1. Introduction
The study of the quality system of hospitals is a necessary activity for the improvement of the services they offer [
1]. In recent years, different public and private institutions have established a set of activity and quality indicators that allow the evaluation, monitoring and comparison of the activities of hospital emergency services [
2]. For example, the Spanish Society of Emergency Medicine developed a minimum set of indicators establishing a common, homogeneous and reliable system of information in the emergency services [
3]. Three groups of indicators [
4] are defined: activity (they measure the number of requests for assistance), quality (they measure qualitative aspects of the operation of the service) and result (they measure results reporting the quality, technical and decisive capacity). Among the quality indicators are the following [
5]: average time of first medical attention [
6], average time spent in the emergency department, degree of completion of the history, information to patients and relatives, diagnostic coding of discharges, proportion of admissions, rate of return to the emergency room and mortality rate in the emergency room [
3]. This work will analyze one of the quality indicators mentioned: the rate of return to the emergency room [
7]. This measures the number of patients who, after being treated in an emergency department and discharged, return in less than 72 h [
8]. The rate of return to the emergency room is calculated as the quotient (multiplied by a thousand) between the number of patients who return in less than 72 h and the total number of patients who come to the same service in a given period of time. The importance of the study of re-admissions lies in improving the quality of hospital emergency services [
2], since avoiding the patient’s return to the emergency room is a consequence of the quality provided [
9]. In the field of private healthcare, it is also included as an index of healthcare quality [
10].
There are different approaches to analyze the return to the emergency department that vary according to the factors [
11,
12] that are taken into account to analyze this indicator. A key factor is the time [
13,
14] that must elapse from discharge to the next visit to consider said return as a return. In [
15] the profile of the patients who return is studied through variables such as age, sex, day of the week or pathology, among others. For this, three different times are used, studying separately the patients who return in the first 24 h, those who return between 24 and 48 h, and those who take up to 72 h. The result showed that 88.76% of the patients who return do so in the first 48 h, so they consider that it is not necessary to use a longer time. On the other hand, [
16] analyzes whether the time to return to the emergency room influences the short-term mortality of the patients. From the study carried out, it is defined that the return time is any visit that occurs up to eight days after discharge. In [
17,
18], the optimal time is considered for re-entry. For this, the data on the return to the emergency room of patients in adulthood over a period of 30 days were analyzed, and it was concluded that the most inclusive time was nine days.
Another factor to analyze this variable is the causes that influence returns [
19]. Returns to the emergency room occur when, after a certain time from discharge, the patient returns unscheduled and for the same reason as the first appointment [
20]. However, a difficulty that arises in these studies is knowing if the return is due to the same reason for the first visit or is due to a cause derived from the first visit [
21]. In general, it is preferable to study the return due to any cause [
12]. In [
22], a study of the rate of return to the emergency department was carried out in order to search for the factors associated with said return. To do this, they classified the causes into four groups: related to the patient, the doctor, the health system and the disease; a classification that serves as a reference for subsequent work. However, it is a very expensive process [
23] since different doctors evaluate each case separately and if there is a discrepancy, it should be evaluated by a committee with several reviewers and a doctor. There are quite a few studies [
24] showing that the cause of greatest return is that of the disease or the patient. For example, [
25] shows that unscheduled returns that occur in the first week after discharge are due to the disease with 48% and the patient with 41%. [
26] studied unscheduled returns in the 72 h from discharge and showed that in 60.4% the first cause of return is due to the disease and the second cause with 20.0% is due to the doctor.
Other studies [
27,
28,
29] analyzed the diagnoses of those patients who return, with the aim of observing if there is any type of relationship between readmission and the disease for which they go to the emergency department. For example, in [
30] it was found that renal colic and spondylosis were the most frequent diseases of those individuals who returned, followed by headaches.
In general, the studies carried out [
31] are based on the use of descriptive methods on demographic variables (degree of disability or life situation) or quantitative variables (drug count, time markers, or diagnostic codes). In machine learning, [
32] random forests and gradient boosting have been used to predict return within 30 days [
33], or logical regression [
34] for time intervals shorter than 72 h, such as in [
35]. Another study [
36] used a gradient boosting over a range of 72 h to nine days to analyze data from electronic clinical records [
37] such as administrative data (demographics, previous hospital use, comorbidity categories, historical vital values and current), treatment data (laboratory values, ECG and imaging counts, drugs administered), data available at the time of triage and data available at the time of discharge.
