

Predicting the Geopolymerization Process of Fly-Ash-Based Geopolymer Using Machine Learning
Abstract
:1. Introduction
2. Methodology
2.1. Dataset
2.2. Machine Learning Approaches
2.2.1. Backpropagation Neural Networks (BPNN)
2.2.2. Support Vector Regression (SVR)
2.2.3. Random Forest (RF)
2.2.4. The k-Nearest Neighbor
2.2.5. Logistic Regression
2.2.6. Multiple Linear Regression
2.3. Optimization Algorithm
2.4. K-Fold Cross Validation
2.5. Evaluation of the Predicted Results
3. Results and Discussion
3.1. Evaluation of the Hyperparameter Tuning
3.2. Prediction Performance of ML Models
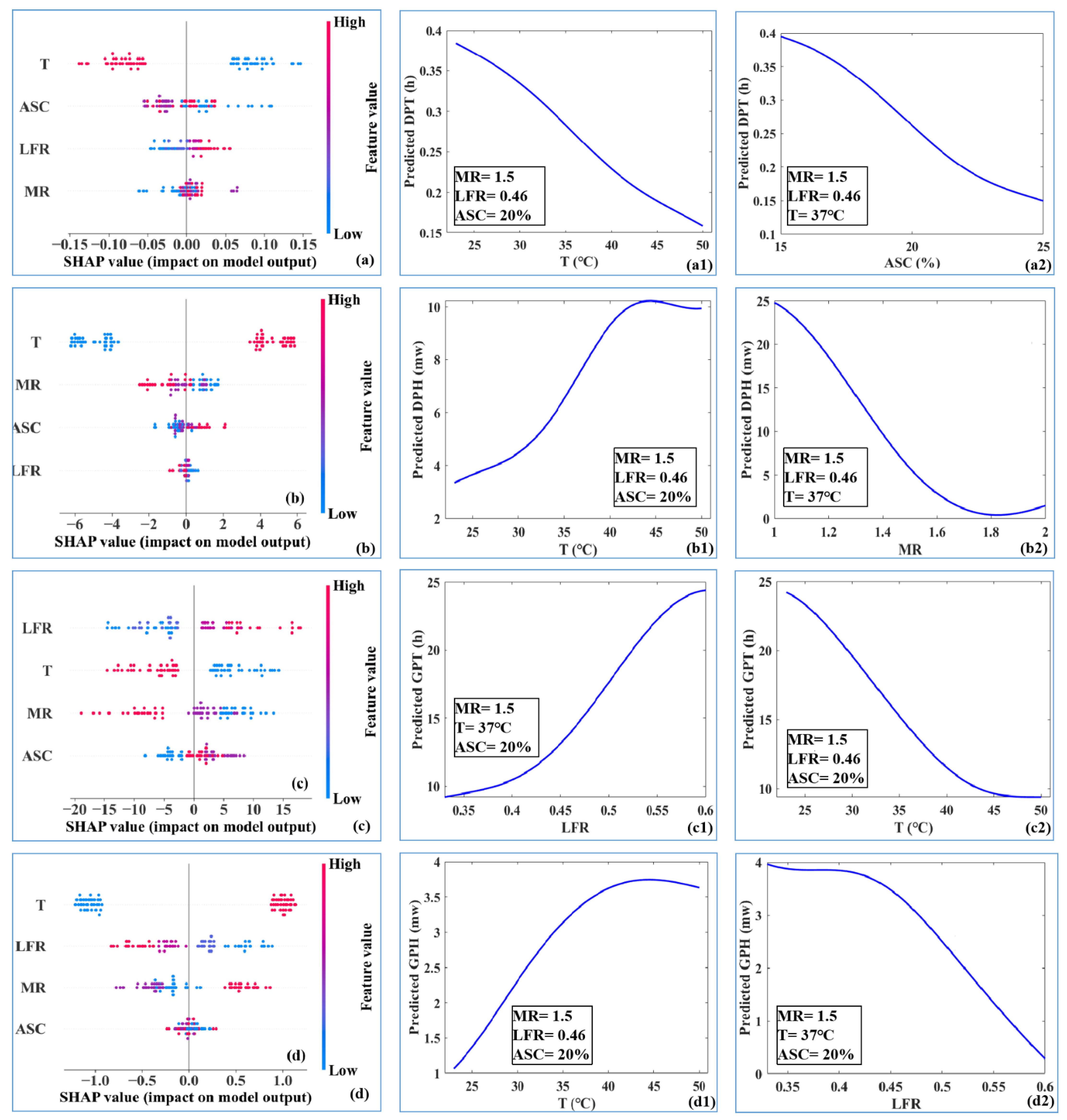
3.3. Importance of the Input Variables
3.4. Sensitivity Analysis
3.5. Implications for Research
4. Conclusions
- The RF model had the best performance for the prediction of GPT, GPH, DPT, and DPH, compared with other ML models due to its use of bagging and feature randomness. Therefore, ensemble learning models are recommended to predict geopolymerization parameters of FA-based geopolymer;
- SHAP analysis shows that temperature had the greatest influence on the geopolymerization of FA-based geopolymer. Control of temperature may not only significantly affect the geopolymerization process but might affect the hardened characterizations of FA-based geopolymer; and
- The elevation of temperature accelerated the geopolymerization rates and promoted the geopolymerization extent. ASC and MR were also important and negatively contributed to DPT and DPH, respectively. LFR was important to both GPT and GPH. Lower LFR can promote the geopolymerization extent and shorten the geopolymerization time.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, C.; Nerella, V.N.; Krishna, A.; Wang, S.; Zhang, Y.; Mechtcherine, V.; Banthia, N. Mix design concepts for 3d printable concrete: A review. Cem. Concr. Compos. 2021, 122, 104155. [Google Scholar] [CrossRef]
- Li, C.; Gong, X.; Cui, S.; Wang, Z.; Zheng, Y.; Chi, B. CO2 emissions due to cement manufacture. In Proceedings of the 11th IUMRS International Conference in Asia (IUMRS-ICA 2010), Qingdao, China, 25–28 September 2010; pp. 181–187. [Google Scholar]
- Ali, M.B.; Saidur, R.; Hossain, M.S. A review on emission analysis in cement industries. Renew. Sustain. Energy Rev. 2011, 15, 2252–2261. [Google Scholar] [CrossRef]
- Zhuang, X.Y.; Chen, L.; Komarneni, S.; Zhou, C.H.; Tong, D.S.; Yang, H.M.; Yu, W.H.; Wang, H. Fly ash-based geopolymer: Clean production, properties and applications. J. Clean. Prod. 2016, 125, 253–267. [Google Scholar] [CrossRef]
