
Wild Terrestrial Animal Re-Identification Based on an Improved Locally Aware Transformer with a Cross-Attention Mechanism


Abstract
:Simple Summary
Abstract
1. Introduction
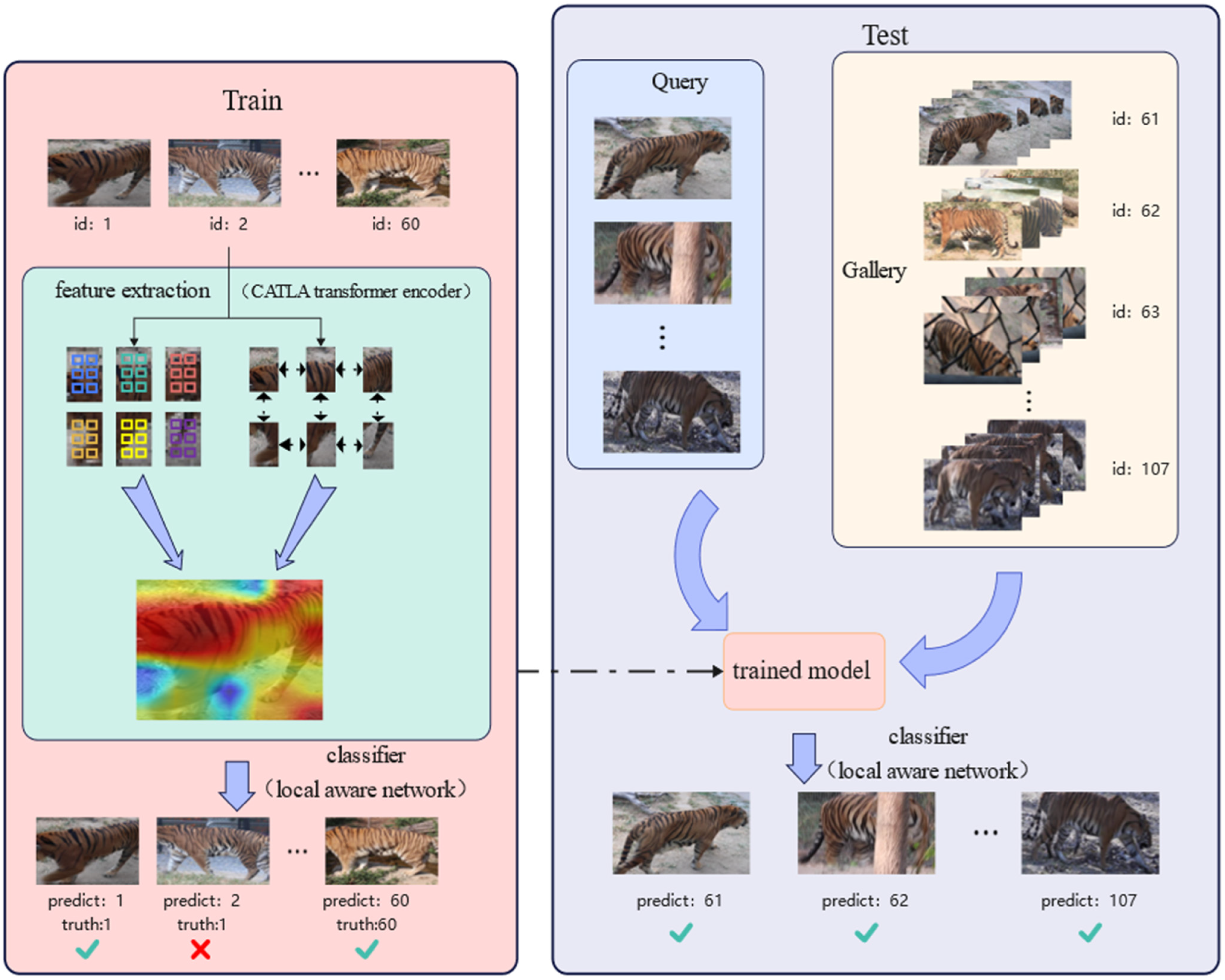
- In order to better extract and fuse global and local information on wildlife, we first applied the transformer network structure to the re-identification of wildlife and proposed a transformer network based on a cross-attention mechanism for the re-identification of wild terrestrial animals;
- After partitioning the whole image into patches, in order to extract the local features of the patches and the global correlation between patches, we replaced the self-attention module of the LA transformer with CAB, which captures the global information of the animal appearance and the differences in local features, such as local fur colors and textures;
- At the stage of the feature fusion, the hierarchical structure of the locally aware network was redesigned according to the distribution of animal body parts in the standing posture. After fusing the weighted-average values of global and local tokens, we obtained the globally enhanced local tokens where the fused features were arranged into 7 × 28 2D distribution;
- To validate the generalization ability of the model, we tested different types of datasets, such as the animal trunk dataset and the animal face datasets including those of tigers, lions, golden monkeys, and other common species.
