1. Introduction
The dairy farming industry is crucial in providing essential nutrients to the human population, including high-quality protein, energy, vitamins, and minerals. As the annual milk production of cows increases, their nutritional requirements also rise throughout the production cycle. The simultaneous demands of milk production and reproduction in dairy cows necessitate careful nutritional management to achieve optimal production and consecutive breeding. Livestock farmers must provide for their cows’ nutritional needs at each production stage based on their output level. Overfeeding can cause obesity, decreased milk production, infertility, and metabolic disorders such as ketosis and fatty liver [
1]. Farmers must balance increasing milk production with providing nutrient-rich feeds to meet the cows’ needs.
On the other hand, failure to meet nutritional needs can result in weight loss, decreased production, infertility, gestation, and delivery problems. It is crucial to ensure that dairy cows receive balanced and adequate nutrition to prevent these issues and promote their overall health and productivity [
2]. Advancements in dairy technology have increased the demand for dairy products. This increased demand has eliminated the need for farmers to seek buyers actively and increased the number of cattle per farm [
3]. As a result, farmers have less time to spend on each cow. Precision dairy farming technology has gained popularity among farmers and the industry due to its ability to increase efficiency and profitability while reducing workload [
4,
5].
As the scale of dairy operations expands, the task of monitoring cows grows more intricate and requires enhanced management skills. Adopting automation and sensor systems, known as precision technology, allows farmers to reduce labor requirements, improve resource efficiency, and improve cows’ health and welfare [
6,
7,
8].
Daily rumination patterns are widely recognized as crucial indicators of individual cows’ health and productivity. Measuring these parameters can provide valuable insights into nutritional physiology for research purposes [
9]. In dairy farming, early detection of physiological and behavioral changes or abnormalities is essential to minimize losses in milk yield and health costs. Automated monitoring of feeding behavior and activity can serve as both a valuable research tool for scientists and an early warning system for farmers [
10]. Currently, various technologies are available for monitoring different aspects of animal behavior and health, including developmental activities [
11,
12] and feeding behavior [
13,
14,
15]. However, many of these technologies have limitations, such as being able to measure only one type of behavior or being less practical for everyday use. Some systems may require specialized training or be challenging to install and maintain. Consequently, it is imperative to engage in further investigation and advancement in this domain to generate more efficient and accessible mechanisms for animal surveillance and administration.
Cow audio recording while eating is a relatively new field of research that has gained significant attention in recent years. By utilizing sound sensors to recognize cow chewing behavior, researchers can monitor these animals’ health and physiological status [
16]. This technology provides numerous benefits to farmers, allowing them to monitor their cows’ health and physiological status more efficiently and accurately. By recognizing chewing behavior, farmers can judge the health status of their cows and make informed decisions about their care. Additionally, cow audio recording can be integrated with other technologies to develop real-time monitoring systems for livestock [
17]. One study employed a neural network to recognize chewing behavior by inputting many labeled ruminating and eating audio data into the network [
18]. Another research proposed a semi-automatic tool for labeling monophonic cow sound events, allowing users to quickly designate the temporal onset and offset points for audio events or make new annotations [
19]. One study monitored and assessed ingestive chewing sounds to predict herbage intake rate in grazing cattle. The study found that by utilizing sound sensors to recognize cow chewing behavior, researchers could accurately predict herbage intake rates in grazing cattle [
20]. Another study developed a web-based monitoring and recording system based on artificial intelligence analysis to classify cattle sounds. The deep learning classification model is a convolutional neural network (CNN) model that takes voice information converted to Mel-frequency cepstral coefficients (MFCCs) as input. The developed model was applied to cattle sound data from an on-site monitoring system through sensors, achieving a final accuracy of 81.96% [
21].
The hypothesis of this study posits that it is possible to distinguish between chewing and ruminating states in dairy cattle based on the analysis of sound signals captured by microphones installed near the cows’ mandibles. Therefore, the present research study explores cows’ feeding behavior to comprehend their nutritional needs and feeding habits. The study examines the audio recordings of cows during their feeding process to evaluate the frequency and patterns of their chewing and rumination. Through this analysis of cow behavior, the study aims to enhance the understanding of animal health and welfare and facilitate the development of more efficacious feeding practices for cattle farmers and ranchers. The outcomes of this study are anticipated to be pertinent for researchers and industry professionals.