- McLellan, B.C.; Williams, R.P.; Lay, J.; van Riessen, A.; Corder, G.D. Costs and carbon emissions for geopolymer pastes in comparison to ordinary portland cement. J. Clean. Prod. 2011, 19, 1080–1090. [Google Scholar] [CrossRef] [Green Version]
- Duxson, P.; Provis, J.L.; Lukey, G.C.; Van Deventer, J.S.J. The role of inorganic polymer technology in the development of ‘green concrete’. Cem. Concr. Res. 2007, 37, 1590–1597. [Google Scholar] [CrossRef]
- Marvila, M.T.; Azevedo, A.R.G.; Delaqua, G.C.G.; Mendes, B.C.; Pedroti, L.G.; Vieira, C.M.F. Performance of geopolymer tiles in high temperature and saturation conditions. Constr. Build. Mater. 2021, 286, 122994. [Google Scholar] [CrossRef]
- Xu, H.; Van Deventer, J.S.J. The geopolymerisation of alumino-silicate minerals. Int. J. Miner. Process. 2000, 59, 247–266. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Yuan, Y.; Cheng, Z.; Wen, T.; Li, J.; Li, F.; Ma, Z.J. Freeze-thaw resistance of class f fly ash-based geopolymer concrete. Constr. Build. Mater. 2019, 222, 474–483. [Google Scholar] [CrossRef]
- Amran, M.; Debbarma, S.; Ozbakkaloglu, T. Fly ash-based eco-friendly geopolymer concrete: A critical review of the long-term durability properties. Constr. Build. Mater. 2021, 270, 121857. [Google Scholar] [CrossRef]
- Nuaklong, P.; Jongvivatsakul, P.; Pothisiri, T.; Sata, V.; Chindaprasirt, P. Influence of rice husk ash on mechanical properties and fire resistance of recycled aggregate high-calcium fly ash geopolymer concrete. J. Clean. Prod. 2020, 252, 119797. [Google Scholar] [CrossRef]
- Hadi, M.N.; Zhang, H.; Parkinson, S. Optimum mix design of geopolymer pastes and concretes cured in ambient condition based on compressive strength, setting time and workability. J. Build. Eng. 2019, 23, 301–313. [Google Scholar] [CrossRef]
- Nath, S.K.; Mukherjee, S.; Maitra, S.; Kumar, S. Kinetics study of geopolymerization of fly ash using isothermal conduction calorimetry. J. Therm. Anal. Calorim. 2017, 127, 1953–1961. [Google Scholar] [CrossRef]
- Udawattha, C.D.; Lakmini, A.V.R.D.; Halwatura, R.U. Fly ash-based geopolymer mud concrete block. In Proceedings of the Moratuwa Engineering Research Conference (MERCon)/4th International Multidisciplinary Engineering Research Conference, Katubedda, Sri Lanka, 30 May–1 June 2018; pp. 583–588. [Google Scholar]
- Ling, Y.; Wang, K.; Wang, X.; Hua, S. Effects of mix design parameters on heat of geopolymerization, set time, and compressive strength of high calcium fly ash geopolymer. Constr. Build. Mater. 2019, 228, 116763. [Google Scholar] [CrossRef]
