
An Ensemble of Deep Learning Object Detection Models for Anatomical and Pathological Regions in Brain MRI

Abstract
:1. Introduction
- A comprehensive ensemble-based object detection study for anatomical and pathological object detection in brain MRI.
- A total of nine state-of-the-art object detection models were employed to propose and evaluate four distinct ensemble strategies aimed at improving the accuracy and robustness of detecting anatomical and pathological regions in brain MRIs. The efficacy of these strategies was empirically assessed through rigorous experiments.
- A comparative evaluation of the current state-of-the-art object detection models for identifying anatomical and pathological regions in brain MRIs was conducted as a benchmarking study in the novel Gazi Brains 2020 dataset.
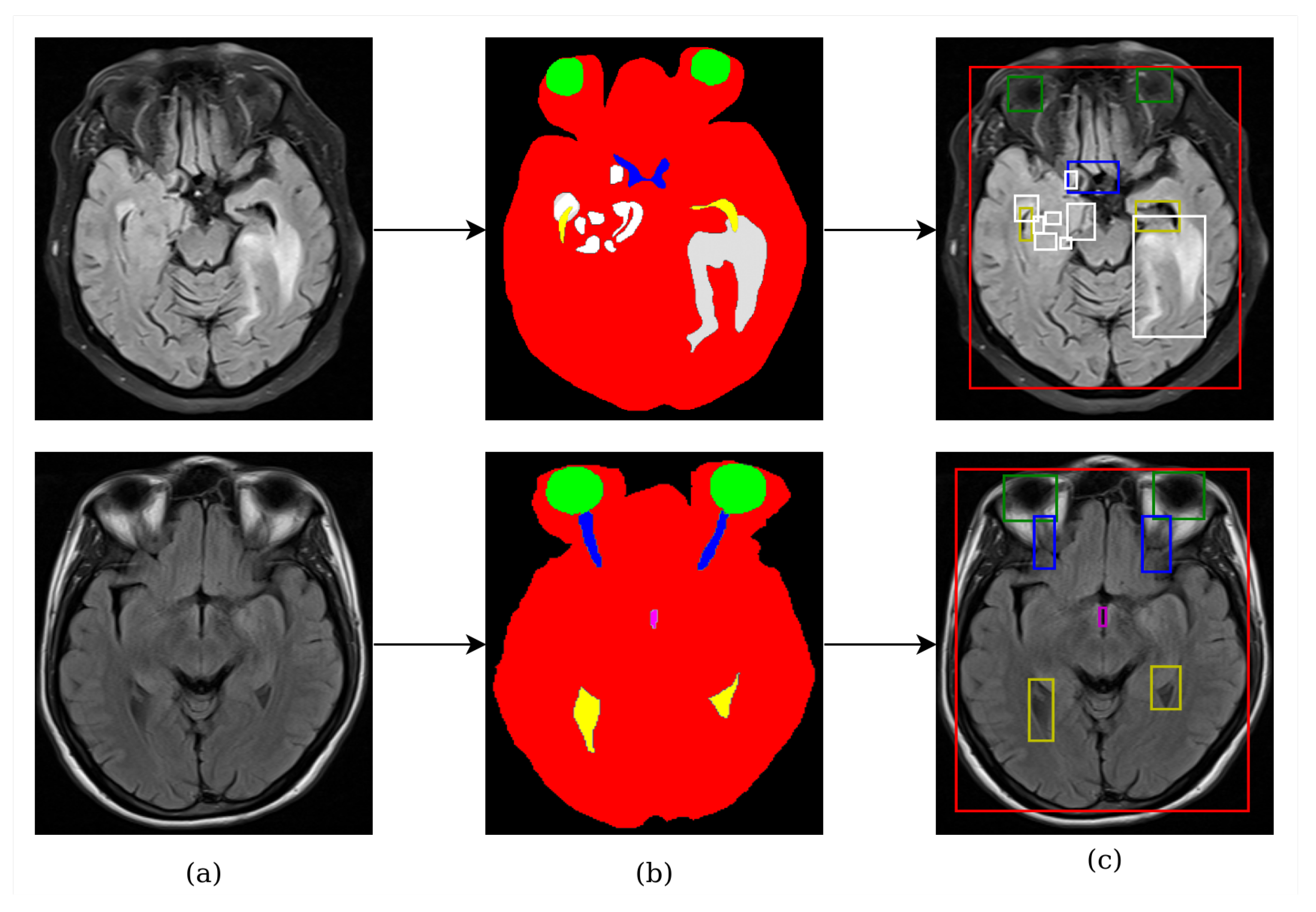
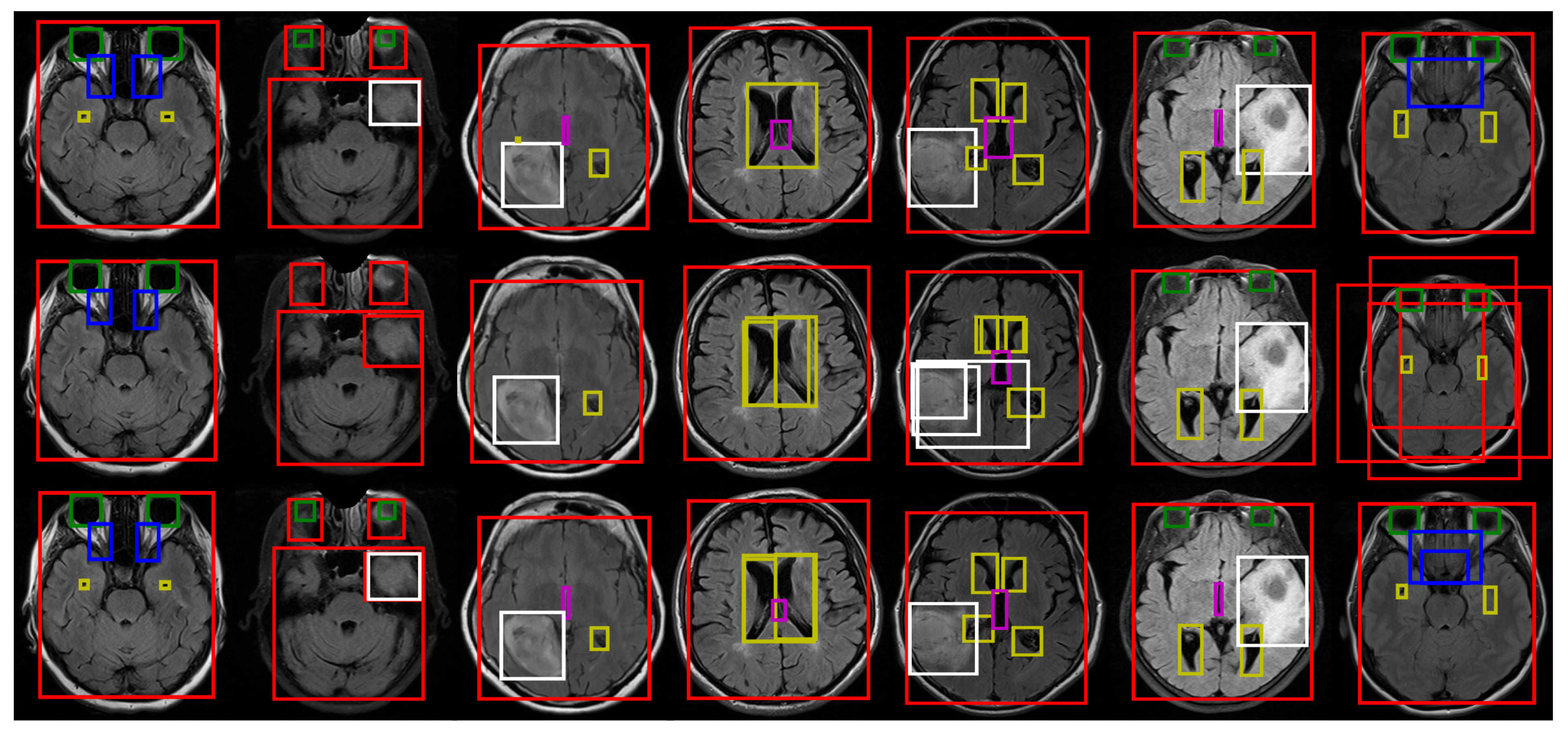
- Five different anatomical structures such as the brain tissue, eyes, optic nerves, lateral ventricles, and the third ventricle, as well as pathological objects including whole tumor parts seen in brain MRI, were detected simultaneously.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Purpose | Methods | Ensemble Strategy | Learning Task | Year |
|---|---|---|---|---|---|
| [28] | Brain tissue segmentation for infant | Custom 3D CNN | Model outputs are combined using majority voting | Segmentation | 2019 |
| [29] | Tumor segmentation | Potential Field Segmentation, FOR, and PFC | Model outputs are combined by rule | Segmentation | 2016 |
| [32] | Tumor classification | AlexNet, VGG, ResNet, and GoogleNet | Model outputs are combined using majority voting | Classification | 2022 |
| [24] | Tumor classification | Custom CNN, EfficientNet-B0, and ResNet, Support Vector Machine, Random Forest, K-Nearest Neighbor, and AdaBoost. | Feature level ensemble | Classification | 2022 |
| [25] | Tumor classification | EfficientNet and ResNet | Feature level ensemble | Classification | 2022 |
| [37] | Alzheimer’s disease classification | SVM, Logistic Regression, Naive Bayes, and K-Nearest Neighbor | Model outputs are combined using majority voting | Classification | 2022 |
| [36] | Parkinson’s detection | VGG16, ResNet, Inception-V3, and Xception | Model outputs are combined using fuzzy logic | Classification | 2022 |
