1. Introduction
Dentofacial dysmorphosis is characterized by retrognathism, prognathism, and asymmetry [
1,
2,
3]. Various orthognathic surgery techniques have been applied for treatment [
4,
5]. An accurate and stereoscopic diagnosis of the patient’s current condition is required prior to operation [
6]. Until now, orthognathic surgery has mainly depended on linear and angular measurements for the diagnosis and planning of therapeutic procedures [
6,
7,
8]. These measurements rely on the identification of several landmarks on cephalometric images, which are then applied to define the measurements. This is not only complicated and cumbersome, but it also takes a long time because it is greatly affected by proficiency.
Deep learning has developed rapidly in recent years, making it possible to automatically extract information in the medical field from diagnoses using medical imaging and pattern analysis [
9,
10,
11,
12,
13,
14,
15]. Deep neural networks (DNNs), a type of deep learning, have been widely applied to medical images because of their high performance in detection, classification, and segmentation [
16,
17,
18,
19,
20]. It can reduce the labor of experts while detecting image information that may be missed by humans. Deep learning research related to the diagnosis and planning of dentofacial dysmorphosis is being actively conducted [
21,
22,
23]. However, most have focused only on finding reference points, planes, and angles using conventional methods [
21,
22,
23]. This may have been due to their failure to grasp the true nature of DNNs. Hence, we propose a method that better fits DNN characteristics. In this study, the authors introduced the prediction of postoperative results for orthognathic surgery that are not bound by points, planes, and angles.
The present method is used to predict postoperative orthognathic surgery using a DNN trained with actual three-dimensional (3D) point cloud data. In contrast to a previous study using artificially generated 3D point cloud data [
24], the present method considers actual pre- and postoperative surgery data for training. In doing so, the present method resolved three main issues.
The first issue is related to the generation of training data from actual pre- and postoperative surgery data. In this study, we attempted to learn from actual data, not from simulation data that arbitrarily caused skull deformations in previous studies [
24]. However, there is a problem when trying to generate training data from actual data: the point cloud of pre- and postoperative computed tomography (CT) data does not match one-to-one. Thus, the displacement of each point cannot be defined. Therefore, training data cannot be generated. To solve this problem, we segment the point cloud by considering osteotomized segments and matching the segmented parts to each part after surgery. The iterative closest point (ICP) method was used to match the preoperative point cloud to the postoperative point cloud. After matching, six transformation parameters were calculated and used as labels for the training data. Through the proposed training data generation method, it is possible to use actual pre- and postoperative point cloud data during training.
The second issue relates to the architecture of the DNN. The present method divides the skull into six parts and predicts the 3D deformation parameters for each. To do this, it is necessary to define a network to learn the transformation parameters of each part. Orthognathic surgery was performed considering the overall shape of the skull. Therefore, when only the divided part is used as input, the features of the transformation to be learned cannot appear; therefore, the reference point cloud should be input. In this study, features were extracted by inputting the entire point cloud of the preoperative skull and the divided part into the feature extractor. Each extracted feature is then merged through concatenation, and, finally, the deformation parameters of each part are predicted through a fully connected layer. Additionally, the accuracies according to the feature extractors for irregular point cloud data proposed in the previous studies, such as pointnet [
25], pointnet++ [
26], and pointconv [
27], were compared to construct a network with higher accuracy.
The third issue is related to the loss function for higher accuracy. When using the network described in the second issue, two types of point cloud data are input, and six transformation parameters are predicted. The purpose of the network is to accurately predict the six transformation parameters. Therefore, the mean absolute error (MAE) of the six transformation parameters between prediction and ground truth should be minimized. However, when learning with only the MAE of the transformation parameters, the information given to the DNN is limited, and the learning efficiency tends to decrease. To solve this issue, we defined a 3D functional transformation layer that uses divided point cloud data and predicted transformation parameters. By using the transformation layer, the predicted transformed point cloud coordinates are output, and the MAE can be calculated by comparing them to the ground truth coordinates. Finally, the loss function is defined by using the sum of the MAE of the transformation parameters and coordinates, and it is confirmed that the accuracy can be improved.
