1. Introduction
Civil infrastructures such as roads, railroads, and bridges have an important role in human activities. Thus, it is important to ensure that they last a long time through proper maintenance. The current maintenance practice uses manpower to inspect the exterior of the structure and check for damage, deterioration, and erosion of the structure. Manual inspection is ineffective in terms of time, cost, and need for manpower. Thus, techniques that can improve the current maintenance practice are being introduced.
Recent developments in information technology (IT) have influenced the civil engineering domain, including the maintenance field. In particular, numerous studies have been carried out to replace the exterior survey dependent on manpower in the prior maintenance techniques through sensors or images. Yoon et al. [
1] carried out health monitoring of structures using drones and imaging equipment. Cha et al. [
2] carried out a study to automatically discriminate cracks on concrete surfaces using artificial intelligence. Narazaki et al. [
3] reported automatic recognition of structural elements using artificial intelligence. Lee et al. [
4] automatically extracted bridge design parameters based on point cloud data (PCD). Park et al. [
5] predicted the dynamic characteristics of structures using image data.
Building information modeling (BIM) has recently been integrated into the field to conduct systematic and effective structure planning, design, construction, and maintenance. In Korea, a BIM guideline, “BIM application guide for architecture”, has been established, required for all projects with a total construction cost over 50 million dollars [
6]. In addition, BIM was used to increase the productivity and reduce costs in projects such as the Admiralty Station project in Hong Kong, Danjiang Bridge project in Taiwan, and Zaha Hadid Architects project in the UK [
7].
Although the BIM technique is increasingly being applied to newly planned structures, there are many difficulties in applying BIM to existing structures. Various studies have been carried out to apply BIM to existing structures [
8,
9,
10,
11,
12,
13,
14,
15]. Most of these techniques begin by generating a three-dimensional (3D) model of the structure. However, drawings may not exist for some structures, particularly old structures, when the drawings were not archived digitally. Furthermore, even if there is a design drawing, the current structure can be different from the drawing owing to deterioration, construction errors, etc. Therefore, to generate the as-is model of the structure, 3D PCD are obtained by either using light detection and ranging (LiDAR) or applying photogrammetry with images of the structure.
LiDAR can accurately produce a 3D point cloud model of a structure by emitting laser pulses and measuring the distance to the object by receiving the light reflected back from the target object. LiDAR is usually installed near the structure, which not only requires the operation of the facility to be stopped, but also is time-consuming and expensive. On the other hand, photogrammetry collects photographic data using a camera and generates 3D PCD by applying a 3D modeling technique such as Structure from Motion (SfM) [
16]. The photogrammetry method requires less manpower and is less expensive than LiDAR. Photogrammetry has a lower accuracy than those of LiDAR systems but is improved with the recent advances in unmanned aerial vehicles (UAVs) and camera technologies.
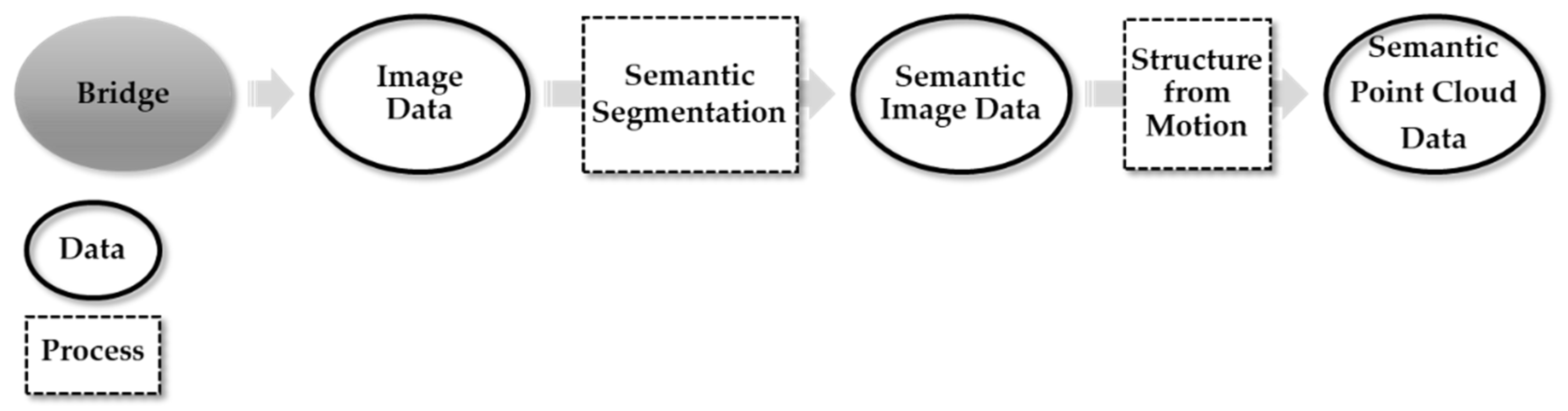
Therefore, this study aims to develop a semantic structure from motion (SSfM) method that collects photographic data and automatically assigns the structural component using a camera installed on an UAV. The proposed method utilizes a deep-learning-based semantic segmentation technique together with SfM to automatically classify the bridge component in a reconstructed 3D point cloud model. The proposed system consists of two steps, (1) semantic segmentation, which classifies every pixel in the bridge image into a structural component, and (2) SfM, which generates 3D PCD using the results of semantic segmentation. A detailed explanation of the proposed system, validation test, and discussion are presented.
