
Body Mass Index and Birth Weight Improve Polygenic Risk Score for Type 2 Diabetes



Abstract
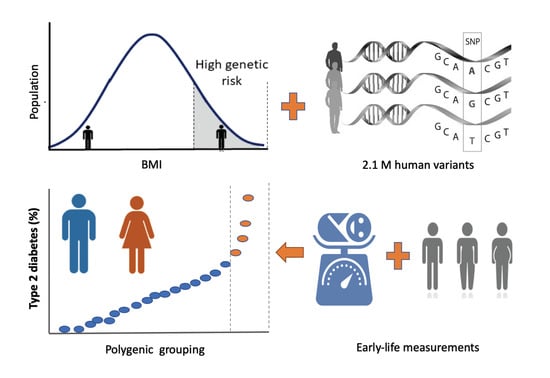
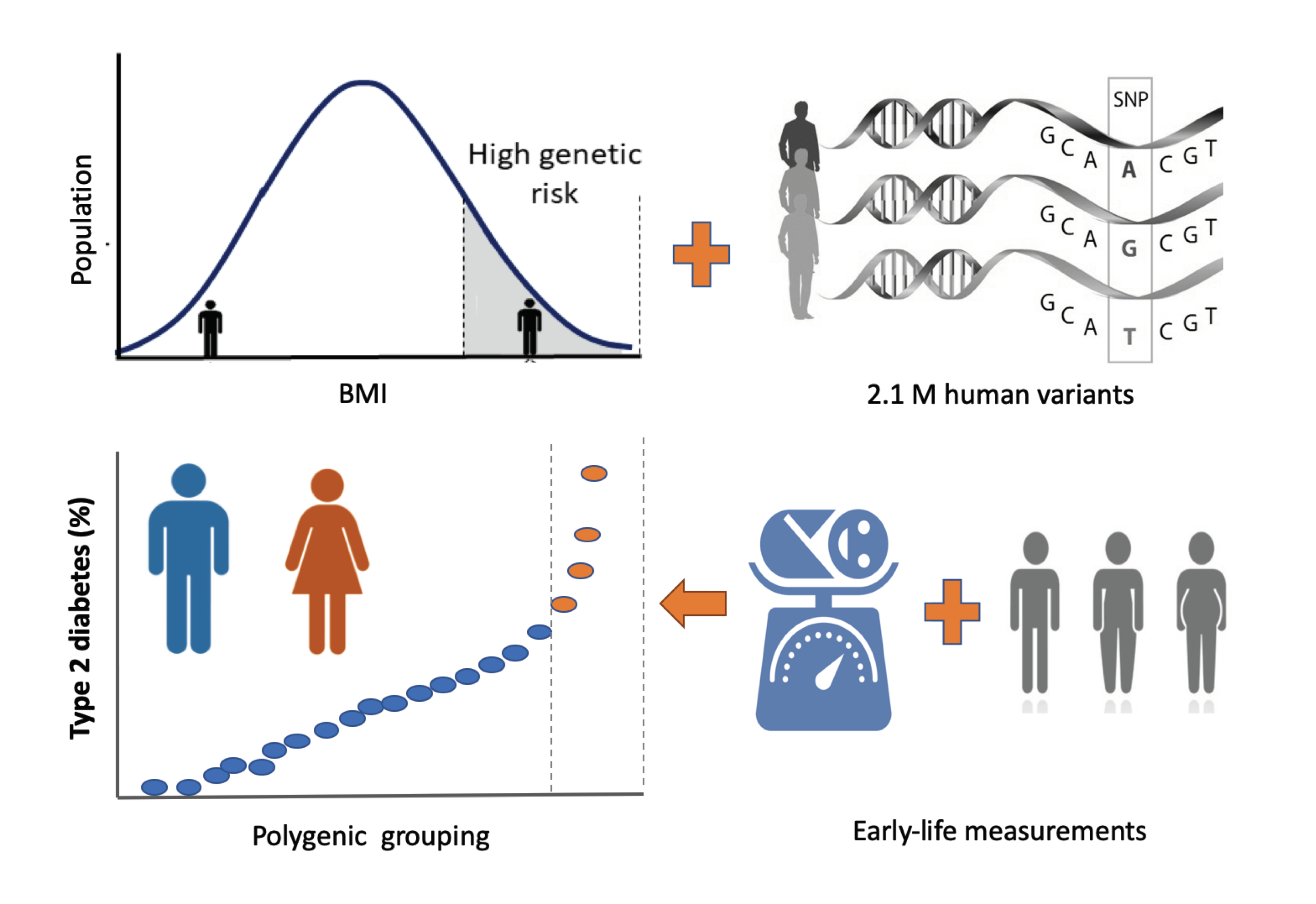
:
1. Introduction
2. Methods
2.1. UK Biobank (UKB) Data
2.2. Polygenic Risk Score Calculation
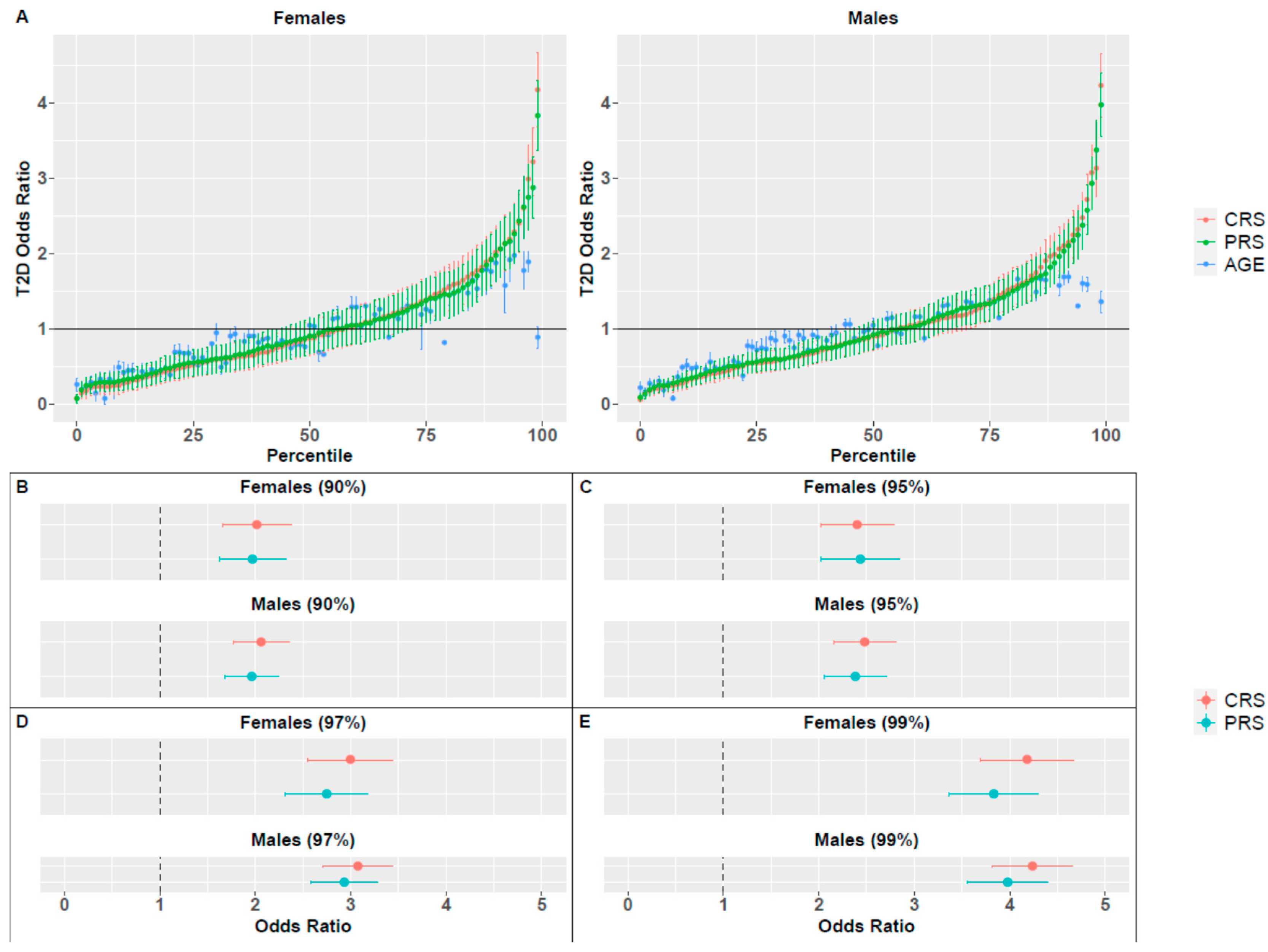
2.3. Composite Risk Score
2.4. Evaluation of the Results
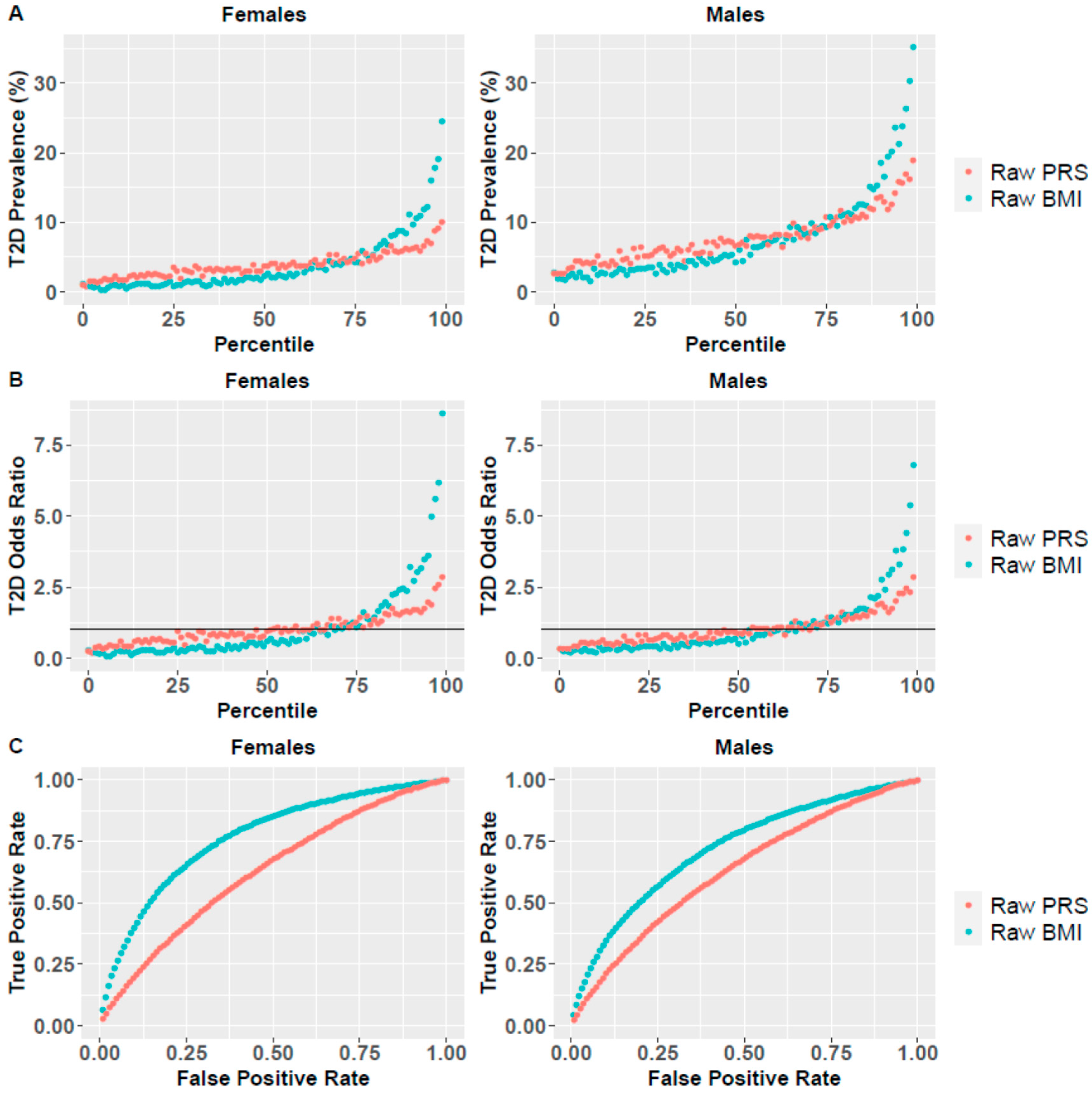
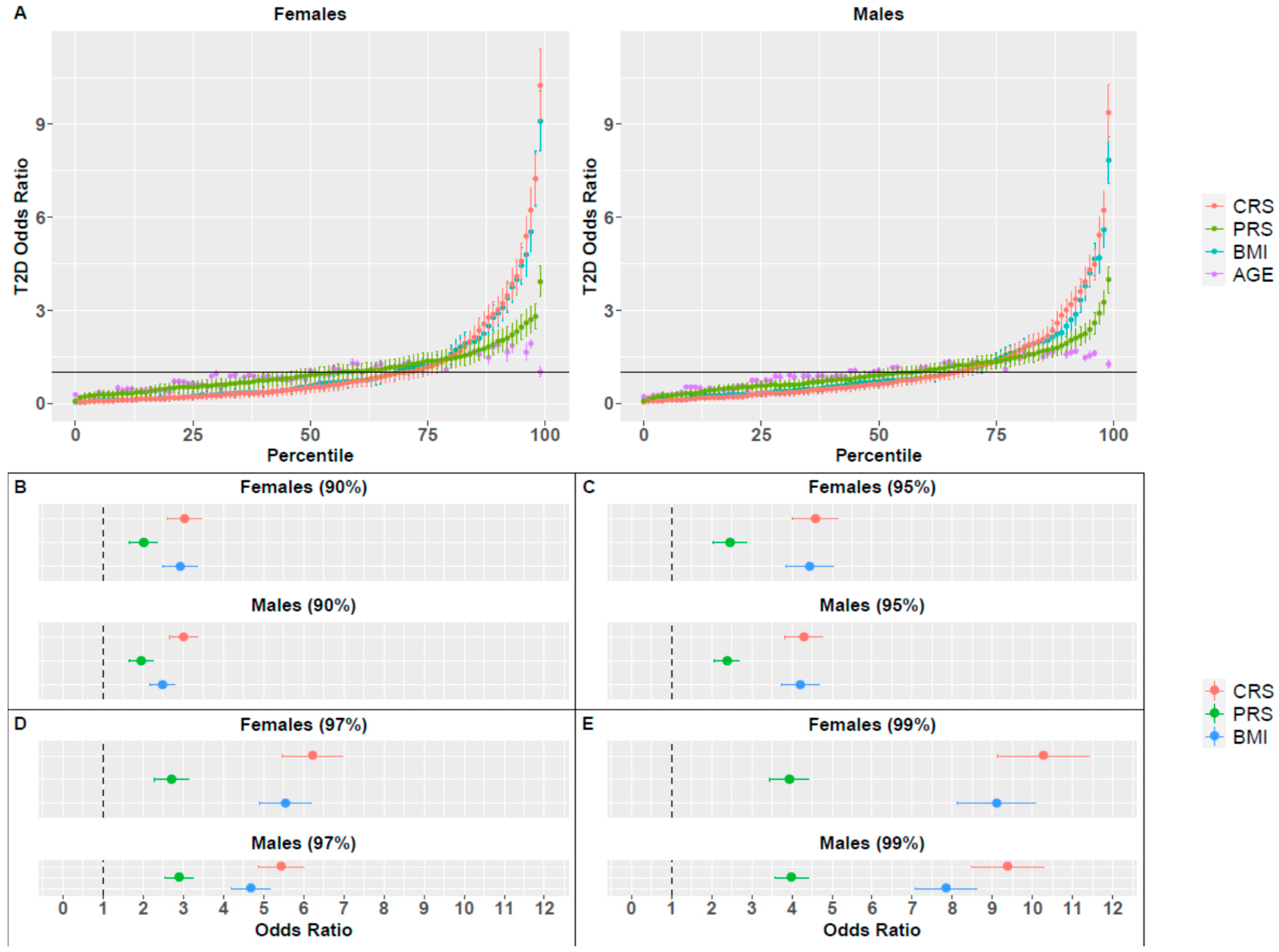
3. Results
3.1. PRS and BMI
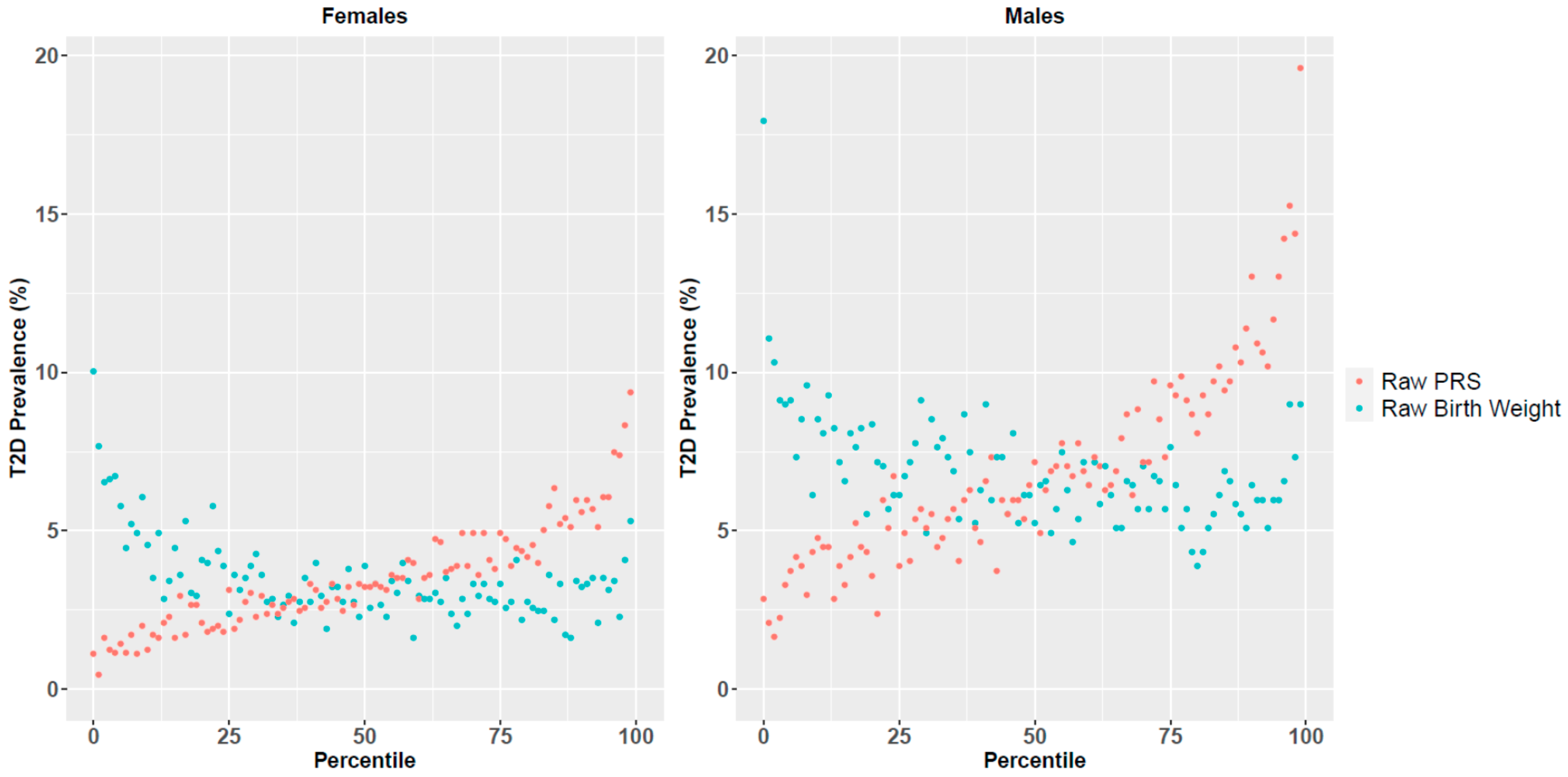
3.2. PRS and Birth Weight
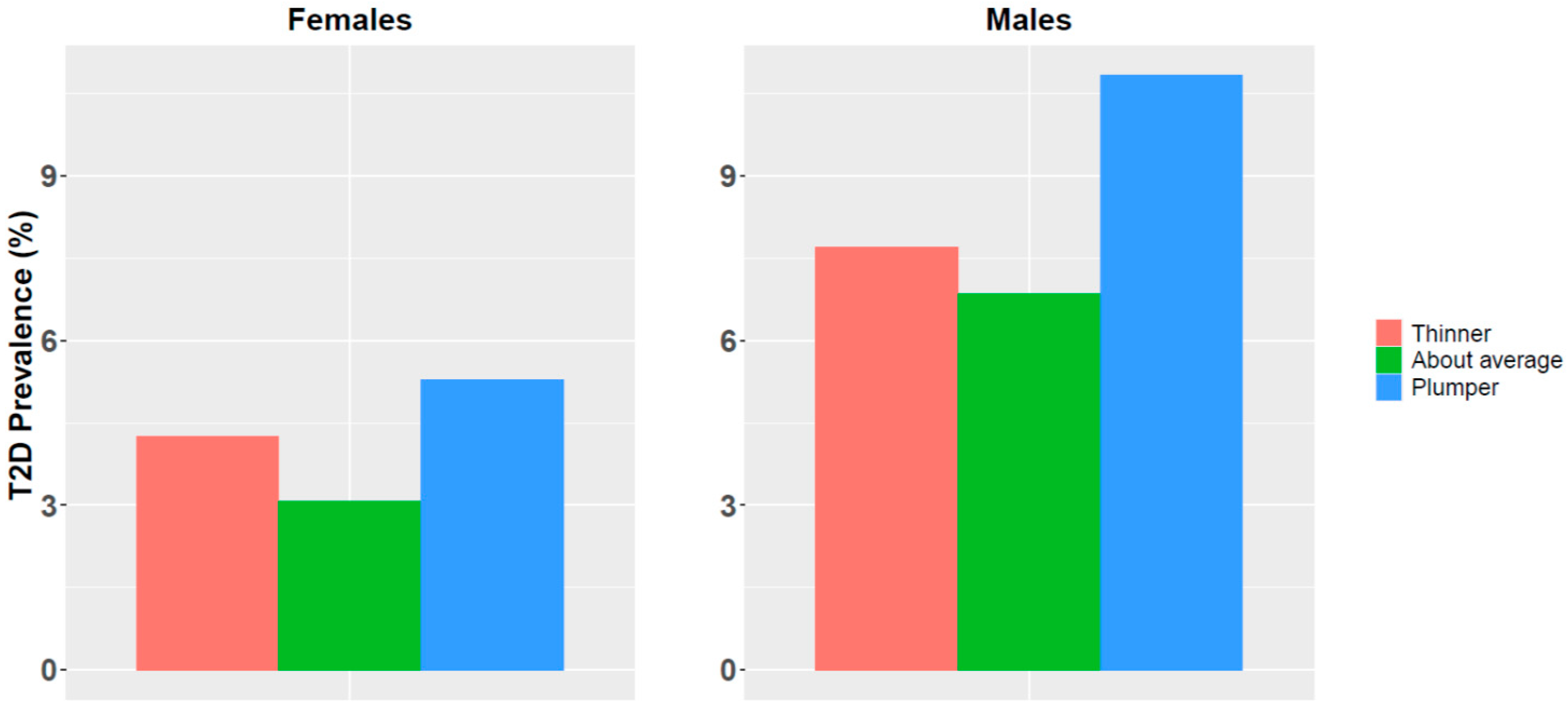
3.3. PRS and Body Size at Age Ten
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Torkamani, A.; Wineinger, N.E.; Topol, E.J. The personal and clinical utility of polygenic risk scores. Nat. Rev. Genet. 2018, 19, 581–590. [Google Scholar] [CrossRef] [PubMed]
- Hirschhorn, J.N.; Daly, M.J. Genome-wide association studies for common diseases and complex traits. Nat. Rev. Genet. 2005, 6, 95–108. [Google Scholar] [CrossRef]
- Lander, E.S. Initial impact of the sequencing of the human genome. Nature 2011, 470, 187–197. [Google Scholar] [CrossRef] [PubMed]
- Bush, W.S.; Moore, J.H. Chapter 11, Genome-Wide Association Studies. PLoS Comput. Biol. 2012, 8, e1002822. [Google Scholar] [CrossRef] [Green Version]
- Manolio, T.A.; Collins, F.S.; Cox, N.J.; Goldstein, D.B.; Hindorff, L.A.; Hunter, D.J.; McCarthy, M.I.; Ramos, E.M.; Cardon, L.R.; Chakravarti, A.; et al. Finding the missing heritability of complex diseases. Nature 2009, 461, 747–753. [Google Scholar] [CrossRef] [Green Version]
- Eichler, E.E.; Flint, J.; Gibson, G.; Kong, A.; Leal, S.M.; Moore, J.H.; Nadeau, J.H. Missing heritability and strategies for finding the underlying causes of complex disease. Nat. Rev. Genet. 2010, 11, 446–450. [Google Scholar] [CrossRef] [Green Version]
