
Incorporating Context into BIM-Derived Data—Leveraging Graph Neural Networks for Building Element Classification

Abstract
:1. Introduction
2. Background
2.1. BIM and Semantic Enrichment
2.2. Buildings as Graphs
2.3. Classes of ML Models
3. Research Aims
4. Methods
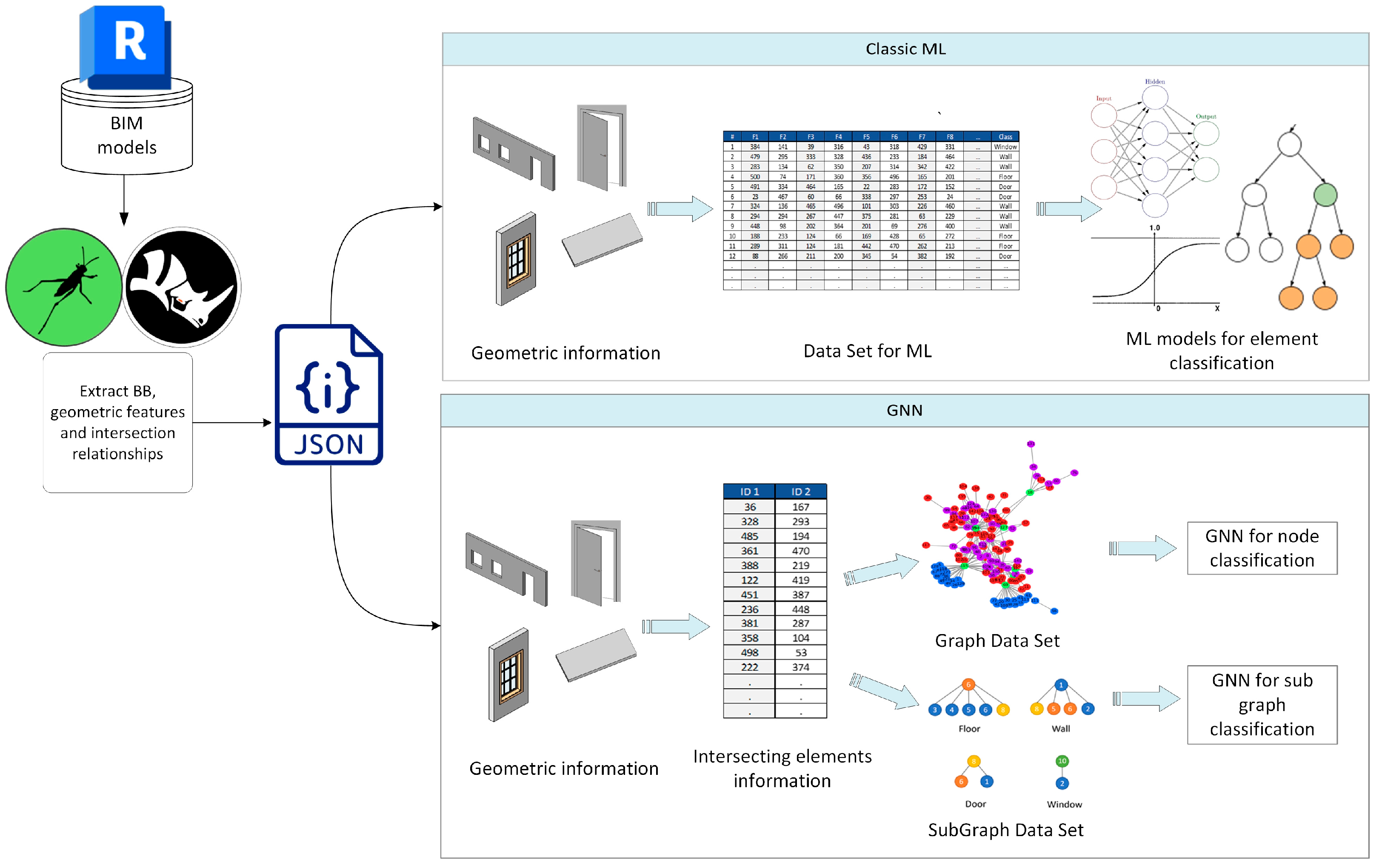
4.1. Graph DataSet Generation
