
Application of Machine Learning to Improve Appropriateness of Treatment in an Orthopaedic Setting of Personalized Medicine

Abstract
:1. Introduction
Related Works
2. Methods
2.1. Classification Method
2.2. Hyper-Parameter Optimization and Cross-Validation Strategy
2.3. Class Imbalance
2.4. Evaluation Metrics
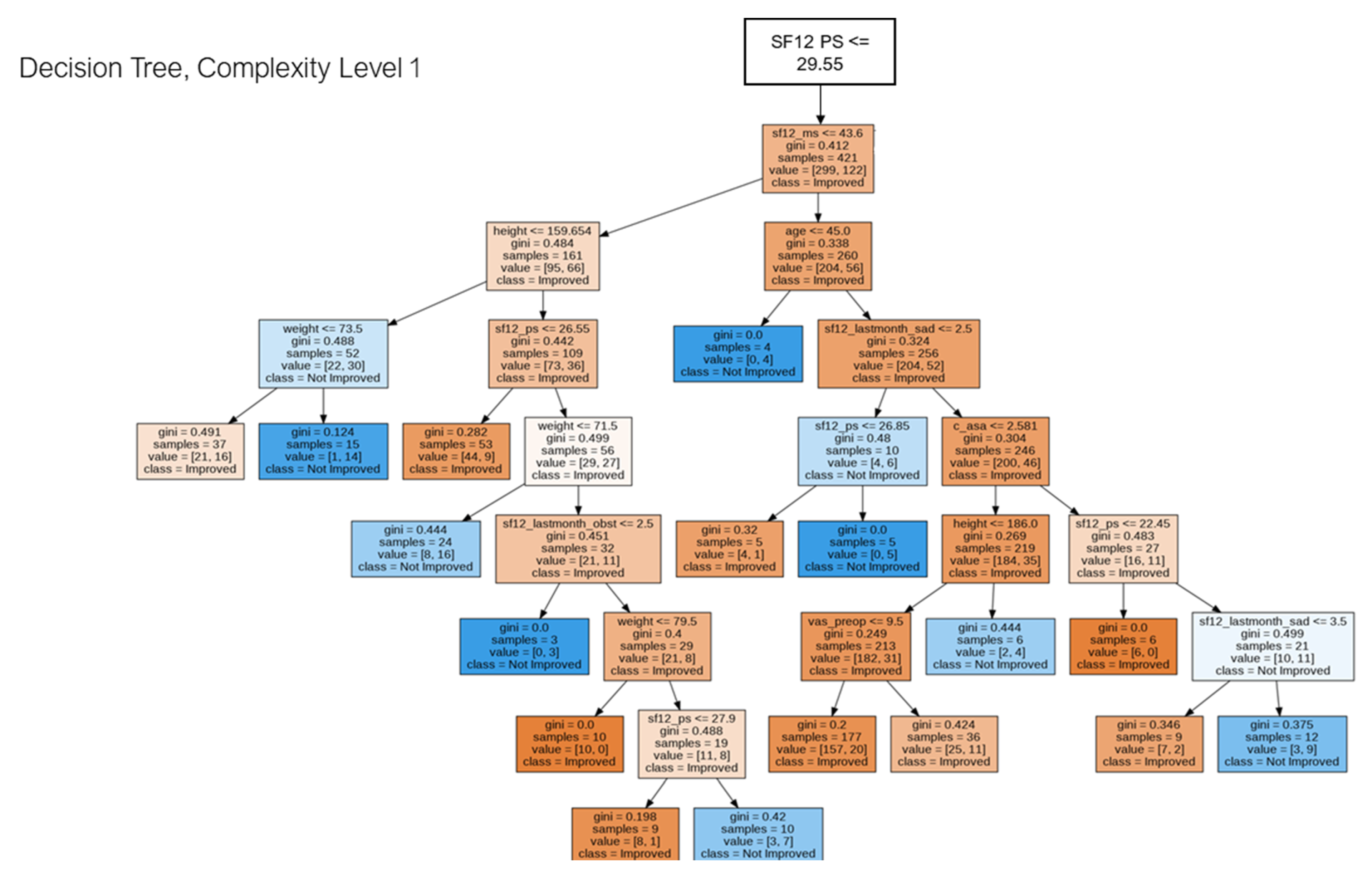
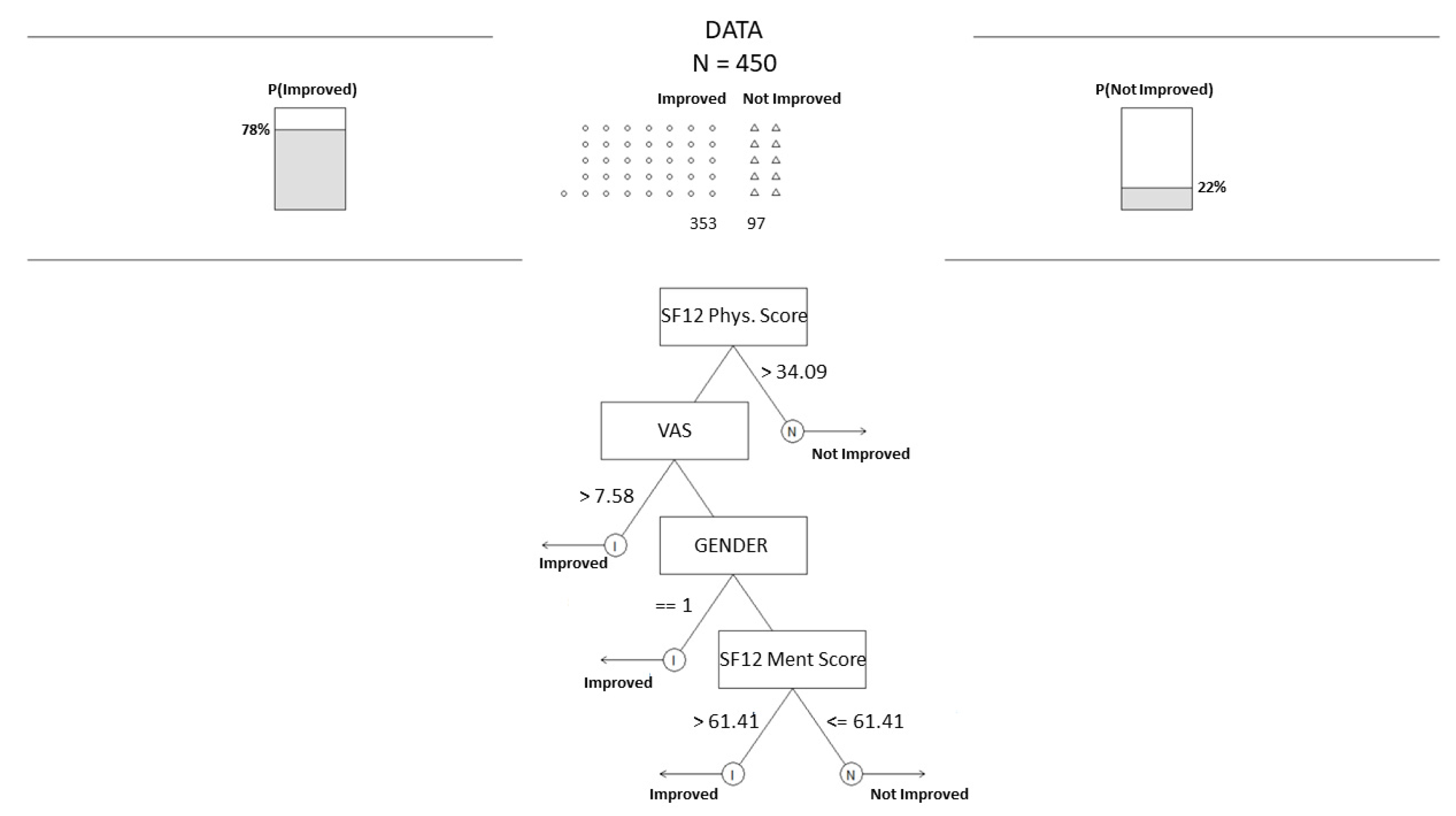
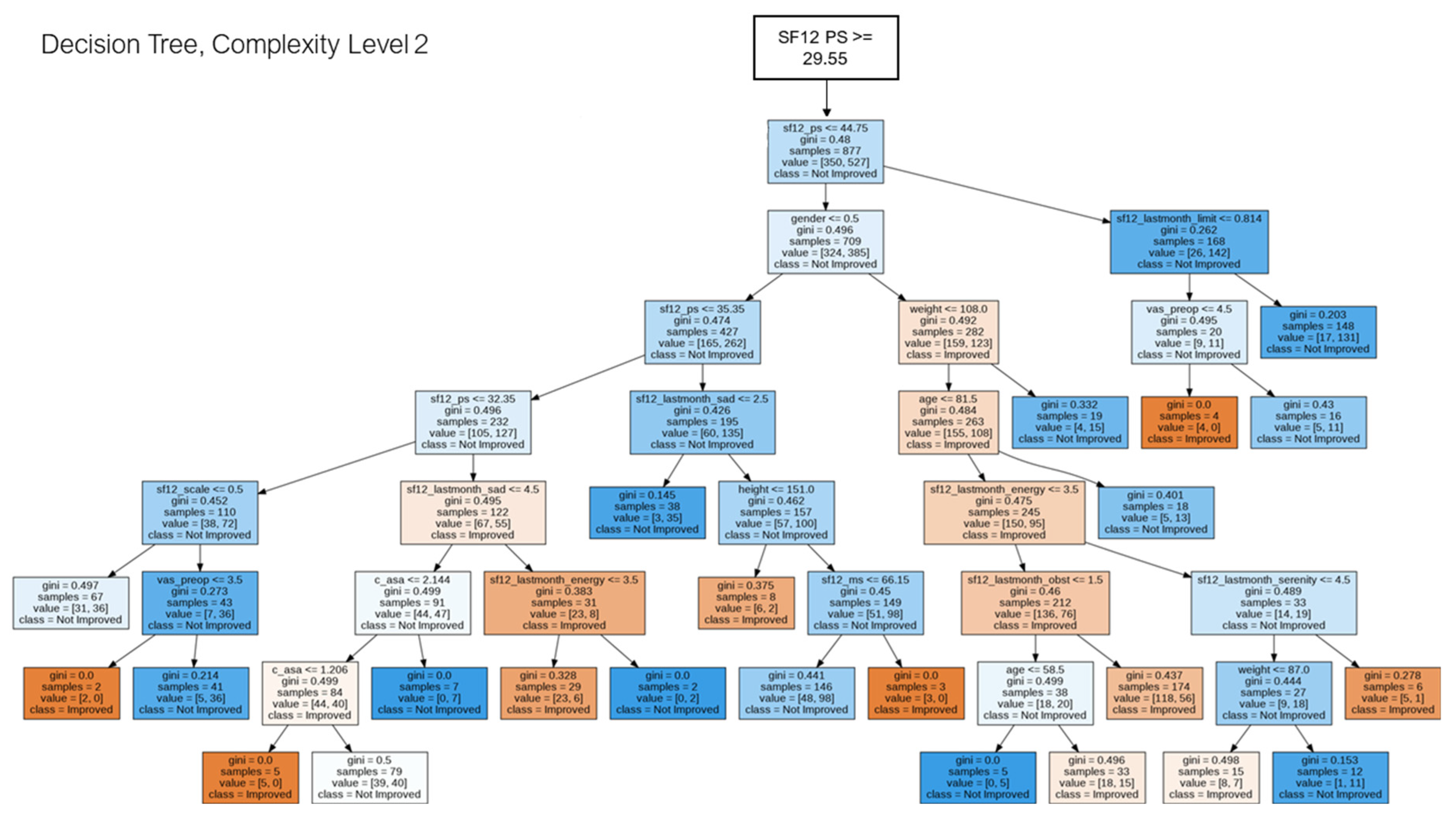
2.5. Decision Tree for Pattern Analysis & Decision Support
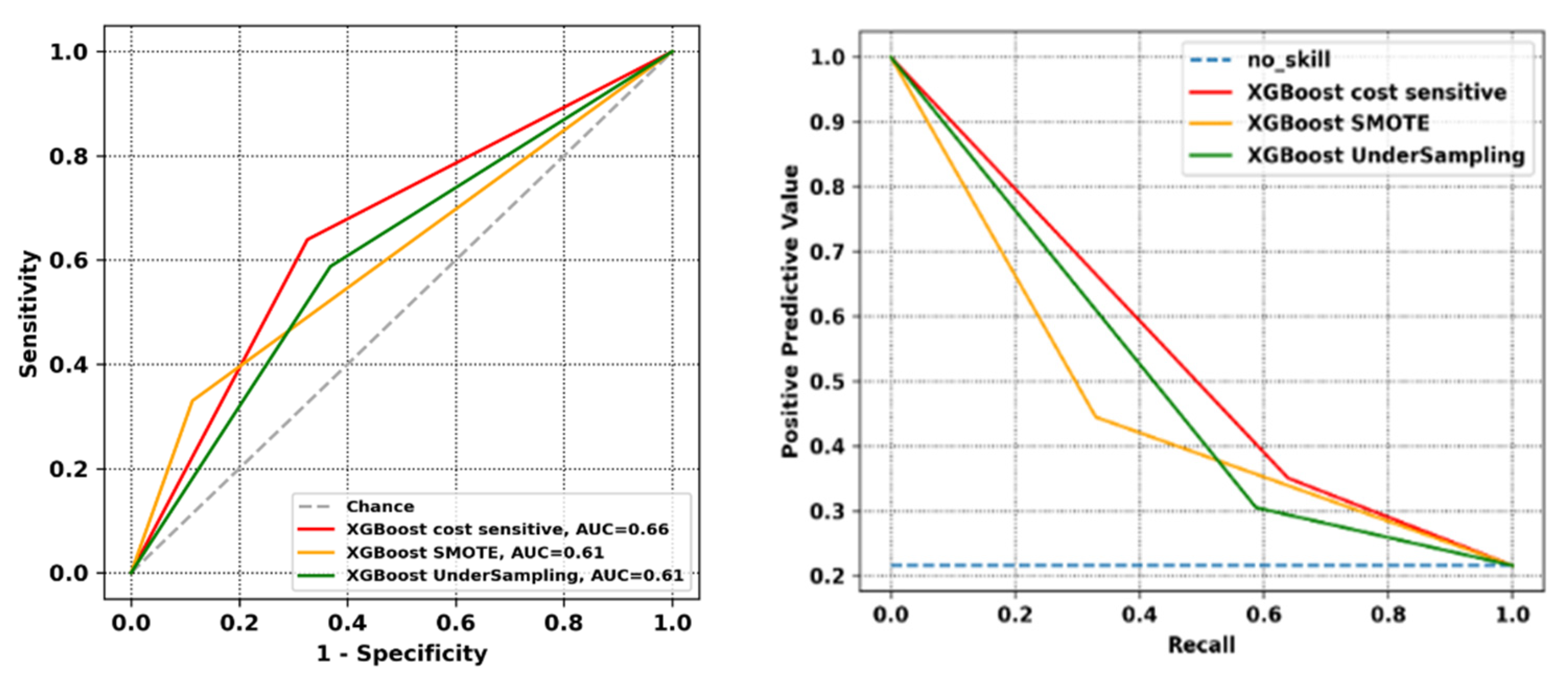
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Kadi, H.; Rebbah, M.; Meftah, B.; Lézoray, O. Medical decision-making based on the exploration of a personalized medicine dataset. Inform. Med. Unlocked 2021, 23, 100561. [Google Scholar] [CrossRef]
- El-Alti, L.; Sandman, L.; Munthe, C. Person Centered Care and Personalized Medicine: Irreconcilable Opposites or Potential Companions? Health Care Anal. 2019, 27, 45–59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moor, C.C.; Heukels, P.; Kool, M.; Wijsenbeek, M.S. Integrating patient perspectives into personalized medicine in idiopathic pulmonary fibrosis. Front. Med. 2017, 4, 226. [Google Scholar] [CrossRef] [Green Version]
- Llamocca, P.; López, V.; Santos, M. Personalized characterization of emotional states in patients with bipolar disorder. Mathematics 2021, 9, 1174. [Google Scholar] [CrossRef]
- Katakam, A.; Karhade, A.V.; Collins, A.; Shin, D.; Bragdon, C.; Chen, A.F.; Melnic, C.M.; Schwab, J.H.; Bedair, H.S. Development of machine learning algorithms to predict achievement of minimal clinically important difference for the KOOS-PS following total knee arthroplasty. J. Orthop. Res. 2021, 40, 808–815. [Google Scholar] [CrossRef] [PubMed]
- Weszl, M.; Rencz, F.; Brodszky, V. Is the trend of increasing use of patient-reported outcome measures in medical device studies the sign of shift towards value-based purchasing in Europe? Eur. J. Health Econ. 2019, 20, 133–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davidson, G.H.; Haukoos, J.S.; Feldman, L.S. Practical guide to assessment of patient-reported outcomes. JAMA Surg. 2020, 155, 432–433. [Google Scholar] [CrossRef]