This article describes a study on the phenomenon of the return of patients to the emergency department of a hospital in less than 72 h. Firstly, the time limit of 72 h was used as it is the most accepted in the scientific literature and contains a greater number of case studies in the dataset used. On the other hand, the objective of the study was established to find the best set of variables that explain the phenomenon and the best machine learning algorithm to model this phenomenon. For this, the binary variable of the rate of return to the hospital emergency department was considered as the objective study variable. In addition, to carry out the analysis the use of machine learning algorithms was proposed (logistic regression [
38], neural networks [
39], random forest [
40], gradient boosting [
41] and assembly models [
42]). Many of the studies carried out (discussed in the previous paragraphs) are based on classical statistical techniques. However, in this case, the characteristics of the dataset used (which contains a large amount of data (143,803 observations) from a sufficiently broad period from June 2015 to February 2018 inclusively for a total of 33 months) are ideal to be used with machine learning algorithms. The main contributions of this work are the model and the variables obtained that better explain the phenome analyzed. In this sense, the analysis performed indicates that the best model is a neural network with activation function tanh, algorithm levmar and three nodes in the hidden layer, and the set of variables that best explain the phenomenon are pathology2 (corresponding to general medicine), reason_discharge2 (hospitalization of the plant) and reason_discharge5 (evasion). The model found shows a better behavior than the rest of the studied models (since it presents a lower mean squared error (MSE) than the rest of the models and a better area under the curve (AUC)). In addition, the result is consistent with what is stated in the studies of other authors about the non-linear nature of the phenomenon studied (since neural networks generally model quite well phenomena that have non-linear behavior).
The structure of the paper is as follows. In the first section, we will describe the dataset that has been used. The following explains how the data was prepared before performing the analysis (detection of extreme points, treatment of missing data, transformation of data and selection of variables). The next section describes the results of the analysis carried out with each type of machine learning algorithm. In the discussion section, the results are analyzed together to obtain a response to the stated objectives. Finally, a set of conclusions and lines of future work are proposed.
4. Results
The study that has been carried out is of an analytical and observational type. It is analytical because it looked for the characteristics of the patients who returned to the hospital 72 h after discharge. In addition, it is observational because the study factor was not assigned by the researcher and was limited to observing, measuring and analyzing certain variables without exercising direct control of the intervention. Finally, from the temporal point of view, it is a cross-sectional and retrospective study that analyzed the data at a specific moment in the past.
Two programs from the SAS statistical processing package were used to perform the analysis.: SAS Enterprise Miner and SAS Base. The first program is interesting because of the large number of results it shows, including graphs and statistics even in the “black box” models, and the second program stands out for the method of evaluating the results (repeated cross-validation), which is more accurate than the one used with SAS Miner.
SAS Miner was used to create the logistic regression and neural network models, while the random forest models were built with SAS Base. This is because the SAS Miner Random Forest modeling node was not working properly and often gave errors. Gradient boosting and assembly models were carried out through the two programs, complementing some results with others. The idea of using both programs was the same: to take advantage of the main advantages of each to obtain more complete results.
4.1. Logistic Regression
This analysis used the imputed data. The processing was carried out as follows:
In the first examination, a logistic regression was performed “forward,” “backward” and “step by step” for each of the sets of variables A, B and C. The results (
Table 10) show that the misclassification rate was the same in all cases. Although the rest of the statistics vary between the models, nevertheless the best results were obtained with the backward selection method in all the sets of variables. The AUC value shows that the model with the highest discriminatory capacity was the one built with the set of variables C, followed by the models built with the set of variables B and A, in that order. Thus, it was necessary to do a new examination in order to determine which the dataset provided the optimal results.
A training test of 10 repetitions and different seeds was carried out to determine the best set of variables. In each iteration, a logistic regression was performed with a backward selection method on each set of variables. The results (
Table 11) show small differences between the statistics. However, the best values in terms of model quality throughout the iterations was obtained with the model built with the set of variables A (pathology2, reason_discharge2 and reason_discharge5).
Finally, the global significance of the model (
Table 12) was checked, obtaining a value of 0.0001 < 0.05.