4.1.1. BIM to JSON
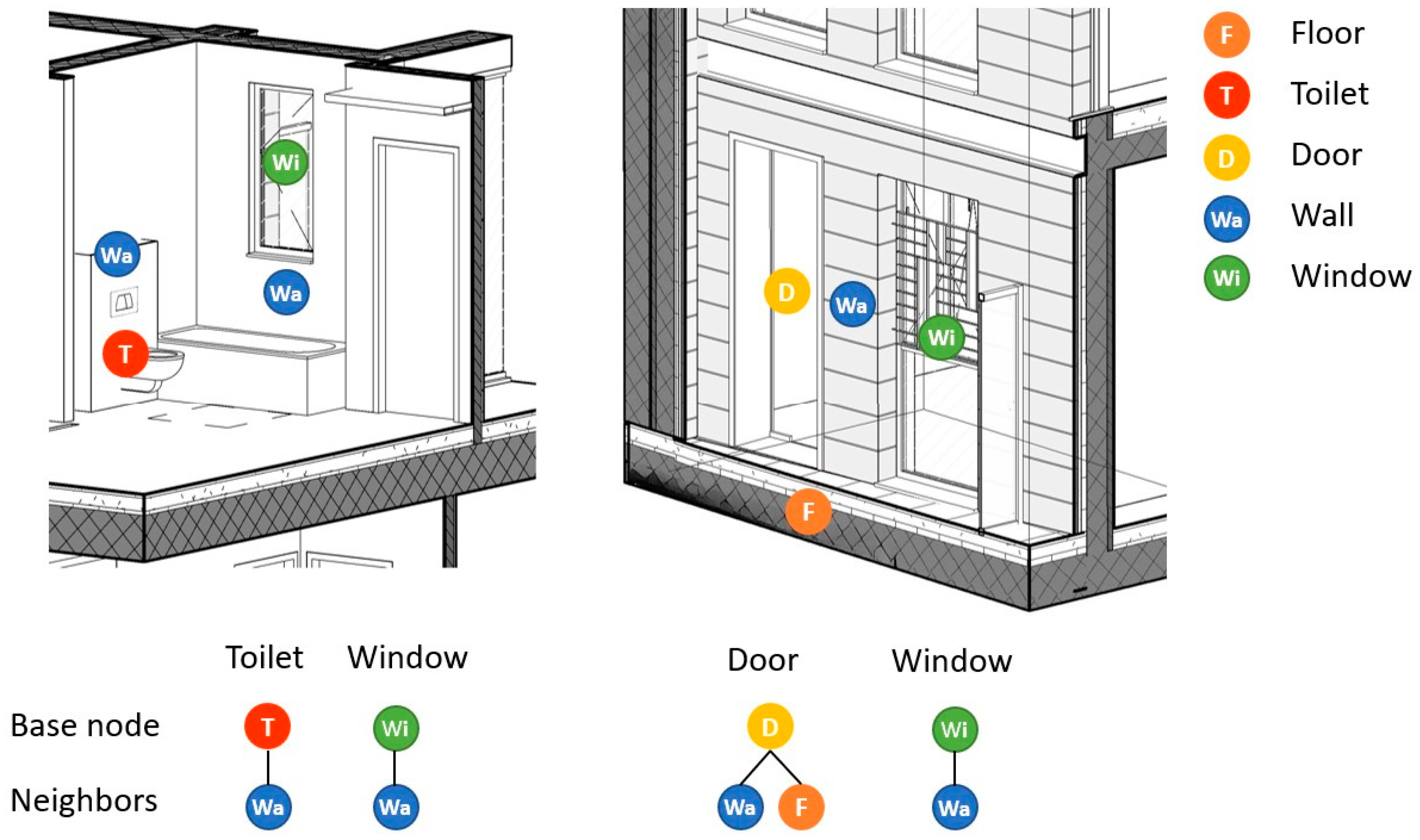
4.1.2. Constructing the Relation Graph
4.1.3. Feature Encoding
4.2. Machine Learning with and without Contextual Information
4.2.1. Training Classic ML Models as a Baseline
4.2.2. Training a Graph Convolutional Network for Node Classification
4.2.3. Training a Subgraph Classification GNN