| [30] | Tumor segmentation and survival prediction | 3D U-Net Variants | Model outputs are averaged | Segmentation | 2020 |
| [31] | Tumor segmentation | Basic Encoder–Decoder, U-Net, and SegNet model | Models outputs are combined based on accuracy | Segmentation | 2022 |
| [26] | Tumor segmentation | PIF-Net | Pixel and feature level ensemble | Segmentation | 2022 |
| [27] | Age estimation | Ridge Regression and Support Vector Regression (SVR) and Resnet | Feature level ensemble | Regression | 2021 |
| [33] | Tumor detection with federated learning | DenseNet, VGG, and Inception V3 | Model outputs are combined using majority voting | Classification | 2022 |
| [35] | Tumor classification | ResNet, DenseNet, VGG, AlexNet, Inception V3, ResNext, ShuffleNet, MobileNet, MnasNet, FC layer, Gaussian NB, AdaBoost, K-NN, RF, SVM, and ELM | Model outputs are averaged | Classification | 2021 |
| [38] | Tumor classification | VGG, SqueezeNet, GoogleNet, ResNet, XceptionNet, InceptionV3, ShuffleNet, DenseNet, SVM, MLP, and AdaBoost | Features and classifiers ensemble | Classification | 2022 |
| [34] | Tumor classification | SVM, Naive Bayes, and K-NN | Model outputs are combined using majority voting | Classification | 2023 |
| This study | Anatomical and pathological object detection | RetinaNet, YOLOv3, FCOS, NAS-FPN, ATSS, VFNet, Faster R-CNN, Dynamic R-CNN, and Cascade R-CNN | Model bounding box outputs are recalculated using weighted sum | Object Detection |
2. Materials and Methods
2.1. Dataset
2.2. Deep Learning Architectures for Anatomical and Pathological Object Detection
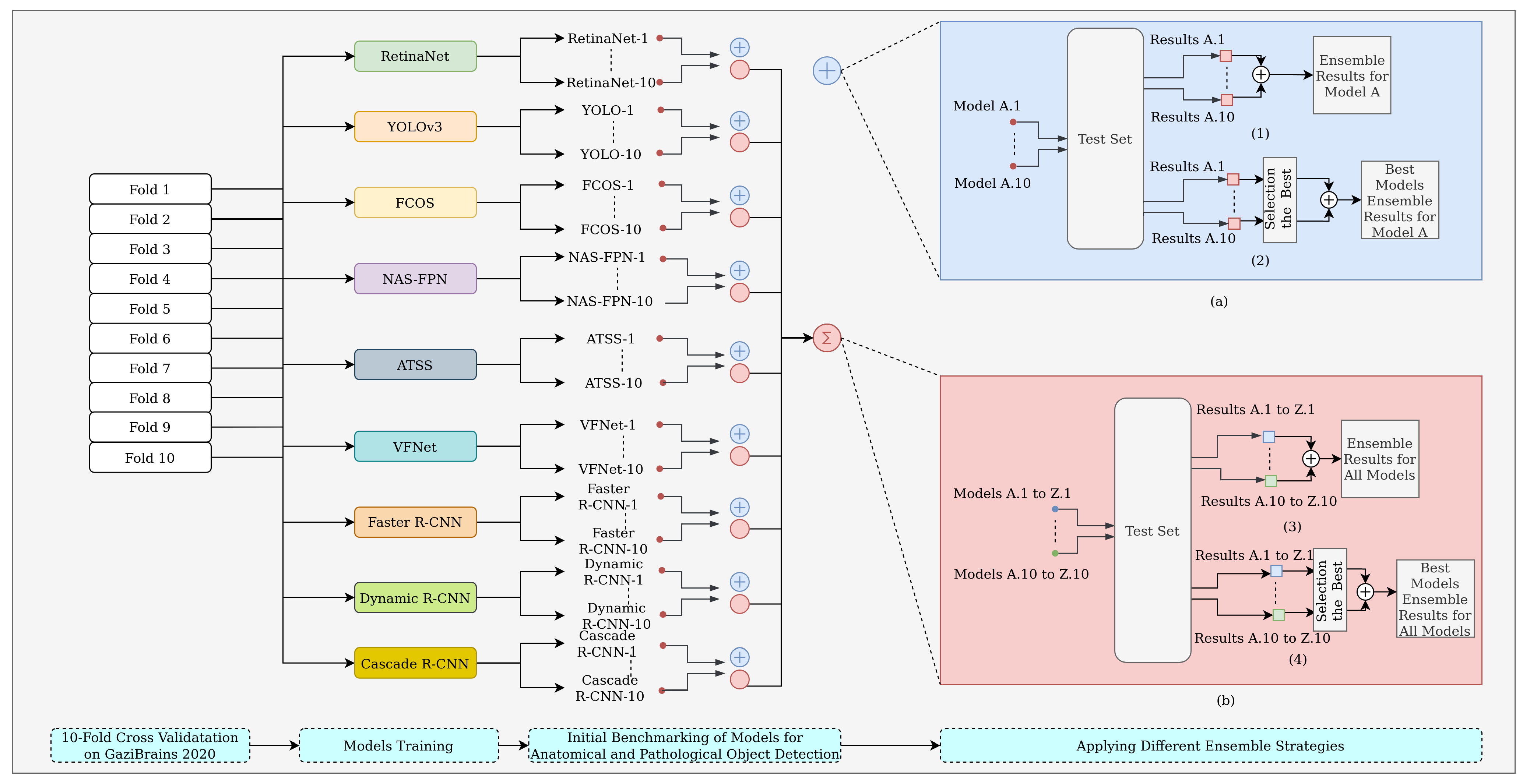
2.3. Model Ensemble
- Strategy 1: an ensemble of all cross-validated folds for a model;
- Strategy 2: an ensemble of the best folds for a model;
- Strategy 3: an ensemble of different models fold-by-fold;
- Strategy 4: an ensemble of the best different models.
3. Results
3.1. Evaluation Metrics
3.2. Experimental Setup
3.3. Experimental Results
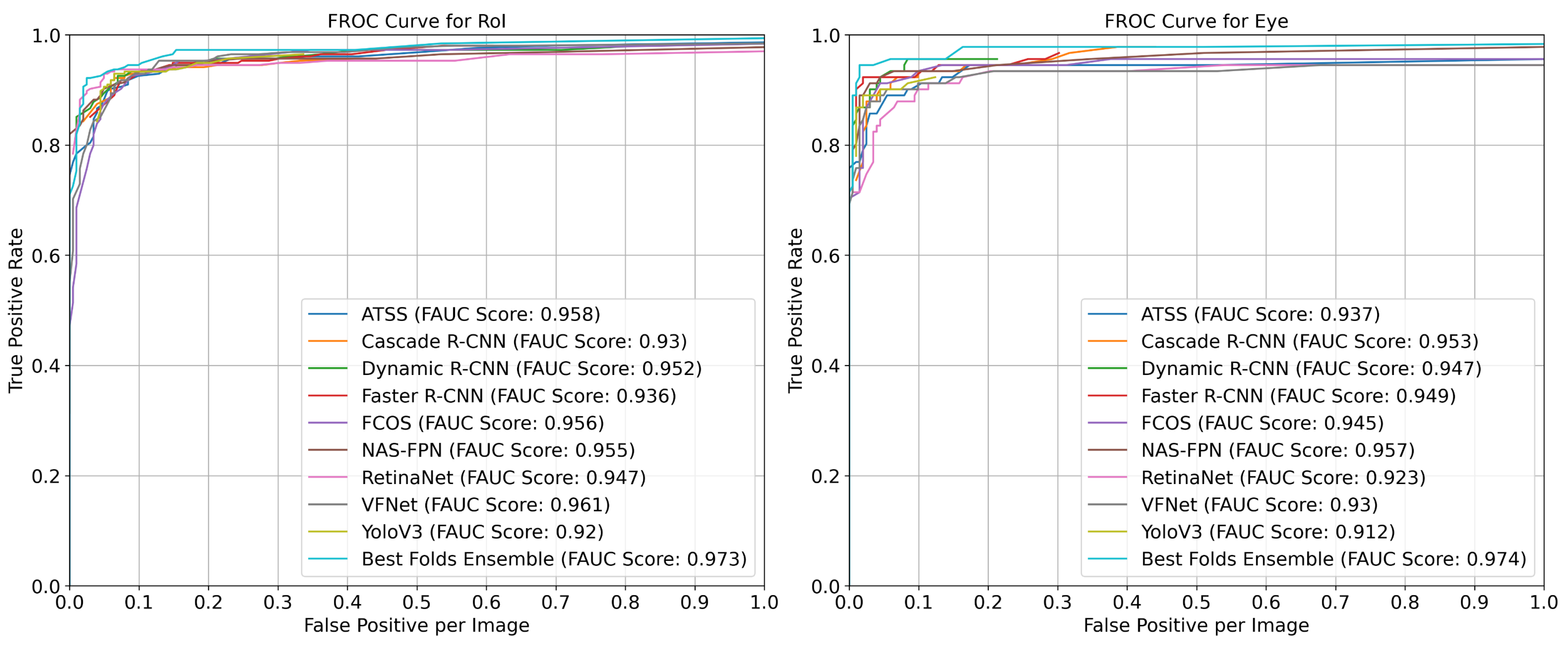
- All the models had similar success results for the brain ROI object;
- The Dynamic R-CNN had a 0.95 AP(@0.5 IoU) value for the eye object;
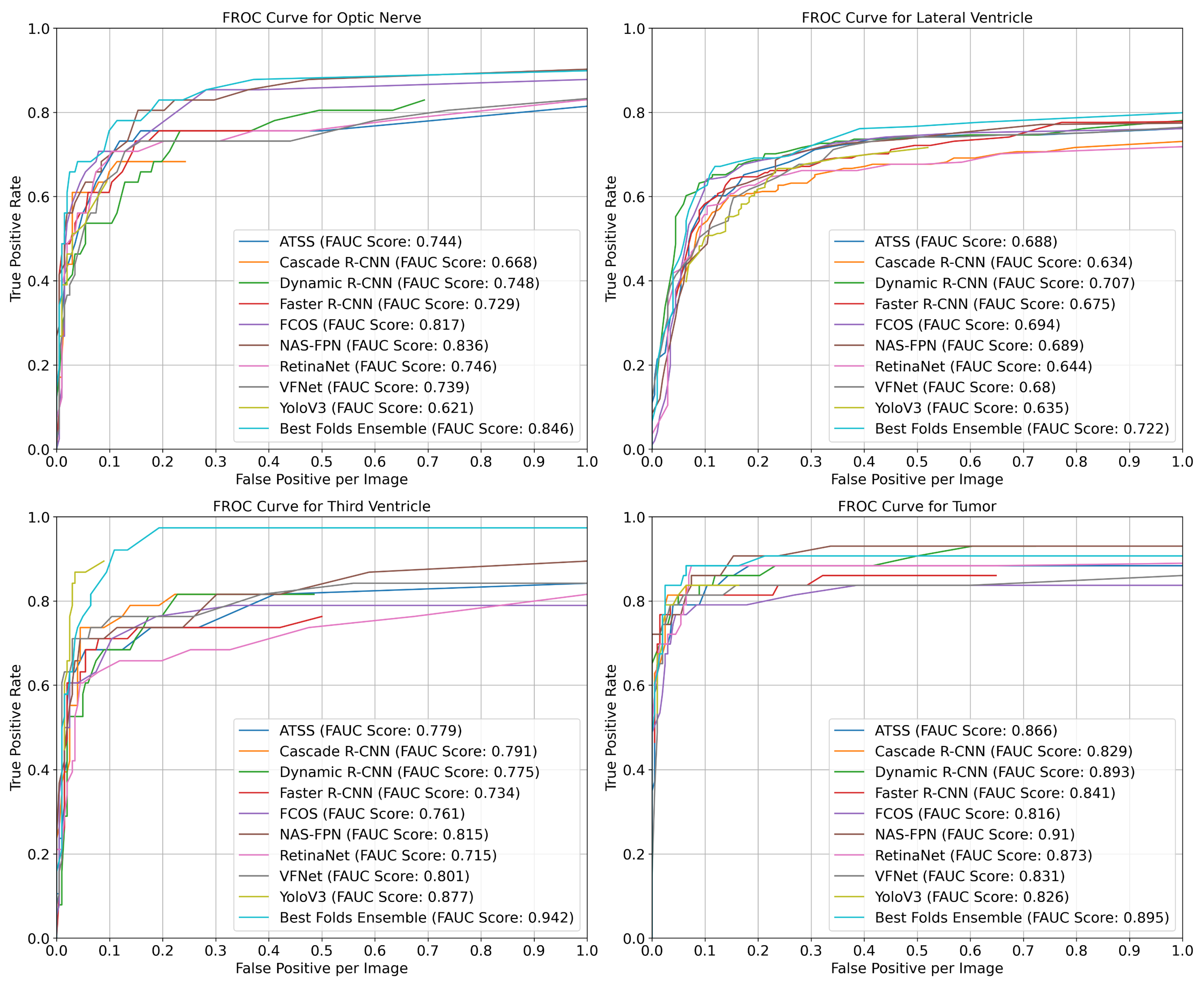
- The RetinaNet and VFNet models had a 0.59 AP(@0.5 IoU) value for the optic nerve object;
- The NAS-FPN and YOLOv3 models had a 0.62 AP(@0.5 IoU) value for the third ventricle object;
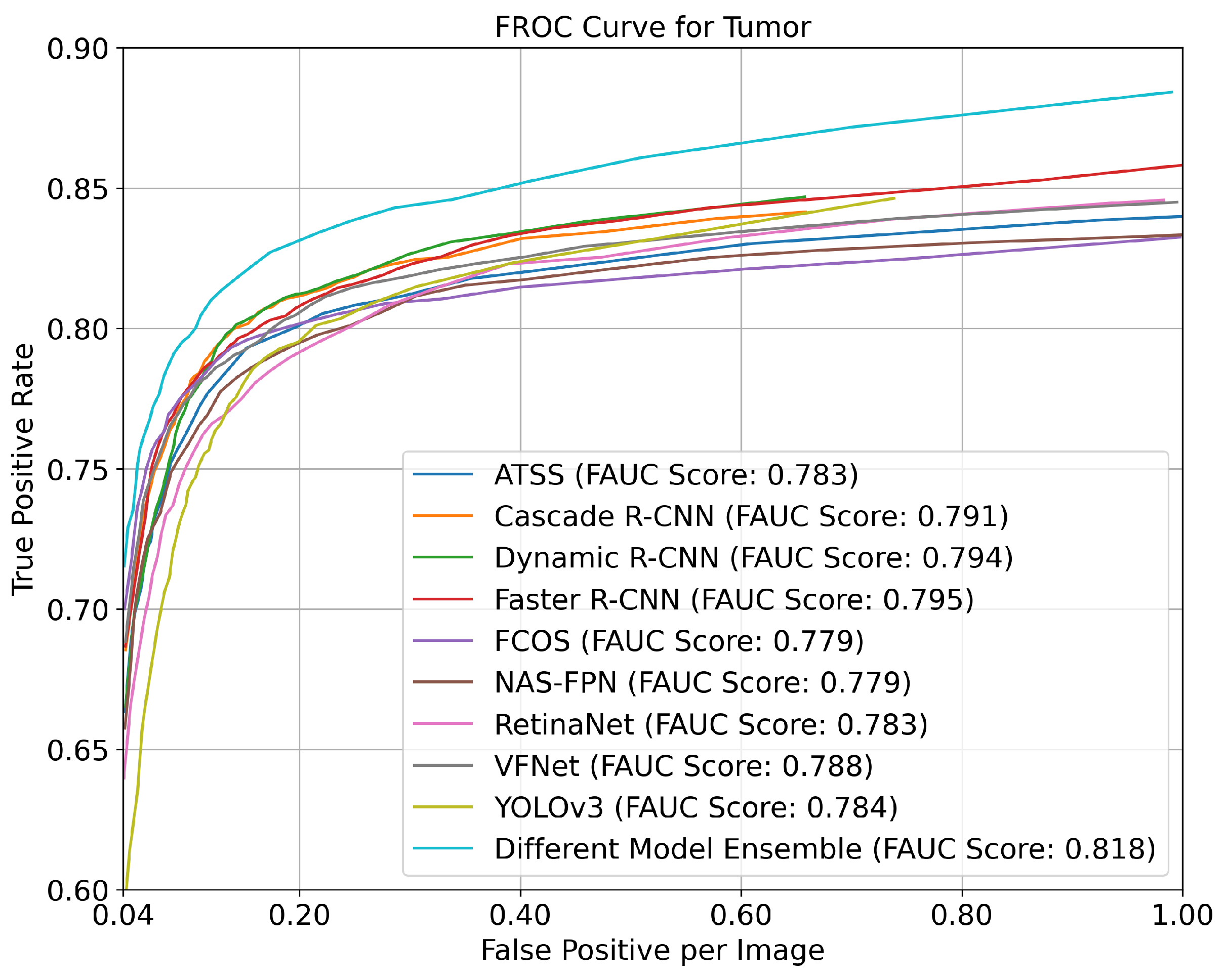
