Many of the existing concrete structures built during the 1960–70s are rapidly nearing the end of their service life [
1]. It is estimated that nearly 10% of bridges built during this time have been repaired in the United States [
2]. In Korea, the number of buildings over 30 years old was evaluated as 3.8% in 2014, reaching 13.8% by 2024, and 33.7% by 2029 [
3,
4]. Likewise, concrete structures are often exposed to aggressive environments, fatigue stresses, and cyclic loading that initiate cracks on the surfaces [
5,
6]. The cracks in structures have a significant impact on durability and make it easy for external aggressive substances to reach the reinforcement bars and cause corrosion [
7,
8]. In addition, cracks in the structures also reduce the local stiffness and cause material discontinuities [
9,
10]. Therefore, cracks must be detected and repaired in time in order to maintain the reliability and performance of the structure. Generally, crack detections were performed by non-destructive and destructive tests [
11]. Visual inspections combined with surveying equipment were manually performed to detect cracks in the structures [
12]. A PZT-based electro-mechanical admittance method combined with FEM analysis was enacted to quantitatively identify the damage caused by concrete cracking and steel yielding of flexural beams subjected to monotonic and cyclic loading [
13]. Chalioris et al. [
14] developed a wireless impedance/admittance monitoring system to identify the incipient damages caused by concrete cracking. In addition, non-destructive testing techniques such as infrared, thermal, ultrasonic, laser, and radiographic tests were also used to detect and analyze the crack development in concrete structures [
15]. Although the above methods provide reliable crack detection results, they are difficult and time-consuming to perform because they require large instrumentation, and are expensive and labor intensive [
16]. To overcome the shortcomings of the manual methods, several image processing methods were developed to provide automated crack detection and visualization in concrete structures. Most of the image processing methods used filtering, thresholding, and feature extraction techniques to identify and localize the cracks [
17,
18,
19,
20,
21,
22]. Furthermore, the crack regions were separated by fuzzy transforms and segmentation algorithms [
21]. Although image processing methods were effective in detecting cracks, the real-time applicability in structures was limited due to the variations in external environmental factors such as light, shadows, and rough surfaces. To improve the performance of image processing techniques, machine learning algorithms were developed through pattern recognition and extraction [
23]. Machine learning algorithms such as support vector machine (SVM) and artificial neural network (ANN) have also been explored to detect cracks in the concrete structures [
24,
25,
26,
27]. A local entropy-based thresholding algorithm was proposed that automatically detects spalled regions on the surface of the reinforced concrete columns [
28]. In addition, the length and width of cracks were also measured using a local binary pattern (LBP) algorithm [
29]. Machine learning algorithms consisting of feature extraction and classification were used to extract relevant crack features. The machine learning algorithm extracts only a few layers of features, and the algorithm might not provide accurate crack detection results if the extracted features do not reflect the cracks.
Deep learning algorithms such as convolutional neural networks (CNNs) have been used in many studies for crack detection and classification to improve the feature extraction process. CNN models can extract relevant features from the input data through multilayer neural networks, which are more advantageous than the existing limitations of image processing and machine learning methods. CNN-based crack detection was performed for the safety diagnosis and localization of damages in concrete structures in [
30]. Similarly, Bayesian algorithms were used to identify cracks in nuclear power plants, and deep learning segmentation algorithms were used to identify cracks in the tunnels [
31]. Furthermore, deep convolutional neural networks (DCNNs) were recently explored for crack detection and classification [
32,
33]. Most of the DCNNs focused on pixel-wise crack classification through semantic segmentation by associating each pixel [
32,
34]. Deep learning networks require a large amount of training data and time. These can be minimized by fine-tuned pretrained DCNNs that use small amounts of data and provide reliable results in minimal time. Fine-tuned pretrained DCNNs such as AlexNet, GoogleNet, ResNet, SqueezeNet, and VGGNet have recently been used to detect and classify cracks in concrete structures. A VGG19 pretrained model was applied to create pixel-level crack maps on concrete pavements and walls [
35]. Crack segmentations were performed using SegNet, U-Net, and ResNet models [
36,
37,
38,
39]. A DenseNet-121-based fully convolutional network was studied to provide the pixel-level detection of multiple damages including cracks, spalling, efflorescence, and holes in concrete structures [
40]. Furthermore, DCNNs based on VGG16 were also used for crack segmentation on the concrete surfaces [
41].