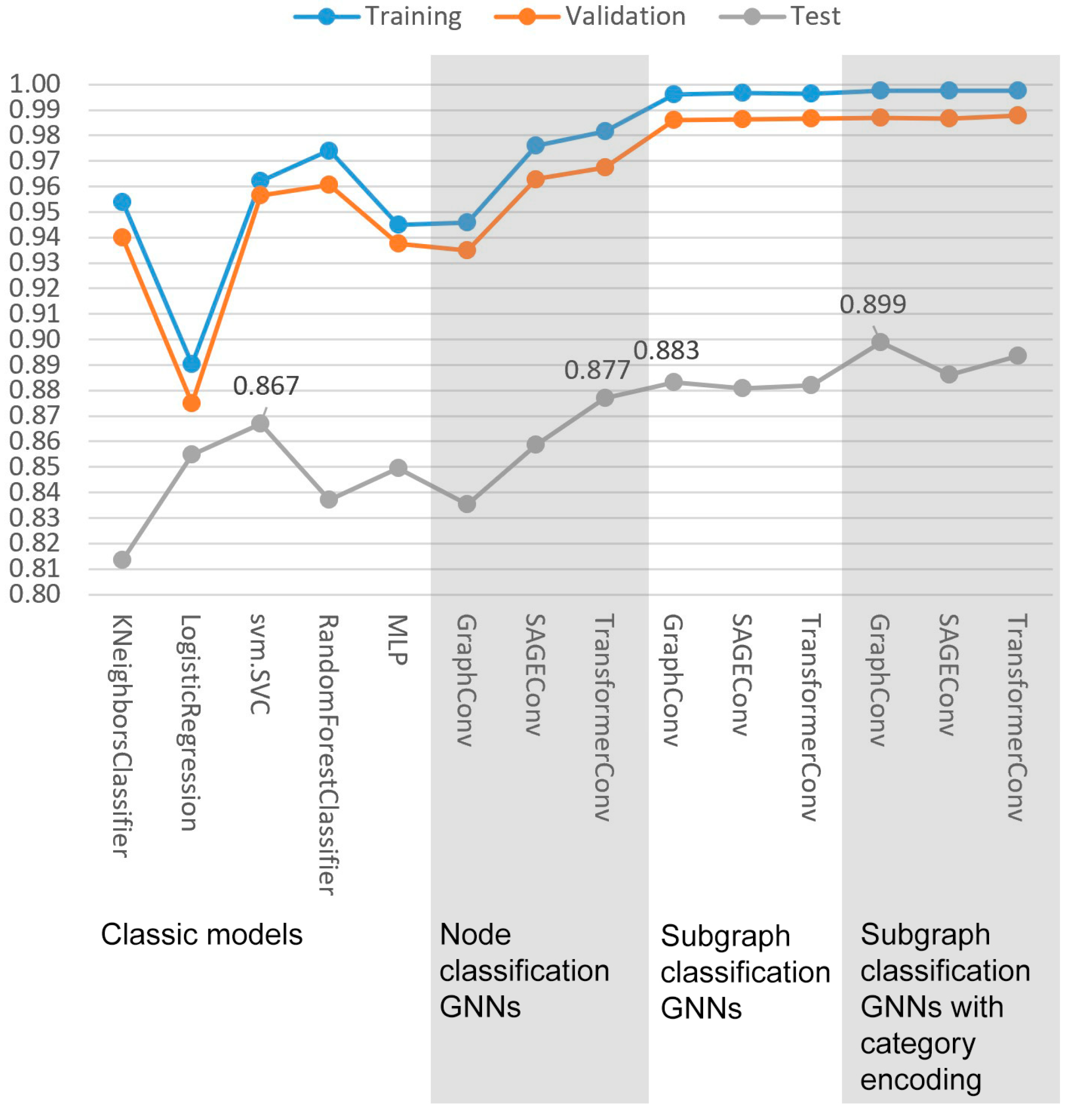
5. Results
5.1. Comparison between Classification Results
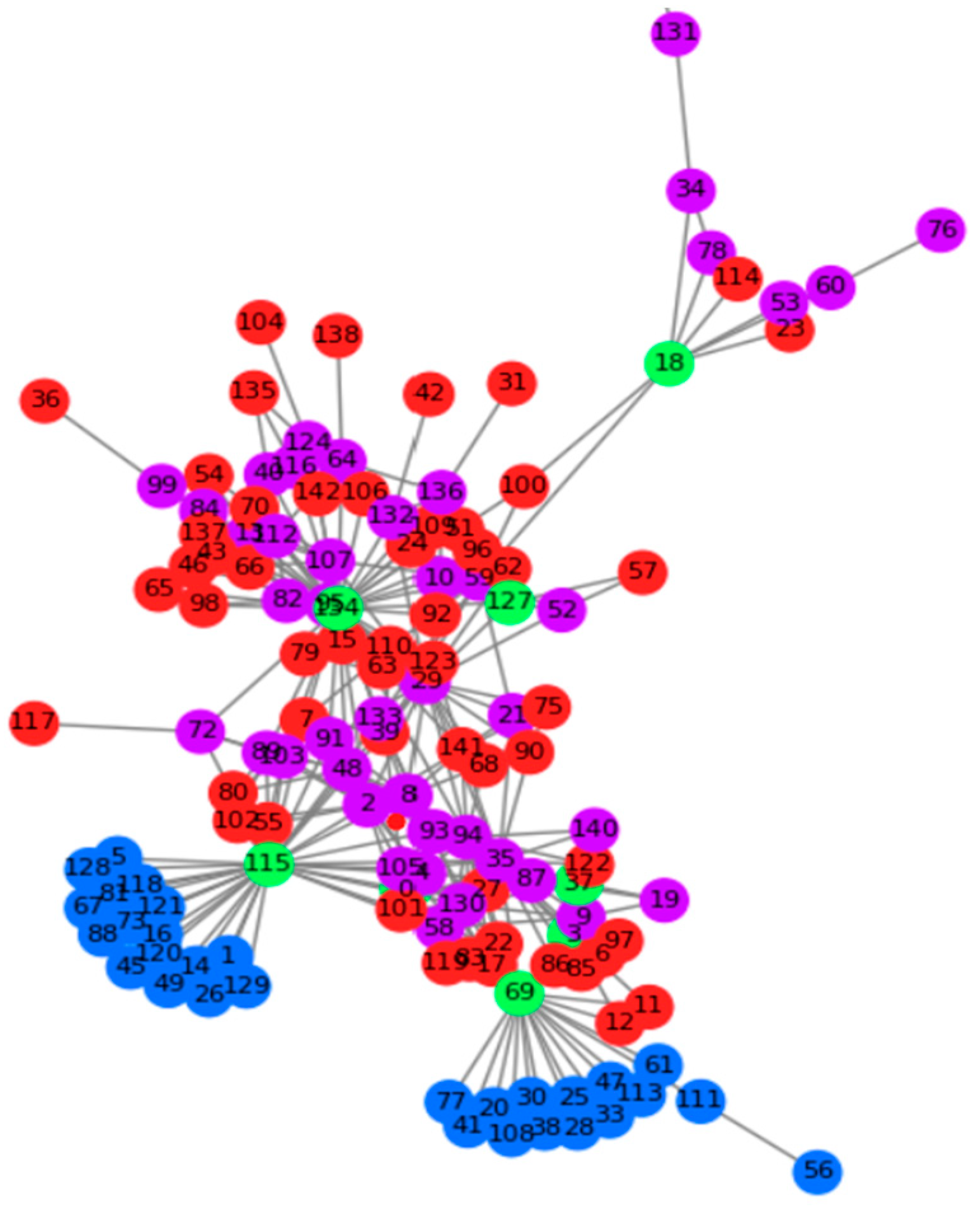
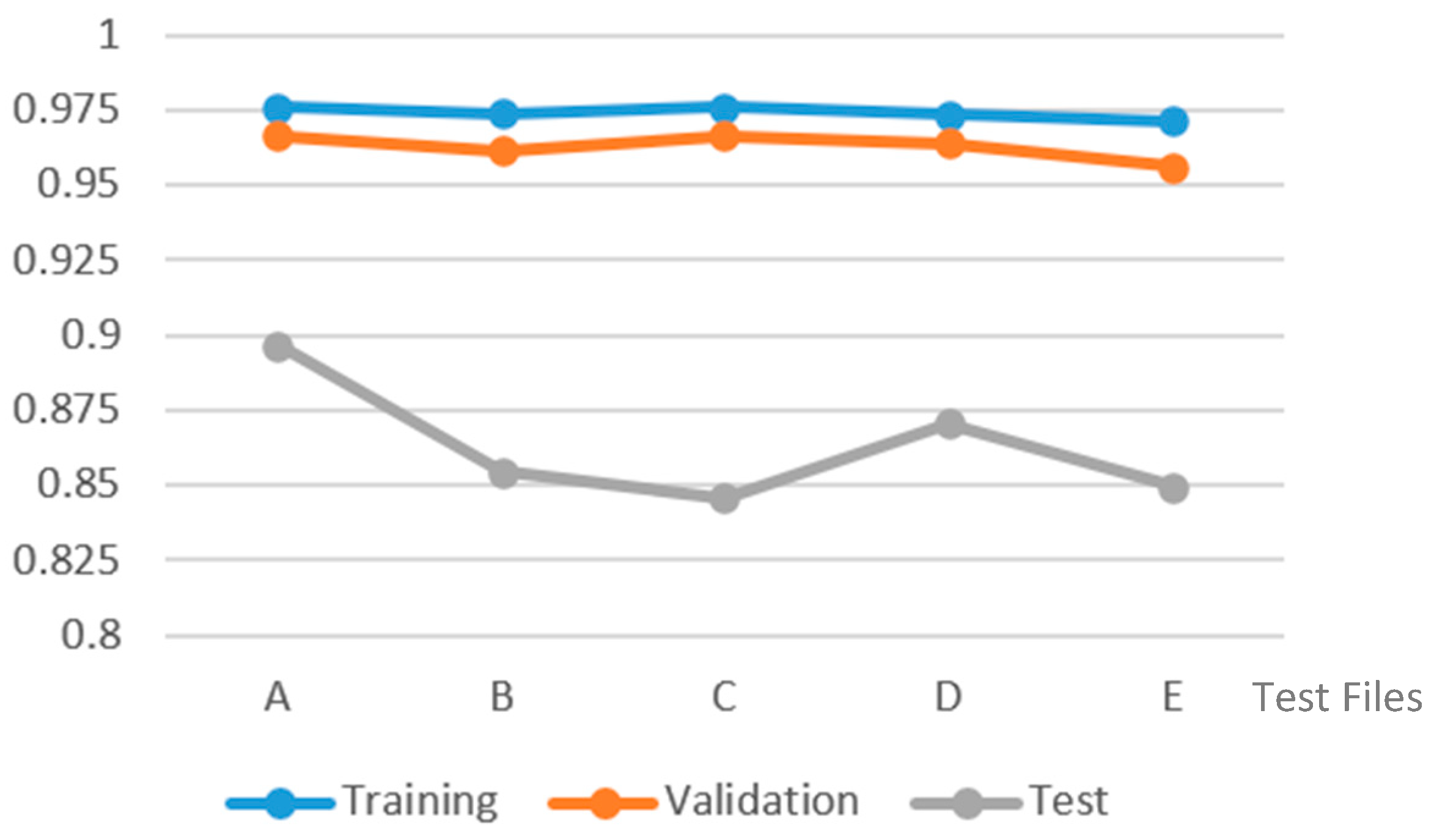
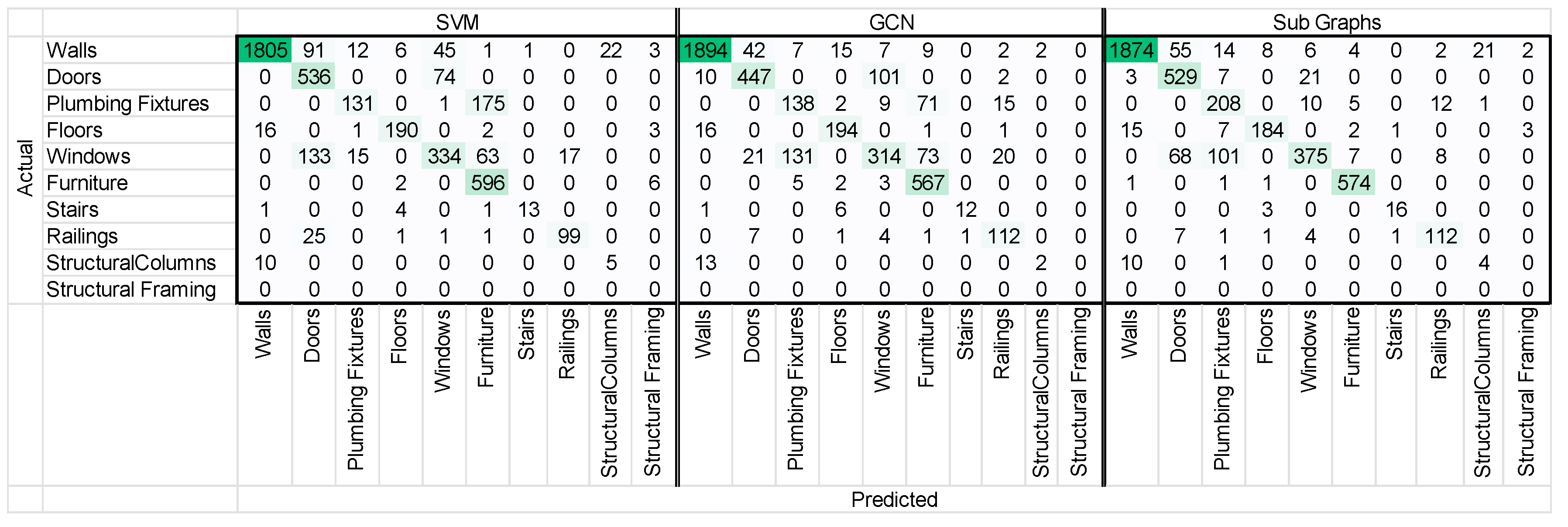
5.2. Test Case Analysis
6. Discussion
6.1. Limitations
6.2. Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bloch, T. Connecting research on semantic enrichment of BIM-review of approaches, methods and possible applications. J. Inf. Technol. Constr. 2022, 27, 416–440. [Google Scholar] [CrossRef]
- Autodesk. Autodesk Revit Software. Available online: https://www.autodesk.com/products/revit/overview (accessed on 29 October 2023).
