A Preprocessing Strategy for Denoising of Speech Data Based on Speech Segment Detection



Abstract
:1. Introduction
- 1.
- Statistical feature-based methods: There have been previous studies that exclude the noise by the threshold value according to a specific statistical feature. The proposed representative criteria are nonnegative matrix factorization [3], Wiener filter [1,4,5], and wavelet transformation denoising [2,6]. Before AutoEncoder and deep learning-based methods were proposed, this approach had been widely used.
- 2.
- AutoEncoder-based methods: Denoising AutoEncoder (DAE) has been already used in image processing to extract the noise for the classification [7]. For denoising in speech signals, there have also been many previous studies to adopt the DAE to extract the noise from noisy speech data: DAE using the noisy speech as the input and the clean speech as the output [8], a new pre-training and fine tuning methods based on the DAE [9], weighted DAE capturing the relationship between the noisy and clean speech signals [10], time-domain convolutional DAE [11], and speaker-aware DAE [12].This approach allows us to conduct unsupervised learning without manual labeling because the noises are automatically generated in the model. However, it has been known that the strength and accuracy of the model are lower than the deep learning methods, which are supervised learning based on the labeling of clean and noisy data sets.
- 3.
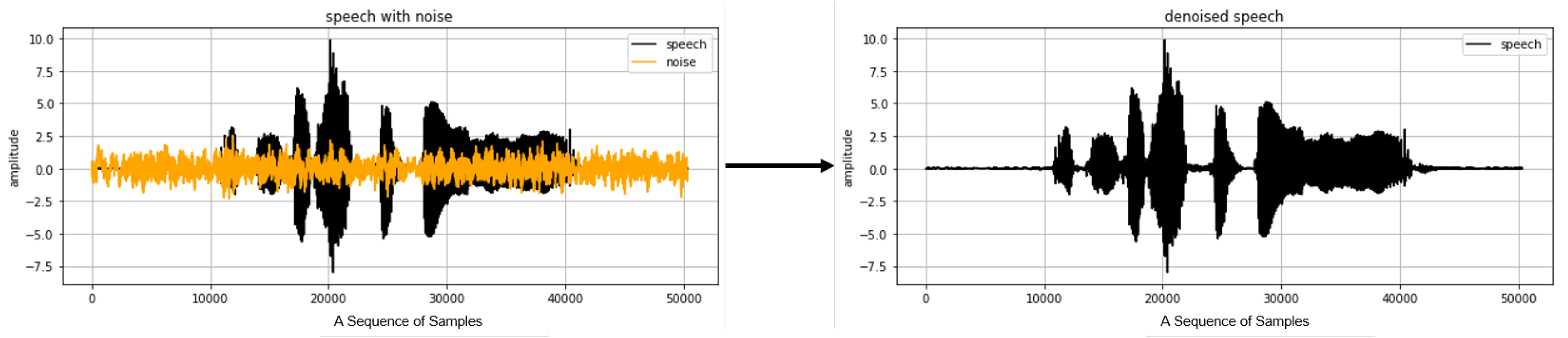
- Deep neural network (DNN)-based models: Deep learning-based denoising learns the difference between noisy speech data and clean speech data. Various deep learning models have been proposed: Wavenet-based denoising model [13], Fully-Convolutional Networks (FCNs) denoising model [14], Convolutional Neural Network (CNN) denoising model [15], Recurrent Neural Networks (RNNs) denoising model [16], and Convolutional-RNN (CRNN) denoising model [17]. This approach generally shows a high performance although it requires large-scale data sets with labeling and requires significant computing costs in the training process. One of recent advances in deep learning-based methods is the Wavenet-based algorithm, which is an end-to-end model developed by Google [13]. Wavenet has been used to produce sound waveforms within Tacotron [18], Google’s voice synthesis model [13], which can identify speech features effectively. It has been shown that Wavenet-based denoising performs better than Wiener filter, which is one of the most widely used methods [4].
- 1.
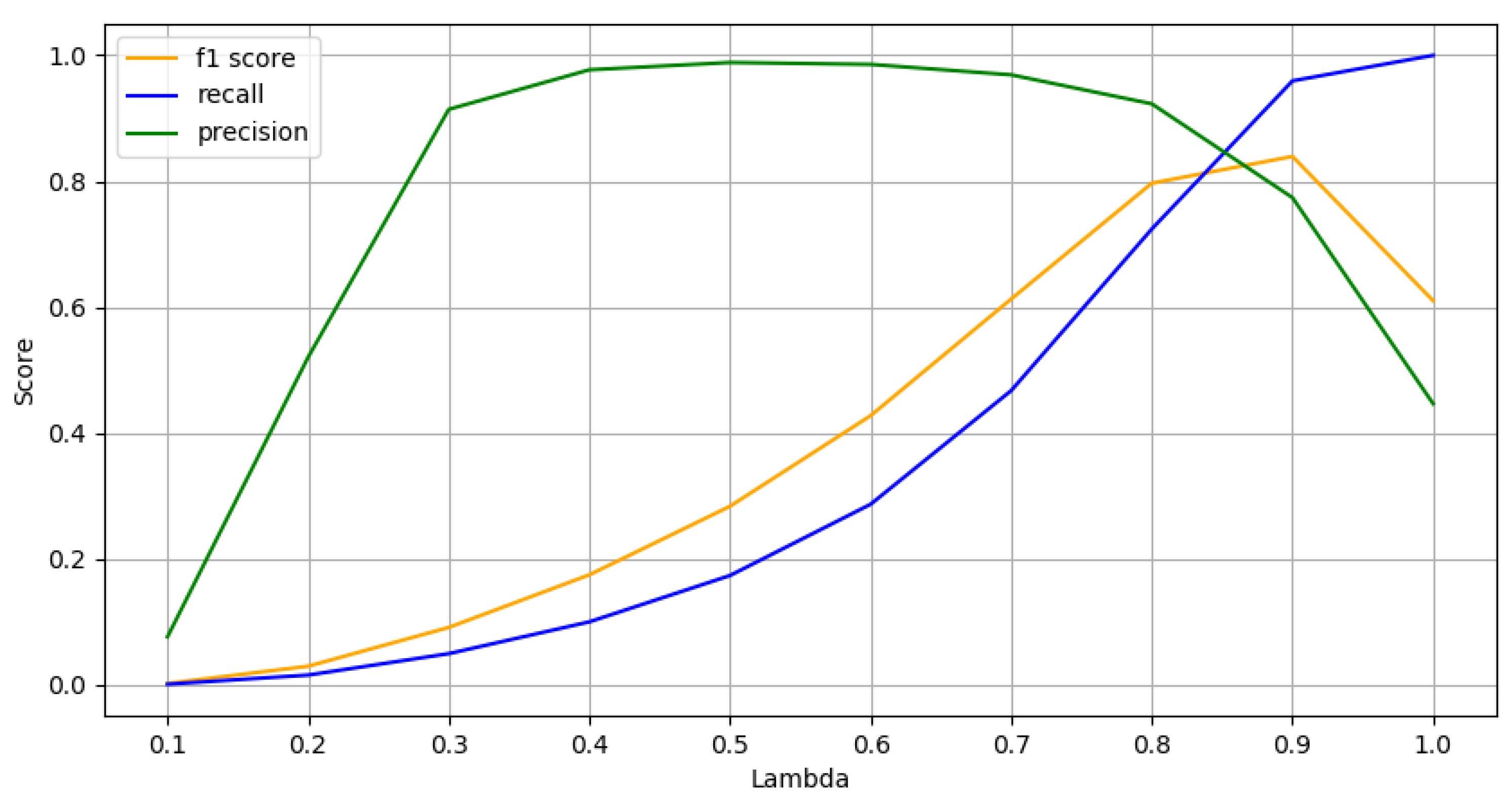
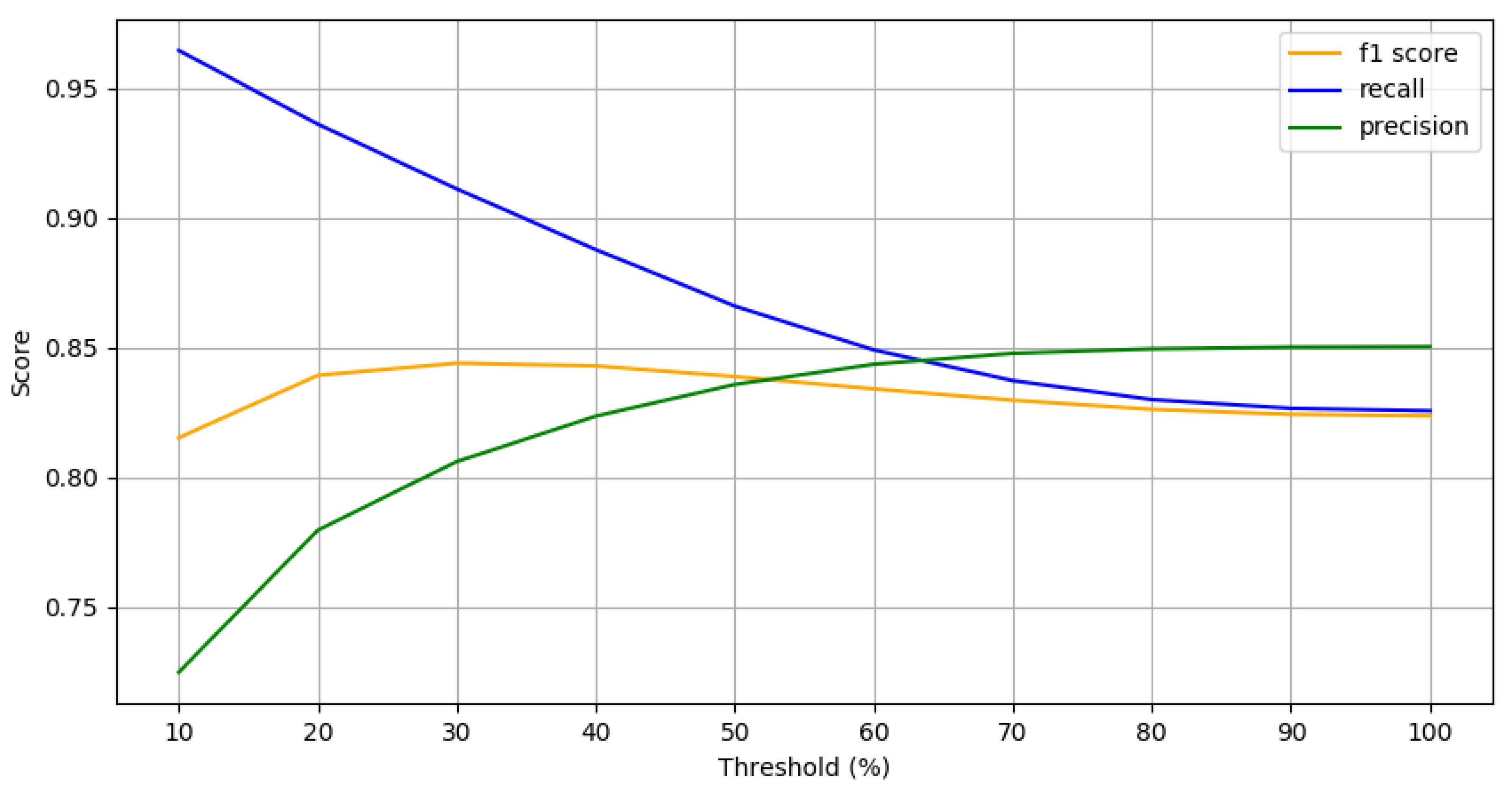
- We speculate the target environment using samples of noisy and clean data files to figure out the characteristics of the environment. To define the environment, we use different levels of signal-to-noise ratio (SNR) and multiple evaluation criteria, which affect the results of preprocessing significantly. That is, the effects of the speech segment detection methods are quite varied according to the level of SNR (See Section 4). In addition, we need to determine a preferred evaluation criterion. Specifically, in some environments, we should not allow to exclude any small speech segments even if many non-speech segments are not excluded (i.e., recall takes the precedence over precision); in other environments, we can improve the overall effects of denoising by allowing to exclude some negligible speeches (i.e., precision over recall).
