Vision-Based Distance Measurement in Advanced Driving Assistance Systems


Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
3. Depth Map Estimation
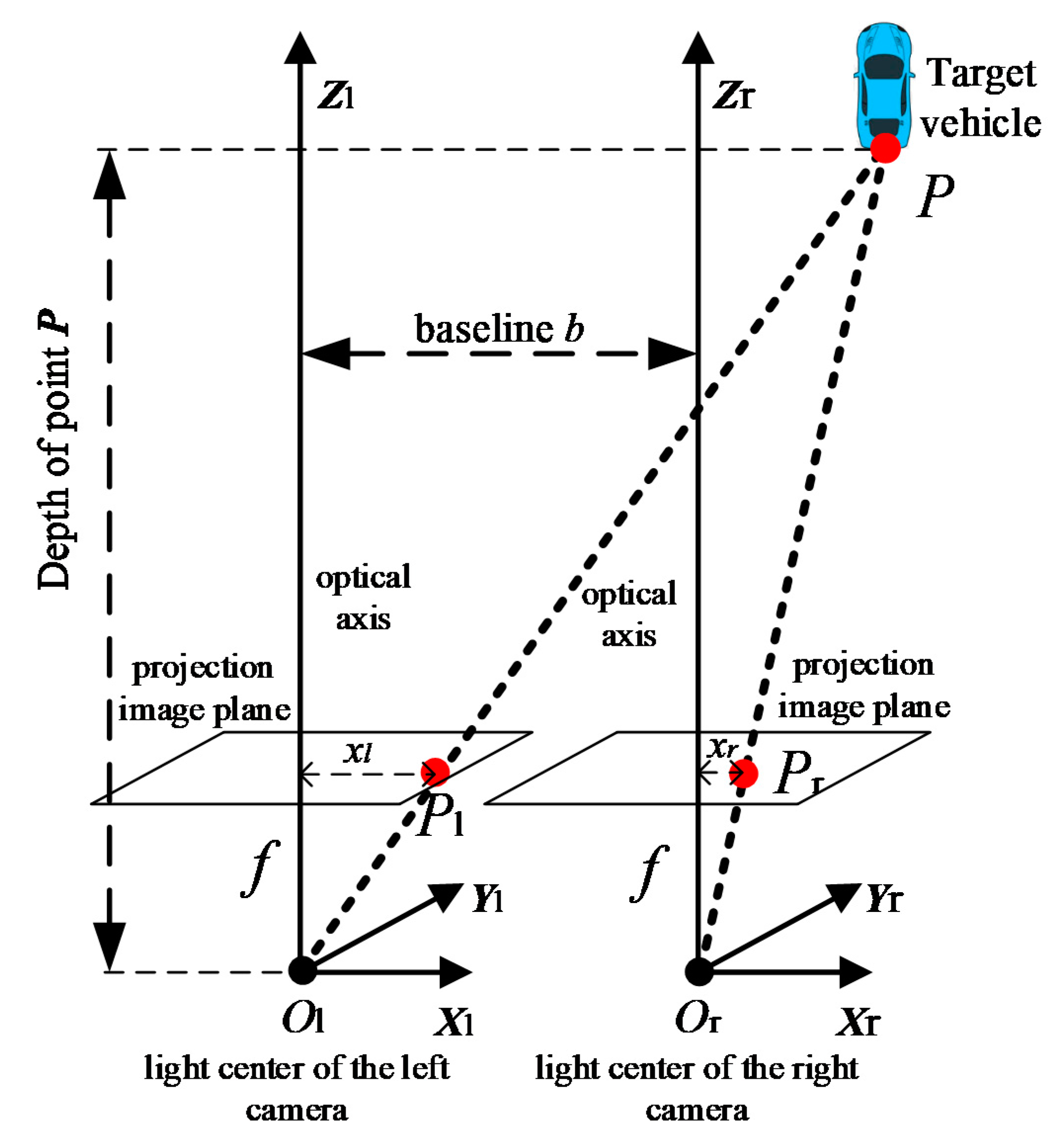
3.1. Relationship between Disparity and Depth
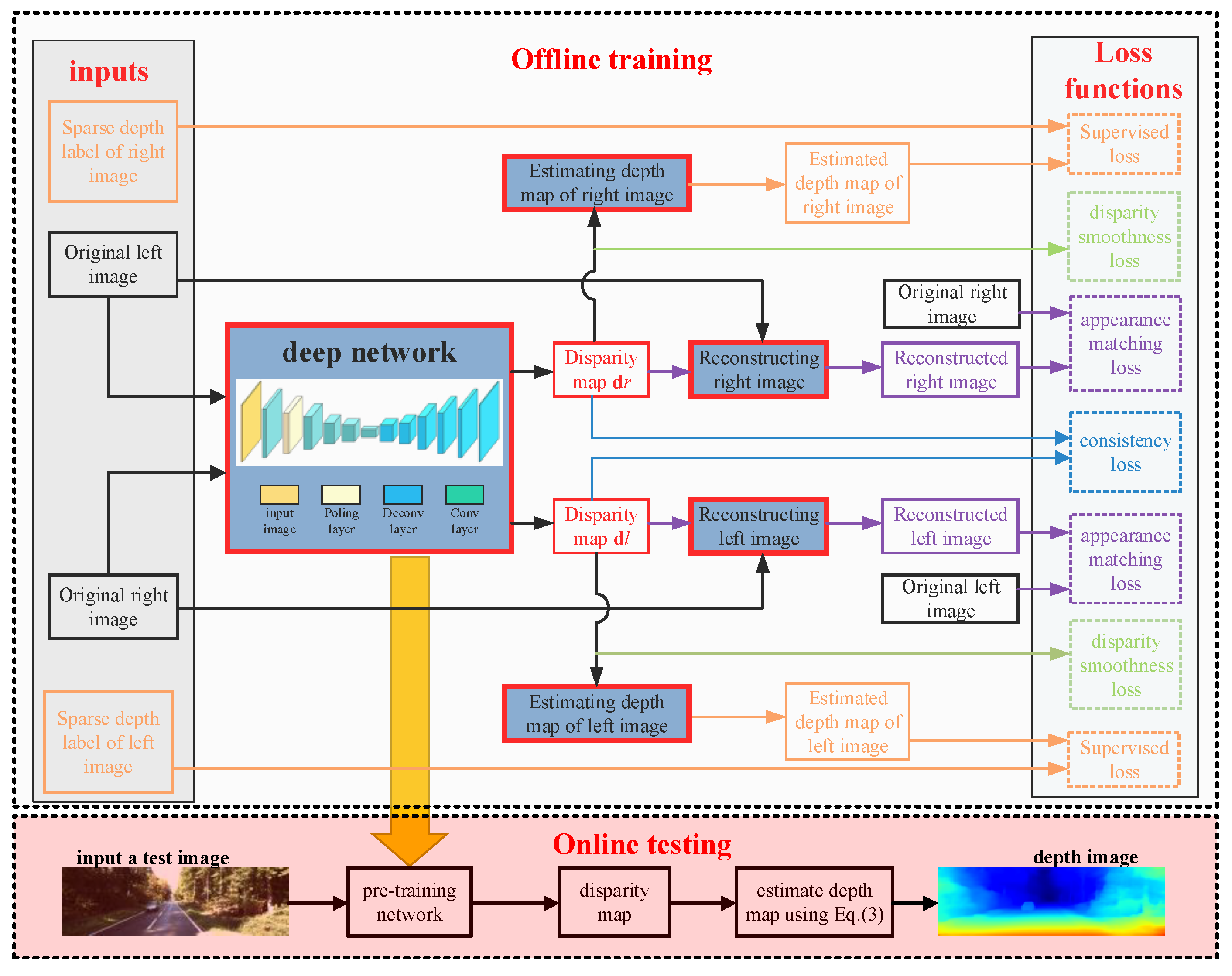
3.2. Semi-Supervised Learning Network for Depth Map Estimation
3.2.1. Loss Functions
- Appearance Matching Loss
- Disparity Smoothness Loss
- Left–Right Disparity Consistency Loss
- Supervised Loss
- Loss Function for Depth Estimation
3.2.2. Depth Map Estimation
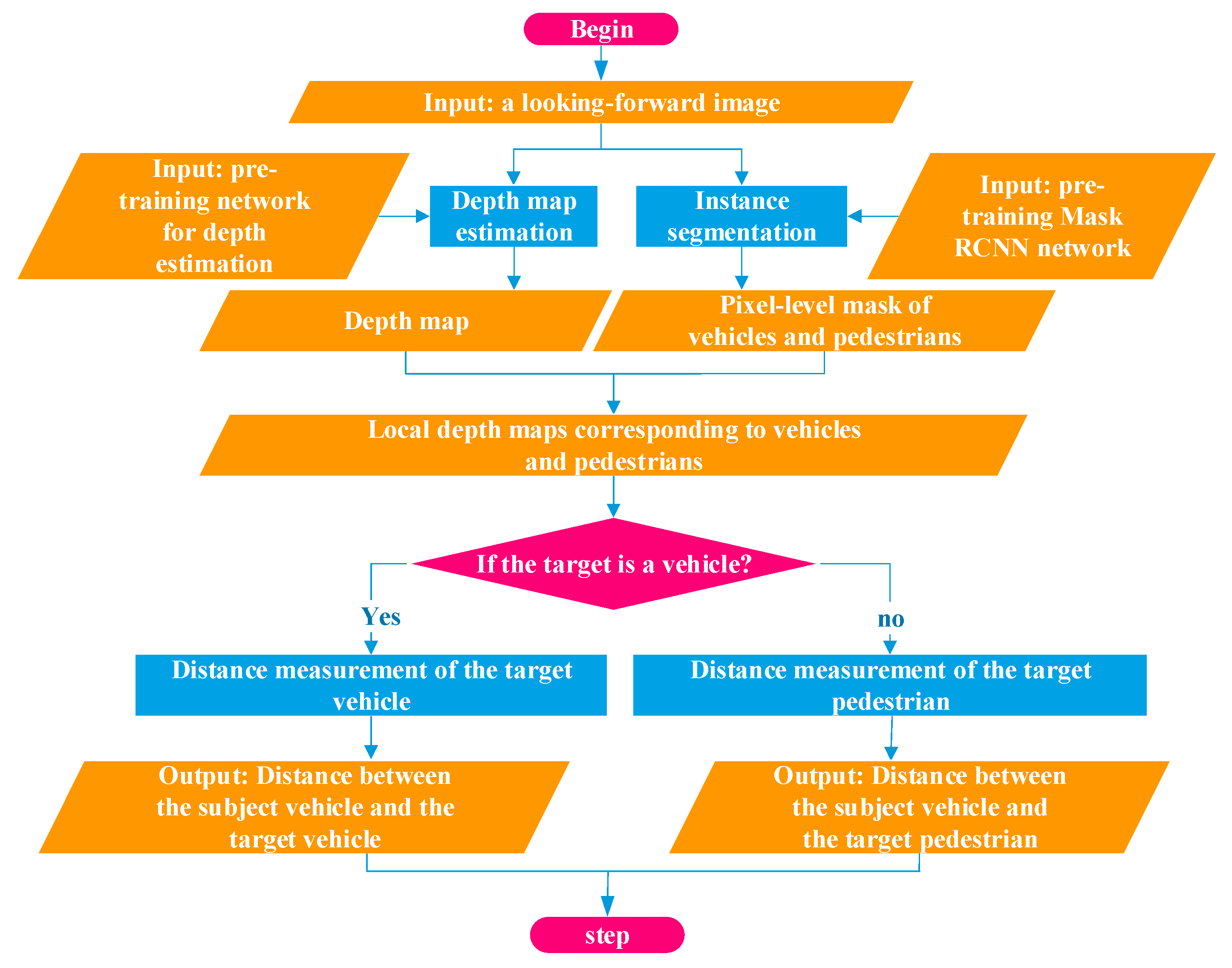
4. Distance Measurement between the Target and the Subject Vehicle
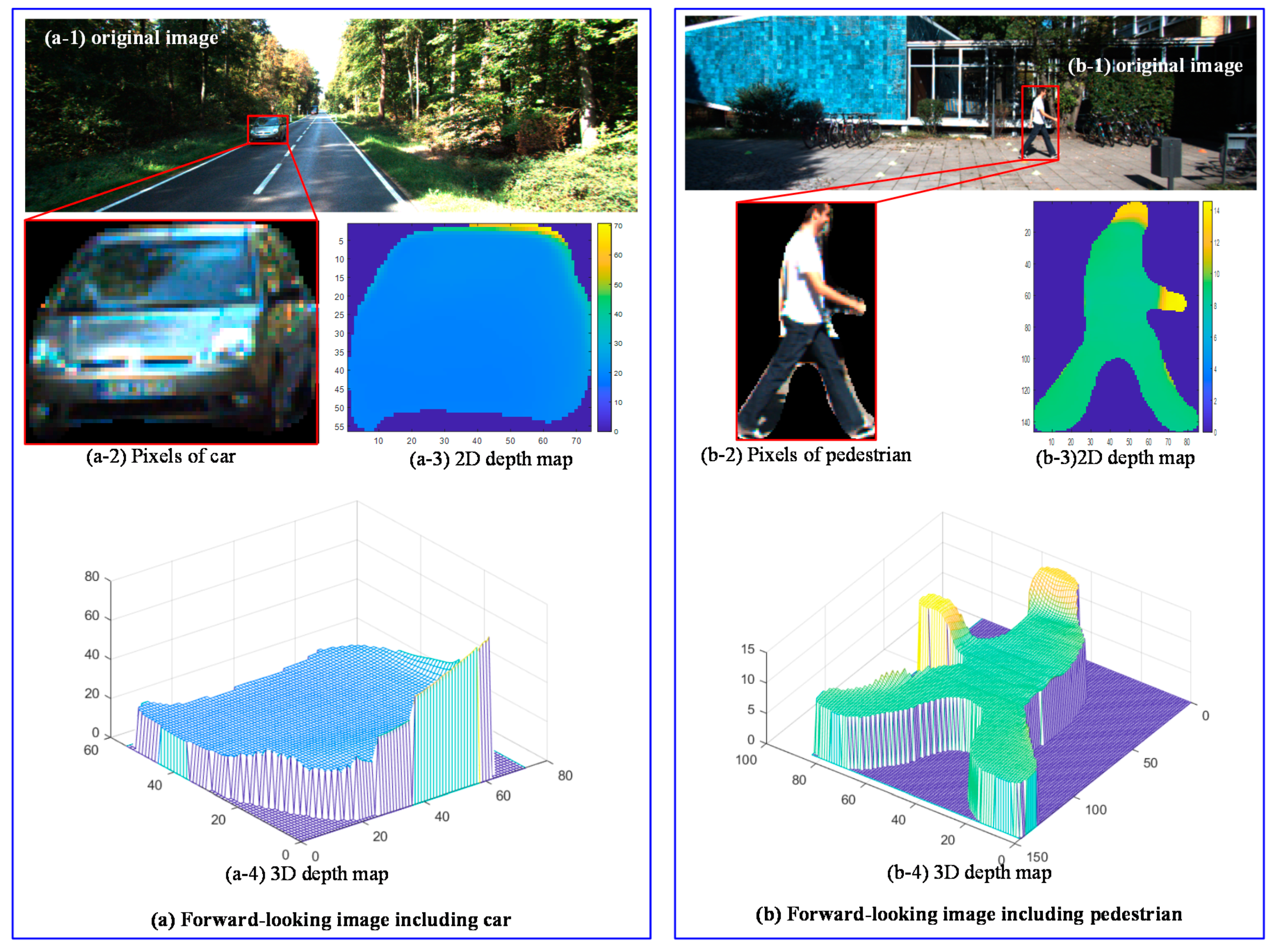
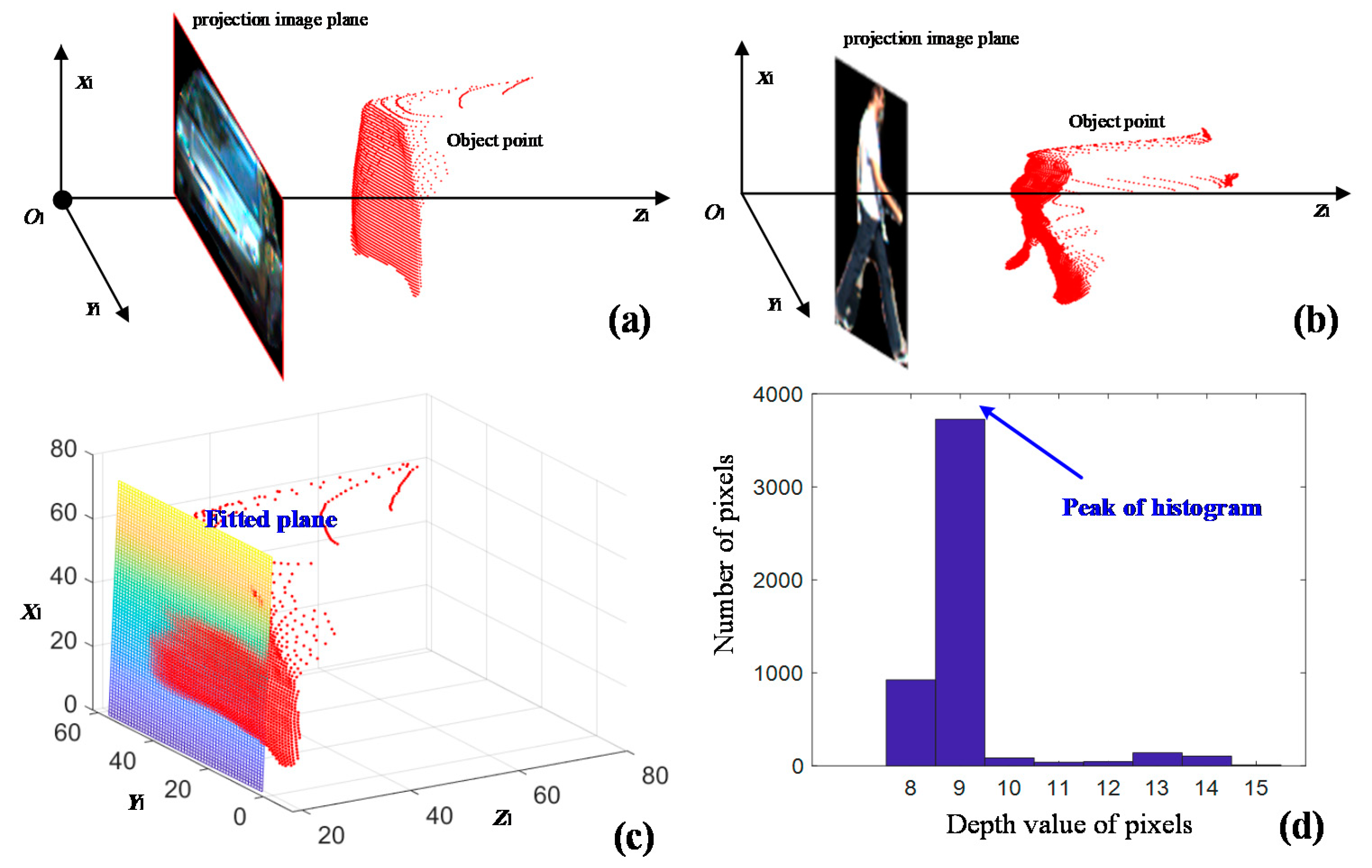
4.1. Pixel-Level Depth Map of the Target
4.2. Target Distance Measurement
4.2.1. Distance Measurement of the Target Vehicle
4.2.2. Distance Measurement of the Target Pedestrian
5. Proposed Method Implementation
6. Experiments and Results
6.1. Implementation Details
