
Multi-Agent Reinforcement Learning with Optimal Equivalent Action of Neighborhood

Abstract
:1. Introduction
2. Related Work
3. Reinforcement Learning Based on the OEAN
3.1. Background
3.2. Multi-Agent Policy with the OEAN
3.3. Nash Equilibrium Policy Based on the OEAN
4. OEAN Based on HMRF
4.1. HMRF for Multi-Agent System
4.2. Optimal Equivalent Action of the Neighborhood
4.3. Convergence Proof
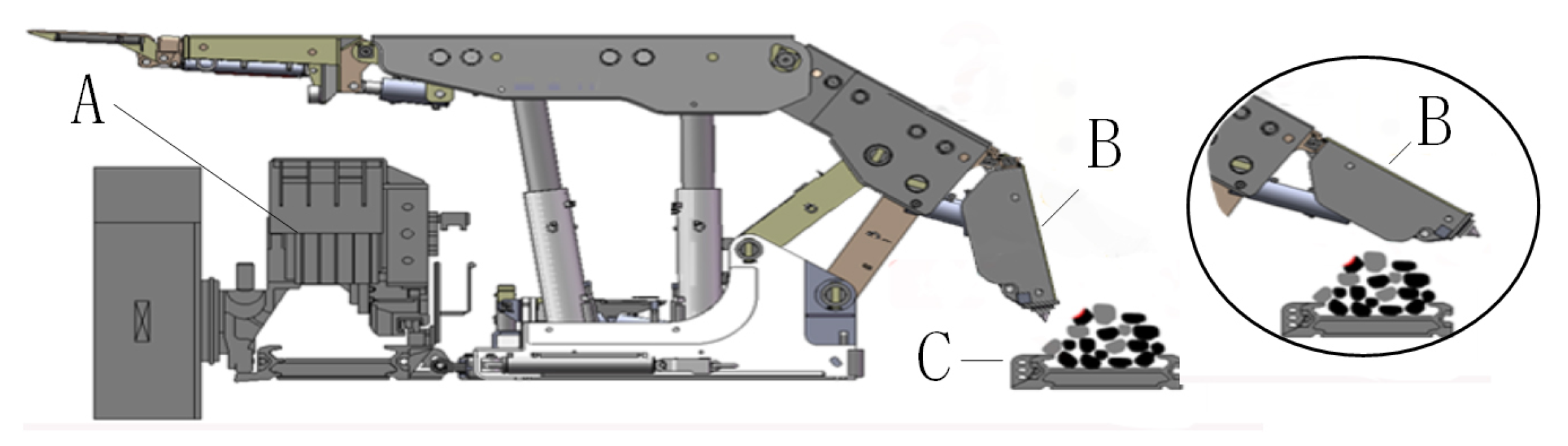
5. Top-Coal Caving Experiment
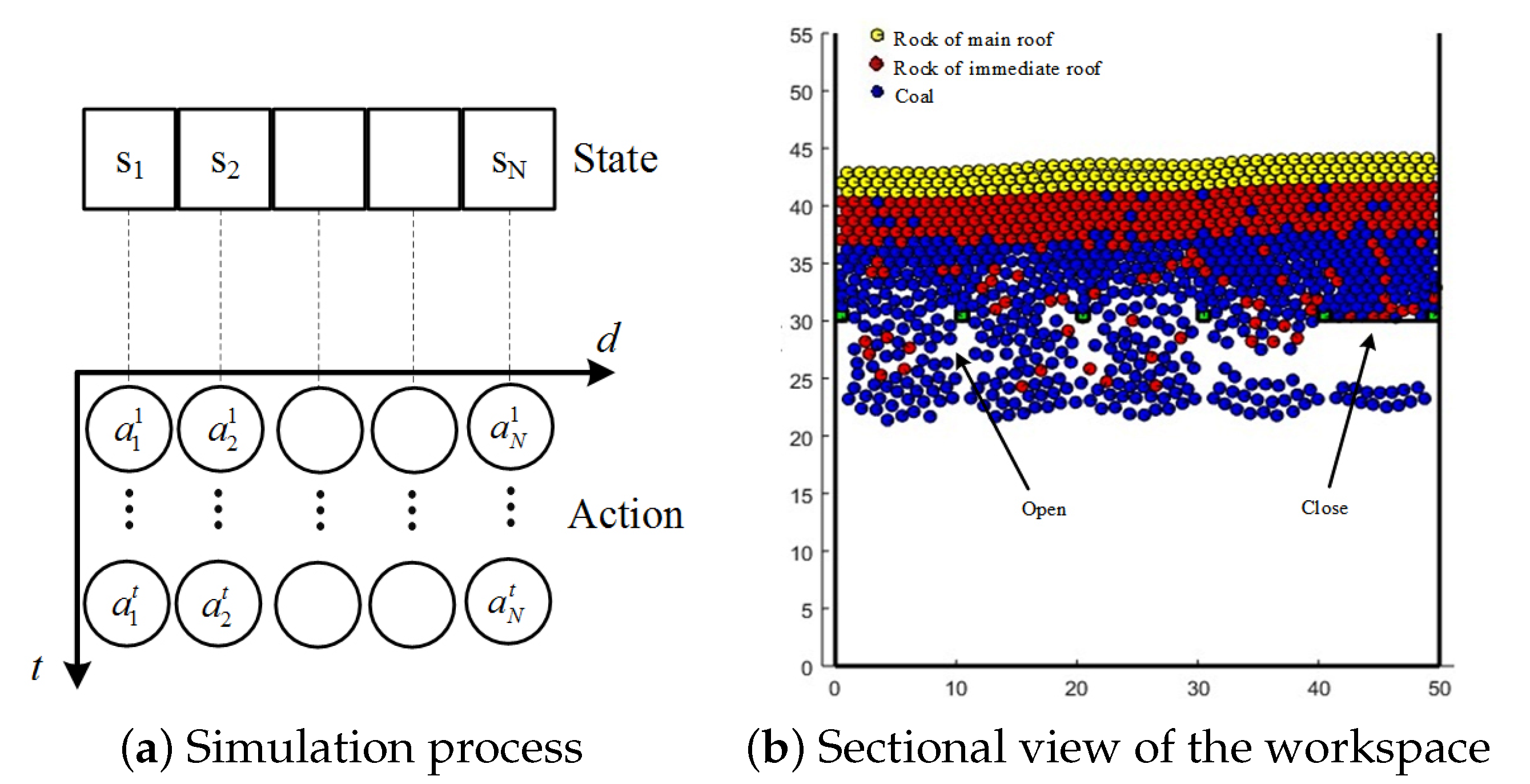
5.1. Top-Coal Caving Simulation Platform
5.2. Top-Coal Caving Decision Experiment Based on OEAN
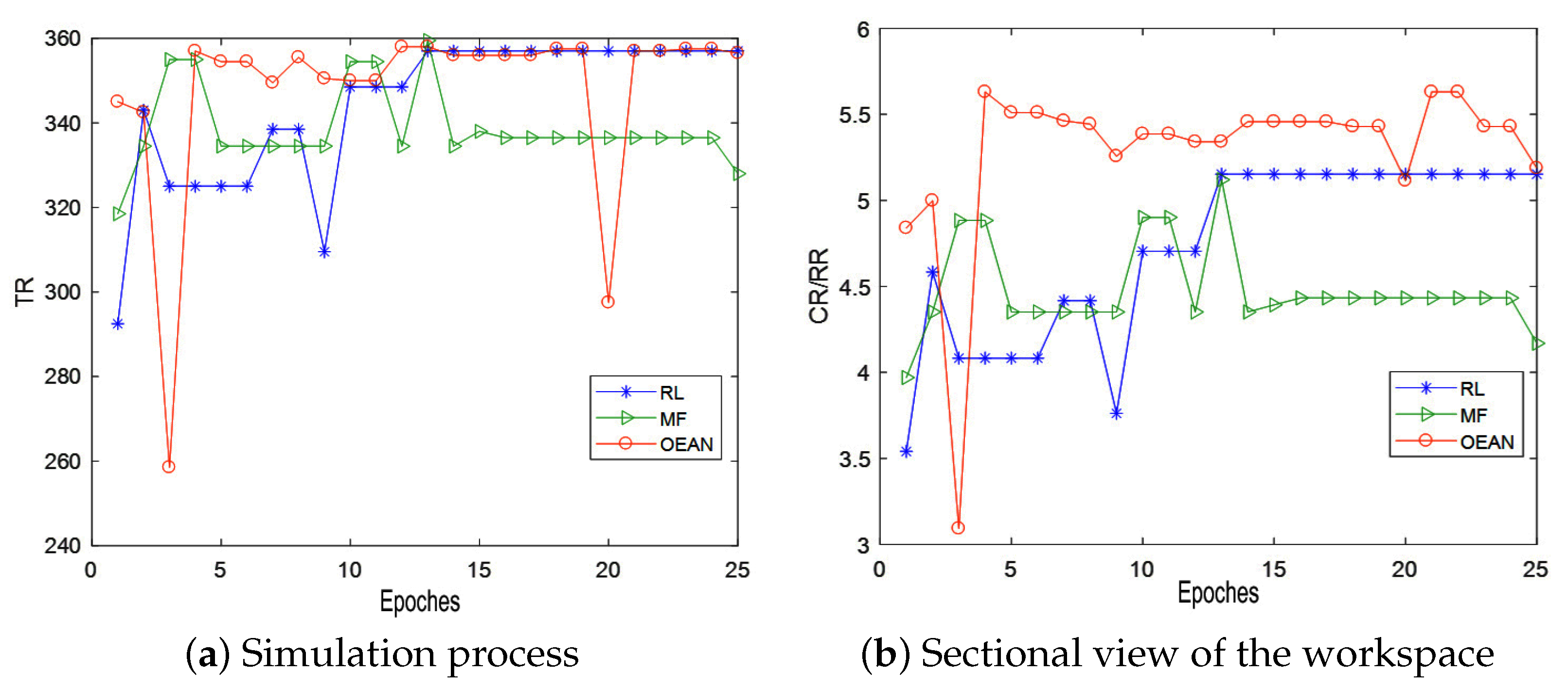
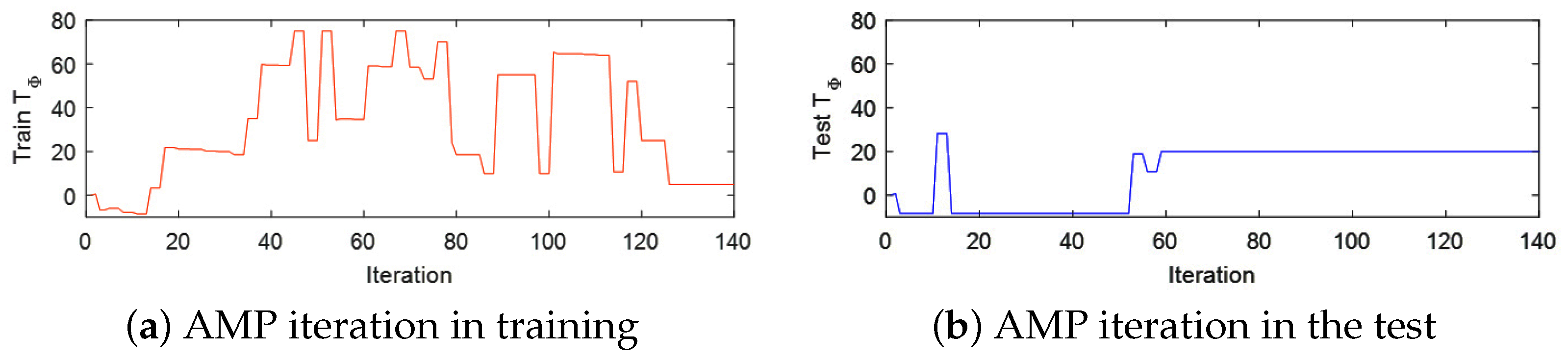
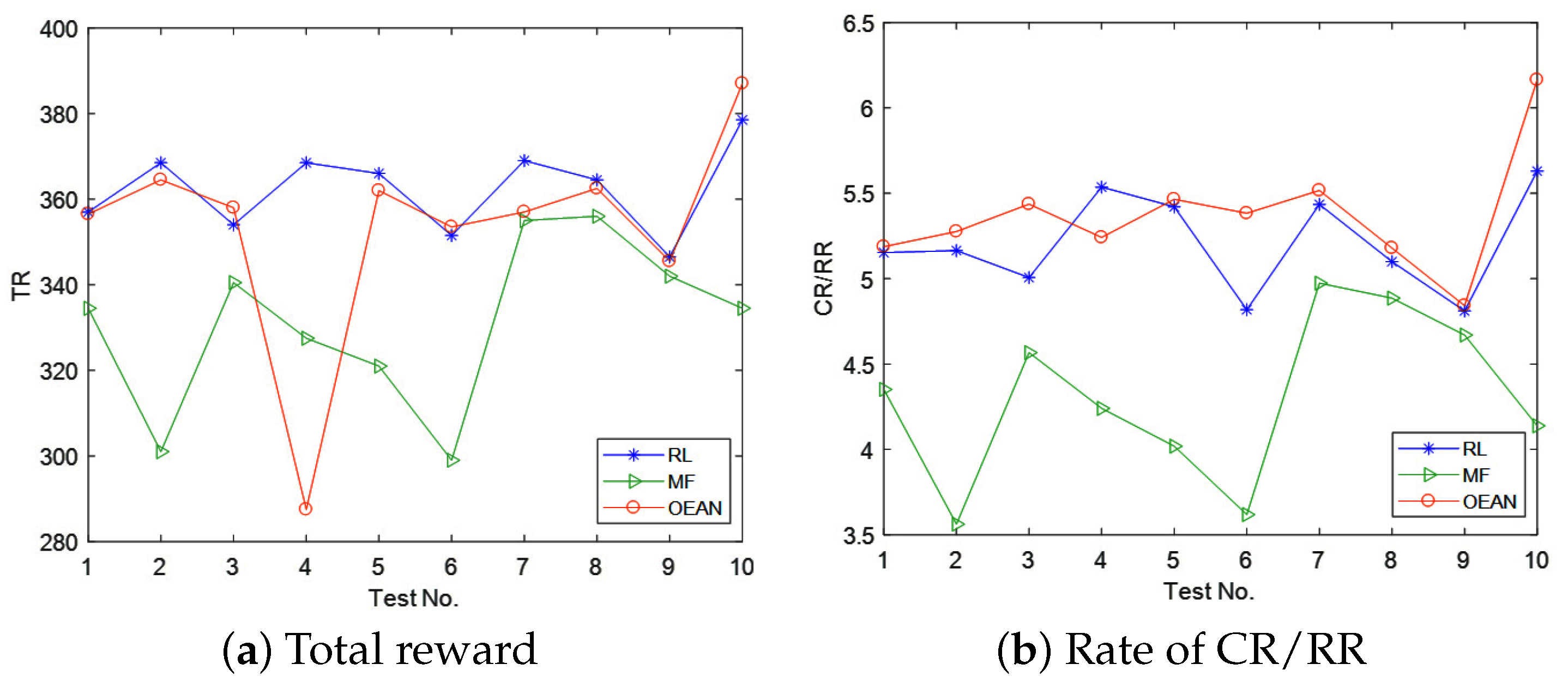
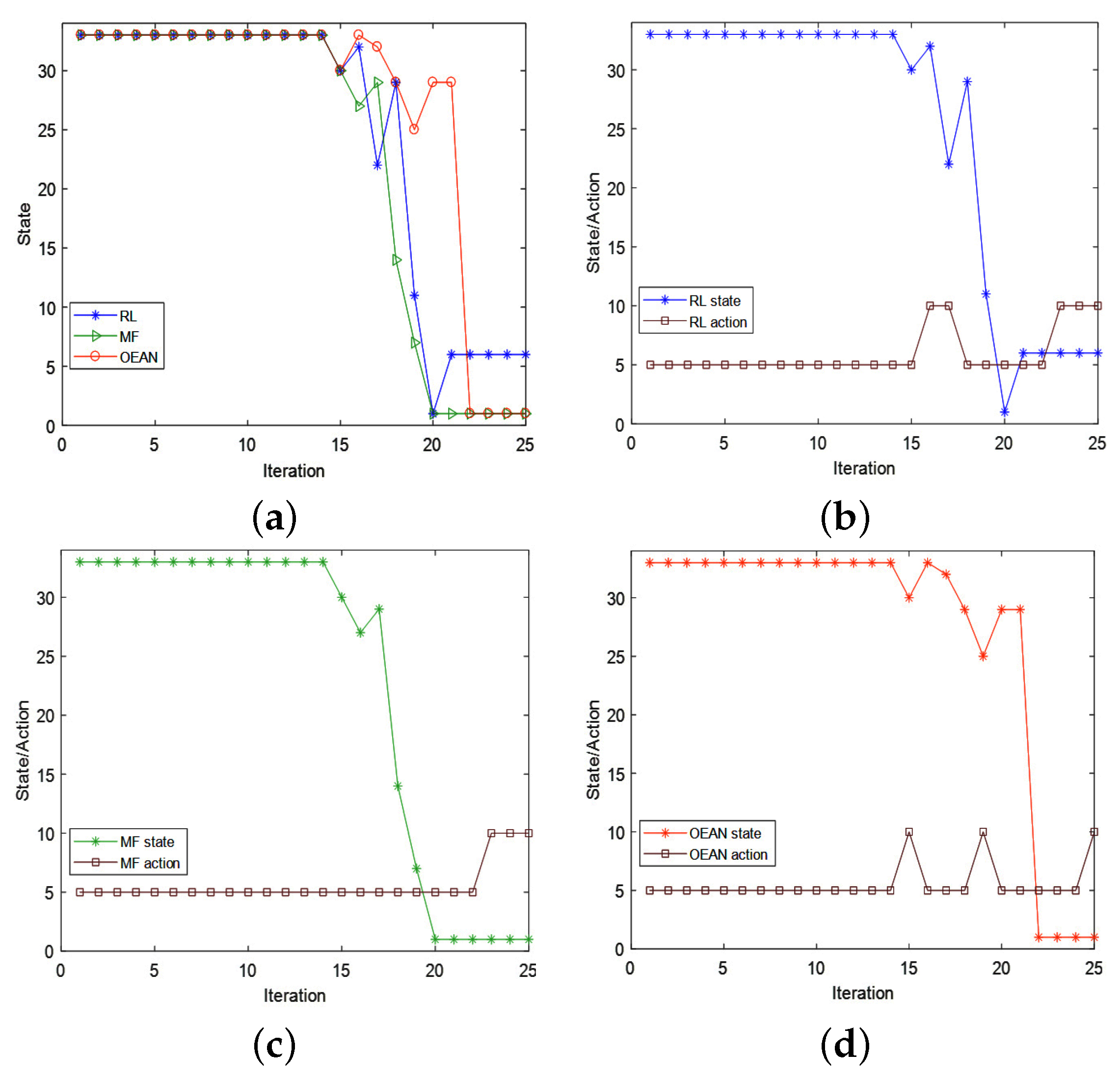
5.3. Experiment Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qian, W.; Xing, W.; Fei, S. H∞ infinity state estimation for neural networks with general activation function and mixed time-varying delays. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3909–3918. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y.; Zhao, Z.; Zhang, C.; Yang, Q.; Hong, K.S. Adaptive neural-network boundary control for a flexible manipulator with input constraints and model uncertainties. IEEE Trans. Cybern. 2020, 51, 4796–4807. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Wen, G.; Zhao, Z.; Sedaghati, R. Neural-network-based sliding-mode control of an uncertain robot using dynamic model approximated switching gain. IEEE Trans. Cybern. 2020, 51, 2339–2346. [Google Scholar] [CrossRef]
