
Dynamic Mechanical Strength Prediction of BFRC Based on Stacking Ensemble Learning and Genetic Algorithm Optimization

Abstract
:1. Introduction
2. Data Preprocessing
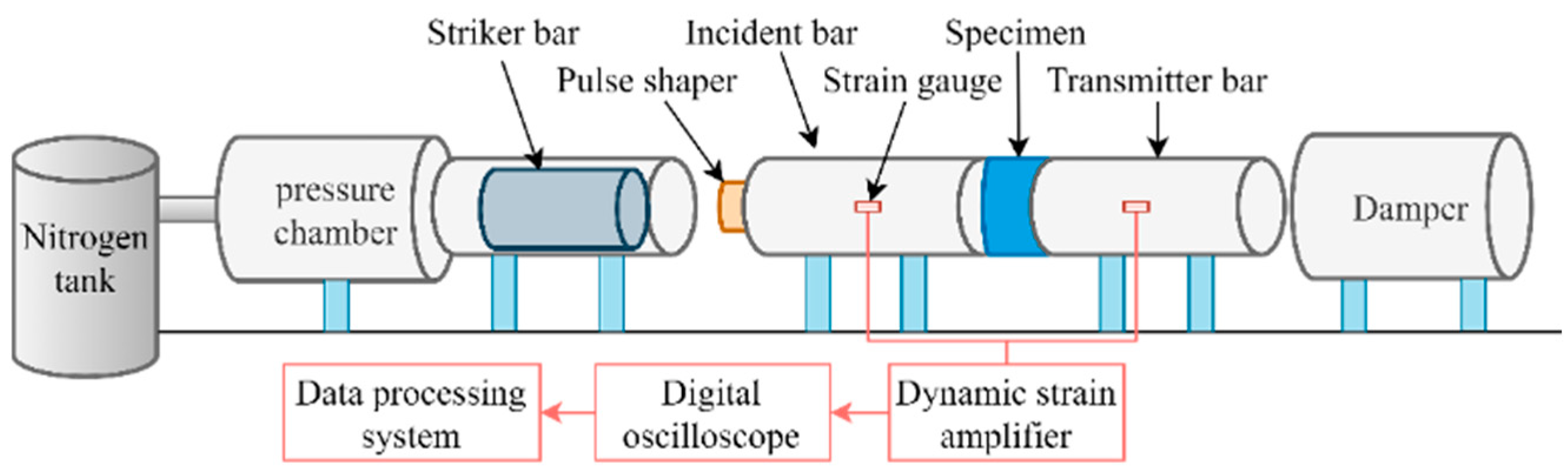
2.1. Experimental Dataset
2.2. Data Scaling and Splitting
3. Method
3.1. Overview of Stacking Ensemble Algorithm
3.2. Overview of Genetic Algorithm (GA)
3.3. Overview of Random Forest (RF)
3.4. Overview of Gradient Boosting (GB) and Extreme Gradient Boosting (XGBoost)
3.5. Overview of Support Vector Regression (SVR)
3.6. Model Development
3.7. Model Evaluation
4. Result and Discussion
4.1. Comparison of Different Ways of Parameters Optimization
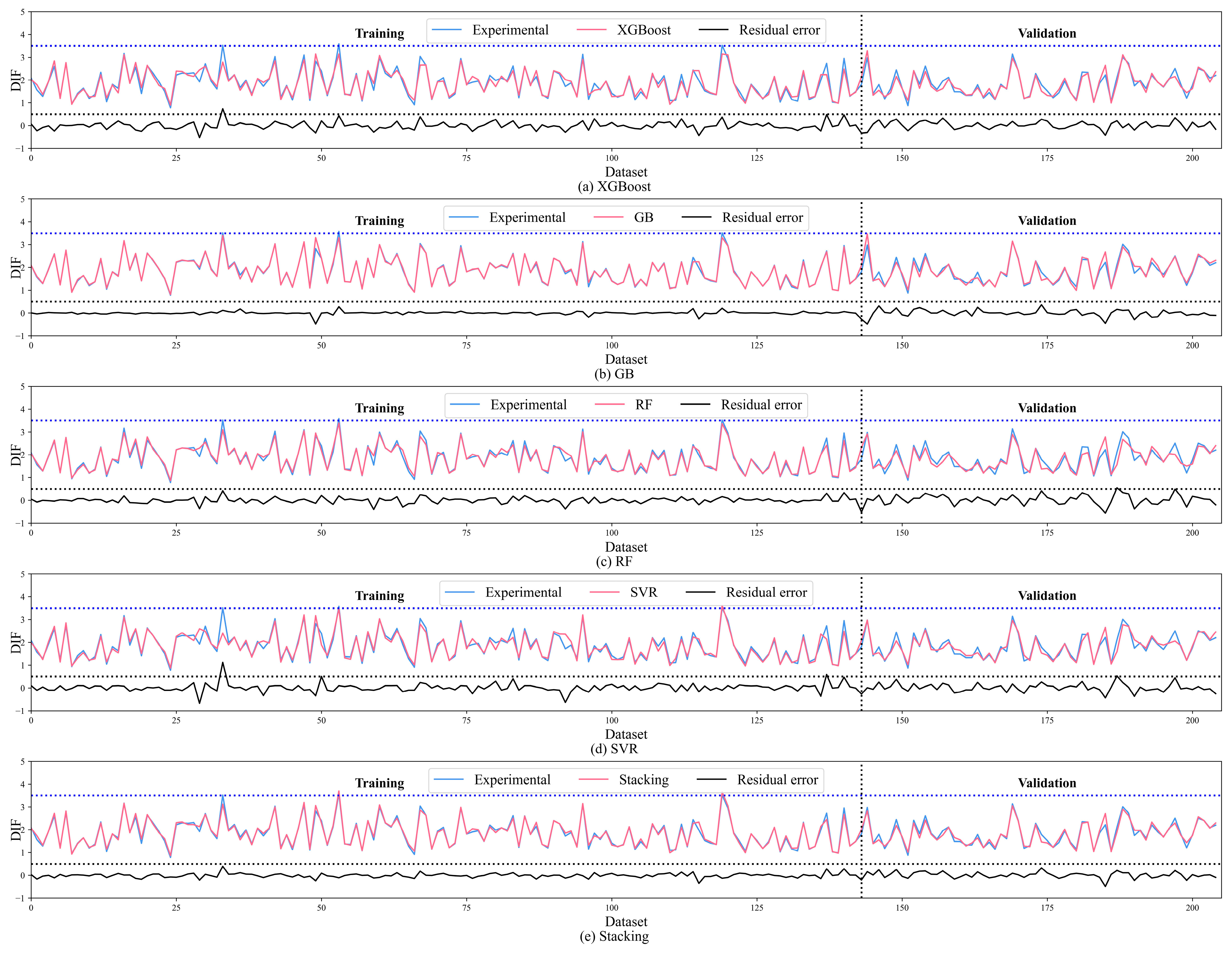
4.2. Comparison and Evaluation of Five Model
4.3. Sensitivity Analysis Using SHAP
5. Conclusions
- (1)
- In comparison to grid search, the performance of the model is improved when the parameters are optimized via GA. The performance of the algorithm can be improved by simultaneously optimizing more parameters with GA.
- (2)
- The stacking ensemble model presented in this research allows distinct prediction models to learn from one another by observing data space and structure from diverse angles. Predicted to experimental ratio also showed the stacking ensemble model’s advantage.
- (3)
- The SHAP analysis validated the developed stacking model and showed that the strain rate of the SHPB test was the most influential variable on the DIF values, followed by the specimen diameter and the compressive strength.
- (1)
- It guides the dynamic mechanical strength calculation of BFRC required for engineering.
- (2)
- It effectively reduces the difficulty of obtaining the dynamic mechanical strength of BFRC, reduces the workload of conducting experiments, and is more economical and environmentally friendly.
- (1)
- A dynamic mechanical property performance prediction dataset was developed based on the SHPB experiments.