6.2. Performance Comparison of Depth Estimation
6.2.1. Quantitative Comparison with the Other Four Methods
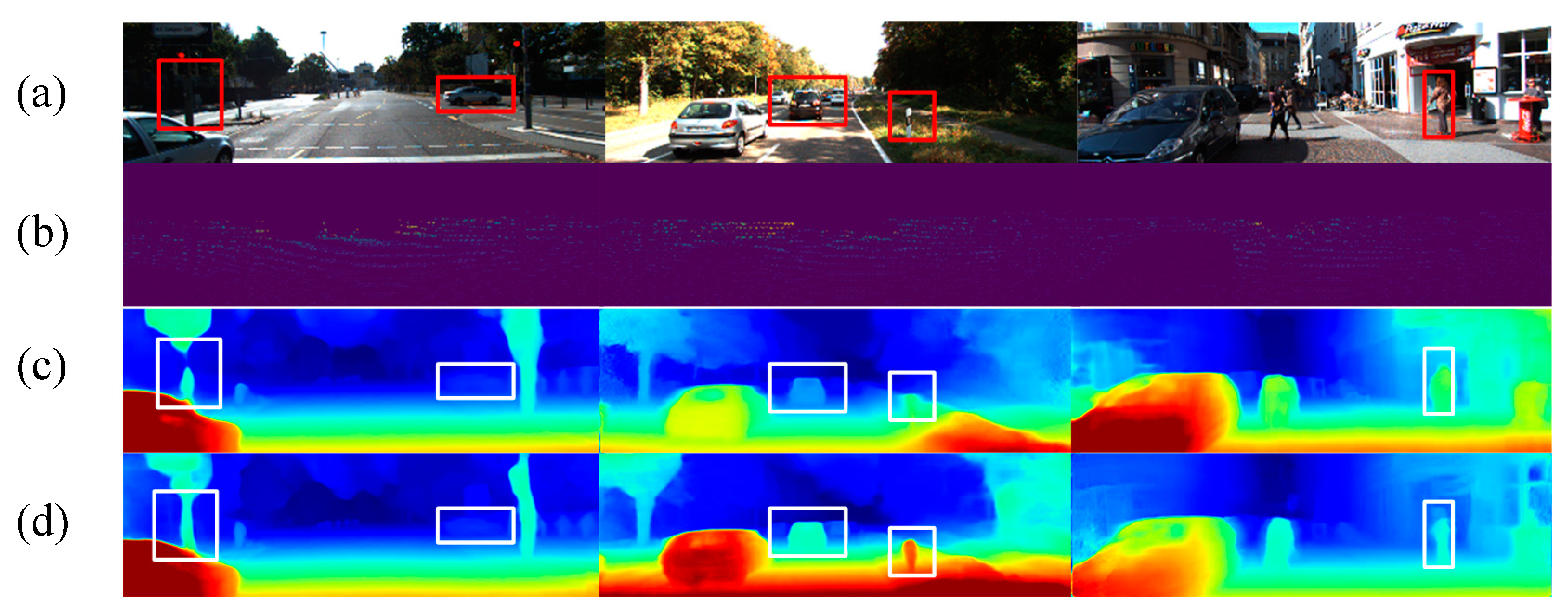
6.2.2. Ablation Study of Depth Map Estimation
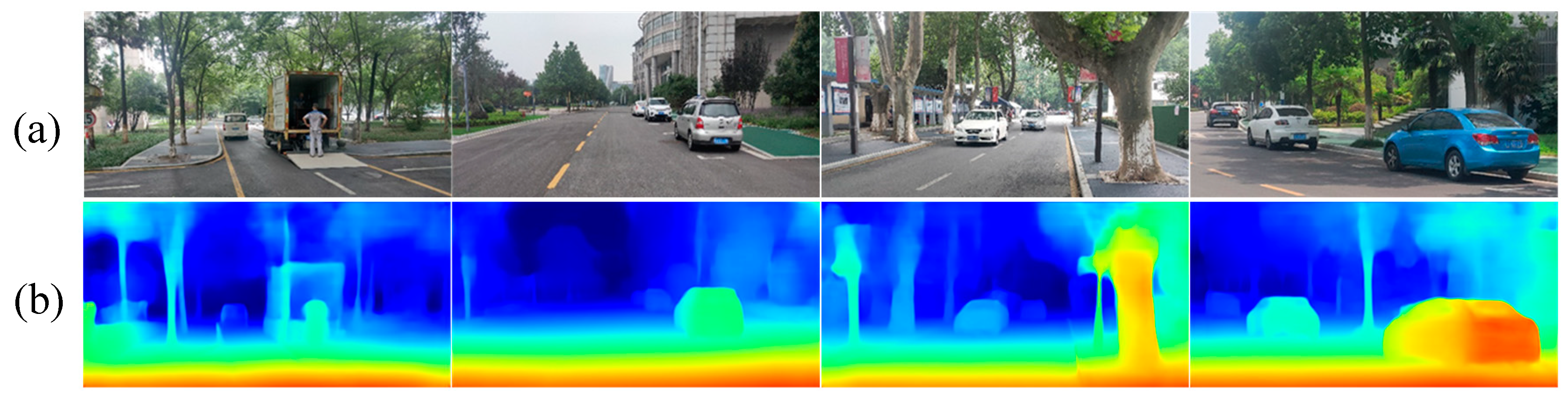
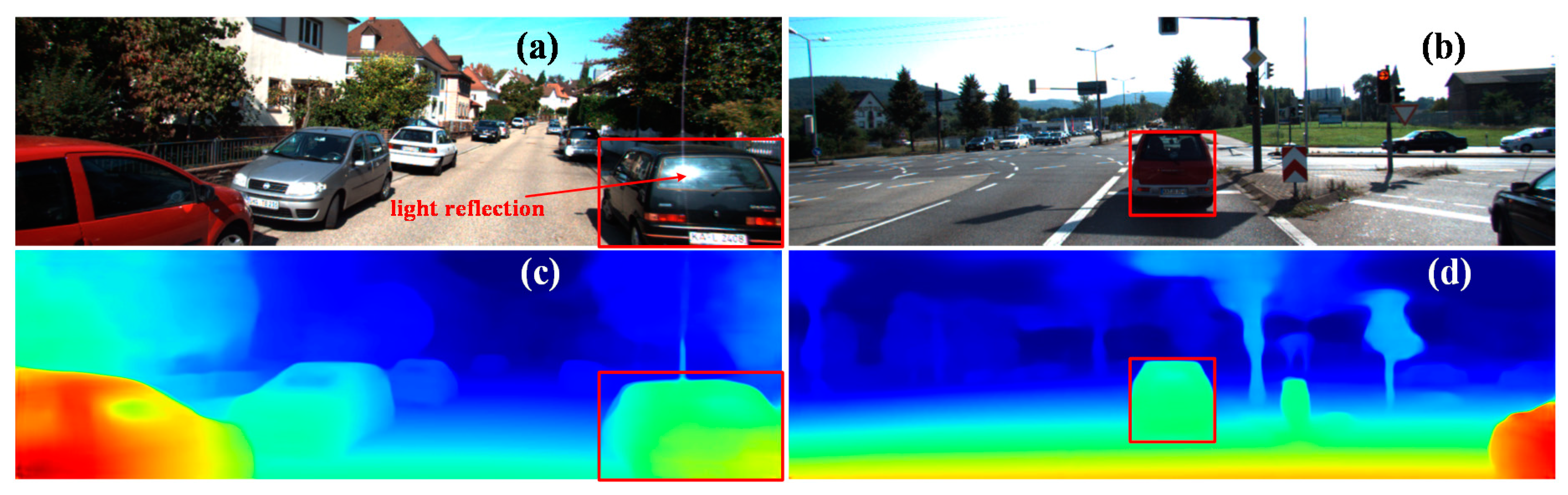
6.2.3. Depth Map Estimation in Real Road Scenarios
6.3. Distance Measurement of the Target
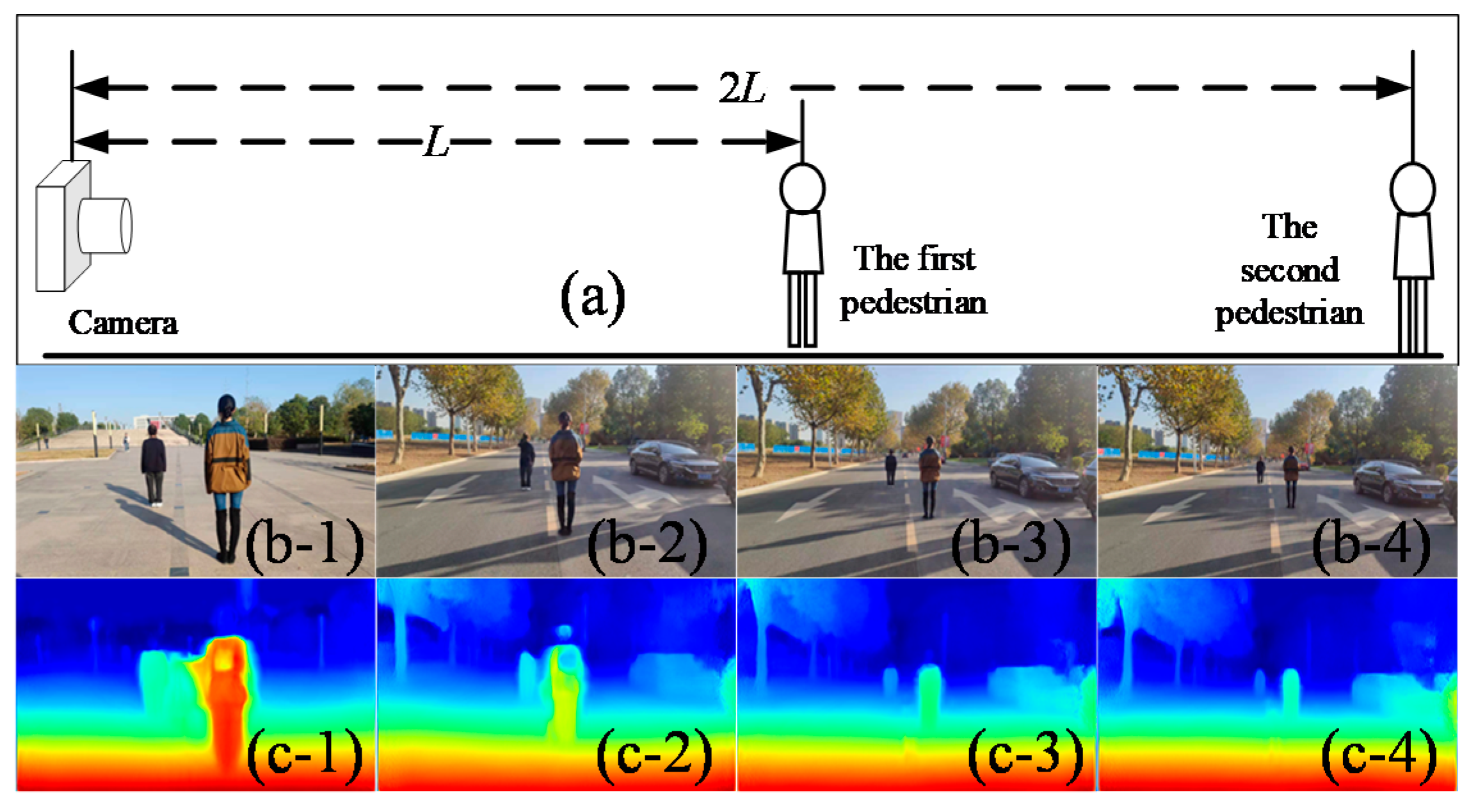
6.3.1. Distance Measurement of the Pedestrian
6.3.2. Distance Measurement of the Vehicle
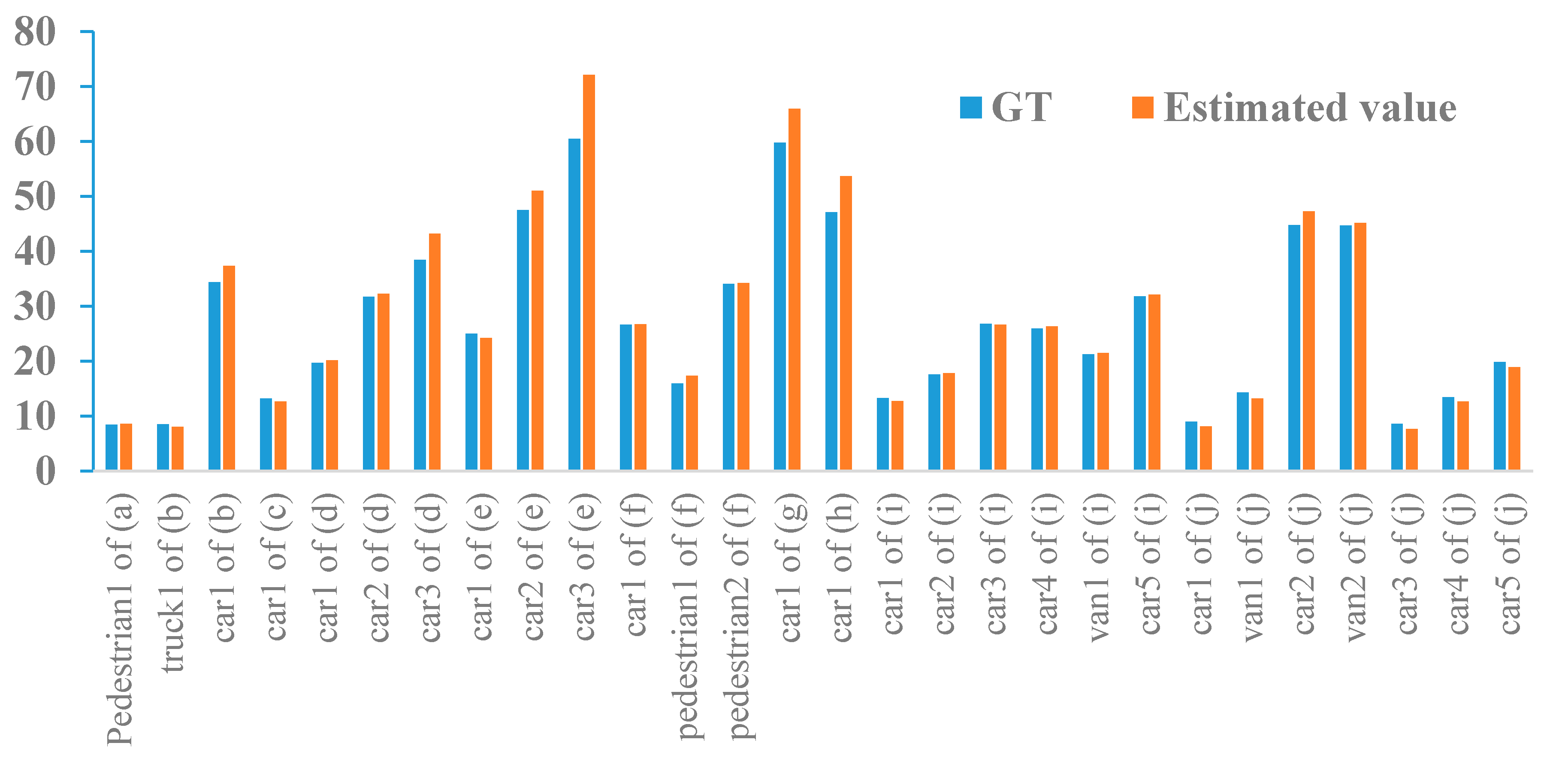
6.3.3. Distance Measurement on the KITTI Dataset
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kukkala, V.K.; Tunnell, J.; Pasricha, S. Advanced Driver-Assistance Systems. IEEE Consum. Electron. Mag. 2018, 7, 18–25. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Zhe, T.; Huang, L.; Wu, Q.; Zhang, J.; Pei, C.; Li, L. Inter-Vehicle Distance Estimation Method Based on Monocular Vision Using 3D Detection. IEEE Trans. Veh. Technol. 2020, 69, 4907–4919. [Google Scholar] [CrossRef]
