2.1. Cone Penetration Test (CPT)
In a CPT, a cone with a specific diameter gets pushed vertically into the ground under a constant rate. Based on the measured data, e.g., tip resistance q
c and sleeve friction f
s, various soil behavior charts were developed to identify the soil strata and soil behavior types [
9,
10,
11,
12,
13]. Additionally, various empirical correlations have been published for a quick and easy interpretation of CPT data (including parameter determination). However, these correlations are generally not applicable to all soils and subsurface conditions and might need to be validated before their application (e.g., for over-consolidated soils [
14,
15] or reclaimed fills [
16]).
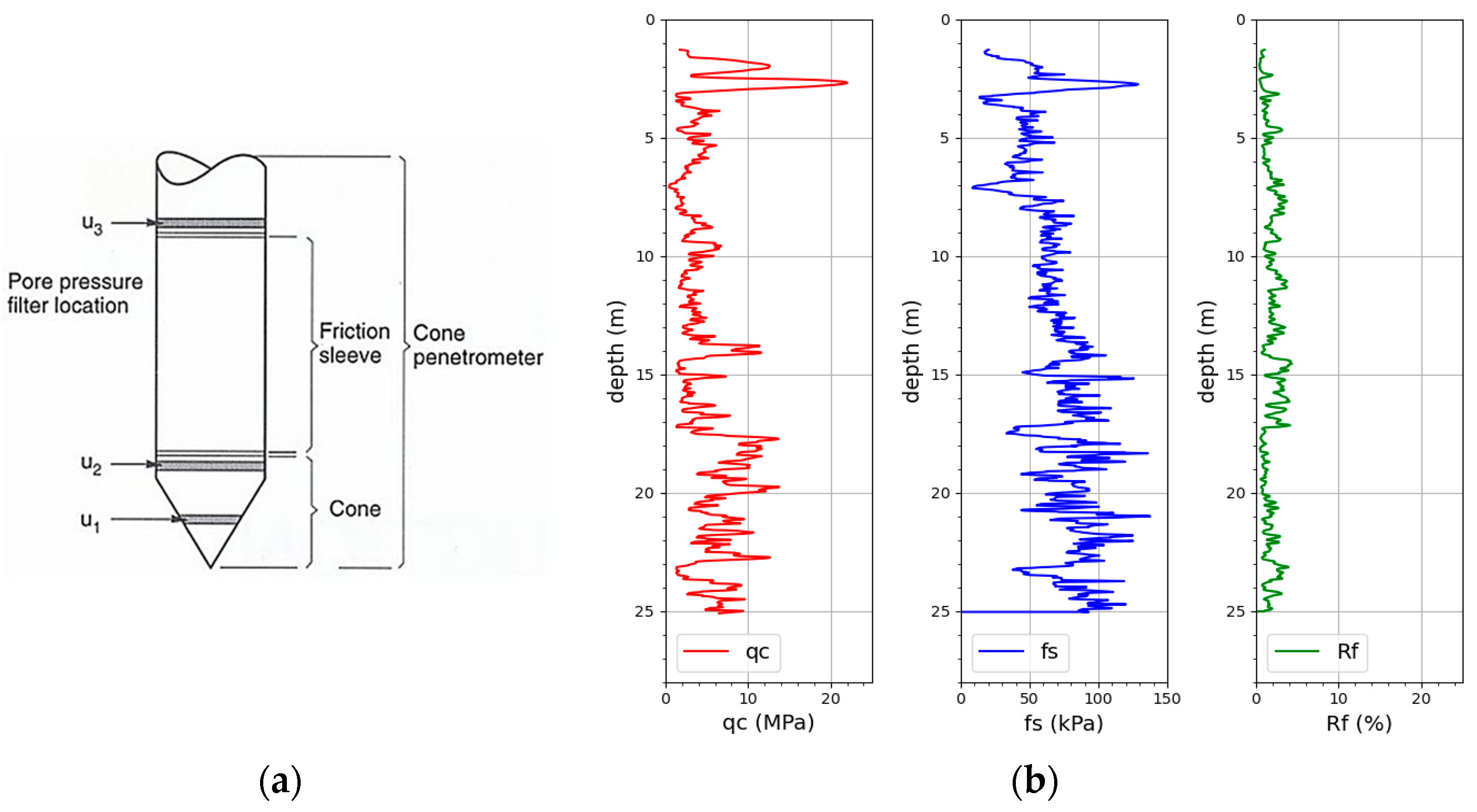
Figure 1a shows the scheme of the cone and
Figure 1b shows a plot of the measured tip resistance q
c, sleeve friction f
s and the resulting friction ratio R
f (f
s/q
c in percent). In a piezocone test (CPTu), additional pore-pressures, due to groundwater (and installation effects) are measured (u
1, u
2, u
3). In a seismic cone penetration test (SCPT, SCPTu), the shear wave velocity Vs at specific penetration depth intervals (usually 50–100 cm) is measured. CPTs are mainly performed to determine subsoil conditions, such as soil type and strata, and to estimate geotechnical parameters (e.g., effective friction angle φ’, cohesion c, etc.) [
17]. The disadvantages of a cone penetration test are that its application is limited to predominantly fine-grained soils and that the subsoil is not visible to the engineer. Therefore, the CPT tests are usually complemented by core drillings to verify the applicability of the correlations (e.g., for parameter identification).
2.2. Dataset
The dataset consists of 1339 CPT tests from sites in Austria and southern Germany. All tests were performed by the company “Premstaller Geotechnik ZT GmbH”. For the tests, a CPT-truck or CPT-rig with a standardized 15 cm² probe was used.
For the interpretation, the test data were processed with the software bundle CPeT-IT of Geologismiki to identify the soil behavior types according to Robertson [
9,
10,
11]. Additionally, 490 of them were classified based on grain size distribution from adjacent boreholes.