- Zuk, O.; Hechter, E.; Sunyaev, S.R.; Lander, E.S. The mystery of missing heritability: Genetic interactions create phantom heritability. Proc. Natl. Acad. Sci. USA 2012, 109, 1193–1198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Benyamin, B.; McEvoy, B.P.; Gordon, S.; Henders, A.K.; Nyholt, D.R.; Madden, P.A.; Heath, A.C.; Martin, N.G.; Montgomery, G.W.; et al. Common SNPs explain a large proportion of the heritability for human height. Nat. Genet. 2010, 42, 565–569. [Google Scholar] [CrossRef] [Green Version]
- Boyle, E.A.; Li, Y.I.; Pritchard, J.K. An Expanded View of Complex Traits: From Polygenic to Omnigenic. Cell 2017, 169, 1177–1186. [Google Scholar] [CrossRef] [Green Version]
- Chatterjee, N.; Shi, J.; García-Closas, M. Developing and evaluating polygenic risk prediction models for stratified disease prevention. Nat. Rev. Genet. 2016, 17, 392–406. [Google Scholar] [CrossRef]
- Inouye, M.; Abraham, G.; Nelson, C.P.; Wood, A.M.; Sweeting, M.J.; Dudbridge, F.; Lai, F.Y.; Kaptoge, S.; Brozynska, M.; Wang, T.; et al. Genomic Risk Prediction of Coronary Artery Disease in 480,000 Adults: Implications for Primary Prevention. J. Am. Coll. Cardiol. 2018, 72, 1883–1893. [Google Scholar] [CrossRef]
- Lambert, S.A.; Abraham, G.; Inouye, M. Towards clinical utility of polygenic risk scores. Hum Mol Genet 2019, 28, R133–R142. [Google Scholar] [CrossRef] [PubMed]
- Lewis, C.M.; Vassos, E. Polygenic risk scores: From research tools to clinical instruments. Genome Med. 2020, 12, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Khera, A.V.; Chaffin, M.; Aragam, K.G.; Haas, M.E.; Roselli, C.; Choi, S.H.; Natarajan, P.; Lander, E.S.; Lubitz, S.A.; Ellinor, P.T.; et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat. Genet. 2018, 50, 1219–1224. [Google Scholar] [CrossRef] [PubMed]
- Fahed, A.C.; Wang, M.; Homburger, J.R.; Patel, A.P.; Bick, A.G.; Neben, C.L.; Lai, C.; Brockman, D.; Philippakis, A.; Ellinor, P.T.; et al. Polygenic background modifies penetrance of monogenic variants for tier 1 genomic conditions. Nat. Commun. 2020, 11, 1–9. [Google Scholar] [CrossRef]
- Wang, W.Y.S.; Barratt, B.J.; Clayton, D.G.; Todd, J.A. Genome-wide association studies: Theoretical and practical concerns. Nat. Rev. Genet. 2005, 6, 109–118. [Google Scholar] [CrossRef]
