Audio-Visual Tensor Fusion Network for Piano Player Posture Classification

Abstract
:1. Introduction
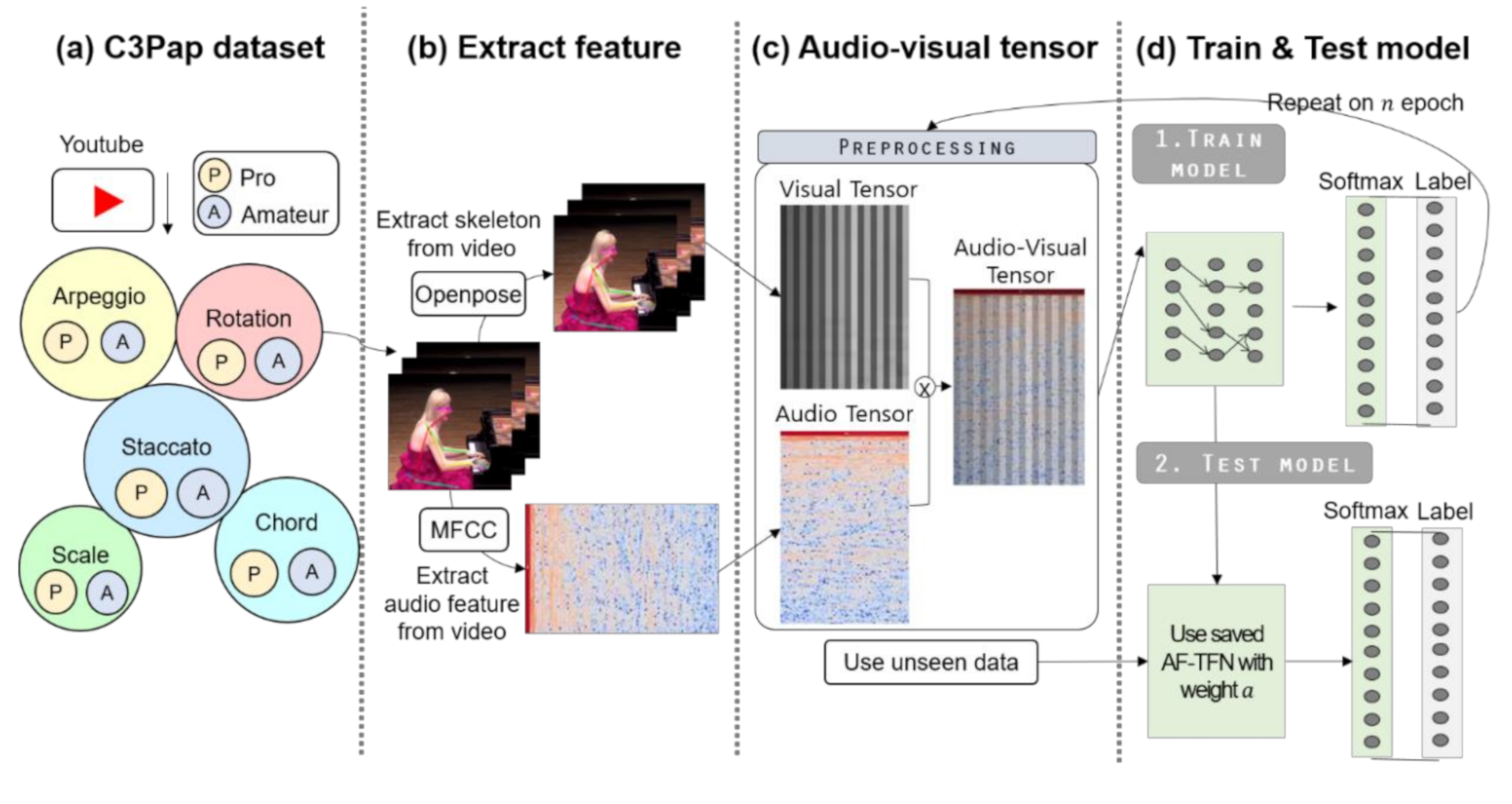
- We first propose a dataset called C3Pap (Classic Piano Performance Postures of Amateur and Professionals). For this study, we collected videos of both professional and amateur pianists from the YouTube platform. The main advantage of the proposed dataset is that we collected actual performance videos in diverse environments, unlike existing datasets that do not consider various situations of the pianist.