2. Background
Computer vision, a field that enables computers to recognize and analyze visual information, has been continuously developed [
17,
18,
19,
20,
21]. Deep learning techniques have recently introduced numerous applications in computer vision [
22,
23,
24]. In particular, a convolutional neural network (CNN), which is one of the methods to classify images automatically, has been introduced in an image recognition contest “ImageNet Large-Scale Visual Recognition Challenge (ILSVRC)”, held in 2012. This study used a CNN-based semantic segmentation algorithm, Deeplab-V3+ [
25], to classify each image pixel into a bridge component.
2.1. Semantic Segmentation Using Deep Learning
Semantic segmentation is a method of predicting and displaying the semantic information of an image by segmenting an image into pixels using a CNN. The general structure of a CNN is shown in
Figure 1. The CNN extracts a convolution feature using the convolution layer and pooling layer alternately from the image (input data) and classifies the extracted features using a fully connected layer.
In this study, semantic segmentation was carried out using Deeplab-V3+. The structure of the Deeplab-V3+ model is shown in
Figure 2. Deeplab-V3+ separates the structure into an encoder and decoder to overcome the disadvantage of the CNN, which loses location information owing to the loss of dimensions while passing the fully connected layer. The encoder extracts features at random resolution through atrous convolution from a deep convolutional neural network (DCNN). The output stride, which refers to the ratio of the resolution of the input image to the resolution of the output image, was applied. The decoder reduces the channel by performing a 1 × 1 convolution on the final output image of the encoder and performs concat after a bilinear upsample. Through the above process, the decoder efficiently maintains the object segmentation details [
25].
Deeplab-V3+ has the advantage of using a pretrained deep learning model. In this study, ResNet-50 was used as a module together with Deeplab-V3+. ResNet-50 is a module using the proposed residual learning to address the gradient loss. In this phenomenon, a variable disappears as it passes a layer. The structure of the existing convolution layer and residual learning is shown in
Figure 3.
Residual learning is the addition of a residual connection (or skip connection) to a prior convolution layer. It is composed of the addition of an input to the stack of two convolution layers.
Figure 3a describes the structure of the existing CNN. Back-propagation training is performed to obtain a weight that minimizes the difference between the predicted value (
H(
x)) of the network and target value (label) of the training data. The predicted value
H(
x) refers to the result of learning the network through data. The target value refers to a label matching the training data.
Figure 3b shows the structure of the residual learning block of ResNet-50. The purpose of learning is
F(
x) becoming 0, considering the hypothesis that it is better to approximate
F(
x) +
x to
H(
x) than to approximate
H(
x) as a function of a complex nonlinear structure. In other words, when
H(
x) ≃
F(
x) +
x, it changes to
F(
x) ≃
H(
x)–
x, and eventually learning F(x) is the output factor
H(
x) and the input factor
x is to learn the difference. Therefore, it can be considered that the residual that is the remainder is learned. Finally, the meaning of learning the optimal
F(
x) is the same as that of the convergence of
F(
x) to 0; as
x becomes a residual connection (or skip connection), there is no increase in the amount of computation [
26].
2.2. SfM
SfM is one of the most popular methods for generation of a 3D model using image data [
27,
28,
29]. The first step in SfM is to identify the correspondence between the images. SfM uses scale-invariant feature transform (SIFT) and speeded-up robust feature (SURF) algorithms to find feature points in photographic data and identify correspondence between feature points [
30,
31]. However, not all of the obtained feature points belong to a correspondence relationship. An outlier in which the feature points do not coincide can exist. In SfM, random sample consensus (RANSAC) was used, which is a method of randomly selecting sample data to remove outliers and selecting data with the largest consensus. As shown in
Figure 4, a feature model of each photograph was obtained by applying RANSAC and a feature matching process was performed to compare the feature models. In this process, if the points match through feature matching, it is determined as a correspondence relationship; if not, it is regarded as an outlier and removed.
When the correspondence between the pictures is grasped through the above process, the position of the camera can be estimated, and the feature points can be expressed as 3D PCD. However, it is not possible to express all shapes of an object with 3D PCD generated only with feature points. Therefore, the 3D dense reconstruction technique is used to obtain dense 3D PCD. The 3D dense reconstruction technique is a method of interpolation using pixels around feature points. Normalized cross correlation (NCC) and inverse distance weighted techniques are used.