2. Materials and Methods
2.1. Datasets
2.2. Methods
2.2.1. CATLA Transformer Encoder for Extracting Wildlife Muti-Scale Features
2.2.2. Locally Aware Network
3. Results
3.1. Experimental Details
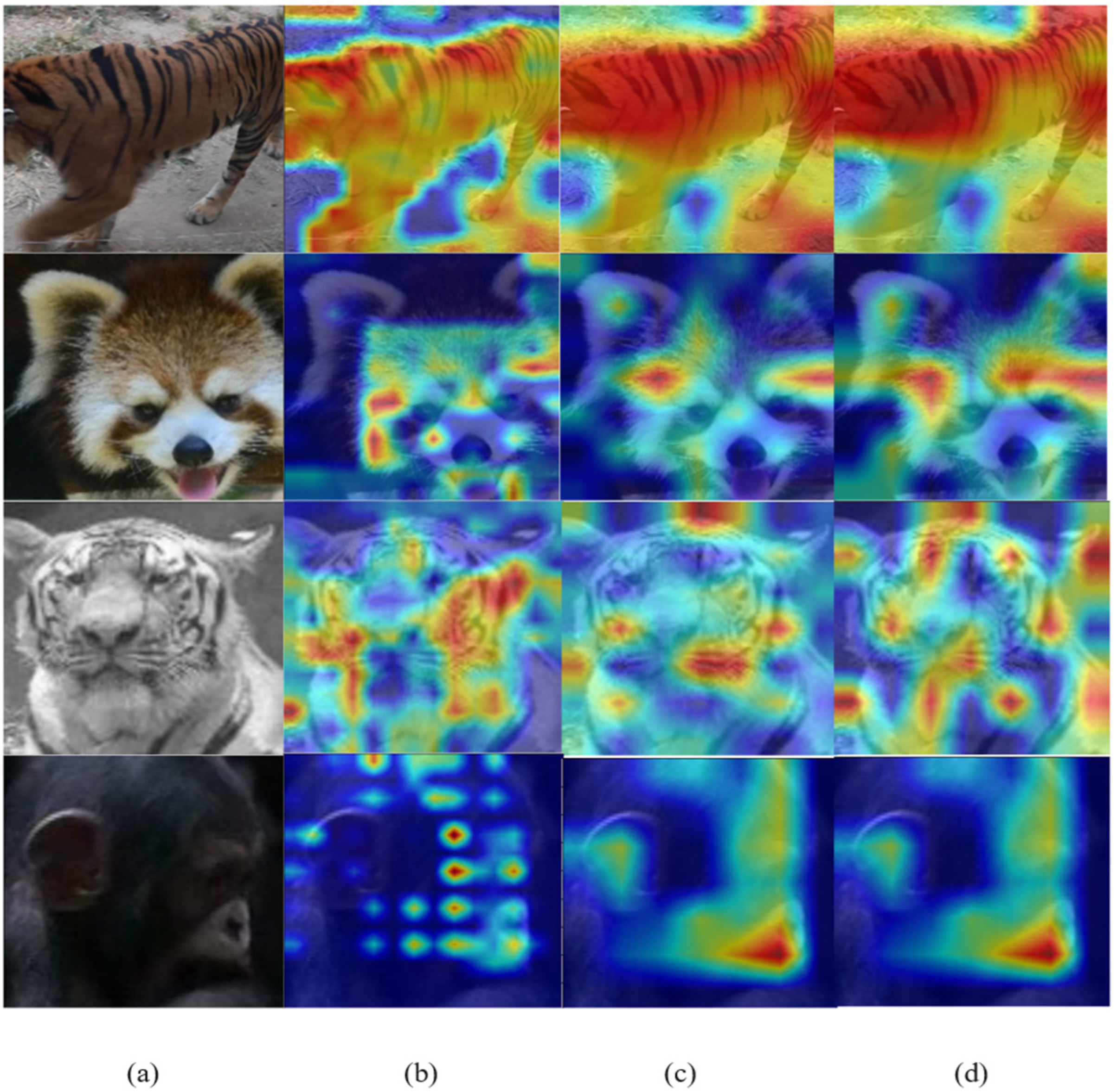
3.2. Effectiveness of the Cross-Attention Module
3.3. Decision on the Layer Number of a Local Aware Network
3.4. Comparison against the State of the Art
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stock, T. The Convention on Biological Diversity; 10 years on taking stock, looking forward; The Secretariat of the Convention on Biological Diversity: Montreal, QC, Canada, 1992. [Google Scholar]
- Vié, J.C.; Hilton-Taylor, C.; Stuart, S.N. (Eds.) Wildlife in a Changing World: An Analysis of the 2008 IUCN Red List of Threatened Species; IUCN: Gland, Switzerland, 2009. [Google Scholar]
- Gowans, S.; Whitehead, H.; Arch, J.K.; Hooker, S.K. Population size and residency patterns of northern bottlenose whales (Hyperoodon ampullatus) using the Gully, Nova Scotia. J. Cetacean Res. Manag. 2000, 2, 201–210. [Google Scholar]
- Reynolds-Hogland, M.; Ramsey, A.B.; Muench, C.; Pilgrim, K.L.; Engkjer, C.; Erba, G.; Ramsey, P.W. Integrating video and genetic data to estimate annual age-structured apparent survival of American black bears. Popul. Ecol. 2022, 64, 300–322. [Google Scholar] [CrossRef]
- Kulits, P.; Wall, J.; Bedetti, A.; Henley, M.; Beery, S. ElephantBook: A semi-automated human-in-the-loop system for elephant re-identification. In Proceedings of the ACM SIGCAS Conference on Computing and Sustainable Societies, Virtual Event, Australia, 28 June–2 July 2021; pp. 88–98. [Google Scholar]
- Schneider, S.; Taylor, G.W.; Linquist, S.; Kremer, S.C. Past, present and future approaches using computer vision for animal re-identification from camera trap data. Methods Ecol. Evol. 2019, 10, 461–470. [Google Scholar] [CrossRef] [Green Version]
- Welbourne, D.J.; Claridge, A.W.; Paull, D.J.; Lambert, A. How do passive infrared triggered camera traps operate and why does it matter? Breaking down common misconceptions. Remote Sens. Ecol. Conserv. 2016, 2, 77–83. [Google Scholar] [CrossRef] [Green Version]
