


From Data to Insights: Machine Learning Empowers Prognostic Biomarker Prediction in Autism
 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Ethics Statement
2.2. Data Set
2.3. Data Pre-Processing
2.3.1. Feature Selection
2.3.2. Lasso
2.4. Machine Learning Algorithms
2.5. Validation Approaches
2.6. Pathway Analysis and Gene Ontology (GO)
3. Results
3.1. Subject Characteristics
3.2. ROC Analysis
3.3. Machine Learning
3.4. Functional Analysis
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lord, C.; Elsabbagh, M.; Baird, G.; Veenstra-vanderweele, J. Seminar Autism spectrum disorder. Lancet 2018, 392, 508–520. [Google Scholar] [CrossRef] [PubMed]
- Iakoucheva, L.M.; Muotri, A.R.; Sebat, J. Getting to the Cores of Autism. Cell 2019, 178, 1287–1298. [Google Scholar] [CrossRef] [PubMed]
- Carroll, L.; Braeutigam, S.; Dawes, J.M.; Krsnik, Z.; Kostovic, I.; Coutinho, E.; Dewing, J.M.; Horton, C.A.; Gomez-nicola, D.; Menassa, D.A. Autism Spectrum Disorders: Multiple Routes to, and Multiple Consequences of, Abnormal Synaptic Function and Connectivity. Neuroscientist 2021, 27, 10–29. [Google Scholar] [CrossRef] [PubMed]
- Miles, J.H. Genetics in Medicine Autism spectrum disorders—A genetics review. Genet. Med. 2011, 13, 278–294. [Google Scholar] [CrossRef] [PubMed]
- Maenner, M.J.; Shaw, K.A.; Bakian, A.V.; Bilder, D.A.; Durkin, M.S.; Esler, A.; Furnier, S.M.; Hallas, L.; Hall-Lande, J.; Hudson, A.; et al. Prevalence and Characteristics of Autism Spectrum Disorder among Children Aged 8 Years—Autism and Developmental Disabilities Monitoring Network, 11 Sites, United States, 2018. MMWR Surveill. Summ. 2021, 70, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Maenner, M.J.; Warren, Z.; Williams, A.R.; Amoakohene, E.; Bakian, A.V.; Bilder, D.A.; Durkin, M.S.; Fitzgerald, R.T.; Furnier, S.M.; Hughes, M.M.; et al. Prevalence and Characteristics of Autism Spectrum Disorder among Children Aged 8 Years—Autism and Developmental Disabilities Monitoring Network, 11 Sites, United States, 2020. MMWR Surveill. Summ. 2023, 72, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Hyman, S. Autism: The Science of Mental Health; Routledge: Abingdon, UK, 2013; Available online: https://books.google.com.hk/books/about/Autism.html?id=_WZGAQAAQBAJ&source=kp_book_description&redir_esc=y (accessed on 14 July 2023).