- Ma, L.; Sacks, R.; Kattel, U.; Bloch, T. 3D Object Classification Using Geometric Features and Pairwise Relationships. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 152–164. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A. Vandergheynst, Geometric deep learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Sacks, R.; Eastman, C.; Lee, G.; Teicholz, P. BIM Handbook: A Guide to Building Information Modeling for Owners, Designers, Engineers, Contractors, and Facility Managers; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Azhar, S.; Khalfan, M.; Maqsood, T. Building Information Modeling (BIM): Now and beyond. Australas. J. Constr. Econ. Build. 2012, 12, 15–28. [Google Scholar]
- Ghaffarianhoseini, A.; Tookey, J.; Ghaffarianhoseini, A.; Naismith, N.; Azhar, S.; Efimova, O.; Raahemifar, K. Building Information Modelling (BIM) uptake: Clear benefits, understanding its implementation, risks and challenges. Renew. Sustain. Energy Rev. 2017, 75, 1046–1053. [Google Scholar] [CrossRef]
- Booch, G. Object Oriented Design with Applications; Benjamin-Cummings Publishing Co., Inc.: San Francisco, CA, USA, 1990. [Google Scholar]
- Wu, J.; Zhang, J. New Automated BIM Object Classification Method to Support BIM Interoperability. J. Comput. Civ. Eng. 2019, 33, 04019033. [Google Scholar] [CrossRef]
- Belsky, M.; Sacks, R.; Brilakis, I. Semantic Enrichment for Building Information Modeling. Comput. Aided Civ. Infrastruct. Eng. 2016, 31, 261–274. [Google Scholar] [CrossRef]
- Sacks, R.; Ma, L.; Yosef, R.; Borrmann, A.; Daum, S.; Kattel, U. Semantic Enrichment for Building Information Modeling: Procedure for Compiling Inference Rules and Operators for Complex Geometry. J. Comput. Civ. Eng. 2017, 31, 04017062. [Google Scholar] [CrossRef]
- Bloch, T.; Katz, M.; Yosef, R.; Sacks, R. Automated model checking for topologically complex code requirements—Security room case study. In Proceedings of the 2019 European Conference for Computing in Construction, University College Dublin, Chania, Greece, 10–12 July 2019. [Google Scholar] [CrossRef]
- Pauwels, P.; Zhang, S.; Lee, Y.-C. Semantic web technologies in AEC industry: A literature overview. Autom. Constr. 2017, 73, 145–165. [Google Scholar] [CrossRef]
- Koo, B.; La, S.; Cho, N.-W.; Yu, Y. Using support vector machines to classify building elements for checking the semantic integrity of building information models. Autom. Constr. 2019, 98, 183–194. [Google Scholar] [CrossRef]
- Bloch, T.; Sacks, R. Clustering Information Types for Semantic Enrichment of Building Information Models to Support Automated Code Compliance Checking. J. Comput. Civ. Eng. 2020, 34, 04020040. [Google Scholar] [CrossRef]
- Wang, Z.; Ying, H.; Sacks, R.; Borrmann, A. CBIM: A Graph-based Approach to Enhance Interoperability Using Semantic Enrichment. arXiv 2023, arXiv:2304.11672. [Google Scholar]
- Bloch, T.; Sacks, R. Comparing machine learning and rule-based inferencing for semantic enrichment of BIM models. Autom. Constr. 2018, 91, 256–272. [Google Scholar] [CrossRef]
- Wang, Z.; Sacks, R.; Yeung, T. Exploring graph neural networks for semantic enrichment: Room type classification. Autom. Constr. 2022, 134, 104039. [Google Scholar] [CrossRef]
- Kim, J.; Song, J.; Lee, J. Recognizing and Classifying Unknown Object in BIM Using 2D CNN. In Computer-Aided Architectural Design. “Hello, Culture”. CAAD Futures 2019; Lee, J., Ed.; Springer: Singapore, 2019; pp. 47–57. [Google Scholar] [CrossRef]
- Koo, B.; Jung, R.; Yu, Y. Automatic classification of wall and door BIM element subtypes using 3D geometric deep neural networks. Adv. Eng. Inform. 2021, 47, 101200. [Google Scholar] [CrossRef]
- Wu, J.; Akanbi, T.; Zhang, J. Constructing Invariant Signatures for AEC Objects to Support BIM-Based Analysis Automation through Object Classification. J. Comput. Civ. Eng. 2022, 36, 04022008. [Google Scholar] [CrossRef]
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications, 290; Macmillan: London, UK, 1976. [Google Scholar]
- Degenne, A.; Forsé, M. Introducing Social Networks; Sage: Thousand Oaks, CA, USA, 1999. [Google Scholar]