- 2.
- We enumerate the speech segment detection methods by combining filtering and unsupervised methods that have been used for the voice activity detection [22] and conduct their performance evaluation to select the most effective method for a target environment. Here, we note that the purpose of the speech segment detection methods is effectively excluding the non-speech segments as preprocessing of denoising, not improving the performance of the speech segment detection itself. As a result, we investigate simple and efficient speech segment detection methods that can work effectively with the denoising method.
- 3.
- We apply the speech segment detection method with the best setting by each method into noisy data files. In this step, the non-speech segments, which will be removed with a significant cost in deep learning-based denoising process, are efficiently excluded, while the overall accuracy is maintained.
- 4.
- We apply the Wavenet-based denoising model [13], which is one of recent advanced denoising methods based on deep neural networks, to only the speech segments. Through extensive experiments, we evaluate the performance of the proposed strategy by each speech segment detection method where the best setting in the previous step is used and compare them with the original Wavenet-based denoising model in terms of the speed and accuracy of denoising.
- 1.
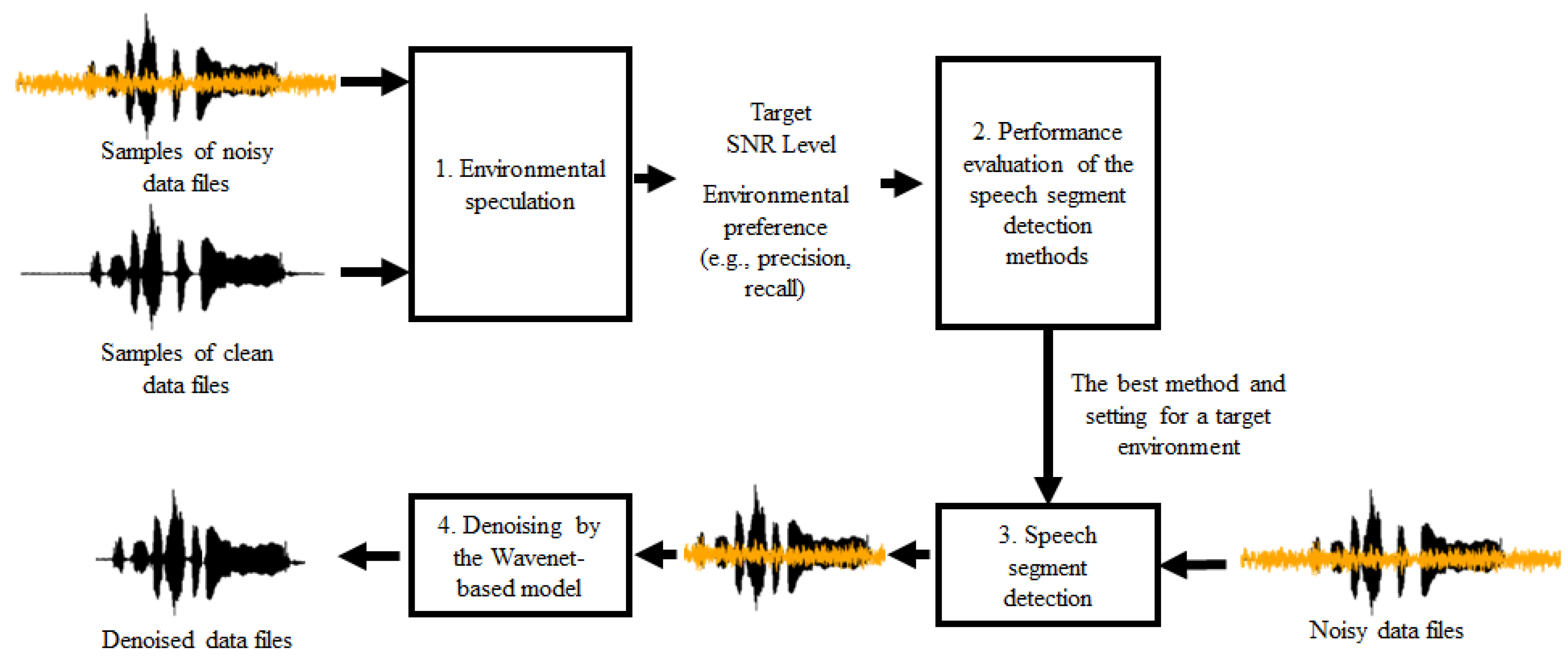
- We devise a framework to choose the best preprocessing method for denoising based on the speech segment detection for a target environment. For this, we speculate the environments for denoising using different levels of SNR and multiple evaluation metrics. As shown in Figure 2, the framework finds the best speech segment detection method tailored to a target environment according to the performance evaluation of speech segment detection methods.
- 2.
- We investigate the accuracy of the speech segment detection methods extensively. We conduct the performance evaluation of five speech segment detection methods with different levels of SNRs and multiple evaluation metrics. Especially, we show that we can adjust the accuracy between the precision and recall of each method by controlling a parameter. Through extensive experiments, we measure the accuracy of the speech segment detection methods with a variety of SNRs and evaluation metrics and observe that a different speech segment detection method shows the best accuracy for each group of SNRs and evaluation metric. This result indicates that we need to select the most effective speech segment detection method for a given target environment.
- 3.
- We incorporate the best speech segment detection method for a target environment into a denoising process. Through extensive experiments, we show that the accuracy of the proposed preprocessing strategy is comparable to or even better than that of the original Wavenet-based denoising in terms of multiple evaluation metrics of denoising, i.e., SNR, STOI, and PESQ, while it can reduce the denoising time of the Wavenet-based denoising by 40.06–50.76% according to the used speech segment detection method.