- Khera, A.V.; Chaffin, M.; Wade, K.H.; Zahid, S.; Brancale, J.; Xia, R.; Distefano, M.; Senol-Cosar, O.; Haas, M.E.; Bick, A.; et al. Polygenic Prediction of Weight and Obesity Trajectories from Birth to Adulthood. Cell 2019, 177, 587–596. [Google Scholar] [CrossRef] [Green Version]
- Chan, J.M.; Rimm, E.B.; Colditz, G.A.; Stampfer, M.J.; Willett, W.C. Obesity, fat distribution, and weight gain as risk factors for clinical diabetes in men. Diabetes Care 1994, 17, 961–969. [Google Scholar] [CrossRef] [Green Version]
- Tirosh, A.; Shai, I.; Afek, A.; Dubnov-Raz, G.; Ayalon, N.; Gordon, B.; Derazne, E.; Tzur, D.; Shamis, A.; Vinker, S.; et al. Adolescent BMI Trajectory and Risk of Diabetes versus Coronary Disease. N. Engl. J. Med. 2011, 364, 1315–1325. [Google Scholar] [CrossRef] [Green Version]
- Warrington, N.M.; Beaumont, R.N.; Horikoshi, M.; Day, F.R.; Helgeland, Ø.; Laurin, C.; Bacelis, J.; Peng, S.; Hao, K.; Feenstra, B.; et al. Maternal and fetal genetic effects on birth weight and their relevance to cardio-metabolic risk factors. Nat. Genet. 2019, 51, 804–814. [Google Scholar] [CrossRef]
- Whincup, P.H.; Kaye, S.J.; Owen, C.G.; Huxley, R.; Cook, D.G.; Anazawa, S.; Barrett-Connor, E.; Bhargava, S.K.; Birgisdottir, B.E.; Carlsson, S.; et al. Birth weight and risk of type 2 diabetes a systematic review. JAMA J. Am. Med. Assoc. 2008, 300, 2886–2897. [Google Scholar]
- Zhao, H.; Song, A.; Zhang, Y.; Zhen, Y.; Song, G.; Ma, H. The association between birth weight and the risk of type 2 diabetes mellitus: A systematic review and meta-analysis. Endocr. J. 2018, 65, EJ18-0072. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Knop, M.R.; Geng, T.T.; Gorny, A.W.; Ding, R.; Li, C.; Ley, S.H.; Huang, T. Birth weight and risk of type 2 diabetes mellitus, cardiovascular disease, and hypertension in adults: A meta-analysis of 7 646 267 participants from 135 studies. J. Am. Heart Assoc. 2018, 7, e008870. [Google Scholar] [CrossRef] [Green Version]