- Zhao, Z.; Ren, Y.; Mu, C.; Zou, T.; Hong, K.S. Adaptive neural-network-based fault-tolerant control for a flexible string with composite disturbance observer and input constraints. IEEE Trans. Cybern. 2021, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Wang, Y.; Miao, Z.; Na, J.; Zhao, Z.; Yang, C. Composite-learning-based adaptive neural control for dual-arm robots with relative motion. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1010–1021. [Google Scholar] [CrossRef]
- Qian, W.; Li, Y.; Chen, Y.; Liu, W. L2-L∞ infinity filtering for stochastic delayed systems with randomly occurring nonlinearities and sensor saturation. Int. J. Syst. Sci. 2020, 51, 2360–2377. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Lan, X.; Liu, Y.; Zhao, Z. Cooperative control for swarming systems based on reinforcement learning in unknown dynamic environment. Neurocomputing 2020, 410, 410–418. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef]
- Luo, B.; Liu, D.; Huang, T.; Wang, D. Model-Free Optimal Tracking Control via Critic-Only Q-Learning. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2134–2144. [Google Scholar] [CrossRef]
- Qian, W.; Gao, Y.; Yang, Y. Global consensus of multiagent systems with internal delays and communication delays. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1961–1970. [Google Scholar] [CrossRef]
- Wei, Q.; Kasabov, N.; Polycarpou, M.; Zeng, Z. Deep learning neural networks: Methods, systems, and applications. Neurocomputing 2020, 396, 130–132. [Google Scholar] [CrossRef]
- Liu, Z.; Shi, J.; Zhao, X.; Zhao, Z.; Li, H.X. Adaptive Fuzzy Event-triggered Control of Aerial Refueling Hose System with Actuator Failures. IEEE Trans. Fuzzy Syst. 2021, 1. [Google Scholar] [CrossRef]
