
Innovative Strategies for Early Autism Diagnosis: Active Learning and Domain Adaptation Optimization
 , , ,
, , ,
Abstract
:1. Introduction
- (a)
- The assimilation of novel facial image dataset, YTUIA: Presented as a diagnostic tool for ASD, the YTUIA dataset introduces a novel and distinctive set of features. Unlike existing datasets, YTUIA encapsulates a broader spectrum of facial expressions, ages, and ethnicities, making it a valuable addition to the landscape of ASD research. This dataset addresses a critical gap in the existing literature, where previous studies predominantly relied on single-domain data.
- (b)
- The optimization of a pretrained model using data from various domains: Through the incorporation of active learning, this study pioneers an approach to optimize pretrained models using data from diverse domains. Leveraging facial images from both Kaggle ASD and YTUIA datasets, the models are fine-tuned to capture nuanced patterns associated with ASD across different populations and imaging conditions. This innovative method significantly enhances the adaptability of the model, allowing it to generalize effectively in clinical scenarios with varying patient demographics.
- (c)
- Enhanced weight optimization through active learning: Active learning plays a pivotal role in the optimization process by guiding the selection of informative samples from each domain. These samples, strategically chosen based on uncertainty, refine the model’s weights, thereby improving its diagnostic accuracy. This approach mitigates the challenges posed by domain variations and ensures that the model adapts dynamically to the intricacies of each dataset. The result is a more robust and flexible diagnostic tool that excels in recognizing ASD-indicative patterns.
2. Materials and Methods
2.1. Dataset
2.1.1. Dataset 1 (Kaggle)
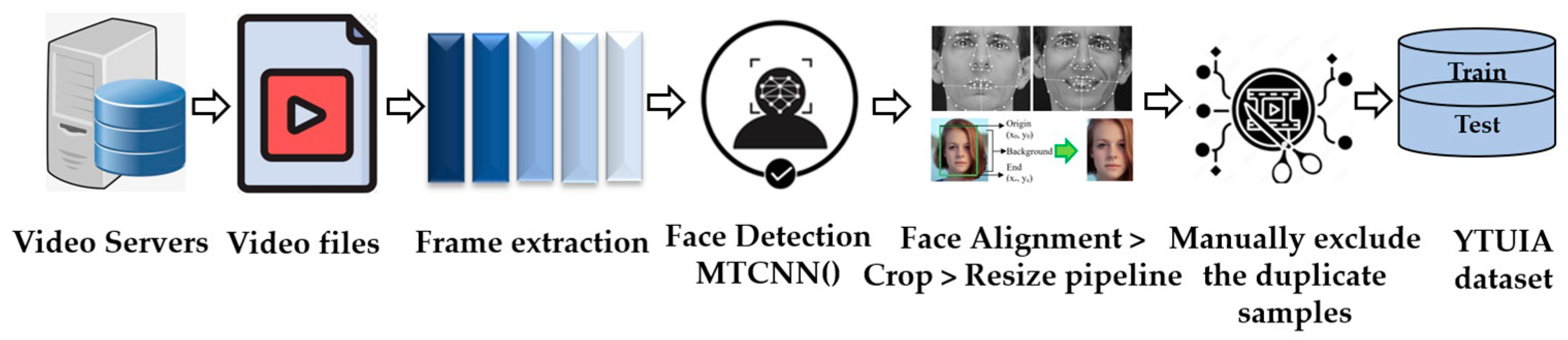
2.1.2. Dataset 2 (YTUIA)
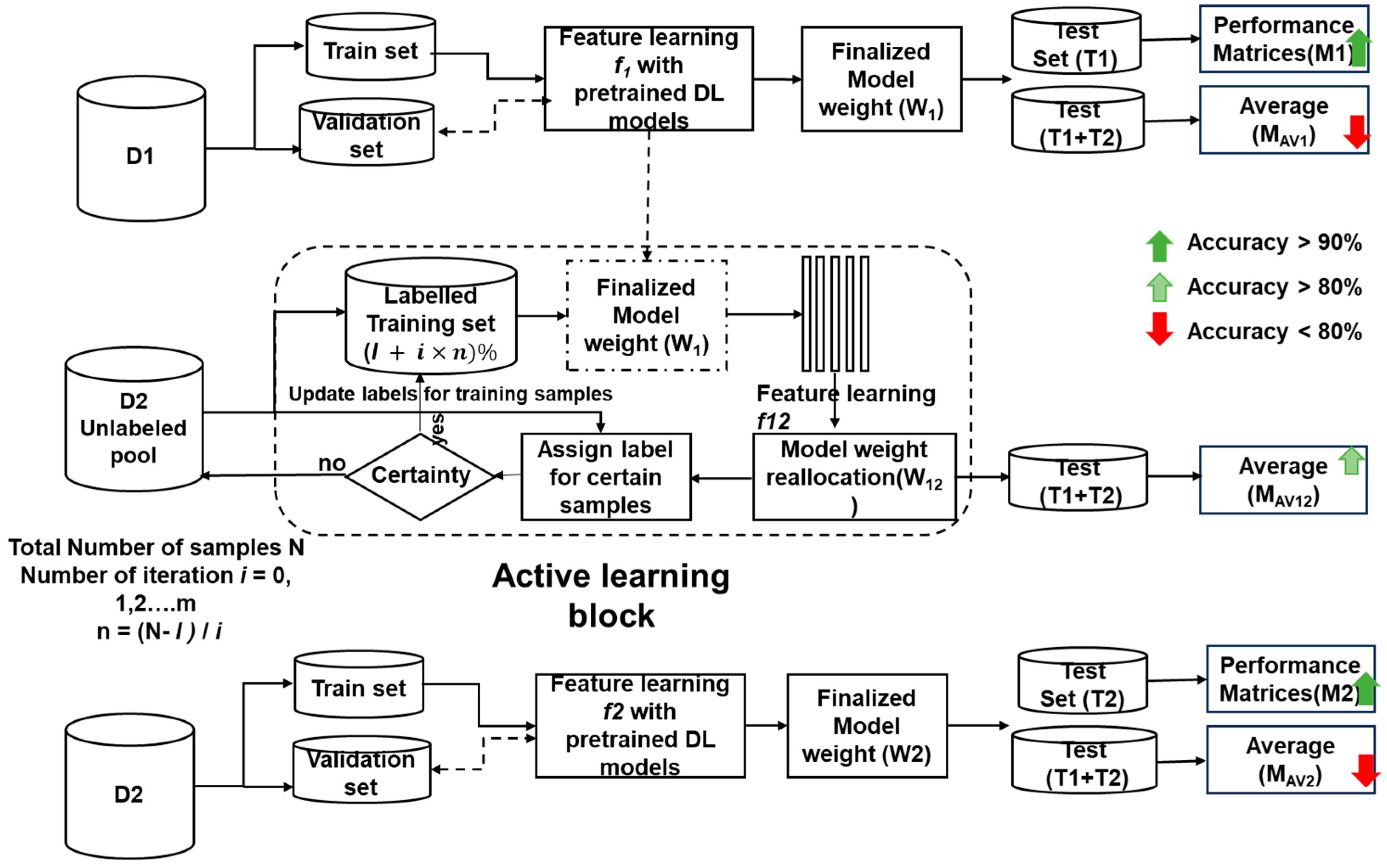
2.2. Active Learning
- I.
- Initial Model Training: A small subset of labeled images is used to train an initial classification model.
- II.