- The NAS-FPN and RetinaNet had a 0.82 AP(@0.5 IoU) value for the tumor object;
- The most successful model according to the mean average precision was the NAS-FPN with a 0.76 (±0.02) (@0.5 IoU) mAP value.
4. Discussion
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abraham, T.; Feng, J. Evolution of brain imaging instrumentation. Semin. Nucl. Med. 2011, 41, 202–219. [Google Scholar] [CrossRef]
- Lenroot, R.K.; Giedd, J.N. Brain development in children and adolescents: Insights from anatomical magnetic resonance imaging. Neurosci. Biobehav. Rev. 2006, 30, 718–729. [Google Scholar] [CrossRef] [PubMed]
- Schwarz, A.J.; Danckaert, A.; Reese, T.; Gozzi, A.; Paxinos, G.; Watson, C.; Merlo-Pich, E.V.; Bifone, A. A stereotaxic MRI template set for the rat brain with tissue class distribution maps and co-registered anatomical atlas: Application to pharmacological MRI. Neuroimage 2006, 32, 538–550. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Kushibar, K.; Asfaw, D.S.; Valverde, S.; Oliver, A.; Martí, R.; Lladó, X. Deep convolutional neural networks for brain image analysis on magnetic resonance imaging: A review. Artif. Intell. Med. 2019, 95, 64–81. [Google Scholar] [CrossRef] [PubMed]
- Hanson, S.J.; Halchenko, Y.O. Brain reading using full brain support vector machines for object recognition: There is no “face” identification area. Neural Comput. 2008, 20, 486–503. [Google Scholar] [CrossRef]
- Akkus, Z.; Galimzianova, A.; Hoogi, A.; Rubin, D.L.; Erickson, B.J. Deep learning for brain MRI segmentation: State of the art and future directions. J. Digit. Imaging 2017, 30, 449–459. [Google Scholar] [CrossRef]
- Bermudez, C.; Plassard, A.J.; Chaganti, S.; Huo, Y.; Aboud, K.S.; Cutting, L.E.; Resnick, S.M.; Landman, B.A. Anatomical context improves deep learning on the brain age estimation task. Magn. Reson. Imaging 2019, 62, 70–77. [Google Scholar] [CrossRef]
- Li, H.; Deklerck, R.; De Cuyper, B.; Hermanus, A.; Nyssen, E.; Cornelis, J. Object recognition in brain CT-scans: Knowledge-based fusion of data from multiple feature extractors. IEEE Trans. Med. Imaging 1995, 14, 212–229. [Google Scholar]
- Bly, B.M.; Kosslyn, S.M. Functional anatomy of object recognition in humans: Evidence from positron emission tomography and functional magnetic resonance imaging. Curr. Opin. Neurol. 1997, 10, 5–9. [Google Scholar] [CrossRef]