NCC is a technique for measurement of geometric similarity by comparing the red–green–blue (RGB) values of pixels. The 3D dense reconstruction technique refers to the surrounding pixels of the feature point. The RGB value of the surrounding pixels is extracted using a filter on the pixel size. If the RGB obtained from the 3D dense reconstruction technique is calculated using Equation (1), the NCC can be obtained.
where
n is the size of the filter,
f(
x,
y) is the RGB at the coordinates of the filter,
t(
x,
y) is the RGB at the
x and
y coordinates of the comparison filter,
is the average RGB of the filter,
is the average RGB of the comparison filter,
is the standard deviation of the RGB of the filter, and
is the standard deviation of the RGB of the comparison filter. As the RGB is nonnegative, NCC has a value between −1 and 1. If NCC is close to 1, the two filters are similar. However, because the NCC obtained from the process does not include the distance information of the photograph, a high reliability cannot be ensured. Therefore, the process of assigning a weight to a distance is required. The NCC uses the inverse distance weighting method, expressed by
where
is the estimated value (interpolation value) of the estimation point,
is the reference value of the position (
,
),
is the weight, and
n is the number of reference values. The weight
can be calculated using Equation (3), where
represents the distance,
Through this process, interpolation is performed on a section in which no feature point exists, and dense 3D PCD can be generated based on the result.
4. Validation Test
To verify the performance of the proposed SSfM system, an experiment was carried out using the test data collected from the Osong 3rd test track in Osong-eup, Heungdeok-gu, Cheongju-si, Chungcheongbuk-do, Korea. A total of 183 test data were collected from the Osong 3rd test track using drones as test data and the semantic segmentation technique developed in this study was applied to automatically classify the components of the bridge. In addition, SfM was applied based on 183 images with semantic information and a 3D point cloud model including information on the components of the bridge was obtained.
In general, a confusion matrix, as shown in
Table 4, was used to evaluate the result of semantic segmentation. Measures to evaluate using the error matrix include accuracy, intersection over union (IoU), precision, recall, and F1 score.
Accuracy is one of the measures used to intuitively evaluate the performance of a classification model, as shown in Equation (4). However, data with unbalanced results can distort the performance of the model and must be expressed using other methods.
IoU is an intuitive measure for the evaluation of the performance of a classification model as an intersection. It is most often used to evaluate the prediction results in semantic segmentation and object detection,
Precision and recall are usually used together and exhibit an inverse relationship. However, both measures have drawbacks, so that they are used together in the F1 score. The F1 score is an index representing the harmonic average of precision and recall and can accurately evaluate the performance of the model even with unbalanced data. Precision, recall, and F1 scores (denoted BF) are defined in Equations (6)–(8), respectively.
The proposed semantic segmentation network classified 183 test data collected from the Osong 3rd test track. The results are shown in
Figure 12 and
Table 5. The bridge component classification network proposed in this study was able to automatically classify the girder and pier on the image, with an average accuracy of approximately 80%, IoU of 66%, and BF-score of approximately 56%.
After the application of 183 data to the bridge component classification network, 3D PCD were generated by applying SfM. The results are shown in
Figure 13 and
Table 6. The results of semantic segmentation could be successfully expressed in the 3D point cloud model. The average precision was approximately 74%, the IoU was approximately 65%, and the BF-score was approximately 55%. It was expected that an additional error will occur in SfM, which converts 2D images to a 3D point cloud model, resulting in lower SfM results than the 2D segmentation results. However, as the semantic segmentation results of several images were averaged to a 3D point of one, the IoU and BF-score of a specific class (pier) slightly increased.
5. Conclusions and Discussion
In this study, an automatic procedure for generation of a 3D point cloud model that contains bridge component information was proposed using deep learning and computer vision. The verification test was carried out at the Osong 3rd test track located in Osong-eup, Heungdeok-gu, Cheongju-si, Korea, by applying the proposed technique to the collected images. The proposed method was able to automatically generate a 3D point cloud model containing information on bridge components with an accuracy of 74.23%, IoU of 65.90%, and average BF score of 55.59%.
Lee et al. [
4] conducted a study to automatically extract design parameters of bridges using 3D Point Cloud Data, and the results showed high reliability. However, this study used LiDAR to acquire 3D Point Cloud Data. There is a problem where the bridge must be shut down in order to obtain 3D point cloud data from LiDAR. In order to solve this problem, in this study was conducted to collect 2D image data with an unmanned aerial and generate 3D point cloud data using the 2D image data.
It was confirmed that the proposed method in this study has a problem of increasing the error because errors are accumulated in the process of SSfM. However, if errors are minimized in the future by using deep learning models with improved modulus and big data, it is expected that time and cost in the modeling for the BIM of existing structures can be saved.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}