- Yao, X.; Zhang, Z.; Zhu, H.; Chen, Y. Geopolymerization process of alkali-metakaolinite characterized by isothermal calorimetry. Thermochim. Acta 2009, 493, 49–54. [Google Scholar] [CrossRef]
- Provis, J.L.; van Deventer, J.S.J. Geopolymerisation kinetics. 1. In situ energy-dispersive x-ray diffractometry. Chem. Eng. Sci. 2007, 62, 2309–2317. [Google Scholar] [CrossRef]
- Zhang, Y.S.; Sun, W.; Li, Z.J. Hydration process of potassium polysialate (k-psds) geopolymer cement. Adv. Cem. Res. 2005, 17, 23–28. [Google Scholar] [CrossRef]
- Provis, J.L.; Duxson, P.; van Deventer, J.S.J.; Lukey, G.C. The role of mathematical modelling and gel chemistry in advancing geopolymer technology. Chem. Eng. Res. Des. 2005, 83, 853–860. [Google Scholar] [CrossRef]
- Ben Chaabene, W.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, Y.; Wang, Y.; Ma, G. Multi-objective optimization of concrete mixture proportions using machine learning and metaheuristic algorithms. Constr. Build. Mater. 2020, 253, 119208. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, Y.; Ma, G.; Nener, B. Mixture optimization for environmental, economical and mechanical objectives in silica fume concrete: A novel frame-work based on machine learning and a new meta-heuristic algorithm. Resour. Conserv. Recycl. 2021, 167, 105395. [Google Scholar] [CrossRef]
- Qian, J.; Wang, P.; Pu, C.; Peng, X.; Chen, G. Application of modified beetle antennae search algorithm and bp power flow prediction model on multi-objective optimal active power dispatch. Appl. Soft Comput. 2021, 113, 108027. [Google Scholar] [CrossRef]
- Shao, X.; Fan, Y. An improved beetle antennae search algorithm based on the elite selection mechanism and the neighbor mobility strategy for global optimization problems. IEEE Access 2021, 9, 137524–137542. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhang, Z.; Man, W.; Tong, X.; Qiu, J.; Li, F. A new beetle antennae search algorithm for multi-objective energy management in microgrid. In Proceedings of the 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; IEEE: New York, NY, USA; pp. 1599–1603. [Google Scholar]
- Nguyen, T.; Nguyen, D.; Le, A.; Shin, J.; Lee, K. Analyzing the compressive strength of green fly ash based geopolymer concrete using experiment and machine learning approaches. Constr. Build Mater. 2020, 247, 118581. [Google Scholar] [CrossRef]
- Tanyildizi, H. Predicting the geopolymerization process of fly ash-based geopolymer using deep long short-term memory and machine learning. Cem. Concr. Comp. 2021, 123, 104177. [Google Scholar] [CrossRef]