- Meek, P.D.; Vernes, K.; Falzon, G. On the reliability of expert identification of small-medium sized mammals from camera trap photos. Wildl. Biol. Pract. 2013, 9, 1–19. [Google Scholar] [CrossRef]
- Xu, Q.J.; Qi, D.W. Parameters for texture feature of Panthera tigris altaica based on gray level co-occurrence matrix. J. Northeast For. Univ. 2008, 37, 125–128. [Google Scholar]
- Arzoumanian, Z.; Holmberg, J.; Norman, B. An astronomical pattern-matching algorithm for computer-aided identification of whale sharks Rhincodon typus. J. Appl. Ecol. 2005, 42, 999–1011. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, J.; Wan, Z.; Zhang, D.; Jiang, D. Rotor Fault Diagnosis Using Domain-Adversarial Neural Network with Time-Frequency Analysis. Machines 2022, 10, 610. [Google Scholar] [CrossRef]
- Yang, F.; Jiang, Y.; Xu, Y. Design of Bird Sound Recognition Model Based on Lightweight. IEEE Access 2022, 10, 85189–85198. [Google Scholar] [CrossRef]
- Beery, S.; Wu, G.; Rathod, V.; Votel, R.; Huang, J. Context r-cnn: Long term temporal context for per-camera object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 2–5 March 2020; pp. 13075–13085. [Google Scholar]
- Carter, S.J.B.; Bell, I.P.; Miller, J.J.; Gash, P.P. Automated marine turtle photograph identification using artificial neural networks, with application to green turtles. J. Exp. Mar. Biol. Ecol. 2014, 452, 105–110. [Google Scholar] [CrossRef]
- Nepovinnykh, E.; Eerola, T.; Kalviainen, H. Siamese network based pelage pattern matching for ringed seal re-identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, Snowmass Village, CO, USA, 2–5 May 2020; pp. 25–34. [Google Scholar]
- Yu, J.; Su, H.; Liu, J.; Yang, Z.; Zhang, Z.; Zhu, Y.; Yang, L.; Jiao, B. A strong baseline for tiger re-id and its bag of tricks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Li, S.; Li, J.; Tang, H.; Qian, R.; Lin, W. ATRW: A benchmark for Amur tiger re-identification in the wild. arXiv 2019, arXiv:1906.05586. [Google Scholar]
- Deb, D.; Wiper, S.; Gong, S.; Shi, Y.; Tymoszek, C.; Fletcher, A.; Jain, A.K. Face recognition: Primates in the wild. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–10. [Google Scholar]
