
The Da Vinci European BioBank: A Metabolomics-Driven Infrastructure

 and
and
Abstract
:1. Introduction
2. Metabolomics
Metabolomics for Biobanks and Biobanks for Metabolomics
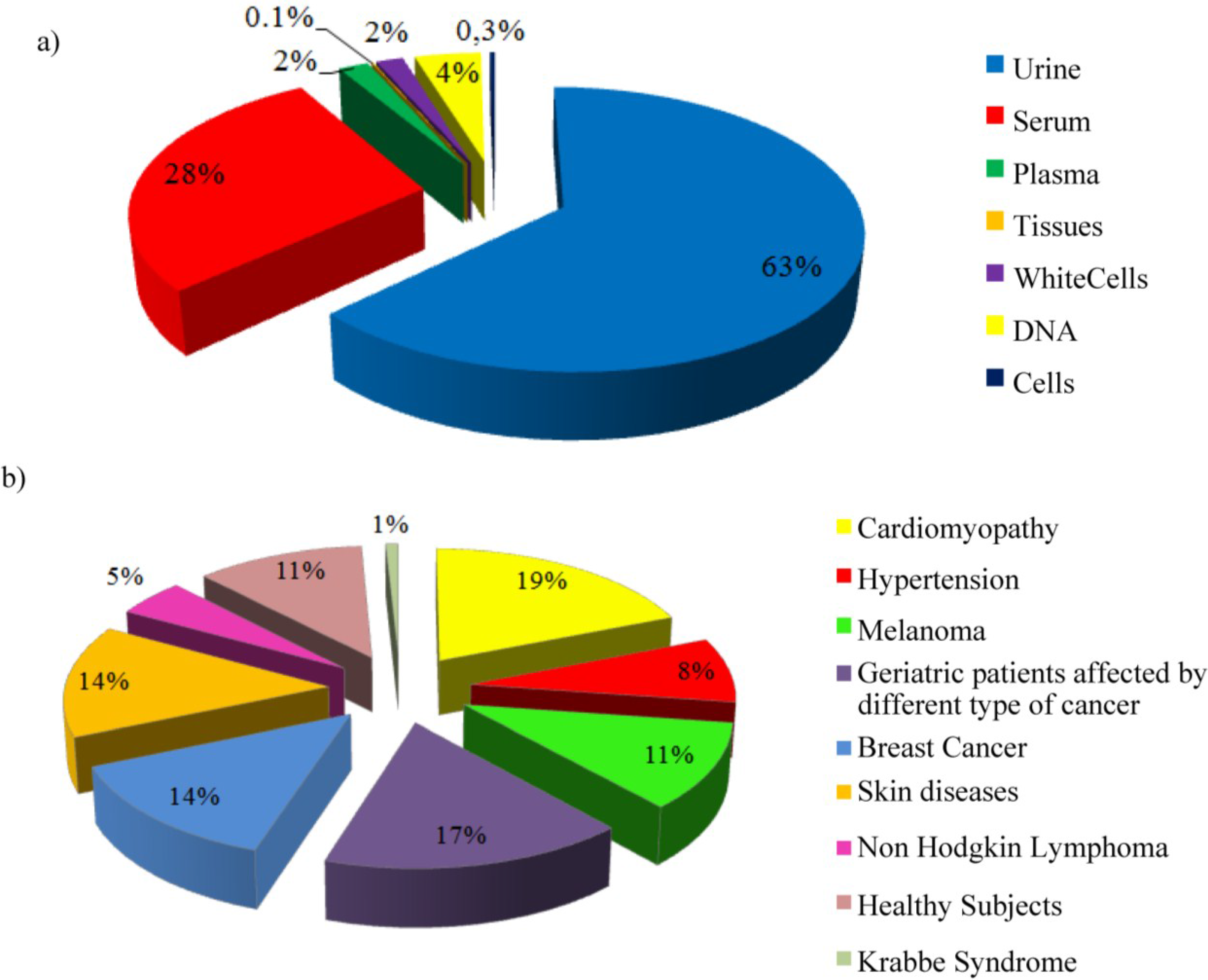
3. daVEB Collections

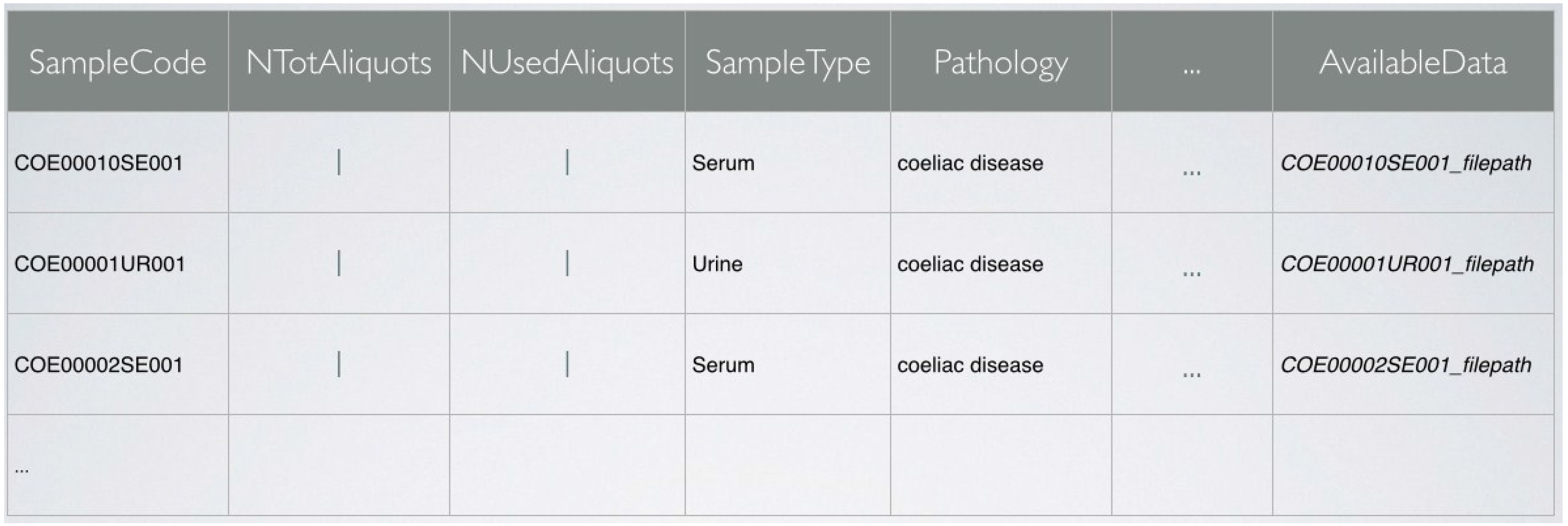
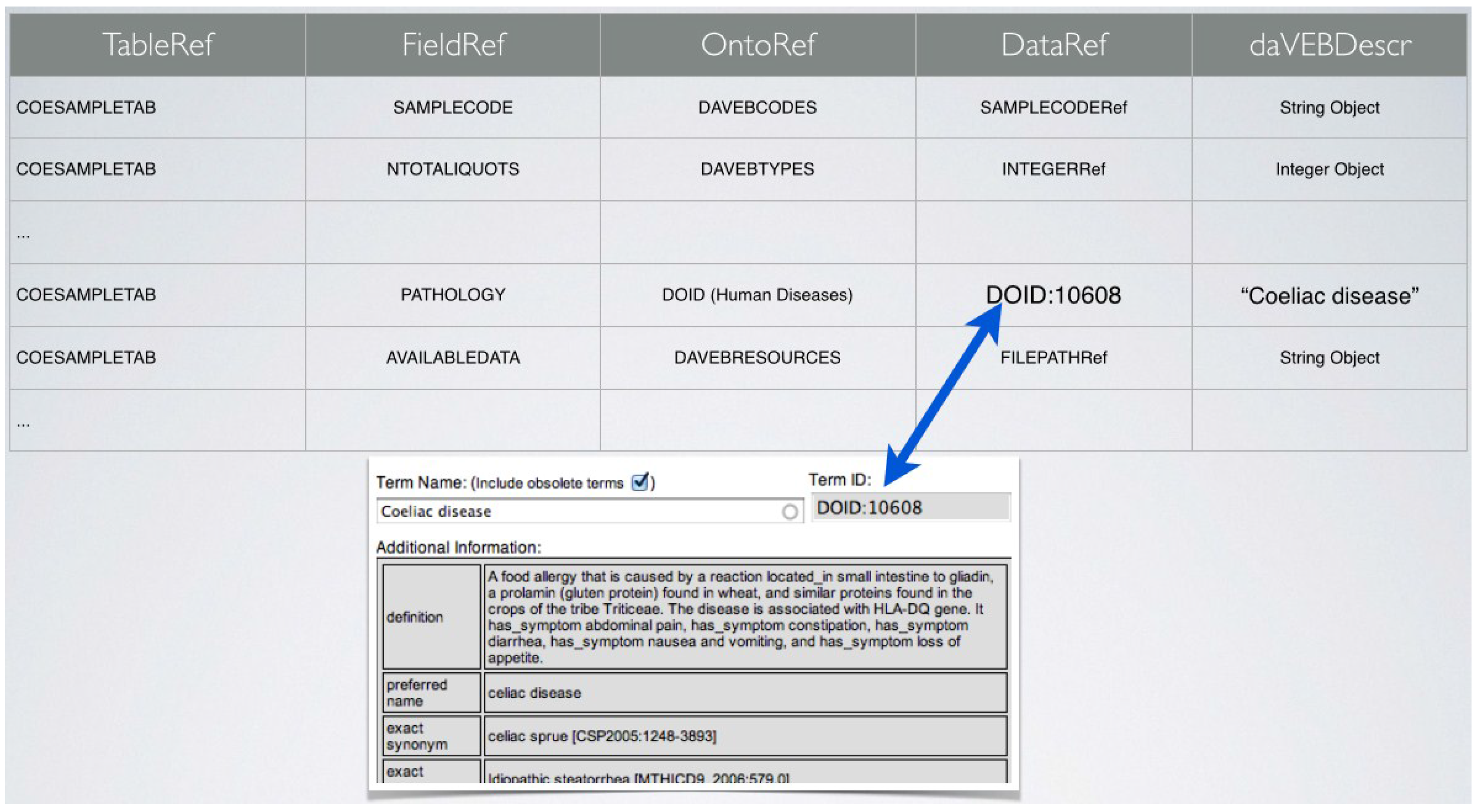
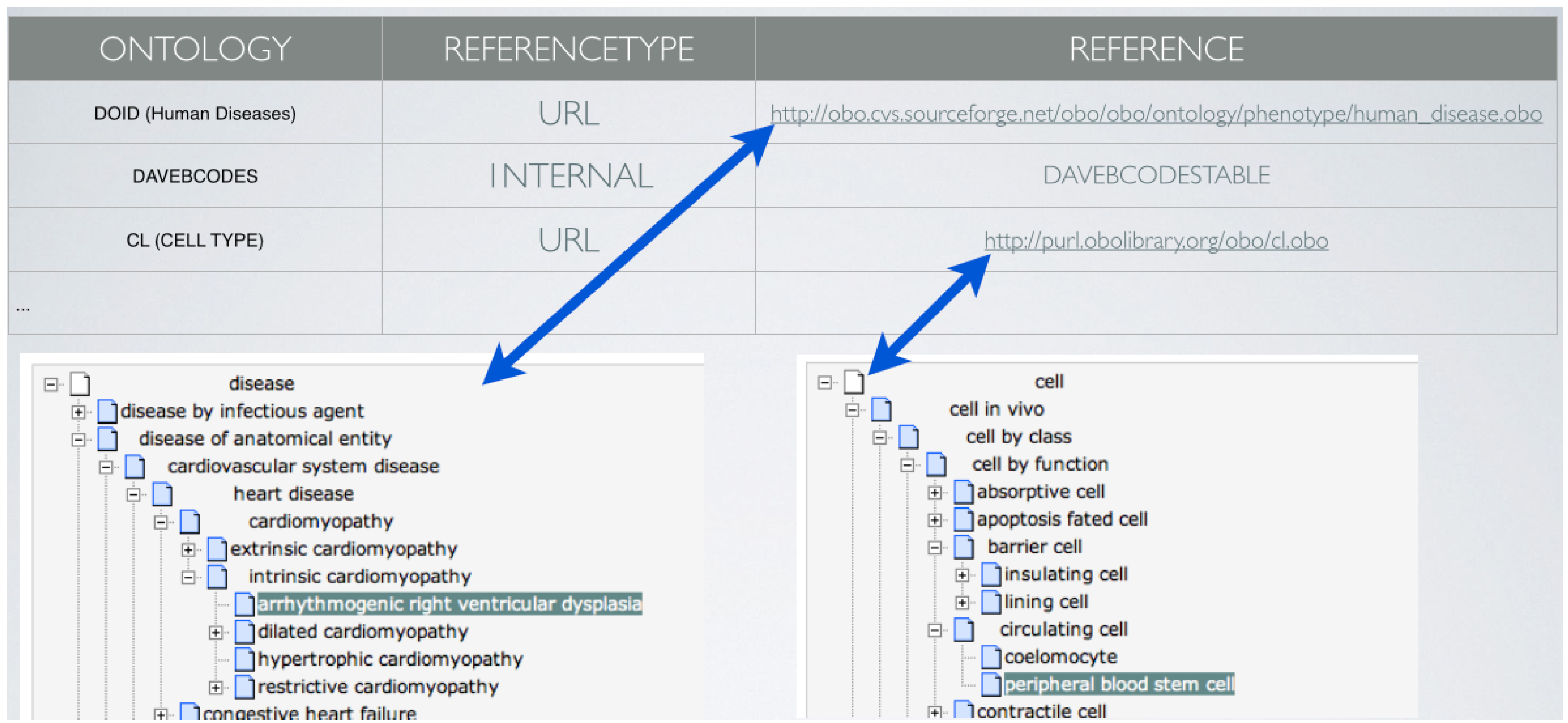
4. High Standards in the Data Management System



5. Conclusions
Acknowledgments
Author Contributions
Appendix

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease | Donor number | Sample type | Sample number | Available aliquots |
|---|---|---|---|---|
| Cardiomyopathy | 291 | Urine | 776 | 2863 |
| Serum | 810 | 2492 | ||
| Hypertension | 126 | Serum | 126 | 378 |
| Melanoma | 156 | Urine | 153 | 892 |
| 169 | Serum | 174 | 1137 | |
| 166 | Plasma | 170 | 1132 | |
| 154 | White Cells | 156 | 454 | |
| 4 | Tissue | 5 | 12 | |
| Geriatric patients affected by different type of cancer | 257 | Urine | 514 | 941 |
| Serum | 257 | 263 | ||
| Breast Cancer | 209 | Urine | 1520 | 2150 |
| Serum | 735 | 412 | ||
| Skin diseases | 219 | Serum | 219 | 254 |
| 2 | Plasma | 2 | 2 | |
| 21 | Cells | 27 | 27 | |
| 3 | Tissue | 3 | 3 | |
| Non Hodgkin Lymphoma | 73 | DNA | 381 | 402 |
| Healthy Subjects | 175 | Urine | 2476 | 9604 |
| Serum | 149 | 170 | ||
| Krabbe Syndrome | 13 | Urine | 10 | 79 |
| Serum | 11 | 45 |
Conflicts of Interest
References
- Marcon, G.; Nincheri, P. The Multispecialistic da Vinci European BioBank. Open J. Bioresour. 2014, 1, e6. [Google Scholar]