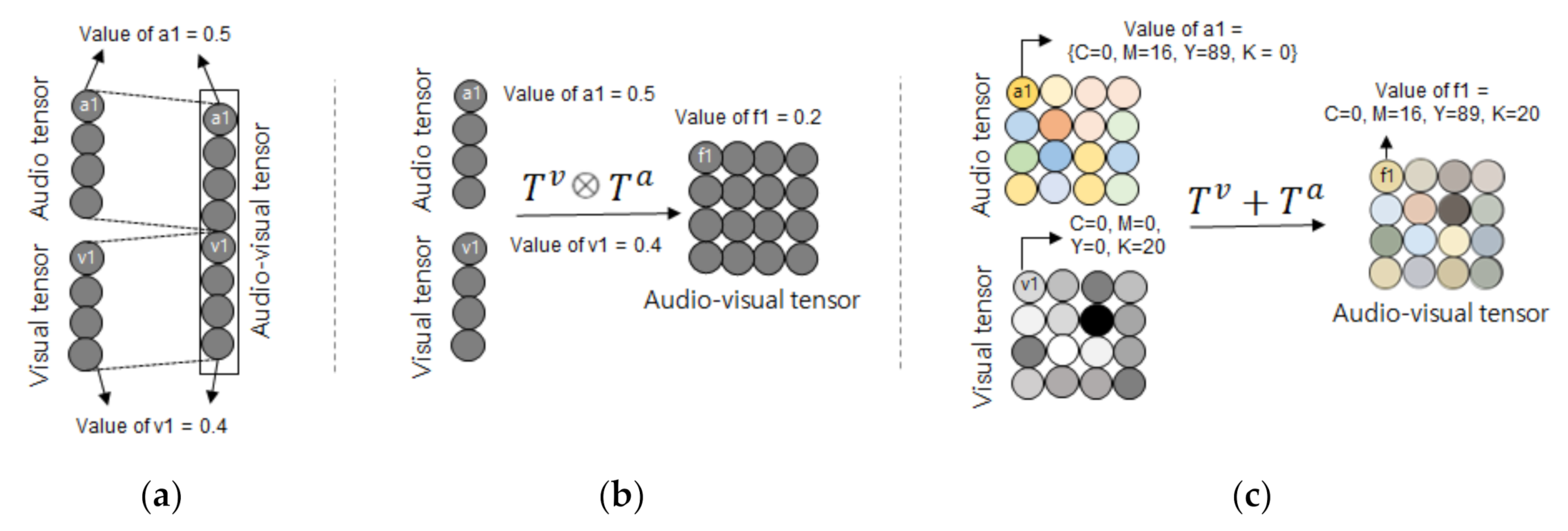
- Second, this study proposes an audio-visual fusion method that represents the audio-visual information as a data structure. The proposed audio-visual fusion method expresses audio information on the color scale and visual information on the black and white scale. It mixes the two colors to represent one data structure. As such, it is a data representation method that can retain audio-visual identity in one data structure and represent relativeness between audio and video information for piano playing posture classification.
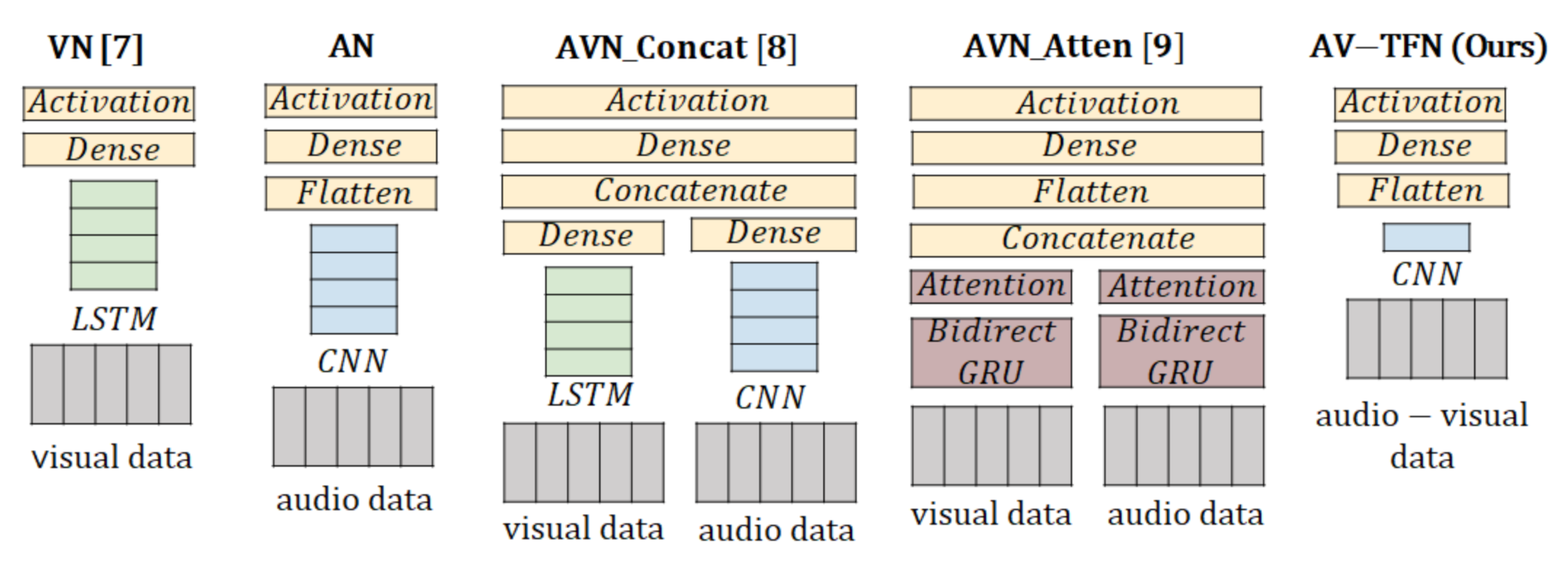
- Third, this study demonstrates the superiority of the proposed AV-TFN method through comparisons of the performances of the visual network (VN) [7], audio network (AN), and audio-visual network (AVN) with concatenation (AVN-Concat) [8] and attention (AVN-Atten) [9] techniques. The experiment results show that AV-TFN significantly improves F1 score compared with AN, VN, AVN-Concat, and AVN-Atten methods, while also achieving speeds similar to that of the fast VN method.
2. Related Work
2.1. Piano Playing Posture Classification Methods
2.2. Data Representation Methods
3. Proposed Audio-Visual Tensor Fusion Network
3.1. Explanation of C3Pap Dataset
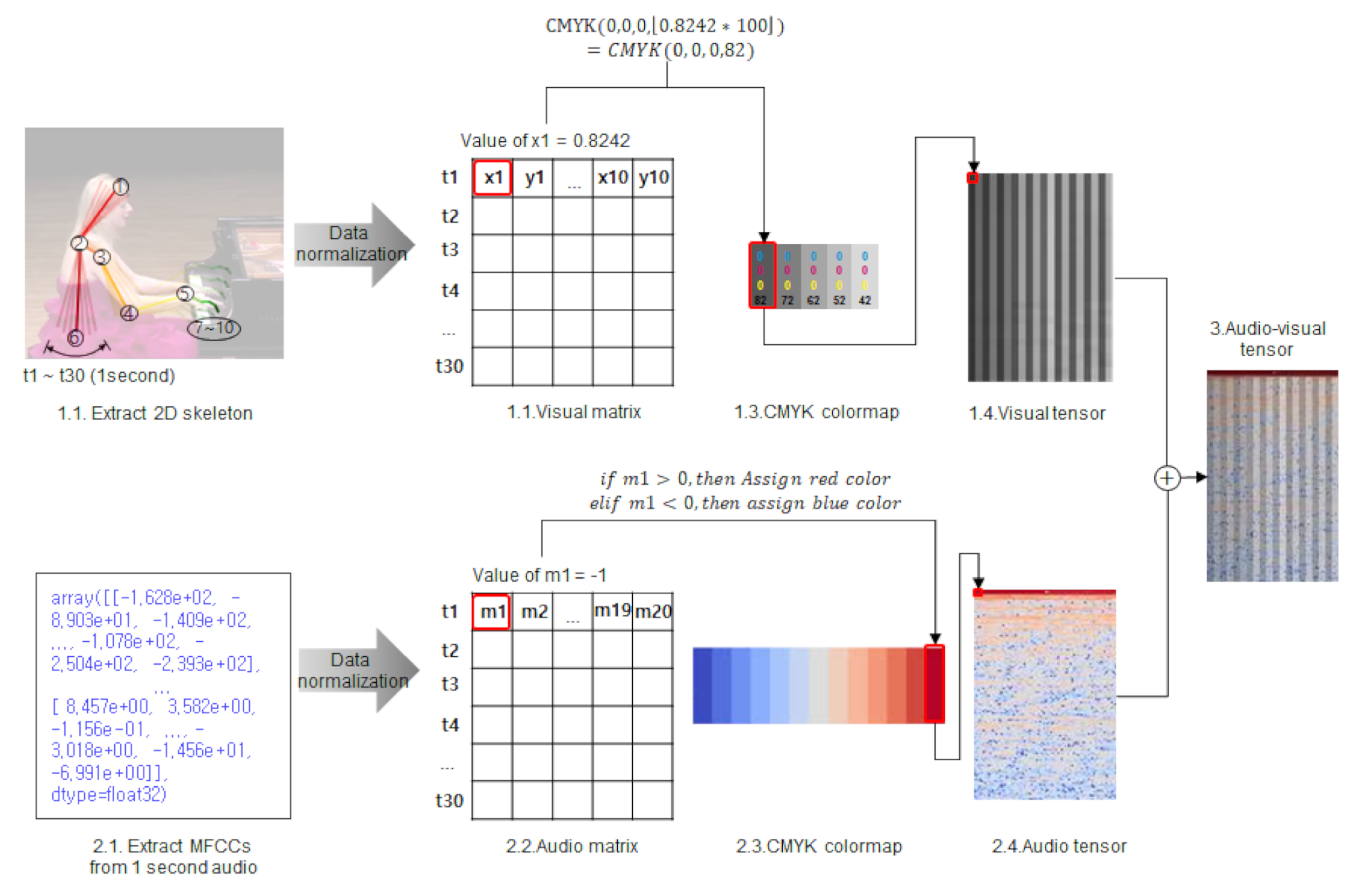
3.2. Feature Extraction
3.3. Data Normalization
3.4. Audio-Visual Tensor
3.5. Model Training
4. Performance Evaluation
4.1. Implementation Details