- (2)
- A stacking ensemble model for predicting the DIF of BFRC was proposed based on the superposition algorithm; in this model, XGBoost, GB, and RF are used as basic models and SVR is used as a meta-learner.
- (3)
- We developed a GA for parameter optimization to determine the key parameters for the prediction model.
- (4)
- To evaluate the effectiveness of the proposed method, extensive numerical experiments were conducted on the collected data and results showing that the proposed method performs better than popular machine learning algorithms, including SVR, RF, GB, and XGBoost.
- (5)
- According to the SHAP and feature importance analyses, the strain rate of the SHPB test influenced the DIF most, followed by the specimen diameter and the compressive strength.
6. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, S.-H.; Liao, S.-J.; Zhong, G.-Q.; Guo, Y.-C.; Lin, J.-X.; Xie, Z.-H.; Song, Y. Dynamic properties of PVA short fiber reinforced low-calcium fly ash—Slag geopolymer under an SHPB impact load. J. Build. Eng. 2021, 44, 103220. [Google Scholar] [CrossRef]
- Li, L.; Wang, H.; Wu, J.; Du, X.; Zhang, X.; Yao, Y. Experimental and numerical investigation on impact dynamic performance of steel fiber reinforced concrete beams at elevated temperatures. J. Build. Eng. 2022, 47, 103841. [Google Scholar] [CrossRef]
- Sica, S.; Pagano, L.; Rotili, F. Rapid drawdown on earth dam stability after a strong earthquake. Comput. Geotech. 2019, 116, 103187. [Google Scholar] [CrossRef]
- Hao, Y.F.; Hao, H.; Jiang, G.P.; Zhou, Y. Experimental confirmation of some factors influencing dynamic concrete compressive strengths in high-speed impact tests. Cem. Concr. Res. 2013, 52, 63–70. [Google Scholar] [CrossRef]
- Zhang, X.; Elazim, A.A.; Ruiz, G.; Yu, R. Fracture behaviour of steel fibre-reinforced concrete at a wide range of loading rates. Int. J. Impact Eng. 2014, 71, 89–96. [Google Scholar] [CrossRef]
- Branston, J.; Das, S.; Kenno, S.Y.; Taylor, C. Mechanical behaviour of basalt fibre reinforced concrete. Constr. Build. Mater. 2016, 124, 878–886. [Google Scholar] [CrossRef]
- Jiang, C.; Fan, K.; Wu, F.; Chen, D. Experimental study on the mechanical properties and microstructure of chopped basalt fibre reinforced concrete. Mater. Des. 2014, 58, 187–193. [Google Scholar] [CrossRef]
- Sim, J.; Park, C.; Moon, D.Y. Characteristics of basalt fiber as a strengthening material for concrete structures. Compos. Part B Eng. 2005, 36, 504–512. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, C.; He, W.; Wang, D. Static and dynamic compressive properties of ultra-high performance concrete (UHPC) with hybrid steel fiber reinforcements. Cem. Concr. Compos. 2017, 79, 148–157. [Google Scholar] [CrossRef]
- Lai, J.; Sun, W. Dynamic behaviour and visco-elastic damage model of ultra-high performance cementitious composite. Cem. Concr. Res. 2009, 39, 1044–1051. [Google Scholar] [CrossRef]
- Mastali, M.; Dalvand, A.; Sattarifard, A. The impact resistance and mechanical properties of reinforced self-compacting concrete with recycled glass fibre reinforced polymers. J. Clean. Prod. 2016, 124, 312–324. [Google Scholar] [CrossRef]
- Xu, Z.; Hao, H.; Li, H. Experimental study of dynamic compressive properties of fibre reinforced concrete material with dif-ferent fibres. Mater. Des. 2012, 33, 42–55. [Google Scholar] [CrossRef]