Therefore, the contributions of this study can be described as follows:
A new postoperative prediction method using the point coordinate information of real 3D CT data for orthognathic surgery is proposed.
A new training data generation method for training postoperative predictive networks is proposed.
A new architecture and loss function for DNNs of higher accuracy are provided.
In the case of the previous method, it was not possible to train using real pre- and postoperative data, but the method proposed in this study enables training using real pre- and postoperative data.
The remainder of this paper is organized as follows. First, the method for generating training data, alignment network, and loss function is described in detail. Thereafter, the results obtained using the proposed method are described. Accuracies based on the feature extractor and loss function are discussed. Finally, we summarize and discuss our findings.
2. Materials and Methods
2.1. Raw Data Acquisition
In this study, 269 participants at Wonkwang University, Daejeon Dental Hospital, were included. All were native Koreans. The patients’ chief complaints were retrognathism, prognathism, and asymmetry. Accordingly, CT images were taken for analysis before and one week after surgery. The inclusion criteria were as follows: age between 18 and 29 years, complete dentition apart from third molars, and the patient’s agreement with 3D CT of the head. Apart from cases with congenital deformities, such as cleft lip, cleft palate, and hemifacial microsomia, only patients with developmental dysmorphosis were included. All patients underwent preoperative CT after completion of preoperative orthodontic treatment. There was no case of teeth extraction for orthodontic treatment. A single surgeon diagnosed all cases, and two operated on all cases in the same way. LeFort I osteotomy was performed on the maxilla, vertical ramus osteotomy, or sagittal split ramus osteotomy of the mandible, and genioplasty on the chin. This study was approved by the Institutional Review Board of Wonkwang University Daejeon Dental Hospital (W2109/002-001).
A SOMATOM Definition Dual Source CT (DSCT; Siemens, Forchhelm, Germany) was used to conduct a 3D analysis under the following imaging conditions: scanning time, 1 s; 100 kV; field of view, 20.8 cm; 76 mAs; and 0.5 mm thickness. For accurate evaluation, individuals were asked to maintain a centric occlusion and remain still. All CT cross-sections were saved in the Digital Imaging Communications in Medicine format.
2.2. Ground Truth Rigid Transformation Parameter Calculation
To train the alignment network, the ground truth values of the six rigid transformation parameters are needed. In this study, the ICP used for point cloud alignment was used to obtain this value. ICP finds a rigid body transformation where the source points best match the reference, while the reference points are fixed. The ICP finds a rigid body transformation by iteratively minimizing the error metric, expressed as the distance between the reference point cloud and the source point cloud. ICP was first proposed by Chen and Medioni and Besl and McKay, and various ICP variants have been proposed to improve the performance.
The ICP is implemented in an open-source environment, such as Meshlab, CloudCompare, or Point Cloud Library. In this study, alignment was performed using CloudCompare 2.11.3 (Anoia). As the actual preoperative and postoperative skulls are not aligned with each other, and the coordinates of the minimum point are all different. To solve this problem, in step 1, the pre- and postoperative skull were first translated so that the minimum values of each coordinate were zero. Subsequently, the entire preoperative skull was aligned based on the cranium (part 1) of the postoperative skull. In step 2, the rigid transformation parameters were calculated by aligning preoperative parts 2–4 with the corresponding postoperative parts. In this study, the RMS difference and final overlap values were set to 1 × 10−20 and 100%, respectively, for the convergence criteria. Using the process described above, transformation parameters for pre- and postoperative data of a total of 269 patients were calculated and used as ground truth values.
2.3. Data Normalization
To train the proposed network, the data were normalized. After calculating the rigid transformation parameters for all patients, the maximum value,
, and minimum value,
, of each parameter were obtained. With this value, the label value was normalized, as shown in (1):
The point cloud coordinates of all patients were also normalized, as shown in (2), using the maximum value,
, among all patients and used as input.