- Heckemann, R.A.; Hajnal, J.V.; Aljabar, P.; Rueckert, D.; Hammers, A. Automatic anatomical brain MRI segmentation combining label propagation and decision fusion. NeuroImage 2006, 33, 115–126. [Google Scholar] [CrossRef]
- Tu, Z.; Narr, K.L.; Dollár, P.; Dinov, I.; Thompson, P.M.; Toga, A.W. Brain anatomical structure segmentation by hybrid discriminative/generative models. IEEE Trans. Med. Imaging 2008, 27, 495–508. [Google Scholar]
- Bagci, U.; Chen, X.; Udupa, J.K. Hierarchical scale-based multiobject recognition of 3-D anatomical structures. IEEE Trans. Med. Imaging 2011, 31, 777–789. [Google Scholar] [CrossRef]
- Cerrolaza, J.J.; Villanueva, A.; Cabeza, R. Hierarchical statistical shape models of multiobject anatomical structures: Application to brain MRI. IEEE Trans. Med. Imaging 2011, 31, 713–724. [Google Scholar] [CrossRef]
- Bagci, U.; Udupa, J.K.; Mendhiratta, N.; Foster, B.; Xu, Z.; Yao, J.; Chen, X.; Mollura, D.J. Joint segmentation of anatomical and functional images: Applications in quantification of lesions from PET, PET-CT, MRI-PET, and MRI-PET-CT images. Med. Image Anal. 2013, 17, 929–945. [Google Scholar] [CrossRef] [PubMed]
- de Brebisson, A.; Montana, G. Deep neural networks for anatomical brain segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 20–28. [Google Scholar]
- Alansary, A.; Oktay, O.; Li, Y.; Le Folgoc, L.; Hou, B.; Vaillant, G.; Kamnitsas, K.; Vlontzos, A.; Glocker, B.; Kainz, B.; et al. Evaluating reinforcement learning agents for anatomical landmark detection. Med. Image Anal. 2019, 53, 156–164. [Google Scholar] [CrossRef]
- Roy, S.; Bandyopadhyay, S.K. A new method of brain tissues segmentation from MRI with accuracy estimation. Procedia Comput. Sci. 2016, 85, 362–369. [Google Scholar] [CrossRef]
- Roy, S.; Bhattacharyya, D.; Bandyopadhyay, S.K.; Kim, T.H. An iterative implementation of level set for precise segmentation of brain tissues and abnormality detection from MR images. IETE J. Res. 2017, 63, 769–783. [Google Scholar] [CrossRef]
- Akil, M.; Saouli, R.; Kachouri, R. Fully automatic brain tumor segmentation with deep learning-based selective attention using overlapping patches and multi-class weighted cross-entropy. Med. Image Anal. 2020, 63, 101692. [Google Scholar]
- Liu, M.; Zhang, J.; Nie, D.; Yap, P.T.; Shen, D. Anatomical landmark based deep feature representation for MR images in brain disease diagnosis. IEEE J. Biomed. Health Inform. 2018, 22, 1476–1485. [Google Scholar] [CrossRef]