- Wishart, D.S.; Jewison, T.; Guo, A.C.; Wilson, M.; Knox, C.; Liu, Y.; Djoumbou, Y.; Mandal, R.; Aziat, F.; Dong, E.; et al. HMDB 3.0—The Human Metabolome Database in 2013. Nucleic Acids Res. 2013, 41, D801–D807. [Google Scholar]
- Veenstra, T.D. Metabolomics: The final frontier. Genome Med. 2012, 4. [Google Scholar] [CrossRef]
- Calabrò, A.; Gralka, E.; Luchinat, C.; Saccenti, E.; Tenori, L. A Metabolomic Perspective on Coeliac Disease. Autoimmune Dis. 2014, 2014. [Google Scholar] [CrossRef]
- Bernini, P.; Bertini, I.; Calabrò, A.; la Marca, G.; Lami, G.; Luchinat, C.; Renzi, D.; Tenori, L. Are patients with potential celiac disease really potential? The answer of metabonomics. J. Proteome Res. 2011, 10, 714–721. [Google Scholar]
- Bertini, I.; Calabrò, A.; de Carli, V.; Luchinat, C.; Nepi, S.; Porfirio, B.; Renzi, D.; Saccenti, E.; Tenori, L. The metabonomic signature of celiac disease. J. Proteome Res. 2009, 8, 170–177. [Google Scholar] [CrossRef] [PubMed]
- Padeletti, L.; Modesti, P.A.; Cartei, S.; Checchi, L.; Ricciardi, G.; Pieragnolia, P.; Sacchi, S.; Padeletti, M.; Alterini, B.; Pantaleo, P.; et al. Metabolomic does not predict response to cardiac resynchronization therapy in patients with heart failure. J. Cardiovasc. Med. (Hagerstown) 2014, 15, 295–300. [Google Scholar]
- Tenori, L.; Hu, X.; Pantaleo, P.; Alterini, B.; Castelli, G.; Olivotto, I.; Bertini, I.; Luchinat, C.; Gensini, G.F. Metabolomic fingerprint of heart failure in humans: A nuclear magnetic resonance spectroscopy analysis. Int. J. Cardiol. 2013, 168. [Google Scholar] [CrossRef]
- Bernini, P.; Bertini, I.; Luchinat, C.; Tenori, L.; Tognaccini, A. The cardiovascular risk of healthy individuals studied by NMR metabonomics of plasma samples. J. Proteome Res. 2011, 10, 4983–4992. [Google Scholar] [CrossRef] [PubMed]