- Mu, S.; Liu, J.; Liu, J.; Wang, Y.; Shi, L.; Jiang, Q. Property and microstructure of waterborne self-setting geopolymer coating: Optimization effect of sio2/na2o molar ratio. Minerals 2018, 8, 162. [Google Scholar] [CrossRef] [Green Version]
- Chindaprasirt, P.; Chareerat, T.; Sirivivatnanon, V. Workability and strength of coarse high calcium fly ash geopolymer. Cem. Concr. Comp. 2007, 29, 224–229. [Google Scholar] [CrossRef]
- Vatcheva, K.P.; Lee, M.; McCormick, J.B.; Rahbar, M.H. Multicollinearity in regression analyses conducted in epidemiologic studies. Epidemiology 2016, 6, 227. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.-Y.; Lee, Y.-C.; Yen, T.-M.; Tsai, C.-H. Using bpnn and dematel to modify importance-performance analysis model-a study of the computer industry. Expert Syst. Appl. 2009, 36, 9969–9979. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, J.; Gu, Y.; Huang, Y.; Sun, Y.; Ma, G. Prediction of permeability and unconfined compressive strength of pervious concrete using evolved support vector regression. Constr. Build. Mater. 2019, 207, 440–449. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. Isprs J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mahapatra, R.P.; Chakraborty, P.S. Comparative analysis of nearest neighbor query processing techniques. In Proceedings of the 3rd International Conference on Recent Trends in Computing (ICRTC), Delhi, India, 12–13 March 2015; pp. 1289–1298. [Google Scholar]
- Cawley, G.C.; Talbot, N.L.C. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Ling, Y.; Wang, K.; Wang, X.; Li, W. Prediction of engineering properties of fly ash-based geopolymer using artificial neural networks. Neural Comput. Appl. 2021, 33, 85–105. [Google Scholar] [CrossRef]
- Qi, C.; Wu, M.; Zheng, J.; Chen, Q.; Chai, L. Rapid identification of reactivity for the efficient recycling of coal fly ash: Hybrid machine learning modeling and interpretation. J. Clean. Prod. 2022, 343, 130958. [Google Scholar] [CrossRef]
- Kuenzel, C.; Ranjbar, N. Dissolution mechanism of fly ash to quantify the reactive aluminosilicates in geopolymerisation. Resour. Conserv. Recycl. 2019, 150, 104421. [Google Scholar] [CrossRef]
- El-Sappagh, S.; Alonso, J.M.; Islam, S.M.R.; Sultan, A.M.; Kwak, K.S. A multilayer multimodal detection and prediction model based on explainable artificial intelligence for Alzheimer’s disease. Sci. Rep. 2021, 11, 1–26. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LOI | K2O | Na2O | MgO | CaO | SO3 | Fe2O3 | Al2O3 | SiO2 | Others |