- Uncertainty Sampling: The model then analyzes unlabeled images, identifying those with the highest uncertainty or disagreement about their predicted class. These “informative” images are prioritized for manual annotation by expert clinicians.
- III.
- Model Retraining: The newly labeled images are incorporated into the training set, allowing the model to refine its decision boundaries and learn from the expert annotations.
- IV.
- Iterative Process: Steps 2 and 3 are repeated iteratively, with the model progressively improving its accuracy and confidence as it acquires more informative data points.
| Algorithm 1 Algorithm to apply active learning for ASD screening |
| Input: N = Total number of samples in D2 T2 = Test set for evaluation of matrices l = Number of labeled samples on first iteration U = N − l samples, pool of unlabeled data m = Number of iterations n = , Number of labeled samples added per iteration Start for iteration in range (m) do n_labeled l + m × n model_train (n_labeled) f12 feature learning (model) w12 model_get_weights () prediction model_predict (U) confidence assign_confidence (prediction) uncertain samples query_on (prediction) M12 model_evaluate(T2) End |
2.3. Domain Adaptation
2.4. Convolutional Neural Networks
2.4.1. MobileNetV2 Model
2.4.2. ResNet50V2 Model
2.4.3. Xception Model
2.5. Experimental Setup
- i.
- Train and evaluate all three models (ResNet50V2, Xception, MobileNetV2) on the D1 dataset;
- ii.
- Extract the learned weights (w1) after initial feature learning (f1);
- iii.
- Evaluate the combined test set (T1 + T2) using w1 weights to assess the initial extent of domain adaptation.
- i.
- Initialize active learning with models containing w1 weights and limited labeled samples (l);
- ii.
- Over m iterations,
- Use the models to label unlabeled samples from D2, iteratively updating weights (w12);
- Evaluate the performance of T2 against the current number of labeled samples.
- iii.
- Train the models with the labeled D2 dataset (100%);
- iv.
- Finally, evaluate the combined test set using these models to gauge the overall effectiveness of active learning in enhancing domain adaptation.
