1. Introduction
Ground special vehicle is a kind of complex equipment that is used for the purpose of satellite transportation and space launch preparation, which contains hydraulic control subsystem, temperature control subsystem, fixed aiming subsystem, power supply, and distribution subsystem, fuel subsystem, electronic control subsystem, communication subsystem, and so on.
In a mission-critical launch, The GSV is required to operate in a reliable and efficient way; at the same time, the incident of system degradations and fault-related abnormality must be reduced or prevented in advance. In the case of system degradation or failure, GSV will operate abnormally, and the consequence is very serious. The mission will be forced to abort the launch. In addition, the personnel will be seriously injured, and components of GSV will be damaged. As a result, consideration of reliability and safety risk for GSV is very important prior to the operation process. For such complex equipment as GSV, effective measures and practical methods must be taken into consideration to ensure high availability of GSV, and having an automated procedure of safety management and health maintenance is very important. In order to comprehensively manage the operation of GSV, researchers prefer to adopt the Prognostic and Health Management (PHM) structure to ensure safety and reliability, and to provide solutions based on health management [
1,
2,
3,
4]. Based on diagnostics/prognostic information, available resources, and operational demand, PHM is capable of making appropriate decisions about maintenance actions in its actual life-cycle conditions. One of the important tasks involves continuous monitoring with analysis using proven algorithms [
5,
6,
7,
8].
When it comes to GSV, the development of data collecting and processing technologies is introduced, a large number of multiple on-board sensors are deployed to perform condition monitoring and health management of GSV, at the same time, a large amount of data about the operation conditions of the GSV are recorded. In addition to data from historical operation record, historical experiences from expert’s domain knowledge are also maintained and stored. In this way, GSV stores a large amount of historical operational knowledge about problems and solutions during the operation and maintenance cycle, this information constitutes a case library for reasoning. How to make better use of the knowledge as a reference to offer feasible solutions is the main topic. Based on the inference of a large amount of knowledge retrieval and analysis, a quantitative or qualitative conclusion about the health of the system can be derived.
In some practical cases, a rule-based reasoning model can be appropriate for knowledge representation in PHM structure [
9]. However, in this model, knowledge acquisition and expression are based on expert experience and have a certain degree of subjectivity. Therefore, it is difficult to express and acquire knowledge. Unlike other application areas, for GSV, a large amount of historical operational knowledge about problems and solutions were stored during the operation and maintenance cycle, and case-based reasoning (CBR) methods can make better use of this knowledge to provide solutions and maintenance suggestions for the diagnosis and health management of the system [
10].
CBR is a kind of reasoning and machine learning method in the field of artificial intelligence (AI). It is especially applicable to the fields with no accurate mathematical models, but with much information of experience and historical knowledge. The basic principle of the CBR method is to solve new problems by reusing solutions of the previous similar problems accumulated in historical experiences [
11,
12]. The historical experiences are combination of past operation cases that contain data records, semantic descriptions, evaluation results, and solution references. CBR can imitate analogy human thinking, and learns from experiences, which is in line with the human cognitive process of new things. CBR has the characteristics of easy acquisition of knowledge, simplification of solving process, high quality of the solution, and incremental learning [
13]. CBR has developed rapidly in recent years. Several international case-based reasoning conferences have been held in European and other CBR workshops [
12,
13]. CBR technology has been applied in various fields, such as fault diagnosis, product design, pattern classification, regression prediction, intelligent control, and has achieved remarkable application success [
14,
15,
16,
17,
18,
19].