2. Preliminaries
2.1. Wavenet-Based Denoising
2.2. Voice Activity Detection
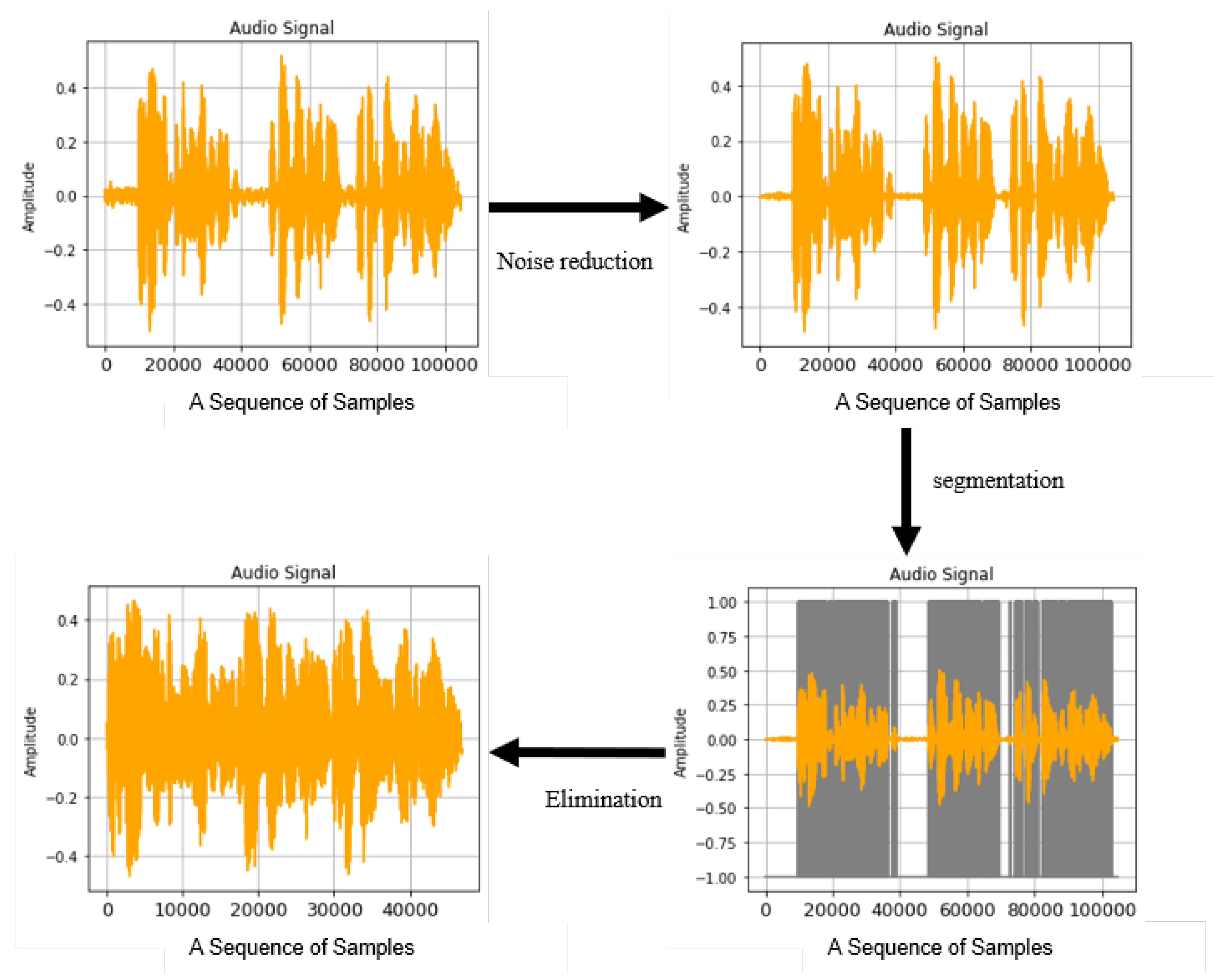
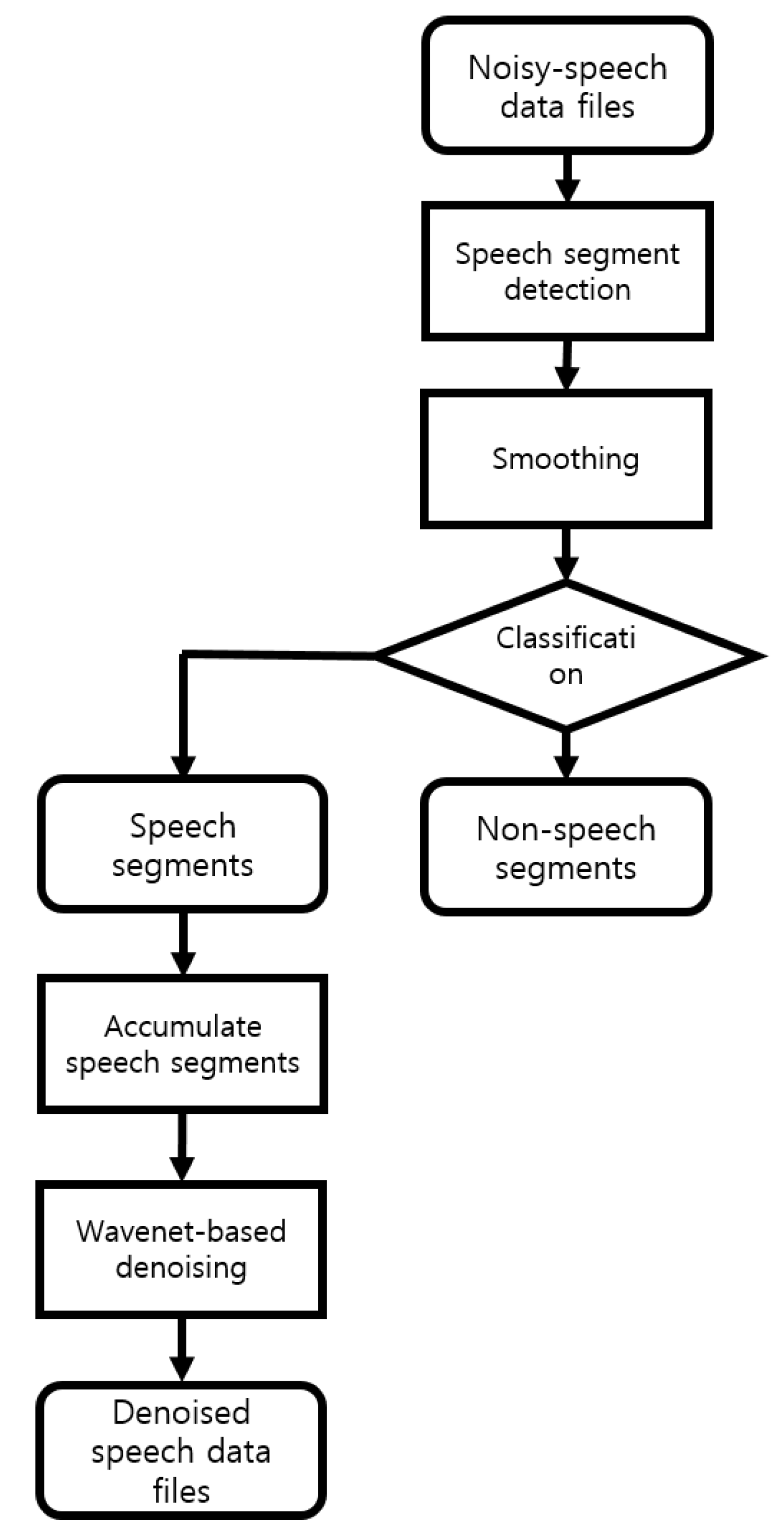
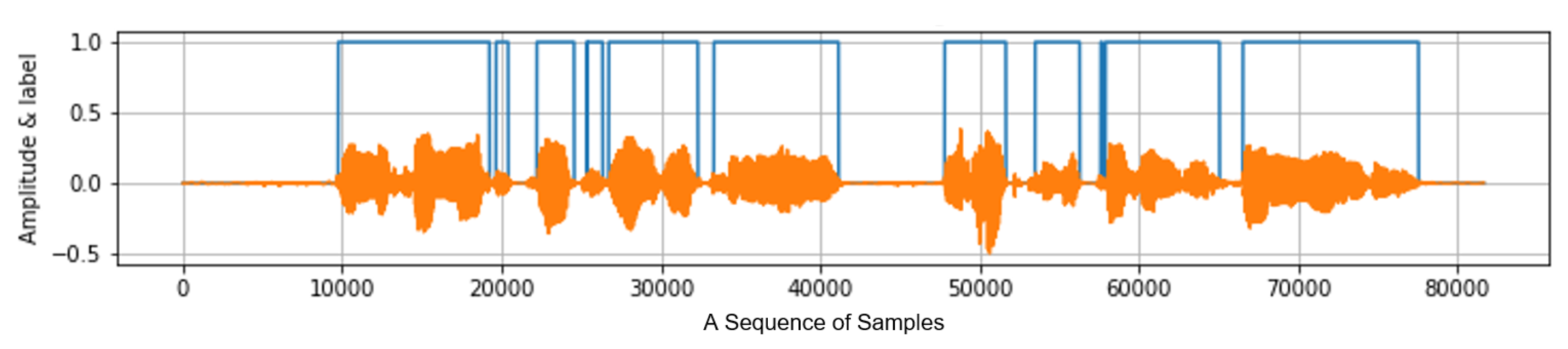
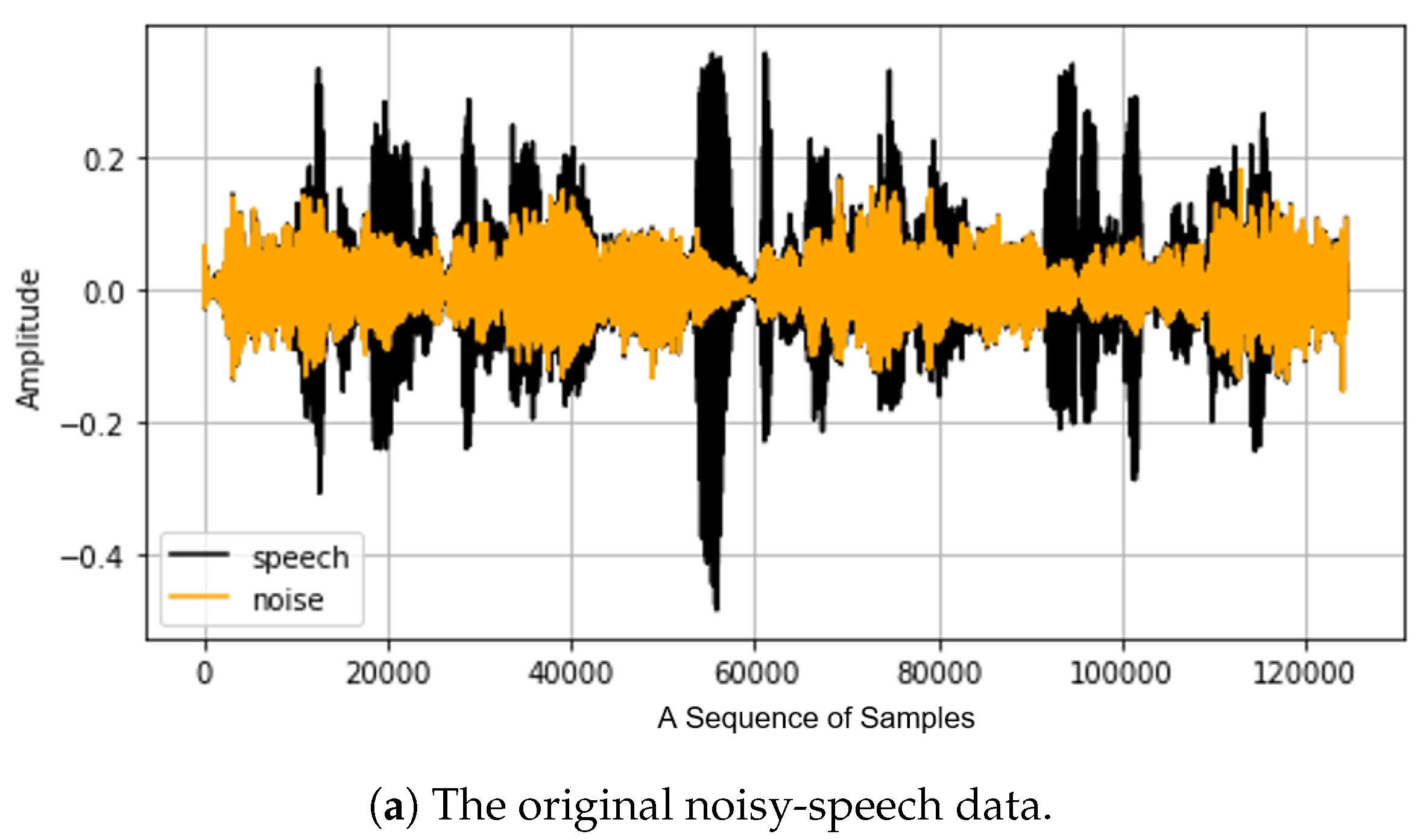
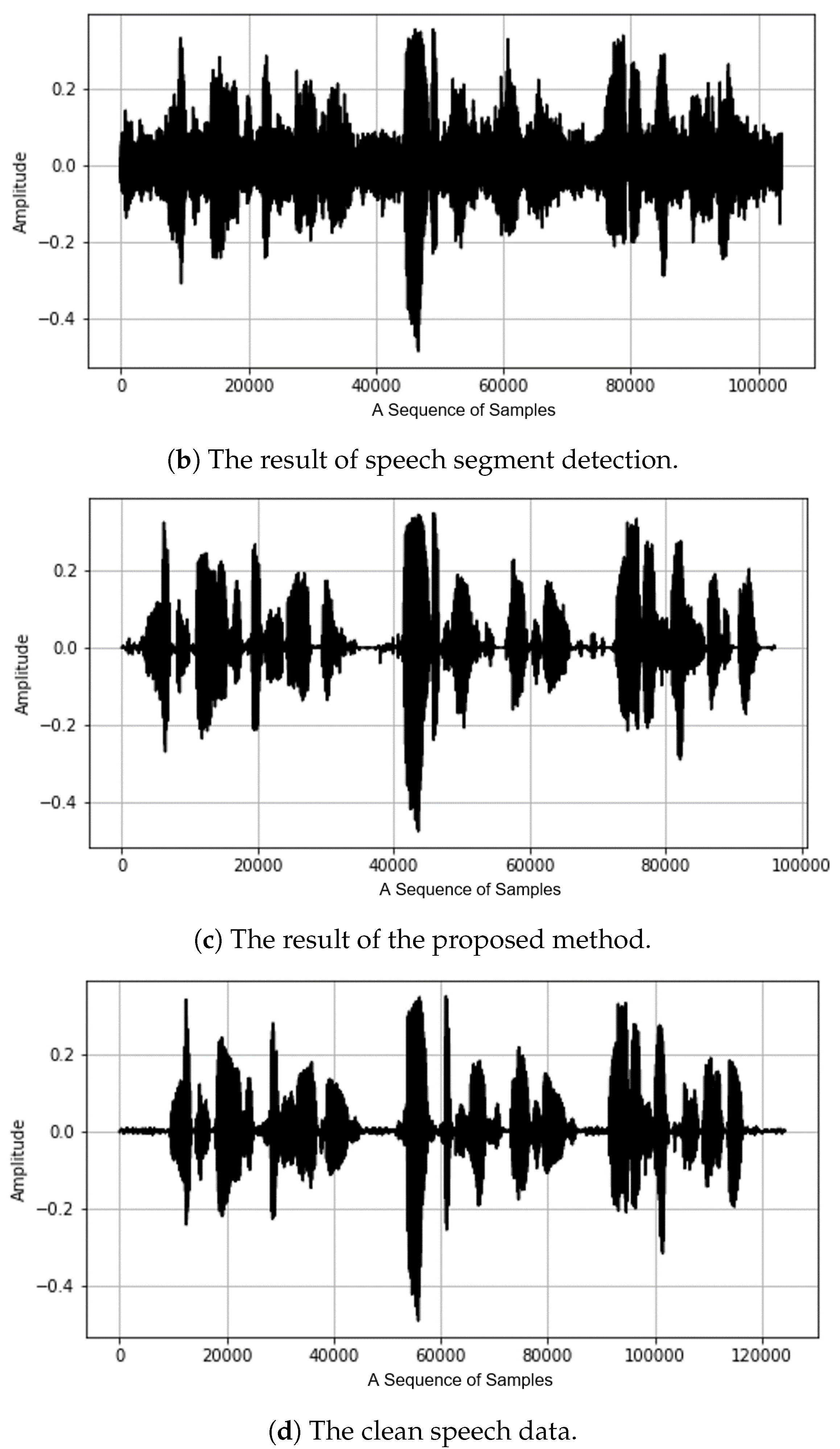
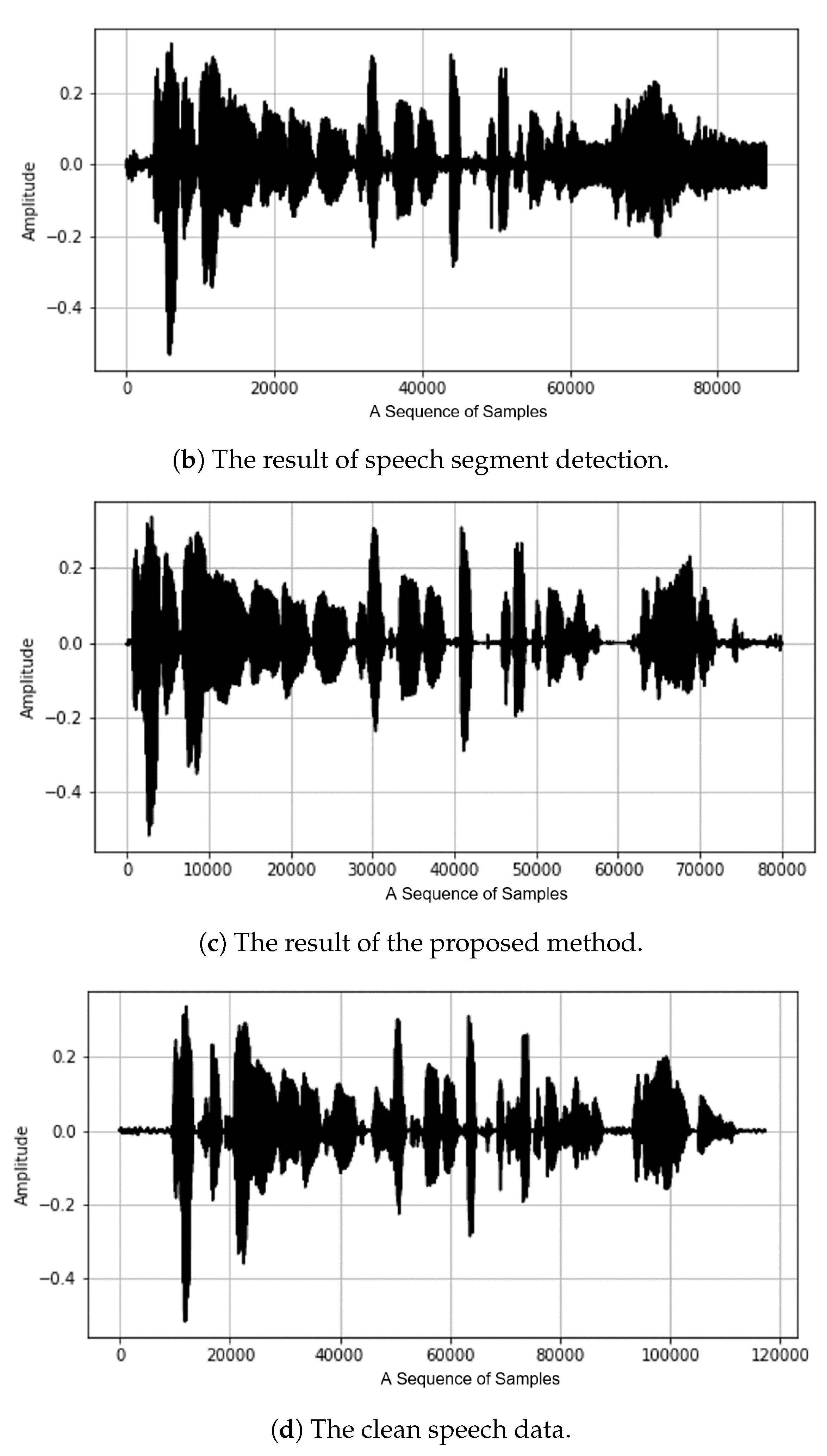
3. Denoising Based on the Speech Segment Detection
3.1. The Overall Flowchart
3.2. Filtering Methods
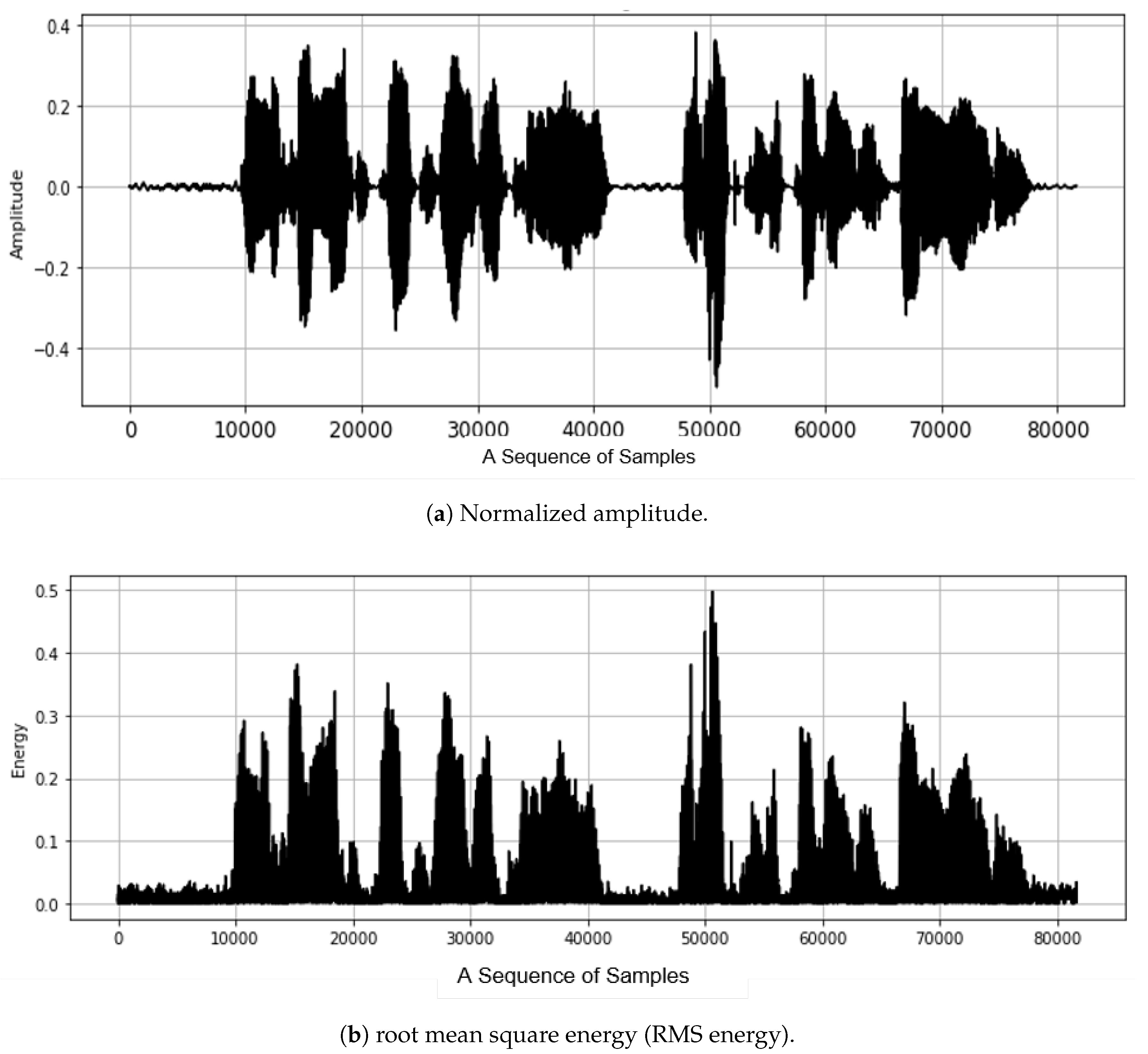
3.2.1. Energy-Based Filtering
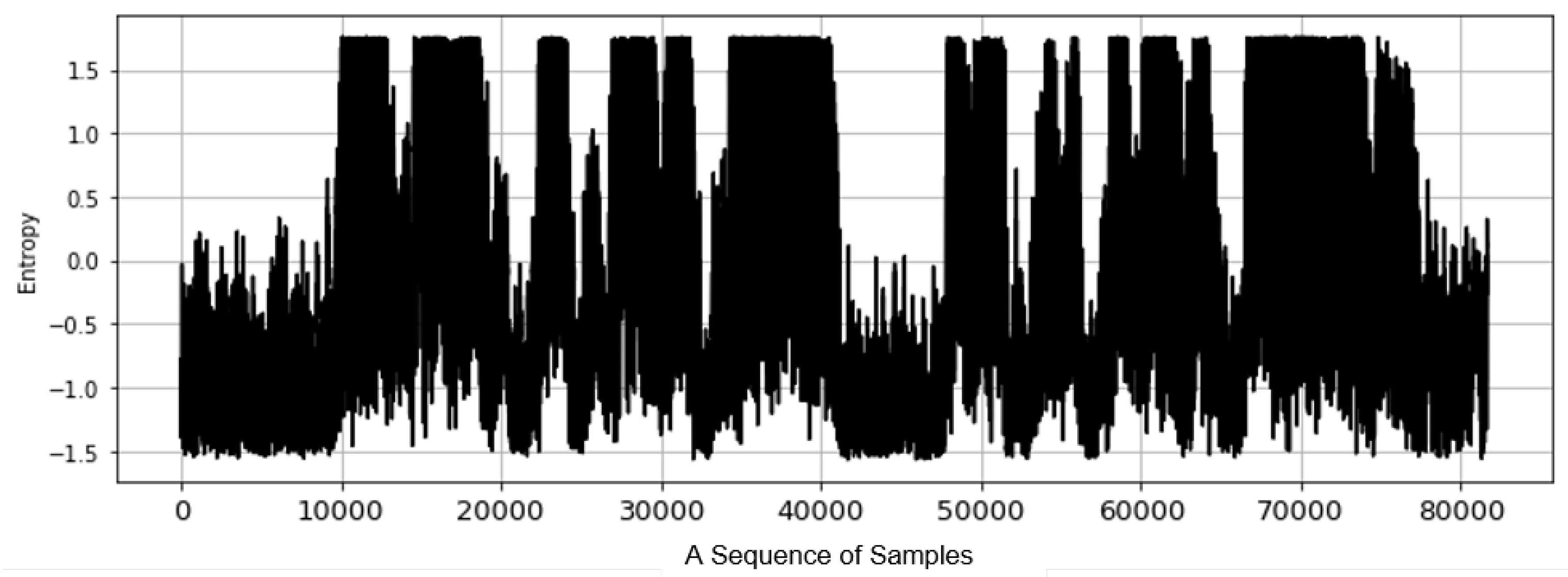
3.2.2. Entropy-Based Filtering
3.3. Fuzzy Clustering
3.4. Filtering with Fuzzy Clustering
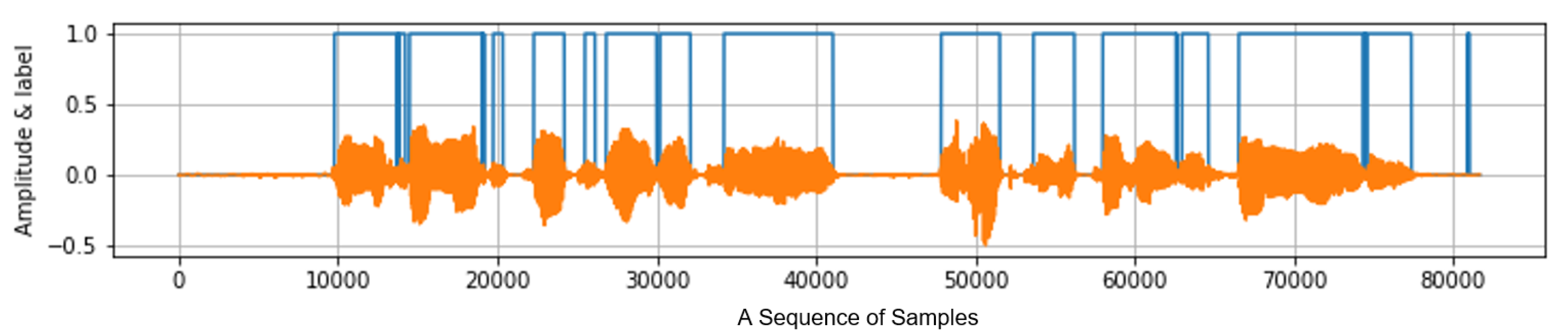
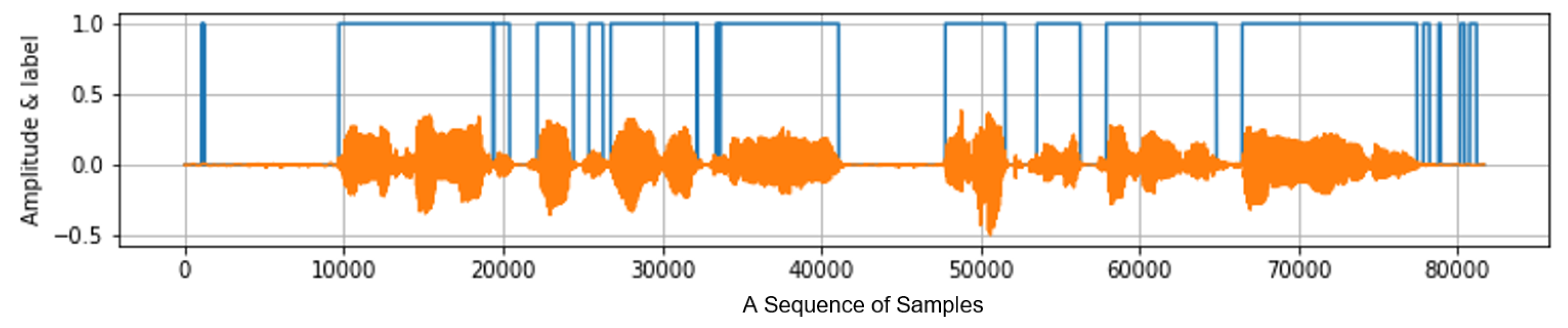
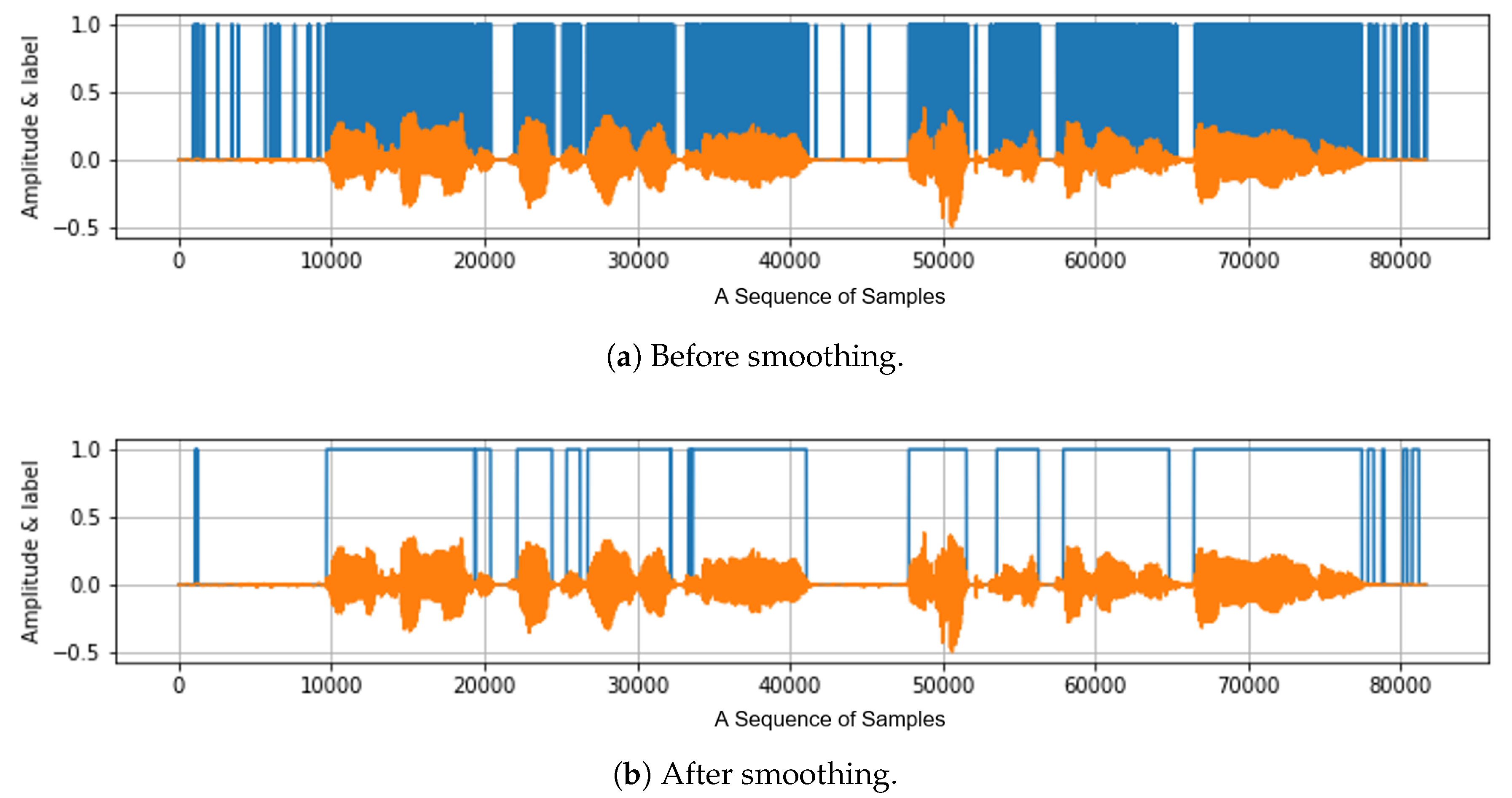
3.5. Smoothing
4. Performance Evaluation
4.1. Experimental Environments and Method
4.2. Results and Discussion
4.2.1. The Accuracy of the Speech Segment Detection Methods
4.2.2. The Execution Time of Denoising
4.2.3. The Accuracy of Denoising
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gui, Y.; Kwan, H.K. Adaptive subband Wiener filtering for speech enhancement using critical-band gammatone filterbank. In Proceedings of the 48th Midwest Symposium on Circuits and Systems, Covington, GA, USA, 7–10 August 2005; pp. 732–735. [Google Scholar]
- Soon, Y.; Koh, S.N.; Yeo, C.K. Wavelet for speech denoising. In Proceedings of the IEEE TENCON’97, Brisbane, Australia, 4 December 1997; pp. 479–482. [Google Scholar]
- Wilson, K.W.; Raj, B.; Smaragdis, P.; Divakaran, A. Speech denoising using nonnegative matrix factorization with priors. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NA, USA, 31 March–4 April 2008; pp. 4029–4032. [Google Scholar]
- Venkateswarlu, S.C.; Prasad, K.S.; Reddy, A.S. Improve Speech Enhancement Using Wiener Filtering. Glob. J. Comput. Sci. Technol. 2011, 11, 30–38. [Google Scholar]
- Stahl, V.; Fischer, A.; Bippus, R. Quantile based noise estimation for spectral subtraction and Wiener filtering. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Istanbul, Turkey, 5–9 June 2000; pp. 1875–1878. [Google Scholar]
- Hidayat, R.; Bejo, A.; Sumaryono, S.; Winursito, A. Denoising speech for mfcc feature extraction using wavelet transformation in speech recognition system. In Proceedings of the 2018 10th International Conference on Information Technology and Electrical Engineering (ICITEE), Bali, Indonesia, 24–26 July 2018; pp. 280–284. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 436–440. [Google Scholar]
- Feng, X.; Zhang, Y.; Glass, J. Speech feature denoising and dereverberation via deep autoencoders for noisy reverberant speech recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1759–1763. [Google Scholar]