- Mi, D.; Fang, H.; Zhao, Y.; Zhong, L. Birth weight and type 2 diabetes: A meta-analysis. Exp. Ther. Med. 2017, 14, 5313–5320. [Google Scholar] [CrossRef] [Green Version]
- Zimmermann, E.; Gamborg, M.; Sørensen, T.I.A.; Baker, J.L. Sex differences in the association between birth weight and adult type 2 diabetes. Diabetes 2015, 64, 4220–4225. [Google Scholar] [CrossRef] [Green Version]
- Bycroft, C.; Freeman, C.; Petkova, D.; Band, G.; Elliott, L.T.; Sharp, K.; Motyer, A.; Vukcevic, D.; Delaneau, O.; O’Connell, J.; et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 2018, 562, 203–209. [Google Scholar] [CrossRef] [Green Version]
- Kautzky-Willer, A.; Harreiter, J.; Pacini, G. Sex and gender differences in risk, pathophysiology and complications of type 2 diabetes mellitus. Endocr. Rev. 2016, 37, 278–316. [Google Scholar] [CrossRef] [Green Version]
- Huebschmann, A.G.; Huxley, R.R.; Kohrt, W.M.; Zeitler, P.; Regensteiner, J.G.; Reusch, J.E.B. Sex differences in the burden of type 2 diabetes and cardiovascular risk across the life course. Diabetologia 2019, 62, 1761–1772. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geng, T.; Smith, C.E.; Li, C.; Huang, T. Childhood BMI and Adult Type 2 Diabetes, Coronary Artery Diseases, Chronic Kidney Disease, and Cardiometabolic Traits: A Mendelian Randomization Analysis. Diabetes Care 2018, 41, 1089–1096. [Google Scholar] [CrossRef] [Green Version]
- Dong, S.S.; Zhang, K.; Guo, Y.; Ding, J.M.; Rong, Y.; Feng, J.C.; Yao, S.; Hao, R.H.; Jiang, F.; Chen, J.B.; et al. Phenome-wide investigation of the causal associations between childhood BMI and adult trait outcomes: A two-sample Mendelian randomization study. Genome Med. 2021, 13, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Mosley, J.D.; Gupta, D.K.; Tan, J.; Yao, J.; Wells, Q.S.; Shaffer, C.M.; Kundu, S.; Robinson-Cohen, C.; Psaty, B.M.; Rich, S.S.; et al. Predictive Accuracy of a Polygenic Risk Score Compared with a Clinical Risk Score for Incident Coronary Heart Disease. JAMA J. Am. Med. Assoc. 2020, 323, 627–635. [Google Scholar] [CrossRef] [PubMed]