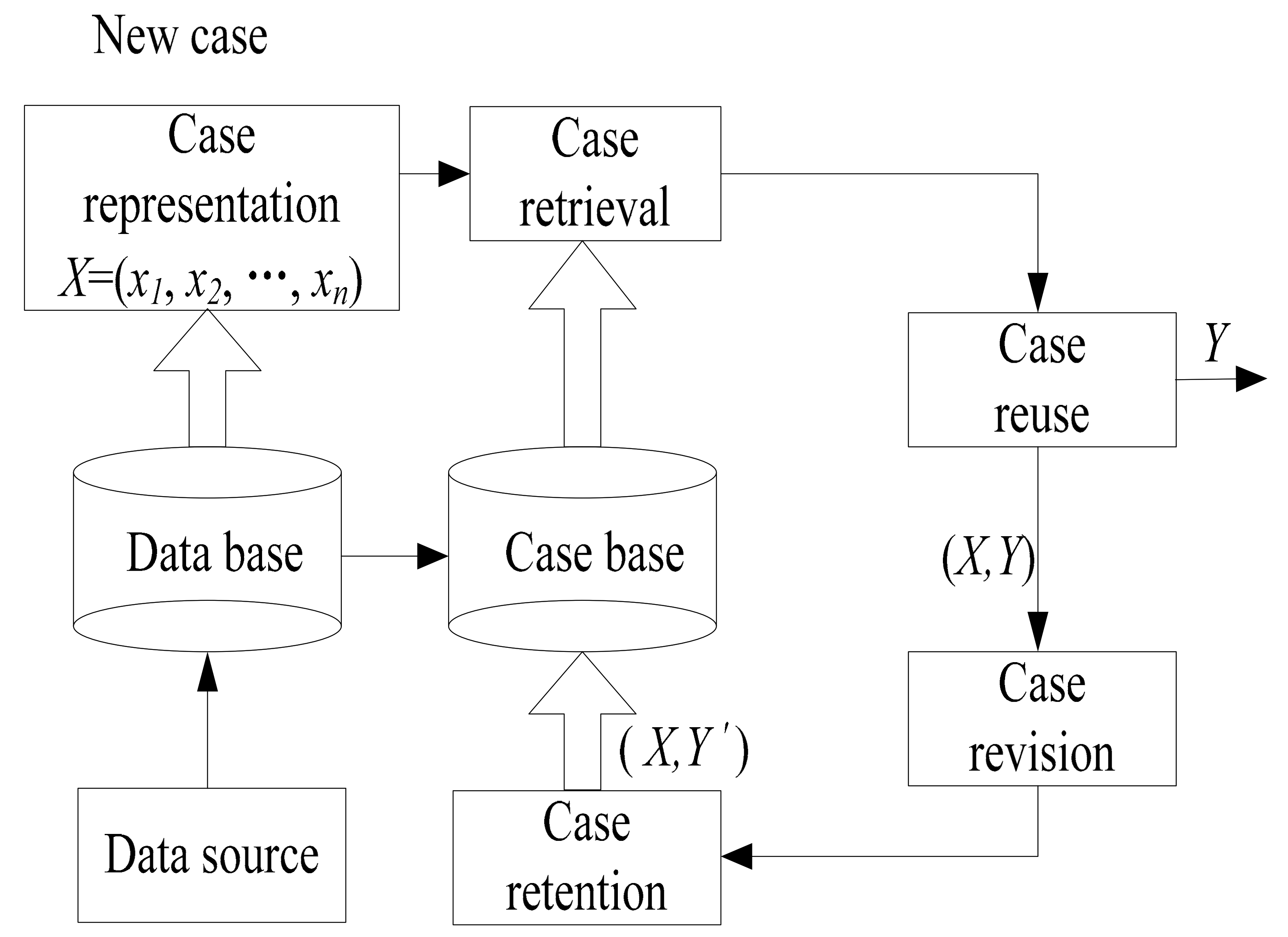
The basic CBR is composed of 4R procedures, namely, case retrieval, case reuse, case revision, and case retain. In the case of retrieval, the weight allocation of the case attribute determines the similarity between cases, thus affecting the result of case retrieval [
20,
21]. Due to the different characteristics of practical fields, the specific case-based reasoning model is not applicable to other application fields; moreover, the reasoning algorithm must not only meet the application model requirements of the actual system, but also be able to make it practical. Weight calculation for case similarity is a key issue of the CBR method. Algorithms for weight allocation must be improved or re-considered according to the case base of a certain field. It is necessary to set weights for the cases in these case libraries through fast and effective algorithms. Simulated annealing (SA) algorithm is a kind of optimization algorithm that converges to the optimal global solution with a probability of 1 [
22,
23]. SA has the adaptability to deal with both discrete data and continuous data. SA has the characteristics of universal, easy to achieve, and high quality, and is widely used in engineering fields, such as fault diagnosis, circuit design, vehicle routing, and image processing [
23,
24,
25,
26,
27]. It is of high practical value. To make GSV PHM structure more suitable and practical, a CBR model containing a simulated annealing algorithm for optimizing case attribute weights is developed. The model begins with case representation, then, the optimization methods for attribute weights are established for case retrieval. The proposed method is applied to subsystem health evaluation of GSV. Cross-validation results show that the proposed method can reach the accuracy of case-based reasoning of GSV PHM structure.