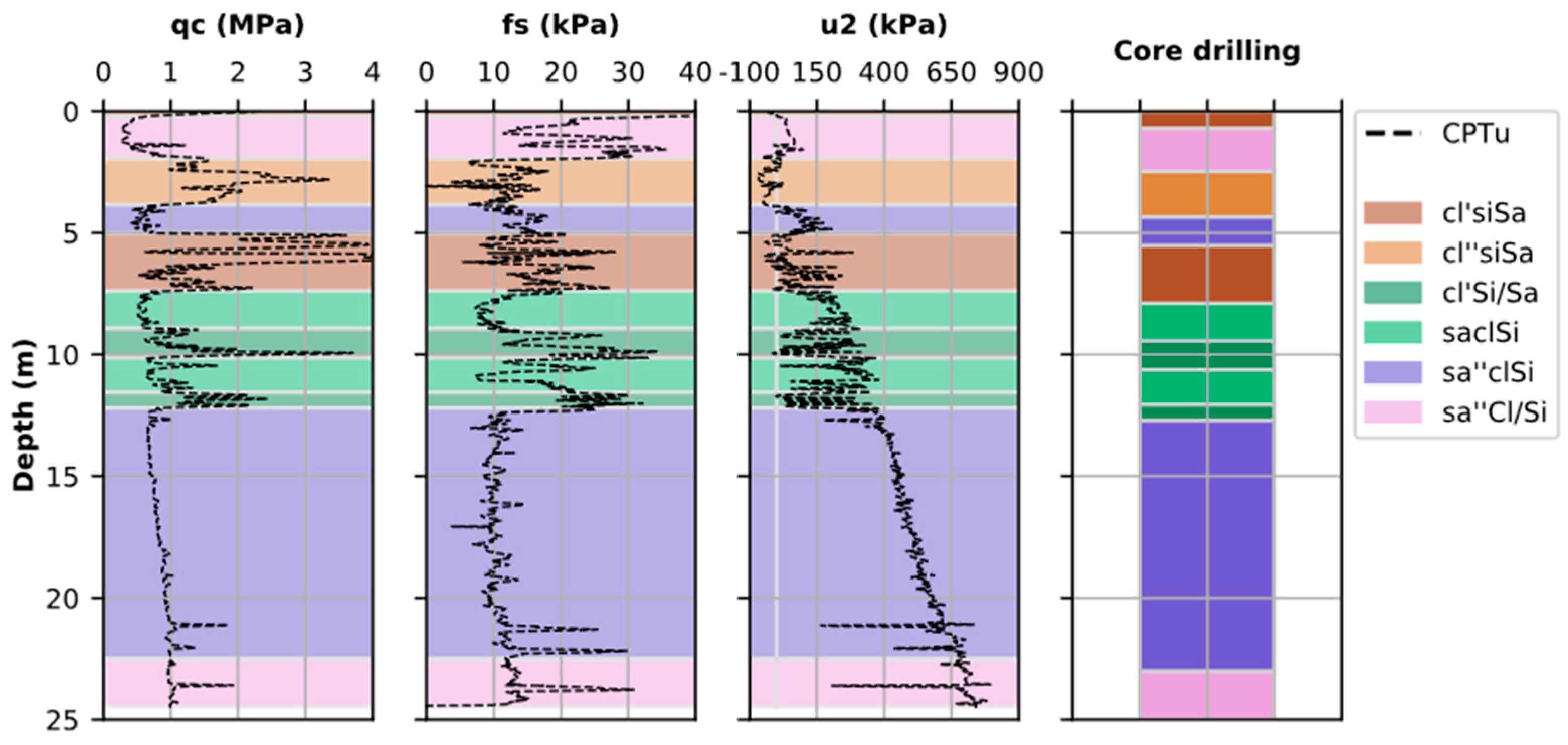
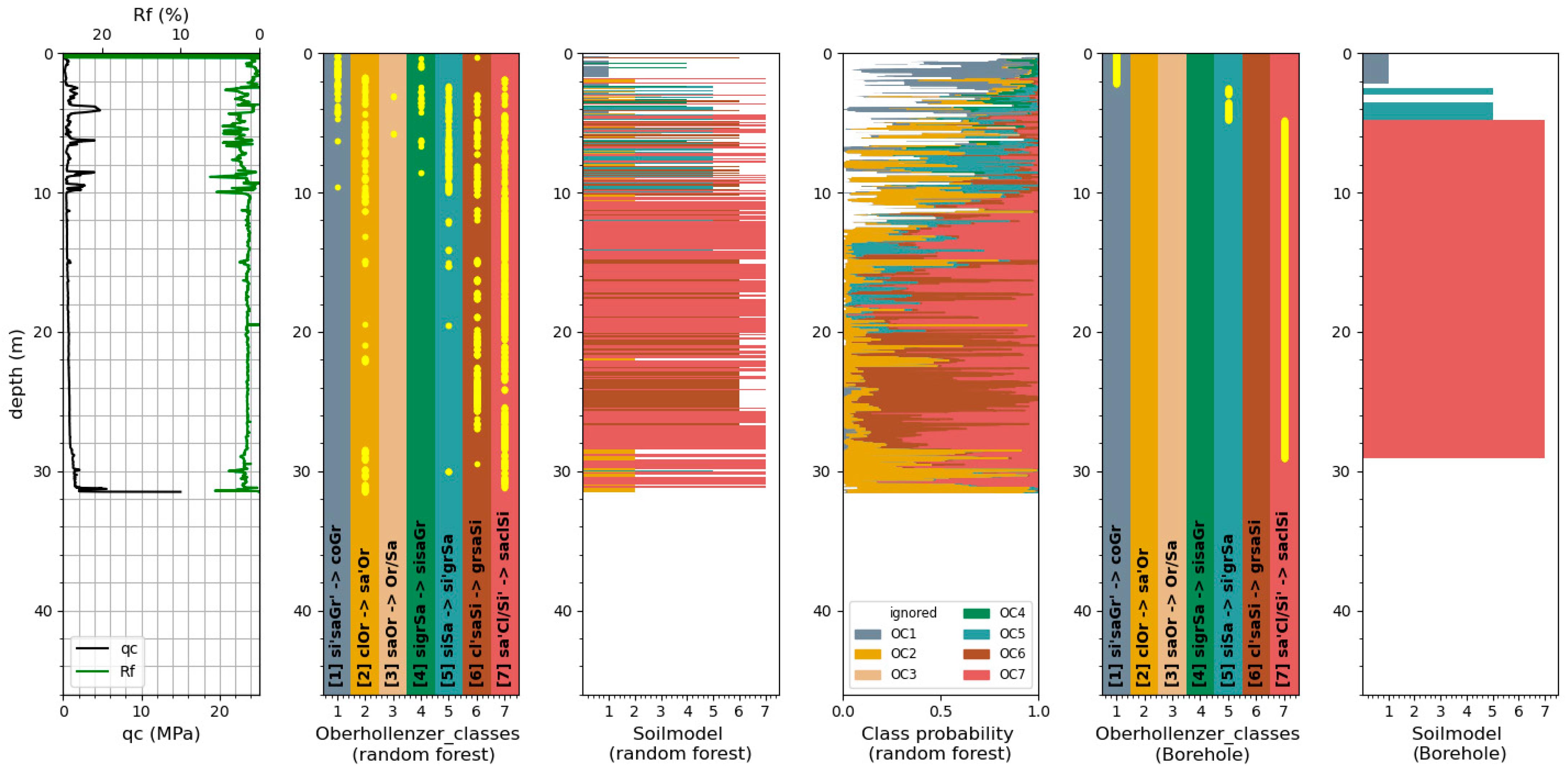
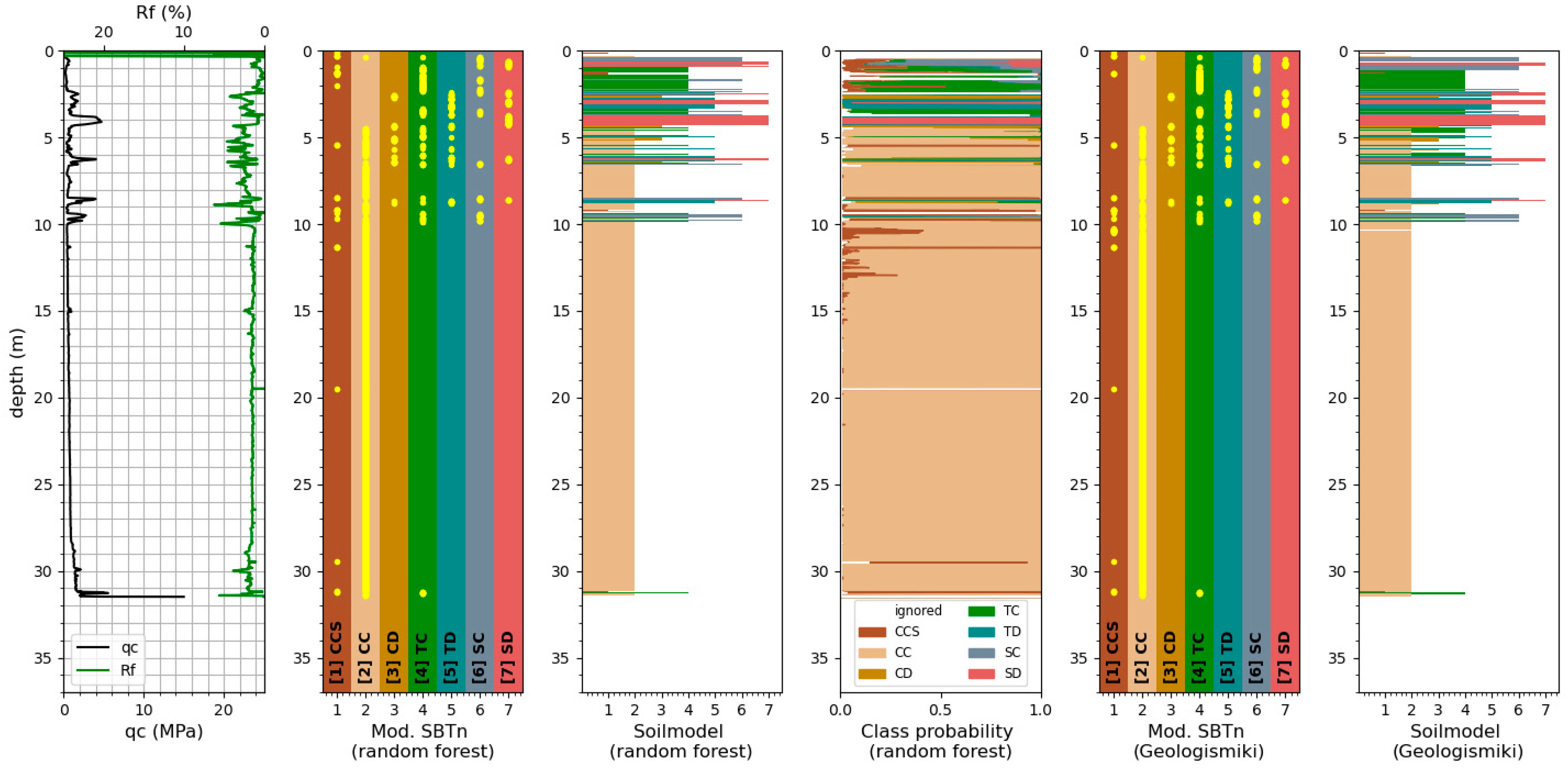
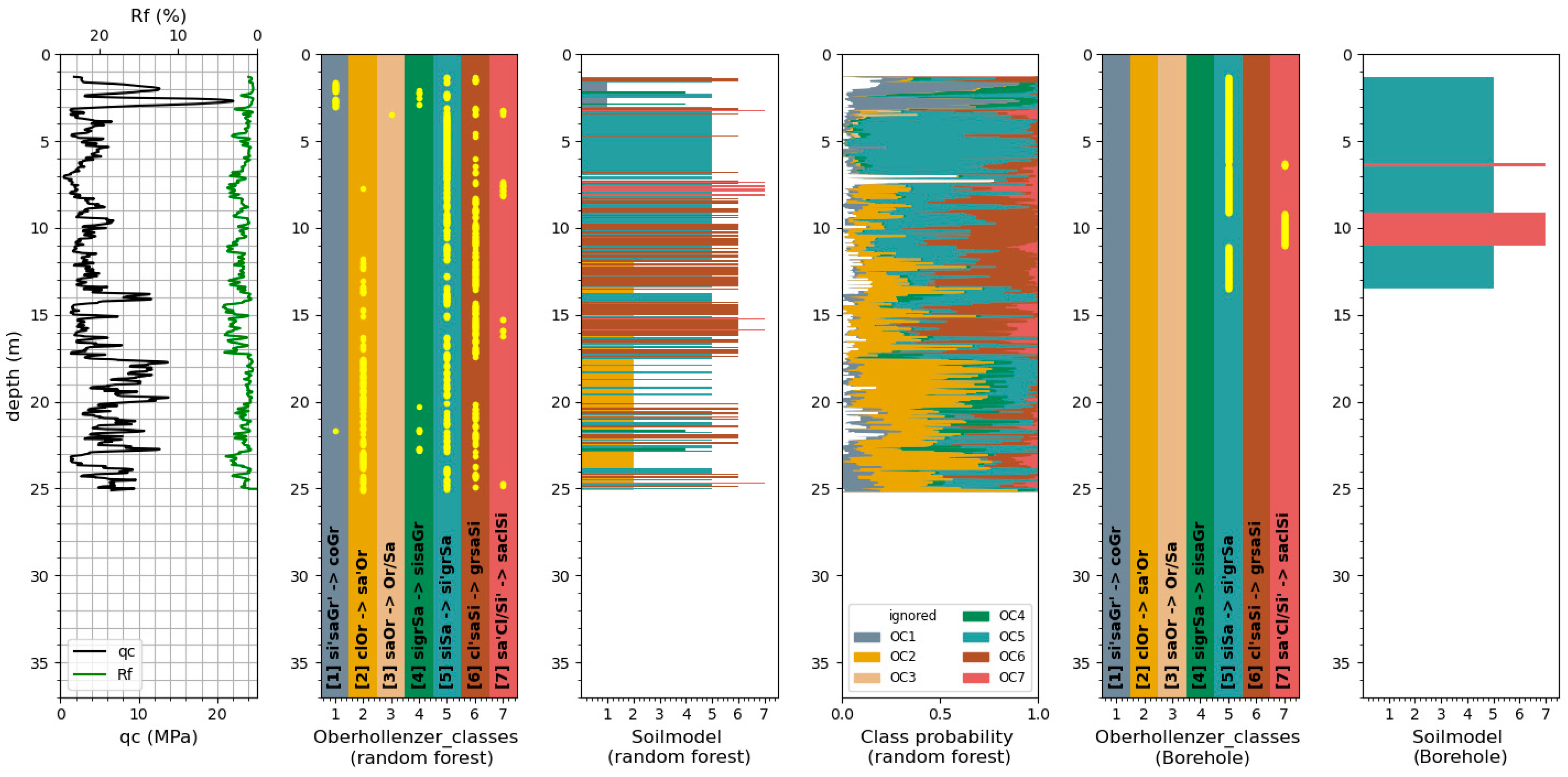
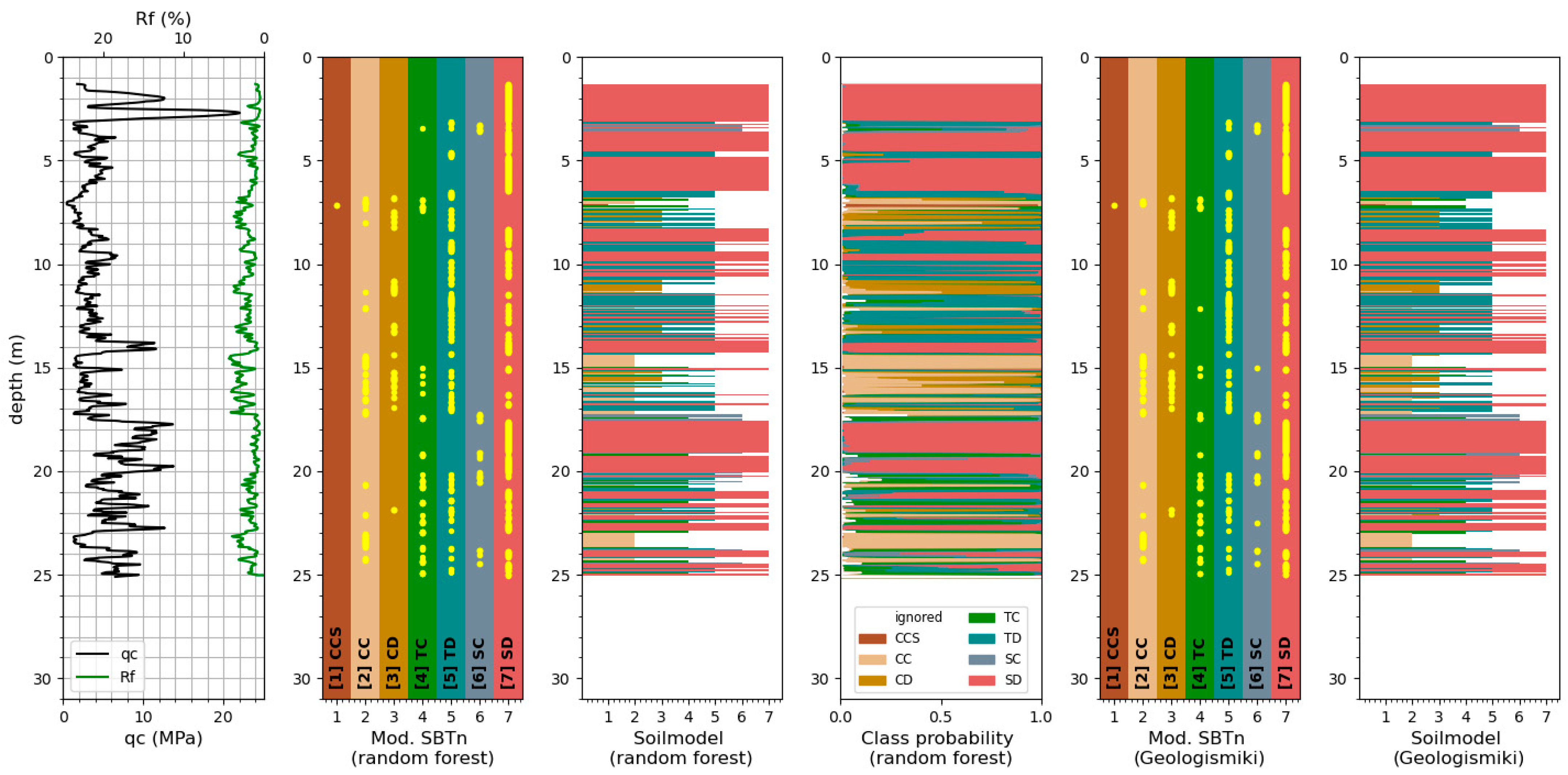
Figure 2 shows an example of the assignment of soil classification from borehole samples to the CPT data. The maximum distance between the CPT test and its adjacent borehole is approximately 50 m. Differences in the position of the soil layer changes, due to the distance between the CPT and borehole, were considered by manually adjusting the location of the soil layers by Oberhollenzer et al. [
8].