- Elliott, J.; Bodinier, B.; Bond, T.A.; Chadeau-Hyam, M.; Evangelou, E.; Moons, K.G.M.; Dehghan, A.; Muller, D.C.; Elliott, P.; Tzoulaki, I. Predictive Accuracy of a Polygenic Risk Score-Enhanced Prediction Model vs a Clinical Risk Score for Coronary Artery Disease. JAMA J. Am. Med. Assoc. 2020, 323, 636–645. [Google Scholar] [CrossRef]
- Khan, S.S.; Cooper, R.; Greenland, P. Do Polygenic Risk Scores Improve Patient Selection for Prevention of Coronary Artery Disease? JAMA J. Am. Med. Assoc. 2020, 323, 614–615. [Google Scholar] [CrossRef]
- Wald, N.J.; Old, R. The illusion of polygenic disease risk prediction. Genet. Med. 2019, 21, 1705–1707. [Google Scholar] [CrossRef] [PubMed]
- Riveros-Mckay, F.; Weale, M.E.; Moore, R.; Selzam, S.; Krapohl, E.; Sivley, R.M.; Tarran, W.A.; Sørensen, P.; Lachapelle, A.S.; Griffiths, J.A.; et al. Integrated Polygenic Tool Substantially Enhances Coronary Artery Disease Prediction. Circ. Genom. Precis. Med. 2021, 14, e003304. [Google Scholar] [CrossRef]
- Mars, N.; Koskela, J.T.; Ripatti, P.; Kiiskinen, T.T.J.; Havulinna, A.S.; Lindbohm, J.V.; Ahola-Olli, A.; Kurki, M.; Karjalainen, J.; Palta, P.; et al. Polygenic and clinical risk scores and their impact on age at onset and prediction of cardiometabolic diseases and common cancers. Nat. Med. 2020, 26, 549–557. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Zhuang, Z.; Wang, W.; Huang, T.; Liu, Z. An Improved Genome-Wide Polygenic Score Model for Predicting the Risk of Type 2 Diabetes. Front. Genet. 2021, 12, 632385. [Google Scholar] [CrossRef]
- Sun, L.; Pennells, L.; Kaptoge, S.; Nelson, C.P.; Ritchie, S.C.; Abraham, G.; Arnold, M.; Bell, S.; Bolton, T.; Burgess, S.; et al. Polygenic risk scores in cardiovascular risk prediction: A cohort study and modelling analyses. PLoS Med. 2021, 18, e1003498. [Google Scholar] [CrossRef]