- Basher, A.; Choi, K.Y.; Lee, J.J.; Lee, B.; Kim, B.C.; Lee, K.H.; Jung, H.Y. Hippocampus localization using a two-stage ensemble Hough convolutional neural network. IEEE Access 2019, 7, 73436–73447. [Google Scholar] [CrossRef]
- Chegraoui, H.; Philippe, C.; Dangouloff-Ros, V.; Grigis, A.; Calmon, R.; Boddaert, N.; Frouin, F.; Grill, J.; Frouin, V. Object Detection Improves Tumour Segmentation in MR Images of Rare Brain Tumours. Cancers 2021, 13, 6113. [Google Scholar] [CrossRef]
- Xuan, J.; Adali, T.; Wang, Y.J.; Siegel, E.L. Automatic detection of foreign objects in computed radiography. J. Biomed. Opt. 2000, 5, 425–431. [Google Scholar] [CrossRef] [PubMed]
- Aurna, N.F.; Yousuf, M.A.; Taher, K.A.; Azad, A.; Moni, M.A. A classification of MRI brain tumor based on two stage feature level ensemble of deep CNN models. Comput. Biol. Med. 2022, 146, 105539. [Google Scholar] [CrossRef]
- Aamir, M.; Rahman, Z.; Dayo, Z.A.; Abro, W.A.; Uddin, M.I.; Khan, I.; Imran, A.S.; Ali, Z.; Ishfaq, M.; Guan, Y.; et al. A deep learning approach for brain tumor classification using MRI images. Comput. Electr. Eng. 2022, 101, 108105. [Google Scholar] [CrossRef]
- Liu, Y.; Mu, F.; Shi, Y.; Cheng, J.; Li, C.; Chen, X. Brain tumor segmentation in multimodal MRI via pixel-level and feature-level image fusion. Multimodal Brain Image Fusion Methods Eval. Appl. 2023, 16648714, 62. [Google Scholar] [CrossRef]
- Kuo, C.Y.; Tai, T.M.; Lee, P.L.; Tseng, C.W.; Chen, C.Y.; Chen, L.K.; Lee, C.K.; Chou, K.H.; See, S.; Lin, C.P. Improving individual brain age prediction using an ensemble deep learning framework. Front. Psychiatry 2021, 12, 626677. [Google Scholar] [CrossRef]
- Dolz, J.; Desrosiers, C.; Wang, L.; Yuan, J.; Shen, D.; Ayed, I.B. Deep CNN ensembles and suggestive annotations for infant brain MRI segmentation. Comput. Med. Imaging Graph. 2020, 79, 101660. [Google Scholar] [CrossRef] [PubMed]
- Cabria, I.; Gondra, I. MRI segmentation fusion for brain tumor detection. Inf. Fusion 2017, 36, 1–9. [Google Scholar] [CrossRef]
- Feng, X.; Tustison, N.J.; Patel, S.H.; Meyer, C.H. Brain tumor segmentation using an ensemble of 3d u-nets and overall survival prediction using radiomic features. Front. Comput. Neurosci. 2020, 14, 25. [Google Scholar] [CrossRef]