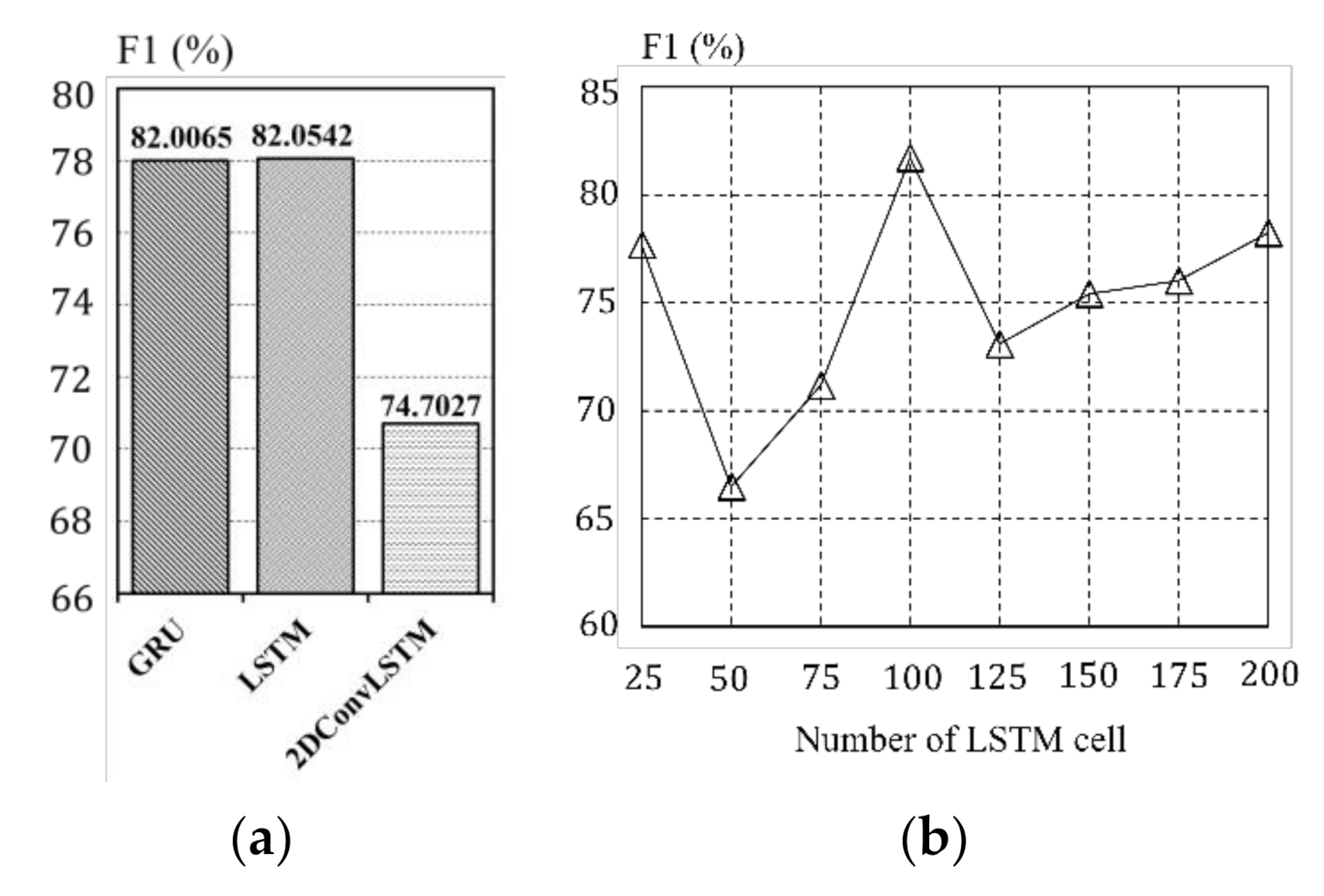
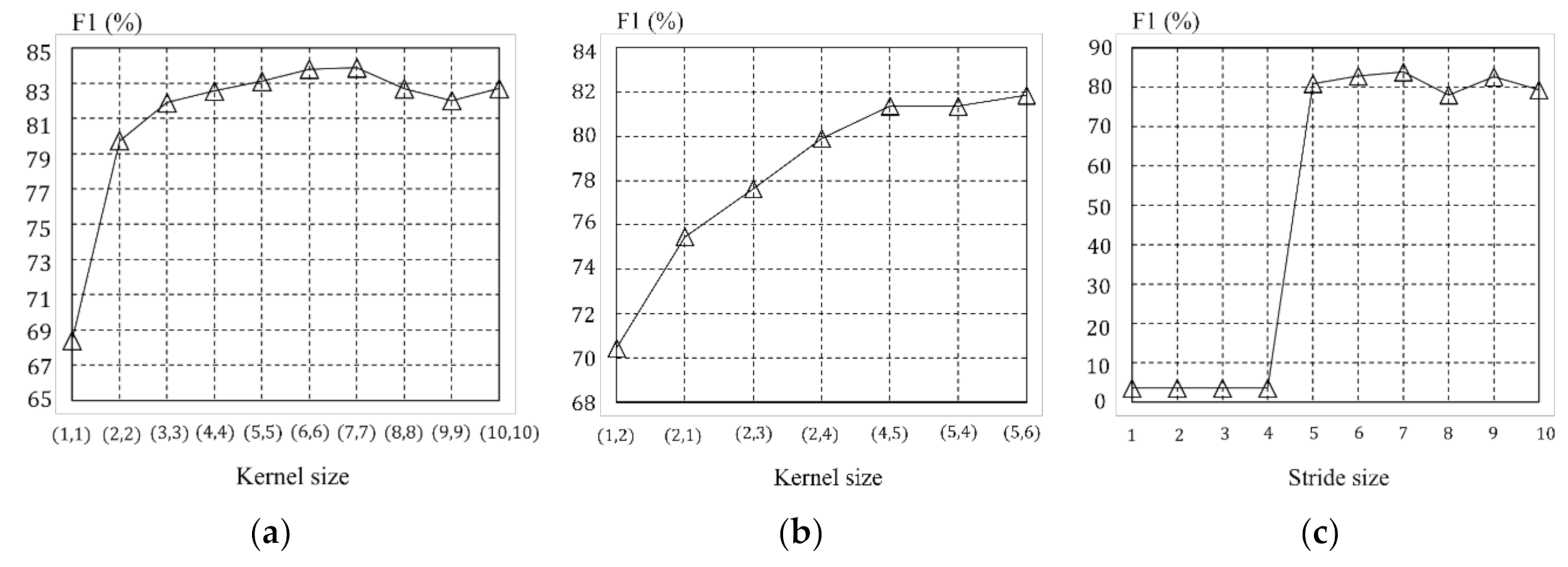
4.2. Hyperparameter Setting
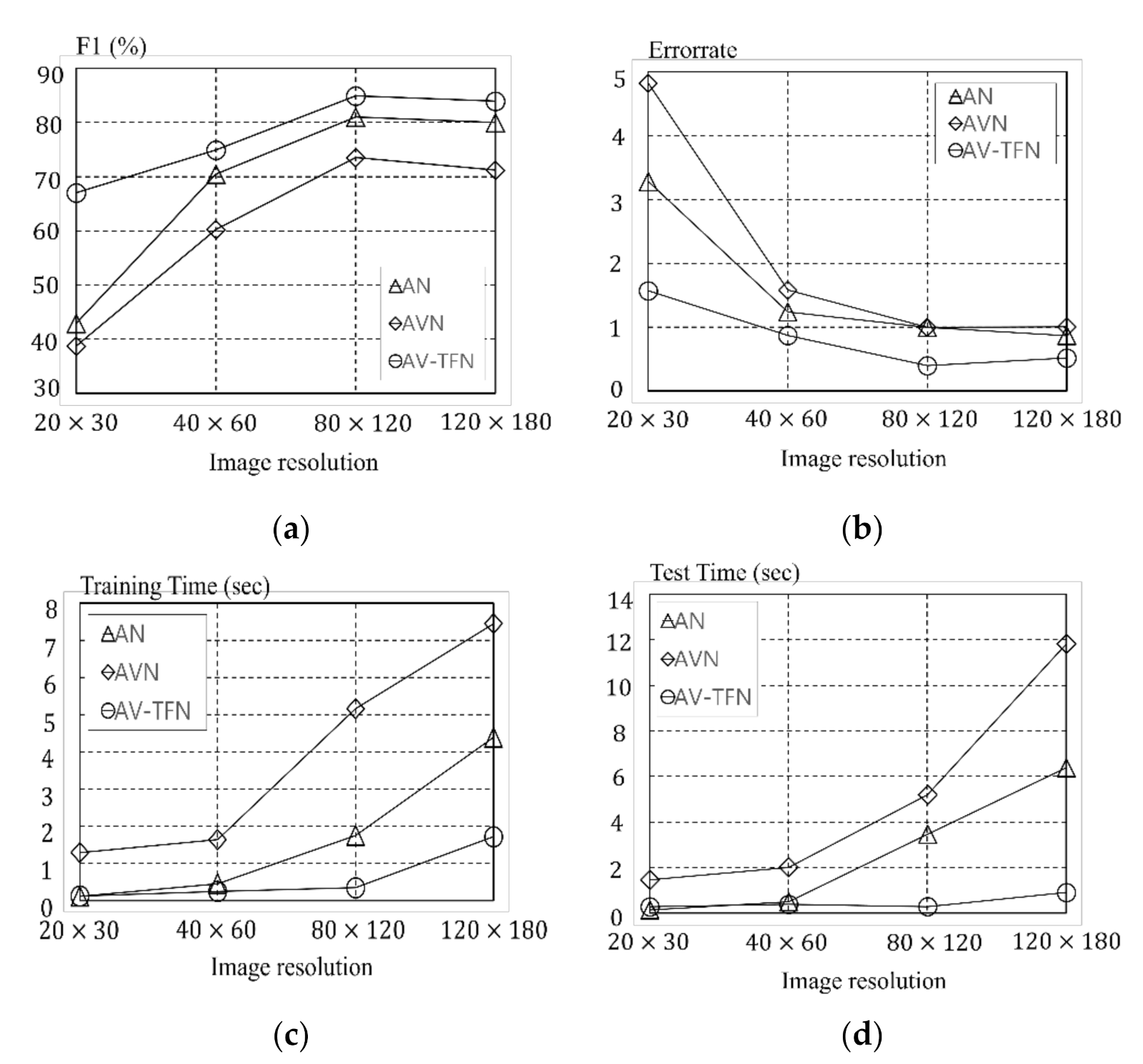
4.3. Experiments and Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bragge, P.; Bialocerkowski, A.; McMeeken, J. A systematic review of prevalence and risk factors associated with playing-related musculoskeletal disorders in pianists. Occup. Med. 2006, 56, 28–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neninger, C.R.; Sun, Y.; Lee, S.H.; Chodil, J. A complete motion and music capture system to study hand injuries among musicians. In Proceedings of the International Conference on Emergency Management & Robotics for Hazardous Environments, Knoxville, TN, USA, 8–10 August 2011; pp. 1–11. [Google Scholar]
- Zandt-Escobar, A.V.; Caramjaux, B.; Tanaka, A. PiaF: A tool for augmented piano performance using gesture variation following. In Proceedings of the International Conference on New Interfaces for Musical Expression, London, UK, 30 June–4 July 2014; pp. 167–170. [Google Scholar]
- Hadjakos, A. Pianist motion capture with the Kinect depth camera. In Proceedings of the 9th Sound and Music Computing Conference, Copenhage, Denmark, 11–14 July 2012; pp. 303–310. [Google Scholar]
- Winges, S.A.; Furuya, S. Distinct digit kinematics by professional and amateur pianists. Neuroscience 2015, 284, 643–652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, S.H.; Nasridinov, A.; Park, Y.H. A kinect-based piano education system for correction of pianist posture. Asia Life Sci. 2015, 12, 571–586. [Google Scholar]