- Meisner, A.; Kundu, P.; Zhang, Y.D.; Lan, L.V.; Kim, S.; Ghandwani, D.; Choudhury, P.P.; Berndt, S.I.; Freedman, N.D.; Garcia-Closas, M.; et al. Combined utility of 25 disease and risk factor polygenic risk scores for stratifying risk of all-cause mortality. medRxiv 2020, 107, 418–431. [Google Scholar] [CrossRef] [PubMed]
- Barker, D.J.P. The origins of the developmental origins theory. Wiley Online Libr. 2007, 261, 412–417. [Google Scholar] [CrossRef]
- Choi, S.W.; Mak, T.S.H.; O’Reilly, P.F. Tutorial: A guide to performing polygenic risk score analyses. Nat. Protoc. 2020, 15, 2759–2772. [Google Scholar] [CrossRef]
- Censin, J.C.; Peters, S.A.E.; Bovijn, J.; Ferreira, T.; Pulit, S.L.; Mägi, R.; Mahajan, A.; Holmes, M.V.; Lindgren, C.M. Causal relationships between obesity and the leading causes of death in women and men. PLoS Genet. 2019, 15, e1008405. [Google Scholar] [CrossRef] [Green Version]
- Power, M.L.; Schulkin, J. Sex differences in fat storage, fat metabolism, and the health risks from obesity: Possible evolutionary origins. Br. J. Nutr. 2008, 99, 931–940. [Google Scholar] [CrossRef]
- Halim, M.; Halim, A. The effects of inflammation, aging and oxidative stress on the pathogenesis of diabetes mellitus (type 2 diabetes). Diabetes Metab. Syndr. Clin. Res. Rev. 2019, 13, 1165–1172. [Google Scholar] [CrossRef]
- Lambert, S.A.; Gil, L.; Jupp, S.; Ritchie, S.C.; Xu, Y.; Buniello, A.; McMahon, A.; Abraham, G.; Chapman, M.; Parkinson, H.; et al. The Polygenic Score Catalog as an open database for reproducibility and systematic evaluation. Nat. Genet. 2021, 53, 420–425. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.C.; Banks, S.J.; Thompson, W.K.; Chen, C.H.; McEvoy, L.K.; Tan, C.H.; Kukull, W.; Bennett, D.A.; Farrer, L.A.; Mayeux, R.; et al. Sex-dependent polygenic effects on the clinical progressions of Alzheimer’s disease. bioRxiv 2019, 613893. [Google Scholar]
- Alva, M.L.; Hoerger, T.J.; Zhang, P.; Gregg, E.W. Identifying risk for type 2 diabetes in different age cohorts: Does one size fit all? BMJ Open Diabetes Res. Care 2017, 5, e000447. [Google Scholar] [CrossRef] [Green Version]