- Yoo, D.-Y.; Banthia, N. Impact resistance of fiber-reinforced concrete—A review. Cem. Concr. Compos. 2019, 104, 103389. [Google Scholar] [CrossRef]
- Ghosh, S.; Dinda, S.; Das Chatterjee, N.; Dutta, S.; Bera, D. Spatial-explicit carbon emission-sequestration balance estimation and evaluation of emission susceptible zones in an Eastern Himalayan city using Pressure-Sensitivity-Resilience framework: An approach towards achieving low carbon cities. J. Clean. Prod. 2022, 336, 130417. [Google Scholar] [CrossRef]
- Li, H.; Lin, J.; Zhao, D.; Shi, G.; Wu, H.; Wei, T.; Li, D.; Zhang, J. A BFRC compressive strength prediction method via kernel extreme learning machine-genetic algorithm. Constr. Build. Mater. 2022, 344, 128076. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- DeRousseau, M.; Kasprzyk, J.; Srubar, W. Computational design optimization of concrete mixtures: A review. Cem. Concr. Res. 2018, 109, 42–53. [Google Scholar] [CrossRef]
- Li, H.; Lin, J.; Lei, X.; Wei, T. Compressive strength prediction of basalt fiber reinforced concrete via random forest algorithm. Mater. Today Commun. 2022, 30, 103117. [Google Scholar] [CrossRef]
- Mousavi, M.; Gandomi, A.H.; Holloway, D.; Berry, A.; Chen, F. Machine learning analysis of features extracted from time–frequency domain of ultrasonic testing results for wood material assessment. Constr. Build. Mater. 2022, 342, 127761. [Google Scholar] [CrossRef]
- Kahraman, E.; Ozdemir, A.C. The prediction of durability to freeze–thaw of limestone aggregates using machine-learning techniques. Constr. Build. Mater. 2022, 324, 126678. [Google Scholar] [CrossRef]
- Tran, V.Q. Machine learning approach for investigating chloride diffusion coefficient of concrete containing supplementary cementitious materials. Constr. Build. Mater. 2022, 328, 127103. [Google Scholar] [CrossRef]
- Shamsabadi, E.A.; Roshan, N.; Hadigheh, S.A.; Nehdi, M.L.; Khodabakhshian, A.; Ghalehnovi, M. Machine learning-based compressive strength modelling of concrete incorporating waste marble powder. Constr. Build. Mater. 2022, 324, 126592. [Google Scholar] [CrossRef]
- Kang, M.C.; Yoo, D.Y.; Gupta, R. Machine learning-based prediction for compressive and flexural strengths of steel fi-ber-reinforced concrete. Constr. Build. Mater. 2021, 266, 121117. [Google Scholar] [CrossRef]
- Altayeb, M.; Wang, X.; Musa, T.H. An ensemble method for predicting the mechanical properties of strain hardening ce-mentitious composites. Constr. Build. Mater. 2021, 286, 122807. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2021, 33, 4501–4532. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Mostafa, R.R.; Mohammed, A.; Sihag, P.; Qadir, A. Support vector regression (SVR) and grey wolf optimization (GWO) to predict the compressive strength of GGBFS-based geopolymer concrete. Neural Comput. Appl. 2022, 35, 2909–2926. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, L.; Zheng, K.; Bakura, T.J.; Jibrin, T.; Totakhil, P.G. Research on compressive impact dynamic behavior and constitutive model of polypropylene fiber reinforced concrete. Constr. Build. Mater. 2018, 187, 584–595. [Google Scholar] [CrossRef]
- Li, N.; Jin, Z.; Long, G.; Chen, L.; Fu, Q.; Yu, Y.; Zhang, X.; Xiong, C. Impact resistance of steel fiber-reinforced self-compacting concrete (SCC) at high strain rates. J. Build. Eng. 2021, 38, 102212. [Google Scholar] [CrossRef]