- Das, S.; Bose, S.; Nayak, G.K.; Saxena, S. Deep learning-based ensemble model for brain tumor segmentation using multi-parametric MR scans. Open Comput. Sci. 2022, 12, 211–226. [Google Scholar] [CrossRef]
- Tandel, G.S.; Tiwari, A.; Kakde, O. Performance enhancement of MRI-based brain tumor classification using suitable segmentation method and deep learning-based ensemble algorithm. Biomed. Signal Process. Control 2022, 78, 104018. [Google Scholar] [CrossRef]
- Islam, M.; Reza, M.T.; Kaosar, M.; Parvez, M.Z. Effectiveness of Federated Learning and CNN Ensemble Architectures for Identifying Brain Tumors Using MRI Images. Neural Process. Lett. 2022, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Ghafourian, E.; Samadifam, F.; Fadavian, H.; Jerfi Canatalay, P.; Tajally, A.; Channumsin, S. An Ensemble Model for the Diagnosis of Brain Tumors through MRIs. Diagnostics 2023, 13, 561. [Google Scholar] [CrossRef]
- Kang, J.; Ullah, Z.; Gwak, J. MRI-based brain tumor classification using ensemble of deep features and machine learning classifiers. Sensors 2021, 21, 2222. [Google Scholar] [CrossRef]
- Kurmi, A.; Biswas, S.; Sen, S.; Sinitca, A.; Kaplun, D.; Sarkar, R. An Ensemble of CNN Models for Parkinson’s Disease Detection Using DaTscan Images. Diagnostics 2022, 12, 1173. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, S.; Byun, Y.C. Voting Ensemble Approach for Enhancing Alzheimer’s Disease Classification. Sensors 2022, 22, 7661. [Google Scholar] [CrossRef]
- Zahoor, M.M.; Qureshi, S.A.; Bibi, S.; Khan, S.H.; Khan, A.; Ghafoor, U.; Bhutta, M.R. A new deep hybrid boosted and ensemble learning-based brain tumor analysis using MRI. Sensors 2022, 22, 2726. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef] [PubMed]
- Mueller, S.G.; Weiner, M.W.; Thal, L.J.; Petersen, R.C.; Jack, C.R.; Jagust, W.; Trojanowski, J.Q.; Toga, A.W.; Beckett, L. Ways toward an early diagnosis in Alzheimer’s disease: The Alzheimer’s Disease Neuroimaging Initiative (ADNI). Alzheimer’s Dement. 2005, 1, 55–66. [Google Scholar] [CrossRef]
- Maier, O.; Wilms, M.; von der Gablentz, J.; Krämer, U.M.; Münte, T.F.; Handels, H. Extra tree forests for sub-acute ischemic stroke lesion segmentation in MR sequences. J. Neurosci. Methods 2015, 240, 89–100. [Google Scholar] [CrossRef]
- GaziBrais2020. Synapse. Available online: https://www.synapse.org/#!Synapse:syn22159468 (accessed on 23 January 2023).
