
Phenotype-Driven Plasma Biobanking Strategies and Methods

 ,
,
Abstract
:1. Introduction
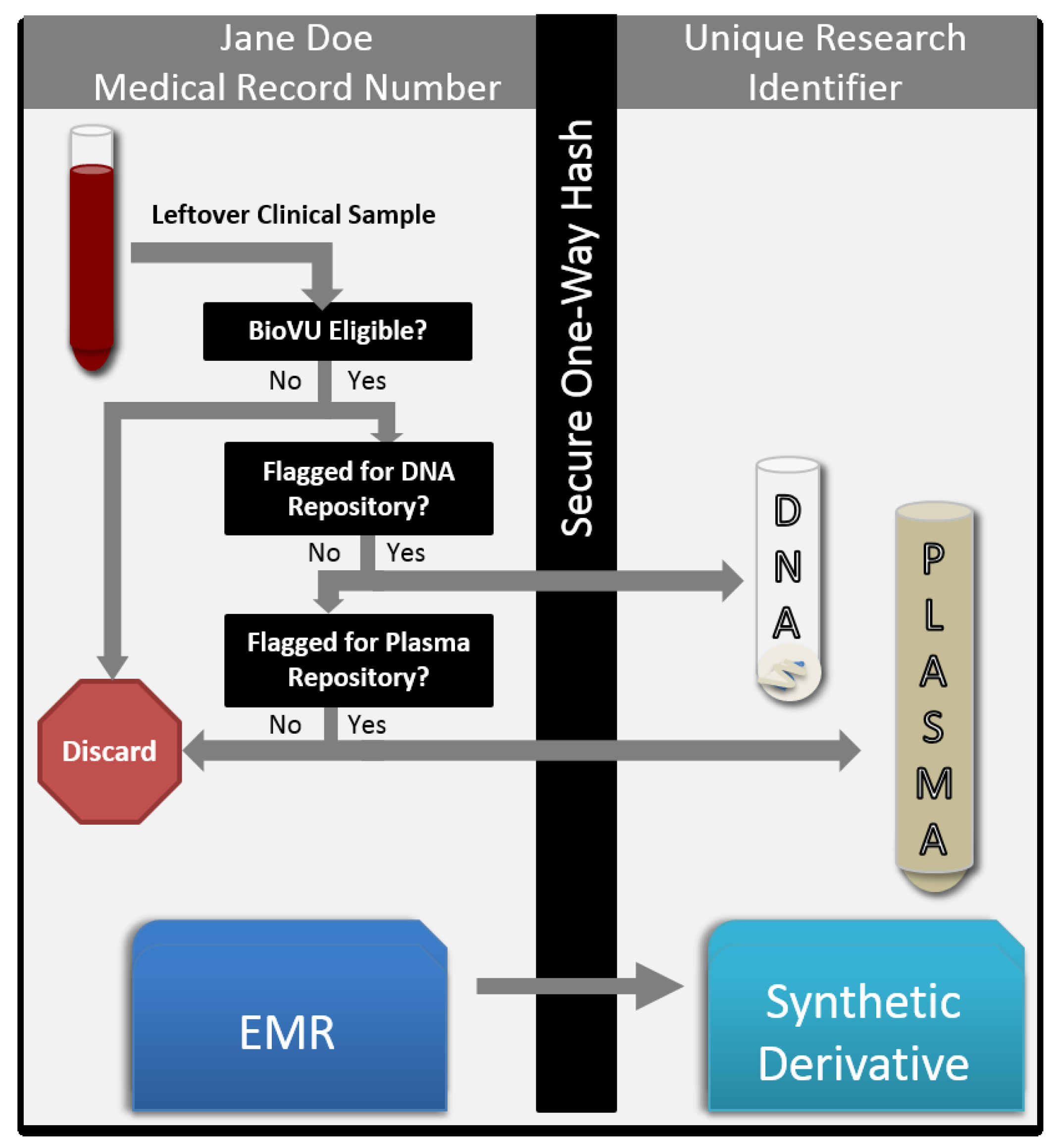
1.1. Perspectives from DNA Banking

1.2. Considerations for Plasma Collection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Standard Deviation | Median | |
|---|---|---|---|
| Total scanned samples | 35,519 | 5,527 | 36,409 |
| Total duplicate samples scanned | 11,165 | 2,063 | 11,437 |
2. Results and Discussion
2.1. Input and Approvals
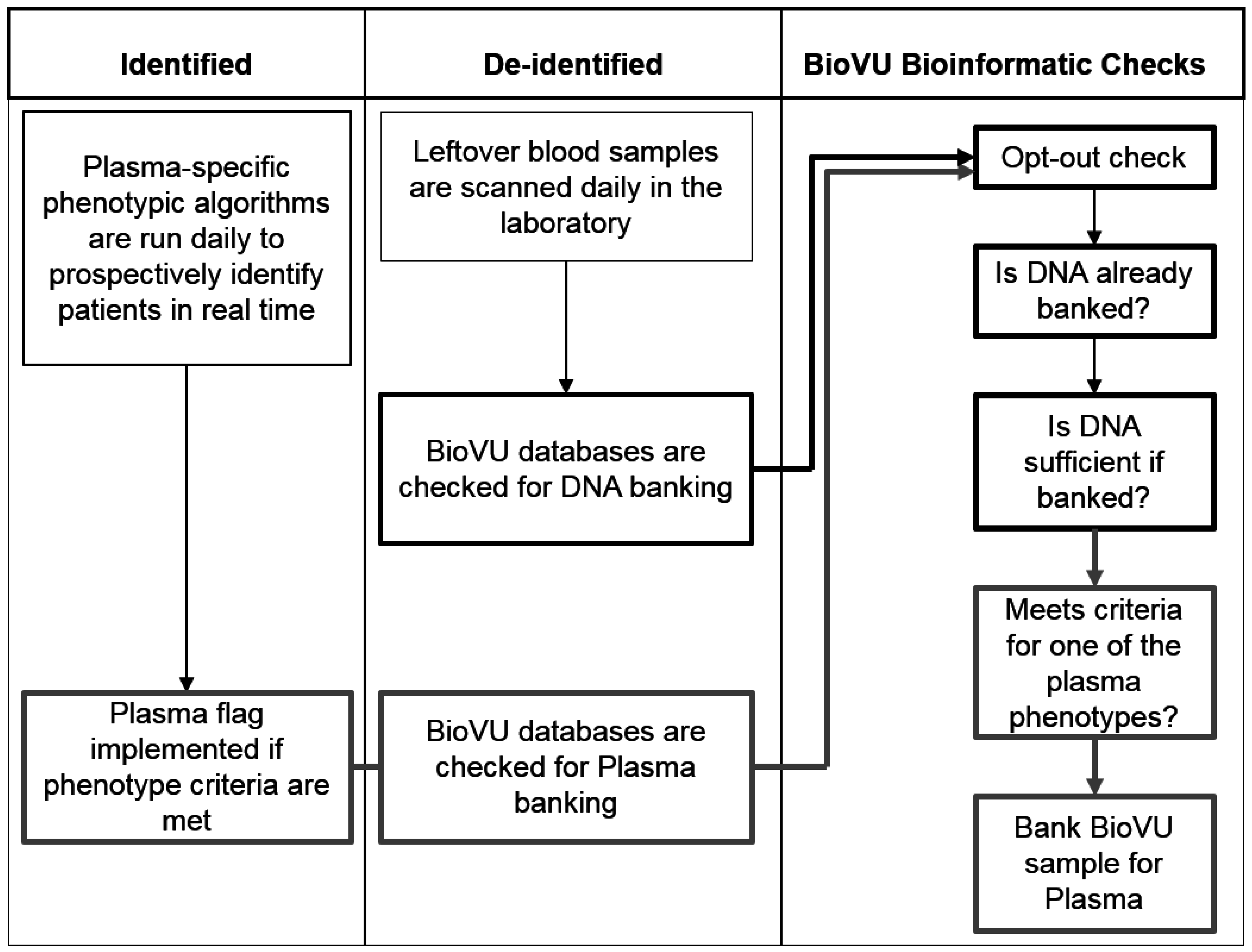
2.2. Pilot Plasma Project
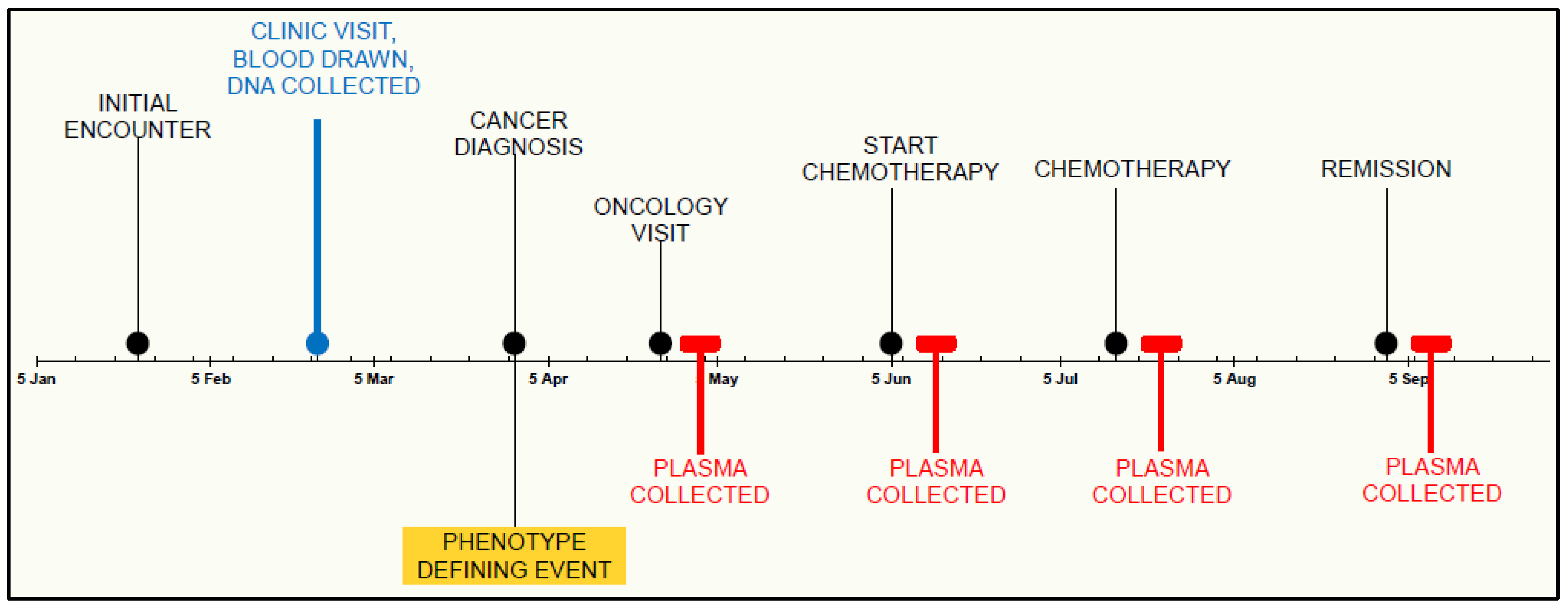
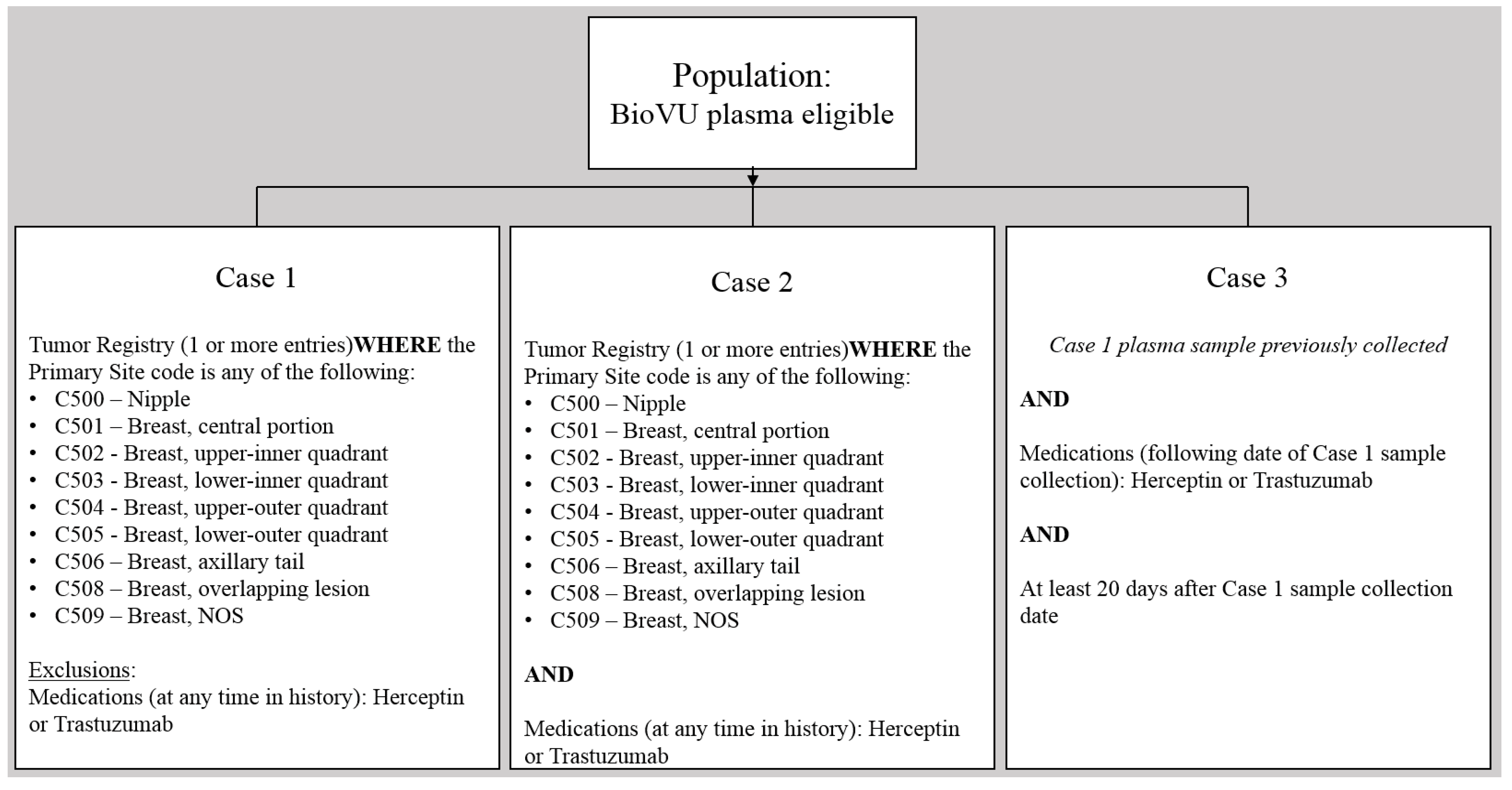
2.3. Phenotype-Driven Selection of Subjects


2.4. Collection and Processing
2.5. Discussion
3. Conclusions
Acknowledgments
Funding
Author Contributions
Abbreviations
| ICD | International Classification of Diseases |
| CPT | Current Procedural Terminology |
Appendix

Conflicts of Interest
References
- Ritchie, M.D.; Denny, J.C.; Crawford, D.C.; Ramirez, A.H.; Weiner, J.B.; Pulley, J.M.; Basford, M.A.; Brown-Gentry, K.; Balser, J.R.; Masys, D.R.; et al. Robust replication of genotype-phenotype associations across multiple diseases in an electronic medical record. Am. J. Hum. Genet. 2010, 86, 560–572. [Google Scholar] [CrossRef] [PubMed]