All aforementioned deep learning approaches have shown promising performance in the crack detection of structures. Since the performance of DCNNs depends on various factors, such as data, filters, the number of layers, the number of epochs, and the network depth, it is difficult to select an appropriate pre-trained DCNN for crack detection with high precision and accuracy. The advantage of selecting an appropriate DCNNs is that it ensures better generalization and prevents overfitting. AlexNet, with many pre-trained DCNNs, is the most influential CNN widely applied to image classification and won the ImageNet LSVRC-2012 competition with a minor error rate of 15.3% [
42]. The highlights of AlexNet are listed as follows: there are more filters in each layer; each convolutional layer is followed by a pooling layer; it uses ReLU instead of tanh, arctan, and logistic to add non-linearity that increases speed by up to 6x with the same accuracy; it uses a dropout layer instead of regularization to deal with overfitting; and it makes use of an overlap pooling layer to reduce the size of the network [
43,
44]. These characteristics motivated the utilization of AlexNet in this study for crack detection and classification.
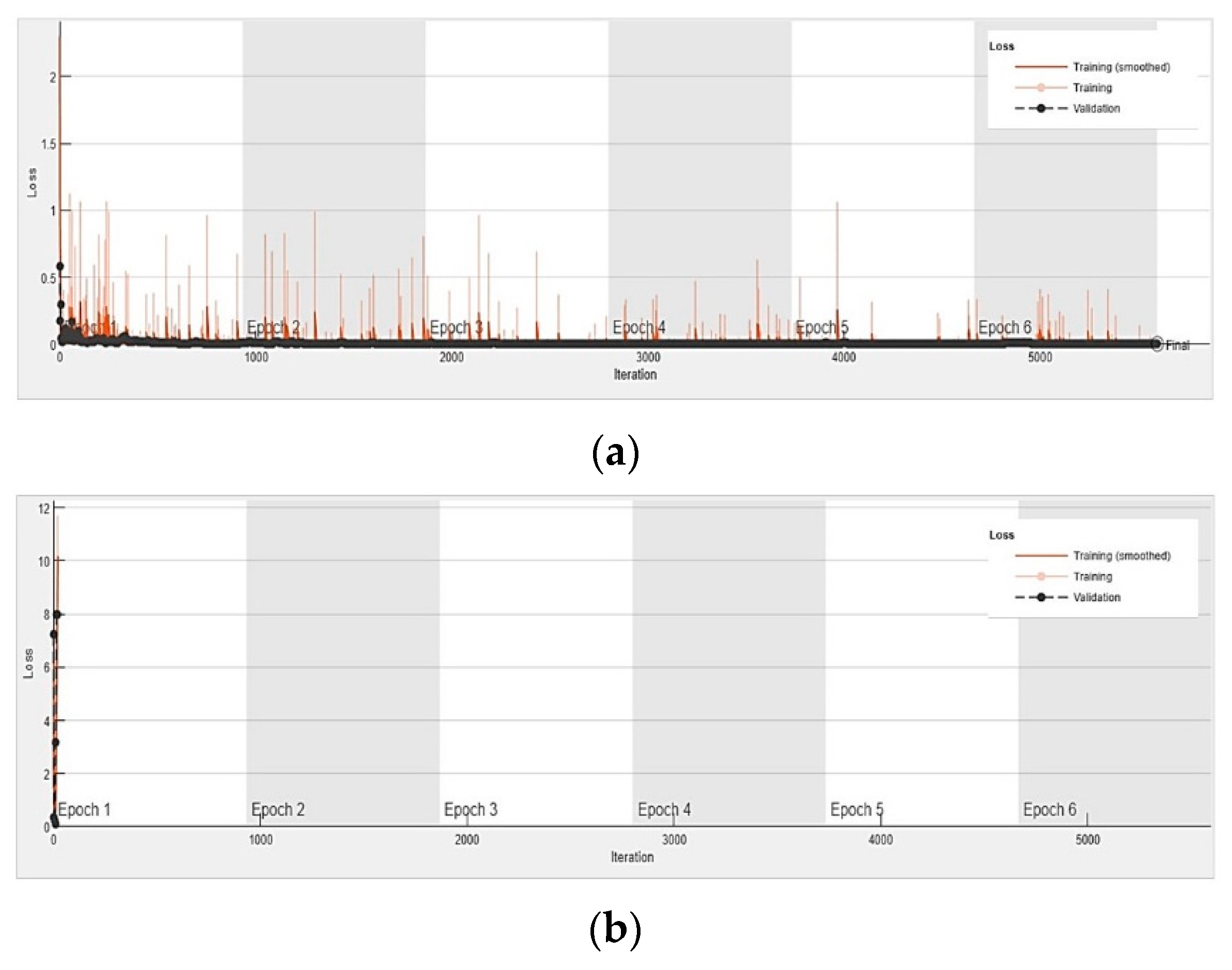
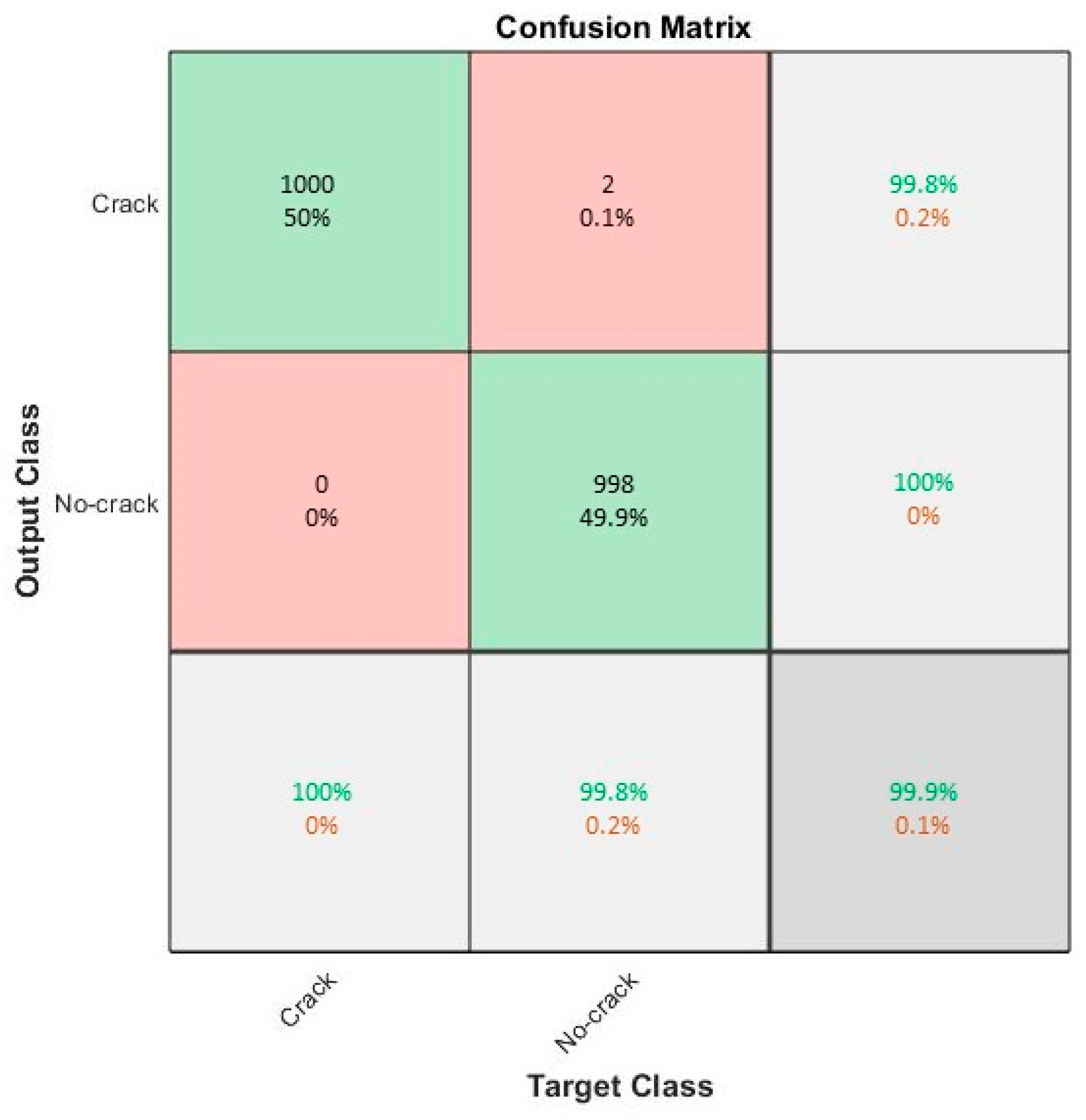
This study utilized AlexNet, a pre-trained deep convolutional neural network, for the automated vision-based crack detection and classification. The proposed method consists of three steps: (1) collecting a large number of images from an open-source image dataset with subsequent categorization of two classes (no-crack and crack images); (2) developing a DCNN model, transferring the learning and augmentation process; and (3) automatically detecting and classifying the images using the trained deep learning model. Additionally, a cross-dataset study was performed to verify the ability of the trained AlexNet model. The precision, recall, accuracy, and F1 metrics were used to evaluate the performance of the trained AlexNet model. The accuracy of the trained AlexNet model was further compared to other pretrained DCNNs such as GoogleNet, ResNet101, InceptionResNetv2, and VGG19.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}