
“Quo Vadis Diagnosis”: Application of Informatics in Early Detection of Pneumothorax
 , , ,
, , ,
Abstract
:1. Introduction
- We proposed a DL model, PneumoNet, to classify X-ray images.
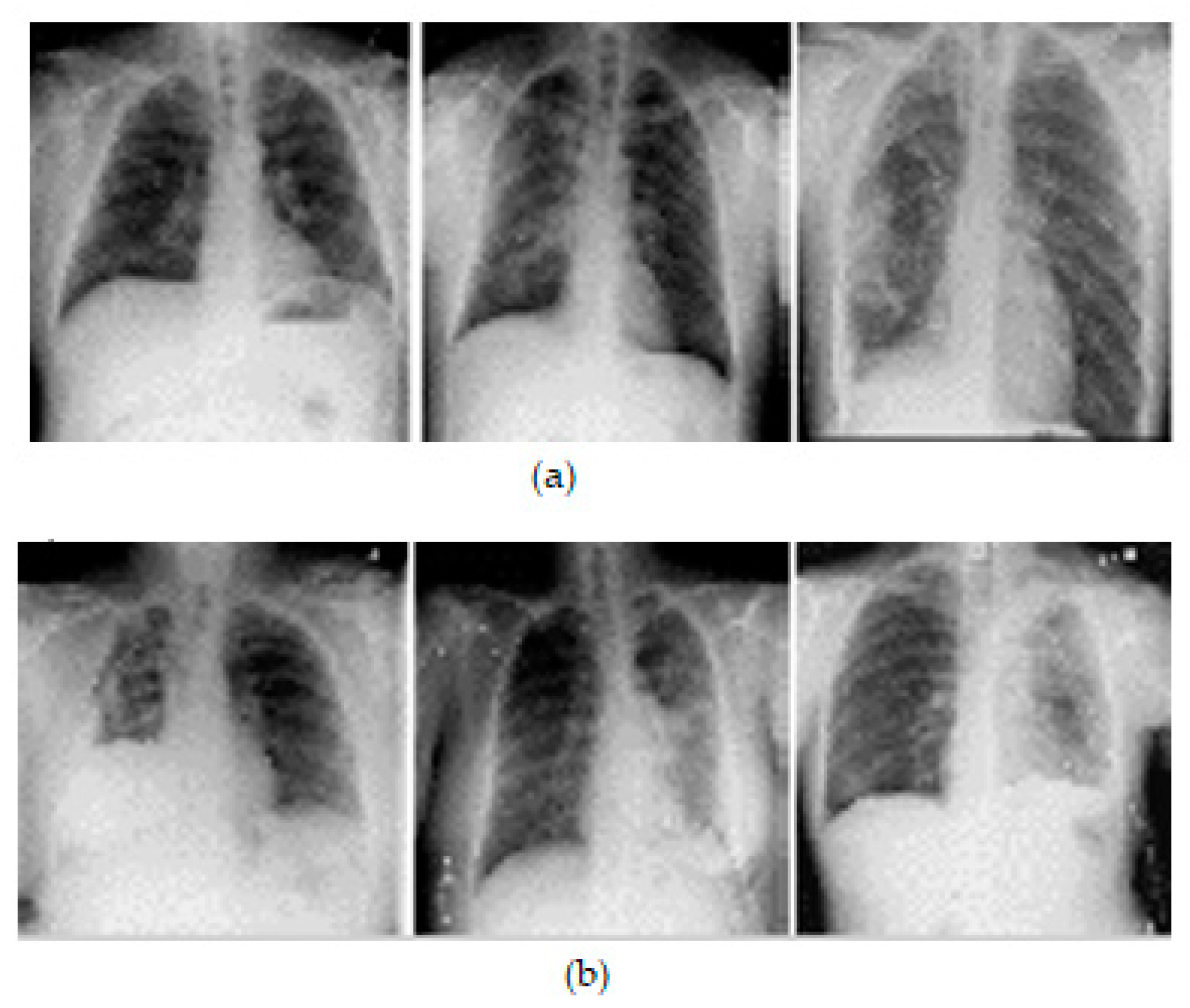
- We utilized a profound and publicly available dataset, the Society for Imaging Informatics in Medicine (SIIM) pneumothorax dataset from Kaggle [15], which is specifically for pneumothorax analyses.
- We proposed a channel optimization technique (COT) to improve the quality of the input image.
- We also used the affine image enhancement tool for image augmentation and noise removal.