- Qian, W.; Li, Y.; Zhao, Y.; Chen, Y. New optimal method for L2-L∞ infinity state estimation of delayed neural networks. Neurocomputing 2020, 415, 258–265. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–8 December 2017; pp. 6379–6390. [Google Scholar]
- Matta, M.; Cardarilli, G.C.; Di Nunzio, L.; Fazzolari, R.; Giardino, D.; Re, M.; Silvestri, F.; Spanò, S. Q-RTS: A real-time swarm intelligence based on multi-agent Q-learning. Electron. Lett. 2019, 55, 589–591. [Google Scholar] [CrossRef]
- Sadhu, A.K.; Konar, A. Improving the speed of convergence of multi-agent Q-learning for cooperative task-planning by a robot-team. Robot. Auton. Syst. 2017, 92, 66–80. [Google Scholar] [CrossRef]
- Ni, Z.; Paul, S. A Multistage Game in Smart Grid Security: A Reinforcement Learning Solution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2684–2695. [Google Scholar] [CrossRef]
- Sun, C.; Karlsson, P.; Wu, J.; Tenenbaum, J.B.; Murphy, K. Stochastic prediction of multi-agent interactions from partial observations. arXiv 2019, arXiv:1902.09641. [Google Scholar]
- Mo, X.; Huang, Z.; Xing, Y.; Lv, C. Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network. IEEE Trans. Intell. Transp. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Niu, Y.; Paleja, R.; Gombolay, M. Multi-agent graph-attention communication and teaming. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, Online, 3–7 May 2021; pp. 964–973. [Google Scholar]