- Heatherly, R.D.; Loukides, G.; Denny, J.C.; Haines, J.L.; Roden, D.M.; Malin, B.A. Enabling genomic-phenomic association discovery without sacrificing anonymity. PLOS One 2013, 8, e53875. [Google Scholar] [CrossRef] [PubMed]
- McGregor, T.L.; van Driest, S.L.; Brothers, K.B.; Bowton, E.A.; Muglia, L.J.; Roden, D.M. Inclusion of pediatric samples in an opt-out biorepository linking DNA to de-identified medical records: pediatric BioVU. Clin. Pharmacol. Ther. 2013, 93, 204–211. [Google Scholar] [CrossRef] [PubMed]
- Pulley, J.; Clayton, E.; Bernard, G.R.; Roden, D.M.; Masys, D.R. Principles of human subjects protections applied in an opt-out, de-identified biobank. Clin. Transl. Sci. 2010, 3, 42–48. [Google Scholar] [CrossRef] [PubMed]
- Pulley, J.M.; Denny, J.C.; Peterson, J.F.; Bernard, G.R.; Vnencak-Jones, C.L.; Ramirez, A.H.; Delaney, J.T.; Bowton, E.; Brothers, K.; Johnson, K.; et al. Operational implementation of prospective genotyping for personalized medicine: The design of the Vanderbilt PREDICT project. Clin. Pharmacol. Ther. 2012, 92, 87–95. [Google Scholar] [CrossRef] [PubMed]
- Roden, D.M.; Pulley, J.M.; Basford, M.A.; Bernard, G.R.; Clayton, E.W.; Balser, J.R.; Masys, D.R. Development of a large-scale de-identified DNA biobank to enable personalized medicine. Clin. Pharmacol. Ther. 2008, 84, 362–369. [Google Scholar] [CrossRef] [PubMed]