- Su, H.; Xu, J.; Ren, W. Mechanical properties of geopolymer concrete exposed to dynamic compression under elevated tem-peratures. Ceram. Int. 2016, 42, 3888–3898. [Google Scholar] [CrossRef]
- Shen, L.; Xu, J.; Li, W.; Fan, F.; Yang, J. Experimental investigation on the static and dynamic behaviour of Basalt fibres reinforced concrete. Concrete 2008, 4, 026. [Google Scholar]
- Zhang, H.; Wang, B.; Xie, A.; Qi, Y. Experimental study on dynamic mechanical properties and constitutive model of basalt fiber reinforced concrete. Constr. Build. Mater. 2017, 152, 154–167. [Google Scholar] [CrossRef]
- Pengfei, C. Research and Numerical Analysis on Impact Resistance of Basalt Fiber and Polypropylene Fiber Reinforced Concrete; Qingdao Technological University: Qingdao, China, 2021. [Google Scholar]
- Ganorkar, K.; Goel, M.D.; Chakraborty, T. Specimen Size Effect and Dynamic Increase Factor for Basalt Fiber–Reinforced Concrete Using Split Hopkinson Pressure Bar. J. Mater. Civ. Eng. 2021, 33, 04021364. [Google Scholar] [CrossRef]
- Xu, J.; Fan, F.; Bai, E.; Liu, J. Study on dynamic mechanical properties of basalt fibre reinforced concrete. Chin. J. Undergr. Space Eng. 2010, 6, 1665–1671. [Google Scholar]
- Xie, L.; Sun, X.; Yu, Z.; Guan, Z.; Long, A.; Lian, H.; Lian, Y. Experimental study and theoretical analysis on dynamic mechanical properties of basalt fiber reinforced concrete. J. Build. Eng. 2022, 62, 105334. [Google Scholar] [CrossRef]
- Oey, T.; Jones, S.; Bullard, J.W.; Sant, G. Machine learning can predict setting behavior and strength evolution of hydrating cement systems. J. Am. Ceram. Soc. 2019, 103, 480–490. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Jiang, Y.; Tong, G.; Yin, H.; Xiong, N. A Pedestrian Detection Method Based on Genetic Algorithm for Optimize XGBoost Training Parameters. IEEE Access 2019, 7, 118310–118321. [Google Scholar] [CrossRef]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. Open Access J. 2014, 2, 602–609. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Hastie, T.; Friedman, J.H.; Tibshirani, R. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 1, Issue 3; pp. 267–268. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, J.; Gu, Y.; Huang, Y.; Sun, Y.; Ma, G. Prediction of permeability and unconfined compressive strength of pervious concrete using evolved support vector regression. Constr. Build. Mater. 2019, 207, 440–449. [Google Scholar] [CrossRef]
- Duan, J.; Asteris, P.G.; Nguyen, H.; Bui, X.-N.; Moayedi, H. A novel artificial intelligence technique to predict compressive strength of recycled aggregate concrete using ICA-XGBoost model. Eng. Comput. 2021, 37, 3329–3346. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Yuvaraj, P.; Murthy, A.R.; Iyer, N.R.; Sekar, S.; Samui, P. Support vector regression based models to predict fracture characteristics of high strength and ultra high strength concrete beams. Eng. Fract. Mech. 2013, 98, 29–43. [Google Scholar] [CrossRef]
- DeRousseau, M.; Laftchiev, E.; Kasprzyk, J.R.; Rajagopalan, B.; Srubar, W.V., III. A comparison of machine learning methods for predicting the compressive strength of field-placed concrete. Constr. Build. Mater. 2019, 228, 116661. [Google Scholar] [CrossRef]
- Cameron, A.C.; Windmeijer, F.A.G. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econ. 1997, 77, 329–342. [Google Scholar] [CrossRef]
