much evidence of this in our work.
Simulations were performed for PU labeled fault detection and classification for a variety of different
values representing the percentage of known labels for the class of interest. Both the original MLR and the new MLRf algorithm provide extremely robust results, equaling or surpassing a fully supervised oracle algorithm when less than 10% of labels from the class of interest were available. These results are remarkable and confirm the results found in [
13].




{kind=link}
{kind=link}
{kind=link}
{kind=link}