- Xia, B.; Bao, C. Speech enhancement with weighted denoising auto-encoder. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 3444–3448. [Google Scholar]
- Tawara, N.; Kobayashi, T.; Ogawa, T. Multi-Channel Speech Enhancement Using Time-Domain Convolutional Denoising Autoencoder. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 86–90. [Google Scholar]
- Chuang, F.K.; Wang, S.S.; Hung, J.W.; Tsao, Y.; Fang, H.S. Speaker-Aware Deep Denoising Autoencoder with Embedded Speaker Identity for Speech Enhancement. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 3173–3177. [Google Scholar]
- Rethage, D.; Pons, J.; Serra, X. A wavenet for speech denoising. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5069–5073. [Google Scholar]
- Fu, S.W.; Tsao, Y.; Lu, X.; Kawai, H. Raw waveform-based speech enhancement by fully convolutional networks. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 6–12. [Google Scholar]
- Fu, S.W.; Tsao, Y.; Lu, X. SNR-Aware Convolutional Neural Network Modeling for Speech Enhancement. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3768–3772. [Google Scholar]
- Maas, A.; Le, Q.V.; O’Neil, T.M.; Vinyals, O.; Nguyen, P.; Ng, A.Y. Recurrent neural networks for noise reduction in robust ASR. In Proceedings of the Interspeech 2012, Portland, OH, USA, 9–13 September 2012; pp. 22–25. [Google Scholar]
- Zhao, H.; Zarar, S.; Tashev, I.; Lee, C.H. Convolutional-recurrent neural networks for speech enhancement. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2401–2405. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N. Tacotron: Towards end-to-end speech synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Brakel, P.; Stroob, T.D.; Schrauwen, B. Bidirectional truncated recurrent neural networks for efficient speech denoising. In Proceedings of the Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 2973–2977. [Google Scholar]
- Vanhoucke, V.; Senior, A.; Mao, M.Z. Improving the Speed of Neural Networks on CPUs. Deep Learning and Unsupervised Feature Learning Workshop, NIPS 2011, Granada, Spain, 12–17 December 2011; pp. 1–8. [Google Scholar]
- Drakopoulos, F.; Baby, D.; Verhulst, S. Real-time audio processing on a Raspberry Pi using deep neural networks. In Proceedings of the 23rd International Congress on Acoustics (ICA 2019), Aachen, Germany, 9–13 September 2019; pp. 2827–2834. [Google Scholar]
- Tashev, I.; Mirsamadi, S. DNN-based causal voice activity detector. In Proceedings of the Information Theory and Applications Workshop, La jolla, USA, 31 January–5 February 2016. [Google Scholar]
- Wang, K.C. Robust Audio Content Classification Using Hybrid-Based SMD and Entropy-Based VAD. Entropy 2020, 22, 183. [Google Scholar] [CrossRef] [Green Version]