- Bowton, E.; Field, J.R.; Wang, S.; Schildcrout, J.S.; Van Driest, S.L.; Delaney, J.T.; Cowan, J.; Weeke, P.; Mosley, J.D.; Wells, Q.S.; et al. Biobanks and electronic medical records: Enabling cost-effective research. Sci. Transl. Med. 2014, 6. [Google Scholar] [CrossRef]
- Chen, H.; Zhu, Z.; Zhu, Y.; Wang, J.; Mei, Y.; Cheng, Y. Pathway mapping and development of disease-specific biomarkers: Protein-based network biomarkers. J. Cell. Mol. Med. 2015, 19, 297–314. [Google Scholar] [CrossRef] [PubMed]
- Anderson, N.L. The clinical plasma proteome: A survey of clinical assays for proteins in plasma and serum. Clin. Chem. 2010, 56, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Kiddle, S.J.; Sattlecker, M.; Proitsi, P.; Simmons, A.; Westman, E.; Bazenet, C.; Nelson, S.K.; Williams, S.; Hodges, A.; Johnston, C.; et al. Candidate blood proteome markers of Alzheimer’s disease onset and progression: A systematic review and replication study. J. Alzheimers Dis. 2014, 38, 515–531. [Google Scholar] [PubMed]
- Jacobs, J.M.; Adkins, J.N.; Qian, W.-J.; Liu, T.; Shen, Y.; Camp, D.G.; Smith, R.D. Utilizing human blood plasma for proteomic biomarker discovery. J. Proteome Res. 2005, 4, 1073–1085. [Google Scholar] [CrossRef] [PubMed]
- Anderson, N.L.; Anderson, N.G. The human plasma proteome: History, character, and diagnostic prospects. Mol. Cell. Proteomics 2002, 1, 845–867. [Google Scholar] [CrossRef] [PubMed]
