
Clustering of Asphalt Pavement Maintenance Sections Based on 3D Ground-Penetrating Radar and Principal Component Techniques

 ,
,
Abstract
:1. Introduction
1.1. Background
1.2. Objective and Scope
2. Methods
2.1. Systematic Clustering Methods
2.2. Dynamic Clustering Methods
2.3. Ordered Clustering Methods
3. Data Collection
3.1. Project and Materials
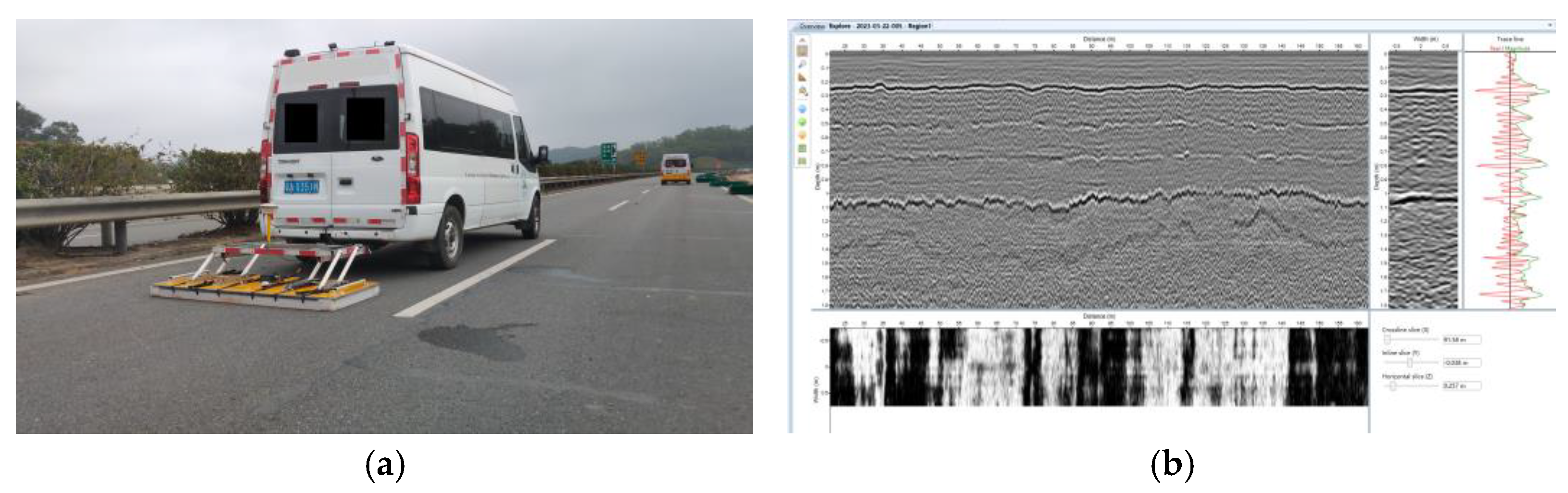
3.2. Data Collection for the Surface Technical Condition
3.3. Data Collection for the Pavement Internal Crack Rate
4. Results and Analysis
4.1. Principal Components Analysis
- (1)
- Applicability test for PCA
- (2)
- Principal component retention
- (3)
- Principal component matrix
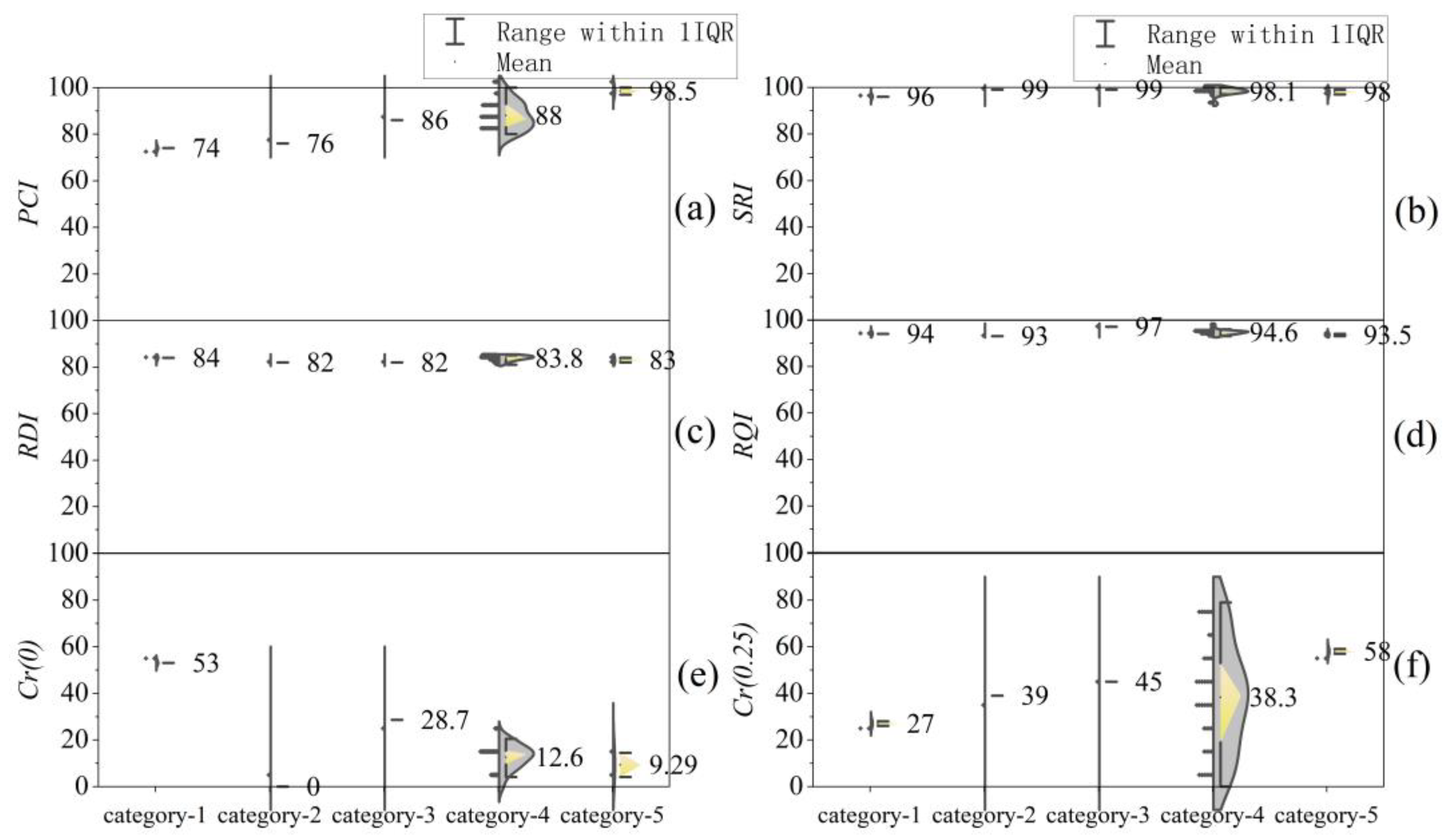
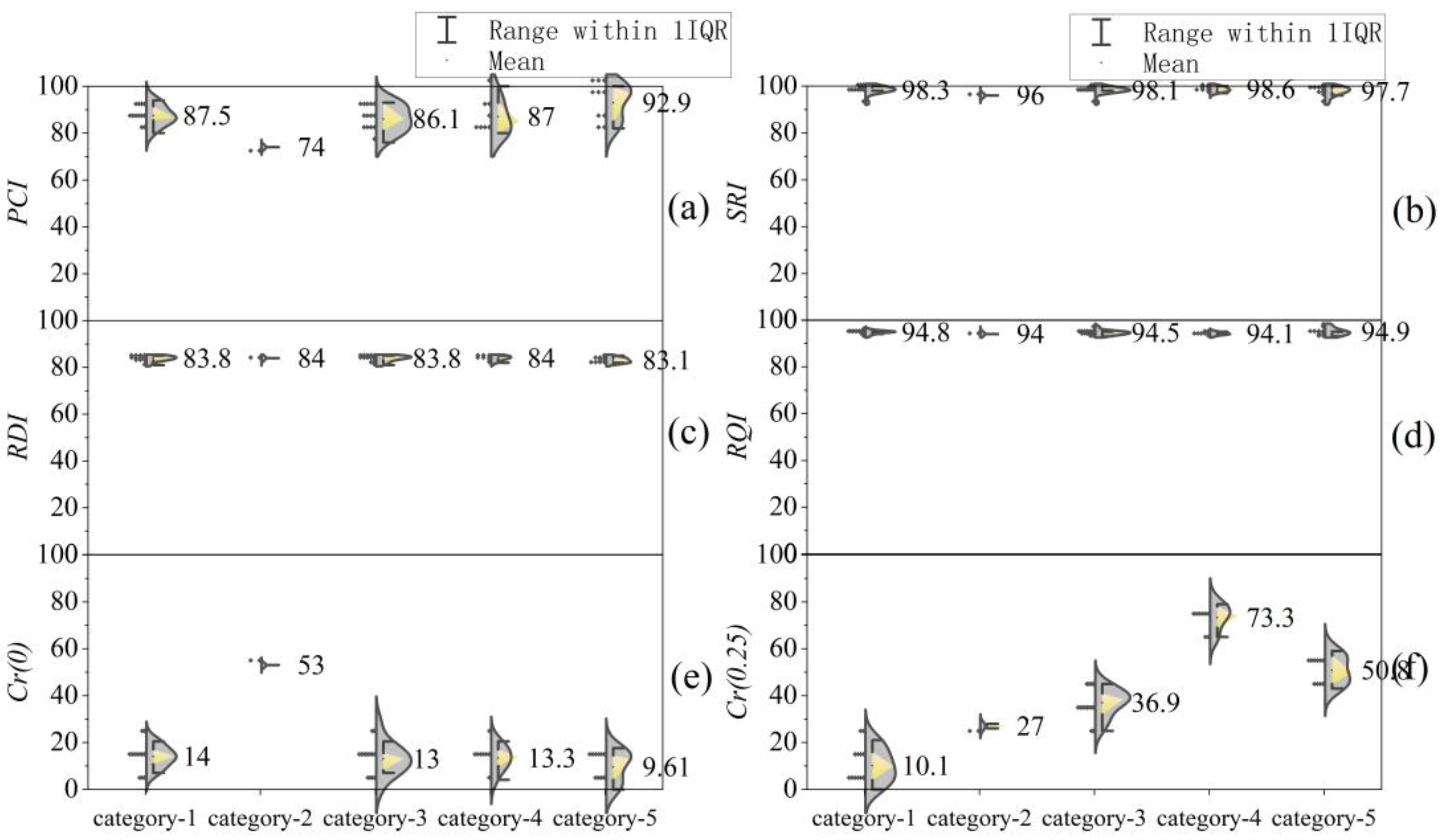
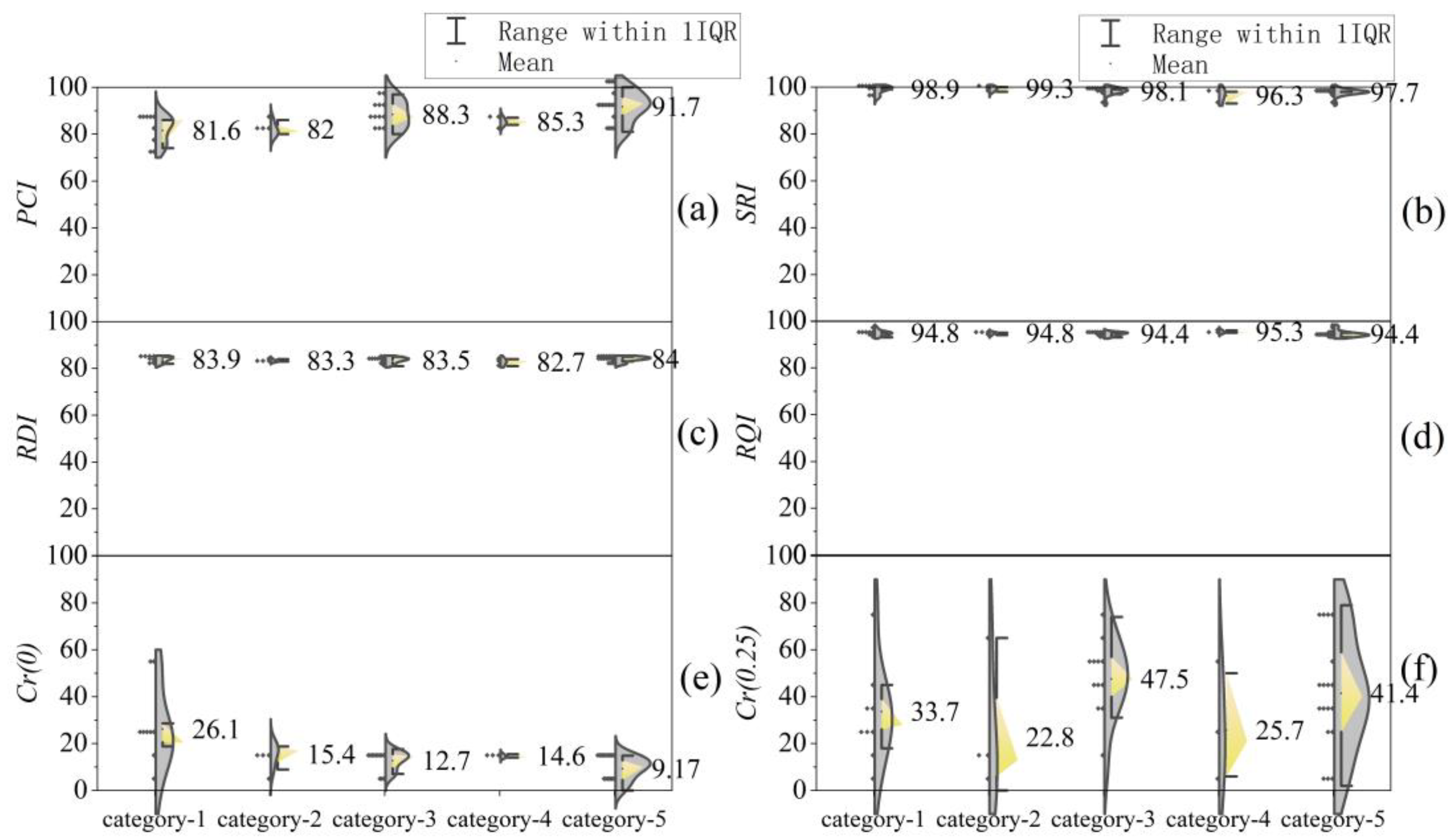
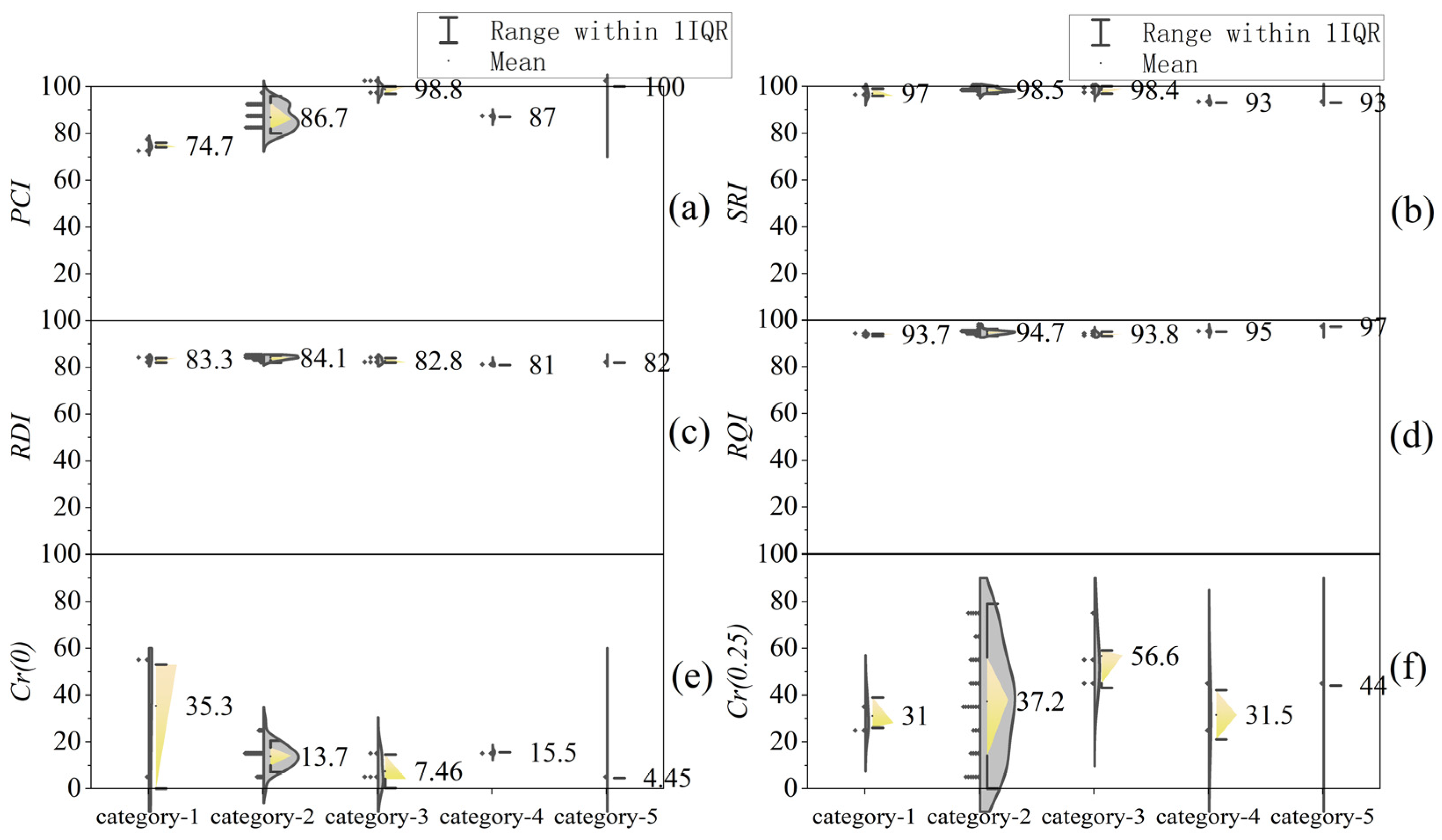
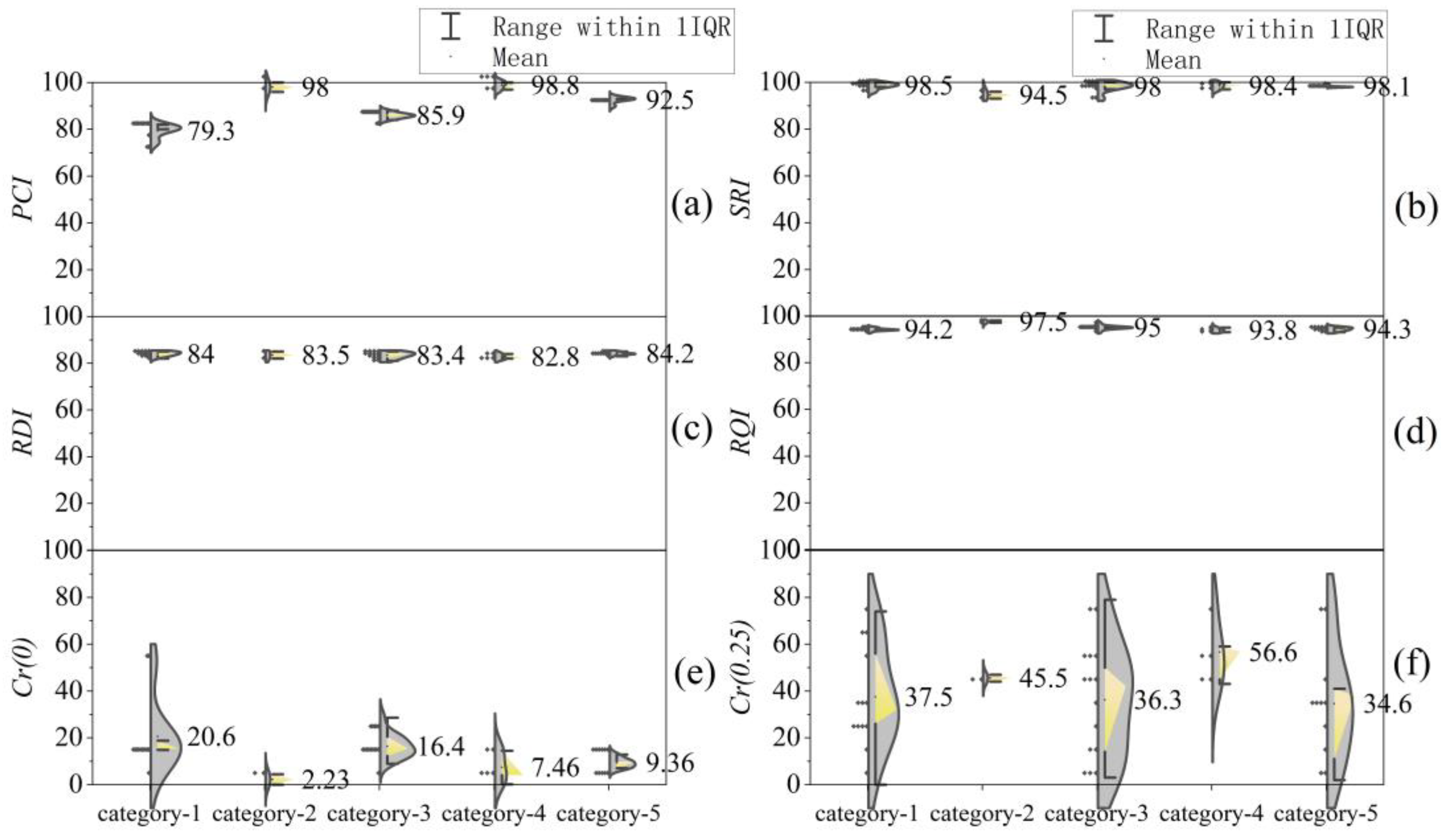
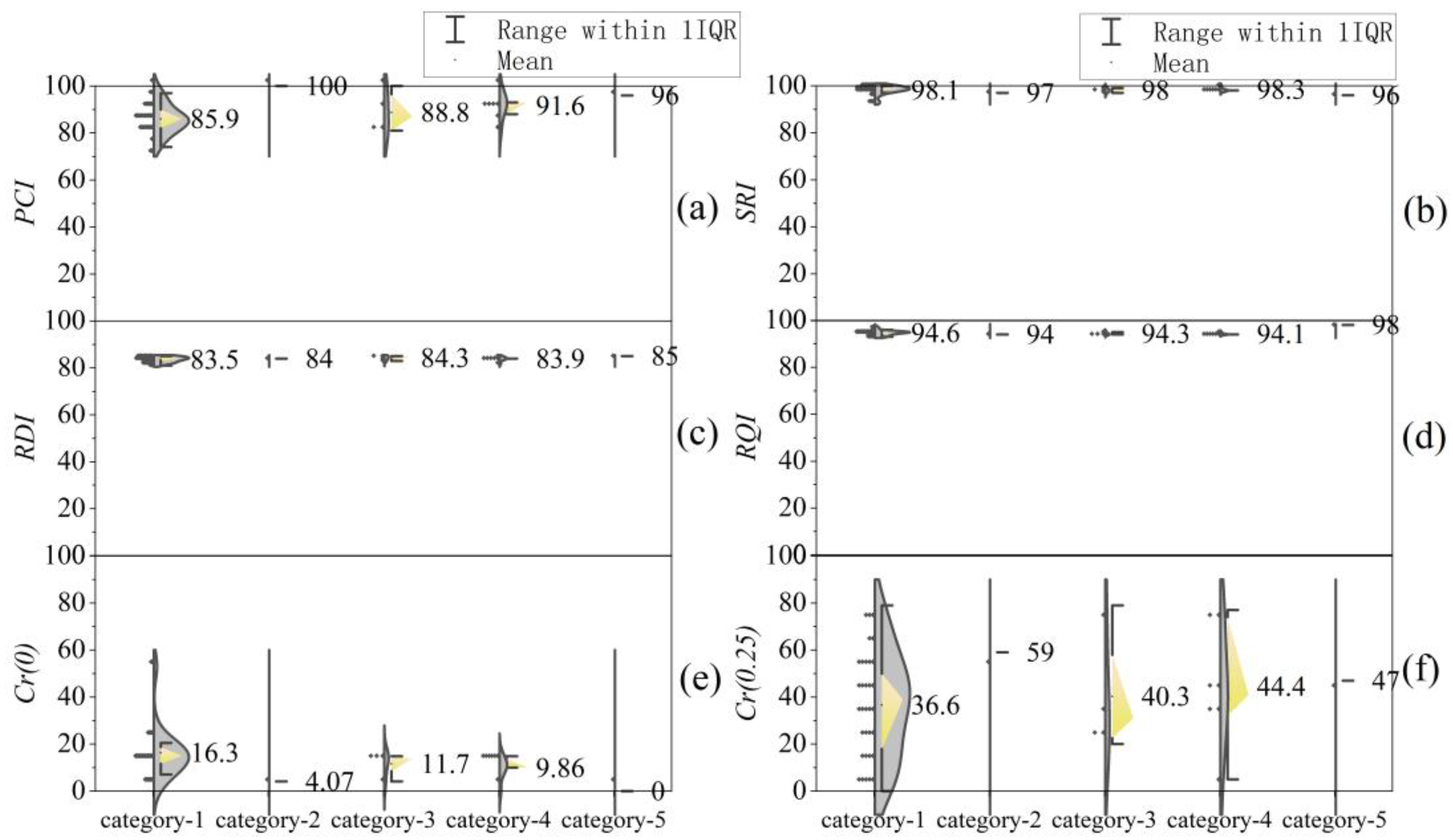
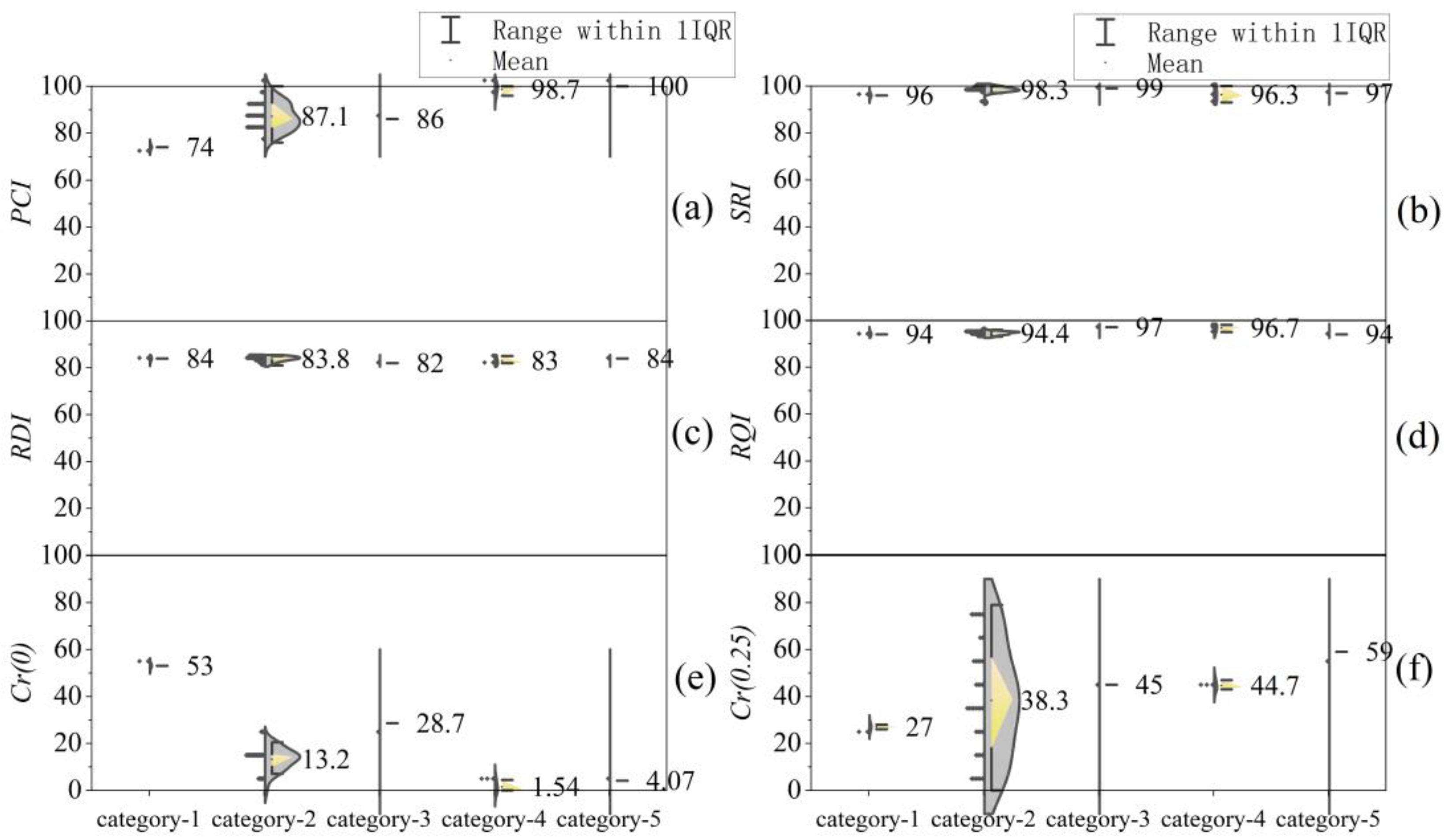
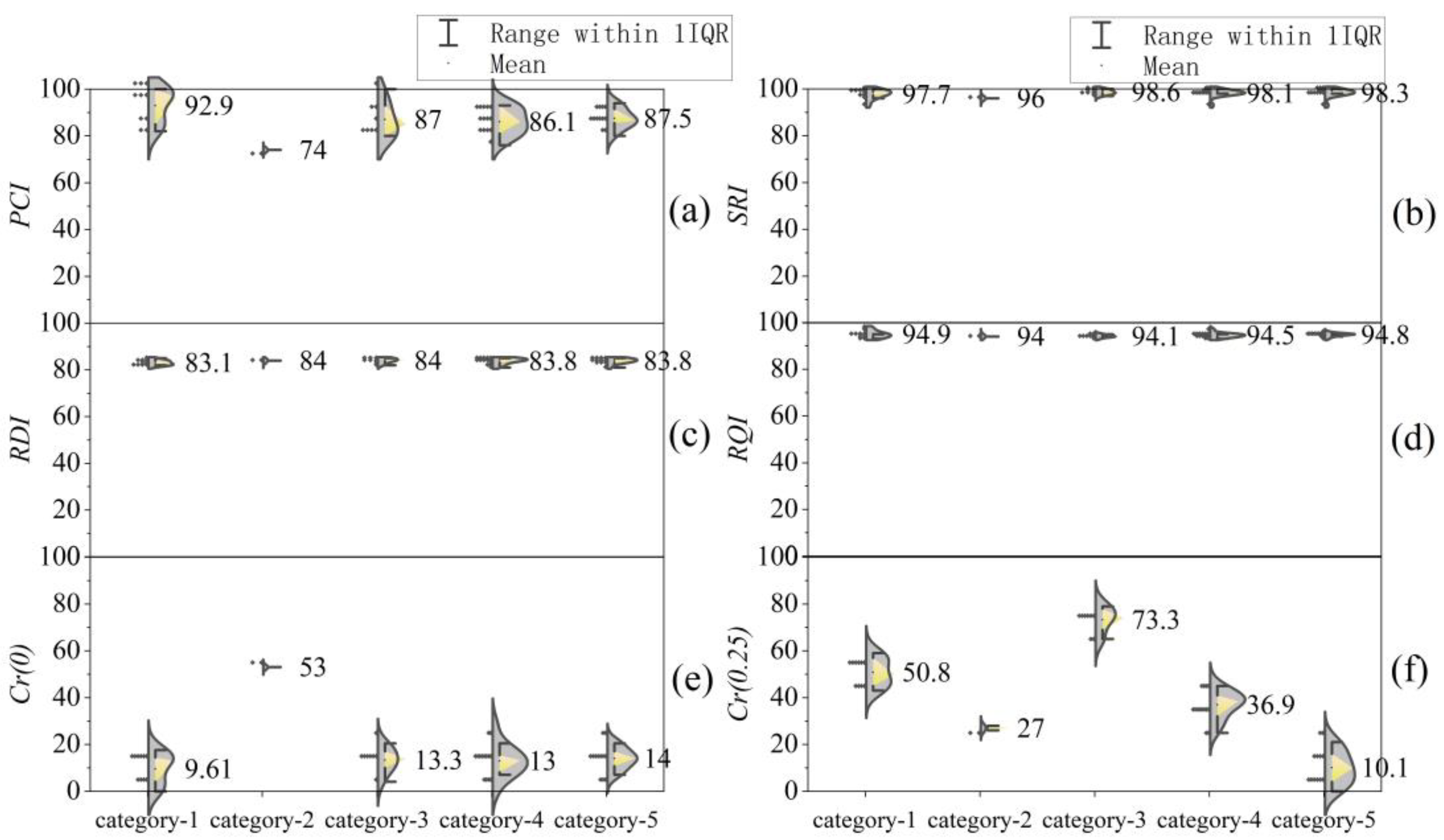
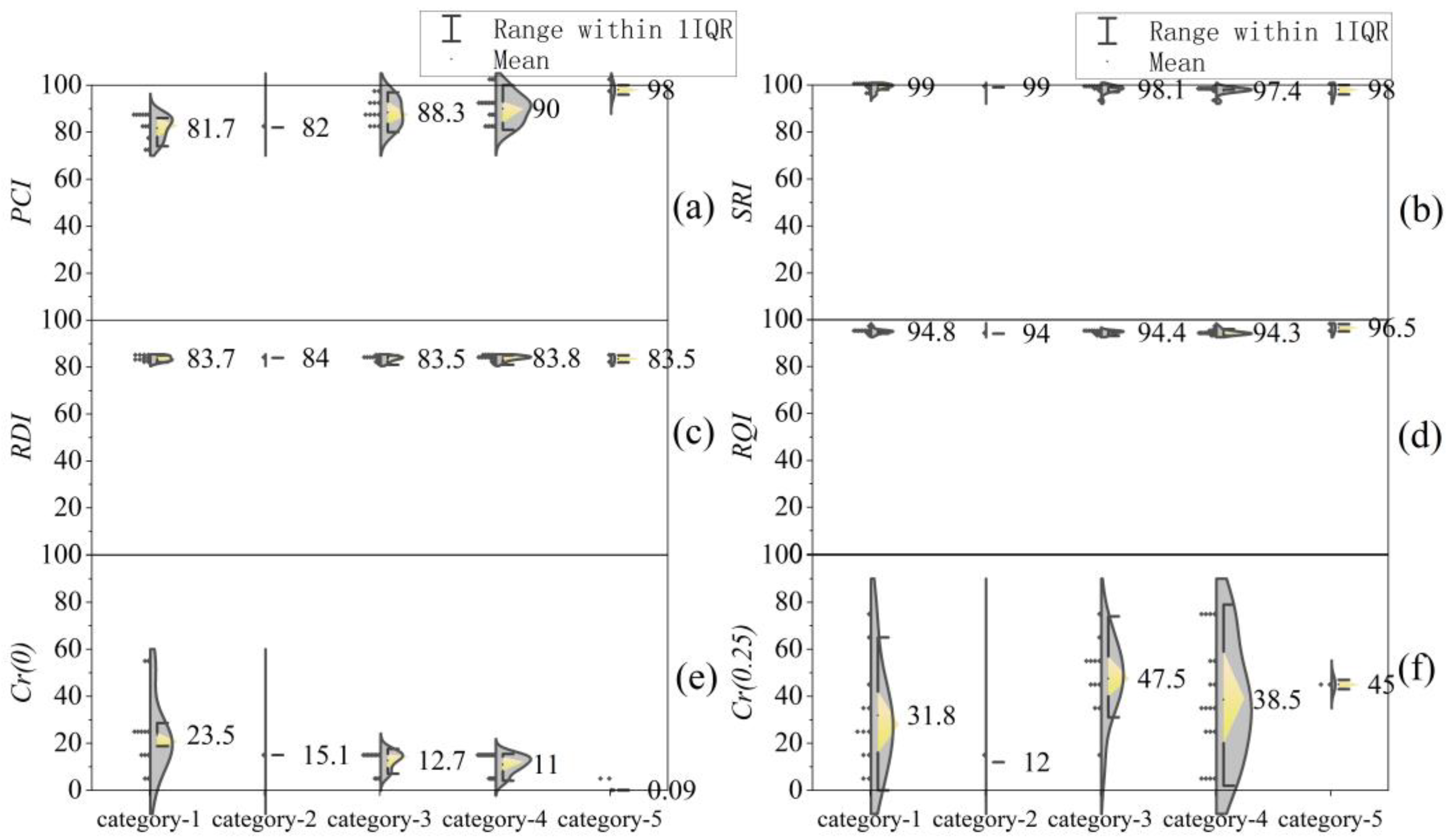
4.2. Analysis of Clustering Results
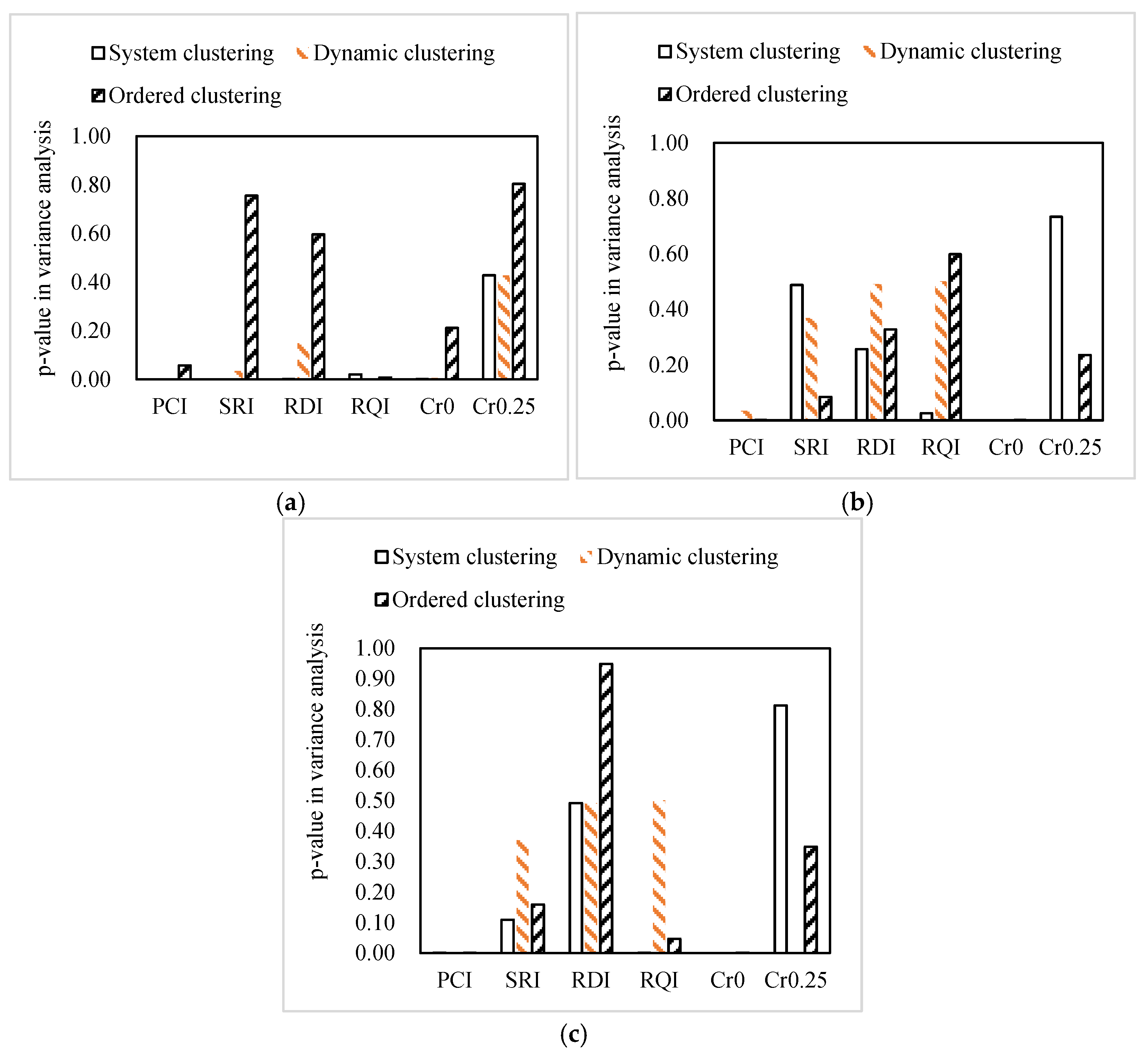
4.3. Applicability of Clustering Methods
5. Conclusions
- (1)
- The characteristics of the cluster data and the technical characteristics of the subdivisions are genetically related. A clustering data matrix that takes into account internal cracking rates is essential in order to provide an effective means of classifying differences in asphalt pavement performance or maintenance requirements;
- (2)