- Hillier, B.; Hanson, J. The Social Logic of Space; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar]
- Martin, B.D.; Fernández, Á.L.G.; Higueruela, F.R.F. Semantic and topological representation of building indoors: An overview. In Proceedings of the Joint ISPRS Workshop on 3D City Modelling & Applications and the 6th 3D GeoInfo Conference, Wuhan, China, 26–28 June 2011. [Google Scholar]
- Langenhan, C.; Weber, M.; Liwicki, M.; Petzold, F.; Dengel, A. Graph-based retrieval of building information models for supporting the early design stages. Adv. Eng. Inform. 2013, 27, 413–426. [Google Scholar] [CrossRef]
- Strug, B. Automatic design quality evaluation using graph similarity measures. Autom. Constr. 2013, 32, 187–195. [Google Scholar] [CrossRef]
- Isaac, S.; Sadeghpour, F.; Navon, R. Analyzing Building Information Using Graph Theory. In Proceedings of the 30th International Symposium on Automation and Robotics in Construction and Mining, Held in Conjunction with the 23rd World Mining Congress, Montreal, QC, Canada, 11–15 August 2013. [Google Scholar] [CrossRef]
- Porter, S.; Tan, T.; Tan, T.; West, G. Breaking into BIM: Performing static and dynamic security analysis with the aid of BIM. Autom. Constr. 2014, 40, 84–95. [Google Scholar] [CrossRef]
- Skandhakumar, N.; Salim, F.; Reid, J.; Drogemuller, R.; Dawson, E. Graph theory based representation of building information models for access control applications. Autom. Constr. 2016, 68, 44–51. [Google Scholar] [CrossRef]
- Strug, B.; Ślusarczyk, G. Reasoning about accessibility for disabled using building graph models based on BIM/IFC. Vis. Eng. 2017, 5, 10. [Google Scholar] [CrossRef]
- Ismail, A.; Strug, B.; Ślusarczyk, G. Building Knowledge Extraction from BIM/IFC Data for Analysis in Graph Databases. In Artificial Intelligence and Soft Computing; Lecture Notes in Computer Science; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 652–664. [Google Scholar] [CrossRef]
- Khalili, A.; Chua, D.K.H. IFC-Based Graph Data Model for Topological Queries on Building Elements. J. Comput. Civ. Eng. 2015, 29, 04014046. [Google Scholar] [CrossRef]
- Tauscher, E.; Bargstädt, H.-J.; Smarsly, K. Generic BIM queries based on the IFC object model using graph theory. In Proceedings of the 16th International Conference on Computing in Civil and Building Engineering, Osaka, Japan, 6–8 July 2016. [Google Scholar]
- Solihin, W.; Eastman, C. A Knowledge Representation Approach to Capturing BIM Based Rule Checking Requirements Using Conceptual Graph. Available online: https://www.semanticscholar.org/paper/A-Knowledge-Representation-Approach-to-Capturing-Solihin-Eastman/6eea60c1d1444974d50e9ed6bff4ea787227f507 (accessed on 21 January 2021).
- Zhao, Q.; Li, Y.; Hei, X.; Yang, M.; A Graph-Based Method for IFC Data Merging. Advances in Civil Engineering. Available online: https://www.hindawi.com/journals/ace/2020/8782740/ (accessed on 21 January 2021).
- Gan, V.J.L. BIM-based graph data model for automatic generative design of modular buildings. Autom. Constr. 2022, 134, 104062. [Google Scholar] [CrossRef]
- Liu, H.; Cheng, J.C.P.; Gan, V.J.L.; Zhou, S. A novel Data-Driven framework based on BIM and knowledge graph for automatic model auditing and Quantity Take-off. Adv. Eng. Inform. 2022, 54, 101757. [Google Scholar] [CrossRef]
- Dutton, D.M.; Conroy, G.V. A review of machine learning. Knowl. Eng. Rev. 1997, 12, 341–367. [Google Scholar] [CrossRef]
- Simeone, O. A Very Brief Introduction to Machine Learning With Applications to Communication Systems. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 648–664. [Google Scholar] [CrossRef]
- Berkson, J. Application of the Logistic Function to Bio-Assay. J. Am. Stat. Assoc. 1944, 39, 357–365. [Google Scholar] [CrossRef]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Chervonenkis, A.Y. Early History of Support Vector Machines. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Schölkopf, B., Luo, Z., Vovk, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–20. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. Available online: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf (accessed on 20 November 2018).