- Goh, G.S.; Tarabichi, S.; Baker, C.M.; Qadiri, Q.S.; Austin, M.S. Should We Aim to Help Patients “Feel Better” or “Feel Good” After Total Hip Arthroplasty? Determining Factors Affecting the Achievement of the Minimal Clinically Important Difference and Patient Acceptable Symptom State. J. Arthroplast. 2022, S0883-5403(22)00754-9. [Google Scholar] [CrossRef]
- Bernstein, D.N.; Nwachukwu, B.U.; Bozic, K.J. Value-based Health Care: Moving Beyond “Minimum Clinically Important Difference” to a Tiered System of Evaluating Successful Clinical Outcomes. Clin. Orthop. Relat. Res. 2019, 477, 945–947. [Google Scholar] [CrossRef]
- Malec, J.F.; Ketchum, J.M. A standard method for determining the minimal clinically important difference for rehabilitation measures. Arch. Phys. Med. Rehabil. 2020, 101, 1090–1094. [Google Scholar] [CrossRef] [PubMed]
- Çelik, D.; Çoban, Ö.; Kılıçoğlu, Ö. Minimal clinically important difference of commonly used hip-, knee-, foot-, and ankle-specific questionnaires: A systematic review. J. Clin. Epidemiol. 2019, 113, 44–57. [Google Scholar] [CrossRef] [PubMed]
- Fontana, M.A.; Lyman, S.; Sarker, G.K.; Padgett, D.E.; MacLean, C.H. Can Machine Learning Algorithms Predict Which Patients Will Achieve Minimally Clinically Important Differences From Total Joint Arthroplasty? Clin. Orthop. Relat. Res. 2019, 477, 1267–1279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keurentjes, J.C.; Van Tol, F.R.; Fiocco, M.; Schoones, J.W.; Nelissen, R.G. Minimal clinically important differences in health-related quality of life after total hip or knee replacement: A systematic review. Bone Jt. Res. 2012, 1, 71–77. [Google Scholar] [CrossRef]
- Holzinger, A. Trends in Interactive Knowledge Discovery for Personalized Medicine: Cognitive Science meets Machine Learning. IEEE Intell. Inform. Bull. 2014, 15, 6–14. [Google Scholar]
- van der Willik, E.M.; Terwee, C.B.; Bos, W.J.W.; Hemmelder, M.H.; Jager, K.J.; Zoccali, C.; Dekker, F.W.; Meuleman, Y. Patient-reported outcome measures (PROMs): Making sense of individual PROM scores and changes in PROM scores over time. Nephrology 2021, 26, 391–399. [Google Scholar] [CrossRef] [PubMed]