- Tenori, L.; Oakman, C.; Morris, P.G.; Gralka, E.; Turner, N.; Cappadona, S.; Fornier, M.; Hudis, C.; Norton, L.; Luchinat, C.; et al. Serum metabolomic profiles evaluated after surgery may identify patients with oestrogen receptor negative early breast cancer at increased risk of disease recurrence. Results from a retrospective study. Mol. Oncol. 2015, 9, 128–139. [Google Scholar]
- Oakman, C.; Tenori, L.; Cappadona, S.; Luchinat, C.; Bertini, I.; di Leo, A. Targeting metabolomics in breast cancer. Curr. Breast Cancer Rep. 2012, 4, 249–256. [Google Scholar] [CrossRef]
- Tenori, L.; Oakman, C.; Claudino, W.M.; Bernini, P.; Cappadona, S.; Nepi, S.; Biganzoli, L.; Arbushites, M.C.; Luchinat, C.; Bertini, I.; et al. Exploration of serum metabolomic profiles and outcomes in women with metastatic breast cancer: A pilot study. Mol. Oncol. 2012, 6, 437–444. [Google Scholar]
- Oakman, C.; Tenori, L.; Claudino, W.M.; Cappadona, S.; Nepi, S.; Battaglia, A.; Bernini, P.; Zafarana, E.; Saccenti, E.; Fornier, M.; et al. Identification of a serum-detectable metabolomic fingerprint potentially correlated with the presence of micrometastatic disease in early breast cancer patients at varying risks of disease relapse by traditional prognostic methods. Ann. Oncol. 2011, 22, 1295–1301. [Google Scholar]
- Claudino, W.M.; Quattrone, A.; Biganzoli, L.; Pestrin, M.; Bertini, I.; di Leo, A. Metabolomics: Available results, current research projects in breast cancer, and future applications. J. Clin. Oncol. 2007, 25, 2840–2846. [Google Scholar] [CrossRef] [PubMed]