4.2. Neural Network
The imputed dataset was used in this algorithm. To obtain the best model, the number of hidden layer nodes and the training algorithm were varied. Regarding the activation function, the function tanh (x) = 1 − (2/(1 + e2x) was always used as it works best. The processing was done as follows:
First, four networks were built for each of the three sets of variables (12 network models). These four models consisted of the following parameters: three nodes and “bprop” algorithm, three nodes and “levmar” algorithm, seven nodes and “bprop” algorithm, and seven nodes and “levmar” algorithm. The result (
Table 13) shows that the dataset C was the worst model since the AIC and SBC statistics were much higher than those of the other models, and the misclassification rate and the AUC were not able to be calculated. With respect of sets A and B, the misclassification rate was the same. However, the best values with respect to the AIC and the AUC were obtained by the set of variables A with seven nodes (regardless of the algorithm). However, the best SBC and MSE values were obtained by the set of variables A with three nodes (regardless of algorithm). Thus, the best set of variables was A. The optimal number of nodes will have to be studied since good results were achieved with three nodes and seven. Finally, it seems that the algorithm did not influence since the models were numerically the same with algorithm “levmar” and “bprop.”
In the second exploration, six models were constructed using the set of variables A. Four of them were with the “levmar” algorithm and two of them with the “quasi-Newton” algorithm with the aim of checking whether the algorithm influenced the results. The influence of the number of nodes was also analyzed so that the four models with “levmar” consisted of 3, 5, 7 and 10 nodes, respectively, while the ”quasi-Newton” models had three and seven nodes. The result shows (
Table 14) that the misclassification rate was similar in all models and that the algorithm did not influence the results, so the “levmar” algorithm was selected. In addition, it was observed that there was no model that was strictly better than the rest.
In the third exploration, a training test was repeated 10 times with the four best models obtained: set of variables A, “levmar” algorithm and nodes 3, 7, 10 and 12, respectively. The result (
Table 15) shows that the best models were those of three and seven nodes.
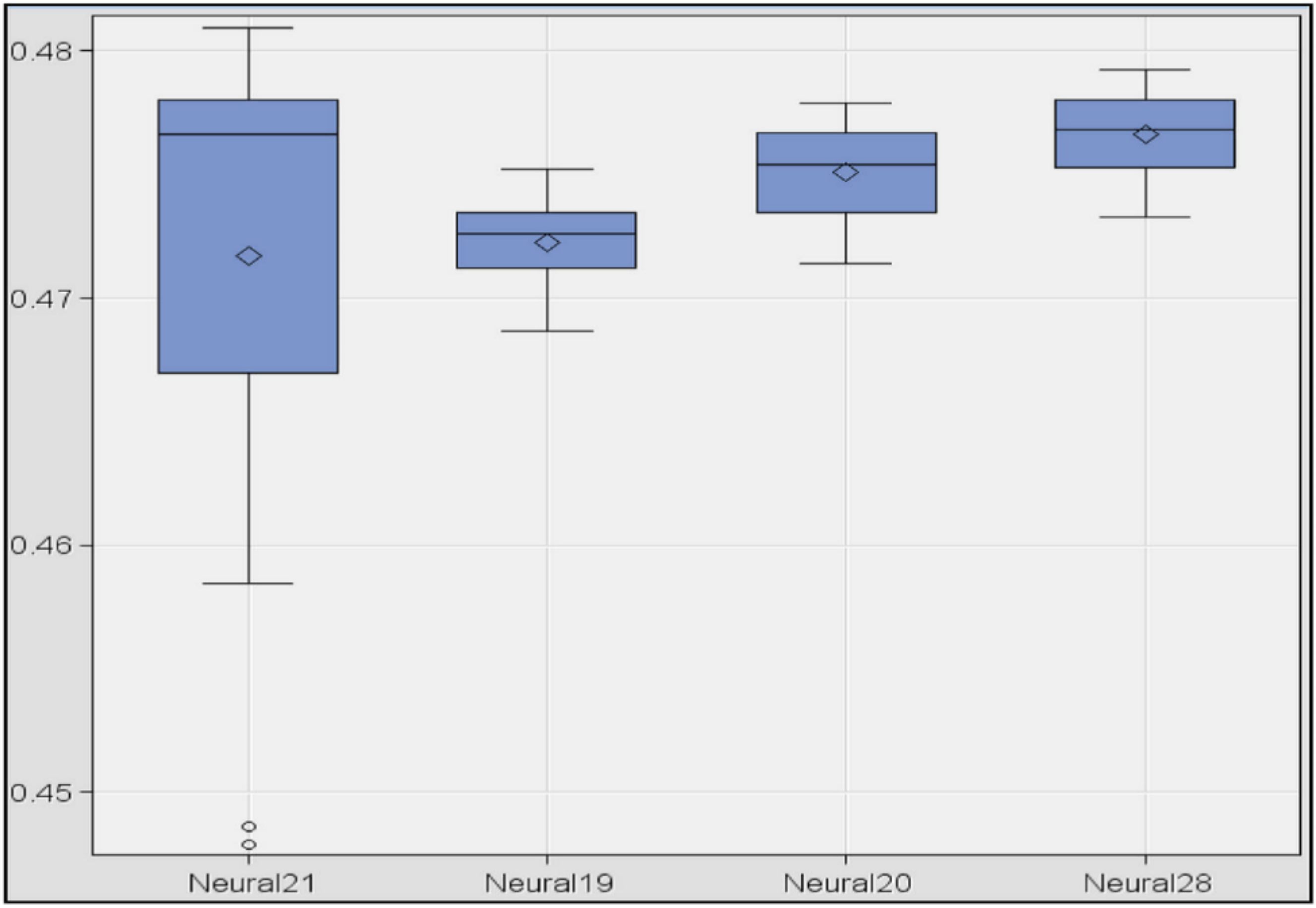
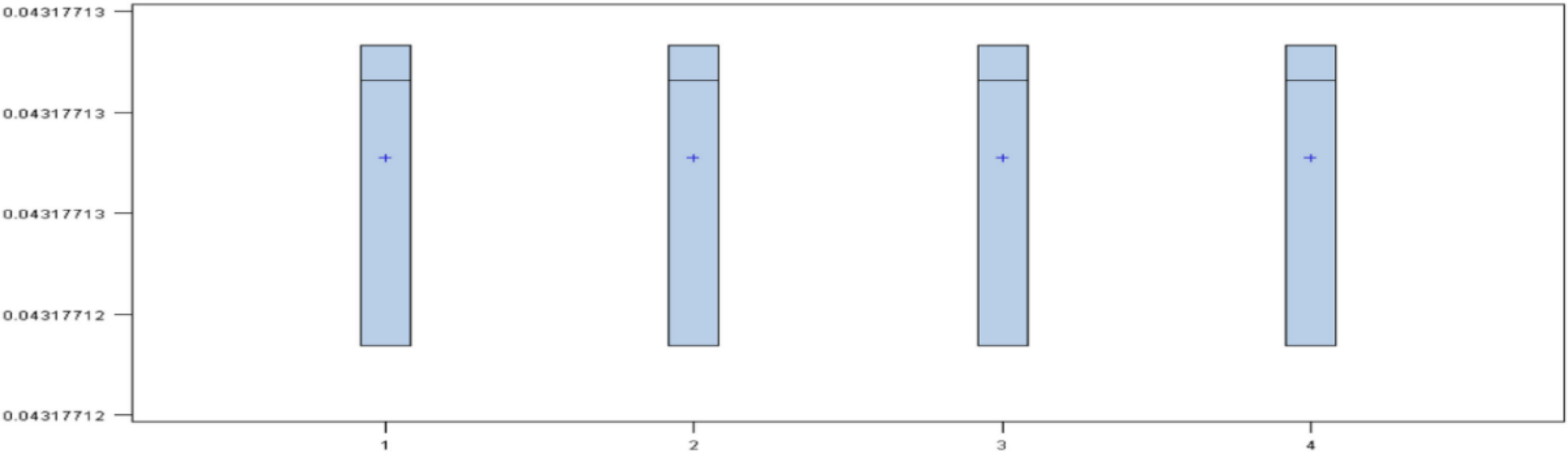
Finally, in order to determine the best model, a box-plot diagram of the MSE of the models was done. The result shows (
Figure 1) the diagrams for the models 10, 3, 7 and 12 nodes (in this order). The smallest errors appeared in the models with 10 and three nodes. However, the dispersion was greater in the first case. Comparing the models with three and seven nodes, it was observed that the model with three nodes had the smallest error, both in mean and variance. Therefore, the best model was obtained with the set of variables A, activation function “tanh,” algorithm “levmar” and a total of three nodes in the hidden layer.