The rest of this paper is organized as follows. In
Section 2, the application framework using the CBR model for PHM is briefly introduced, as well as the topics regarding case representation, case retrieval, and case reuse are described. In
Section 3, the optimization method of feature attribute weight allocation based on the SA algorithm is presented, which is developed in Java.
Section 4 is application validation and design of comparative experiment in some data sets to evaluate the running performance of the application, and the results and analysis are provided as well. In
Section 5, some conclusions and future outlooks are presented.
3. Module of Weight Optimization
In the process of case retrieval, the weights should be allocated, so that importance for each attribute value reaches the optimized result. There are two kinds of weight allocation methods: The subjective method and objective method. The subjective method includes expert consultation method; factor paired comparison method, the minimum sum of squares method, and analytic hierarchy process, etc. [
29]. Such weight allocation methods rely on human experience, which is subjective and uncertain. In order to overcome the subjective influence, some objective methods have been put forward. There are artificial neural network method, water injection theory method, and genetic algorithm method [
30,
31,
32,
33,
34]. But these methods also have some shortcomings. The artificial neural network method calculates the feature weights according to the training model and its connection weight value, which is poor to explain, and hard to be transplanted [
35,
36]. The principle of the water injection method is based on data correlation, which is strict to the types of data. It would make a poor performance in some discrete data sets. The genetic algorithm tends to converge prematurely. The population size, cross-rate, and mutation rate of the genetic algorithm have a great influence on the solution, but the setting of parameter is neither uniform enough nor simple enough. From the viewpoint of practical purpose, simulated annealing algorithm has the characteristics of universal, easy to achieve. It is also easy to code and can generate better solutions. This is an attractive option for optimization problems where complex algorithms are not feasible, especially for application development of practical fields. In this paper, the SA method is employed and coded to optimize weight.
3.1. Basic Steps for Algorithm
The basic steps of the SA algorithm are developed as a function module, so the main procedure can call the module whenever necessary. The basic steps are given as follows.
- Step 1.
Initialize parameters: Temperature T, Temperature decreasing factor , current solution , , repeat number L, minimum temperature .
- Step 2.
For temperature T, repeat Step 3 to Step 5 for L times.
- Step 3.
Generate the new solution (Namely, the new weight vector in the feasible solution space is obtained based on the initial weight vector).
- Step 4.
Substitute the new solution
into the case-based reasoning process, and calculate the increment
. Where,
denotes the objective function of the SA algorithm. The calculation detail of the objective function is explained in
Section 3.2.
- Step 5.
If the increment of objective function is less than zero, the new solution is directly accepted as the current solution. Otherwise, the new solution is accepted as the current solution with probability .
- Step 6.
If some termination condition is satisfied, the algorithm will stop, and the approximation of the optimal solution is output. Otherwise, go to Step 7.