- Park, S.H.; Ihm, S.Y.; Nasridinov, A.; Park, Y.H. A Feasibility Test on Preventing PRMDs Based on Deep Learning. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 10005–10006. [Google Scholar]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL-based multimodal emotion recognition and sentiment analysis. In Proceedings of the IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Akhtar, M.S.; Chauhan, D.S.; Ghosal, D.; Poria, S.; Ekbal, A.; Bhattacharyya, P. Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; pp. 370–379. [Google Scholar]
- Mora, J.; Lee, W.S.; Comeau, G. 3D visual feedback in learning of piano posture. In Proceedings of the International Conference on Technologies for E-Learning and Digital Entertainment, Hong Kong, China, 11–13 June 2007; pp. 763–771. [Google Scholar]
- Li, M.; Savvidou, P.; Willis, B.; Skubic, M. Using the kinect to detect potentially harmful hand postures in pianists. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 762–765. [Google Scholar]
- Johnson, D.; Dufour, I.; Damian, D.; Tzanetakis, G. Detecting pianist hand posture mistakes for virtual piano tutoring. In Proceedings of the 42nd International Computer Music Conference, Utrecht, The Netherlands, 12–16 September 2016; pp. 168–171. [Google Scholar]
- Tits, M.; Tilmanne, J.; D’Alessandro, N.; Wanderley, M.M. Feature extraction and expertise analysis of pianists’ Motion-Captured Finger Gestures. In Proceedings of the 41st International Computer Music Conference, Denton, TX, USA, 25 September–1 October 2015; pp. 1–4. [Google Scholar]
- Shlizerman, E.; Dery, L.; Schoen, H.; Kemelmacher-Shlizerman, I. Audio to body dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7574–7583. [Google Scholar]
- Ueno, K.; Frukawa, K.; Nagano, M.; Asami, T.; Yoshida, R.; Yoshida, F.; Saito, I. Good Posture Improves Cello Performance. In Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Hong Kong, China, 29 October–1 November 1998; pp. 2386–2389. [Google Scholar]
- Morency, L.; Mihalcea, R.; Doshi, P. Towards Multimodal Sentiment Analysis: Harvesting Opinions from the Web. In Proceedings of the 13th International Conference on Multimodal Interfaces, Suzhou, China, 14–18 October 2019; pp. 169–176. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1103–1114. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 7291–7299. [Google Scholar]
- Sándor, G. On Piano Playing: Motion, Sound and Expression; Schirmer Books: New York, NY, USA, 1981; pp. 37–140. [Google Scholar]
- Banowetz, J. Piano-Related Musculoskeletal Disorders: Posture and Pain. Doctoral Dissertation, University of North Texas, Denton, TX, USA, May 2013. [Google Scholar]