- Huang, L.; Zhe, T.; Wu, J.; Wu, Q.; Pei, C.; Chen, D. Robust Inter-Vehicle Distance Estimation Method Based on Monocular Vision. IEEE Access 2019, 7, 46059–46070. [Google Scholar] [CrossRef]
- Raj, T.; Hashim, F.H.; Huddin, A.B. A Survey on LiDAR Scanning Mechanisms. Electronics 2020, 9, 741. [Google Scholar] [CrossRef]
- Ranft, B.; Stiller, C. The role of machine vision for intelligent vehicles. IEEE Trans. Intell. Veh. 2016, 1, 8–19. [Google Scholar] [CrossRef]
- Velez, G.; Otaegui, O. Embedding vision-based advanced driver assistance systems: A survey. IET Intell. Transp. Syst. 2017, 11, 103–112. [Google Scholar] [CrossRef]
- Liu, Z.; Lu, D.; Qian, W. Vision-based inter-vehicle distance estimation for driver alarm system. IET Intell. Transp. Syst. 2019, 13, 927–932. [Google Scholar] [CrossRef]
- Tram, V.T.B.; Yoo, M. Vehicle-to-vehicle distance estimation using a low-resolution camera based on visible light communications. IEEE Access 2018, 6, 4521–4527. [Google Scholar] [CrossRef]