- Koller, D.; Friedman, N.; Bach, F. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Sadhu, A.K.; Konar, A. An Efficient Computing of Correlated Equilibrium for Cooperative Q-Learning-Based Multi-Robot Planning. IEEE Trans. Syst. Man, Cybern. Syst. 2018, 8, 2779–2794. [Google Scholar] [CrossRef]
- Yang, Y.; Rui, L.; Li, M.; Ming, Z.; Wang, J. Mean Field Multi-Agent Reinforcement Learning. arXiv 2018, arXiv:1802.05438. [Google Scholar]
- Matignon, L.; Laurent, G.J.; Le Fort-Piat, N. Independent reinforcement learners in cooperative markov games: A survey regarding coordination problems. Knowl. Eng. Rev. 2012, 27, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Buşoniu, L.; Babuška, R.; De Schutter, B. Multi-agent reinforcement learning: An overview. In Innovations in Multi-Agent Systems and Applications-1; Springer: Berlin/Heidelberg, Germany, 2010; pp. 183–221. [Google Scholar]
- Shoham, Y.; Powers, R.; Grenager, T. If multi-agent learning is the answer, what is the question? Artif. Intell. 2007, 171, 365–377. [Google Scholar] [CrossRef] [Green Version]
- Littman, M.L. Value-function reinforcement learning in Markov games. Cogn. Syst. Res. 2001, 2, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Wellman, M.P. Nash Q-Learning for General-Sum Stochastic Games. J. Mach. Learn. Res. 2003, 4, 1039–1069. [Google Scholar]
- Hu, J.; Wellman, M.P. Multiagent reinforcement learning: Theoretical framework and an algorithm. In Proceedings of the ICML, Madison, WI, USA, 24–27 July 1998; Volume 98, pp. 242–250. [Google Scholar]
- Jaakkola, T.; Jordan, M.I.; Singh, S.P. Convergence of Stochastic Iterative Dynamic Programming Algorithms. Neural Comput. 1993, 6, 1185–1201. [Google Scholar] [CrossRef] [Green Version]