- Padilla-Martínez, F.; Collin, F.; Kwasniewski, M.; Kretowski, A. Systematic review of polygenic risk scores for type 1 and type 2 diabetes. Int. J. Mol. Sci. 2020, 21, 1703. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thomas, M.; Sakoda, L.C.; Hoffmeister, M.; Rosenthal, E.A.; Lee, J.K.; van Duijnhoven, F.J.B.; Platz, E.A.; Wu, A.H.; Dampier, C.H.; de la Chapelle, A.; et al. Response to Li and Hopper. Am. J. Hum. Genet. 2021, 108, 527–529. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Hopper, J.L. Age dependency of the polygenic risk score for colorectal cancer. Am. J. Hum. Genet. 2021, 108, 525–526. [Google Scholar] [CrossRef] [PubMed]
- Maier, R.M.; Zhu, Z.; Lee, S.H.; Trzaskowski, M.; Ruderfer, D.M.; Stahl, E.A.; Ripke, S.; Wray, N.R.; Yang, J.; Visscher, P.M.; et al. Improving genetic prediction by leveraging genetic correlations among human diseases and traits. Nat. Commun. 2018, 9, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Ahlqvist, E.; Storm, P.; Käräjämäki, A.; Martinell, M.; Dorkhan, M.; Carlsson, A.; Vikman, P.; Prasad, R.B.; Aly, D.M.; Almgren, P.; et al. Novel subgroups of adult-onset diabetes and their association with outcomes: A data-driven cluster analysis of six variables. Lancet Diabetes Endocrinol. 2018, 6, 361–369. [Google Scholar] [CrossRef] [Green Version]
- Duncan, L.; Shen, H.; Gelaye, B.; Meijsen, J.; Ressler, K.; Feldman, M.; Peterson, R.; Domingue, B. Analysis of polygenic risk score usage and performance in diverse human populations. Nat. Commun. 2019, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- De La Vega, F.M.; Bustamante, C.D. Polygenic risk scores: A biased prediction? Genome Med. 2018, 10, 1–3. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sex | Percentile | OR (BMI) a | OR (PRS) | OR (CRS) | p-Value b |
|---|---|---|---|---|---|
| Females | 90 | 2.92 ± 0.43 | 2.01 ± 0.36 | 3.03 ± 0.44 | 3.63 × 10−13 |
| 95 | 4.44 ± 0.6 | 2.46 ± 0.41 | 4.59 ± 0.57 | <10−16 | |
| 97 | 5.54 ± 0.65 | 2.71 ± 0.44 | 6.22 ± 0.75 | <10−16 | |
| 99 | 9.10 ± 0.98 | 3.94 ± 0.48 | 10.27 ± 1.16 | <10−16 | |