The database contains 28 columns and 2,516,978 rows. The feature columns are distinguished in raw test data, data defined by an engineer and data based on empirical correlations (using the test and defined data). Measurement errors and outliers are eliminated by setting threshold values for the measured data of −100 and +10,000. Datapoints which exceed those boundaries are left blank.
The soil behavior types determined with the software package of Geologismiki [
18] are based on the publications of Robertson from 2009, 2010 and 2016. In 1986, Robertson published the first chart for soil classification based on the cone penetration test data. With the cone resistance q
t (Pa), the friction ratio R
f (%) and the pore pressure ratio B
q (-), the chart distinguishes between 12 behavior types for predominantly fine-grained soils [
13]. In 1990, Robertson provided a new soil behavior type classification based on normalized, and thus adapted to ground water conditions, CPT data. Additionally, the number of soil behavior types was decreased to nine [
12]. An updated version of this chart using normalized parameters was published in 2009, where the normalized soil behavior types are determined by the soil behavior type index, I
c (-) (Equation (3)), which is calculated with the normalized cone resistance Q
t (-) and the normalized friction ratio F
r (-) [
9]. In 2010, Robertson published an updated version of the soil behavior chart from 1986, where the 12 behavior types were adjusted to the nine types of 1990 [
10]. Instead of q
t (Pa), this chart uses the dimensionless cone resistance q
c/p
a (-), where p
a (Pa) is the atmospheric pressure, and the friction ratio R
f (%), on both log scales. In 2016, Robertson published a new version of the soil behavior types, where the chart distinguishes between soil beyond the type, based on its behavior under loading. This is based on the updated normalized cone resistance Q
tn (-) (Equation (1)) and the normalized friction ratio F
r (%) (Equation (4)) [
11]. The discussed soil behavior type charts are provided in
Figure 3.
where
n (-) is the stress exponent (Equation (2) and ≤1, which is based on the soil behavior type index
Ic (-) (Equation (3)).
As mentioned above, an additional soil classification based on grain size distribution from adjacent boreholes was assigned to the 490 CPTs in the dataset by Oberhollenzer et al., in 2021 [
8]. In this project, the borehole samples were classified according to ESCS [
7]. Due to the fact that the soil classification of the borehole samples was performed by different engineers, the determined soil classes spread with regard to their denotation. Oberhollenzer et al. [
8] summarized all classifications into seven different soil classes, henceforth called Oberhollenzer_classes (OC). These soil classes are summarized in
Table 1. Classes which could not be assigned to one of the seven classes, e.g., due to the too widely spread classifications, are summarized in class 0 (ignored classifications).
2.2.1. Data Pre-Processing
In the pre-processing step, the dataset is evaluated with regard to its completeness and amount of data.
Since the number of samples is sufficiently high, rows with not a number (NAN) or null entries are deleted. For the learning models using grain-size-based soil classes as targets (Oberhollenzer_classes) 1,025,284 samples are available and, for the learning models using soil behavior types (SBT, SBTn, Mod. SBTn) as targets, 2,514,262 samples are available.
Table 2 provides the mean, standard deviation, and numerical range of the input features.
For every target, two different sets of features are defined for training: one where only directly measured data, namely, qc, fs, Rf, and the depth are considered, and one where the total and effective vertical stresses σv and σ’v, as well as the hydrostatic groundwater conditions u0, are additionally considered. This leads to a total number of 24 models which are investigated in this study. Note: It was the intention of the authors to utilize as many data as possible to train the ML models, but only 362 CPTs were performed as CPTu. Therefore, it was decided to use qc instead of qt as an input feature.
The split of the data into subsets for training and validation and testing was done with the scikit-learn feature “train_test_split”, which randomly splits the samples into two datasets. The ratio of training and test data is defined as 80/20.
To ensure the uniform contribution of each feature to the training and prediction process, the features are scaled using the “StandardScaler” module. The features are scaled between −1 and +1 while the median is kept on the same level; therefore, the data are not biased by this process.