- Kalia, A.; Sharma, S.; Pandey, S.K.; Jadoun, V.K.; Das, M. Comparative Analysis of Speaker Recognition System Based on Voice Activity Detection Technique, MFCC and PLP Features. In Intelligent Computing Techniques for Smart Energy Systems; Springer: Singapore, 2020; pp. 781–787. [Google Scholar]
- Kim, S.K.; Kang, S.I.; Park, Y.J.; Lee, S.; Lee, S. Power spectral deviation-based voice activity detection incorporating teager energy for speech enhancement. Symmetry 2016, 8, 58. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.W.; Kim, H.K. Multi-Task Learning U-Net for Single-Channel Speech Enhancement and Mask-Based Voice Activity Detection. Appl. Sci. 2020, 10, 3230. [Google Scholar] [CrossRef]
- Johny, E.R.; Vasuki, P.; Mohanalin, J. Voice activity detection using fuzzy entropy and support vector machine. Entropy 2016, 18, 298. [Google Scholar] [CrossRef] [Green Version]
- Petsatodis, T.; Boukis, C.; Talantzis, F.; Tan, Z.H.; Prasad, R. Convex combination of multiple statistical models with application to VAD. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2314–2327. [Google Scholar] [CrossRef]
- Sakhnov, K.; Verteletskaya, E.; Simak, B. Approach for Energy-Based Voice Detector with Adaptive Scaling Factor. IAENG Int. J. Comput. Sci. 2009, 36, 4. [Google Scholar]
- Górriz, J.M.; Ramírez, J.; Segura, J.C.; Puntonet, C.G.; González, J.J. Noise subspace fuzzy c-means clustering for robust speech recognition. In Proceedings of the International Conference on Computational Science and Its Applications, Glasgow, UK, 8–11 May 2006; pp. 772–779. [Google Scholar]
- Ramírez, J.; Segura, J.C.; Benítez, C.; García, L.; Rubio, A. Statistical voice activity detection using a multiple observation likelihood ratio test. IEEE Signal Process. Lett. 2005, 12, 689–692. [Google Scholar] [CrossRef]
- Petsatodis, T.; Talantzis, F.; Boukis, C.; Tan, Z.H.; Prasad, R. Multi-sensor voice activity detection based on multiple observation hypothesis testing. In Proceedings of the Interspeech 2011, Florence, Italy, 28–31 August 2011; pp. 2633–2636. [Google Scholar]
- Tan, Z.H.; Dehak, N. rVAD: An unsupervised segment-based robust voice activity detection method. Comput. Speech Lang. 2020, 59, 1–21. [Google Scholar] [CrossRef]
- Ferrer, L.; Graciarena, M.; Mitra, V. A phonetically aware system for speech activity detection. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5710–5714. [Google Scholar]
- Cavallaro, A.; Beritelli, F.; Casale, S. A fuzzy logic-based speech detection algorithm for communications in noisy environments. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Seattle, USA, 12–15 May 1998; pp. 565–568. [Google Scholar]
