1. Introduction
The general approach for modeling autonomous vehicles contains hierarchical three-layered modeling, i.e., the perception layer, a planning layer, and a trajectory control layer. The perception layer preprocesses data from multiple sensors (lidar, radar, video camera, GPS, etc.) to fuse them into a reliable perception of the surrounding environment and traffic situation. The trajectory control layer drives the actuators and gives commands based on the second planning layer. This contains three sublayers: route planning, behavioral decision-making, and path planning [
1].
The route and path planning layer generates a global route and feasible local trajectories. The behavioral decision-making layer provides safe and feasible driving actions on the strategic level, such as “left lane change, follow, etc.”. Self-driving vehicles’ decision-making system should foresee the near future to predict the surrounding vehicles’ future driving behavior [
2]. Without the prediction function, emergency incidents may happen, such as the collision between MIT’s “Talos” AV and Cornell’s “Skynet” AV during the 2007 urban challenge, which was held by the Defense Advanced Research Projects Agency (DAPRA) [
3].
Autonomous vehicles must navigate safely and efficiently in a complex vehicle traffic system, either by individual or cooperative decisions [
4]. To do this, they need to make decisions continuously about what steps to take in a given traffic situation, such as when to start an overtaking or lane change maneuver. A necessary condition for decision-making is that the autonomous vehicle could interpret and consider the movement of surrounding vehicles’ behavior [
5]. The behavioral prediction for autonomous driving is challenging and surrounded by great attention. Dagli, Brost, and Breuel present a hierarchical dynamic Bayesian network utilized for predicting behavioral patterns [
6]. Gaussian process regressions are also used for trajectory pattern classification and prediction by Trautman and Krause [
7].
The Gaussian mixture model for trajectory prediction is also a subject of research. Wiest et al. [
8] present a solution which can predict the future trajectory by learning patterns in trajectories, to infer a joint probability distribution as a motion model. The future path is predicted by calculating the probability for the motion, conditioned on the current observed trajectory. Their work’s novelty is that they provide a distribution over the future trajectories. Hence, the evaluation of the statistical properties can predict a specific scenario.
Cruz et al. present a study of location prediction applied to trajectories obtained from sensors placed on road networks [
9]. A variety of Recurrent Neural Networks (RNN) is applied using a different combination of features to measure the features’ impact on the prediction task. The authors show the underlined road network’s use to estimate a finer granularity trajectory definition and obtain better models in terms of accuracy and error of distance.
A novel approach presents a Long-Short Term Memory (LSTM) model for motion prediction of surrounding vehicles on freeways, aware of all the surrounding cars [
10]. This model’s output is not a single motion trajectory but a multi-modal distribution over future motion. A trajectory encoder LSTM encodes the vehicle’s track histories and relative positions being predicted and its adjacent vehicles in a context vector. The context vector is appended with maneuver encodings of the lateral and longitudinal maneuver classes. The decoder LSTM generates maneuver specific future distributions of vehicle positions at each time step, and the maneuver classification branch assigns maneuver probabilities.
Rodrigues et al. claim that, in a system consisting of three planners (global path, behavioral, and local path), the behavior planner is the limitation of a successful oath planning solution. A new tactical behavior planner is proposed, motivated by how expert human drivers behave in intersections and is made up of a three-module architecture [
11].
High-reliability lane change maneuver prediction is achieved by combining Support Vector Machine (SVM) and Artificial Neural Network (ANN) methods by Dou, Yan, and Feng [
12]. The SVM and ANN classifiers predict the feasibility and suitability to change lane under certain environmental conditions. Three different classifiers to predict lane changes are compared, and the best performance is the proposed combined model with 94% accuracy for non-merge behavior and 78% accuracy for merge behavior.
Izquierdo et al. have examined vehicle movement and lane changing predictions using ANN and SVM classifiers. In their paper [
13], they evaluate the performance of two kinds of ANNs predicting the lateral motion of the ego vehicle. Vehicle-to-vehicle communication systems can perform such prediction extensible to the surrounding vehicles. These two ANN architectures are evaluated in two datasets to achieve different results in different datasets with different variability. The authors use a Nonlinear Autoregressive Neural Network (NARNN), which is specially tuned to predict time series in dynamical models, which indicates when mapping between inputs and outputs is desired. In conclusion, the authors propose a baseline method to evaluate the lateral position prediction algorithms’ performance. The NARNN specially indicated to predict dynamical systems is not better than the baseline method. However, the FFNN can reduce the mean absolute error on the predicted positions about 23% and 30% up to 4 s in the University of Peking and University of Alcala datasets, respectively. For lane change detection, an SVM classifier is tested. The SVM can detect precisely a lane change 3 s before it happens [
13].
Maneuver detection and short-term forecasting of road vehicles are essential parts of the autonomous cars’ behavior planning algorithms.