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Terzi, R.; Azginoglu, N.; Terzi, D.S. False positive repression: Data centric pipeline for object detection in brain MRI. Concurr. Comput. Pract. Exp. 2021, 34, e6821. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. A review of object detection models based on convolutional neural network. In Intelligent Computing: Image Processing Based Applications; Springer: Singapore, 2020; pp. 1–16. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards high quality object detection via dynamic training. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 260–275. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted boxes fusion: Ensembling boxes from different object detection models. Image Vis. Comput. 2021, 107, 104117. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]






| Total Patients | 100 patients (50 normal, 50 HGG) |
| Total Number of Slices | 2209 |
| Number of Anatomical and Pathological Objects | Brain ROI: 2209 Eye: 476 Optic Nerve: 233 Lateral Ventricle: 789 Third Ventricle 388 Peritumoral Edema: 427 Contrast Enhancing Part: 309 Tumor Necrosis: 221 Hemorrhage: 23 No Contrast Enhancing Part: 77 |
| Number of Structures Seen in Slices | Brain ROI: 2628 Eye: 928 Optic Nerve: 357 Lateral Ventricle: 1988 Third Ventricle: 403 Whole Tumor: 556 |
| Models | Backbone | Common Hyperparameters |
|---|---|---|
| ATSS Cascade R-CNN Dynamic R-CNN Faster R-CNN FCOS NAS-FPN RetinaNet VFNet YOLOv3 | ResNet_101 ResNext_101 ResNet_50 ResNext_101 ResNext_101 ResNet_50 with RetinaNet ResNext_101 ResNext_101 Darknet_53 | sample_per_gpu:4 workers_per_gpu:2 image_size:512*512 optimizer:SGD lr_rate:5e-3 lr_config:linear step epoch_num:50 gpu_num:4 augmentation: random brightness (0.15) contrast (0.15) vertical flip |
| Model | Brain ROI | Eye | Optic Nerve | Lateral Ventricle | Third Ventricle | Whole Tumor | mAP |
|---|---|---|---|---|---|---|---|
| ATSS | 0.96 (±0.01) | 0.92 (±0.02) | 0.57 (±0.04) | 0.64 (±0.02) | 0.56 (±0.05) | 0.79 (±0.02) | 0.74 (±0.01) |
| Cascade R-CNN | 0.96 (±0.01) | 0.93 (±0.02) | 0.55 (±0.04) | 0.63 (±0.02) | 0.51 (±0.08) | 0.79 (±0.03) | 0.73 (±0.02) |
| Dynamic R-CNN | 0.96 (±0.01) | 0.95 (±0.01) | 0.40 (±0.06) | 0.66 (±0.01) | 0.45 (±0.06) | 0.81 (±0.02) | 0.71 (±0.01) |
| Faster R-CNN | 0.95 (±0.01) | 0.94 (±0.01) | 0.48 (±0.05) | 0.64 (±0.01) | 0.45 (±0.06) | 0.79 (±0.03) | 0.71 (±0.02) |
| FCOS | 0.96 (±0.01) | 0.94 (±0.01) | 0.54 (±0.07) | 0.65 (±0.01) | 0.55 (±0.06) | 0.77 (±0.04) | 0.73 (±0.02) |
| NAS-FPN | 0.96 (±0.01) | 0.93 (±0.02) | 0.58 (±0.08) | 0.64 (±0.02) | 0.62 (±0.05) | 0.82 (±0.04) | 0.76 (±0.02) |
| RetinaNet | 0.96 (±0.01) | 0.91 (±0.01) | 0.59 (±0.04) | 0.61 (±0.03) | 0.49 (±0.05) | 0.82 (±0.02) | 0.73 (±0.01) |
| VFNet | 0.96 (±0.01) | 0.92 (±0.01) | 0.59 (±0.06) | 0.66 (±0.02) | 0.58 (±0.05) | 0.78 (±0.03) | 0.75 (±0.02) |
| YOLOv3 | 0.74 (±0.03) | 0.90 (±0.01) | 0.44 (±0.05) | 0.57 (±0.02) | 0.62 (±0.06) | 0.74 (±0.03) | 0.67 (±0.01) |
| Model | Ensemble Strategy | Brain ROI | Eye | Optic Nerve | Lateral Ventricle | Third Ventricle | Whole Tumor | mAP | Dif. |
|---|---|---|---|---|---|---|---|---|---|
| ATSS | Best Fold | 0.97 | 0.91 | 0.61 | 0.66 | 0.64 | 0.81 | 0.765 | - |
| Mean+ Folds | 0.97 | 0.94 | 0.64 | 0.67 | 0.68 | 0.81 | 0.784 | 0.02 | |
| All Folds | 0.97 | 0.94 | 0.66 | 0.67 | 0.65 | 0.82 | 0.785 | 0.02 | |
| Cascade R-CNN | Best Fold | 0.94 | 0.95 | 0.58 | 0.60 | 0.64 | 0.81 | 0.754 | - |
