3.1. Network Architecture
In this paper, the residual neural network ResNet [
9] was selected as the backbone network for feature extraction, and DeepLabv3+ [
10] and U-Net ++[
11] were used as semantic segmentation models for the segmentation and statistics of sorbite content.
The network structure of ResNet is based on VGG-19, which is improved, and residual elements are added by a short circuit mechanism. In ResNet-34, it adopts 3 × 3 filters, and its design principle is that: first, in the same output feature map, the number of filters in each layer is the same; second, when the size of the feature map is reduced by half, the number of filters will double to ensure the time complexity of each layer. The network ends with a global average pooling layer and a 1000-dimensional fully connected layer with softmax. The rest of the residual neural network structure is deformed on this basis.
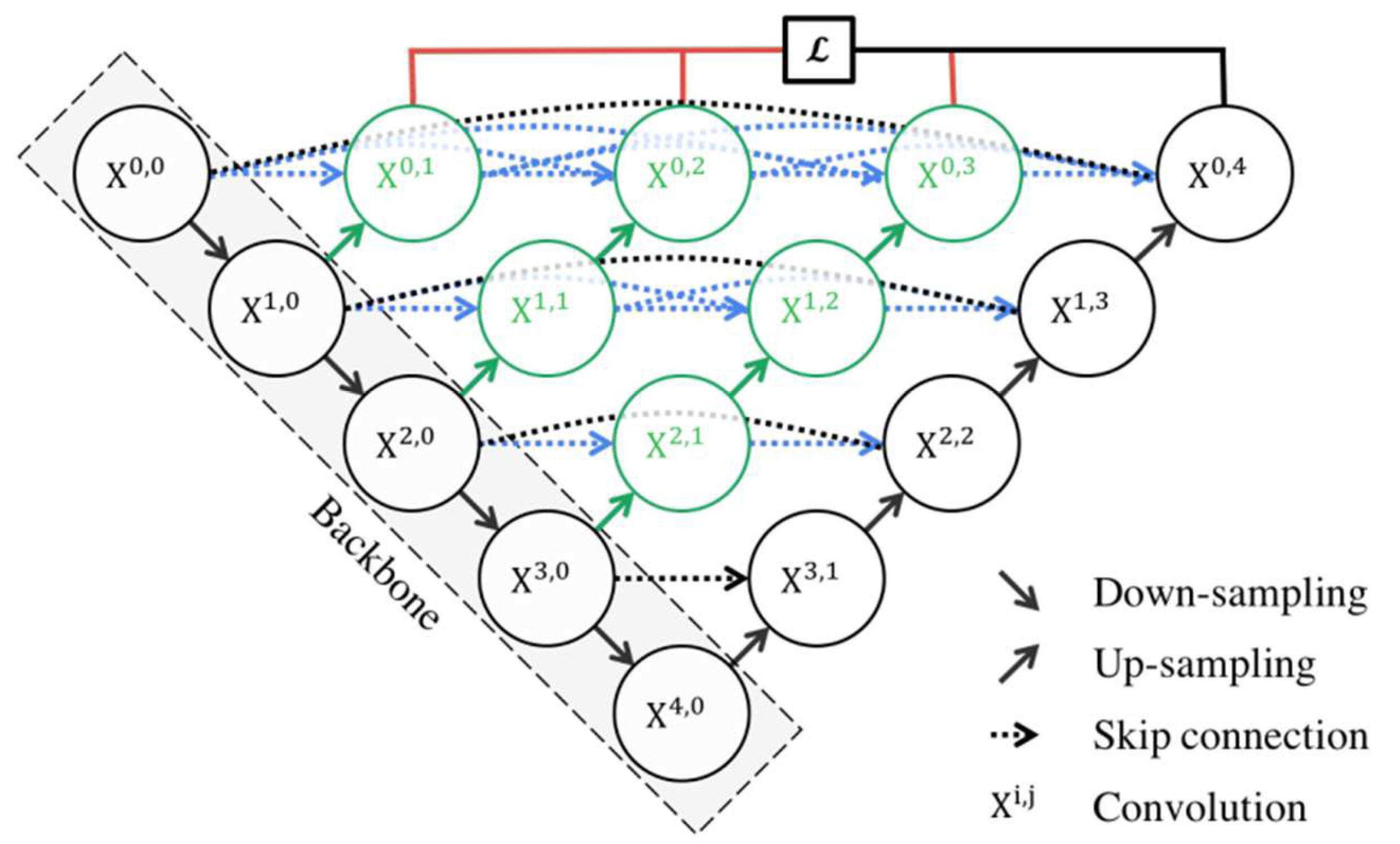
The U-Net++ network structure is shown in
Figure 2, which consists of several parts: the convolution unit, down-sampling and up-sampling modules, and skip connection between convolution units. In the U-Net model structure, nodes X0.4 only form a skip connection with nodes X0.0, while in the U-Net++ model structure, nodes