Several articles address the problem of classifying the maneuvers of vehicles moving in the ego vehicle’s environment based on their trajectory data [
10,
11,
12,
13]. In [
14], an LSTM RNN classifier is presented, which can classify 3 s of vehicle trajectory data to three lateral maneuver classes with 86% precision without using any information about surrounding vehicles. For this specific task, other approaches and input compilations are compared and discussed. On the other hand, a completely unified framework for surrounding vehicle maneuver recognition and motion prediction is presented with a greater generality by Nachiket et al. [
15]. Their framework outperforms an interacting multiple model-based trajectory prediction baselines and runs in real-time at about six frames per second. Trajectory prediction has an inherent uncertainty because of the surrounding vehicles, and it can be handled by multi-modal prediction. In [
16], this problem is addressed even just in [
10], but a CNN based approach is presented. Their approach first generates a raster image encoding each vehicle actor’s context and uses a CNN model to output several possible trajectories and their probabilities.
These operations are computationally intensive and require computational capabilities for real-time traffic analysis. On the other hand, the data transferred by V2X are sensitive and need secure communication, which places additional overhead on the computational requirements and hence hardens the real-time application [
17,
18]. It is advisable to compress the trajectory data in such a way that the compressed data are at least one order of magnitude smaller and capable of reconstructing the real trajectory with relatively high accuracy. At the same time, carrying useful information about the latent properties beyond the data distribution.
Contributions of the Paper
This paper presents a Variational Autoencoder (VAE) to compress trajectory data, which can select useful latent features with little loss and small reconstruction error. It is shown that the representation learned during compression inherently separates the trajectories according to three maneuver classes (lane keeping, right, and left lane change). VAEs can be used for learning images and, based on the encoded information, annotate or label them in an unsupervised way [
19,
20]. It opens new possibilities for clustering multi-dimensional data [
21,
22].
Furthermore, this tool can be used to classify texts even better than LSTM-based encoder–decoder tools [
23]. It is not a new idea to use VAE and generative models for trajectory analysis either. Krajewski et al. show that Generative Adversarial Networks (GAN)s and VAEs can learn latent features that are unintelligible by polynomial models [
24]. Classification and compression are two very distinct tasks. Compression is trained in an unsupervised way, without class labels, merely copying the input trajectory to the output as accurately as possible. During classification, the device learns in a supervised manner using class labels, only the separation without being forced to find the data’s appropriate latent properties. Overall, there are two main findings of the research:
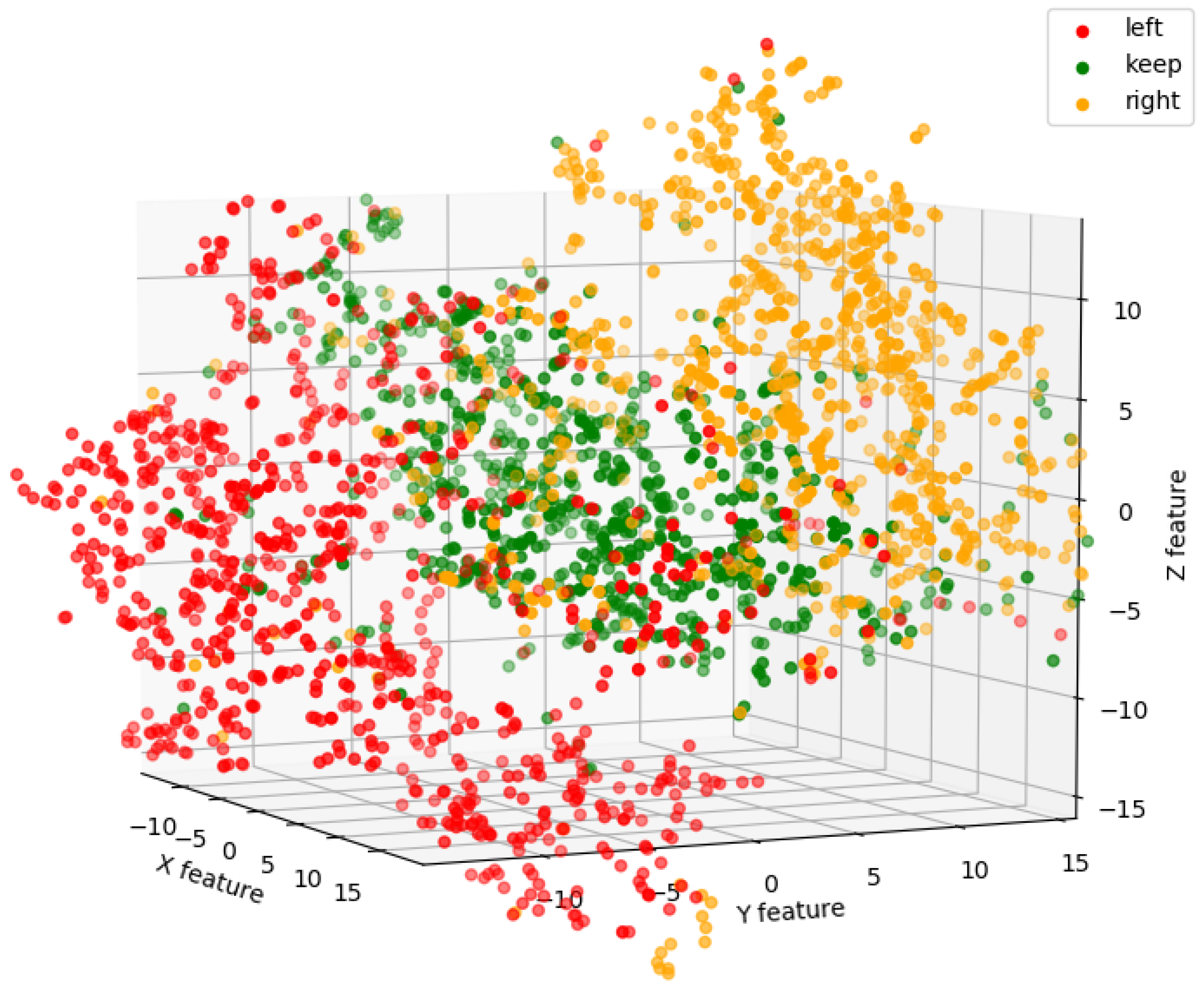
First, the data compression capabilities of the VAE is presented, which is proved to be an effective tool for representing road vehicle trajectories in a dense, highly compressed context vector.