- Zimmerman, L.J.; Li, M.; Yarbrough, W.G.; Slebos, R.J.C.; Liebler, D.C. Global stability of plasma proteomes for mass spectrometry-based analyses. Mol. Cell. Proteomics 2012, 11. [Google Scholar] [CrossRef] [PubMed]
- Villanueva, J.; Shaffer, D.R.; Philip, J.; Chaparro, C.A.; Erdjument-Bromage, H.; Olshen, A.B.; Fleisher, M.; Lilja, H.; Brogi, E.; Boyd, J.; et al. Differential exoprotease activities confer tumor-specific serum peptidome patterns. J. Clin. Investig. 2006, 116, 271–284. [Google Scholar] [CrossRef] [PubMed]
- Marshall, J.; Kupchak, P.; Zhu, W.; Yantha, J.; Vrees, T.; Furesz, S.; Jacks, K.; Smith, C.; Kireeva, I.; Zhang, R.; et al. Processing of serum proteins underlies the mass spectral fingerprinting of myocardial infarction. J. Proteome Res. 2003, 2, 361–372. [Google Scholar] [CrossRef] [PubMed]
- Koomen, J.M.; Li, D.; Xiao, L.; Liu, T.C.; Coombes, K.R.; Abbruzzese, J.; Kobayashi, R. Direct tandem mass spectrometry reveals limitations in protein profiling experiments for plasma biomarker discovery. J. Proteome Res. 2005, 4, 972–981. [Google Scholar] [CrossRef] [PubMed]
- Borges, C.R.; Rehder, D.S.; Jensen, S.; Schaab, M.R.; Sherma, N.D.; Yassine, H.; Nikolova, B.; Breburda, C. Elevated plasma albumin and apolipoprotein A-I oxidation under suboptimal specimen storage conditions. Mol. Cell. Proteomics 2014, 13, 1890–1899. [Google Scholar] [CrossRef] [PubMed]