4.3. Random Forest
In this algorithm, the dataset with missing values was used since it efficiently handled this type of data. Models were constructed by repeated cross-validation with various seeds in order to calculate the failure rate from the three sets of variables. The result is represented with a box-plot diagram.
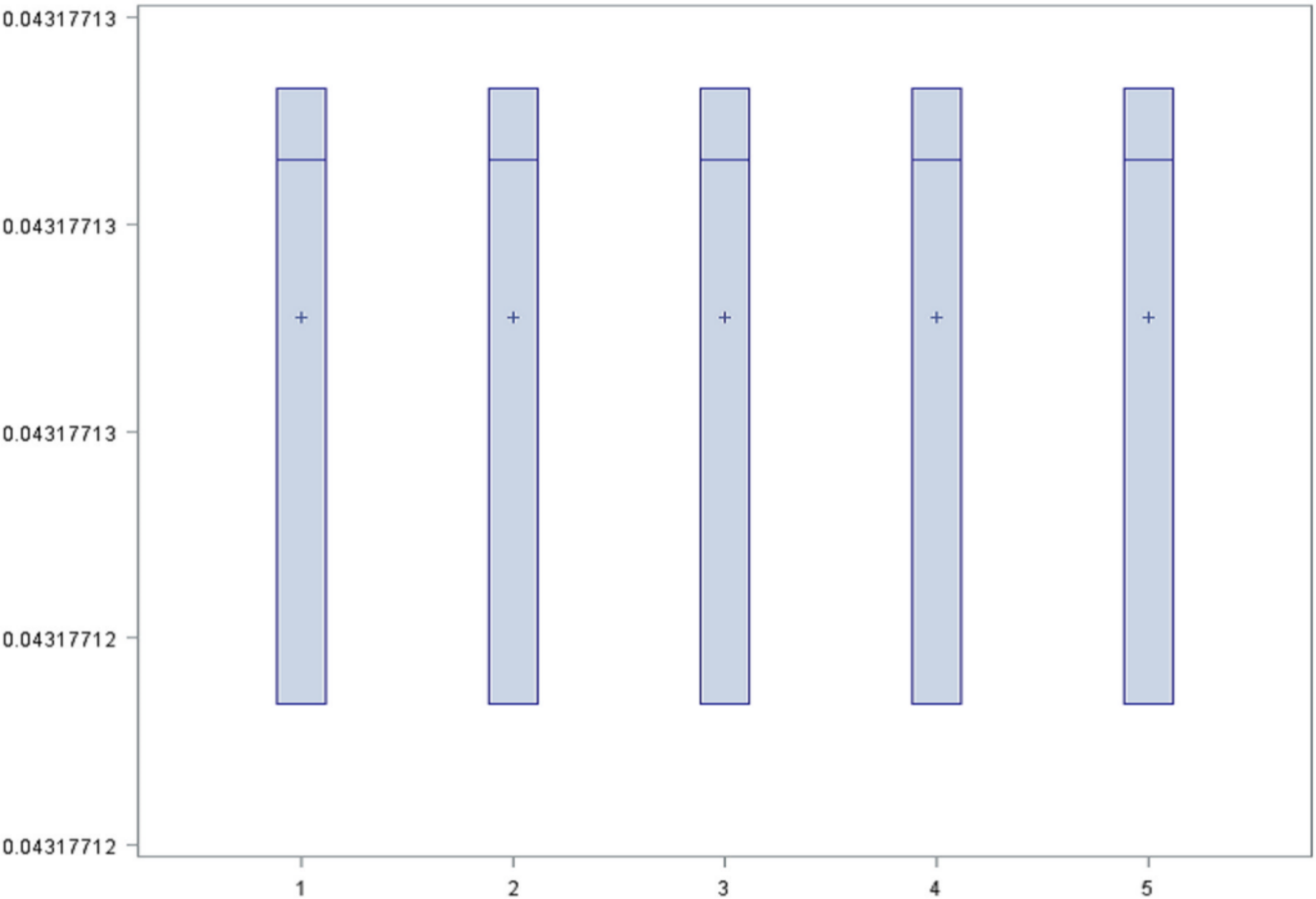
For set A two models were created, one with 200 iterations and maximum depth of tree 50, and another with 50 iterations and maximum depth of tree 10. For set B, two models were created with the same parameters used for the set A. In addition, for set C only a single model was created (with 200 iterations and maximum depth of 50) due to the large number of variables. The diagram of result (
Figure 2) shows that the rate had the same mean and distribution in all the models, therefore it was considered that all of them worked equally. For this reason, the simplest model was chosen as the best model. The model was the set of variables A (pathology2, reason_discharge2 and reason_discharge5) with 50 iterations, maximum depth of 10 and misclassification rate of 0.043.