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches. arXiv 2018, arXiv:1803.01164v2. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Buruzs, A.; Šipetić, M.; Blank-Landeshammer, B.; Zucker, G. IFC BIM Model Enrichment with Space Function Information Using Graph Neural Networks. Energies 2022, 15, 8. [Google Scholar] [CrossRef]
- Bloch, T.; Borrmann, A.; Pauwels, P. Graph-based learning for automated code checking—Exploring the application of graph neural networks for design review. Adv. Eng. Inform. 2023, 58, 102137. [Google Scholar] [CrossRef]
- Yang, L.; Huang, W. Representation and assessment of spatial design using a hierarchical graph neural network: Classification of shopping center types. Autom. Constr. 2023, 147, 104727. [Google Scholar] [CrossRef]
- Ouyang, B.; Wang, Z.; Sacks, R. Semantic Enrichment of Object Associations Across Federated BIM Semantic Graphs in a Common Data Environment. In ECPPM 2022—eWork and eBusiness in Architecture, Engineering and Construction 2022; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Collins, F.; Ringsquandl, M.; Braun, A.; Hall, D.; Borrmann, A. Assessing IFC classes with means of geometric deep learning on different graph encodings. In Proceedings of the 2021 European Conference on Computing in Construction, Ixia, Greece, 25–27 July 2021. [Google Scholar]
- Kaczmarek, I.; Iwaniak, A.; Świetlicka, A. Classification of Spatial Objects with the Use of Graph Neural Networks. ISPRS Int. J. Geo-Inf. 2023, 12, 3. [Google Scholar] [CrossRef]
- McNeel. Rhino.Inside®.Revit. Available online: https://www.rhino3d.com/inside/revit/1.0/ (accessed on 29 October 2023).
- Davidson, S. Grasshopper. Available online: https://www.grasshopper3d.com/ (accessed on 29 October 2023).
- Francis, N.; Green, A.; Guagliardo, P.; Libkin, L.; Lindaaker, T.; Marsault, V.; Plantikow, S.; Rydberg, M.; Selmer, P.; Taylor, A. Cypher: An Evolving Query Language for Property Graphs. In Proceedings of the SIGMOD ’18: 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1433–1445. [Google Scholar] [CrossRef]
- Vicknair, C.; Macias, M.; Zhao, Z.; Nan, X.; Chen, Y.; Wilkins, D. A comparison of a graph database and a relational database: A data provenance perspective. In Proceedings of the ACM SE ’10: 48th Annual Southeast Regional Conference, Oxford, MS, USA, 15–17 April 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–6. [Google Scholar] [CrossRef]
- NetworkX. NetworkX—NetworkX Documentation. Available online: https://networkx.org/ (accessed on 29 October 2023).
- pandas. pandas Documentation—pandas 2.1.2 Documentation. Available online: https://pandas.pydata.org/docs/index.html (accessed on 29 October 2023).
- Dahouda, M.K.; Joe, I. A Deep-Learned Embedding Technique for Categorical Features Encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Seger, C. An Investigation of Categorical Variable Encoding Techniques in Machine Learning: Binary versus One-Hot and Feature Hashing. 2018. Available online: https://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-237426 (accessed on 8 January 2024).
- Li, J.; Si, Y.; Xu, T.; Jiang, S. Deep convolutional neural network based ECG classification system using information fusion and one-hot encoding techniques. Math. Probl. Eng. 2018, 2018, 1–10. [Google Scholar] [CrossRef]