Note that before being input into the transformation layer of the proposed network, the transformation parameter values and input coordinate values were unnormalized and used.
2.4. Input Point Generation for Segmentation and Alignment Network
The number of point clouds in the actual patient data was different for each patient. In this study, a certain number of points were input into the segmentation and alignment networks. In the case of segmentation, all point cloud data of patients were divided into 2048 points in order, and input data were generated by setting the batch size to 64. In the case of the alignment network, three networks were trained for parts 2–4. In the case of part 1 used as a reference, 16,384 points were input for all alignment networks, and 8192, 16,384, and 2048 points were input for parts 2, 3, and 4, respectively. For the alignment network, the input points were randomly selected from each part.
2.5. Three-Dimensional Postoperative Prediction Method
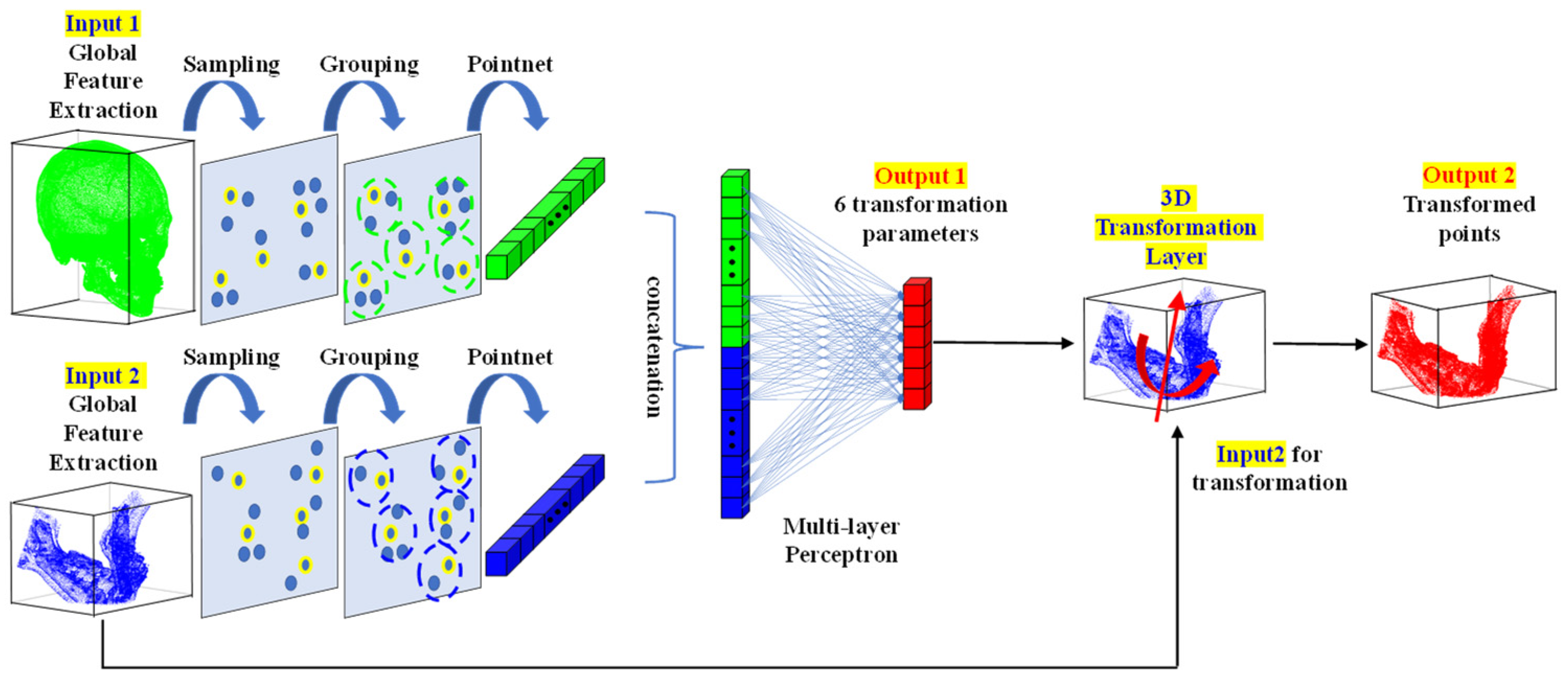
The proposed DNN is divided into two main stages, as shown in
Figure 1. The role of the first network is to segment the patient’s skull by learning the actual osteotomy area. The divided parts in the first network were used as inputs for the second network. The role of the second network is to learn the actual patient’s surgical results and align each part. The alignment network is the core method proposed in this study, and it serves to align each part based on the cranium, which does not change after surgery. Subsequently, the loss function for training the proposed network is explained.