3. Results
By transforming the sound signals emanating from feeding cows in different modes into visual representations, the resultant textural features of the images were regarded as potential attributes for employment in the classifier under investigation. Algorithms related to texture (GLCM, GLRLM, GLDM, and SGLDM) were used to classify jaw movements [
56,
57]. A total of 31 textural features were extracted from the images. However, only a few of these features were effective in classification performance. Therefore, in this study, feature selection consists of two main goals; the first goal involves eliminating irrelevant and non-informative features, and the second goal is to utilize sound and relevant features to enhance classification accuracy and speed.
A GA was employed for feature selection, which involves identifying the most pertinent and significant features from a large set of available features. The textural features extracted from images were entered into the GA to select the optimal features and enhance the classification performance. As illustrated in
Figure 3, entropy, energy, local homogeneity, contrast, and inverse difference moment normalized were identified as the most impactful features, with performance percentages of 52%, 68%, 76%, 88%, and 98%, respectively.
In the process of analyzing jaw movements, it is anticipated that varying levels of sound intensity would be generated due to the significant impact of the lower jaw colliding with the upper jaw in each of the states—biting, chewing, chewing-biting, and sorting. This variation in sound intensity is represented as entropy, which measures the randomness or complexity of the image. A higher entropy value indicates more complexity and less uniformity. It is implied that an increase in sound intensity correspondingly increases the image energy, as the intensity of these generated sounds is directly proportional to the energy of the image. Higher energy values indicate more uniformity and less complexity. An uneven image matrix results from the sudden impacts of the jaw during biting and chewing-biting. This non-uniformity is expected to be reflected in the feature of local homogeneity, which measures the closeness of the distribution of elements in the GLCM to the GLCM diagonal. Images with a high degree of local homogeneity have pixel pairs with similar intensity. Image contrast is among the features selected by the genetic algorithm, as fluctuations in pixel intensity serve as an indicator thereof. Contrast measures the amount of local variations present in an image. During the chewing and sorting state, where sound intensity is relatively uniform, an image with uniform pixel intensity is anticipated. This is expected to align with a descriptor of grayscale color distribution uniformity in the image, represented as inverse difference moment normalized (IDMN). IDMN is a measure of the homogeneity of an image and gives higher values for homogeneous images.
Valuable insight into the characteristics of jaw movements is provided by these texture features and can be used to accurately classify different states. These features were identified as impactful because they capture essential characteristics of jaw movements. Entropy and energy can capture the complexity and uniformity of jaw movements, respectively. Local homogeneity can provide information about the similarity in jaw movements, while contrast can capture the amount of variation in these movements. Lastly, IDMN can provide a measure of how homogeneous these movements are.
Upon selecting the most prominent features, they were input into six classifiers: SVM, KNN, decision tree, MLP, naive Bayes, and k-means clustering. As depicted in
Table 2, the highest precision values for all classifiers corresponded to the biting state with respective values of 99.21%, 97.91%, 97.04%, 100%, 96.17%, and 93.61% for SVM, KNN, DT, MLP, Naive Bayes and K-means Clustering, respectively. Compared to other states, such as chew, chew-bite, and sort, the accuracy of detecting the biting state was elevated. This can be attributed to its higher sound intensity level and distinctiveness, which is evident across all classifiers. In contrast, the lowest precision values for all classifiers were associated with the chewing-biting state, with respective values of 89.07%, 86.12%, 82.14%, 86.21%, 84.12%, and 79.87%. This can be attributed to the interference caused by the overlapping sound intensity of signals generated by jaw movements in both chewing and chewing-biting states, presenting a significant challenge for all classifiers. Based on the classification results, the most effective classifiers for biting, chewing, chewing-biting, and sorting states were identified as MLP, KNN, SVM, and SVM, respectively, with respective values of 100%, 97.91%, 89.07%, and 97.73% Conversely, the least successful classifiers for these states were the first three modes k-means, and Bayes, with respective values of 93.61%, 91.53%, 79.87%, and 92.79%.