- Ashihara, K. Hearing thresholds for pure tones above 16 kHz. J. Acoust. Soc. Am. 2007, 122, EL52–EL57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shannon, C.E. A Mathematical Theory of Communication. ACM Sigmobile Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Jaiswal, R.; Hines, A. The Sound of Silence: How Traditional and Deep Learning Based Voice Activity Detection Influences Speech Quality Monitoring. In Proceedings of the 6th Irish Conference on Artificial Intelligence and Cognitive Science, Dublin, Ireland, 6–7 December 2018; pp. 174–185. [Google Scholar]
- Höppner, F.; Klawonn, F.; Kruse, R.; Runkler, T. Fuzzy Cluster Analysis: Methods for Classification, Data Analysis and Image Recognition; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Beliakov, G.; King, M. Density based fuzzy c-means clustering of non-convex patterns. Eur. J. Oper. Res. 2006, 173, 717–728. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Tang, Z.M.; Li, Y.P.; Luo, Y. A hierarchical framework approach for voice activity detection and speech enhancement. Sci. World J. 2014, 2014, 723643. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rabiner, L.; Sambur, M.; Schmidt, C. Applications of a nonlinear smoothing algorithm to speech processing. IEEE Trans. Acoust. Speech, Signal Process. 1975, 23, 552–557. [Google Scholar] [CrossRef]
- Janbakhshi, P.; Kodrasi, I.; Bourlard, H. Pathological speech intelligibility assessment based on the short-time objective intelligibility measure. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6405–6409. [Google Scholar]
- Lindner, T.; Wyrwał, D.; Białek, M.; Nowak, P. Face recognition system based on a single-board computer. In Proceedings of the 2020 International Conference Mechatronic Systems and Materials (MSM), Bialystok, Poland, 1–3 July 2020; pp. 1–6. [Google Scholar]
- Niu, W.; Ma, X.; Lin, S.; Wang, S.; Qian, X.; Lin, X.; Ren, B. Patdnn: Achieving real-time DNN execution on mobile devices with pattern-based weight pruning. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 907–922. [Google Scholar]
- Suja, P.; Tripathi, S. Real-time emotion recognition from facial images using Raspberry Pi II. In Proceedings of the 2016 3rd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 11–12 February 2016; pp. 666–670. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Data Sets | Number of Data Sets | Avg. of SNR (dB) | Avg. of (Min∼Max) Signal Length (Seconds) | Portion of Speech Segments (%) |
|---|---|---|---|---|
| Low SNR group | 200 | 0.915 | 2.469 (1.367∼9.768) | 46.05 |
| Medium SNR group | 227 | 6.147 | 2.548 (1.320∼7.184) | 46.04 |
| High SNR group | 397 | 13.555 | 2.518 (1.237∼8.509) | 46.70 |
| Total data set | 824 | 8.446 | 2.514 (1.237∼9.768) | 46.34 |