- Bertini, I.; Cacciatore, S.; Jensen, B.V.; Schou, J.V.; Johansen, J.S.; Kruhøffer, M.; Luchinat, C.; Nielsen, D.L.; Turano, P. Metabolomic NMR fingerprinting to identify and predict survival of patients with metastatic colorectal cancer. Cancer Res. 2012, 72, 356–364. [Google Scholar] [CrossRef] [PubMed]
- Dani, C.; Bresci, C.; Berti, E.; Ottanelli, S.; Mello, G.; Mecacci, F.; Breschi, R.; Hu, X.; Tenori, L.; Luchinat, C. Metabolomic profile of term infants of gestational diabetic mothers. J. Matern. Fetal Neonatal Med. 2014, 27, 537–542. [Google Scholar] [CrossRef] [PubMed]
- Bertini, I.; Luchinat, C.; Miniati, M.; Monti, S.; Tenori, L. Phenotyping COPD by 1H-NMR metabolomics of exhaled breath condensate. Metabolomics 2014, 10, 302–311. [Google Scholar] [CrossRef]
- Aimetti, M.; Cacciatore, S.; Graziano, A.; Tenori, L. Metabonomic analysis of saliva reveals generalized chronic periodontitis signature. Metabolomics 2012, 8, 465–474. [Google Scholar] [CrossRef]
- Assfalg, M.; Bertini, I.; Colangiuli, D.; Luchinat, C.; Schäfer, H.; Schütz, B.; Spraul, M. Evidence of different metabolic phenotypes in humans. Proc. Natl. Acad. Sci. USA 2008, 105, 1420–1424. [Google Scholar] [CrossRef] [PubMed]
- Bernini, P.; Bertini, I.; Luchinat, C.; Nepi, S.; Saccenti, E.; Schäfer, H.; Schütz, B.; Spraul, M.; Tenori, L. Individual human phenotypes in metabolic space and time. J. Proteome Res. 2009, 8, 4264–4271. [Google Scholar] [CrossRef] [PubMed]
- Bertini, I.; Luchinat, C.; Tenori, L. Metabolomics for the future of personalized medicine through information and communication technologies. Pers. Med. 2012, 9, 133–136. [Google Scholar] [CrossRef]