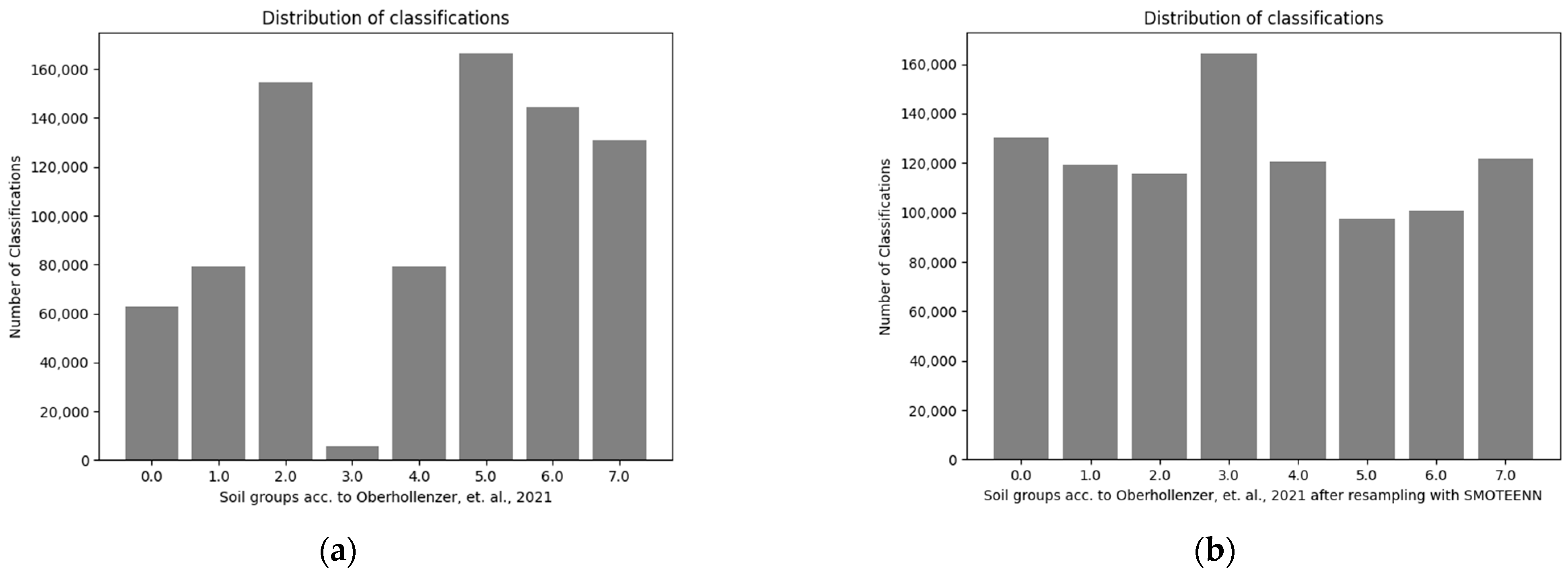
The uneven distribution of data between the classes could cause problems for the prediction performance of many machine learning algorithms. Unbalanced datasets can affect the learning model, e.g., if one class is highly underrepresented compared to the rest of the dataset, the model might ignore this class and still compute sufficient accuracy, but if the goal of the model is to find this specific class, then the model might be completely useless. In this study, the class balance of the data is considered within the Random forest models by setting the model parameter “class_weight” to ‘balanced’. This setting assigns a higher penalty to wrong classifications in minority classes. Another possible way to handle unbalanced data is the application of resampling algorithms. Two popular algorithms for this task are SMOTEENN and SMOTETomek. Both algorithms resample the data using a combination of under- and oversampling, which means that underrepresented classes are filled with synthetic data (which is based on the already available data), and data of overrepresented classes are removed, while statistical parameters like the mean and median of the data are kept on the same level. The difference between raw and resampled data is shown in
Figure 4.
Preliminary studies showed that the application of these algorithms did not improve the overall model performance in this study and, additionally, the Random Forest models were barely susceptible to unbalanced data. Therefore, all models were trained with unbalanced datasets. More information on the sampling algorithms is provided on the imbalanced learning website [
19].
2.3. Machine Learning Models—General Information
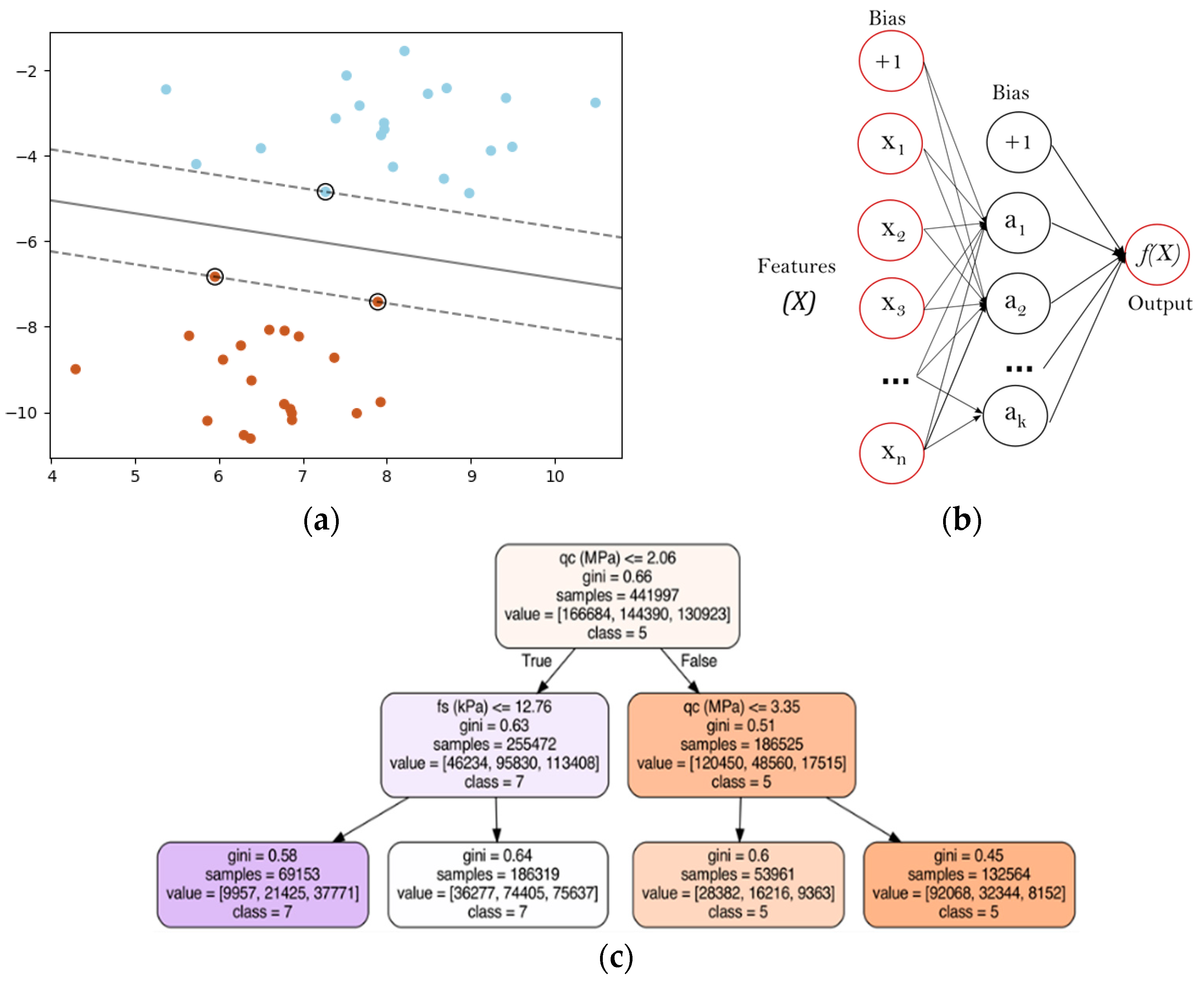
Machine learning (ML) has become a popular tool in various sciences for the interpretation of large datasets. The difference in the function principle of machine learning models compared to common computing algorithms is mainly that, rather than computing the results from an input and a predefined solution, the ML model finds a solution by learning from the input (features) with the respective output (targets), regardless of the specific algorithm (ANN, RF, etc.). The present study evaluates three different machine learning algorithms, namely, the Support Vector Machine, Artificial Neural Network and Random Forest. Their function principles are described briefly in the following section (
Figure 5).