| Mean+ Folds | 0.98 | 0.95 | 0.66 | 0.68 | 0.61 | 0.82 | 0.783 | 0.03 | |
| All Folds | 0.97 | 0.95 | 0.67 | 0.68 | 0.60 | 0.82 | 0.783 | 0.03 | |
| Dynamic R-CNN | Best Fold | 0.96 | 0.94 | 0.45 | 0.67 | 0.50 | 0.82 | 0.723 | - |
| Mean+ Folds | 0.97 | 0.94 | 0.56 | 0.67 | 0.57 | 0.84 | 0.757 | 0.03 | |
| All Folds | 0.97 | 0.96 | 0.52 | 0.69 | 0.59 | 0.83 | 0.760 | 0.04 | |
| Faster R-CNN | Best Fold | 0.96 | 0.93 | 0.57 | 0.63 | 0.54 | 0.79 | 0.738 | - |
| Mean+ Folds | 0.97 | 0.96 | 0.63 | 0.66 | 0.53 | 0.83 | 0.762 | 0.02 | |
| All Folds | 0.98 | 0.96 | 0.61 | 0.68 | 0.53 | 0.81 | 0.760 | 0.02 | |
| FCOS | Best Fold | 0.96 | 0.93 | 0.65 | 0.65 | 0.61 | 0.78 | 0.762 | - |
| Mean+ Folds | 0.96 | 0.95 | 0.58 | 0.66 | 0.55 | 0.80 | 0.749 | -0.01 | |
| All Folds | 0.97 | 0.94 | 0.65 | 0.67 | 0.58 | 0.81 | 0.768 | 0.01 | |
| NAS-FPN | Best Fold | 0.97 | 0.95 | 0.71 | 0.66 | 0.69 | 0.86 | 0.805 | - |
| Mean+ Folds | 0.98 | 0.95 | 0.69 | 0.70 | 0.69 | 0.86 | 0.812 | 0.01 | |
| All Folds | 0.98 | 0.95 | 0.68 | 0.71 | 0.74 | 0.87 | 0.820 | 0.02 | |
| Retinanet | Best Fold | 0.96 | 0.91 | 0.61 | 0.61 | 0.54 | 0.83 | 0.745 | - |
| Mean+ Folds | 0.97 | 0.91 | 0.61 | 0.66 | 0.59 | 0.82 | 0.761 | 0.02 | |
| All Folds | 0.98 | 0.92 | 0.65 | 0.65 | 0.62 | 0.81 | 0.770 | 0.03 | |
| VFNet | Best Fold | 0.97 | 0.92 | 0.62 | 0.66 | 0.67 | 0.79 | 0.772 | - |
| Mean+ Folds | 0.98 | 0.93 | 0.69 | 0.70 | 0.66 | 0.82 | 0.793 | 0.02 | |
| All Folds | 0.98 | 0.95 | 0.67 | 0.70 | 0.65 | 0.81 | 0.792 | 0.02 | |
| YOLOv3 | Best Fold | 0.75 | 0.90 | 0.43 | 0.57 | 0.70 | 0.74 | 0.683 | - |
| Mean+ Folds | 0.81 | 0.93 | 0.61 | 0.66 | 0.80 | 0.82 | 0.772 | 0.09 | |
| All Folds | 0.84 | 0.94 | 0.60 | 0.67 | 0.85 | 0.83 | 0.787 | 0.10 |
| Ensemble Strategy | Brain ROI | Eye | Optic Nerve | Lateral Ventricle | Third Ventricle | Whole Tumor | mAP |
|---|---|---|---|---|---|---|---|
| All Folds - 1 | 0.98 | 0.95 | 0.67 | 0.73 | 0.72 | 0.87 | 0.820 |
| All Folds - 2 | 0.98 | 0.97 | 0.70 | 0.71 | 0.74 | 0.85 | 0.825 |
| All Folds - 3 | 0.98 | 0.96 | 0.68 | 0.71 | 0.67 | 0.86 | 0.810 |
| All Folds - 4 | 0.98 | 0.97 | 0.73 | 0.71 | 0.73 | 0.85 | 0.828 |
| All Folds - 5 | 0.98 | 0.96 | 0.67 | 0.70 | 0.77 | 0.85 | 0.821 |
| All Folds - 6 | 0.98 | 0.96 | 0.68 | 0.71 | 0.72 | 0.85 | 0.815 |
| All Folds - 7 | 0.98 | 0.98 | 0.69 | 0.69 | 0.75 | 0.85 | 0.824 |
| All Folds - 8 | 0.98 | 0.97 | 0.67 | 0.71 | 0.76 | 0.86 | 0.822 |
| All Folds - 9 | 0.98 | 0.96 | 0.68 | 0.71 | 0.64 | 0.86 | 0.804 |
| All Folds - 10 | 0.98 | 0.95 | 0.70 | 0.69 | 0.67 | 0.85 | 0.808 |
| Mean | 0.98 | 0.96 | 0.69 | 0.71 | 0.72 | 0.86 | 0.818 |
| the best (Fold-4) | 0.98 | 0.97 | 0.73 | 0.71 | 0.73 | 0.85 | 0.828 |
| Best Folds * | 0.98 | 0.97 | 0.75 | 0.73 | 0.73 | 0.87 | 0.838 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terzi, R. An Ensemble of Deep Learning Object Detection Models for Anatomical and Pathological Regions in Brain MRI. Diagnostics 2023, 13, 1494. https://doi.org/10.3390/diagnostics13081494
Terzi R. An Ensemble of Deep Learning Object Detection Models for Anatomical and Pathological Regions in Brain MRI. Diagnostics. 2023; 13(8):1494. https://doi.org/10.3390/diagnostics13081494
Chicago/Turabian StyleTerzi, Ramazan. 2023. "An Ensemble of Deep Learning Object Detection Models for Anatomical and Pathological Regions in Brain MRI" Diagnostics 13, no. 8: 1494. https://doi.org/10.3390/diagnostics13081494