- Aguilar-Mahecha, A.; Kuzyk, M.A.; Domanski, D.; Borchers, C.H.; Basik, M. The Effect of Pre-Analytical Variability on the Measurement of MRM-MS-Based Mid- to High-Abundance Plasma Protein Biomarkers and a Panel of Cytokines. PLOS One 2012, 7, e38290. [Google Scholar] [CrossRef] [PubMed]
- Betsou, F.; Gunter, E.; Clements, J.; DeSouza, Y.; Goddard, K.A.B.; Guadagni, F.; Yan, W.; Skubitz, A.; Somiari, S.; Yeadon, T.; et al. Identification of Evidence-Based Biospecimen Quality-Control Tools. J. Mol. Diagn. 2013, 15, 3–16. [Google Scholar] [CrossRef] [PubMed]
- Skogstrand, K.; Ekelund, C.K.; Thorsen, P.; Vogel, I.; Jacobsson, B.; Nørgaard-Pedersen, B.; Hougaard, D.M. Effects of blood sample handling procedures on measurable inflammatory markers in plasma, serum and dried blood spot samples. J. Immunol. Methods 2008, 336, 78–84. [Google Scholar] [CrossRef] [PubMed]
- Clark, S.; Youngman, L.D.; Palmer, A.; Parish, S.; Peto, R.; Collins, R. Stability of plasma analytes after delayed separation of whole blood: Implications for epidemiological studies. Int. J. Epidemiol. 2003, 32, 125–130. [Google Scholar] [CrossRef] [PubMed]
- Ostroff, R.; Foreman, T.; Keeney, T.R.; Stratford, S.; Walker, J.J.; Zichi, D. The stability of the circulating human proteome to variations in sample collection and handling procedures measured with an aptamer-based proteomics array. J. Proteomics 2010, 73, 649–666. [Google Scholar] [CrossRef] [PubMed]