Second, coming from the continuous encoding nature of the VAE, the encoding of similar trajectories are also close to each other in the context vector, hence it can provide maneuver classification information without training information.
In
Section 2, the problem is outlined regarding sequential data encoding and interpretation and gives the motivation of this research. Briefly, the purpose of this article is to provide examples of efficient trajectory data compression for behavior prediction using autoencoder neural networks. Trajectory prediction is not the subject of this article as it attempts to analyze trajectories in more depth. Sequential data compression and classification are separate tasks. All the experiments are performed using the Next Generation Simulation (NGSIM) trajectory database [
25,
26]. The database is presented in
Section 3, along with each preprocessing step. In
Section 4, the models used in the research are introduced, with special emphasis on the VAE, divided into three sub-sections. The LSTM and Convolutional Sparse Autoencoders (
Section 4.1 and
Section 4.2) and the Convolutional Variational Autoencoders (CVAE)
Section 4.3 are shown in separate sub-sections. The explanation of the CVAE’s loss function is a key point, and therefore its introduction is justified in more detail.
Section 5 presents the results of model training and data research. All details regarding the training can be found in
Section 5.1, while the coding ability in
Section 5.2 is illustrated with figures. The result of the network’s coding capability is used for a classification problem and discussed in
Section 5.3, and finally
Section 5.4 is devoted to the analysis of latent spatial behavior.
2. Problem Formulation
Convolutional neural networks (CNN) and LSTM Recurrent Neural Networks [
27,
28] for the optimization are studied in this paper. Different tools can be applied for the maneuver classification problem, such as Support Vector Machine, Gaussian Classifier, and LSTM neural networks [
10,