4.4. Gradient Boosting
In this algorithm, the dataset with missing values was used (since it efficiently handled this type of data) and the failure rate obtained is represented with a box-plot diagram. The processing was carried out as follows:
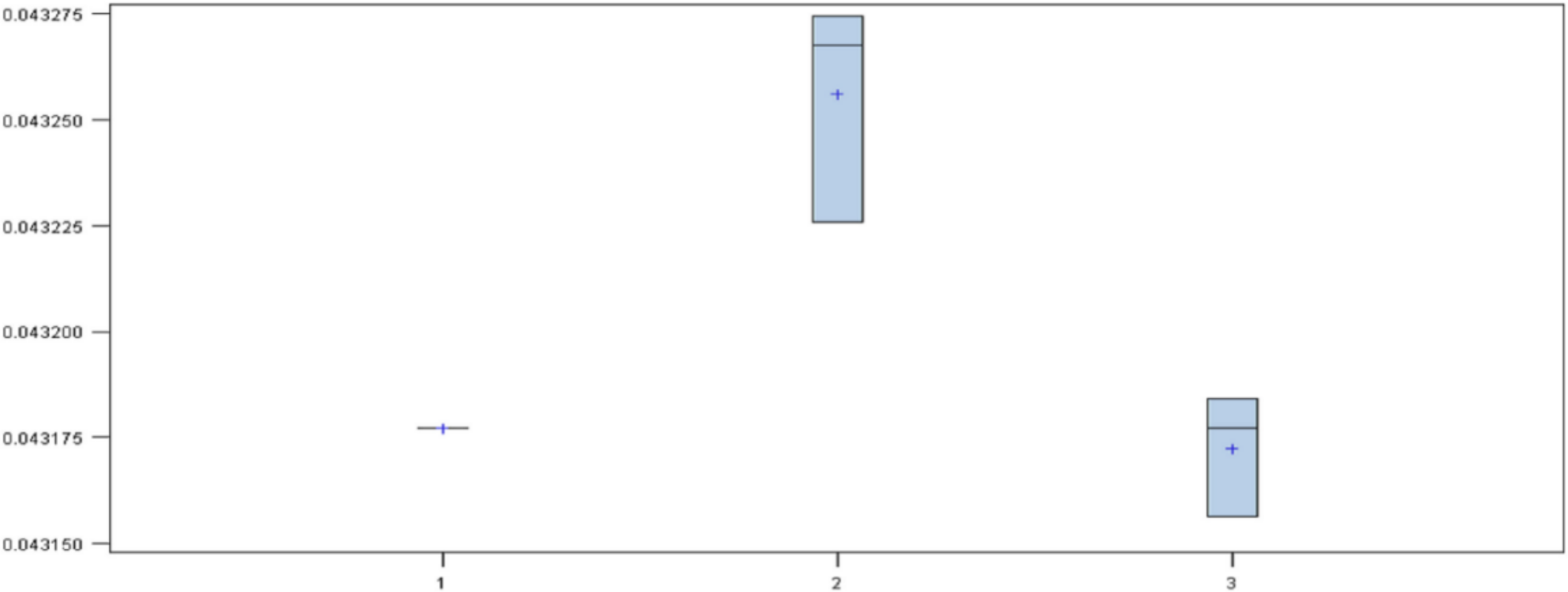
First, a model was created for each dataset with the following configurations: for the set of variables A with 50 iterations a regularization constant of 0.2 was used; for the set B with 150 iterations a regularization constant of 0.1 was used; and for the set C with 250 iterations a regularization constant of 0.01 was used. The maximum depth of the three models was 2. The diagram (
Figure 3) of results shows that the model with the highest mean was the set of variables B. The set of variables A and C had the same mean but different variance, with the set of variables A as the best of the three. Thus, the set of variables B was discarded.