| Speech Segment Detection Methods | Energy-Based Filtering | Entropy-Based Filtering | Fuzzy Clustering | Energy-Based Filtering with Fuzzy Clustering | Entropy-Based Filtering with Fuzzy Clustering | |
|---|---|---|---|---|---|---|
| Low SNR Group | Threshold(%)/λ | 0.8 | 0.5 | 40 | 50 | 80 |
| Recall | 0.779 | 0.839 | 0.876 | 0.864 | 0.891 | |
| Precision | 0.758 | 0.652 | 0.637 | 0.642 | 0.626 | |
| F1 score | 0.751 | 0.719 | 0.727 | 0.726 | 0.725 | |
| Medium SNR Group | Threshold(%)/λ | 0.9 | 0.5 | 50 | 60 | 90 |
| Recall | 0.966 | 0.829 | 0.866 | 0.869 | 0.871 | |
| Precision | 0.705 | 0.814 | 0.790 | 0.786 | 0.786 | |
| F1 score | 0.809 | 0.812 | 0.817 | 0.816 | 0.817 | |
| High SNR Group | Threshold(%)/λ | 0.9 | 0.6 | 20 | 40 | 70 |
| Recall | 0.943 | 0.932 | 0.945 | 0.923 | 0.943 | |
| Precision | 0.933 | 0.914 | 0.902 | 0.919 | 0.902 | |
| F1 score | 0.935 | 0.920 | 0.919 | 0.917 | 0.918 | |
| Total Group | Threshold(%)/λ | 0.9 | 0.6 | 30 | 50 | 80 |
| Recall | 0.959 | 0.941 | 0.911 | 0.890 | 0.910 | |
| Precision | 0.773 | 0.773 | 0.806 | 0.817 | 0.803 | |
| F1 score | 0.839 | 0.834 | 0.844 | 0.842 | 0.843 | |
| Wavenet-Based Denoising | Energy-Based Filtering | Entropy-Based Filtering | Fuzzy-Based Clustering | Energy-Based Filtering with Fuzzy Clustering | Entropy-Based Filtering with Fuzzy Clustering | |
|---|---|---|---|---|---|---|
| Denoising Time (seconds) | 3867 | 2318 | 1904 | 1996 | 1938 | 2000 |
| Signal Length (seconds) | 2072.04 | 1234.37 | 945.50 | 1092.16 | 1044.86 | 1094.29 |
| Denoising Time/Original Signal Length | 1.866 | 1.12 | 0.919 | 0.963 | 0.935 | 0.965 |
| Denoising Methods | Noisy | Wavenet-Based Denoising [13] | Energy-Based Filtering | Entropy-Based Filtering | Fuzzy Clustering | Energy-Based Filtering with Fuzzy Clustering | Entropy-Based Filtering with Fuzzy Clustering | |
|---|---|---|---|---|---|---|---|---|
| Low SNR Group | SNR | 0.915 | 14.552 | 5.408 | 7.554 | 7.669 | 7.639 | 8.349 |
| STOI | 0.868 | 0.864 | 0.848 | 0.846 | 0.845 | 0.843 | 0.846 | |
| PESQ | 1.413 | 1.551 | 1.290 | 1.225 | 1.272 | 1.229 | 1.223 | |
| Medium SNR Group | SNR | 6.147 | 17.311 | 12.213 | 10.299 | 10.570 | 10.694 | 10.749 |
| STOI | 0.913 | 0.895 | 0.898 | 0.900 | 0.901 | 0.898 | 0.898 | |
| PESQ | 1.757 | 1.824 | 1.515 | 1.531 | 1.577 | 1.520 | 1.519 | |
| High SNR Group | SNR | 13.555 | 19.639 | 15.504 | 15.742 | 15.811 | 15.567 | 15.820 |
| STOI | 0.951 | 0.914 | 0.943 | 0.942 | 0.942 | 0.942 | 0.941 | |
| PESQ | 2.373 | 2.140 | 2.283 | 2.202 | 2.229 | 2.238 | 2.200 | |
| Total Group | SNR | 6.872 | 17.167 | 12.127 | ||||
| STOI | 0.910 | 0.891 | 0.897 | |||||
| PESQ | 1.847 | 1.838 | 1.716 | |||||