11,
12,
13,
14]. For more precise trajectory forecasting and analysis, one way is to use some method of dimension reduction.
The obvious choice for sequence analysis is an RNN architecture. Still, in the case of longer sequences, the vanishing and exploding gradient problem become the main obstacle of the optimization, according to [
29]. To avoid this, one can use, e.g., LSTM RNN, but its complexity (the number of parameters) can be high. Therefore, the training, as well as the inference process, can be slow. It is not an important aspect during the research work if GPUs are available for accelerating the optimization and the inference. Lately, several forecasting and classification concepts have been thoroughly proven in the literature. However, carefully choosing the neural networks’ architecture to minimize the model complexity can be useful in the practice.
A CNN can also find and learn temporal features and patterns in a one-dimensional “image”; in our case, this dimension is the time [
16]. Every pixel is one-time step, and the number of channels is equal to the
d feature number. CNN based autoencoder can yield the same or better result as a Bidirectional LSTM with a tenth of its complexity.
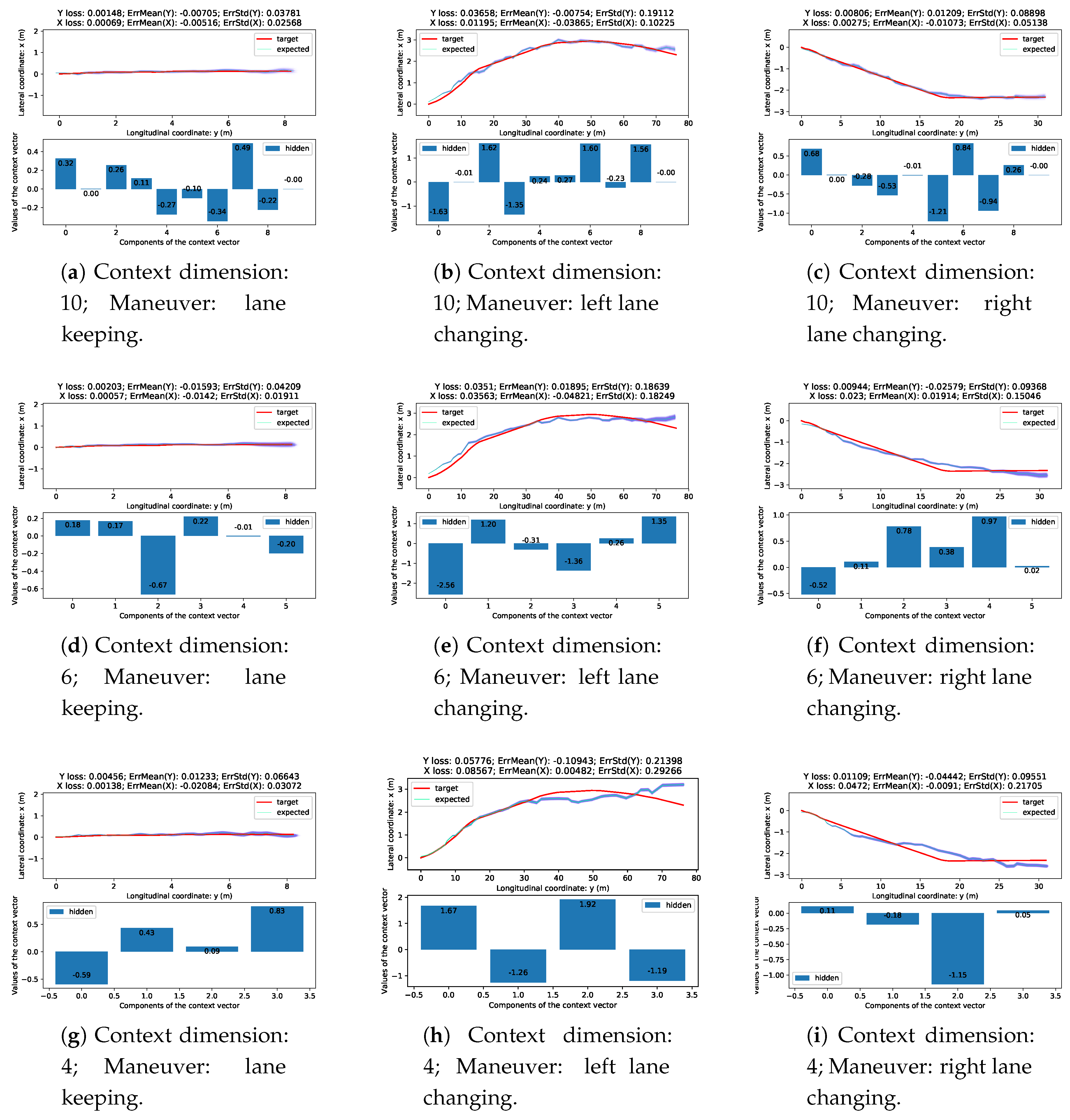
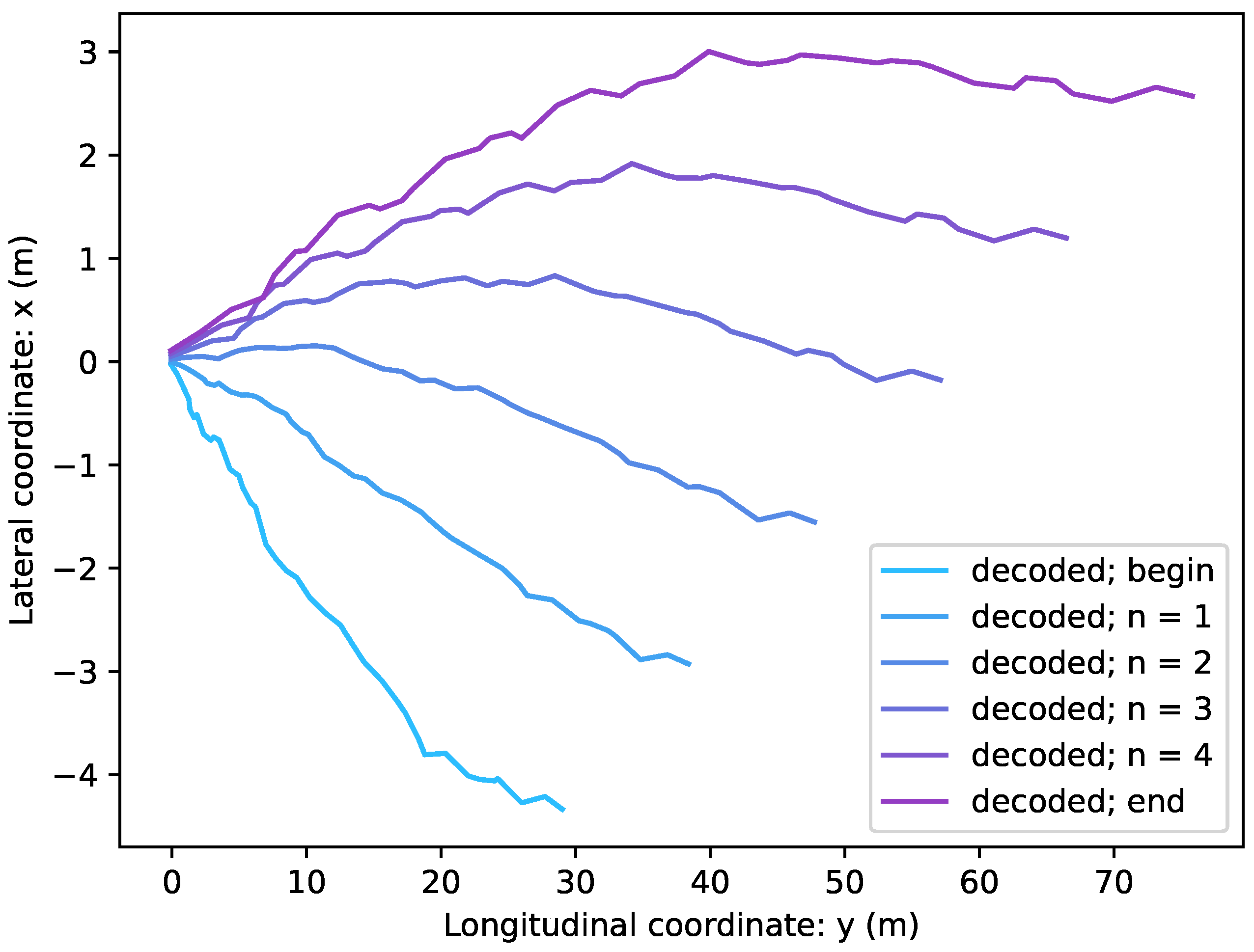
The context vector can be used for maneuver detection, classification, and data visualization. This paper presents autoencoders trained to copy the trajectories while the context vector is low dimensional and carries useful information. Using the same architecture for predicting future trajectory fails because of the lack of information about the surrounding vehicles [
15,
30,
31]. A hypothesis is set up predicting the future trajectory’s context vector instead of the future trajectory itself. From this, it is decoded that the performance should be better. It is shown that the experimental result overturns this hypothesis, so the trajectories do not decode enough latent information about surrounding vehicle motions.