- i.
- Retrain the ImageNet-pretrained models directly on the labeled D2 dataset;
- ii.
- Extract the final learned weights (w2) after feature learning (f2);
- iii.
- Evaluate the performance of T2 and the combined test set using w2 weights.
3. Results
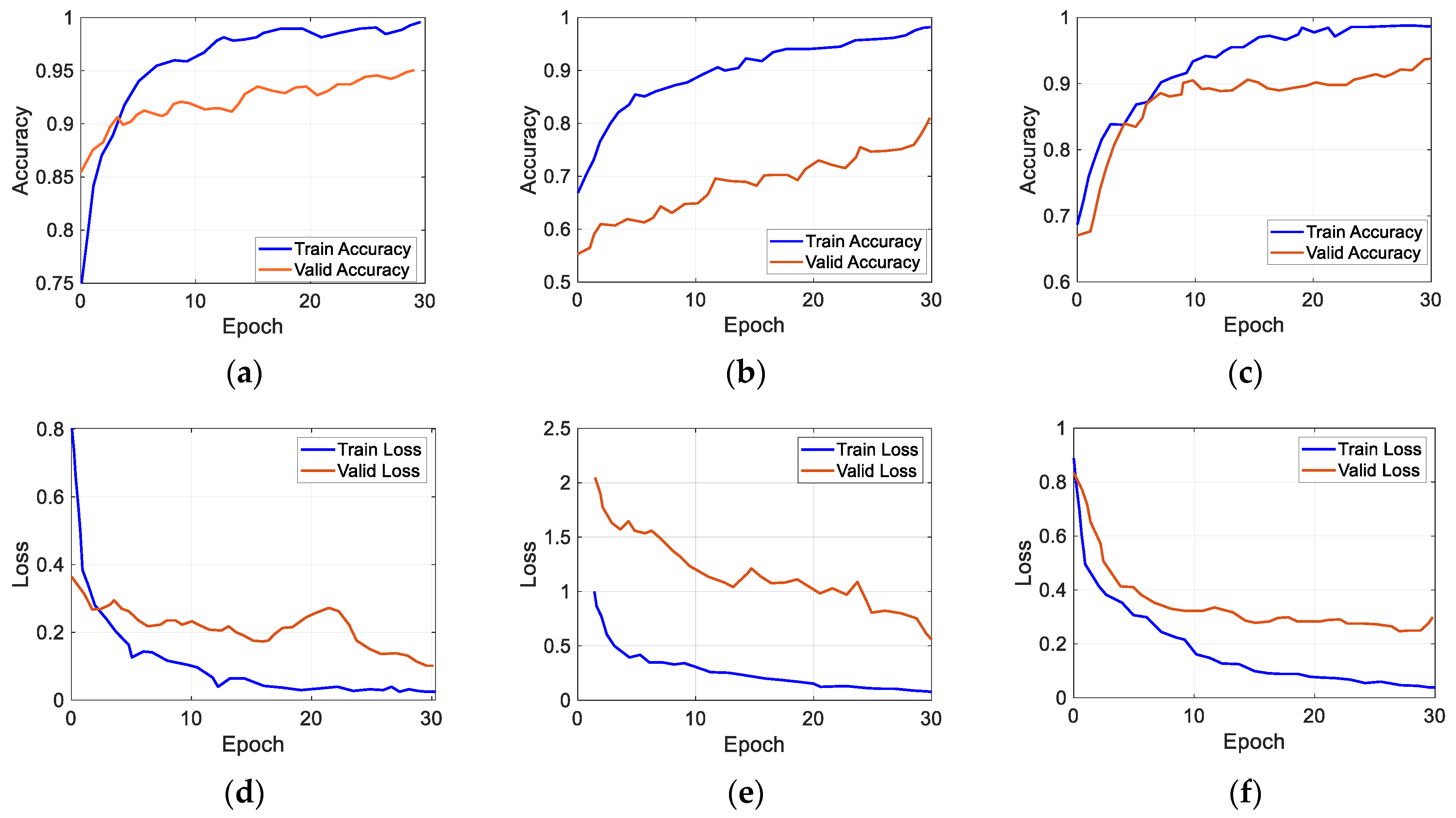
3.1. Performance Evaluation after Transfer Learning with D1
3.2. Performance Evaluation after Transfer Learning with D2
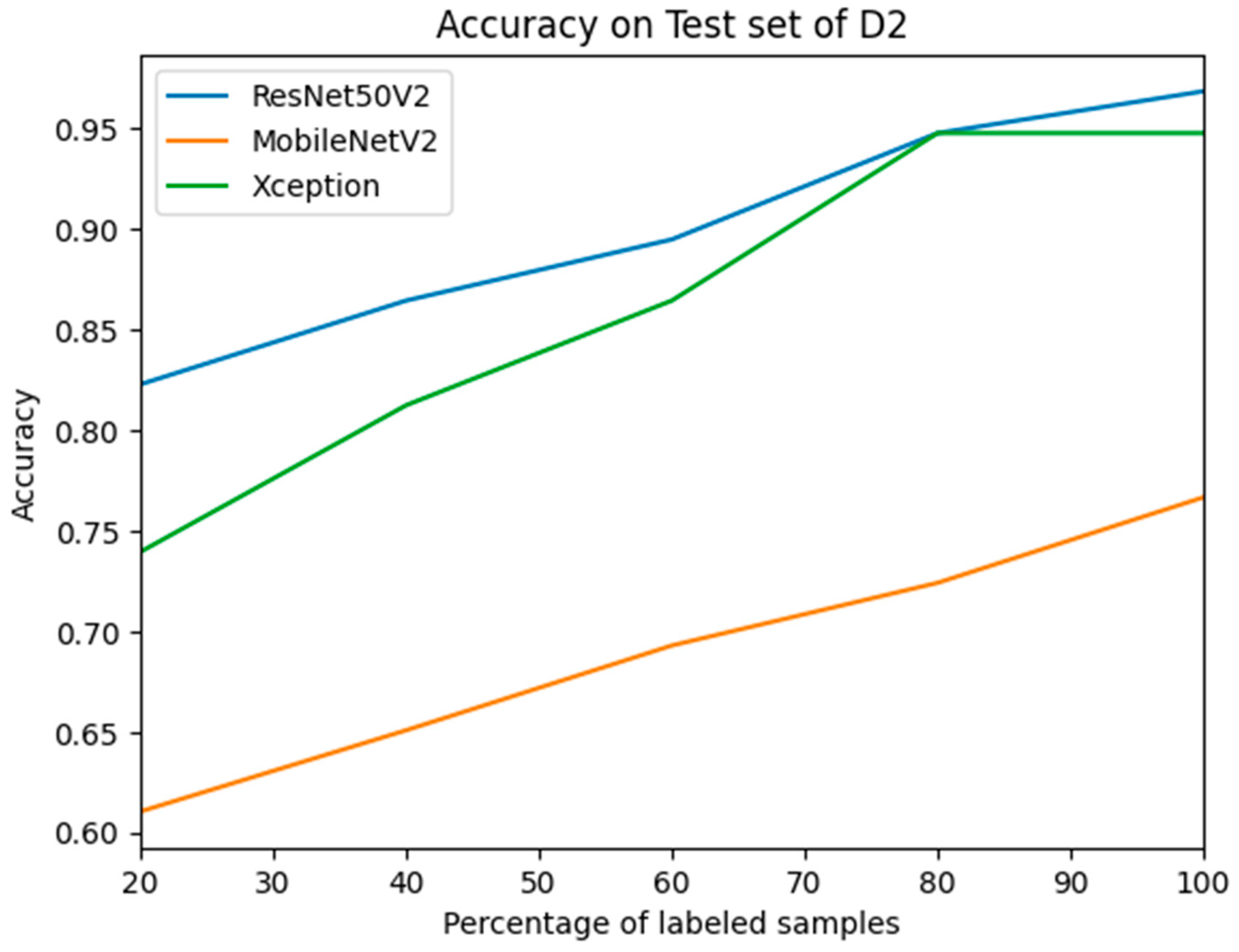
3.3. Performance Evaluation after Active Learning Using D2