- Ding, M.; Zhang, X.; Chen, W.; Wei, L.; Cao, Y. Thermal Infrared Pedestrian Tracking via fusion of features in Driving Assistance System of Intelligent Vehicles. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 6089–6103. [Google Scholar] [CrossRef]
- Liu, L.; Fang, C.; Chen, S. A novel distance estimation method leading a forward collision avoidance assist system for vehicles on highways. IEEE Trans. Intell. Transp. Syst. 2017, 18, 937–949. [Google Scholar] [CrossRef]
- Kim, G.; Cho, J.S. Vision-based vehicle detection and inter-vehicle distance estimation. Opt. Rev. 2012, 19, 388–393. [Google Scholar] [CrossRef]
- Wongsaree, P.; Sinchai, S.; Wardkein, P.; Koseeyaporn, J. Distance detection technique using enhancing inverse perspective mapping. In Proceedings of the 3rd International Conference on Computer and Communication Systems 2018, Nagoya, Japan, 27–30 April 2018; pp. 217–221. [Google Scholar]
- Gökçe, F.; Üçoluk, G.; Sahin, E.; Kalkan, S. Vision-based detection and distance estimation of micro unmanned aerial vehicles. Sensors 2015, 15, 23805–23846. [Google Scholar] [CrossRef]