A decrease in sensitivity was observed across all classifiers due to the misclassification of chewing-biting and sorting data within the biting category and the misclassification of chewing-biting data within the chewing category. Although MLP and KNN classifiers performed better in classifying biting and chewing states than the SVM classifier, SVM outperformed both in classifying chewing-biting and sorting. Overall, the SVM classifier showed higher accuracy and sensitivity in classifying all four mentioned states than other classifiers. The highest average F1 score (95.66%) was obtained using the SVM algorithm, which consistently exhibited higher F1 scores than other classifiers and clustering methods across nearly all instances of jaw movements.
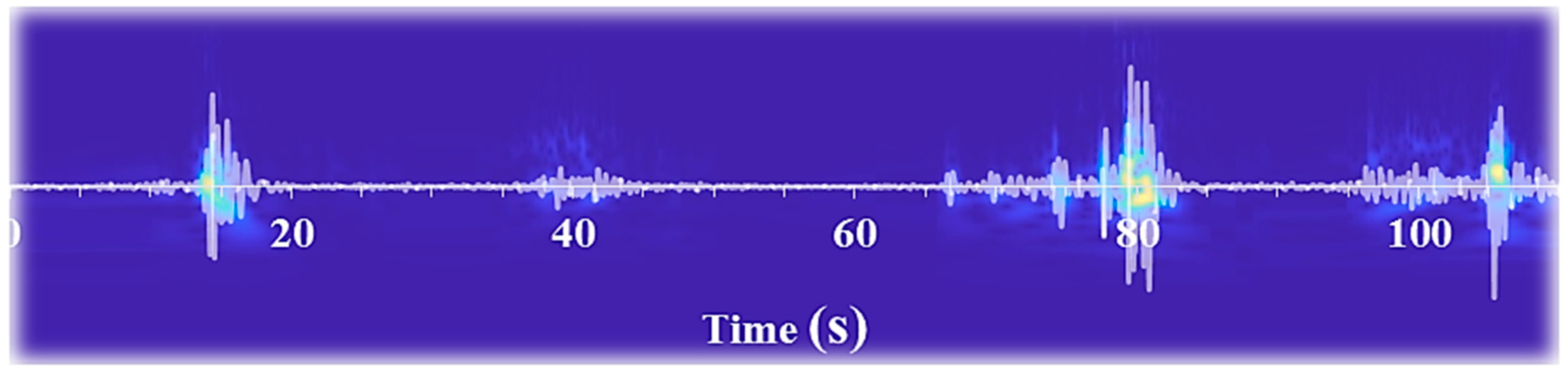
The images derived from the transformation of bovine mandibular movements during feeding were scrutinized for conformity concerning the temporal intervals of the events. To facilitate a comparison between the timing of each action, including biting, mastication, chewing-biting, and sorting, in both audio signals and images, the audio signals were superimposed onto the images and subjected to visual analysis.
Figure 4 exemplifies this comparison, highlighting that the timing of each action coincides with abrupt fluctuations in image intensity within the corresponding time intervals. Furthermore, it is anticipated that the energy level of the image also increases at the peak points of the sound, which was precisely observed. Thus, by employing intelligent image thresholding, all events arising from the animal’s mandibular movements during feeding can be ascertained regarding their timing and range. In this regard, the classifiers mentioned above can be employed.
Figure 5a illustrates the transformation of an audio signal resulting from the mandibular movements of a cow during the feeding process. As observed in the image, the variation in sound intensity creates a color spectrum ranging from magenta to yellow, where magenta represents the lowest sound intensity, and yellow indicates the highest sound intensity. Since magenta represents the lower sound produced from the jaw movement of the animal, regions consisting solely of magenta color can be associated with chewing. Additionally, the yellow points denote pronounced impacts between the upper and lower jaws or mandibular movements of the cow while selecting the best nutritional content in the food (a process known as sorting).
In light of this observation, three alternative interpretations may be proposed. The first interpretation refers to the points created by the proximity of yellow regions, which exhibit markedly low magenta color intensity. This phenomenon may be attributed to the biting process, as there are strong collisions between the upper and lower jaws during this action, generating a high-intensity sound. In this state, chewing is absent, as evidenced by the minimal presence of magenta regions. The second interpretation concerns the appearance of yellow-colored points close to magenta areas. When the animal commences sorting food for desirable nutritional content using its jaw, it produces a high-intensity sound. The number of yellow regions in the image is anticipated to be larger than the chewing-biting state. The third interpretation involves a higher amalgamation of magenta and yellow colors, representing the concurrent occurrence of biting and mastication. In this state, the magenta combined with yellow is higher than in all states, as mentioned earlier.