- Classification results vary considerably between clustering methods and the choice of clustering method is related to pavement maintenance objectives. Ordered clustering is not suitable for projects requiring sophisticated maintenance plans, whereas it could be considered for traffic-limited projects. For projects focusing on surface functional indicators only, systematic clustering is advantageous, but combining functional and internal crack rates may be counterproductive. Dynamic clustering is suitable for projects focusing on internal distress effects;
- (3)
- Principal component analysis could reduce data matrix dimensionality by 33% and retain more than 84% of the information. The dynamic clustering method combined with the principal component analysis could significantly improve the significance of the differences for the indicators of interest in the clustering results, as well as the indicators not of interest, effectively improving the classification of asphalt pavement maintenance sections.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Peterson, J.C.; Bourgin, D.D.; Agrawal, M.; Reichman, D.; Griffiths, T.L. Using large-scale experiments and machine learning to discover theories of human decision-making. Science 2021, 372, 1209–1214. [Google Scholar] [CrossRef] [PubMed]
- Davids, E.L. The Interaction between Basic Psychological Needs, Decision-Making and Life Goals among Emerging Adults in South Africa. Soc. Sci. 2022, 11, 316. [Google Scholar] [CrossRef]
- Babashamsi, P.; Khahro, S.H.; Omar, H.A.; Al-Sabaeei, A.M.; Memon, A.M.; Milad, A.; Khan, M.I.; Sutanto, M.H.; Yusoff, N.I. Perspective of Life-Cycle Cost Analysis and Risk Assessment for Airport Pavement in Delaying Preventive Maintenance. Sustainability 2022, 14, 2905. [Google Scholar] [CrossRef]
- Mousa, M.R.; Elseifi, M.A.; Zhang, Z.; Gaspard, K. Development of a Decision-Making Tool to Select Optimum Preventive Maintenance Treatments in a Hot and Humid Climate. Transp. Res. Rec. J. Transp. Res. Board 2020, 2674, 44–56. [Google Scholar] [CrossRef]