The Support Vector Machine (SVM) is a supervised learning algorithm for classification, regression, and detection of outliers [
20]. For different tasks like classification and regression, the separating hyperplanes in a high or infinite dimensional space with the largest margin are to be found by the algorithm. The larger the margin, the lower the generalization error of the model.
Figure 5a shows an example of a linear SVM. The samples on the boundaries are called support vectors. SVMs have recently been used in geotechnical engineering for soil classification [
21], to estimate the bearing capacity of bored piles from CPT data [
22] or for the assessment of soil compressibility [
23].
The Artificial Neural Network is based on the function principle of a brain, and consists of three different types of layer (
Figure 5b): first, the input layer, where the input features are handed to the model, second, the hidden layer(s), where the information of the input layers is combined with the weights, and third, the output layer, where the results are computed. The applied neural network in this study is a backpropagation algorithm, which is trained iteratively. Then, the output of the model is compared with the real targets of the training set to calculate the error and update the weights in the hidden layer(s). This process is performed until a minimum error is reached or the incremental improvement between iterations reaches zero. In recent research, ANNs have been used to classify soils from CPT data [
3], identify soil parameters [
24] or estimate the cone resistance of a cone penetration test [
25].
The Random Forest (RF) is an ensemble of decision trees. A decision tree is a non-parametric supervised learning method that can summarize the decision rules from a series of data with features and labels, and use the structure of the tree to present these rules to solve classification and regression problems [
26]. The solution of decision trees is comprehensible, and it is possible to identify the contribution of each input feature to the classification or regression model. Random forest models were recently used to predict the pile drivability [
26], estimate geotechnical parameters [
24] and, notably, the undrained shear strength [
6].
Figure 5c shows an example of a decision tree with two splits for an ML model with two input features and three targets. The first line of the node provides the decision function; the second line provides the Gini impurity, which represents the probability of a random datapoint being classified as wrong and indicates the quality of a split (0.0 is best case; 1.0 is worst case). The third line indicates the number of samples which are observed in the node. The fourth line provides the final classification of the observed samples. The last line provides the most common resulting class, which was observed in the node [
20].
The hyperparameter settings and input features of the applied machine learning models for this study are described in the following sections. All models are built on a MacBook Pro 13” 2018 (CPU: INTEL core i5 2.3 GHz quad core, RAM: 8 GB, GPU: Intel Iris Plus Graphics 655 1536 MB) using the SPYDER python environment. The Machine Learning algorithms used are part of the open-source-software library of scikit-learn [
20].
2.3.1. Support Vector Machine
The evaluated Support Vector Classifier (SVC) uses a linear kernel function in order to keep training times low. A change in the kernel was investigated and showed that, for this interpretation, a radial basis function does not significantly improve the prediction accuracy but considerably increases the necessary learning time. The SVC models targeting soil classes based on grain size distribution (Oberhollenzer_classes) are evaluated without further hyperparameter modifications. The training and evaluation of SVC models targeting soil behavior types were cancelled due to the long necessary training time (compared to the other models), which exceeded 24 h. In contrast, the training times of ANN and RF models are within a few minutes.
Table 3 shows the originally planned models for the support vector classifier. However, as stated above, only the two models for Oberhollenzer_classes are further analyzed and compared to the Artificial Neural Network and Random Forest models.
The influence of class balance on the model quality was considered by setting the hyperparameter “class_weight” to ‘balanced’. Then, the penalty size for wrong predictions is assigned with respect to the amount of data in each class. This leads to a higher penalty for wrong predictions in minority classes. The evaluation of the obtained results shows that, in the considered problem, the overall performance of the SVM models does not increase when considering the class balance with the hyperparameter “class_weight”. Sampling algorithms are not used for the SVM models.
2.3.2. Artificial Neural Network Models
The artificial neural network models are built using the MLPCLassifier module of the scikit-learn library. The network size is chosen based on recommendations provided by Heaton [
27]. Similar to the support vector classifier, eight different models are analyzed. The best combination of hyperparameters is evaluated and determined using grid search techniques, where a range for each parameter is defined. The chosen hyperparameters are then validated using cross-validation. In order to keep the training times within acceptable limits, the number of hidden layers is set to a maximum of three and the number of neurons in these layers is set to a maximum of 10. (Note: It would be possible to increase the number of hidden layers and neurons, which would also slightly increase the prediction accuracy of the models. However, the training times would increase significantly, and thus would no longer be comparable to the training times of Random Forest models).