X0.4 connect the outputs of four convolution units X0.0, X0.1, X0.2, and X0.3 at the same layer, where each node Xi.j represents one convolution down-sampling or deconvolution up-sampling. The U-Net++ network has a nested structure and dense skip paths, which is conducive to aggregating features with different semantic scales on the decoder subnetwork and has achieved excellent performance levels in other fields [
12,
13]. In this paper, after grayscale processing, the sorbite was quite different from other tissues, which was intuitively applicable to this problem.
Enter X0.0 from X0.0 on the first layer of the model, and calculate according to the following formula in turn:
where
denotes the convolution,
[] denotes the feature cascade,
denotes the deconvolution up-sampling, and
denotes the output of the node
, where
denotes the down-sampling layer along the encoder index and
denotes the convolution layer along the skip index dense block.
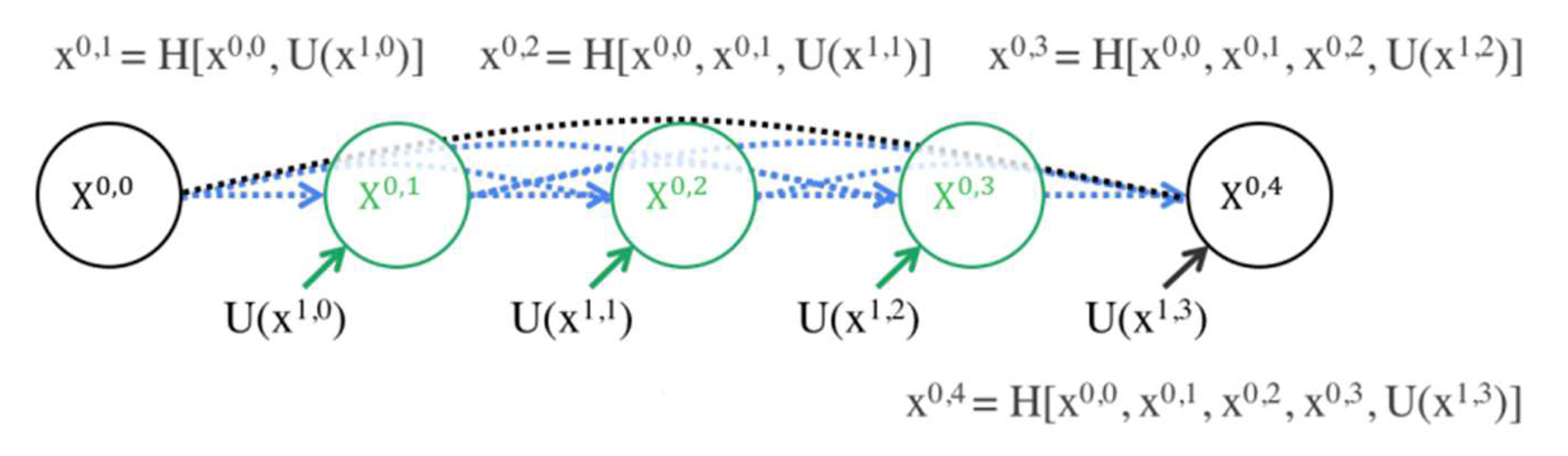
The skip connection can introduce high-resolution information in the image into the result of the up-sampling, thereby ensuring high segmentation accuracy. Taking the first layer of the model as an example, the skip connection results are shown in
Figure 3.