- Miah, M.T.; Oh, E.; Chai, G.; Bell, P. An overview of the airport pavement management systems (APMS). Int. J. Pavement Res. Technol. 2021, 13, 581–590. [Google Scholar] [CrossRef]
- Fani, A.; Golroo, A.; Mirhassani, S.A.; Gandomi, A.H. Pavement maintenance and rehabilitation planning optimisation under budget and pavement deterioration uncertainty. Int. J. Pavement Eng. 2020, 23, 414–424. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, M. Multi-objective optimization for pavement maintenance and rehabilitation decision-making: A critical review and future directions. Autom. Constr. 2021, 130, 103840. [Google Scholar] [CrossRef]
- Mo T. JTG 5142-2019; Technical Specifications for Maintenance of HighwayAsphalt Pavement. China Communications Press: Beijing, China, 2019.
- JTG H20-2007; Highway Performance Assessment Standards. Ministry of Transport of the People’s Republic of China: Beijing, China, 2008.
- Anastasopoulos, P.C.; Mannering, F.L. Analysis of Pavement Overlay and Replacement Performance Using Random Parameters Hazard-Based Duration Models. J. Infrastruct. Syst. 2015, 21, 04014024. [Google Scholar] [CrossRef]
- Cinar, Z.M.; Abdussalam Nuhu, A.; Zeeshan, Q.; Korhan, O.; Asmael, M.; Safaei, B. Machine Learning in Predictive Maintenance towards Sustainable Smart Manufacturing in Industry 4.0. Sustainability 2020, 12, 8211. [Google Scholar] [CrossRef]
- Li, F.; Feng, J.; Li, Y.; Zhou, S. Introduction to the Pavement Preventive Maintenance Technology. Preventive Maintenance Technology for Asphalt Pavement; Springer Tracts on Transportation and Traffic; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–35. [Google Scholar]