- Step 7.
Decreasing temperature . If T is less than , the algorithm will stop. Otherwise go to Step 2, and continue the cycle.
3.2. Performance Index for Objective Function
In this application, a case library is established using the historical data record set. In order to improve the optimization effect of weights, a cross-validation method is adopted. The procedure is described as below.
At first, select
n case from case library, and divide the selected
n cases into five subsets, and the subsets are marked as
,
,
and
, respectively. The total number of cases in each subset is equal. Mark one subset as the target case, and the remaining four subsets are combined to form the source case. The source case is the training set, and the target case is the test set. Following that, case retrieval and case reuse are implemented according to description in
Section 2.4. Finally, the solution attribute value of each target case is obtained. Each subset in
will be taken as the target case in turn, and the remaining four subsets will form the source case base. This process repeats five times until the cross-validation is completed, the objective function is described as below.
- (1)
The selected case in the case library is expressed as Equations (1)–(3); for each case, there is more than one condition attribute and only one solutions attribute, and the value of the solution attribute can only be a normal state or abnormal state. The subsets from source cases are organized, as below.
In Equations (10)–(12),
denotes
jth case has condition attribute of
m in subset
,
denotes
jth case has 1 solution attribute of
in subset
.
can only be normal state or abnormal state. According to the description in
Section 2.4.1, suppose the number of cases with correct state classification in the target case set is
, and the number of target cases is
G, the state classification accuracy and state classification error is computed, as follows.
where
ei denotes the percentage of misclassified cases in the target case set. The smaller the state classification error rate, the better the state classification accuracy. The objective function is setup by averaging the state classification error rate.
- (2)
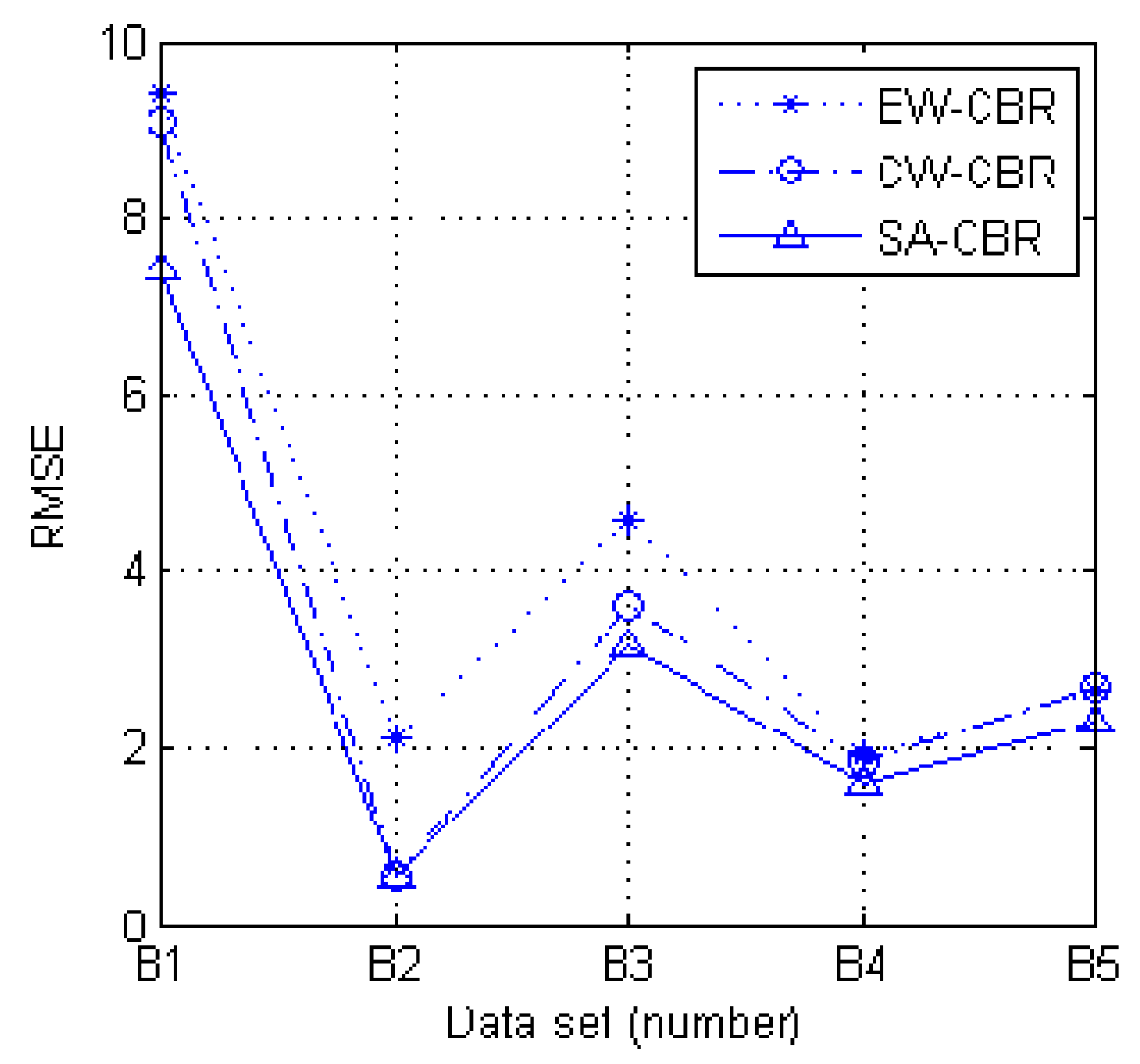
The selected case in the case library is expressed as Equations (1)–(3); for each case, there are more than one condition attribute and only one solutions attribute, and the value of the solution attribute is the probability value in the range of (0,1). The subsets from source cases are organized as the same in Equations (10)–(12), but the root mean square error is taken, as below.
In the formula,