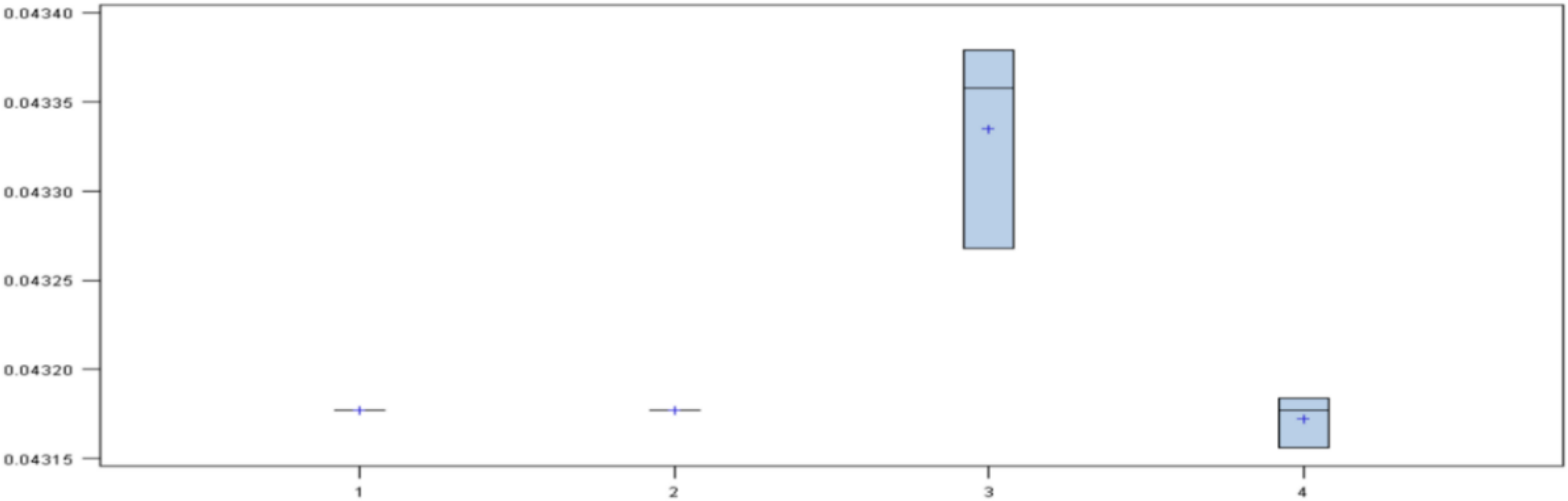
Next, four models were created: two with variables A (one with 50 iterations and a regularization constant of 0.2, and another with 250 iterations and regularization constant of 0.01), and the other two with variables C (in the same way). The diagram of the results (
Figure 4) shows that there were three models with the same mean. However, the models of the set of variables A had the least variance, so the set of variables C was discarded.
Next, four models were created with the set of variables A, varying the parameters corresponding to the iterations, the regularization constant and the maximum depth. The diagram of the results (
Figure 5) shows that models were not influenced by the parameters, so the best model was the simplest.
Thus, the best model was obtained using the set of variables A (pathology2, reason_discharge2 and reason_discharge5) with parameters of 50 iterations, a regularization constant of 0.2 and maximum depth of 10.
4.5. Assemble
The assemblies were done using the best models obtained from each technique with missing and imputed datasets depending on each technique, assembling the techniques two by two, three by three and even four. The result shows (
Table 16) that the misclassification rate and the AUC were the same in all cases, so the statistic to discriminate was the MSE. The lowest index was obtained with the assembly of regression and neural network followed by the assemblies of neural network and gradient boosting.
5. Discussions
The constructed models can be compared to analyze which best predicts the target variable. For this,
Table 17 has been constructed which shows for each model studied (logistic regression, neural networks, random forest, and gradient boosting and model assembly) the misclassification rate, the MSE and the AUC.
The misclassification rate is the same for all models, so it is necessary to use the rest of the statistics to obtain a conclusion. If the AUC is considered, it is observed that the random forest and gradient boosting models should be discarded since they present the smallest values. Then, for the remaining models, the MSE is used to compare them. Therefore, it is observed that the model with the lowest value corresponds to the model of neural networks.
In order to validate this result, a cross validation was carried out, rebuilding the models and analyzing the results. In this sense, the same results were obtained. This may be due to two factors: an overfit is occurring or the sample is very homogeneous. To study if there is an overfit, the results obtained in the training and test sets were considered with the aim of verifying if the training results were very good (overfit) and if the test the results worsened significantly.