- Amarasiri, S.; Muhunthan, B. Evaluating the Effectiveness of Pavement Preventive-Maintenance Treatments in Mitigating Longitudinal Cracks in Wet-Freeze Climatic Zones. J. Transp. Eng. Part B Pavements 2020, 146, 04020014. [Google Scholar] [CrossRef]
- Yamany, M.S.; Abraham, D.M. Hybrid Approach to Incorporate Preventive Maintenance Effectiveness into Probabilistic Pavement Performance Models. J. Transp. Eng. Part B Pavements 2021, 147, 04020077. [Google Scholar] [CrossRef]
- Li, J.; Yin, G.; Wang, X.; Yan, W. Automated decision making in highway pavement preventive maintenance based on deep learning. Autom. Constr. 2022, 135, 104111. [Google Scholar] [CrossRef]
- Hassan, M.U.; Steinnes, O.-M.H.; Gustafsson, E.G.; Løken, S.; Hameed, I.A. Predictive Maintenance of Norwegian Road Network Using Deep Learning Models. Sensors 2023, 23, 2935. [Google Scholar] [CrossRef] [PubMed]
- Nautiyal, A.; Sharma, S. Cost-Optimized Approach for Pavement Maintenance Planning of Low Volume Rural Roads: A Case Study in Himalayan Region. Int. J. Pavement Res. Technol. 2022, 1–18. [Google Scholar] [CrossRef]
- Liang, X.; Yu, X.; Chen, C.; Jin, Y.; Huang, J. Automatic Classification of Pavement Distress Using 3D Ground-Penetrating Radar and Deep Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22269–22277. [Google Scholar] [CrossRef]
- Xiong, C.; Yu, J.; Zhang, X. Use of NDT systems to investigate pavement reconstruction needs and improve maintenance treatment decision-making. Int. J. Pavement Eng. 2021, 1–15. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, W.; Gu, X.; Li, S.; Wang, L.; Zhang, T. Application of Combining YOLO Models and 3D GPR Images in Road Detection and Maintenance. Remote Sens. 2021, 13, 1081. [Google Scholar] [CrossRef]
- Hong, X.; Tan, W.; Xiong, C.; Qiu, Z.; Yu, J.; Wang, D.; Wei, X.; Li, W.; Wang, Z. A Fast and Non-Destructive Prediction Model for Remaining Life of Rigid Pavement with or without Asphalt Overlay. Buildings 2022, 12, 868. [Google Scholar] [CrossRef]