- Feng, D.-C.; Wang, W.-J.; Mangalathu, S.; Taciroglu, E. Interpretable XGBoost-SHAP Machine-Learning Model for Shear Strength Prediction of Squat RC Walls. J. Struct. Eng. 2021, 147, 04021173. [Google Scholar] [CrossRef]
- Amin, M.N.; Iqbal, M.; Jamal, A.; Ullah, S.; Khan, K.; Abu-Arab, A.M.; Al-Ahmad, Q.M.S.; Khan, S. GEP Tree-Based Prediction Model for Interfacial Bond Strength of Externally Bonded FRP Laminates on Grooves with Concrete Prism. Polymers 2022, 14, 2016. [Google Scholar] [CrossRef]
- Alabdullah, A.A.; Iqbal, M.; Zahid, M.; Khan, K.; Amin, M.N.; Jalal, F.E. Prediction of rapid chloride penetration resistance of metakaolin based high strength concrete using light GBM and XGBoost models by incorporating SHAP analysis. Constr. Build. Mater. 2022, 345, 128296. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| W/C | F/C | CA | FA | S/C | FL/FD | FC | CS | SR | SD | DIF | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| unit | - | - | kg/m3 | kg/m3 | % | 103 | % | MPa | /s | mm | - |
| mean | 0.438 | 0.107 | 1126 | 681.8 | 0.725 | 0.699 | 0.416 | 42.63 | 183.1 | 78.33 | 1.854 |
| std | 0.0563 | 0.106 | 107 | 101.3 | 0.371 | 0.314 | 0.608 | 12.93 | 164.8 | 13.95 | 0.594 |
| min | 0.302 | 0 | 891 | 518.3 | 0 | 0.2 | 0 | 22.29 | 21 | 54 | 0.78 |
| max | 0.485 | 0.25 | 1368 | 800 | 1.301 | 1.2 | 2 | 73.6 | 796 | 96 | 3.582 |
| count | 205 | 205 | 205 | 205 | 205 | 205 | 205 | 205 | 205 | 205 | 205 |
| ML Models | Parameters | Grid Search | GA |
|---|---|---|---|
| XGBoost | N-estimators | 100 | 223 |
| Learning-rate | 0.1 | 0.41 | |
| Max-depth | 3 | 2 | |
| Min-child-weight | 1 | 10 | |
| Gamma | 1 | 0.07 | |
| Subsample | 1 | 0.95 | |
| Colsample-bytree | 1 | 0.98 | |
| GB | N-estimators | 100 | 230 |
| Learning-rate | 0.15 | 0.53 | |
| Max-depth | 2 | 9 | |
| Min-samples-leaf | 0 | 10 | |
| Alpha | 0.9 | 0.79 | |
| Subsample | 1 | 0.71 | |
| RF | N-estimators | 100 | 103 |
| Max-depth | 6 | 8 | |
| SVR | C | 10 | 178.73 |
| Gamma | 0.1 | 0.1 |
| ML Models | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | MAE | MSE | RMSE | R2 | MAE | MSE | RMSE | |
| XGBoost | 0.9261 | 0.1203 | 0.0286 | 0.1692 | 0.9035 | 0.1263 | 0.0258 | 0.1608 |
| GB | 0.9877 | 0.0349 | 0.0048 | 0.0691 | 0.9143 | 0.106 | 0.023 | 0.1515 |
| RF | 0.963 | 0.0848 | 0.0143 | 0.1198 | 0.8189 | 0.1708 | 0.0485 | 0.2203 |
| SVM | 0.9111 | 0.1219 | 0.0345 | 0.1857 | 0.8825 | 0.1329 | 0.0315 | 0.1774 |
| Stacking | 0.9769 | 0.0669 | 0.0089 | 0.0946 | 0.9326 | 0.1007 | 0.0181 | 0.1344 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Wang, M.; Yao, T.; Tang, Y.; Liu, H. Dynamic Mechanical Strength Prediction of BFRC Based on Stacking Ensemble Learning and Genetic Algorithm Optimization. Buildings 2023, 13, 1155. https://doi.org/10.3390/buildings13051155
Zheng J, Wang M, Yao T, Tang Y, Liu H. Dynamic Mechanical Strength Prediction of BFRC Based on Stacking Ensemble Learning and Genetic Algorithm Optimization. Buildings. 2023; 13(5):1155. https://doi.org/10.3390/buildings13051155
Chicago/Turabian StyleZheng, Jiayan, Minghui Wang, Tianchen Yao, Yichen Tang, and Haijing Liu. 2023. "Dynamic Mechanical Strength Prediction of BFRC Based on Stacking Ensemble Learning and Genetic Algorithm Optimization" Buildings 13, no. 5: 1155. https://doi.org/10.3390/buildings13051155