


The Spatial Patterns of the Crime Rate in London and Its Socio-Economic Influence Factors


Abstract
:1. Introduction
2. Study Region and Datasets
3. Methodology
3.1. Exploratory Spatial Data Analysis
3.1.1. Global Moran’s I
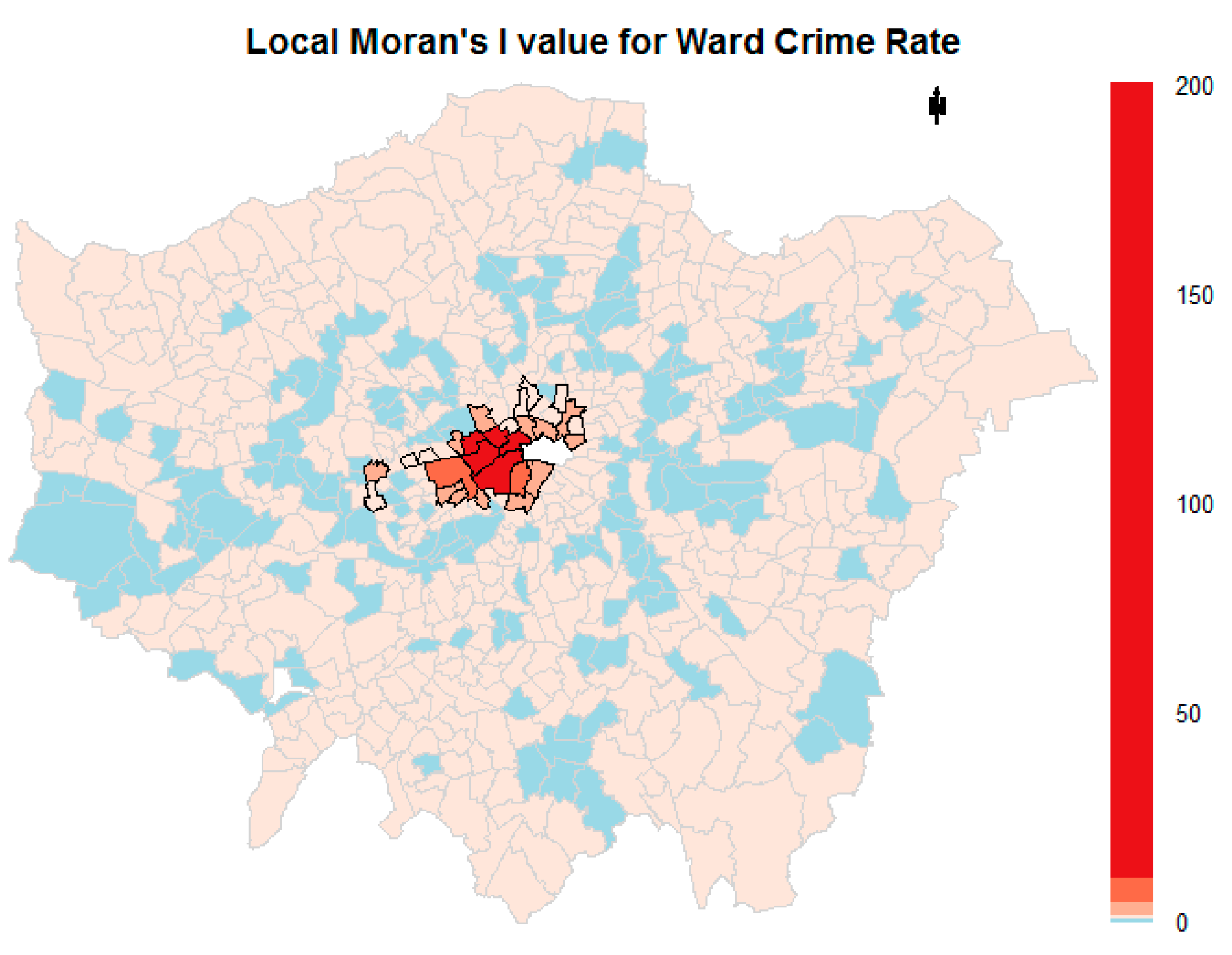
3.1.2. Local Moran’s I
3.2. Regression Analysis
3.2.1. Ordinary Least Squares (OLS) Regression Model
3.2.2. Geographically Weighted Regression Model
4. Results and Analysis
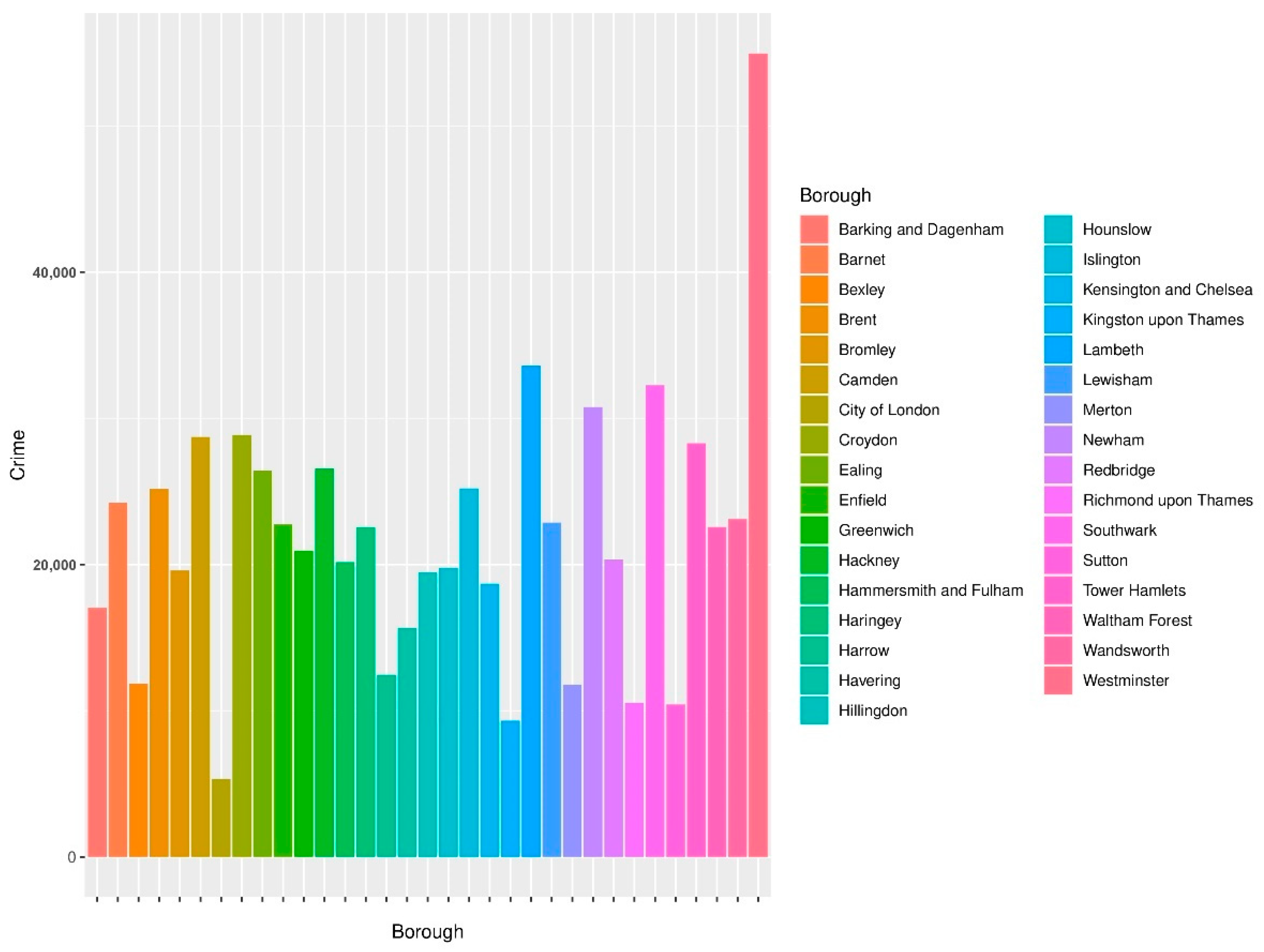
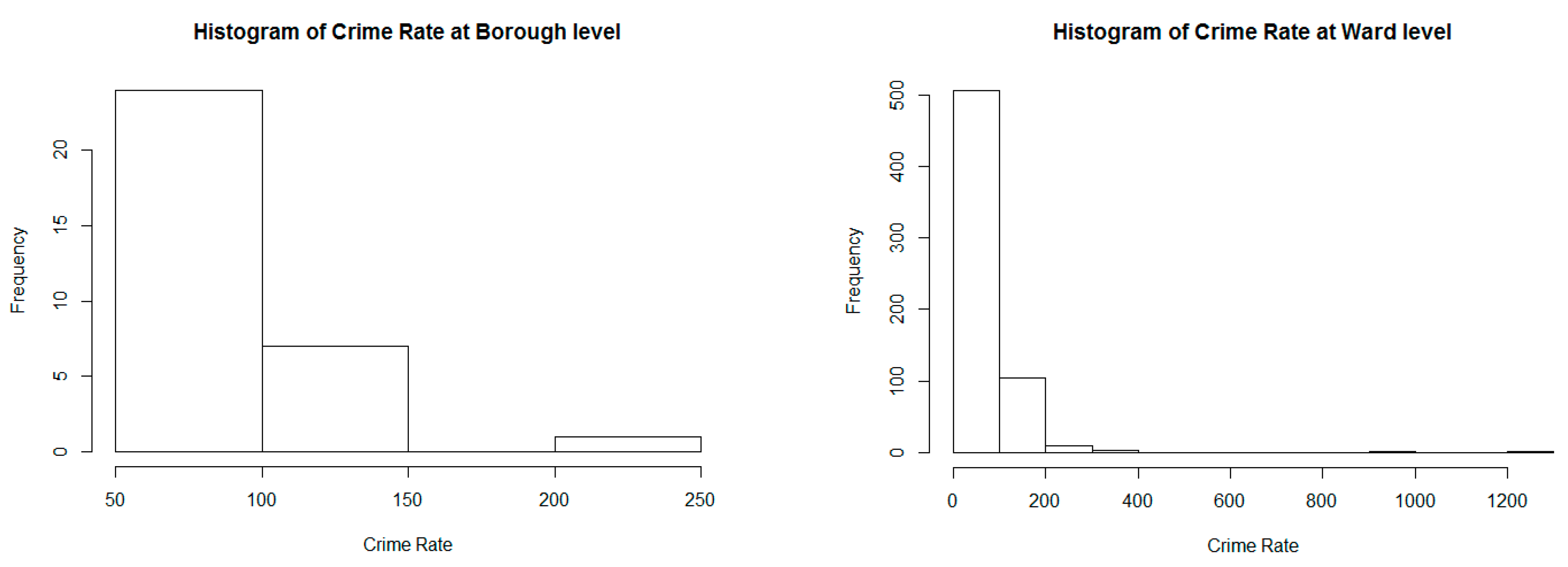
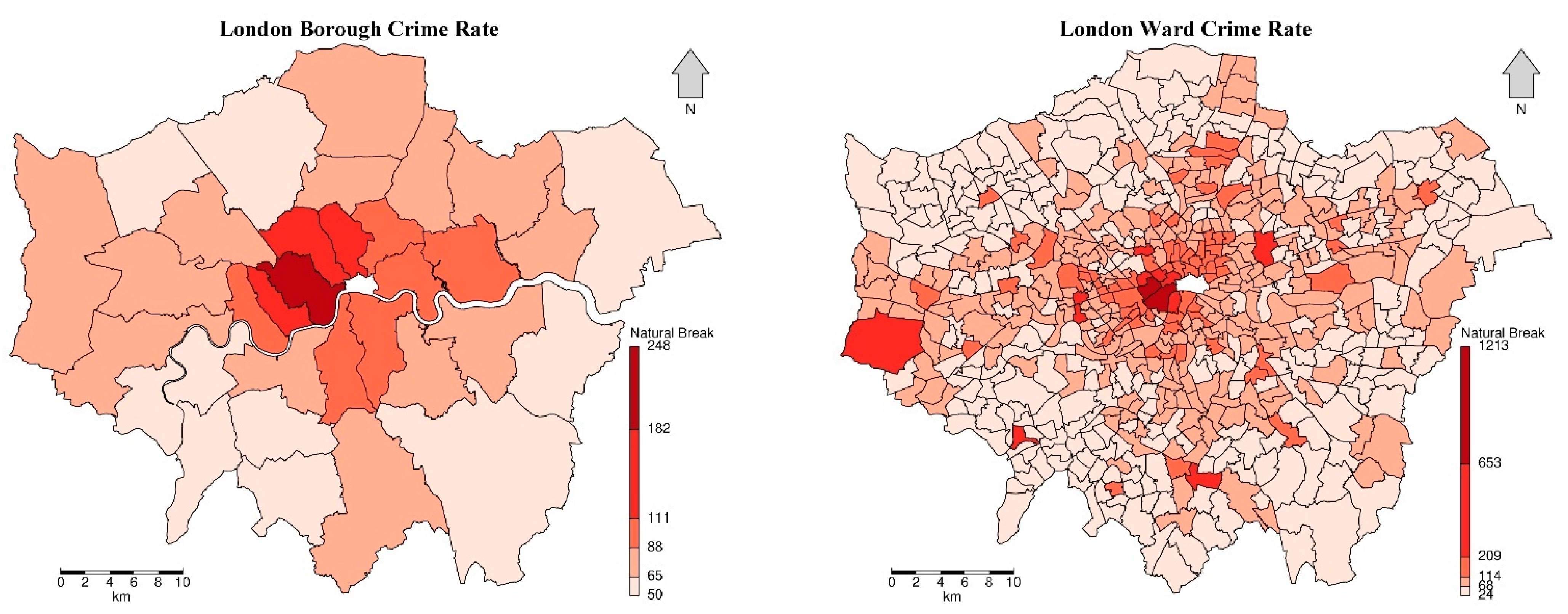
4.1. Overall Understanding of Crime Rates
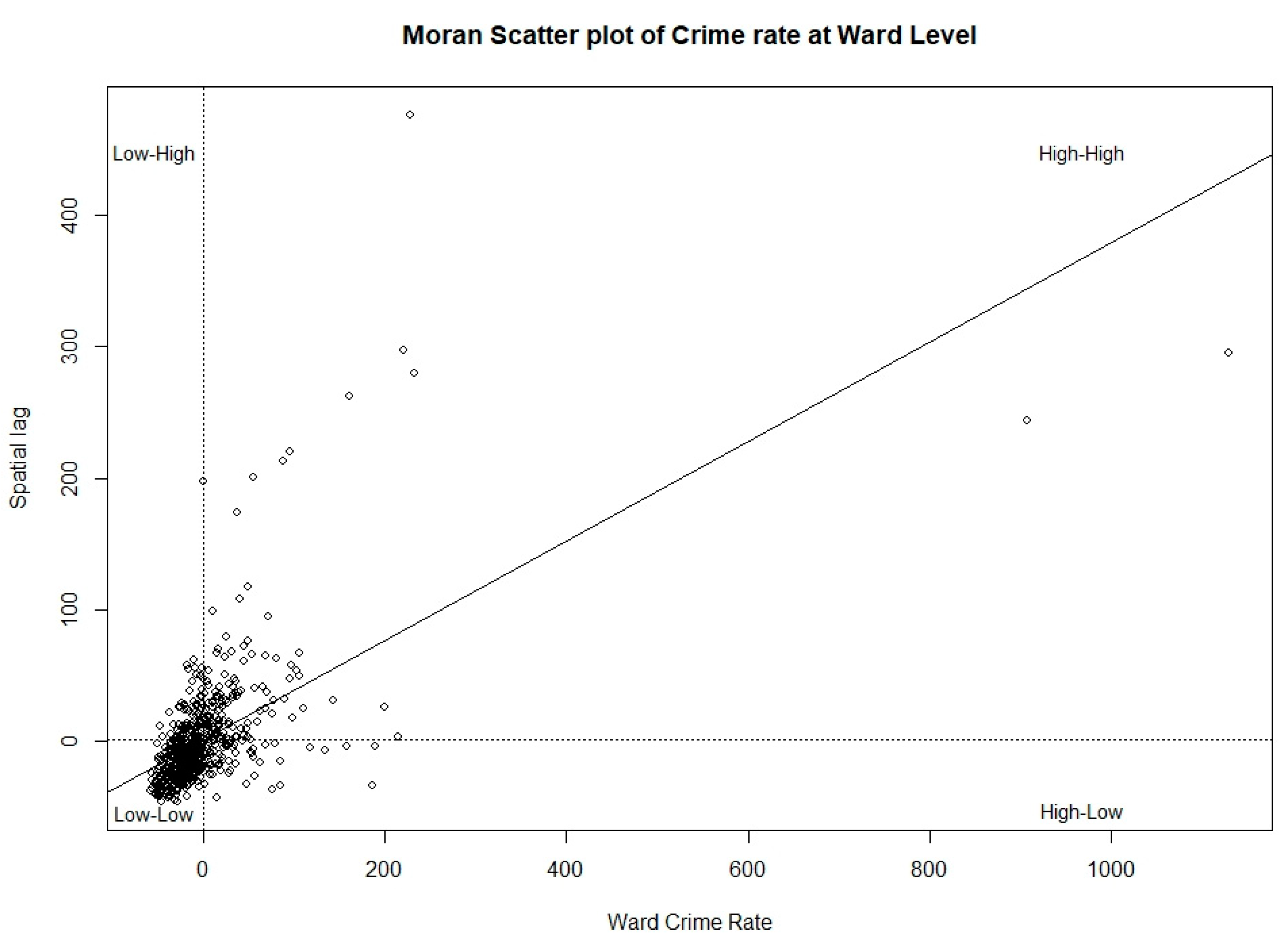
4.2. Exploratory Spatial Analysis Results
4.3. Regression Analysis
4.3.1. OLS Model Results