4. Discussion
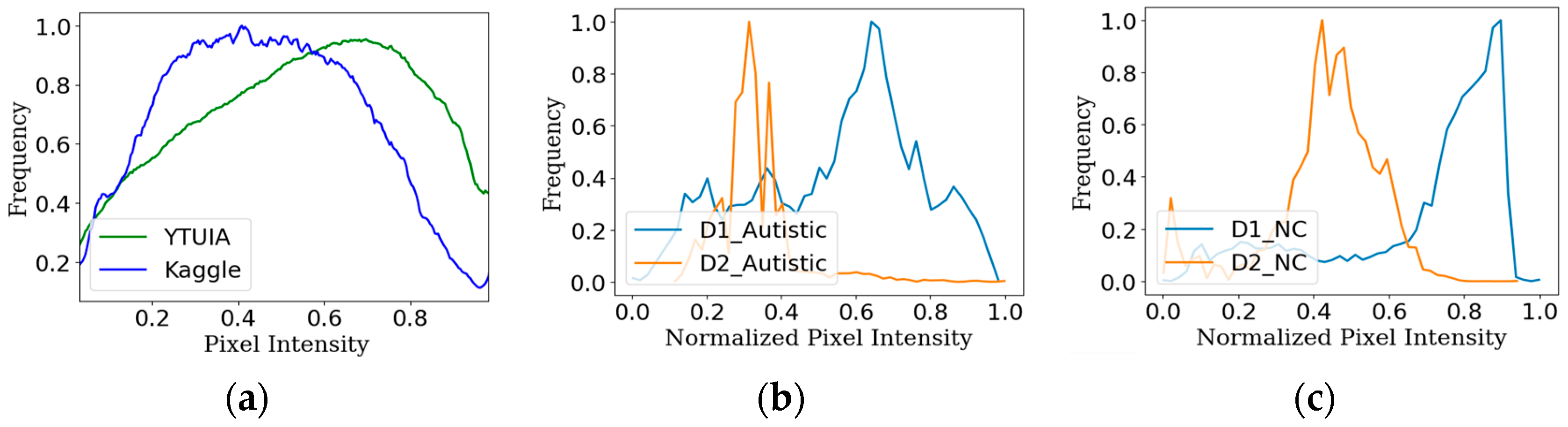
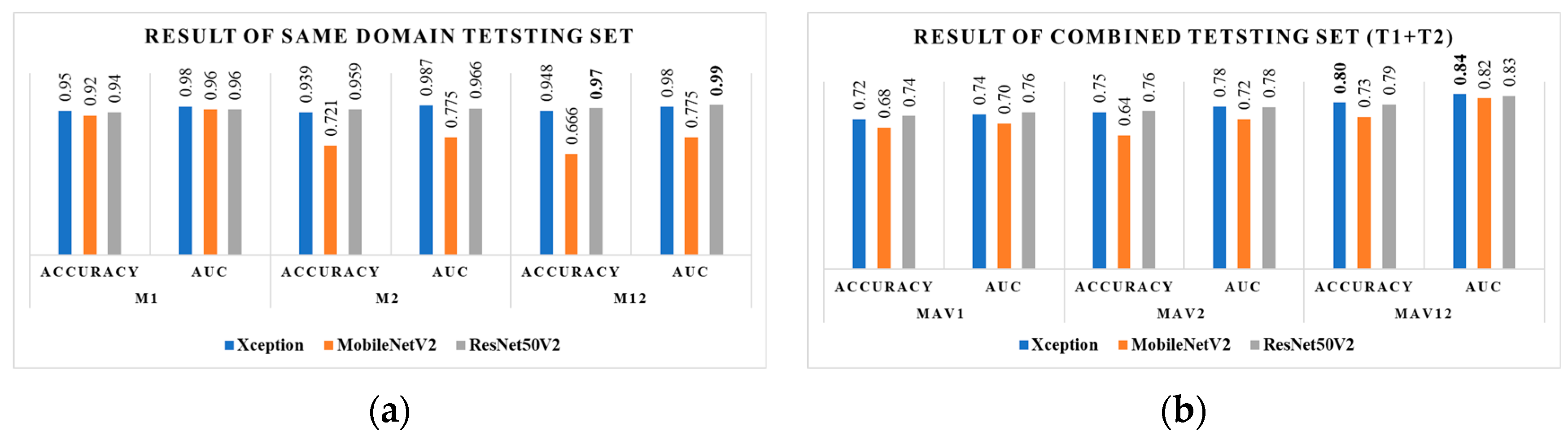
4.1. Evaluation of Same-Domain Test Sets
4.2. Evaluation of Different-Domain Test Sets
4.3. Explaining AI in Active Learning Context
4.4. Comparative Insights: Benchmarking against Recent Research Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghosh, T.; Al Banna, M.H.; Rahman, M.S.; Kaiser, M.S.; Mahmud, M.; Hosen, A.S.M.S.; Cho, G.H. Artificial Intelligence and Internet of Things in Screening and Management of Autism Spectrum Disorder. Sustain. Cities Soc. 2021, 74, 103189. [Google Scholar] [CrossRef]
- Lord, C.; Brugha, T.S.; Charman, T.; Cusack, J.; Dumas, G.; Frazier, T.; Jones, E.J.H.; Jones, R.M.; Pickles, A.; State, M.W.; et al. Autism Spectrum Disorder. Nat. Rev. Dis. Prim. 2020, 6, 5. [Google Scholar] [CrossRef] [PubMed]
- Autism. Available online: https://www.who.int/news-room/fact-sheets/detail/autism-spectrum-disorders (accessed on 5 March 2024).