3. The Training Dataset
The data set for training is and every data point is a vehicle trajectory with sequence length s and feature dimension d. Sequence length is , which means 6 s, and the feature dimension is , which is the longitudinal and lateral coordinate of the vehicle in every time step. The traffic situation is a multi-lane highway road in the US, and the data collection was made by the New Generation Simulations (NGSIM).
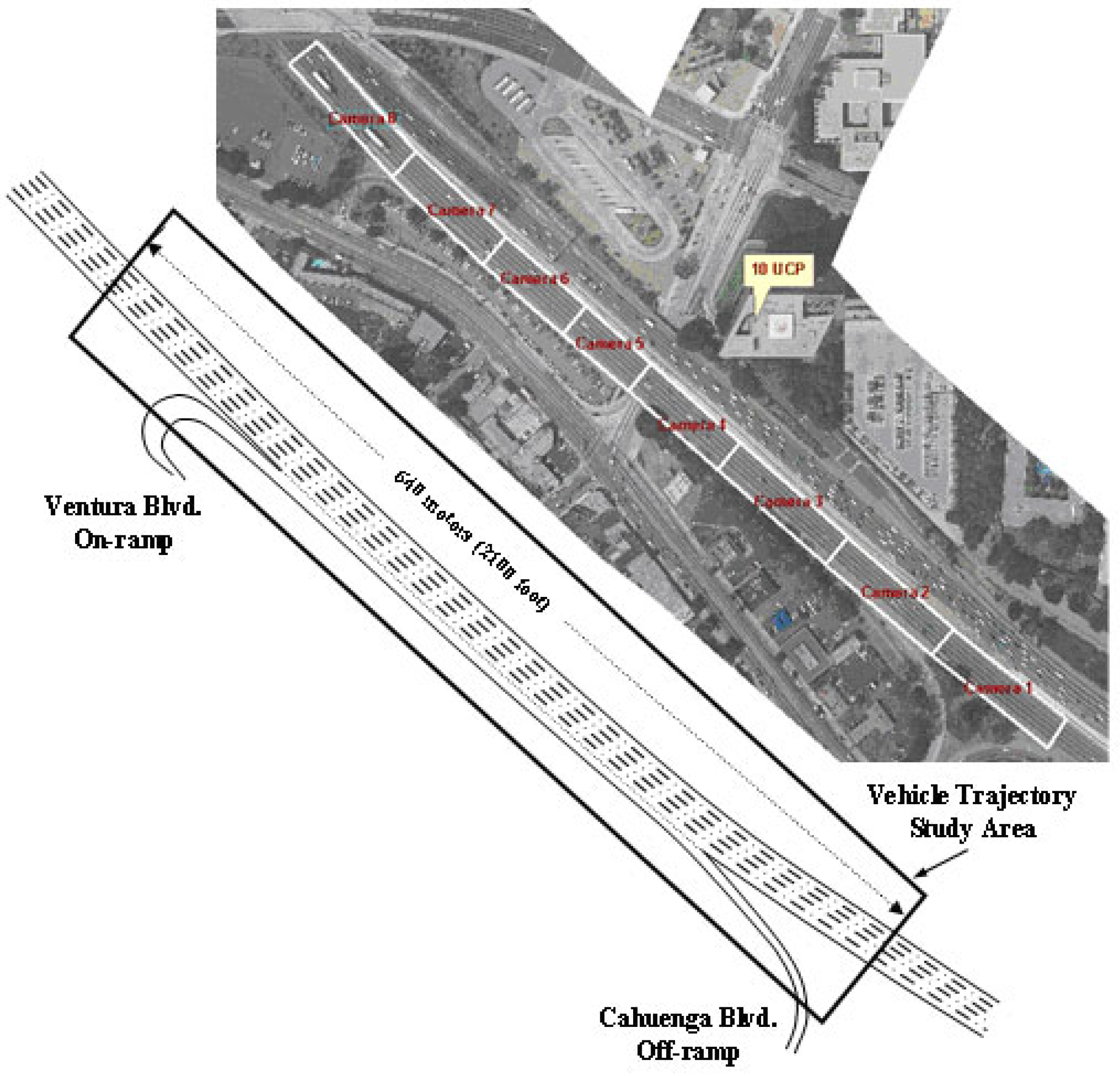
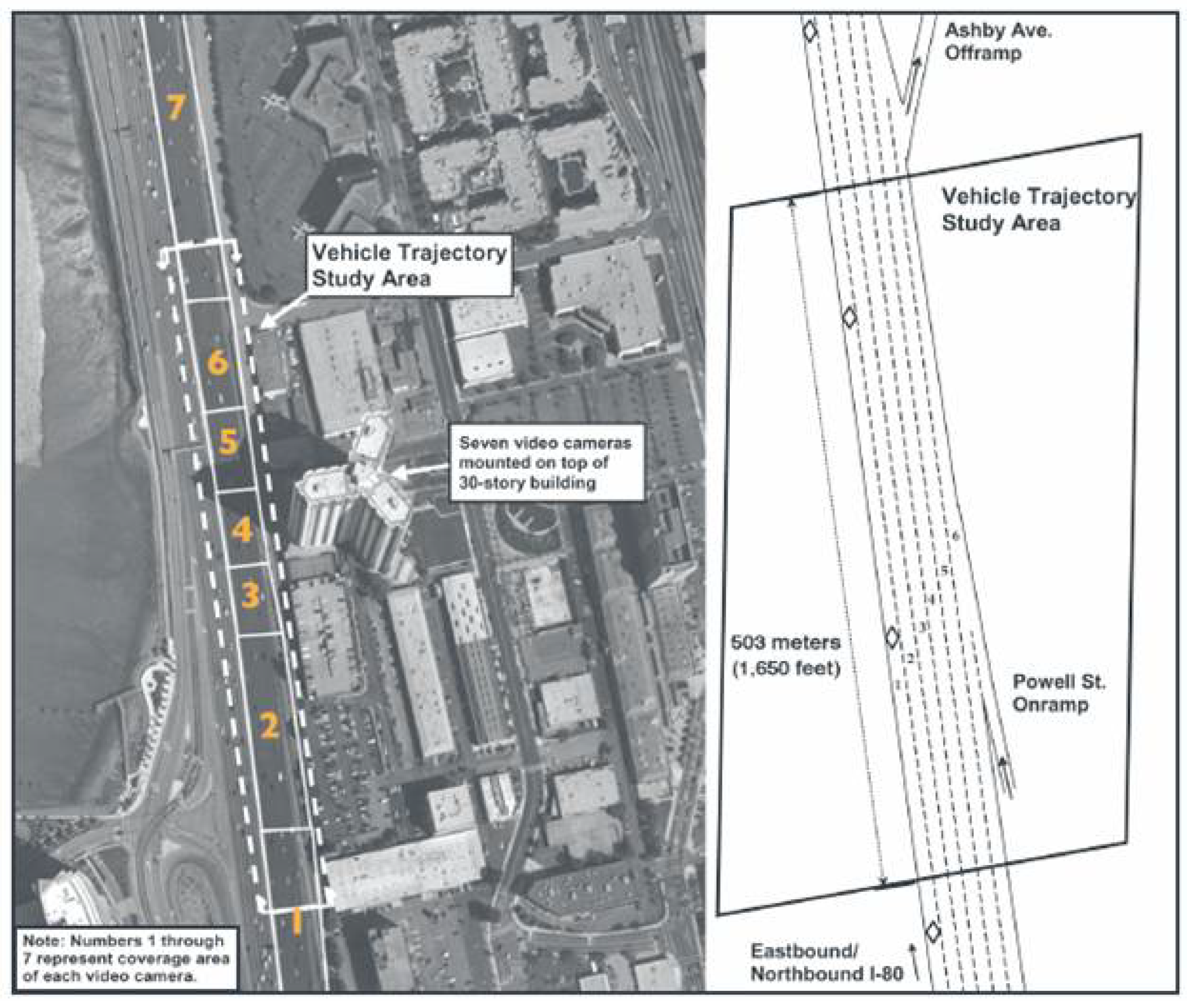
The NGSIM Unites States Highway 101 (US-101) (
Figure 1) and Interstate 80 (I-80) (
Figure 2) datasets [
25,
26] are used for training and evaluating the trajectory autoencoding problem. This trajectory data has precise location, velocity, and acceleration of each vehicle within a specific area every
s. Furthermore, it provides relative positions to surrounding vehicles and lane position in every frame. There are
million rows and 25 columns in this dataset. Each row represents one vehicle in a specific frame with all the information. The columns in ascending order are the following: vehicle identification number, frame identification number ascending by start time, the total number of frames in which the vehicle appears, global time, lateral (
x) and longitudinal (
y) coordinate of the vehicle’s front center concerning the left-most edge of the section in the direction of travel, global
coordinate, length and width of the vehicle, vehicle type (1—motorcycle, 2—auto, 3—truck), instantaneous velocity and acceleration, and lane position.