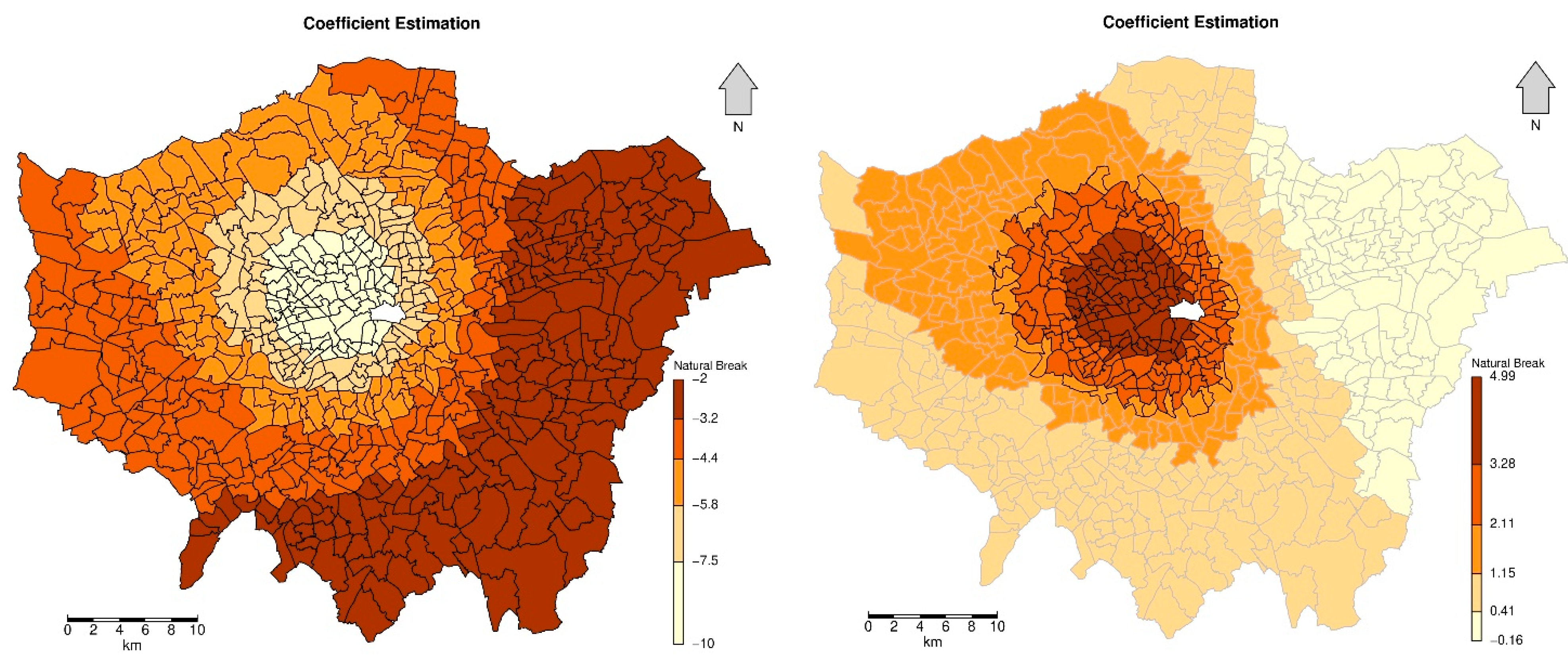
4.3.2. GWR Model Results
5. Discussion
5.1. Comparisons between OLS and GWR Models
5.2. Policy Implications
5.3. Further Improvement and Future Research Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adeyemi, Rasheed A., James Mayaki, Temesgen T. Zewotir, and Shaun Ramroop. 2021. Demography and crime: A spatial analysis of geographical patterns and risk factors of Crimes in Nigeria. Spatial Statistics 41: 100485. [Google Scholar] [CrossRef]
- Andresen, Martin A., Olivia K. Ha, and Garth Davies. 2021. Spatially varying unemployment and crime effects in the long run and short run. The Professional Geographer 73: 297–311. [Google Scholar] [CrossRef]