- Al Banna, M.H.; Ghosh, T.; Taher, K.A.; Kaiser, M.S.; Mahmud, M. A Monitoring System for Patients of Autism Spectrum Disorder Using Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2020; pp. 251–262. [Google Scholar]
- Kojovic, N.; Natraj, S.; Mohanty, S.P.; Maillart, T.; Schaer, M. Using 2D Video-Based Pose Estimation for Automated Prediction of Autism Spectrum Disorders in Young Children. Sci. Rep. 2021, 11, 15069. [Google Scholar] [CrossRef] [PubMed]
- Khodatars, M.; Shoeibi, A.; Sadeghi, D.; Ghaasemi, N.; Jafari, M.; Moridian, P.; Khadem, A.; Alizadehsani, R.; Zare, A.; Kong, Y.; et al. Deep Learning for Neuroimaging-Based Diagnosis and Rehabilitation of Autism Spectrum Disorder: A Review. Comput. Biol. Med. 2021, 139, 104949. [Google Scholar] [CrossRef] [PubMed]
- Abdou, M.A. Literature Review: Efficient Deep Neural Networks Techniques for Medical Image Analysis. Neural Comput. Appl. 2022, 34, 5791–5812. [Google Scholar] [CrossRef]
- Wang, M.; Xu, D.; Zhang, L.; Jiang, H. Application of Multimodal MRI in the Early Diagnosis of Autism Spectrum Disorders: A Review. Diagnostics 2023, 13, 3027. [Google Scholar] [CrossRef] [PubMed]
- Esqueda-Elizondo, J.J.; Juárez-Ramírez, R.; López-Bonilla, O.R.; García-Guerrero, E.E.; Galindo-Aldana, G.M.; Jiménez-Beristáin, L.; Serrano-Trujillo, A.; Tlelo-Cuautle, E.; Inzunza-González, E. Attention Measurement of an Autism Spectrum Disorder User Using EEG Signals: A Case Study. Math. Comput. Appl. 2022, 27, 21. [Google Scholar] [CrossRef]
- Alam, M.S.; Tasneem, Z.; Khan, S.A.; Rashid, M.M. Effect of Different Modalities of Facial Images on ASD Diagnosis Using Deep Learning-Based Neural Network. J. Adv. Res. Appl. Sci. Eng. Technol. 2023, 32, 59–74. [Google Scholar] [CrossRef]
- Cîrneanu, A.-L.; Popescu, D.; Iordache, D. New Trends in Emotion Recognition Using Image Analysis by Neural Networks, a Systematic Review. Sensors 2023, 23, 7092. [Google Scholar] [CrossRef]
- Jung, S.-K.; Lim, H.-K.; Lee, S.; Cho, Y.; Song, I.-S. Deep Active Learning for Automatic Segmentation of Maxillary Sinus Lesions Using a Convolutional Neural Network. Diagnostics 2021, 11, 688. [Google Scholar] [CrossRef]
- Ammari, A.; Mahmoudi, R.; Hmida, B.; Saouli, R.; Hedi Bedoui, M. Deep-Active-Learning Approach towards Accurate Right Ventricular Segmentation Using a Two-Level Uncertainty Estimation. Comput. Med. Imaging Graph. 2023, 104, 102168. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Xin, X.; Zhang, J. Domain Adaptation Using a Three-Way Decision Improves the Identification of Autism Patients from Multisite FMRI Data. Brain Sci. 2021, 11, 603. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, A.; Tong, L.; Zhu, Y.; Wang, M.D. Advancing Medical Imaging Informatics by Deep Learning-Based Domain Adaptation. Yearb. Med. Inform. 2020, 29, 129–138. [Google Scholar] [CrossRef] [PubMed]
- Derbali, M.; Jarrah, M.; Randhawa, P. Autism Spectrum Disorder Detection: Video Games Based Facial Expression Diagnosis Using Deep Learning. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 110–119. [Google Scholar] [CrossRef]
- El Mouatasim, A.; Ikermane, M. Control Learning Rate for Autism Facial Detection via Deep Transfer Learning. Signal Image Video Process. 2023, 17, 3713–3720. [Google Scholar] [CrossRef] [PubMed]
- Gaddala, L.K.; Kodepogu, K.R.; Surekha, Y.; Tejaswi, M.; Ameesha, K.; Kollapalli, L.S.; Kotha, S.K.; Manjeti, V.B. Autism Spectrum Disorder Detection Using Facial Images and Deep Convolutional Neural Networks. Rev. d’Intelligence Artif. 2023, 37, 801–806. [Google Scholar] [CrossRef]
- Kaur, N.; Gupta, G. Refurbished and Improvised Model Using Convolution Network for Autism Disorder Detection in Facial Images. Indones. J. Electr. Eng. Comput. Sci. 2023, 29, 883. [Google Scholar] [CrossRef]
- Singh, A.; Laroia, M.; Rawat, A.; Seeja, K.R. Facial Feature Analysis for Autism Detection Using Deep Learning. In Proceedings of the International Conference On Innovative Computing and Communication, Delhi, India, 17–18 February 2023; pp. 539–551. [Google Scholar]
- Kunda, M.; Zhou, S.; Gong, G.; Lu, H. Improving Multi-Site Autism Classification via Site-Dependence Minimization and Second-Order Functional Connectivity. IEEE Trans. Med. Imaging 2023, 42, 55–65. [Google Scholar] [CrossRef]
- Musser, M. Detecting Autism Spectrum Disorder in Children with Computer Vision. Available online: https://github.com/mm909/Kaggle-Autism (accessed on 23 May 2023).