- Guo, S.; Xu, P.; Miao, Q.; Shao, G.; Chapman, C.A.; Chen, X.; He, G.; Fang, D.; Zhang, H.; Sun, Y.; et al. Automatic identification of individual primates with deep learning techniques. Iscience 2020, 23, 101412. [Google Scholar] [CrossRef] [PubMed]
- Schofield, D.; Nagrani, A.; Zisserman, A.; Hayashi, M.; Matsuzawa, T.; Biro, D.; Carvalho, S. Chimpanzee face recognition from videos in the wild using deep learning. Sci. Adv. 2019, 5, eaaw0736. [Google Scholar] [CrossRef] [PubMed]
- Freytag, A.; Rodner, E.; Simon, M.; Loos, A.; Kühl, H.S.; Denzler, J. Chimpanzee faces in the wild: Log-euclidean CNNs for predicting identities and attributes of primates. In Proceeding of the German Conference on Pattern Recognition, Hannover, Germany, 12–15 September 2016; pp. 51–63. [Google Scholar]
- Zhang, G.; Zhang, P.; Qi, J.; Lu, H. Hat: Hierarchical aggregation transformers for person re-identification. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 516–525. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Sharma, C.; Kapil, S.R.; Chapman, D. Person re-identification with a locally aware transformer. arXiv 2021, arXiv:2106.03720. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Kanal, L.N. Perceptron. In Encyclopedia of Computer Science; John Wiley and Sons: Chichester, UK, 2003; pp. 1383–1385. [Google Scholar]
- Lin, H.; Cheng, X.; Wu, X.; Shen, D. Cat: Cross attention in vision transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Rao, Y.; Chen, G.; Lu, J.; Zhou, J. Counterfactual attention learning for fine-grained visual categorization and re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 1025–1034. [Google Scholar]
- Quispe, R.; Pedrini, H. Top-db-net: Top dropblock for activation enhancement in person re-identification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2980–2987. [Google Scholar]
- Ebrahimi, M.; Ebrahimie, E.; Bull, C.M. Minimizing the cost of translocation failure with decision-tree models that predict species’ behavioral response in translocation sites. Conserv. Biol. 2015, 29, 1208–1216. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Training Set | Testing Set | |||||
|---|---|---|---|---|---|---|---|
| Train Ids | Train Images | Query Ids | Query Images | Gallery Ids | Gallery Images | ||
| Tiger body | ATRW | 120 | 2310 | 47 | 234 | 47 | 499 |