- Anselin, Luc. 1995. Local indicators of spatial association-LISA. Geographical Analysis 27: 93–115. [Google Scholar] [CrossRef]
- Anselin, Luc, Jacqueline Cohen, David Cook, Wilpen Gorr, and George Tita. 2000. Spatial analyses of crime. In Criminal Justice 2000, Volume 4, Measurement and Analysis of Crime and Justice. Edited by Duffee David. Washington, DC: National Institute of Justice, pp. 213–62. [Google Scholar]
- Bellitto, Matteo, and Mario Coccia. 2018. Interrelationships between Violent crime, demographic and socioeconomic factors: A preliminary analysis between Central-Northern European countries and Mediterranean countries. Journal of Economic and Social Thought 5: 230–46. [Google Scholar]
- Brunsdon, Chris, Stewart Fotheringham, and Martin Charlton. 1998. Geographically weighted regression. Journal of the Royal Statistical Society: Series D (The Statistician) 47: 431–43. [Google Scholar] [CrossRef]
- Bursik, Robert J., Jr. 1988. Social disorganization and theories of crime and delinquency: Problems and prospects. Criminology 26: 519–52. [Google Scholar] [CrossRef]
- Cahill, Meagan E., and Gordon F. Mulligan. 2003. The determinants of crime in Tucson, Arizona. Urban Geography 24: 582–610. [Google Scholar] [CrossRef]
- Cahill, Meagan, and Gordon Mulligan. 2007. Using geographically weighted regression to explore local crime patterns. Social Science Computer Review 25: 174–93. [Google Scholar] [CrossRef]
- Cho, Seong-Hoon, Dayton M. Lambert, and Zhuo Chen. 2010. Geographically weighted regression bandwidth selection and spatial autocorrelation: An empirical example using Chinese agriculture data. Applied Economics Letters 17: 767–72. [Google Scholar] [CrossRef]
- Ciacci, Andrea, and Giulia Tagliafico. 2020. Measuring the existence of a link between crime and social deprivation within a metropolitan area. Revista de Estudios Andaluces 40: 58–77. [Google Scholar] [CrossRef]
- Data.london.gov.uk. 2022a. London Borough Profiles and Atlas—London Datastore. Available online: https://data.london.gov.uk/dataset/london-borough-profiles (accessed on 7 April 2022).
- Data.london.gov.uk. 2022b. Statistical GIS Boundary Files for London—London Datastore. Available online: https://data.london.gov.uk/dataset/statistical-gis-boundary-files-london (accessed on 7 April 2022).