- Molina, J.P.; Zolezzi, J.M.; Contreras, J.; Rudnick, H.; Reveco, M.J. Nash-Cournot Equilibria in Hydrothermal Electricity Markets. IEEE Trans. Power Syst. 2011, 26, 1089–1101. [Google Scholar] [CrossRef]
- Yang, L.; Sun, Q.; Ma, D.; Wei, Q. Nash Q-learning based equilibrium transfer for integrated energy management game with We-Energy. Neurocomputing 2019, 396, 216–223. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G. Non-zero sum Nash Q-learning for unknown deterministic continuous-time linear systems. Automatica 2015, 61, 274–281. [Google Scholar] [CrossRef]
- Levine, S. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv 2018, arXiv:1805.00909. [Google Scholar]
- Chalkiadakis, G.; Boutilier, C. Coordination in multiagent reinforcement learning: A Bayesian approach. In Proceedings of the Second International Joint Conference on Autonomous Agents and Multiagent Systems, Melbourne, Australia, 14–18 July 2003; pp. 709–716. [Google Scholar]
- Teacy, W.L.; Chalkiadakis, G.; Farinelli, A.; Rogers, A.; Jennings, N.R.; McClean, S.; Parr, G. Decentralized Bayesian reinforcement learning for online agent collaboration. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems-Volume 1. International Foundation for Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012; pp. 417–424. [Google Scholar]
- Chalkiadakis, G. A Bayesian Approach to Multiagent Reinforcement Learning and Coalition Formation under Uncertainty; University of Toronto: Toronto, ON, Canda, 2007. [Google Scholar]
- Zhang, X.; Aberdeen, D.; Vishwanathan, S. Conditional random fields for multi-agent reinforcement learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 1143–1150. [Google Scholar]