- Emwas, A.-H.; Luchinat, C.; Turano, P.; Tenori, L.; Roy, R.; Salek, R.M.; Ryan, D.; Merzaban, J.S.; Kaddurah-Daouk, R.; Zeri, A.C.; et al. Standardizing the experimental conditions for using urine in NMR-based metabolomic studies with a particular focus on diagnostic studies: A review. Metabolomics 2014. [Google Scholar] [CrossRef]
- Cacciatore, S.; Hu, X.; Viertler, C.; Kap, M.; Bernhardt, G.A.; Mischinger, H.J.; Riegman, P.; Zatloukal, K.; Luchinat, C.; Turano, P. Effects of intra- and post-operative ischemia on the metabolic profile of clinical liver tissue specimens monitored by NMR. J. Proteome Res. 2013, 12, 5723–5729. [Google Scholar] [CrossRef] [PubMed]
- Bernini, P.; Bertini, I.; Luchinat, C.; Nincheri, P.; Staderini, S.; Turano, P. Standard Operating Procedures for pre-analytical handling of blood and urine for metabolomic studies and biobanks. J. Biomol. NMR 2011, 49, 231–243. [Google Scholar] [CrossRef] [PubMed]
- Van Ommen, G.J.; Törnwall, O.; Bréchot, C.; Dagher, G.; Galli, J.; Hveem, K.; Landegren, U.; Luchinat, C.; Metspalu, A.; Nilsson, C.; et al. BBMRI-ERIC as a resource for pharmaceutical and life science industries: The development of biobank-based Expert Centres. Eur. J. Hum. Genet. 2014. [Google Scholar] [CrossRef]
- Smith, B.; Ashburner, M.; Rosse, C.; Bard, J.; Bug, W.; Ceusters, W.; Goldberg, L.J.; Eilbeck, K.; Ireland, A.; Mungall, C.J.; et al. The OBO Foundry: Coordinated evolution of ontologies to support biomedical data integration. Nat. Biotechnol. 2007, 25, 1251–1255. [Google Scholar]