- Our proposed PneumoNet model analyzed the input image in the obverse and flip sides of the image, thereby further improving the recognition rate.
- The results of our proposed approach were analyzed using various machine learning parameters to assess its accuracy. The results prove that our proposed approach outperforms the existing DL approaches in detecting pneumothoraces.
2. Related Work
2.1. The Machine Learning Literature
2.2. The Deep Learning Literature
2.3. Heuristic and Hybrid Methods
3. Methods and Materials
3.1. Dataset
3.2. Data Preprocessing
3.3. Data Augmentation
3.4. Image Segmentation
3.5. Proposed PneumoNet Model
3.6. Hyper Parameter Optimization
3.7. Computational Complexities
4. Results
4.1. Analysis of Model’s Accuracy for Various Pneumothoraces
4.2. Ablation Study
4.3. Ablation Study_1: Modifying the Number of Dense and Convolution Layers
4.4. Ablation Study_2: Adjusting the Activation Function
4.5. Ablation Study_3: Varying the Dropout Value
4.6. Ablation Study_4: With and without Channel Optimization
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zarogoulidis, P.; Kioumis, I.; Pitsiou, G.; Porpodis, K.; Lampaki, S.; Papaiwannou, A.; Katsikogiannis, N.; Zaric, B.; Branislav, P.; Secen, N.; et al. Pneumothorax: From definition to diagnosis and treatment. J. Thorac. Dis. 2014, 6 (Suppl. 4), S372–S376. [Google Scholar] [CrossRef]
- Gupta, D.; Hansell, A.; Nichols, T.; Duongb, T.; Ayresa, J.G.; Strachanb, D. Epidemiology of pneumothorax in England. Thorax 2000, 55, 666–671. [Google Scholar] [CrossRef] [Green Version]
- Gang, P.; Zhen, W.; Zeng, W.; Gordienko, Y.; Kochura, Y.; Alienin, O.; Rokovyi, O.; Stirenko, S. Dimensionality reduction in deep learning for chest X-ray analysis of lung cancer. In Proceedings of the 2018 Tenth International Conference on Advanced Computational Intelligence (ICACI), Xiamen, China, 29–31 March 2018; pp. 878–883. [Google Scholar] [CrossRef] [Green Version]
- Cai, J.; Lu, L.; Harrison, A.P.; Shi, X.; Chen, P.; Yang, L. Iterative attention mining for weakly supervised thoracic disease pattern localization in chest X-rays. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 589–598. [Google Scholar]
- Mohan, A.P. Deep Convolutional Neural Networks in Detecting Lung Mass From Chest X-Ray Images. Int. J. Appl. Res. Bioinform. 2021, 11, 22–30. [Google Scholar] [CrossRef]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, C.; Yao, D.; Shi, Y.; Song, Z. Computer-aided detection in chest radiography based on artificial intelligence: A survey. Biomed. Eng. 2018, 17, 113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Setio, A.A.; Ciompi, F.; Litjens, G.; Gerke, P.; Jacobs, C.; van Riel, S.J.; Wille, M.M.; Naqibullah, M.; Sanchez, C.I.; van Ginneken, B. Pulmonary Nodule Detection in CT Images: False Positive Reduction Using Multi-View Convolutional Networks. IEEE Trans. Med Imaging 2016, 35, 1160–1169. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, L.; Jin, Q. Enhanced Diagnosis of Pneumothorax with an Improved Real-Time Augmentation for Imbalanced Chest X-rays Data Based on Deep Conv. Neural NW” IEEE/ACM Trans. Compute. Biol. B. Infs. 2021, 18, 951–962. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Huang, X. Lung nodule detection in CT using 3D CNN. In Proceedings of the IEEE 14th International Symposium on Biomedical Imaging (ISBI), Melbourne, VIC, Australia, 18–21 April 2017; pp. 379–383. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K. Chex Net: Radiologist-Level Pneumonia Detection on Chest X-Rays with DL. Comput. Vis. Pattern Recognit. 2017, 10, 276–281. [Google Scholar] [CrossRef]
- Zawacki; Carol; George; Elliott; Fomitchev; Hussain; Lakhani; Culliton; Siim-Acr-Pneumothorax-Segmentation; Bao; Kaggle. 2019. Available online: https://kaggle.com/competitions/siim-acr-pneumothorax-segmentation (accessed on 10 February 2022).