- Data.london.gov.uk. 2022c. Ward Profiles and Atlas—London Datastore. Available online: https://data.london.gov.uk/dataset/ward-profiles-and-atlas (accessed on 7 April 2022).
- Eck, John, and David L. Weisburd. 1955. Crime places in crime theory. In Crime and Place: Crime Prevention Studies. Monsey: Criminal Justice Press, vol. 4. [Google Scholar]
- ESRI. 2019. Data Classification Methods—ArcGIS Pro|ArcGIS Desktop. Available online: http://pro.arcgis.com/en/pro-app/help/mapping/layer-properties/data-classification-methods.htm (accessed on 8 March 2022).
- Fazel, Seena, Johan Zetterqvist, Henrik Larsson, Niklas Långström, and Paul Lichtenstein. 2014. Antipsychotics, mood stabilisers, and risk of violent crime. The Lancet 384: 1206–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fotheringham, A. Stewart, and Chris Brunsdon. 1999. Local forms of spatial analysis. Geographical Analysis 31: 340–58. [Google Scholar] [CrossRef]
- Fotheringham, A. Stewart, Ricardo Crespo, and Jing Yao. 2015. Geographical and temporal weighted regression (GTWR). Geographical Analysis 47: 431–52. [Google Scholar] [CrossRef] [Green Version]
- Goh, Lim Thye, and Siong Hook Law. 2023. The crime rate of five Latin American countries: Does income inequality matter? International Review of Economics & Finance 86: 745–63. [Google Scholar]
- Gollini, Isabella, Binbin Lu, Martin Charlton, Christopher Brunsdon, and Paul Harris. 2013. GWmodel: An R package for exploring spatial heterogeneity using geographically weighted models. arXiv arXiv:1306.0413. [Google Scholar] [CrossRef] [Green Version]
- Griffith, Daniel A., Carl G Amrhein, and Joseph R Desloges. 1991. Statistical Analysis for Geographers. Englewood Cliffs: Prentice Hall. [Google Scholar]
- Gruenewald, Paul J., Bridget Freisthler, Lillian Remer, Elizabeth A. LaScala, and Andrew Treno. 2006. Ecological models of alcohol outlets and violent assaults: Crime potentials and geospatial analysis. Addiction 101: 666–77. [Google Scholar] [CrossRef] [PubMed]
- Harris, Richard. 2016. Quantitative Geography: The Basics. London: Sage. [Google Scholar]
- He, Li, Antonio Páez, Desheng Liu, and Shiguo Jiang. 2015. Temporal stability of model parameters in crime rate analysis: An empirical examination. Applied Geography 58: 141–52. [Google Scholar] [CrossRef]
- Higgins, N., P. Robb, and A. Binton. 2010. Geographic Patterns of Crime in Home Office (2010) Crime in England and Wales 2009/10: Findings from the British Crime Survey and Police Recorded Crime. London: Home Office. [Google Scholar]
- Holt, James B. 2007. The topography of poverty in the United States: A spatial analysis using county-level data from the community health status indicators project. Preventing Chronic Disease 4: 1–9. [Google Scholar]
- IACA International Association of Crime Analysts. 2014. Definition and Types of Crime Analysis [White Paper 2014-02]. Overland Park: Author. [Google Scholar]
- IMD. 2010. English Indices of Deprivation 2019, GOV.UK. Available online: https://www.gov.uk/government/statistics/english-indices-of-deprivation-2010 (accessed on 8 May 2023).
- Kim, Suhong, Param Joshi, Parminder Singh Kalsi, and Pooya Taheri. 2018. Crime Analysis Through Machine Learning. Paper presented at 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, November 1–3. [Google Scholar]
- Leng, Ling, Tianyi Zhang, Lawrence Kleinman, and Wei Zhu. 2007. Ordinary least square regression, orthogonal regression, geometric mean regression and their applications in aerosol science. Journal of Physics: Conference Series 78: 012084. [Google Scholar] [CrossRef]
- Lightowlers, Carly, Jose Pina-Sánchez, and Fiona McLaughlin. 2023. The role of deprivation and alcohol availability in shaping trends in violent crime. European Journal of Criminology 20: 738–57. [Google Scholar] [CrossRef]
- Livingston, Mark, Ade Kearns, and Jon Bannister. 2014. Neighbourhood structures and crime: The influence of tenure mix and other structural factors upon local crime rates. Housing Studies 29: 1–25. [Google Scholar] [CrossRef]
- Lochner, Lance, and Enrico Moretti. 2004. The effect of education on crime: Evidence from prison inmates, arrests, and self-reports. American Economic Review 94: 155–89. [Google Scholar] [CrossRef] [Green Version]
- Luo, Liang, Min Deng, Yan Shi, Shijuan Gao, and Baoju Liu. 2022. Associating street crime incidences with geographical environment in space using a zero-inflated negative binomial regression model. Cities 129: 103834. [Google Scholar] [CrossRef]
- Mair, Christina, Paul J. Gruenewald, William R. Ponicki, and Lillian Remer. 2013. Varying impacts of alcohol outlet densities on violent assaults: Explaining differences across neighbourhoods. Journal of Studies on Alcohol and Drugs 74: 50–58. [Google Scholar] [CrossRef] [Green Version]
- Martinez, Natalie N., YongJei Lee, and John E. Eck. 2017. How concentrated is crime among victims? A systematic review from 1977 to 2014. Crime Science 6: 9. [Google Scholar]
- Messer, Lynne C., Jay S. Kaufman, Nancy Dole, David A. Savitz, and Barbara A. Laraia. 2006. Neighborhood crime, deprivation, and preterm birth. Annals of Epidemiology 16: 455–62. [Google Scholar] [CrossRef]
- Met.police.uk. 2022. Stats and Data|The Met. Available online: https://www.met.police.uk/sd/stats-and-data/ (accessed on 7 April 2022).