| Males | 90 | 2.48 ± 0.32 | 1.95 ± 0.29 | 3.00 ± 0.36 | <10−16 |
| 95 | 4.21 ± 0.47 | 2.38 ± 0.31 | 4.30 ± 0.48 | 1.67 × 10−12 | |
| 97 | 4.69 ± 0.49 | 2.90 ± 0.36 | 5.44 ± 0.57 | <10−16 | |
| 99 | 7.84 ± 0.76 | 3.99 ± 0.42 | 9.38 ± 0.91 | <10−16 |
| Sex | Percentile | OR (Birth Weight) a | OR (PRS) | OR (CRS) | p-Value b |
|---|---|---|---|---|---|
| Females | 90 | 1.84 ± 0.42 | 1.94 ± 0.47 | 2.00 ± 0.45 | 2.25 × 10−6 |
| 95 | 1.99 ± 0.44 | 2.55 ± 0.53 | 2.59 ± 0.52 | 0.014 | |
| 97 | 2.26 ± 0.48 | 2.78 ± 0.54 | 3.11 ± 0.60 | <10−16 | |
| 99 | 3.62 ± 0.57 | 3.81 ± 0.63 | 4.64 ± 0.67 | <10−16 | |
| Males | 90 | 1.67 ± 0.38 | 1.99 ± 0.44 | 1.97 ± 0.40 | 0.11 |
| 95 | 1.83 ± 0.40 | 2.56 ± 0.50 | 2.51 ± 0.50 | 3.39 × 10−4 | |
| 97 | 1.94 ± 0.39 | 2.59 ± 0.47 | 2.81 ± 0.51 | <10−16 | |
| 99 | 3.08 ± 0.51 | 4.54 ± 0.73 | 4.83 ± 0.72 | <10−16 |
| Sex | Percentile | OR (PRS) a | OR (CRS) | p-Value b |
|---|---|---|---|---|
| Females | 90 | 1.97 ± 0.35 | 2.02 ± 0.36 | 7.71 × 10−5 |
| 95 | 2.43 ± 0.41 | 2.40 ± 0.38 | 0.031 | |
| 97 | 2.75 ± 0.43 | 3.00 ± 0.45 | <10−16 | |
| 99 | 3.83 ± 0.46 | 4.18 ± 0.49 | <10−16 | |
| Males | 90 | 1.96 ± 0.28 | 2.06 ± 0.29 | <10−16 |
| 95 | 2.38 ± 0.32 | 2.48 ± 0.33 | <10−16 | |
| 97 | 2.93 ± 0.35 | 3.07 ± 0.37 | <10−16 | |
| 99 | 3.98 ± 0.42 | 4.24 ± 0.42 | <10−16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moldovan, A.; Waldman, Y.Y.; Brandes, N.; Linial, M. Body Mass Index and Birth Weight Improve Polygenic Risk Score for Type 2 Diabetes. J. Pers. Med. 2021, 11, 582. https://doi.org/10.3390/jpm11060582
Moldovan A, Waldman YY, Brandes N, Linial M. Body Mass Index and Birth Weight Improve Polygenic Risk Score for Type 2 Diabetes. Journal of Personalized Medicine. 2021; 11(6):582. https://doi.org/10.3390/jpm11060582
Chicago/Turabian StyleMoldovan, Avigail, Yedael Y. Waldman, Nadav Brandes, and Michal Linial. 2021. "Body Mass Index and Birth Weight Improve Polygenic Risk Score for Type 2 Diabetes" Journal of Personalized Medicine 11, no. 6: 582. https://doi.org/10.3390/jpm11060582