- Beacon, J.F.; Comeau, G.; Payeur, P.; Russell, D. Assessing the suitability of Kinect for measuring the impact of a week-long Feldenkrais method workshop on pianists’ posture and movement. J. Music Technol. Educ. 2017, 10, 51–72. [Google Scholar]
- Payeur, P.; Nascimento, G.M.G.; Beacon, J.; Comeau, G.; Cretu, A.M.; D’Aoust, V.; Charpentier, M.A. Human gesture quantification: An evaluation tool for somatic training and piano performance. In Proceedings of the IEEE International Symposium on Haptic, Audio and Visual Environments and Games, Houston, TX, USA, 23–26 February 2014; pp. 100–105. [Google Scholar]
- Willis, B.; Li, M.; Skubic, M. Assessing injury risk in pianists: Using objective measures to promote self-awareness. MTNA e-J. 2017, 9, 3–17. [Google Scholar]
- Hadjakos, A.; Aitenbichler, E.; Mühlhäuser, M. The Elbow Piano: Sonification of Piano Playing Movements. In Proceedings of the 8th International Conference on New Interfaces for Musical Expression, Genova, Italy, 5–7 June 2008; pp. 285–288. [Google Scholar]
- Furuya, S.; Flanders, M.; Soechting, J.F. Hand kinematics of piano playing. J. Neurophysiol. 2011, 106, 2849–2864. [Google Scholar] [CrossRef] [PubMed]
- Sadeghzadehyazdi, N.; Batabyal, T.; Dhar, N.K.; Familoni, B.O.; Iftekharuddin, K.M.; Acton, S.T. GlidarCo: Gait recognition by 3D skeleton estimation and biometric feature correction of flash lidar data. arXiv 2019, arXiv:1905.07058. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Measure |
|---|---|
| Number of amateur pianists | 8 |