- Dellaert, F.; Seitz, S.M.; Thorpe, C.E.; Sebastian, T. Structure from motion without correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 15 June 2000. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent Advances in Deep Learning for Object Detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Bhoi, A. Monocular depth estimation: A survey. arXiv 2019, arXiv:1901.09402. [Google Scholar]
- Huang, J.; Wang, C.; Liu, Y. The Progress of Monocular Depth Estimation Technology. J. Image Graph. 2019, 24, 2081–2097. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network 2014. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Kuching, Malaysia, 3–6 November 2014; Volume 2, pp. 2366–2374. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Li, B.; Shen, C.H.; Dai, Y.C. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Garg, R.; Vijay, K.B.G.; Gustavo, C.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. In Proceedings of the European Conference on Computer Vision 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 740–756. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6602–6611. [Google Scholar]
- Kuznietsov, Y.; Stückler, J.; Leibe, B. Semi-Supervised Deep Learning for Monocular Depth Map Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6647–6655. [Google Scholar]
- Ji, R.; Li, K.; Wang, Y.; Sun, X.; Guo, F.; Guo, X.; Wu, Y.; Huang, F.; Luo, J. Semi-supervised adversarial monocular depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2410–2422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Chen, Y.; Fan, Z.; Chen, Z. Measuring the absolute distance of a front vehicle from an in-car camera based on monocular vision and instance segmentation. J. Electron. Imaging 2018, 27, 043019. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.Y.; Ding, M. Unsupervised monocular depth estimation with scale unification. In Proceedings of the International Symposium on Computational Intelligence and Design, Hangzhou, China, 14–15 December 2019; pp. 284–287. [Google Scholar]