Table 18 shows the results obtained and as it can be observed, there was no data overfit (the results are numerically very similar). Therefore, it can be concluded that the cause of the results being so similar in the models is because the dataset was very homogeneous.
The result of this research shows that the model that performs best is the one based on a neural network with activation function “tanh,” algorithm “levmar” and three nodes in the hidden layer. This is consistent with the results obtained by other authors previously cited in the introduction [
36,
37,
39,
42]. It also allows us to deduce that the phenomenon to be modeled corresponds to a non-linear model. This explains the best behavior of neural networks (they model nonlinear phenomena quite well). In this sense, it is very likely that the use of more advanced neural networks and a greater number of layers will allow us to obtain models that are closer to reality.
Another aspect of the research is the variables that explain the phenomenon. According to the results, the target variable could be explained based on the values of the dummy pathology2, reason_discharge2 and reason_discharge5 variables. The variable pathology2 is a dummy variable that represents whether a patient’s illness is related to general medicine. The reason_discharge2 variable is a dummy variable that represents the reason for the patient’s discharge from hospital. Finally, the variable reason_discharge5 is a dummy variable that represents the reason for the discharge of a patient that has left. In this sense, the result would indicate that the main reasons why a patient would be returning to the emergency department would depend on whether he has been treated for a general medicine problem or if the cause of discharge is due to hospitalization in the ward of the patient or to the evasion of the patient. Compared with the results of other studies [
24], the results coincide with respect to the disease variable (although the same does not occur with the variables referred to medical discharge). Regarding the disease, other studies describe specific diseases [
27,
28,
29] that influence return such as renal colic, spondiolysis or headache. In this sense, the result indicating “general medicine” diseases would be consistent, also taking into account that the possible groups that appear in the data (general medicine, traumatology, gynecology, ophthalmology, general pediatrics, obstetrics, pediatric trauma). It is very likely that patients with renal colic are classified in “general medicine,” just as in the case of headache. Therefore, the analysis carried out complements other works showing that in addition to the disease, another cause that influences return is the cause of the medical discharge.
Regarding the quality of the results, as shown, the differences between the models are minimal and the reason is not due to an overfit, but to the homogeneity of the samples. The explanation for this situation is due to the state of the data that has been used. Although the initial dataset has important dimensions (period between June 2015 and February 2018 with a total of 143,803 emergencies, of which 6209 returned in less than 72 h after discharge), they could not all be used for problems such as missing values or wrong data. For this reason, the results could be refined if any of the variables could be corrected. Likewise, variable selection methods could be improved using feature selection techniques.
6. Conclusions and Future Work
This article has carried out an analysis on the phenomenon of the return of patients to the emergency department of a hospital in less than 72 h. For this, the prediction of the target binary variable of the patient’s return has been studied using various machine learning algorithms with the aim of obtaining several models for the phenomenon studied and fixing the sets of variables that best explain it.
It has been verified that the neural network model with activation function “tanh,” algorithm “levmar” and three nodes in the hidden layer shows a better behavior than the rest of the studied models (since it presents a lower MSE than the rest of the models and a better AUC). In addition, the set of variables that best explain the phenomenon are pathology2 (corresponding to general medicine), reason_discharge2 (hospitalization of the plant) and reason_discharge5 (evasion). This result is consistent with what is stated in the studies of other authors about the non-linear nature of the phenomenon studied (since neural networks generally model phenomena that have non-linear behavior quite well).
On the other hand, it has been observed that the differences in the values of the statistics of the results obtained show very similar behaviors with the sets of variables used (this is because the results obtained are strongly influenced by the training sets and proof used). The explanation for this fact lies in the impossibility of having used all the variables available in the dataset due to the existence of erroneous data or missing data and the variable selection method used. This results in the fit of the data not being as good as it should be, and does not show a clearly winning model.
As future lines of work, several are proposed. First, analyze the sensitivity of the results according to the size of the source set. It may be valuable to other researchers and developers as it will provide them with a solid basis for determining the required size of the dataset. Second, the repetition of the study using feature selection techniques [
42] to improve the selection of variables is needed. Third, use of other models of machine learning such as deep learning algorithms are needed since the results obtained in this study suggest that more sophisticated neural network models could better explain the studied phenomenon.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