- Gigerenzer, G.; Goldstein, D.G. Reasoning the fast and frugal way: Models of bounded rationality. Psychol. Rev. 1996, 103, 650–669. [Google Scholar] [CrossRef] [Green Version]
- Khan, O.; Badhiwala, J.H.; Grasso, G.; Fehlings, M.G. Use of machine learning and artificial intelligence to drive personalized medicine approaches for spine care. World Neurosurg. 2020, 140, 512–518. [Google Scholar] [CrossRef]
- Staartjes, V.E.; de Wispelaere, M.P.; Vandertop, W.P.; Schröder, M.L. Deep learning-based preoperative predictive analytics for patient-reported outcomes following lumbar discectomy: Feasibility of center-specific modeling. Spine J. 2019, 19, 853–861. [Google Scholar] [CrossRef]
- Pedersen, C.F.; Andersen, M.Ø.; Carreon, L.Y.; Eiskjær, S. Applied machine learning for spine surgeons: Predicting outcome for patients undergoing treatment for lumbar disc herniation using PRO data. Global Spine J. 2022, 12, 866–876. [Google Scholar] [CrossRef]
- Zhang, S.; Lau, B.P.H.; Ng, Y.H.; Wang, X.; Chua, W. Machine learning algorithms do not outperform preoperative thresholds in predicting clinically meaningful improvements after total knee arthroplasty. Knee Surg. Sport. Traumatol. Arthrosc. 2022, 30, 2624–2630. [Google Scholar] [CrossRef] [PubMed]
- Kunze, K.N.; Karhade, A.V.; Sadauskas, A.J.; Schwab, J.H.; Levine, B.R. Development of machine learning algorithms to predict clinically meaningful improvement for the patient-reported health state after total hip arthroplasty. J. Arthroplast. 2020, 35, 2119–2123. [Google Scholar] [CrossRef] [PubMed]
- Huber, M.; Kurz, C.; Leidl, R. Predicting patient-reported outcomes following hip and knee replacement surgery using supervised machine learning. BMC Med. Inform. Decis. Mak. 2019, 19, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harris, A.H.; Kuo, A.C.; Bowe, T.R.; Manfredi, L.; Lalani, N.F.; Giori, N.J. Can Machine Learning Methods Produce Accurate and Easy-to-Use Preoperative Prediction Models of One-Year Improvements in Pain and Functioning After Knee Arthroplasty? J. Arthroplast. 2020, 36, 112–117. [Google Scholar] [CrossRef]
- Song, Y.-Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, California, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2020, 54, 1937–1967. [Google Scholar] [CrossRef]