The deep supervision process was introduced into the U-Net++ network model. The shallow feature perception of the image can be increased by deconvolutional up-sampling of the results
obtained by down-sampling at each level, and then adding the final up-sampling segmentation results
corresponding to each level of the training loss calculation process [
14]. The split loss function designed accordingly is shown in the following formula:
where
is the total segmentation loss,
is the loss function used to calculate the segmentation loss of
, and
is the number of all nodes except the down-sampling nodes in the first layer of the model.
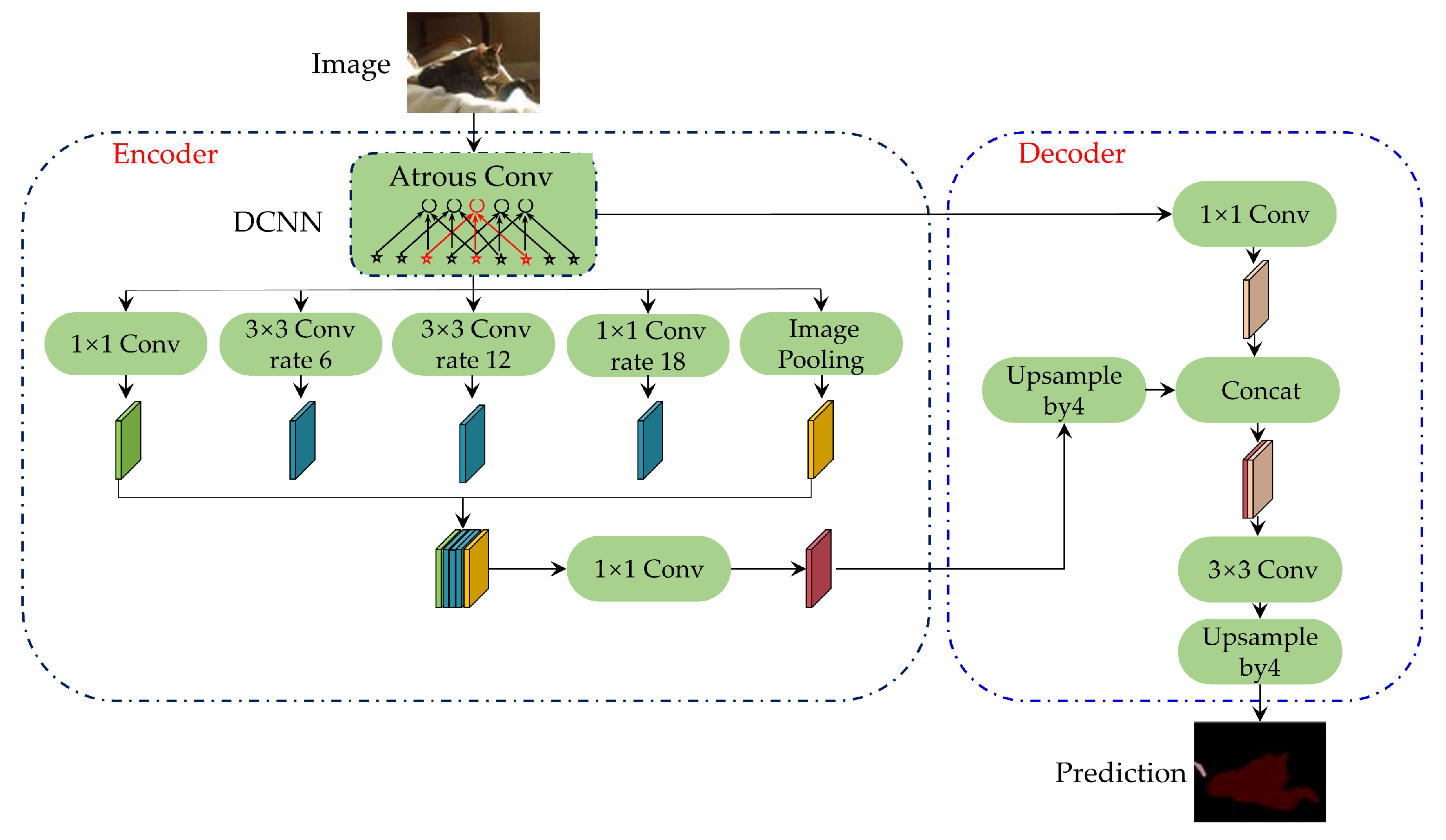
Compared with the U-Net++ network, the DeepLabv3+ network greatly reduces the actual running graphic memory occupancy under the same setting and slightly improves the performance, which is also suitable for this problem. The structure of the DeepLabv3+ network is shown in
Figure 4. The network with a codec structure was generated based on the DeepLabv3 network structure, in which DeepLabv3 was used as the encoder part to extract and fuse multi-scale features. A simple structure was added as the decoder to further merge the underlying features with the higher-layer features, improve the accuracy of the segmentation boundary, and obtain more details, forming a new network that merges atrous spatial pyramid pooling (ASPP) [
15] and codec structures.