- Bailey, A.; Couteur, A.L.E.; Gottesman, I.; Bolton, P.; Simonoff, E.; Yuzda, E. Autism as a strongly genetic disorder: Evidence from a British twin study. Psychol. Med. 1995, 25, 63–77. [Google Scholar] [CrossRef]
- Hu, V.W. From Genes to Environment: Using Integrative Genomics to Build a “Systems-Level” Understanding of Autism Spectrum Disorders. Child Dev. 2013, 84, 89–103. [Google Scholar] [CrossRef]
- Mojarad, B.A.; Yin, Y.; Dov, A.; Chandrakumar, I.; Prasolava, T.; Shum, N.; Hamdan, O.; Pellecchia, G.; Howe, J.L.; Whitney, J.; et al. Genome-wide detection of tandem DNA repeats that are expanded in autism. Nature 2020, 586, 80–86. [Google Scholar] [CrossRef]
- Satterstrom, F.K.; Kosmicki, J.A.; Wang, J.; Breen, M.S.; De Rubeis, S.; An, J.-Y.; Peng, M.; Collins, R.; Grove, J.; Klei, L.; et al. Large-Scale Exome Sequencing Study Implicates Both Developmental and Functional Changes in the Neurobiology of Autism. Cell 2020, 180, 568–584.e23. [Google Scholar] [CrossRef]
- Schaaf, C.P.; Yuen, R.K.C.; Gallagher, L.; Skuse, D.H.; Buxbaum, J.D.; Bolton, P.F.; Cook, E.H.; Scherer, S.W.; Vorstman, J.A.S. A framework for an evidence-based gene list relevant to autism spectrum disorder. Nat. Rev. Genet. 2020, 21, 367–376. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.G.; Imaichi, S.; Kraeutler, E.; Aguilar, R.; Lee, Y.W.; Sheridan, S.D.; Lee, J.T. Site-specific R-loops induce CGG repeat contraction and fragile X gene reactivation. Cell 2023, 186, 2593–2609.e18. [Google Scholar] [CrossRef]
- Ozkul, Y.; Taheri, S.; Bayram, K.K.; Sener, E.F.; Mehmetbeyoglu, E.; Öztop, D.B.; Aybuga, F.; Tufan, E.; Bayram, A.; Dolu, N.; et al. A heritable profile of six miRNAs in autistic patients and mouse models. Sci. Rep. 2020, 10, 9011. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Liu, X.; Lin, C.; Jia, X.; Zhu, H.; Song, J.; Zhang, Y. Noncoding RNAs regulate alternative splicing in Cancer. J. Exp. Clin. Cancer Res. 2021, 40, 11. [Google Scholar] [CrossRef] [PubMed]
- Rahmani, A.M.; Azhir, E.; Ali, S.; Mohammadi, M.; Ahmed, O.H.; Yassin Ghafour, M.; Hasan Ahmed, S.; Hosseinzadeh, M. Artificial intelligence approaches and mechanisms for big data analytics: A systematic study. PeerJ. Comput. Sci. 2021, 7, e488. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Lengerich, B.J.; Aragam, B.; Xing, E.P. Genetics and population analysis Precision Lasso: Accounting for correlations and linear dependencies in high-dimensional genomic data. Bioinformatics 2019, 35, 1181–1187. [Google Scholar] [CrossRef]