- Mardini, M.; Bai, C.; Wanigatunga, A.; Saldana, S.; Casanova, R.; Manini, T. Age Differences in Estimating Physical Activity by Wrist Accelerometry Using Machine Learning. Sensors 2021, 21, 3352. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Gribskov, M. IRESpy: An XGBoost model for prediction of internal ribosome entry sites. BMC Bioinform. 2019, 20, 409. [Google Scholar] [CrossRef] [PubMed]
- Ramraj, S.; Uzir, N.; Sunil, R.; Banerjee, S. Experimenting XGBoost algorithm for prediction and classification of different datasets. Int. J. Control. Theory Appl. 2016, 9, 651–662. [Google Scholar]
- Vaid, A.; Chan, L.; Chaudhary, K.; Jaladanki, S.K.; Paranjpe, I.; Russak, A.; Kia, A.; Timsina, P.; Levin, M.A.; He, J.C.; et al. Predictive Approaches for Acute Dialysis Requirement and Death in COVID-19. Clin. J. Am. Soc. Nephrol. 2021, 16, 1158–1168. [Google Scholar] [CrossRef]
- Hong, W.; Zhou, X.; Jin, S.; Lu, Y.; Pan, J.; Lin, Q.; Yang, S.; Xu, T.; Basharat, Z.; Zippi, M.; et al. A Comparison of XGBoost, Random Forest, and Nomograph for the Prediction of Disease Severity in Patients With COVID-19 Pneumonia: Implications of Cytokine and Immune Cell Profile. Front. Cell. Infect. Microbiol. 2022, 12, 819267. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Zhang, X. Research on orthopedic auxiliary classification and prediction model based on XGBoost algorithm. Neural Comput. Appl. 2019, 32, 1971–1979. [Google Scholar] [CrossRef]
- Bugarin, A.; Shah, A.A.; Devana, S.; Lee, C.; SooHoo, N.F. Development of a Machine Learning Algorithm for Prediction of Complications after Ankle Arthrodesis. Foot Ankle Orthop. 2022, 7, 2473011421S00122. [Google Scholar] [CrossRef]
- Copay, A.G.; Subach, B.R.; Glassman, S.D.; Polly, D.W., Jr.; Schuler, T.C. Understanding the minimum clinically important difference: A review of concepts and methods. Spine J. 2007, 7, 541–546. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Humbert-Vidan, L.; Patel, V.; Oksuz, I.; King, A.P.; Urbano, T.G. Comparison of machine learning methods for prediction of osteoradionecrosis incidence in patients with head and neck cancer. Br. J. Radiol. 2021, 94, 20200026. [Google Scholar] [CrossRef] [PubMed]