Data Preprocessing and Preparations
The database for the training consists of 1614 vehicles. One-third of them perform a lane-changing maneuver to the left, and another one third is right lane changing; the rest is lane-keeping. Two trajectory pieces are extracted from the complete path data of each vehicle. One is 6 s (60 time-steps) ahead of the occurrence of the lane index changing, and one other 6 s after. In the case of the lane-keeping ones, two consecutive pieces of trajectory are taken. All the coordinate units have been changed from feet to meters. The following steps have been performed on both subsets.
First, we checked if a vehicle had at least 120 time-steps in the data set because two 60 long sequences are desired, and separated according to what maneuver is done. Second, a vehicle is only considered in the training set if the lane changing occurred later than the first 60 time-steps, with the two sequences extracted. Thirdly, the two sets have been added together and the largest possible balanced data set is randomly chosen and drawn, with the same number of lane-keeping, left, and right lane changing vehicles.
For the sake of the higher generalization capability, every trajectory sample is translated to start from the origin.
4. Methodology
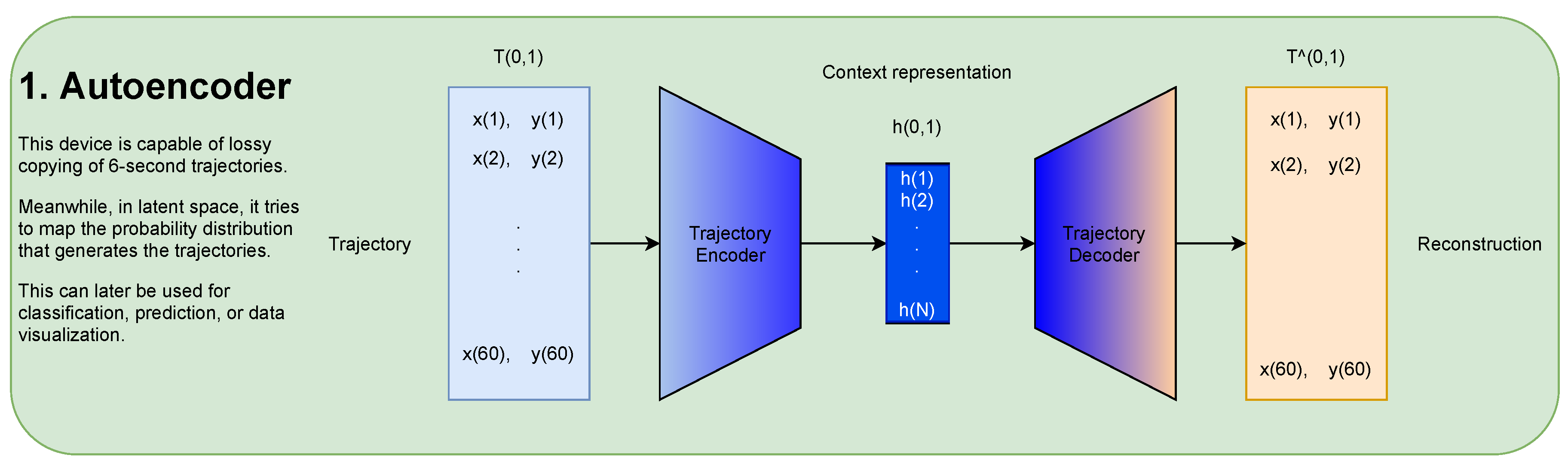
The idea behind the presented research uses autoencoders to train a neural network to a simple task copying the input data into the output as accurately as possible [
20]. An Autoencoder (AE) contains an encoder neural network and a decoder network. The encoder takes the input vector and transforms it into another vector (usually with a smaller dimension) called the context vector. The decoder receives this code and dilates it back to the size of the input data. This scheme fits into any AE’s basic concept, and it is summarized in
Figure 3. At each epoch, one feeds the data forward, the encoder, and the decoder takes the reconstruction error, backpropagates it through the network, and updates its weights. The process can be trained by any gradient descent optimization method. All the models are optimized by Adam [
32] with different learning rates between 0.0001–0.001, depending on the convergence performance.
The training uses mean square error (MSE) loss, which is the reconstruction loss. An additional loss function is also taken to smooth the output. The derivative of the target and decoded sequence is formed, their MSE is calculated and added to the reconstruction loss after multiplication by the weight of
:
where
4.1. Bidirectional LSTM Autoencoder
Based on LSTM networks’ success in learning sequential data generation process’s nonlinear, time-dependent dynamics [
27,
28], the application of LSTM networks is evident. The structure of the model is described below. The Encoder is a Bidirectional LSTM RNN with an adjustable
c context dimension—meaning that the LSTM [
33] cell has a hidden state and cell state dimension equal to
c. Coordinates
are fed in every time-step. The hidden and cell states are initialized randomly in the first time step, and the resulting new one is passed to the next step. The last ones are taken as the context vector and used as the initialization of the Encoder LSTM. During training mode, teacher forcing [
34] is applied with a ratio of
. The decoder in the first step takes the original trajectory’s last time step
coordinates. The other steps take the previous output or the corresponding ground truth from the original trajectory. In the case of validation and test, teacher forcing is turned off. The context dimension is set to be
using three LSTM layers and 0.5 dropout.