- Wang, Q. XGBoost Model for Chronic Kidney Disease Diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 2131–2140. [Google Scholar]
- Article, O. Breast Cancer Risk Estimation with Artificial Neural Networks Revisited. Cancer 2010, 116, 3310–3321. [Google Scholar] [CrossRef]
- Cho, S.; Won, H. Machine Learning in DNA Microarray Analysis for Cancer Classification. In Proceedings of the First Asia-Pacific Bioinformatics Conference on Bioinformatics 2003, Adelaide, Australia, 1 February 2003. [Google Scholar]
- Agresti, A. Categorical Data Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 792. [Google Scholar]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Medica 2014, 24, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Cai, N.; Pacheco, P.P. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics. Cancer Genom. Proteom. January 2018, 15, 41–51. [Google Scholar] [CrossRef]
- Id, J.L.; Jew, B.; Zhan, L.; Hwang, S.; Id, G.C.; Freimer, B.; Sul, J.H. ForestQC: Quality control on genetic variants from next-generation sequencing data using random forest. PLoS Comput. Biol. 2019, 15, e1007556. [Google Scholar]
- Pellegrino, E.; Jacques, C.; Beaufils, N.; Nanni, I.; Carlioz, A.; Metellus, P.; Ouafik, L.H. Machine learning random forest for predicting oncosomatic variant NGS analysis. Sci. Rep. 2021, 11, 21820. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009; Volume 2. [Google Scholar]
- Song, Y.Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef] [PubMed]
- Vlachos, I.S.; Zagganas, K.; Paraskevopoulou, M.D.; Georgakilas, G.; Karagkouni, D.; Vergoulis, T.; Dalamagas, T.; Hatzigeorgiou, A.G. DIANA-miRPath v3.0: Deciphering microRNA function with experimental support. Nucleic Acids Res. 2015, 43, W460–W466. [Google Scholar] [CrossRef]
- Rassoulzadegan, M.; Mehmetbeyoglu, E.; Yilmaz, Z.; Taheri, S.; Ozkul, Y. Progressive decline in the levels of six miRNAs from parents to children in autism. bioRxiv 2022. [Google Scholar] [CrossRef]
- Shaw, L.M. The insulin receptor substrate (IRS) proteins: At the intersection of metabolism and cancer. Cell Cycle 2011, 10, 1750–1756. [Google Scholar] [CrossRef]
- Tang, X.; Chen, Y.; Luo, H.; Bian, Q.; Weng, B.; Yang, A.; Chu, D.; Ran, M.; Chen, B. miR-126 controls the apoptosis and proliferation of immature porcine sertoli cells by targeting the pik3r2 gene through the PI3K/AKT signaling pathway. Animals 2021, 11, 2260. [Google Scholar] [CrossRef]