| Tri-AI Color face | Meerkat | 12 | 480 | 6 | 14 | 6 | 155 |
| Lion | 11 | 402 | 6 | 48 | 6 | 231 | |
| Red panda | 11 | 369 | 5 | 51 | 5 | 231 | |
| Tri-AI Gray face | Golden monkey | 17 | 287 | 7 | 12 | 7 | 57 |
| Tiger | 13 | 603 | 6 | 56 | 6 | 147 | |
| Complex face | C-Zoo and C-Tai | 116 | 4917 | 50 | 419 | 50 | 2346 |
| Datasets | Species | Methods | Rank 1 | Rank 5 | mAP |
|---|---|---|---|---|---|
| ATRW | Tiger | Jiwen Yu’s method | 99.6 | 100 | 90.64 |
| CAL + ResNet | 99.5 | 100 | 81.50 | ||
| Top-DB-Net | 96.20 | 99.10 | 84.40 | ||
| LA Transformer | 91.88 | 98.29 | 89.67 | ||
| Ours | 97.86 | 99.57 | 92.66 | ||
| Tri-AI Color face | Meerkat | Tri-AI | - | - | 90.13 |
| CAL + ResNet | - | - | 93.90 | ||
| Top-DB-Net | - | - | 95.40 | ||
| Ours | - | - | 96.16 | ||
| Lion | Tri-AI | - | - | 93.55 | |
| CAL + ResNet | - | - | 90.20 | ||
| Top-DB-Net | - | - | 95.50 | ||
| Our method | - | - | 98.69 | ||
| Red Panda | Tri-AI | - | - | 92.16 | |
| CAL + ResNet | - | - | 90.30 | ||
| Top-DB-Net | - | - | 95.20 | ||
| Ours | - | - | 98.51 | ||
| Tri-AI Gray face | Golden monkey | Tri-AI | - | - | 94.38 |
| CAL + ResNet | - | - | 92.40 | ||
| Top-DB-Net | - | - | 96.40 | ||
| Our method | - | - | 97.99 | ||
| Tiger | Tri-AI | - | - | 92.03 | |
| CAL + ResNet | - | - | 78.90 | ||
| Top-DB-Net | - | - | 92.40 | ||
| Ours | - | - | 93.77 | ||
| Complex face | chimpanzee | PrimNet | 75.82 | - | - |
| CAL + ResNet | 89.70 | 63.70 | |||
| Top-DB-Net | 83.30 | 55.60 | |||
| Ours | 85.03 | - | 73.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Zhao, Y.; Li, A.; Yu, Q. Wild Terrestrial Animal Re-Identification Based on an Improved Locally Aware Transformer with a Cross-Attention Mechanism. Animals 2022, 12, 3503. https://doi.org/10.3390/ani12243503
Zheng Z, Zhao Y, Li A, Yu Q. Wild Terrestrial Animal Re-Identification Based on an Improved Locally Aware Transformer with a Cross-Attention Mechanism. Animals. 2022; 12(24):3503. https://doi.org/10.3390/ani12243503
Chicago/Turabian StyleZheng, Zhaoxiang, Yaqin Zhao, Ao Li, and Qiuping Yu. 2022. "Wild Terrestrial Animal Re-Identification Based on an Improved Locally Aware Transformer with a Cross-Attention Mechanism" Animals 12, no. 24: 3503. https://doi.org/10.3390/ani12243503