- Moran, Patrick A. P. 1948. The interpretation of statistical maps. Journal of the Royal Statistical Society, Series B 10: 243–51. [Google Scholar] [CrossRef]
- Myers, Raymond H., and Raymond H. Myers. 1990. Classical and Modern Regression with Applications. Belmont: Duxbury Press, vol. 2. [Google Scholar]
- Nezami, Somayeh, and Ehsan Khoramshahi. 2016. Spatial modeling of crime by using of GWR method. Paper presented at 2016 Baltic Geodetic Congress (BGC Geomatics), Gdansk, Poland, June 2–4; pp. 222–27. [Google Scholar]
- O’brien, Robert M. 2007. A caution regarding rules of thumb for variance inflation factors. Quality & Quantity 41: 673–90. [Google Scholar]
- ONS. 2023. The National Archives. Available online: https://webarchive.nationalarchives.gov.uk/ukgwa/20160108131156/http://www.ons.gov.uk/ons/guide-method/geography/beginner-s-guide/administrative/england/electoral-wards-divisions/index.html (accessed on 18 May 2023).
- Oyelade, Aduralere Opeyemi. 2019. Determinants of crime in Nigeria from economic and socioeconomic perspectives: A macro-level analysis. International Journal of Health Economics and Policy 4: 20–28. [Google Scholar] [CrossRef] [Green Version]
- Porter, Jeremy R., and Christopher W. Purser. 2010. Social disorganization, marriage, and reported crime: A spatial econometrics examination of family formation and criminal offending. Journal of Criminal Justice 38: 942–50. [Google Scholar] [CrossRef]
- Raphael, Steven, and Rudolf Winter-Ebmer. 2001. Identifying the effect of unemployment on crime. The Journal of Law and Economics 44: 259–83. [Google Scholar] [CrossRef] [Green Version]
- Ratcliffe, Jerry. 2010. Crime mapping: Spatial and temporal challenges. In Handbook of Quantitative Criminology. Edited by Alexis Russell Piquero and David Weisburd. New York: Springer, pp. 5–24. [Google Scholar]
- Roth, Robert E., Kevin S. Ross, Benjamin G. Finch, Wei Luo, and Alan M. MacEachren. 2010. A user-centered approach for designing and developing spatiotemporal crime analysis tools. Paper presented at GIScience, Zurich, Switzerland, September 14–17; vol. 15. [Google Scholar]
- Sampson, Robert J. 1985. Race and criminal violence: A demographically disaggregated analysis of urban homicide. Crime & Delinquency 31: 47–82. [Google Scholar]
- Sampson, Robert J. 1987. Urban black violence: The effect of male joblessness and family disruption. American Journal of Sociology 93: 348–82. [Google Scholar] [CrossRef] [Green Version]
- Sampson, Robert J., and W. Byron Groves. 1989. Community structure and crime: Testing social-disorganization theory. American Journal of Sociology 94: 774–802. [Google Scholar] [CrossRef] [Green Version]
- Sampson, Robert J., Stephen W. Raudenbush, and Felton Earls. 1997. Neighborhoods and violent crime: A multilevel study of collective efficacy. Science 277: 918–24. [Google Scholar] [CrossRef]
- Santos, Rachel Boba. 2016. Crime Analysis with Crime Mapping. Thousand Oaks: Sage Publications. [Google Scholar]
- Shaw, Clifford Robe, and Henry Donald McKay. 1942. Juvenile Delinquency and Urban Areas: A Study of Rates of Delinquents in Relation to Differential Characteristics of Local Communities in American Cities. Chicago: University of Chicago Press. [Google Scholar]
- Thulin, Elyse J., Justin E. Heinze, Yasamin Kusunoki, Hsing-Fang Hsieh, and Marc A. Zimmerman. 2021. Perceived neighborhood characteristics and experiences of intimate partner violence: A multilevel analysis. Journal of Interpersonal Violence 36: 13162–84. [Google Scholar] [CrossRef]
- Tseloni, Andromachi, Karin Wittebrood, Graham Farrell, and Ken Pease. 2004. Burglary victimization in England and Wales, the United States and the Netherlands: A cross-national comparative test of routine activities and lifestyle theories. British Journal of Criminology 44: 66–91. [Google Scholar] [CrossRef]
- Tukey, John Wilder. 1977. Exploratory Data Analysis. Reading: Addison-Wesley. [Google Scholar]
- UK Census. 2011. Key Statistics and Quick Statistics for Local Authorities in the United Kingdom—Part 1—Office for National Statistics. Available online: https://www.ons.gov.uk/peoplepopulationandcommunity/populationandmigration/populationestimates/datasets/2011censuskeystatisticsandquickstatisticsforlocalauthoritiesintheunitedkingdompart1 (accessed on 8 May 2023).