Atrous convolution is the core of the DeepLab series model [
10,
16,
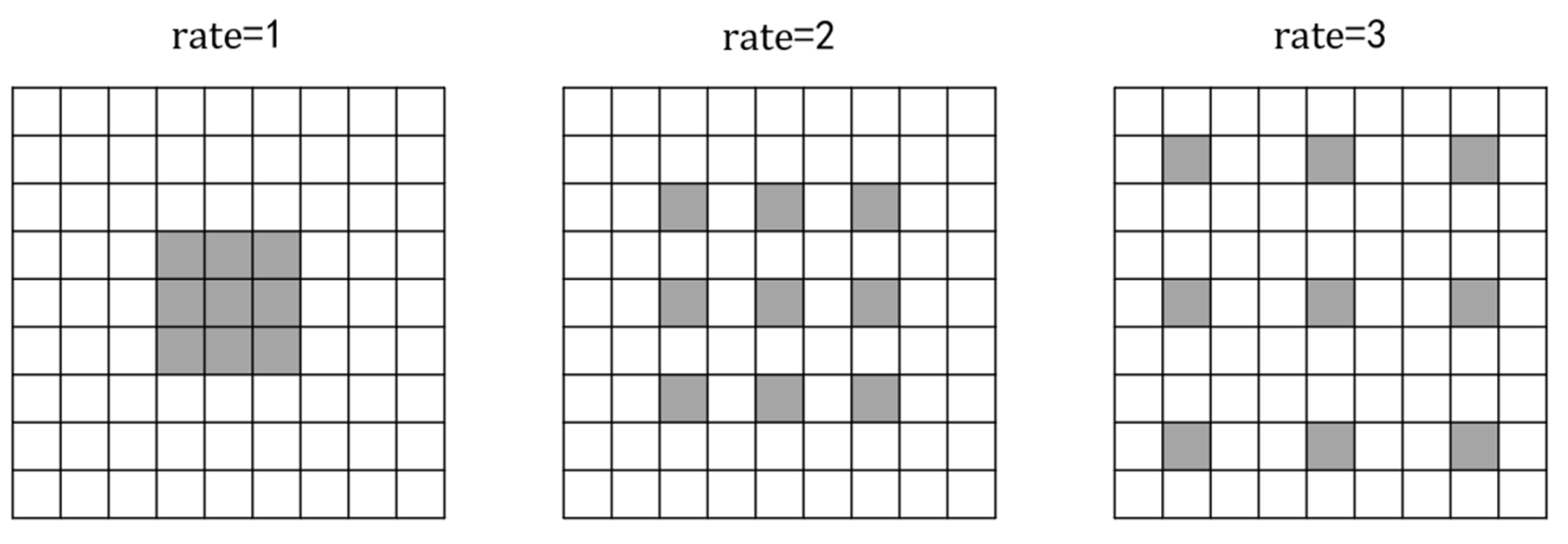
17], which is a convolution method to increase the receptive field and is conducive to extracting multi-scale information. Atrous convolution adds voids based on ordinary convolution, in which a parameter dilation rate is added to control the size of the receptive field. As shown in the
Figure 5, taking
3 × 3 convolution as an example, the grey lattice represents the
3 × 3 convolution kernel, and the receptive field after ordinary convolution is 3. When
, the receptive field after convolution by the atrous convolution module is 5, which is increased by 2 compared with the ordinary convolution receptive field. When
, the receptive field after convolution by the atrous convolution module is 7, which is increased by 4 compared with the ordinary convolution receptive field. Due to the mesh effect of atrous convolution, some information will be lost in the image after the atrous convolution operation.