- Di Mascio, P.; Moretti, L. Implementation of a pavement management system for maintenance and rehabilitation of airport surfaces. Case Stud. Constr. Mater. 2019, 11, e00251. [Google Scholar] [CrossRef]
- Gkyrtis, K.; Plati, C.; Loizos, A. Mechanistic Analysis of Asphalt Pavements in Support of Pavement Preservation Decision-Making. Infrastructures 2022, 7, 61. [Google Scholar] [CrossRef]
- Nautiyal, A.; Sharma, S. Methods and factors of prioritizing roads for maintenance: A review for sustainable flexible pavement maintenance program. Innov. Infrastruct. Solut. 2022, 7, 190. [Google Scholar] [CrossRef]
- Elmansouri, O.; Alossta, A.; Badi, I. Pavement Condition Assessment Using Pavement Condition Index and Multi-Criteria Decision-Making Model. Mechatronics Intell. Transp. Syst. 2022, 1, 57–68. [Google Scholar] [CrossRef]
- Fang, N.; Chang, H.; Hu, S.; Li, H.; Meng, Q. Climate zoning of asphalt pavement based on spatial interpolation and Fuzzy C-Means algorithm. Int. J. Pavement Eng. 2022, 1–14. [Google Scholar] [CrossRef]
- Milad, A.A.; Adwan, I.; Majeed, S.A.; Memon, Z.A.; Bilema, M.; Omar, H.A.; Abdolrasol, M.G.M.; Usman, A.; Yusoff, N.I.M. Development of a Hybrid Machine Learning Model for Asphalt Pavement Temperature Prediction. IEEE Access 2021, 9, 158041–158056. [Google Scholar] [CrossRef]
- Han, C.; Ma, T.; Chen, S. Asphalt pavement maintenance plans intelligent decision model based on reinforcement learning algorithm. Constr. Build. Mater. 2021, 299, 124278. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Ikotun, A.M.; Oyelade, O.O.; Abualigah, L.; Agushaka, J.O.; Eke, C.I.; Akinyelu, A.A. A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Eng. Appl. Artif. Intell. 2022, 110, 104743. [Google Scholar] [CrossRef]