- Wainer, J.; Cawley, G. Nested cross-validation when selecting classifiers is overzealous for most practical applications. Expert Syst. Appl. 2021, 182, 115222. [Google Scholar] [CrossRef]
- Rajpal, H.; Sas, M.; Joakim, R.; Lockwood, C.; Peters, N.S.; Falkenberg, M. Interpretable XGBoost Based Classification of 12-lead ECGs Applying Information Theory Measures From Neuroscience. In Proceedings of the 2020 Computing in Cardiology, Rimini, Italy, 13–16 September 2020; Volume 47. [Google Scholar] [CrossRef]
- Tasci, E.; Zhuge, Y.; Camphausen, K.; Krauze, A.V. Bias and Class Imbalance in Oncologic Data—Towards Inclusive and Transferrable AI in Large Scale Oncology Data Sets. Cancers 2022, 14, 2897. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kashirina, I.; Firyulina, M.A. Building models for predicting mortality after myocardial infarction in conditions of unbalanced classes, including the influence of weather conditions. CEUR Workshop Proc. 2020, 2790, 188–197. [Google Scholar]
- Nguyen, N.N.; Duong, A.T. Comparison of Two Main Approaches for Handling Imbalanced Data in Churn Prediction Problem. J. Adv. Inf. Technol. 2021, 12, 29–35. [Google Scholar] [CrossRef]
- Akarte, M.M.; Hemachandra, N. Predictive maintenance of air pressure system using boosting trees: A machine learning approach. In Proceedings of the ORSI, Mumbai, India, 16–19 December 2018. [Google Scholar]
- Prasad, A.; Chokshi, S.; Khan, S. Predictive programmatic re-targeting to improve website conversion rates. J. Phys. Conf. Ser. 2021, 1714, 012027. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. Performance analysis of cost-sensitive learning methods with application to imbalanced medical data. Inform. Med. Unlocked 2021, 25, 100690. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Keilwagen, J.; Grosse, I.; Grau, J. Area under Precision-Recall Curves for Weighted and Unweighted Data. PLoS ONE 2014, 9, e92209. [Google Scholar] [CrossRef] [PubMed]
- Qi, Q.; Luo, Y.; Xu, Z. Stochastic optimization of areas under precision-recall curves with provable convergence. Adv. Neural Inf. Process. Syst. 2021, 34, 1752–1765. [Google Scholar]