- Handa, H. EDA-RL: Estimation of distribution algorithms for reinforcement learning problems. In Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation, Montreal, QC, Canada, 8–12 July 2009; pp. 405–412. [Google Scholar]
- Daniel, C.; Van Hoof, H.; Peters, J.; Neumann, G. Probabilistic inference for determining options in reinforcement learning. Mach. Learn. 2016, 104, 337–357. [Google Scholar] [CrossRef] [Green Version]
- Dethlefs, N.; Cuayáhuitl, H. Hierarchical reinforcement learning and hidden Markov models for task-oriented natural language generation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short Papers-Volume 2, Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; pp. 654–659. [Google Scholar]
- Sallans, B.; Hinton, G.E. Reinforcement learning with factored states and actions. J. Mach. Learn. Res. 2004, 5, 1063–1088. [Google Scholar]
- Zhang, Y.; Brady, M.; Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 2001, 20, 45–57. [Google Scholar] [CrossRef] [PubMed]
- Chatzis, S.P.; Tsechpenakis, G. The infinite hidden Markov random field model. IEEE Trans. Neural Networks 2010, 21, 1004–1014. [Google Scholar] [CrossRef] [PubMed]
- Littman, M.L.; Stone, P. A polynomial-time Nash equilibrium algorithm for repeated games. Decis. Support Syst. 2005, 39, 55–66. [Google Scholar] [CrossRef]
- Yang, Y.; Lin, Z.; Li, B.; Li, X.; Cui, L.; Wang, K. Hidden Markov random field for multi-agent optimal decision in top-coal caving. IEEE Access 2020, 8, 76596–76609. [Google Scholar] [CrossRef]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Wang, Q. HMRF-EM-image: Implementation of the Hidden Markov Random Field Model and its Expectation-Maximization Algorithm. Comput. Sci. 2012, 94, 222–233. [Google Scholar]