|---|---|---|---|---|---|---|---|---|---|
| 0.49 | 0.27 | 2.97 | 6.74 | 28.8 | 3.47 | 6.8 | 16 | 30.7 | 3.28 |
| Mole Ratio | Alkaline Solution Concentration (%) | L/F |
|---|---|---|
| 2.0 | 25 | 0.6, 0.5, 0.4, 0.33 |
| 2.0 | 20 | 0.6, 0.5, 0.4, 0.33 |
| 2.0 | 15 | 0.6, 0.5, 0.4, 0.33 |
| 1.5 | 25 | 0.6, 0.5, 0.4, 0.33 |
| 1.5 | 20 | 0.6, 0.5, 0.4, 0.33 |
| 1.5 | 15 | 0.6, 0.5, 0.4, 0.33 |
| 1.0 | 25 | 0.6, 0.5, 0.4, 0.33 |
| 1.0 | 20 | 0.6, 0.5, 0.4, 0.33 |
| 1.0 | 15 | 0.6, 0.5, 0.4, 0.33 |
| Variable | Unit | Mean | STD | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| MR | - | 1.50 | 0.41 | 1.00 | 1.00 | 1.50 | 2.00 | 2.00 |
| ASC | % | 20.00 | 4.11 | 15.00 | 15.00 | 20.00 | 25.00 | 25.00 |
| LFR | - | 0.46 | 0.10 | 0.33 | 0.38 | 0.45 | 0.53 | 0.60 |
| T | °C | 36.88 | 13.59 | 23.00 | 23.00 | 50.00 | 50.00 | 50.00 |
| DPT | h | 0.29 | 0.13 | 0.13 | 0.20 | 0.28 | 0.35 | 0.73 |
| DPH | mw | 8.64 | 5.54 | 0.81 | 3.68 | 8.44 | 14.10 | 17.30 |
| GPT | h | 15.03 | 22.37 | 1.05 | 2.84 | 6.76 | 14.79 | 116.15 |
| GPH | mw | 2.23 | 1.43 | 0.28 | 0.98 | 1.81 | 3.31 | 5.43 |
| Data Set | Model | Hyperparameter |
|---|---|---|
| DPT | BPNN | layer_num = 3; neuron_num = [20 8 1] |
| SVR | C = 1.26; γ = 0.8 | |
| RF | min_samples_leaf = 2; tree_num = 57 | |
| KNN | neighbor_num = 1 | |
| RF | min_samples_leaf = 1; tree_num = 6 | |
| MLR | - | |
| DPH | BPNN | layer_num = 3; neuron_num = [7 5 10] |
| SVR | C = 6.54; γ = 20.4 | |
| KNN | neighbor_num = 1 | |
| LR | - | |
| RF | min_samples_leaf = 1; tree_num = 27 | |
| GPT | BPNN | layer_num = 2; neuron_num = [20 3] |
| SVR | C = 12.1; γ = 7.9 | |
| KNN | neighbor_num = 13 | |
| LR | - | |
| MLR | - | |
| GPH | RF | min_samples_leaf = 1; tree_num = 27 |
| SVR | C = 24.1; γ = 6.4 | |
| KNN | neighbor_num = 1 | |
| LR | - | |
| MLR | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.; Cheng, Y.; Yu, M.; Liu, L.; Wang, Y.; Zhang, J. Predicting the Geopolymerization Process of Fly-Ash-Based Geopolymer Using Machine Learning. Buildings 2022, 12, 1792. https://doi.org/10.3390/buildings12111792
Chen K, Cheng Y, Yu M, Liu L, Wang Y, Zhang J. Predicting the Geopolymerization Process of Fly-Ash-Based Geopolymer Using Machine Learning. Buildings. 2022; 12(11):1792. https://doi.org/10.3390/buildings12111792
Chicago/Turabian StyleChen, Kai, Yunhai Cheng, Mingsheng Yu, Long Liu, Yonggang Wang, and Junfei Zhang. 2022. "Predicting the Geopolymerization Process of Fly-Ash-Based Geopolymer Using Machine Learning" Buildings 12, no. 11: 1792. https://doi.org/10.3390/buildings12111792