- Cabitza, F.; Campagner, A.; Famiglini, L. Global Interpretable Calibration Index, a New Metric to Estimate Machine Learning Models’ Calibration. In International Cross-Domain Conference for Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2022; pp. 82–99. [Google Scholar]
- Tajgardoon, M.; Cooper, G.F.; King, A.J. Modeling physician variability to prioritize relevant medical record information. JAMIA Open 2020, 3, 602–610. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Suri, P.; Cui, Y.; Moore, J.H.; Ruth, K.; Stolzenberg-Solomon, R.; Lynch, S.M. A Rigorous Machine Learning Analysis Pipeline for Biomedical Binary Classification: Application in Pancreatic Cancer Nested Case-control Studies with Implications for Bias Assessments. arXiv 2020, arXiv:2008.12829. [Google Scholar]
- Hay, D.C. Data Model Patterns: Conventions of Thought; Dorset House: New York, NY, USA, 1996. [Google Scholar]
- Abidi, S.S.R. Knowledge management in healthcare: Towards ‘knowledge-driven’ decision-support services. Int. J. Med. Inform. 2001, 63, 5–18. [Google Scholar] [CrossRef] [Green Version]
- Wong, A.K.C.; Yang, W. Pattern discovery: A data driven approach to decision support. IEEE Trans. Syst. Man Cybern. 2003, 33, 114–124. [Google Scholar] [CrossRef]
- Wallace, B.C.; Small, K.; Brodley, C.E.; Trikalinos, T. Class imbalance, redux. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011. [Google Scholar]
- Zeng, X.; Martinez, T.R. Distribution-balanced stratified cross-validation for accuracy estimation. J. Exp. Theor. Artif. Intell. 2000, 12, 1–12. [Google Scholar] [CrossRef]
- Bamgbade, O.A.; Rutter, T.W.; Nafiu, O.O.; Dorje, P. Postoperative Complications in Obese and Nonobese Patients. World J. Surg. 2006, 31, 556–560. [Google Scholar] [CrossRef] [PubMed]
- Tjeertes, E.E.; Hoeks, S.S.; Beks, S.S.; Valentijn, T.T.; Hoofwijk, A.G.; Stolker, R.J.R. Obesity—A risk factor for postoperative complications in general surgery? BMC Anesthesiol. 2015, 15, 112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parratte, S.; Pesenti, S.; Argenson, J.-N. Obesity in orthopedics and trauma surgery. Orthop. Traumatol. Surg. Res. 2014, 100, S91–S97. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Williams, D.G.; Wischmeyer, P.E. Perioperative Nutrition Care of Orthopedic Surgery Patient. Tech. Orthop. 2019, 35, 15–18. [Google Scholar] [CrossRef]