- Shen, W.; Zhang, C.; Tian, Y.; Zeng, L.; He, X.; Dou, W.; Xu, X. Inductive Matrix Completion Using Graph Autoencoder. In Proceedings of the CIKM ’21: 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1609–1618. [Google Scholar] [CrossRef]
- scikit-learn. scikit-learn: Machine Learning in Python—scikit-learn 1.3.2 Documentation. Available online: https://scikit-learn.org/stable/ (accessed on 29 October 2023).
- PyTorch. Available online: https://www.pytorch.org (accessed on 29 October 2023).
- PyG. PyG Documentation—pytorch_geometric Documentation. Available online: https://pytorch-geometric.readthedocs.io/en/latest/# (accessed on 29 October 2023).
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907v4. [Google Scholar]
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and Leman Go Neural: Higher-order Graph Neural Networks. arXiv 2019, arXiv:1810.02244v5. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2017, arXiv:1706.02216v4. [Google Scholar]
- Shi, Y.; Huang, Z.; Feng, S.; Zhong, H.; Wang, W.; Sun, Y. Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification. arXiv 2020, arXiv:2009.03509v5. [Google Scholar]










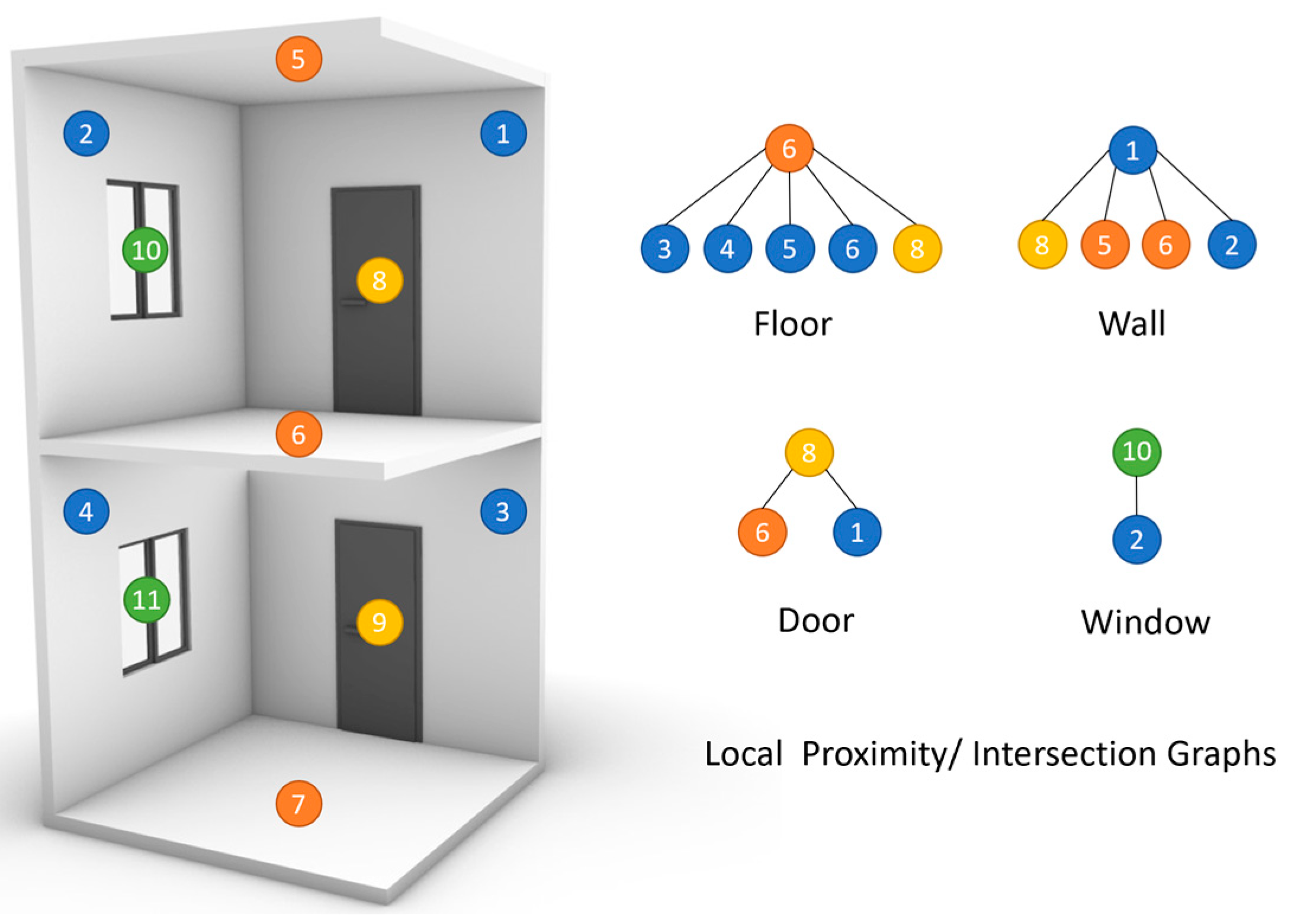{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Count |
|---|---|
| Walls | 22,092 |
| Furniture | 5097 |
| Doors | 5072 |
| Windows | 3448 |
| Floors | 2132 |
| Plumbing Fixtures | 2710 |
| Structural Columns | 829 |
| Railings | 833 |
| Structural Framing | 421 |
| Stairs | 240 |
| Total | 42,874 |
| Bounding Box X Dimension in cm | Bounding Box Y Dimension in cm | Bounding Box Z Dimension in cm |
|---|---|---|
| 0.0 | 0.0 | 0.0 |
| 41.6 | 45.0 | 7.4 |
| 62.8 | 80.6 | 10.0 |
| 90.0 | 125.0 | 15.0 |
| 111.0 | 211.1 | 20.0 |
| 156.2 | 272.0 | 27.0 |
| 220.0 | 310.0 | 40.4 |
| 330.0 | 350.0 | 54.5 |
| 441.6 | 395.0 | 100.0 |
| 1001.7 | 1170.0 | 300.0 |
| Classic Models | Train | Validate | Test |
|---|---|---|---|
| KNNeighbors | 0.956 | 0.945 | 0.778 |
| Logistic Regression | 0.896 | 0.894 | 0.851 |
| Support Vector Machine | 0.966 | 0.961 | 0.835 |
| Random Forest | 0.977 | 0.965 | 0.793 |
| MLP | 0.948 | 0.942 | 0.815 |
| GNN Node Classifiers | |||
| GraphConv | 0.954 | 0.944 | 0.853 |
| SAGEConv | 0.979 | 0.966 | 0.804 |
| TransformerConv | 0.986 | 0.973 | 0.845 |
| GNN Subgraph Classification | |||
| GraphConv | 0.996 | 0.984 | 0.870 |
| SAGEConv | 0.996 | 0.986 | 0.876 |
| TransformerConv | 0.996 | 0.984 | 0.862 |
| GNN Subgraphs with Category Encoding | |||
| GraphConv | 0.998 | 0.989 | 0.921 |
| SAGEConv | 0.998 | 0.989 | 0.903 |
| TransformerConv | 0.998 | 0.989 | 0.907 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Austern, G.; Bloch, T.; Abulafia, Y. Incorporating Context into BIM-Derived Data—Leveraging Graph Neural Networks for Building Element Classification. Buildings 2024, 14, 527. https://doi.org/10.3390/buildings14020527
Austern G, Bloch T, Abulafia Y. Incorporating Context into BIM-Derived Data—Leveraging Graph Neural Networks for Building Element Classification. Buildings. 2024; 14(2):527. https://doi.org/10.3390/buildings14020527
Chicago/Turabian StyleAustern, Guy, Tanya Bloch, and Yael Abulafia. 2024. "Incorporating Context into BIM-Derived Data—Leveraging Graph Neural Networks for Building Element Classification" Buildings 14, no. 2: 527. https://doi.org/10.3390/buildings14020527