2.6. Point Segmentation Network for the Jaw Part Division
Orthognathic surgery involves cutting the jaw and aligning the osteotomized segments. Therefore, the DNN also predicts surgical outcomes in a procedure, such as that of actual surgery. This subsection describes the first process: the jaw segmentation network. The jaw point cloud is segmented using a segmentation network to create each part used as an input to the alignment network. The osteotomized segments of the patient considered in this study were slightly different, depending on the condition of the patient’s jaw. To divide each part through deep learning, the osteotomized area must be generalized so that all patient data were checked. Therefore, the surgical method was generalized. As shown in
Figure 1, the network was configured to divide the skulls of all patients into six parts.
There is a large difference in the number of points, depending on the segmented skull part. For the cranium (
Figure 1, part 1), which occupies the largest part, there were cases in which the number of points was almost 100 times larger than that of parts 5 and 6, which had the smallest number of points. To increase the accuracy of the DNN, it is important to reduce the data imbalance among parts. Therefore, in this study, the skull was divided sequentially by dividing the cranium (part 1) and the other lower parts. After the first segmentation, the lower parts were separated into five parts using the second segmentation network.
There are many networks for point cloud segmentation. In this study, pointnet and pointconv are used as the first segmentation network and second segmentation network, respectively. These networks are a DNN that uses point data composed of x (transverse), y (anterior–posterior), and z (vertical) coordinates in an irregular format rather than a regular one, such as an image. Pointnet is a network designed to satisfy the permutation invariant, in which the result, according to the input order of points, does not change. The rigid motion invariant that the result according to the rigid body transformation of the point also does not change. Pointconv is a density re-weighted convolution based on pointnet++ that improved pointnet. It is able to fully approximate the 3D continuous convolution on any set of 3D points.
2.7. The 3D Point Alignment Network for Jaw Alignment Prediction
The points segmented through the segmentation network are used as inputs to the alignment network, which is the core method of this study. The alignment network presented in this study learns 3D rigid-body transformation parameters. The 3D points can be rigidly transformed by methods, such as a transformation matrix, Euler angle, and axis and angle. In the case of the Euler angle and axis and angle methods, the transformation of a rigid body can be expressed using a total of six parameters: three related to rotation and three related to translation. In the case of the Euler angle method, the parameter values vary according to the order of the rotation axes; therefore, in this study, the network was designed to learn the parameters expressed using the axis and angle method.
The structure of the point alignment network is shown in
Figure 2. For the global feature extraction, pointnet, pointnet++, pointconv, and others can be used. In the proposed network, the points of a whole part and a part requiring alignment are used as the reference input and aligned input, respectively. Subsequently, a feature extraction was performed for each part. The features of each input were then combined through concatenation and input into a multilayer perceptron (MLP). In the MLP, six rigid body transformation parameter values were calculated as the output, as shown in
Figure 2. Additionally, the six rigid body transformation parameter values were input into the 3D functional transformation layer alongside the points of the part that needed alignment, so that the rigid-body transformed points were also calculated. In the 3D transformation layer, the final transformed point,
, was calculated by adding
representing the x, y, and z translation values to the rotated point, as shown in (3):
2.8. Loss Function for Training of Point Alignment Network
The point alignment network described in the previous section learns the 3D transformation parameter values of the part through deep regression. Therefore, the MAE is used as the first loss function to match the transformation parameter value with the ground truth value as much as possible. Additionally, the mean value of distance error (DE) between points of a part is set as the second loss so that the coordinates transformed using the predicted transformation parameter value match the coordinates transformed through the ground truth value. By adding two loss functions, the final loss function is defined as shown in (4):
where
,
, and
are the ground truth values of the six rigid transformation parameters, predicted transformed points, and ground truth transformed points, respectively. Moreover,
and
are the weights for the first loss and the number of points to be transformed, respectively. Each loss value is complementary to the other. If the first loss value is minimized and matches the ground truth value, the second loss value becomes zero. However, in the training process dealing with real data, the loss value rarely becomes zero. In the case of the first loss function, it is possible to have the same loss value, even if the values of each transformation parameter differ. Therefore, the second loss function was defined to train the coordinates between points to be smaller, even if the value of the first loss function was the same. In this study, the value of
was set to 10.