4.2. Convolutional Sparse Autoencoder
The encoder and decoder are one-dimensional CNNs with four compound convolutional layers and one linear layer. The numbers of input channels of the layers are 2, 6, 12, and 8 and the kernel sizes 4, 6, 8, and 5, respectively. PReLU activation function is applied in every layer with one parameter per channel. The last two layers use maximum pooling to reduce sequence length. Their kernel size is 3, and 2 with the dilation of 1. Thus, the output shape of the compound convolutional layers is . A single fully connected layer is used to reduce this number to the c context dimension.
The decoder’s transposed convolutional layers upscale the channel number and the sequence length. The channel numbers are 1, 3, 8, 4, and 2:
4.3. Convolutional Variational Autoencoder
Variational Autoencoder inherently has an explicit regularization during the training process [
35]. VAEs encode the input as a distribution over the latent space instead of encoding it as a point. The context vector is then sampled from this distribution, the sampled context is decoded, and the reconstruction error is computed. One data point from the data set is denoted by
x and the encoded representation, called “context vector” is
z. Let’s denote the prior distribution over the latent space by
Probabilistic decoder: This is defined by , and it describes the distribution of the decoded variable given the encoded variable.
Probabilistic encoder: This is defined by , and it describes the distribution of the encoded variable given the decoded variable.
The probabilistic encoder and decoder concept is not enough to solve the regularization problem regarding the content generation. It is easy to see that the model is not prevented from returning distributions like Dirac delta or punctual functions behave like classic models leading to overfitting. In the next paragraphs, the details of the mathematical concepts of the VAE are covered, and the deduction of the correct loss function for the optimization is presented.
Below, two assumptions are made about the distributions:
F denotes a set of functions that can be parametrized by a finite number of parameters, so it does not cover all the functions in general. The
F elements can be approximated by neural networks, which is the key to finding the optimal decoding. On the other hand, the Bayesian theorem can unfold the probabilistic encoder
which is used in Equation (
7) for the deduction of a practical formula. Otherwise, the integral in Equation (
5) cannot be evaluated, so it cannot be used in practice. By means of the variational inference formulation, the
encoder distribution is approximated by an other Gaussian
, where the mean and the variance are functions of variable
x:
Here,
G and
H are sets of parametrized functions just like
F. Among these functions, one needs to find the best approximation of the
functions by determining their parameters. The best approximation is supposed to minimize the Kullback–Leibler divergence [
36] between the approximation and the original
distribution. The optimal
and
functions obtained by
Here, Equation (
5) is substituted and one gets
After rearranging the terms, the Kullback–Leibler divergence of
and
distributions appears, which can be calculated. The last term does not depend on
g and
h, so, generally, it gives only a constant contribution so that it can be omitted in the minimization problem:
The last equation expresses that the optimizer needs to find a balance between the reconstruction loss, which is the maximization of the log-likelihood for the and the KL divergence of and the prior which enforce the encoder to stay close to the standard normal distribution. This is a trade-off between how much one can rely on the data and how fair assumption is the prior.
In case of the function
f, one should maximize the expected log-likelihood of output
x given a
z context vector sampled from
:
Taking Equation (
11) into account, the final optimization problem is formulated in maximizing the following expression with respect to the parameters of the three functions
:
The mean square error approximates the first term. The second term is the Kullback–Leibler divergence between the normal distribution
with a diagonal covariance matrix and the standard normal distribution. After performing the calculation, one gets the loss function for the VAE;
In addition, using the mean squared error of the first derivatives gives a better and smoother result, thus the final loss function for the VAE with Equation (
1) takes the following form:
All the functions
are parametrized by the parameters of neural networks, and
sets are defined by their architectural design. Empirically determined parameters for the encoder and decoder are given in
Table 1 and
Table 2.
6. Conclusions
The research presented in this paper shows that a CVAE, with an appropriate neural network structure, is capable of the lossy compression of real-world vehicle trajectories. The compressed code, also known as the context vector, or latent representation, can also be used for maneuver detection and classification. In addition, a representation that continuously maps similar patterns is learned, successfully modeling the vehicle trajectories automatically and meaningfully.
In the future, the input for trajectory data analysis and behavior prediction should be further investigated. A more realistic model should have the three lateral classes for lane changing behavior, multiplied by several longitudinal ones. Longitudinal classes could separate acceleration behaviors. Environmental conditions can also affect driver behavior, as light and dense traffic have different inner structures. Hence, a more sophisticated model should handle maneuvers that are specific to this situation.
The paper also shows that the encoded context vector can be used for maneuver classification. It could be used for trajectory prediction, but it is essential to consider more information about the traffic situation to make predictions. One should take the trajectory of surrounding vehicles into account in some manner. It would be possible to test whether such networks can encode the vehicle’s trajectory under investigation with the information of vehicles moving around it. An autoencoder network should be trained for yielding the future trajectory of the vehicle to the output by feeding the historical trajectory of the ego vehicle and the surroundings to the input. It is possible to separate the input encoding (and copying) task to the prediction task. In other words, on the one hand, one can train to predict the future trajectory, but one can also train the method to predict in latent space. In the latter case, it is quite simply a matter of a separately trained device encoding the trajectories and mapping them into the latent space, followed by another performing the prediction on the context vector from which the decoder decrypts the future trajectory.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}