- Lin, S.; Gregory, R.I. MicroRNA biogenesis pathways in cancer. Nat. Rev. Cancer 2015, 15, 321–333. [Google Scholar] [CrossRef]
- Wang, F.; Chen, C.; Wang, D. Circulating microRNAs in cardiovascular diseases: From biomarkers to therapeutic targets. Front. Med. 2014, 8, 404–418. [Google Scholar] [CrossRef] [PubMed]
- Absalon, S.; Kochanek, D.M.; Raghavan, V.; Krichevsky, A.M. MiR-26b, upregulated in Alzheimer’s disease, activates cell cycle entry, tau-phosphorylation, and apoptosis in postmitotic neurons. J. Neurosci. Off. J. Soc. Neurosci. 2013, 33, 14645–14659. [Google Scholar] [CrossRef] [PubMed]
- Hay, N.; Sonenberg, N. Upstream and downstream of mTOR. Genes Dev. 2004, 18, 1926–1945. [Google Scholar] [CrossRef] [PubMed]
- Huber, K.M.; Klann, E.; Costa-Mattioli, M.; Zukin, R.S. Dysregulation of mammalian target of rapamycin signaling in mouse models of autism. J. Neurosci. 2015, 35, 13836. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Qin, Y.; Wu, Q.; Li, X.; Xie, D.; Zhao, Z.; Duan, S. mTOR Signaling Pathway Regulates the Release of Proinflammatory Molecule CCL5 Implicated in the Pathogenesis of Autism Spectrum Disorder. Front. Immunol. 2022, 13, 818518. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Alberts, I.; Li, X. Dysregulation of the IGF-I/PI3K/AKT/mTOR signaling pathway in autism spectrum disorders. Int. J. Dev. Neurosci. 2014, 35, 35–41. [Google Scholar] [CrossRef] [PubMed]
- Yeung, K.S.; Tso, W.W.Y.; Ip, J.J.K.; Mak, C.C.Y.; Leung, G.K.C.; Tsang, M.H.Y.; Ying, D.; Pei, S.L.C.; Lee, S.L.; Yang, W.; et al. Identification of mutations in the PI3K-AKT-mTOR signalling pathway in patients with macrocephaly and developmental delay and/or autism. Mol. Autism 2017, 8, 66. [Google Scholar] [CrossRef] [PubMed]
- Bhandari, R.; Paliwal, J.K.; Kuhad, A. Neuropsychopathology of Autism Spectrum Disorder: Complex Interplay of Genetic, Epigenetic, and Environmental Factors. In Personalized Food Intervention and Therapy for Autism Spectrum Disorder Management; Springer: Cham, Switzerland, 2020; Volume 24. [Google Scholar] [CrossRef]
- Trifonova, E.A.; Klimenko, A.I.; Mustafin, Z.S.; Lashin, S.A.; Kochetov, A.V. The mTOR signaling pathway activity and vitamin d availability control the expression of most autism predisposition genes. Int. J. Mol. Sci. 2019, 20, 6332. [Google Scholar] [CrossRef]