- Rajagopalan, S.S.; Goecke, R. Detecting Self-Stimulatory Behaviours for Autism Diagnosis. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1470–1474. [Google Scholar]
- Boehringer, A.S.; Sanaat, A.; Arabi, H.; Zaidi, H. An Active Learning Approach to Train a Deep Learning Algorithm for Tumor Segmentation from Brain MR Images. Insights Imaging 2023, 14, 141. [Google Scholar] [CrossRef]
- Budd, S.; Robinson, E.C.; Kainz, B. A Survey on Active Learning and Human-in-the-Loop Deep Learning for Medical Image Analysis. Med. Image Anal. 2021, 71, 102062. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, D.; Xie, H.; Zhang, S.; Gu, L. Mammographic Image Classification System via Active Learning. J. Med. Biol. Eng. 2019, 39, 569–582. [Google Scholar] [CrossRef]
- Guan, H.; Liu, M. Domain Adaptation for Medical Image Analysis: A Survey. IEEE Trans. Biomed. Eng. 2022, 69, 1173–1185. [Google Scholar] [CrossRef] [PubMed]
- Karim, S.; Iqbal, M.S.; Ahmad, N.; Ansari, M.S.; Mirza, Z.; Merdad, A.; Jastaniah, S.D.; Kumar, S. Gene Expression Study of Breast Cancer Using Welch Satterthwaite T-Test, Kaplan-Meier Estimator Plot and Huber Loss Robust Regression Model. J. King Saud Univ.-Sci. 2023, 35, 102447. [Google Scholar] [CrossRef]
- Van Pham, H.; Thanh, D.H.; Moore, P. Hierarchical Pooling in Graph Neural Networks to Enhance Classification Performance in Large Datasets. Sensors 2021, 21, 6070. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.; Liu, S.; Zhao, C.; Li, S. An Instance- and Label-Based Feature Selection Method in Classification Tasks. Information 2023, 14, 532. [Google Scholar] [CrossRef]
- Agarwal, D.; Marques, G.; de la Torre-Díez, I.; Franco Martin, M.A.; García Zapiraín, B.; Martín Rodríguez, F. Transfer Learning for Alzheimer’s Disease through Neuroimaging Biomarkers: A Systematic Review. Sensors 2021, 21, 7259. [Google Scholar] [CrossRef]
- Alam, M.S.; Rashid, M.M.; Roy, R.; Faizabadi, A.R.; Gupta, K.D.; Ahsan, M.M. Empirical Study of Autism Spectrum Disorder Diagnosis Using Facial Images by Improved Transfer Learning Approach. Bioengineering 2022, 9, 710. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Amsterdam, The Netherlands, 2016; pp. 630–645. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1800–1807. [Google Scholar]
- Oliphant, T.E. Python for Scientific Computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef]
- Rashid, M.M.; Alam, M.S. Power of Alignment: Exploring the Effect of Face Alignment on Asd Diagnosis Using Facial Images. IIUM Eng. J. 2024, 25, 317–327. [Google Scholar] [CrossRef]
- Chaddad, A.; Peng, J.; Xu, J.; Bouridane, A. Survey of Explainable AI Techniques in Healthcare. Sensors 2023, 23, 634. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Alam, M.S.; Rashid, M.M.; Faizabadi, A.R.; Mohd Zaki, H.F.; Alam, T.E.; Ali, M.S.; Gupta, K.D.; Ahsan, M.M. Efficient Deep Learning-Based Data-Centric Approach for Autism Spectrum Disorder Diagnosis from Facial Images Using Explainable AI. Technologies 2023, 11, 115. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Wang, Q.; Chen, L.; Shi, J.; Chen, X.; Li, Z.; Shen, D. Multi-Class ASD Classification Based on Functional Connectivity and Functional Correlation Tensor via Multi-Source Domain Adaptation and Multi-View Sparse Representation. IEEE Trans. Med. Imaging 2020, 39, 3137–3147. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Li, Z.; Zhang, D. Unsupervised Domain Adaptation for Multi-Center Autism Spectrum Disorder Identification. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1608–1613. [Google Scholar]