- Pasella, S.; Baralla, A.; Canu, E.; Pinna, S.; Vaupel, J.; Deiana, M.; Franceschi, C.; Baggio, G.; Zinellu, A.; Sotgia, S.; et al. Pre-analytical stability of the plasma proteomes based on the storage temperature. Proteome Sci. 2013, 11. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bowton, E.A.; Collier, S.P.; Wang, X.; Sutcliffe, C.B.; Van Driest, S.L.; Couch, L.J.; Herrera, M.; Jerome, R.N.; Slebos, R.J.C.; Alborn, W.E.; et al. Phenotype-Driven Plasma Biobanking Strategies and Methods. J. Pers. Med. 2015, 5, 140-152. https://doi.org/10.3390/jpm5020140
Bowton EA, Collier SP, Wang X, Sutcliffe CB, Van Driest SL, Couch LJ, Herrera M, Jerome RN, Slebos RJC, Alborn WE, et al. Phenotype-Driven Plasma Biobanking Strategies and Methods. Journal of Personalized Medicine. 2015; 5(2):140-152. https://doi.org/10.3390/jpm5020140
Chicago/Turabian StyleBowton, Erica A., Sarah P. Collier, Xiaoming Wang, Cara B. Sutcliffe, Sara L. Van Driest, Lindsay J. Couch, Miguel Herrera, Rebecca N. Jerome, Robbert J. C. Slebos, William E. Alborn, and et al. 2015. "Phenotype-Driven Plasma Biobanking Strategies and Methods" Journal of Personalized Medicine 5, no. 2: 140-152. https://doi.org/10.3390/jpm5020140