- Dalmaijer, E.S.; Nord, C.L.; Astle, D.E. Statistical power for cluster analysis. BMC Bioinform. 2022, 23, 205. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Rezaeipanah, A.; El Din, E.M.T. An ensemble agglomerative hierarchical clustering algorithm based on clusters clustering technique and the novel similarity measurement. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 3828–3842. [Google Scholar] [CrossRef]
- Habib, A.; Akram, M.; Kahraman, C. Minimum spanning tree hierarchical clustering algorithm: A new Pythagorean fuzzy similarity measure for the analysis of functional brain networks. Expert Syst. Appl. 2022, 201, 117016. [Google Scholar] [CrossRef]
- Ashari, I.F.; Banjarnahor, R.; Farida, D.R.; Aisyah, S.P.; Dewi, A.P.; Humaya, N. Application of Data Mining with the K-Means Clustering Method and Davies Bouldin Index for Grouping IMDB Movies. J. Appl. Inform. Comput. 2022, 6, 7–15. [Google Scholar] [CrossRef]
- Nie, F.; Li, Z.; Wang, R.; Li, X. An Effective and Efficient Algorithm for K-Means Clustering with New Formulation. IEEE Trans. Knowl. Data Eng. 2022, 35, 3433–3443. [Google Scholar] [CrossRef]
- Xia, J.; Ying, H.; Huang, Y. Application of ordered aggregation optimal partition method in pavement condition evaluation. In Frontier Research: Road and Traffic Engineering; CRC Press: Boca Raton, FL, USA, 2022; pp. 700–706. [Google Scholar]
- Tang, H.; Wang, Y.; Jia, K. Unsupervised domain adaptation via distilled discriminative clustering. Pattern Recognit. 2022, 127, 108638. [Google Scholar] [CrossRef]
- JTG E60-2008; Field Test Methods of Highway Subgrade and Pavement. Ministry of Transport of the People’s Republic of China: Beijing, China, 2008.