4. Discussion
Deep learning studies are also being conducted for the diagnosis and planning of dentofacial dysmorphosis [
21,
22,
23,
24]. However, most adhere to the classic method using points, planes, and angles [
21,
22,
23]. Among these, Xiao et al. estimated reference bony-shape models for orthognathic surgical planning using 3D point-cloud deep learning [
24]. In contrast to the previous study predicting the displacement of a point using artificially generated training data, the present method predicted the transformation matrix from actual surgery data. Because of this difference, the method of training data generation was completely different, and actual pre- and postoperative surgery data were considered. To predict postoperative surgery results, the present method has two main networks: the segmentation network that divides the skull into six main parts, and the alignment network for predicting the transformation parameters of each. The efficacy of the present method was confirmed by applying it to actual patients’ surgery data.
As a result of this study, the mean absolute error of transformed points showed a value smaller than 2.34 mm in x (transverse), y (anterior–posterior), and z (vertical) (
Table 5). It was suggested that accurate prediction is possible in maxilla (part 2), mandible (part 3), and chin (part 4).
Figure 4 shows the case of randomly selecting two patients. In each, the left represents preoperative and the right represents postoperative. The actual patient’s condition was expressed in transparent green. Then, colors were assigned to parts 2 (red), 3 (red violet), and 4 (purple), respectively. As a result, as shown in
Figure 4, it was confirmed that parts 2, 3, and 4 moved very similarly to the actual post-operative.
For this study, we used only postoperative CT data from two surgeons. In addition, all surgeries were performed through the same diagnostic and surgical methods. As is well known, the preferred diagnosis and surgical method differs, depending on the surgeon. Therefore, if the data of several surgeons were collected, the number of samples could be increased, but it would have been more difficult for DNN to accurately predict the surgical outcome. First of all, this study confirmed that DNN can accurately predict 3D postoperative results. We think that if we can collect data from several surgeons and conduct research in the future, we will be able to get better results.
Despite hard tissue changes being important in orthognathic surgery, especially for surgery planning, soft tissues are equally important to assess the final results of the surgery. The model in this study only predicted hard tissue changes, not soft tissue changes. On the other hand, recently Ma et al. introduced a learning-based framework to speed up the simulation of postoperative facial appearances [
28]. Specifically, they introduced a facial shape change prediction network (FSC-Net) to learn the nonlinear mapping from bony shape changes to facial shape changes. Combining the study of Ma et al. with ours of this study, it is expected to create a model that can be easily used in actual clinical practice.
5. Conclusions
Even for an experienced oral and maxillofacial surgeon, it is almost impossible to intuitively predict the postoperative results of orthognathic surgery. Therefore, we have thus far relied entirely on classical analysis based on points, planes, and angles. This is time consuming. In addition, it is also greatly influenced by the skill level of the practitioner. Even studies using 3D DNN were mostly focused on points, planes, and angles. We found in this study that DNN can predict postoperative results of orthognathic surgery without relying on reference points, planes, and angles. In addition, the results of this study were accurate enough for immediate clinical application. From this study, postoperative results can now be easily predicted by simply entering the point cloud data of CT.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}