- Zhou, T.H.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | Abs_Rel | RMSE | δ < 1.25 | δ < 1.252 | δ < 1.253 |
|---|---|---|---|---|---|---|
| Eigen et al. | Supervised | 0.203 | 6.307 | 0.702 | 0.890 | 0.958 |
| Zhou et al. | Unsupervised | 0.183 | 6.709 | 0.734 | 0.902 | 0.959 |
| Godard et al. | Unsupervised | 0.128 | 5.547 | 0.815 | 0.922 | 0.968 |
| Kuznietsov et al. | Semi-supervised | 0.076 | 3.842 | 0.903 | 0.948 | 0.975 |
| Ours | Semi-supervised | 0.071 | 3.740 | 0.934 | 0.979 | 0.992 |
| L (Ground Truth) | Average Depth Value | Our Method | ||
|---|---|---|---|---|
| The First Pedestrian | The Second Pedestrian | The First Pedestrian | The Second Pedestrian | |
| 2.82 | 2.96 | 5.82 | 2.67 | 5.56 |
| 3.93 | 3.76 | 7.48 | 3.97 | 7.92 |
| 5.87 | 5.44 | 12.07 | 5.82 | 11.34 |
| 7.86 | 7.51 | 15.72 | 8.13 | 16.02 |
| Average error | 0.298 | 0.267 | 0.158 | 0.167 |
| 0.283 | 0.162 | |||