- Liu, Z.; Gu, X.; Chen, J.; Wang, D.; Chen, Y.; Wang, L. Automatic recognition of pavement cracks from combined GPR B-scan and C-scan images using multiscale feature fusion deep neural networks. Autom. Constr. 2023, 146, 104698. [Google Scholar] [CrossRef]
- Wang, S.; Leng, Z.; Sui, X. Detectability of concealed cracks in the asphalt pavement layer using air-coupled ground-penetrating radar. Measurement 2023, 208, 112427. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, X. Performance evaluation of full-scale accelerated pavement using NDT and laboratory tests: A case study in Jiangsu, China. Case Stud. Constr. Mater. 2023, 18, e02083. [Google Scholar] [CrossRef]
- Xiong, C.; Yu, J.; Zhang, X.; Korolev, E.; Svetlana, S.; Chen, B.; Chen, F.; Yang, E. Modulus backcalculation methodology based on full-scale testing road and its rationality and feasibility analysis. Int. J. Pavement Eng. 2022, 1–13. [Google Scholar] [CrossRef]
- Burstyn, I. Principal component analysis is a powerful instrument in occupational hygiene inquiries. Ann. Occup. Hyg. 2004, 48, 655–661. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vidal-Alaball, J.; Mateo, G.F.; Domingo, J.L.G.; Gomez, X.M.; Valmaña, G.S.; Ruiz-Comellas, A.; Seguí, F.L.; Cuyàs, F.G. Validation of a Short Questionnaire to Assess Healthcare Professionals’ Perceptions of Asynchronous Telemedicine Services: The Catalan Version of the Health Optimum Telemedicine Acceptance Questionnaire. Int. J. Environ. Res. Public Health 2020, 17, 2202. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Definition |
|---|---|
| Asphalt overlay | 0.5–2 cm preventive maintenance measures |
| Upper layer (asphalt) | 5 cm AK-16 (with base binder asphalt) |
| Middle layer (asphalt) | 6 cm AC-20 (with base binder asphalt) |
| Lower layer (asphalt) | 7 cm AC-25 (with base binder asphalt) |
| Base layer | 38 cm stabilized gravel (cement content: 5–6%) |
| Sub-base layer | 16 cm stabilized gravel (cement content: 4%) |
| Subgrade | Soil |
| Unit Section Number | ||||||
|---|---|---|---|---|---|---|
| 1 | 74 | 96 | 84 | 94 | 53.0 | 26.0 |
| 2 | 74 | 96 | 84 | 94 | 53.0 | 28.0 |
| 3 | 76 | 99 | 82 | 93 | 0.0 | 39.0 |
| 4 | 86 | 99 | 82 | 97 | 28.7 | 45.0 |
| 5 | 86 | 100 | 85 | 95 | 20.5 | 37.0 |
| 6 | 86 | 100 | 85 | 95 | 20.5 | 18.0 |
| 7 | 86 | 100 | 85 | 95 | 20.5 | 79.0 |
| 8 | 86 | 100 | 85 | 95 | 20.5 | 3.0 |
| 9 | 80 | 100 | 83 | 95 | 18.8 | 28.0 |
| 10 | 80 | 100 | 83 | 95 | 18.8 | 65.0 |
| 11 | 80 | 100 | 83 | 95 | 18.8 | 0.0 |
| 12 | 86 | 98 | 83 | 95 | 9.0 | 14.0 |
| 13 | 82 | 99 | 84 | 94 | 15.1 | 12.0 |
| 14 | 82 | 99 | 84 | 94 | 15.1 | 56.0 |
| 15 | 80 | 99 | 85 | 94 | 15.5 | 74.0 |
| 16 | 80 | 99 | 85 | 94 | 15.5 | 65.0 |
| 17 | 85 | 99 | 84 | 95 | 11.7 | 57.0 |
| 18 | 85 | 99 | 84 | 95 | 11.7 | 44.0 |
| 19 | 88 | 97 | 83 | 95 | 17.7 | 50.0 |
| 20 | 97 | 99 | 82 | 93 | 14.5 | 57.0 |
| 21 | 97 | 99 | 82 | 93 | 14.5 | 45.0 |
| 22 | 93 | 98 | 84 | 95 | 7.1 | 38.0 |
| 23 | 93 | 98 | 84 | 95 | 7.1 | 11.0 |
| 24 | 93 | 98 | 84 | 95 | 7.1 | 31.0 |
| 25 | 87 | 93 | 81 | 95 | 15.5 | 42.0 |
| 26 | 87 | 93 | 81 | 95 | 15.5 | 21.0 |
| 27 | 85 | 98 | 84 | 96 | 14.4 | 6.0 |
| 28 | 84 | 98 | 83 | 95 | 14.0 | 50.0 |
| 29 | 90 | 98 | 85 | 93 | 8.1 | 9.0 |
| 30 | 90 | 98 | 85 | 93 | 8.1 | 39.0 |
| 31 | 84 | 98 | 82 | 93 | 12.2 | 73.0 |
| 32 | 100 | 93 | 82 | 97 | 4.5 | 44.0 |
| 33 | 94 | 98 | 85 | 95 | 12.4 | 2.0 |
| 34 | 100 | 97 | 84 | 94 | 4.1 | 59.0 |
| 35 | 100 | 97 | 84 | 94 | 4.1 | 79.0 |
| 36 | 93 | 99 | 83 | 95 | 12.9 | 20.0 |
| 37 | 81 | 98 | 85 | 94 | 14.8 | 37.0 |
| 38 | 81 | 98 | 85 | 94 | 14.8 | 25.0 |
| 39 | 81 | 98 | 85 | 94 | 14.8 | 32.0 |
| 40 | 88 | 98 | 84 | 94 | 13.9 | 5.0 |
| 41 | 93 | 98 | 84 | 94 | 10.0 | 41.0 |
| 42 | 93 | 98 | 84 | 94 | 10.0 | 74.0 |
| 43 | 93 | 98 | 84 | 94 | 10.0 | 77.0 |
| 44 | 93 | 98 | 84 | 94 | 10.0 | 39.0 |
| 45 | 100 | 100 | 82 | 95 | 0.2 | 43.0 |
| 46 | 96 | 96 | 85 | 98 | 0.0 | 47.0 |
| Correlation Coefficient | ||||||
|---|---|---|---|---|---|---|
| 1.000 | 0.162 | −0.136 | −0.181 | −0.617 | 0.158 | |
| 0.162 | 1.000 | −0.074 | −0.206 | −0.044 | −0.143 | |
| −0.136 | −0.074 | 1.000 | 0.341 | 0.064 | −0.082 | |
| −0.181 | −0.206 | 0.341 | 1.000 | −0.033 | 0.011 | |
| −0.617 | −0.044 | 0.064 | −0.033 | 1.000 | −0.153 | |
| 0.158 | −0.143 | −0.082 | 0.011 | −0.153 | 1.000 | |
| Significance | ||||||
| 0.141 | 0.184 | 0.115 | 0.000 a | 0.146 | ||
| 0.141 | 0.312 | 0.084 | 0.386 | 0.171 | ||
| 0.184 | 0.312 | 0.010 b | 0.337 | 0.293 | ||
| 0.115 | 0.084 | 0.010 b | 0.414 | 0.472 | ||
| 0.000 a | 0.386 | 0.337 | 0.414 | 0.154 | ||
| 0.146 | 0.171 | 0.293 | 0.472 | 0.154 |