- Bhaumik, R.; Pradhan, A.; Das, S.; Bhaumik, D.K. Predicting Autism Spectrum Disorder Using Domain-Adaptive Cross-Site Evaluation. Neuroinformatics 2018, 16, 197–205. [Google Scholar] [CrossRef]
- Lu, A.; Perkowski, M. Deep Learning Approach for Screening Autism Spectrum Disorder in Children with Facial Images and Analysis of Ethnoracial Factors in Model Development and Application. Brain Sci. 2021, 11, 1446. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Refs. | Author | Algorithm | Accuracy | Dataset | Active Learning | Domain Adaptation |
|---|---|---|---|---|---|---|
| [16] | M. Derbali et al. (2023) | VGGFace | 92.30 | Kaggle | No | NR |
| [17] | A. Mouatasim et al. (2023) | Densnet121 | 91.00 | Kaggle | No | NR |
| [18] | L. K. Gaddala et al. (2023) | VGG16 | 88.00 | Kaggle | No | NR |
| [19] | N. Kaur et al. (2023) | VGG16 | 68.54 | Kaggle | No | NR |
| [20] | A. Singh et al. (2023) | MobileNet | 88.00 | Kaggle | No | NR |
| M1 = Evaluation on T1 with Weight w1 | Mav1 = Evaluation on T1 + T2 with Weight w1 | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Accuracy | Precision | f1-Score | AUC | Accuracy | Precision | f1-Score | AUC |
| Xception | 0.950 | 0.950 | 0.940 | 0.98 | 0.720 | 0.720 | 0.720 | 0.743 |
| MobileNetV2 | 0.920 | 0.920 | 0.920 | 0.96 | 0.680 | 0.680 | 0.680 | 0.699 |
| ResNet50V2 | 0.940 | 0.940 | 0.940 | 0.96 | 0.735 | 0.735 | 0.735 | 0.755 |
| M2 = Evaluation on T2 with Weight w2 | Mav2 = Evaluation on T1 + T2 with Weight w2 | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Accuracy | Precision | f1-Score | AUC | Accuracy | Precision | f1-Score | AUC |
| Xception | 0.939 | 0.939 | 0.939 | 0.987 | 0.754 | 0.754 | 0.754 | 0.780 |
| MobileNetV2 | 0.721 | 0.721 | 0.721 | 0.775 | 0.641 | 0.641 | 0.641 | 0.720 |
| ResNet50V2 | 0.959 | 0.959 | 0.959 | 0.966 | 0.759 | 0.759 | 0.759 | 0.778 |
| M12 = Evaluation on T2 with Weight w12 | Mav12 = Evaluation on T1 + T2 with Weight w12 | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Accuracy | Precision | f1-Score | AUC | Accuracy | Precision | f1-Score | AUC |
| Xception | 0.948 | 0.948 | 0.948 | 0.978 | 0.801 | 0.801 | 0.801 | 0.841 |
| MobileNetV2 | 0.666 | 0.667 | 0.667 | 0.775 | 0.731 | 0.731 | 0.731 | 0.820 |
| ResNet50V2 | 0.969 | 0.969 | 0.969 | 0.991 | 0.790 | 0.790 | 0.790 | 0.833 |
| Detail of Dataset | Method | Accuracy | Refs. |
|---|---|---|---|
| Neuroimaging dataset (fMRI) | |||
| ABIDE from 20 different sites | MIDA | 73.00 | [21] |
| ABIDE from 5 different sites | maLRR | 73.44 | [41] |
| ABIDE from 17 different sites | MCDA | 73.45 | [42] |
| ABIDE | PLS | 62.00 | [43] |
| Facial image dataset | |||
| 1.Kaggle ASD, East Asian | Federated learning | 75.20 | [44] |
| 1.Kaggle ASD, 2. TYUIA | Active learning | 80.01 | Proposed |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alam, M.S.; Elsheikh, E.A.A.; Suliman, F.M.; Rashid, M.M.; Faizabadi, A.R. Innovative Strategies for Early Autism Diagnosis: Active Learning and Domain Adaptation Optimization. Diagnostics 2024, 14, 629. https://doi.org/10.3390/diagnostics14060629
Alam MS, Elsheikh EAA, Suliman FM, Rashid MM, Faizabadi AR. Innovative Strategies for Early Autism Diagnosis: Active Learning and Domain Adaptation Optimization. Diagnostics. 2024; 14(6):629. https://doi.org/10.3390/diagnostics14060629
Chicago/Turabian StyleAlam, Mohammad Shafiul, Elfatih A. A. Elsheikh, F. M. Suliman, Muhammad Mahbubur Rashid, and Ahmed Rimaz Faizabadi. 2024. "Innovative Strategies for Early Autism Diagnosis: Active Learning and Domain Adaptation Optimization" Diagnostics 14, no. 6: 629. https://doi.org/10.3390/diagnostics14060629