- MacEachern, S.J.; Forkert, N.D. Machine learning for precision medicine. Genome 2021, 64, 416–425. [Google Scholar] [CrossRef] [PubMed]
- Cabitza, F.; Campagner, A.; Del Zotti, F.; Sternini, A.R.A.F. All you need is higher accuracy? On the quest for minimum acceptable accuracy for medical artificial intelligence. In Proceedings of the e-Health Procedings of the 12th International Conference on e-Health, Online, 21–23 July 2020; pp. 159–166. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learning Rate | Min. Child. Weight | Max Depth | Gamma | Colsample Bytree | N. Estimators | |
|---|---|---|---|---|---|---|
| Search Space | [0.001, 0.01] | [1, 10] | [3, 20] | [0.01, 1] | [0.01, 1] | [3, 150] |
| Max Depth | Min. Samples Leaf | Min. Samples Split | Max Leaf Nodes |
|---|---|---|---|
| 8 | 2 | 2 | 40 |
| HA (n = 3610) Number (%) | KA (n = 2911) Number (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| Unilateral primary | 3218 (89.14) | 2659 (91.34) | ||||||
| Unilateral revision | 349 (9.67) | 213 (7.32) | ||||||
| Bilateral | 43 (1.19) | 39 (1.34) | ||||||
| Gender | ||||||||
| Female | 1996 (55.29) | 1964 (67.5) | ||||||
| Male | 1614 (44.71) | 947 (32.5) | ||||||
| ASA score | ||||||||
| 1 | 390 (10.83) | 131 (4.52) | ||||||
| 2 | 2326 (64.58) | 1854 (63.93) | ||||||
| 3 | 267 (7.41) | 217 (7.48) | ||||||
| 4 | 1 (0.03) | - | ||||||
| Missing | 618 (17.16) | 698 (24.07) | ||||||
| Mean | Sd | Min | Max | Mean | Sd | Min | Max | |
| Age (years) | 67.88 | 11.97 | 14 | 97 | 71.08 | 8.95 | 33 | 93 |
| Length of stay (days) | 4.86 | 2.09 | 0 | 32 | 4.72 | 2.05 | 0 | 35 |
| Missing Values (%) | |
|---|---|
| Gender | 0 |
| Age | 0 |
| ASA score | 12.21 |
| VAS total_PreOp | 0.97 |
| SF12 Physical ScorePreOp | 0 |
| SF12 Mental Score_PreOp | 0 |
| BMI height PreOp | 2.13 |
| BMI weight PreOp | 2.13 |
| SF12 autoevaluation health answer PreOp | 0.17 |
| SF12 Score answer PreOp | 0.17 |
| SF12 lastmonth resa answer PreOp | 0.17 |
| SF12 lastmonth limite answer PreOp | 0.17 |