Figure 5b–g illustrates the outcomes of thresholding utilizing the mentioned classifiers. The images show that the MLP classifier has demonstrated superior performance in pixel thresholding, whereas k-means clustering has exhibited inferior performance. Upon further evaluation of the classifiers, it may be asserted that their performance has been satisfactory. However, detecting chewing pixels and their subsequent thresholding has presented difficulties and challenges for both the naive Bayes and decision tree classifiers.
4. Discussion
The present study successfully classified cow mastication sounds into four classes using vibration analysis. The study employed a rigorous approach to feature selection, using a GA to identify the most pertinent and significant features from a large set of available features. The outcome of the feature selection algorithm yielded five features (entropy, energy, homogeneity, contrast, and moment 2), which were determined to impact classification performance. These selected features were then input into six classifiers: SVM, KNN, decision tree, MLP, naive Bayes, and k-means clustering. The results showed that the highest precision values for all classifiers corresponded to the biting state, and the lowest precision values were associated with the chewing-biting state. The most effective classifiers for biting, chewing, chewing-biting, and sorting states were identified as MLP, KNN, SVM, and SVM, respectively. The results of the study showed that the SVM and KNN classifiers achieved the highest classification precision values of 95.9% and 94.4%, respectively. These results are consistent with the known ability of both classifiers to effectively handle complex and high-dimensional datasets. The superior performance of the SVM classifier can be attributed to its ability to find a hyperplane that maximizes the margin between the two classes, thereby improving the generalization performance of the classifier. Similarly, the high precision of the KNN classifier can be explained by its ability to find the k nearest neighbors to a given data point and assign it to the class that is most common among those neighbors. The decision tree and MLP classifiers also performed well, with precisions of 92.8% and 94.1%, respectively, which can be attributed to their ability to learn complex relationships between features. Unexpectedly, the naive Bayes classifier had a lower precision value compared to the other classifiers. This could be due to its assumption of feature independence, which may not hold true in real-world datasets. The k-means also had a relatively low precision value of 89.6%, which could be due to the fact that it is an unsupervised learning algorithm and may not be suitable for this classification task. Furthermore, the study has faced challenges in accurately classifying the chewing-biting state due to the overlapping sound intensity of signals generated by jaw movements in both chewing and chewing-biting states. This may have presented a significant challenge for all classifiers.
Additionally, the study may have been limited by the number and type of textural features extracted from the images. It is possible that other textural features or feature extraction methods might have improved classification performance. This result is consistent with several previous studies investigating various techniques and methods for accurately detecting and classifying jaw movements in feeding animals. Clapham et al. [
58] employed parameters including frequency, intensity, duration, and time between events, calculated from sound segments ranging from 1 to 5 min, to detect and analyze bites. They achieved an overall behavior classification accuracy of 94% and could differentiate between bites and chews with a 94% accuracy using a discriminate function. Navon et al. [
59] applied a machine learning technique to 10 min grazing session recordings captured by a camera and achieved a 94% accuracy in jaw movement detection. This accuracy was compared to the analysis of sounds by a trained operator. In a different model, the acoustic spectrum characteristics, specifically the energy produced in decibels by each sound, were used to estimate the sequences of bites, chews, and chew-bites, representing three types of jaw movements. These hidden states are not directly observable but can be inferred through the model [
60]. The accuracy of correctly classifying these three jaw movement types ranged from 61% to 99% and was found to be influenced by factors such as pasture type and grass height [
61].
Ungar et al. [
62] employed discriminant analysis, logistic regression, and neural networks as classification methods and reported accuracy rates ranging from 67% to 82%, 87%, and 25% to 90%, respectively, in correctly classifying jaw stats. Giovanetti et al. [
63] successfully used stepwise discriminant analysis (SDA), canonical discriminant analysis (CDA), and discriminant analysis (DA) to automatically evaluate specific behaviors using a triaxial accelerometer (such as the biting activity of dairy sheep in grazing environments). The accuracy of predicting grazing, ruminating, and resting behaviors varied between 89% and 95%, resulting in an overall accuracy of 93%. Chelotti et al. [
64] devised a pattern recognition method to categorize jaw movements in grazing cattle based on acoustic signals, yielding a recognition rate of 90% even under noisy conditions.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}