| Denoising Methods | Noisy | Wavenet-Based Denoising [13] | Energy-Based Filtering | Entropy-Based Filtering | Fuzzy Clustering | Energy-Based Filtering with Fuzzy Clustering | Entropy-Based Filtering with Fuzzy Clustering | |
|---|---|---|---|---|---|---|---|---|
| Low SNR Group | SNR | 1.310 | 15.003 | 14.758 | 14.846 | 14.863 | 14.803 | 14.872 |
| STOI | 0.911 | 0.926 | 0.927 | 0.942 | 0.941 | 0.942 | 0.941 | |
| PESQ | 1.459 | 1.620 | 1.826 | 1.659 | 1.642 | 1.643 | 1.635 | |
| Medium SNR Group | SNR | 7.940 | 19.128 | 18.111 | 18.228 | 18.189 | 18.152 | 18.183 |
| STOI | 0.960 | 0.970 | 0.973 | 0.951 | 0.968 | 0.967 | 0.963 | |
| PESQ | 2.043 | 2.432 | 2.172 | 2.448 | 2.368 | 2.364 | 2.371 | |
| High SNR Group | SNR | 16.490 | 21.919 | 21.047 | 21.028 | 20.997 | 20.966 | 20.991 |
| STOI | 0.985 | 0.984 | 0.982 | 0.980 | 0.982 | 0.979 | 0.985 | |
| PESQ | 3.078 | 3.480 | 3.446 | 3.354 | 3.333 | 3.390 | 3.318 | |
| Total Group | SNR | 8.580 | 18.703 | 18.049 | ||||
| STOI | 0.952 | 0.959 | 0.967 | |||||
| PESQ | 2.194 | 2.511 | 2.573 | |||||
| Denoising Methods | Noisy | Wavenet-Based Denoising [13] | Energy-Based Filtering | Entropy-Based Filtering | Fuzzy Clustering | Energy-Based Filtering with Fuzzy Clustering | Entropy-Based Filtering with Fuzzy Clustering | |
|---|---|---|---|---|---|---|---|---|
| Low SNR Group | SNR | 0.915 | 14.552 | 14.758 | 14.846 | 14.863 | 14.803 | 14.872 |
| STOI | 0.868 | 0.864 | 0.927 | 0.942 | 0.941 | 0.942 | 0.941 | |
| PESQ | 1.413 | 1.551 | 1.826 | 1.659 | 1.642 | 1.643 | 1.635 | |
| Medium SNR Group | SNR | 6.147 | 17.311 | 18.111 | 18.228 | 18.189 | 18.152 | 18.183 |
| STOI | 0.913 | 0.895 | 0.973 | 0.951 | 0.968 | 0.967 | 0.963 | |
| PESQ | 1.757 | 1.824 | 2.172 | 2.448 | 2.368 | 2.364 | 2.371 | |
| High SNR Group | SNR | 13.555 | 19.639 | 21.047 | 21.028 | 20.997 | 20.966 | 20.991 |
| STOI | 0.951 | 0.914 | 0.982 | 0.980 | 0.982 | 0.979 | 0.985 | |
| PESQ | 2.373 | 2.140 | 3.446 | 3.354 | 3.333 | 3.390 | 3.318 | |
| Total Group | SNR | 6.872 | 17.167 | 18.049 | ||||
| STOI | 0.910 | 0.891 | 0.967 | |||||
| PESQ | 1.847 | 1.838 | 2.573 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.-J.; Kwon, H.-Y. A Preprocessing Strategy for Denoising of Speech Data Based on Speech Segment Detection. Appl. Sci. 2020, 10, 7385. https://doi.org/10.3390/app10207385
Lee S-J, Kwon H-Y. A Preprocessing Strategy for Denoising of Speech Data Based on Speech Segment Detection. Applied Sciences. 2020; 10(20):7385. https://doi.org/10.3390/app10207385
Chicago/Turabian StyleLee, Seung-Jun, and Hyuk-Yoon Kwon. 2020. "A Preprocessing Strategy for Denoising of Speech Data Based on Speech Segment Detection" Applied Sciences 10, no. 20: 7385. https://doi.org/10.3390/app10207385