- Szepesvári, C.; Littman, M.L. A unified analysis of value-function-based reinforcement- learning algorithms. Neural Comput. 1999, 11, 2017–2059. [Google Scholar] [CrossRef]
- Vakili, A.; Hebblewhite, B.K. A new cavability assessment criterion for Longwall Top Coal Caving. Int. J. Rock Mech. Min. Sci. 2010, 47, 1317–1329. [Google Scholar] [CrossRef]
- Liu, C.; Li, H.; Mitri, H. Effect of Strata Conditions on Shield Pressure and Surface Subsidence at a Longwall Top Coal Caving Working Face. Rock Mech. Rock Eng. 2019, 52, 1523–1537. [Google Scholar] [CrossRef]
- Zhao, G. DICE2D an Open Source DEM. Available online: http://www.dembox.org/ (accessed on 15 June 2017).
- Sapuppo, F.; Schembri, F.; Fortuna, L.; Llobera, A.; Bucolo, M. A polymeric micro-optical system for the spatial monitoring in two-phase microfluidics. Microfluid. Nanofluidics 2012, 12, 165–174. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | State | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | ||
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | ||
| 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | ||
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | ||
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | ||
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | ||
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | ||
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | ||
| 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | ||
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | ||
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | ||
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | ||
| 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | ||
| 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | ||
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | ||
| 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
| No. | CR | RR | ||||
|---|---|---|---|---|---|---|
| RL | MF | OEAN | RL | MF | OEAN | |
| 1 | 0.90 | 0.94 | 0.91 | 0.17 | 0.23 | 0.18 |
| 2 | 0.94 | 0.96 | 0.92 | 0.18 | 0.27 | 0.17 |
| 3 | 0.91 | 0.92 | 0.89 | 0.18 | 0.19 | 0.16 |
| 4 | 0.90 | 0.93 | 0.66 | 0.16 | 0.19 | 0.13 |
| 5 | 0.93 | 0.95 | 0.91 | 0.17 | 0.24 | 0.17 |
| 6 | 0.92 | 0.94 | 0.89 | 0.19 | 0.23 | 0.17 |
| 7 | 0.93 | 0.92 | 0.89 | 0.17 | 0.17 | 0.16 |
| 8 | 0.94 | 0.94 | 0.92 | 0.18 | 0.19 | 0.18 |
| 9 | 0.92 | 0.93 | 0.92 | 0.19 | 0.2 | 0.19 |
| 10 | 0.93 | 0.94 | 0.93 | 0.17 | 0.19 | 0.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Yang, Y.; Lin, Z.; Wang, T. Multi-Agent Reinforcement Learning with Optimal Equivalent Action of Neighborhood. Actuators 2022, 11, 99. https://doi.org/10.3390/act11040099
Wang H, Yang Y, Lin Z, Wang T. Multi-Agent Reinforcement Learning with Optimal Equivalent Action of Neighborhood. Actuators. 2022; 11(4):99. https://doi.org/10.3390/act11040099
Chicago/Turabian StyleWang, Haixing, Yi Yang, Zhiwei Lin, and Tian Wang. 2022. "Multi-Agent Reinforcement Learning with Optimal Equivalent Action of Neighborhood" Actuators 11, no. 4: 99. https://doi.org/10.3390/act11040099