| SF12 lastmonth emo answer PreOp | 0.17 |
| SF12 lastmonth ostacolo answer PreOp | 0.17 |
| SF12 lastmonth sereno answer PreOp | 0.17 |
| SF12 lastmonth energia answer PreOp | 0.17 |
| SF12 lastmonth triste answer PreOp | 0.17 |
| SF12 lastmonth sociale answer PreOp | 0.17 |
| Target phy | 0 |
| Operating zone | 0 |
| Bilateral Hip | 0 |
| Bilateral knee | 0 |
| Learning Rate | Min. Child. Weight | Max Depth | Gamma | Colsample_bytree | N. Estimators | |
|---|---|---|---|---|---|---|
| XGBoost—Cost sensitive | 0.171 | 9 | 3 | 0.41 | 0.91 | 33 |
| XGBoost—SMOTE | 0.051 | 8 | 3 | 0.31 | 0.51 | 33 |
| XGBoost—UnderSampling | 0.151 | 5 | 3 | 0.51 | 0.21 | 63 |
| HC Balanced Accuracy | HC Balanced Sensitivity | HC Balanced F1 Score | HC Balanced PPV | HC AUROC | HC AUPRC | HC 1-ECE | Coverage | |
|---|---|---|---|---|---|---|---|---|
| XGBoost—Cost sensitive | 0.79 [0.71, 0.87] | 0.84 [0.77, 0.91] | 0.84 [0.77, 0.91] | 0.84 [0.77, 0.91] | 0.79 [0.71, 0.87] | 0.72 [0.63, 0.81] | 0.93 [0.88, 0.98] | 22% |
| XGBoost—SMOTE | 0.82 [0.71, 0.93] | 0.91 [0.83, 0.99] | 0.91 [0.83, 0.99] | 0.91 [0.83, 0.99] | 0.82 [0.71, 0.93] | 0.79 [0.67, 0.91] | 0.86 [0.76, 0.96] | 10% |
| XGBoost—UnderSampling | 0.76 [0.68, 0.84] | 0.75 [0.67, 0.83] | 0.76 [0.68, 0.84] | 0.80 [0.73, 0.87] | 0.76 [0.68, 0.84] | 0.70 [0.62, 0.78] | 0.92 [0.87, 0.97] | 25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Milella, F.; Famiglini, L.; Banfi, G.; Cabitza, F. Application of Machine Learning to Improve Appropriateness of Treatment in an Orthopaedic Setting of Personalized Medicine. J. Pers. Med. 2022, 12, 1706. https://doi.org/10.3390/jpm12101706
Milella F, Famiglini L, Banfi G, Cabitza F. Application of Machine Learning to Improve Appropriateness of Treatment in an Orthopaedic Setting of Personalized Medicine. Journal of Personalized Medicine. 2022; 12(10):1706. https://doi.org/10.3390/jpm12101706
Chicago/Turabian StyleMilella, Frida, Lorenzo Famiglini, Giuseppe Banfi, and Federico Cabitza. 2022. "Application of Machine Learning to Improve Appropriateness of Treatment in an Orthopaedic Setting of Personalized Medicine" Journal of Personalized Medicine 12, no. 10: 1706. https://doi.org/10.3390/jpm12101706