- Pagani, M.; Barsotti, N.; Bertero, A.; Trakoshis, S.; Ulysse, L.; Locarno, A.; Miseviciute, I.; De Felice, A.; Canella, C.; Supekar, K.; et al. mTOR-related synaptic pathology causes autism spectrum disorder-associated functional hyperconnectivity. Nat. Commun. 2021, 12, 6084. [Google Scholar] [CrossRef]
- Tufan, E.; Taheri, S.; Karaca, Z.; Mehmetbeyoglu, E.; Yilmaz Sukranli, Z.; Korkmaz Bayram, K.; Ulutabanca, H.; Tanrıverdi, F.; Unluhizarci, K.; Rassoulzadegan, M.; et al. Alterations in serum miR-126-3p levels over time, a marker of pituitary insufficiency following head trauma. Neuroendocrinology 2023. [Google Scholar] [CrossRef]







{kind=link}
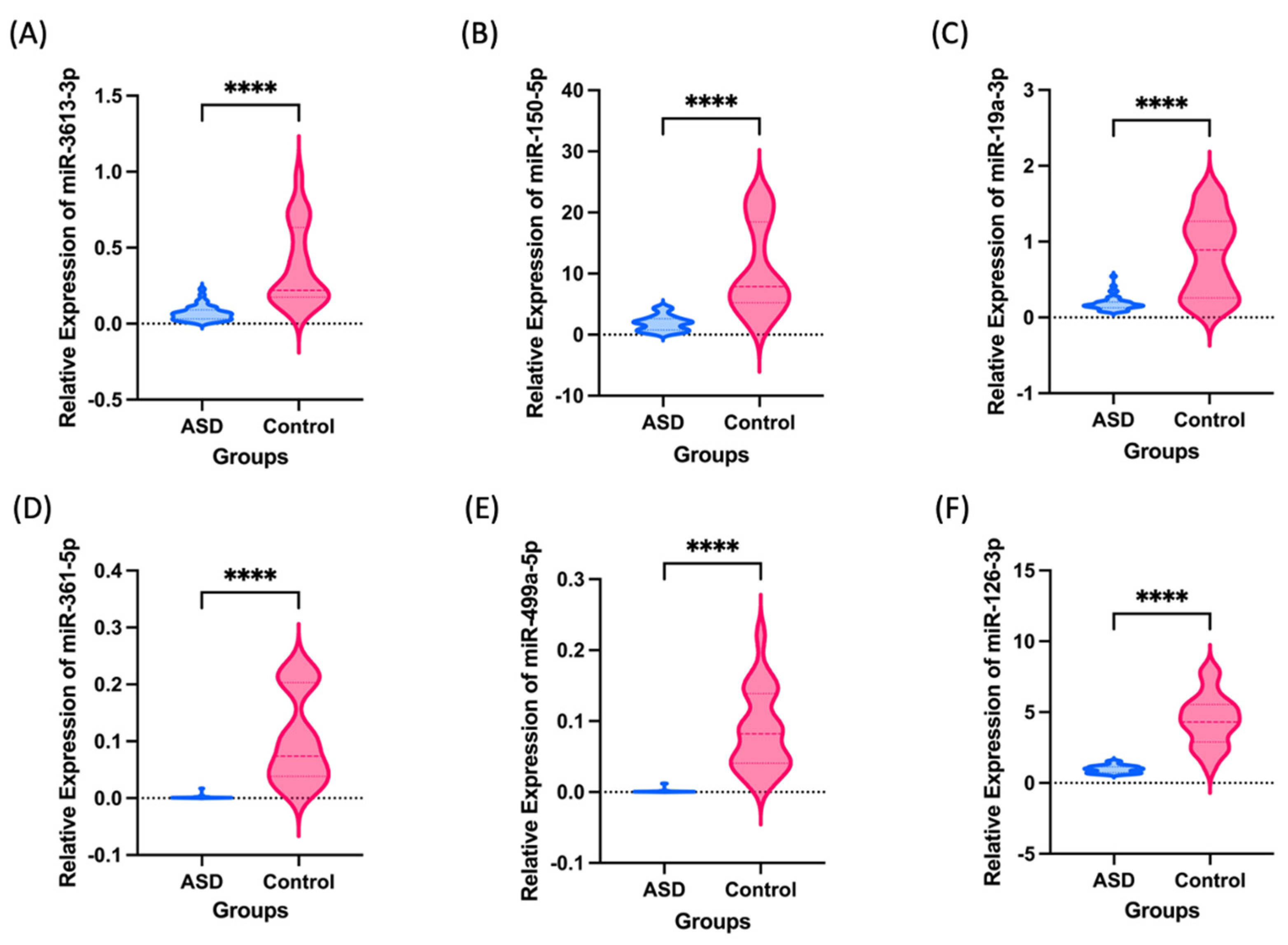{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| miRNAs | AUC | SEM | 95% CI | p |
|---|---|---|---|---|
| miR-3613-3p | 0.956 | 0.023 | 0.9109–1 | <0.0001 |
| miR-150-5p | 0.946 | 0.033 | 0.8803–1 | <0.0001 |
| miR-19a-3p | 0.894 | 0.043 | 0.8094–0.979 | <0.0001 |
| miR-361-5p | 0.998 | 0.001 | 0.9954–1 | <0.0001 |
| miR-499a-5p | 0.956 | 0.001 | 0.9954–1 | <0.0001 |
| miR-126-3p | 0.988 | 0.0123 | 0.9646–1 | <0.0001 |
| Models | Accuracy | SD | Specificity | Sensitivity |
|---|---|---|---|---|
| KNN | 0.94 | 0.06 | 0.81 | 1 |
| Logistic regression | 0.94 | 0.06 | 0.81 | 1 |
| Support vector machine | 0.94 | 0.05 | 0.82 | 1 |
| Random forest classifier | 0.94 | 0.05 | 0.84 | 0.98 |
| Decision tree | 0.96 | 0.05 | 0.9 | 0.99 |
| Models | Accuracy | Specificity | Sensitivity |
|---|---|---|---|
| KNN | 1 | 1 | 1 |
| Logistic regression | 0.90 | 0.71 | 1 |
| Support vector machine | 0.95 | 0.85 | 1 |
| Random forest classifier | 0.90 | 1 | 0.86 |
| Decision tree | 0.95 | 1 | 0.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehmetbeyoglu, E.; Duman, A.; Taheri, S.; Ozkul, Y.; Rassoulzadegan, M. From Data to Insights: Machine Learning Empowers Prognostic Biomarker Prediction in Autism. J. Pers. Med. 2023, 13, 1713. https://doi.org/10.3390/jpm13121713
Mehmetbeyoglu E, Duman A, Taheri S, Ozkul Y, Rassoulzadegan M. From Data to Insights: Machine Learning Empowers Prognostic Biomarker Prediction in Autism. Journal of Personalized Medicine. 2023; 13(12):1713. https://doi.org/10.3390/jpm13121713
Chicago/Turabian StyleMehmetbeyoglu, Ecmel, Abdulkerim Duman, Serpil Taheri, Yusuf Ozkul, and Minoo Rassoulzadegan. 2023. "From Data to Insights: Machine Learning Empowers Prognostic Biomarker Prediction in Autism" Journal of Personalized Medicine 13, no. 12: 1713. https://doi.org/10.3390/jpm13121713