| Number of professional pianists | 5 |
| Number of music piece | 17 |
| Total sequence | 11,850 |
| Total length | 1506 s |
| Mean clip length | 4.18 s |
| Min clip length | 1 s |
| Max clip length | 14 s |
| Frame rate | 29.97 fps |
| Audio | Yes |
| Ex | Parameters | ||
|---|---|---|---|
| Ex. 1 | Comparing performance of AV-TFN with other methods | Image resolution | |
| Kernel size | (6,6) | ||
| Models | VN, AN, AVN-Concate, AVN-Atten, AV-TFN | ||
| Tensor fusion ratio | 50:50 | ||
| Ex. 2 | Estimating performance of model as image resolution increases | Image resolution | , , , |
| Epoch | 1500 | ||
| Kernel size | (1,1), (2,2), (6,6) | ||
| Models | AN, AVN-Concate, AV-TFN | ||
| Tensor fusion ratio | 50:50 | ||
| Ex. 3 | Estimating effect of tensor fusion ratio as tensor fusion ratio is varied | Image resolution | |
| Epoch | 1500 | ||
| Kernel size | (1,1) | ||
| Models | AV-TFN | ||
| Tensor fusion ratio | 0:100, 50:50, 100:0 | ||
| Accuracy | Precision | Recall | F1 Score | Error Rate | Training Time | Test Time | |
|---|---|---|---|---|---|---|---|
| VN [7] | 84.9829 | 83.6057 | 81.7531 | 82.0542 | 0.6118 | 1.0963 | 0.6041 |
| AN | 80.137 | 82.8966 | 80.6059 | 81.0313 | 0.9951 | 1.7541 | 3.4616 |
| AVN-Concate [8] | 76.0274 | 79.8384 | 72.9123 | 73.53 | 0.9951 | 5.1612 | 5.2532 |
| AVN-Atten [9] | 81.57 | 84.8317 | 75.3428 | 75.0957 | 1.0746 | 5.1982 | 4.0455 |
| AV-TFN (Ours) | 87.7133 | 86.1329 | 84.7091 | 84.9085 | 0.3943 | 0.3454 | 0.2799 |