During the grid search analysis, a range of settings was tested for the number of hidden layers, the number of neurons, the activation function, the learning rate and the solver. For the activation function, learning rate and the solver modifications, aside from the default settings, do not significantly increase the model performance; therefore, the default parameters are used for model evaluation. The number of hidden layers and neurons are evaluated in individual steps. First, three sets with one, two and three layers of 10 neurons are evaluated. Then, three different sets of neurons in one layer are evaluated. The best combination was identified with three layers of 10 neurons for both targets, the soil classes based on grain size distribution and soil behavior types. Note: To obtain the best possible prediction accuracy for soil classes based on grain size distribution, the number of hidden layers and neurons must be increased further. This would result in a higher accuracy of about 8–10%. However, the resulting model accuracy is still much lower (10–15%) compared to the Random Forest models (see next chapter). Therefore, it was decided to keep the training times comparable in this study, within the range of from 10 to 30 min. The further optimization of the prediction with neural networks with deeper and more sophisticated networks is part of the ongoing research at the Institute of Soil Mechanics, Foundation Engineering and Numerical Geotechnics at Graz University of Technology.
2.3.3. Random Forest Models
The Random Forest classifier used in this study is part of the ensemble learning module of scikit-learn. Similar to the ANN models, the best set of hyperparameters is determined via cross-validation. Additionally, cross-validation is used to plot learning and validation curves to identify the bias and variance of the model. Cross-validation and hyperparameter tuning are performed for the models targeting Oberhollenzer_classes and soil behavior types. Since the properties of all soil behavior types are quite similar, they are only performed once for all models targeting soil behavior types (SBT, SBTn, ModSBTn). An overview of the models based on the random forest classifier is provided in
Table 3.
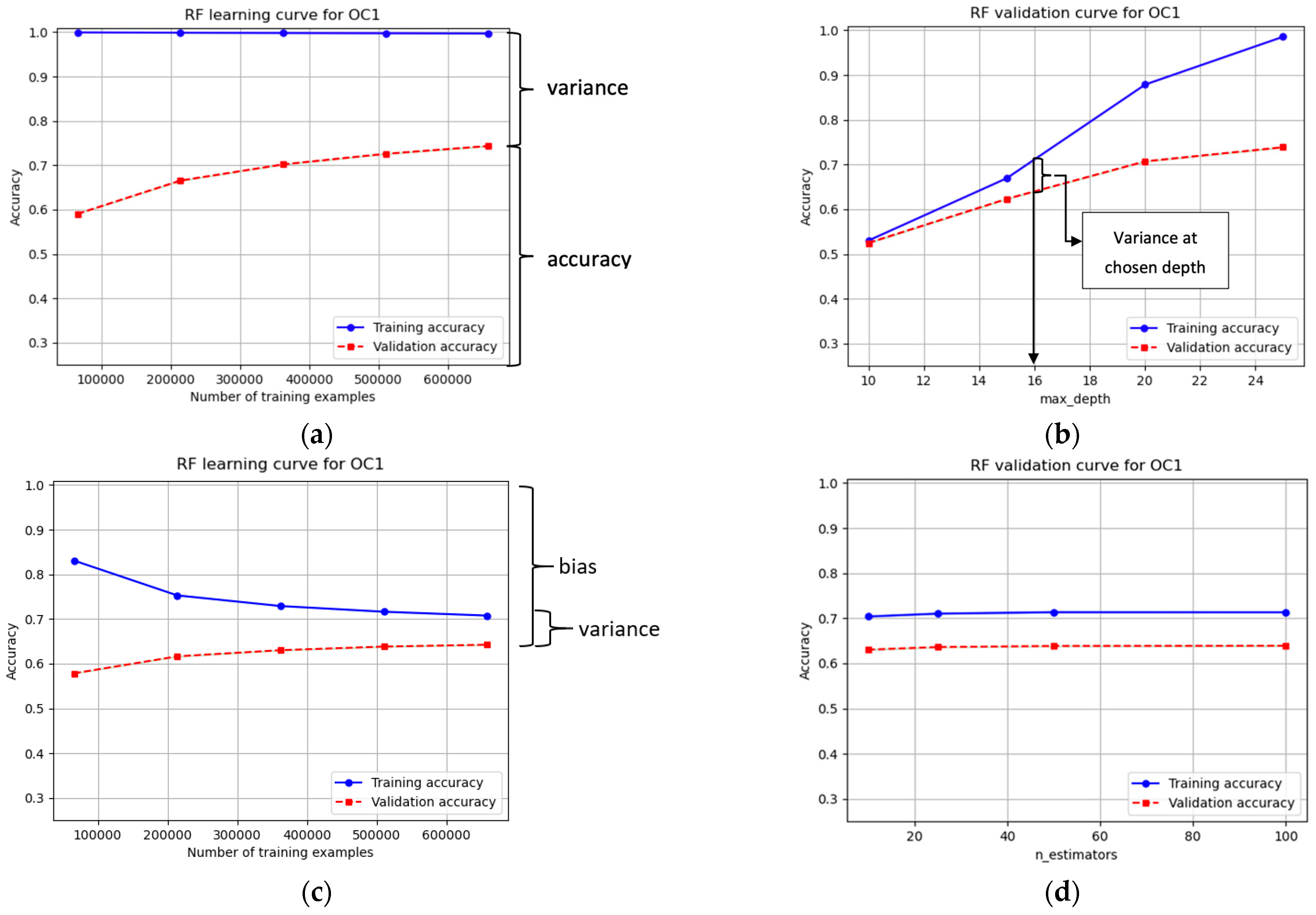
The RF models are analyzed using learning and validation curves to visualize bias and variance, which indicates susceptibility to over- or underfitting. In order to obtain a robust model, bias and variance should be kept low [
28]. The difference between training and validation accuracy is referred to as variance. High variance causes a model that is not able to generalize very well, which results in a much higher training accuracy than validation accuracy. A high bias means that the data are too complex for the model. One of the main hyperparameters governing bias and variance of an RF model, is the maximum size of each tree (“max_depth”) in the forest.
Figure 6 displays the process of hyperparameter optimization. In the learning curve without the limitation of tree-size (
Figure 6a), the curves show high variance. By plotting the validation curve (
Figure 6b), the influence of a specific hyperparameter, in this case the “max_depth” is visualized. After adjusting the settings for the respective hyperparameter (in this case, to 16), the learning curve is plotted again (
Figure 6c), and a reduced variance of nearly 20% can be seen. By reducing the variance, the bias also increases (in this case, ~10%); therefore, a good trade-off must be found. Compared to the size of each tree, the number of trees (n_estimators) does not influence the bias and variance of the model, which is shown in
Figure 6d.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}