| Distance (Ground Truth) | Average Depth Value | Method of Depth Average | Ours | |||
|---|---|---|---|---|---|---|
| Car | SUV | Car | SUV | Car | SUV | |
| 2.5 m | 4.7 | 2.9 | 5.4 | 2.7 | 2.9 | 2.4 |
| 5 m | 7.6 | 6.8 | 5.8 | 5.3 | 5.0 | 5.0 |
| 7.5 m | 11.1 | 8.2 | 7.6 | 7.1 | 7.3 | 7.4 |
| 10 m | 10.6 | 8.8 | 8.5 | 7.7 | 9.2 | 9.3 |
| 12.5 m | 14.3 | 9.9 | 10.4 | 9.5 | 10.8 | 9.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, M.; Zhang, Z.; Jiang, X.; Cao, Y. Vision-Based Distance Measurement in Advanced Driving Assistance Systems. Appl. Sci. 2020, 10, 7276. https://doi.org/10.3390/app10207276
Ding M, Zhang Z, Jiang X, Cao Y. Vision-Based Distance Measurement in Advanced Driving Assistance Systems. Applied Sciences. 2020; 10(20):7276. https://doi.org/10.3390/app10207276
Chicago/Turabian StyleDing, Meng, Zhenzhen Zhang, Xinyan Jiang, and Yunfeng Cao. 2020. "Vision-Based Distance Measurement in Advanced Driving Assistance Systems" Applied Sciences 10, no. 20: 7276. https://doi.org/10.3390/app10207276