| Image Resolution | AN vs. AV-TFN | AVN vs. AV-TFN | ||||||
|---|---|---|---|---|---|---|---|---|
| F1 Score | Error Rate | Training Time | Test Time | F1 Score | Error Rate | Training Time | Test Time | |
| 20 × 30 | 24.136 | 1.7118 | 0.008 | 0.0031 | 28.3329 | 3.251 | 1.9513 | 0.944 |
| 40 × 60 | 4.4681 | 0.3704 | 0.5471 | 0.7885 | 14.6703 | 0.7126 | 2.4798 | 1.4651 |
| 80 × 120 | 3.8772 | 0.6008 | 1.4087 | 3.1817 | 11.3785 | 0.6008 | 4.8158 | 4.9733 |
| 120 × 180 | 3.9825 | 0.3508 | 3.3398 | 5.668 | 12.7281 | 0.4891 | 9.2675 | 14.9646 |
| Average | 9.116 | 0.7447 | 1.3259 | 2.4103 | 16.7775 | 1.2634 | 4.6286 | 5.5868 |
| IR | TFR | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| 0:100 | 64.7917 | 64.2071 | 61.1152 | 61.636 | |
| 50:50 | 70.2083 | 69.4851 | 66.4125 | 67.0412 | |
| 100:0 | 62.7083 | 58.9199 | 55.3345 | 53.9586 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-H.; Park, Y.-H. Audio-Visual Tensor Fusion Network for Piano Player Posture Classification. Appl. Sci. 2020, 10, 6857. https://doi.org/10.3390/app10196857
Park S-H, Park Y-H. Audio-Visual Tensor Fusion Network for Piano Player Posture Classification. Applied Sciences. 2020; 10(19):6857. https://doi.org/10.3390/app10196857
Chicago/Turabian StylePark, So-Hyun, and Young-Ho Park. 2020. "Audio-Visual Tensor Fusion Network for Piano Player Posture Classification" Applied Sciences 10, no. 19: 6857. https://doi.org/10.3390/app10196857