- Wilkinson, Richard. 2004. Why is violence more common where inequality is greater? Annals of the New York Academy of Sciences 1036: 1–12. [Google Scholar] [CrossRef]
- Wilkinson, Richard, Kate Pickett, and Molly Scott Cato. 2009. The Spirit Level: Why More Equal Societies Almost Always Do Better. London: Allen Lane. [Google Scholar]
- Zhang, Tonglin, and Ge Lin. 2007. A decomposition of Moran’s I for clustering detection. Computational Statistics & Data Analysis 51: 6123–37. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Themes | Influence Factors |
|---|---|
| Individual wealth | Employment Rate |
| Median Household Income | |
| Regional deprivation | Median House Price |
| Rank of Average Score of Deprivation | |
| Ethnic | Percentage Not Born in UK |
| Percentage of English as the First Language of no one in household | |
| Residential mobility | Percentage Households Social Rented |
| Percentage Households Private Rented | |
| Education | Percentage with No Qualifications |
| Percentage with Level 4 Qualifications and above | |
| Transportation | Transport Accessibility Score |
| Age | Percentage All Children aged 0 to 15 |
| Moran’s Index | z-Score | p-Value |
|---|---|---|
| 0.378 | 18.299 | <2.2 × 10−16 |
| Variables | OLS Model | |
|---|---|---|
| Coefficient Estimations | Standard Error | |
| Intercept | 2.3710 | |
| Percentage All Children aged 0 to 15 | −3.1620 *** | 0.9263 |
| Percentage Not Born in UK | 0.1447 | 0.3487 |
| Employment Rate | 0.5799 | 0.7513 |
| Median Household Income | *** | 0.7941 |
| Transport Accessibility score | 16.7500 *** | 3.4490 |
| Percentage with Level 4 Qualifications and above | −3.3680 *** | 0.5356 |
| Rank of average Score of Deprivation | 0.0367 | 0.0355 |
| Percentage Households Social Rented | 1.4560 *** | 0.4168 |
| Percentage Households Private Rented | 2.4910 *** | 0.6381 |
| Adjusted | 0.3007 | |
| Index | Min. | 1st Qu. | Median | 3rd Qu. | Max | p Values |
|---|---|---|---|---|---|---|
| Intercept | −5.234 | −2.387 | −0.689 | 3.111 | 9.357 | 0.017 |
| Percentage All Children aged 0 to 15 | −10.050 | −6.146 | −4.365 | −3.162 | −2.043 | 0.002 |
| Percentage Not Born in UK | −1.131 | −0.219 | −0.068 | 0.054 | 0.4594 | 0.518 |
| Employment rate | −0.165 | 0.560 | 1.206 | 2.246 | 4.987 | 0.048 |
| Median Household Income | 0.0032 | 0.0037 | 0.0041 | 0.0049 | 0.0064 | 0.952 |
| Transport Accessibility score | 14.360 | 17.630 | 18.890 | 20.320 | 22.750 | 0.724 |
| Percentage with Level 4 qualifications and above | −8.641 | −5.360 | −4.163 | −3.589 | −2.881 | 0.426 |
| Rank of average score of deprivation | 0.0024 | 0.0181 | 0.0344 | 0.0059 | 0.0850 | 0.540 |
| Percentage Households Social Rented | 1.105 | 1.357 | 1.668 | 1.910 | 2.534 | 0.737 |
| Percentage Households Private Rented | 1.973 | 2.417 | 2.796 | 3.076 | 4.3840 | 0.752 |
| 0.3587 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, F.; Zhou, S. The Spatial Patterns of the Crime Rate in London and Its Socio-Economic Influence Factors. Soc. Sci. 2023, 12, 340. https://doi.org/10.3390/socsci12060340
Zhou Y, Wang F, Zhou S. The Spatial Patterns of the Crime Rate in London and Its Socio-Economic Influence Factors. Social Sciences. 2023; 12(6):340. https://doi.org/10.3390/socsci12060340
Chicago/Turabian StyleZhou, Yunqi, Fengwei Wang, and Shijian Zhou. 2023. "The Spatial Patterns of the Crime Rate in London and Its Socio-Economic Influence Factors" Social Sciences 12, no. 6: 340. https://doi.org/10.3390/socsci12060340