represents the inference value of the solution attribute of the
jth target case in subset
, and
represents its actual value. The smaller the RMSE, the better the result. Similarly, the objective function is setup by averaging the root mean square error.
It can be seen from Equation (17) that the smaller the objective function, the better the attribute weight vector. Therefore, in the step of using the simulated annealing algorithm to obtain the feature attribute weight, the objective function can determine the optimized weight. If the objective function of the new solution becomes smaller, the new solution is directly accepted. Otherwise, the new solution is accepted with metropolis probability to jump out of the local optimum.
5. Conclusions
Through using data-driven health management processing and risk safety analysis in the PHM structure, this paper describes application development and establishes a CBR model to solve the normal/abnormal state determination and degree of health performance determination for practical purposes. In addition, the rules for case retrieval and case reuse have been established for state classification problems and health determination problems. In the weight distribution method, a feature attribute weight optimization method based on the simulated annealing algorithm is proposed. The proposed method combines case-based reasoning with machine learning and is a data-driven method. The developed SA-CBR module within the application uses historical cases to train feature attribute weights. The richer the historical data is collected, the more accurate the inference results will be. SA-CBR algorithm is simple and easy to understand, as well as parameter configuration is convenient; it is, therefore, practical for PHM structure. Three methods of EW-CBR, CW-CBR, and SA-CBR are investigated based on the actual historical data set, and experimental application results are shown and analyzed. The results indicate that validation of the developed SA-CBR module is simple to realize, and the practical requirement is satisfied.
Although the proposed method shows outstanding advantages, there are still many problems to be dealt with. At present, the established CBR model is specifically developed for the PHM structure of the launch vehicle system. In the future, it should be considered to be applied to more engineering fields. In addition, other methods can be introduced in the reasoning method to improve the reasoning performance. As the amount of historical data becomes larger and larger over time, simplifying redundant cases before reasoning is also a problem that needs to be considered.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}