| Principal Component | ||
|---|---|---|
| Z1 | 1.808 | 30.128 |
| Z2 | 1.362 | 52.826 |
| Z3 | 1.089 | 70.974 |
| Z4 | 0.761 | 83.662 |
| Z5 | 0.637 | 94.278 |
| Z6 | 0.343 | 100.000 |
| Index | Z1 | Z2 | Z3 | Z4 | Z5 | Z6 |
|---|---|---|---|---|---|---|
| E1* | 0.632 | 0.190 | −0.180 | 0.089 | 0.171 | 0.704 |
| E2* | 0.227 | −0.419 | −0.539 | −0.605 | −0.334 | −0.071 |
| E3* | −0.324 | 0.417 | −0.474 | −0.326 | 0.622 | −0.053 |
| E4* | −0.311 | 0.584 | −0.204 | 0.011 | −0.683 | 0.233 |
| E5* | −0.549 | −0.397 | 0.204 | −0.231 | 0.072 | 0.664 |
| E6* | 0.216 | 0.340 | 0.608 | −0.683 | −0.014 | −0.041 |
| Unit Section Number | Z1 | Z2 | Z3 | Z4 |
|---|---|---|---|---|
| 1 | −11.371 | 51.559 | −97.436 | −107.845 |
| 2 | −10.939 | 52.239 | −96.220 | −109.211 |
| 3 | 23.438 | 74.725 | −101.169 | −105.477 |
| 4 | 14.081 | 69.627 | −94.292 | −115.259 |
| 5 | 16.715 | 69.814 | −102.376 | −109.513 |
| 6 | 12.611 | 63.354 | −113.928 | −96.536 |
| 7 | 25.787 | 84.094 | −76.840 | −138.199 |
| 8 | 9.371 | 58.254 | −123.048 | −86.291 |
| 9 | 12.577 | 65.467 | −106.173 | −102.848 |
| 10 | 20.569 | 78.047 | −83.677 | −128.119 |
| 11 | 6.529 | 55.947 | −123.197 | −83.724 |
| 12 | 18.260 | 66.568 | −116.682 | −89.283 |
| 13 | 12.171 | 62.124 | −116.745 | −90.622 |
| 14 | 21.675 | 77.084 | −89.993 | −120.674 |
| 15 | 23.761 | 83.086 | −79.083 | −133.562 |
| 16 | 21.817 | 80.026 | −84.555 | −127.415 |
| 17 | 25.337 | 79.924 | −90.820 | −120.296 |
| 18 | 22.529 | 75.504 | −98.724 | −111.417 |
| 19 | 22.303 | 76.157 | −92.842 | −115.095 |
| 20 | 32.638 | 79.079 | −91.047 | −119.252 |
| 21 | 30.046 | 74.999 | −98.343 | −111.056 |
| 22 | 28.588 | 77.229 | −104.212 | −104.939 |
| 23 | 22.756 | 68.049 | −120.628 | −86.498 |
| 24 | 27.076 | 74.849 | −108.468 | −100.158 |
| 25 | 20.869 | 74.947 | −94.863 | −106.150 |
| 26 | 16.333 | 67.807 | −107.631 | −91.807 |
| 27 | 12.312 | 62.523 | −120.947 | −85.466 |
| 28 | 21.995 | 76.419 | −93.402 | −115.218 |
| 29 | 20.144 | 65.627 | −121.153 | −85.992 |
| 30 | 26.624 | 75.827 | −102.913 | −106.482 |
| 31 | 28.897 | 83.369 | −78.903 | −130.207 |
| 32 | 34.637 | 84.068 | −99.123 | −104.110 |
| 33 | 18.182 | 63.472 | −125.662 | −81.824 |
| 34 | 39.279 | 86.725 | −92.573 | −117.372 |
| 35 | 43.599 | 93.525 | −80.413 | −131.032 |
| 36 | 22.039 | 67.951 | −114.027 | −94.276 |
| 37 | 16.514 | 71.361 | −101.347 | −107.454 |
| 38 | 13.922 | 67.281 | −108.643 | −99.258 |
| 39 | 15.434 | 69.661 | −104.387 | −104.039 |
| 40 | 14.861 | 61.764 | −121.778 | −84.434 |
| 41 | 27.922 | 76.490 | −101.580 | −107.683 |
| 42 | 35.050 | 87.710 | −81.516 | −130.222 |
| 43 | 35.698 | 88.730 | −79.692 | −132.271 |
| 44 | 27.490 | 75.810 | −102.796 | −106.317 |
| 45 | 38.976 | 81.323 | −103.967 | −106.698 |
| 46 | 34.598 | 86.673 | −100.730 | −108.269 |
| Clustering Method | Category 1 | Category 2 | Category 3 | Category 4 | Category 5 | |
|---|---|---|---|---|---|---|
| Systematic clustering | X1 –X4 | 1–3 | 4–19, 22–24, 27–31, 33, 36–44, 46 | 20–21, 34–35, 45 | 25–26 | 32 |
| X1 –X6 | 1–2 | 3 | 4 | 5–19, 21–33, 35–46 | 20, 34 | |
| Z1 –Z4 | 1–2 | 3, 5–31, 33, 35–44 | 4 | 32, 45–46 | 34 | |
| Dynamic clustering | X1 –X4 | 1–3, 9–11, 13–16, 37–39 | 32, 46 | 4–8, 12, 17–19, 25–28, 31, 40 | 20–21, 34–35, 45 | 22, 24, 29–30, 33, 36, 41–44 |
| X1 –X6 | 6, 8, 11–13, 23, 26–27, 29, 33, 36, 40 | 1–2 | 3–5, 9, 18, 22, 24–25, 30, 37–39, 41, 44 | 7, 10, 15–16, 31, 35, 42–43 | 14, 17, 19–21, 28, 32, 34, 45–46 | |
| Z1 –Z4 | 14, 17, 19–21, 28, 32, 34, 45–46 | 1–2 | 7, 10, 15–16, 31, 35, 42–43 | 3–5, 9, 18, 22, 24–25, 30, 37–39, 41, 44 | 6, 8, 11–13, 23, 26–27, 29, 33, 36, 40 | |
| Ordered clustering | X1 –X4 | 1–33 | 34 | 35–38 | 39–45 | 46 |
| X1–X6 | 1–9 | 10–13 | 14–25 | 26–28 | 29–46 | |
| Z1 –Z4 | 1–12 | 13 | 14–25 | 26–44 | 45–46 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Zheng, J.; Yu, J.; Xiong, C.; Li, W.; Deng, J. Clustering of Asphalt Pavement Maintenance Sections Based on 3D Ground-Penetrating Radar and Principal Component Techniques. Buildings 2023, 13, 1752. https://doi.org/10.3390/buildings13071752
Liu H, Zheng J, Yu J, Xiong C, Li W, Deng J. Clustering of Asphalt Pavement Maintenance Sections Based on 3D Ground-Penetrating Radar and Principal Component Techniques. Buildings. 2023; 13(7):1752. https://doi.org/10.3390/buildings13071752
Chicago/Turabian StyleLiu, Huimin, Jianhao Zheng, Jiangmiao Yu, Chunlong Xiong, Weixiong Li, and Jie Deng. 2023. "Clustering of Asphalt Pavement Maintenance Sections Based on 3D Ground-Penetrating Radar and Principal Component Techniques" Buildings 13, no. 7: 1752. https://doi.org/10.3390/buildings13071752