For two-dimensional signals, in particular, for each position
on the output feature map
and the convolution filter
, an atrous convolution was applied on the input feature map
, with the following formula:
Atrous spatial pyramid pooling (ASPP) uses atrous convolution with different expansion rates to make up for the defects of atrous convolution, captures the context of multiple layers, fuses the obtained results, reduces the probability of information loss, and helps to improve the accuracy of convolutional neural networks.
3.2. Loss Function
The loss function was used to evaluate the difference between the prediction result of the model and the actual situation. Different loss functions are used in different models. In general, the better the loss function, the more accurate the model predictions. The main microstructure of high-carbon steel is sorbite, the content of which is generally more than 50% and is more than 70% in most samples. Therefore, the proportion of sorbite in the metallographic image is extremely unbalanced with the proportion of the background. In the sample shown in
Figure 1, the sorbite content (dark part) was about 97%. For the data set of this paper, the statistics of sample proportions with different sorbite contents are shown in
Table 1. Samples with a sorbite content higher than 80% accounted for 56.5% of the total. In general, unbalanced samples can cause training models to focus on predicting pixels as dominant types, while “disregarding” the minority types, which negatively affects the model’s ability to generalize on test data. Therefore, it is necessary to use the appropriate loss function or its combination to deal with the imbalance of the sample.
Table 1 shows the proportion of samples with different sorbite contents in the data set.
The detection of sorbite content is essentially a problem of a significant imbalance between positive and negative samples in a binary classification, and a large number of background pixels affect the segmentation accuracy of the model. Therefore, focal loss was selected as the semantic segmentation loss function in this paper. This function was originally proposed by He [
18] to solve the model performance problems caused by the imbalance of data classes and the difference in classification difficulty in the image domain. Focal loss adds a parameter
to the cross-entropy loss function and constructs an adjustment factor
to solve the problem of the sample imbalance. The calculation formula of the loss function is as follows:
where the sample
with accurate classification tends to 1, the regulation factor tends to 0; the sample
with inaccurate classification tends to 1, the regulation factor tends to 1. Compared with the cross-entropy loss function, focal loss does not change for inaccurately classified samples and decreases for accurately classified samples. Overall, it is equal to adding the weight of the sample with inaccurate classification to the loss function,
. It also reflects the difficulty of classification. The greater the
, the higher the confidence of classification, the more easily the representative sample is classified; the smaller the
, the lower the confidence of classification, the lower the confidence of classification, and the more difficult it is to classify the representative sample. Therefore, focal loss is equivalent to increasing the weight of difficult samples in the loss function, so that the loss function tends to be difficult samples, which is helpful to improve the accuracy of difficult samples.
In addition, the problem of region size imbalance between the sample foreground and the background of the sorbite image can be handled by the Dice loss [
19] function. Dice loss is a region-dependent loss, that is, the loss of the current pixel is not only related to the predicted value of the current pixel, but also related to the value of other pixel points. The specific loss function formula is:
where
X represents the target segmented image,
Y represents the predicted segmented image, and the intersection form of
Dice Loss can be understood as a mask operation. Therefore, regardless of the size of the image, the calculated loss of the fixed-size positive sample area is the same, and the supervision contribution to the network does not change with the size of the image.
Dice Loss training tends to tap into foreground areas and thus adapts to the smaller foreground situation in this paper. Training loss, however, is prone to instability, especially against small targets. In addition, gradient saturation occurs in extreme cases. Therefore, considering the sample situation of sorbite content, this paper combines
Dice Loss with focal loss.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}