- Richardson, L.; Ruby, S. RESTful Web Services—Web Services for the Real World, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2007. [Google Scholar]
- Fortier, I.; Burton, P.R.; Robson, P.J.; Ferretti, V.; Little, J.; L’Heureux, F.; Deschênes, M.; Knoppers, B.M.; Doiron, D.; Keers, J.C.; et al. Quality, quantity and harmony: The DataSHaPER approach to integrating data across bioclinical studies. Int. J. Epidemiol. 2010, 39, 1383–1393. [Google Scholar]
- Haug, K.; Salek, R.M.; Conesa, P.; Hastings, J.; de Matos, P.; Rijnbeek, M.; Mahendraker, T.; Williams, M.; Neumann, S.; Rocca-Serra, P.; et al. MetaboLights—An open-access general-purpose repository for metabolomics studies and associated meta-data. Nucleic Acids Res. 2013, 41, D781–D786. [Google Scholar]
- Cacciatore, S.; Luchinat, C.; Tenori, L. Knowledge discovery by accuracy maximization. Proc. Natl. Acad. Sci. USA 2014, 111, 5117–5122. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carotenuto, D.; Luchinat, C.; Marcon, G.; Rosato, A.; Turano, P. The Da Vinci European BioBank: A Metabolomics-Driven Infrastructure. J. Pers. Med. 2015, 5, 107-119. https://doi.org/10.3390/jpm5020107
Carotenuto D, Luchinat C, Marcon G, Rosato A, Turano P. The Da Vinci European BioBank: A Metabolomics-Driven Infrastructure. Journal of Personalized Medicine. 2015; 5(2):107-119. https://doi.org/10.3390/jpm5020107
Chicago/Turabian StyleCarotenuto, Dario, Claudio Luchinat, Giordana Marcon, Antonio Rosato, and Paola Turano. 2015. "The Da Vinci European BioBank: A Metabolomics-Driven Infrastructure" Journal of Personalized Medicine 5, no. 2: 107-119. https://doi.org/10.3390/jpm5020107