- Filice, R.W.; Stein, A.; Wu, C.C.; Arteaga, V.A.; Borstelmann, S.; Gaddikeri, R.; Galperin-Aizenberg, M.; Gill, R.R.; Godoy, M.C.; Hobbs, S.B.; et al. Crowdsourcing pneumothorax annotations using machine learning annotations on the NIH chest X-ray dataset. J. Digit. Imaging 2019, 33, 490–496. [Google Scholar] [CrossRef] [PubMed]
- Kumar, D.R.; Krishna, T.A.; Wahi, A. Health Monitoring Framework for in Time Recognition of Pulmonary Embolism Using Internet of Things. J. Comput. Theor. Nanosci. 2018, 15, 1598–1602. [Google Scholar] [CrossRef]
- Pasa, F.; Golkov, V.; Pfeiffer, F.; Cremers, D. Efficient Deep Network Architectures for Fast Chest X-Ray Tuberculosis Screening and Visualization. Sci. Rep. 2019, 9, 6268. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, R.; Rubin, J.; Lam, G.; Berkowitz, S.; Dalal, S.; Wells, W.; Horng, S.; Golland, P. Semi-supervised learning for quantification of pulmonary edema in chest x-ray images. Comput. Vis. Pat. Recogn. 2019, 3, 1319–1326. [Google Scholar]
- Lindsey, T.; Lee, R.; Grisell, R.; Grisell, R.; Vega, S.; Veazey, S. Automated Pneumothorax Diagnosis Using Deep Neural Networks. In Proceedings of the 23rd Iberoamerican Congress, CIARP 2018, Madrid, Spain, 3 March 2019; Springer: Cham, Switzerland, 2018; pp. 723–731. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Networks Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Chan, Y.-H.; Zeng, Y.-Z.; Wu, H.-C.; Wu, M.-C.; Sun, H.-M. Effective Pneumothorax Detection for Chest X-Ray Images Using Local Binary Pattern and Support Vector Machine. J. Healthc. Eng. 2018, 2018, 2908517. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zuo, J.; Zhang, C.; Sun, Y. Pneumothorax Image Segmentation and Prediction with UNet++ and MSOF Strategy. IEEE International Conference on Consumer Electronics & Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 710–713. [Google Scholar] [CrossRef]
- Sundaram, B.; Lakhani, P. Deep Learning at Chest Radiography: Automated Classification of Pulmonary Tuberculosis by Using Convolutional Neural Networks. Radiology 2017, 284, 574–582. [Google Scholar] [CrossRef]
- Yaakob, S.R. Ensemble deep learning for tuberculosis detection. IAES Int. J. AI 2018, 10, 429–435. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems, Lecturer Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 1857. [Google Scholar] [CrossRef] [Green Version]
- Jaeger, S.; Wáng, Y. Two public chest X-ray datasets for computer-aided screening of pulmonary diseases. Quant. Image. Med. Surg. 2014, 4, 475–477. [Google Scholar]
- Li, X.; Thrall, J.H.; Digumarthy, S.R.; Kalra, M.K.; Pandharipande, P.V.; Zhang, B.; Nitiwarangkul, C.; Singh, R.; Khera, R.D.; Li, Q. Deep learning-enabled system for rapid pneumothorax screening on chest CT. Eur. J. Radiol. 2019, 120, 108692. [Google Scholar] [CrossRef] [PubMed]
- Jaszcz, A.; Połap, D.; Damaševičius, R. Lung X-Ray Image Segmentation Using Heuristic Red Fox Optimization Algorithm. Sci. Program. 2022, 2022, 4494139. [Google Scholar] [CrossRef]
- Rajinikanth, V.; Kadry, S.; Damaševičius, R.; Pandeeswaran, C.; Mohammed, M.A.; Devadhas, G.G. Pneumonia Detection in Chest X-ray using InceptionV3 and Multi-Class Classification. In Proceedings of the 3rd International Conference on Intelligent Computing Instrumentation and Control Technologies, Kannur, India, 11–12 August 2022; pp. 972–976. [Google Scholar] [CrossRef]
- Blumenfeld, A.; Greenspan, H.; Konen, E. Pneumothorax detection in chest radiographs using convolutional neural networks. Proc. SPIE 2018, 10575, 3–12. [Google Scholar] [CrossRef]
- Sanada, S.; Doi, K.; MacMahon, H. Image feature analysis and computer-aided diagnosis in digital radiography: Automated detection of pneumothorax in chest images. Med. Phys. 1992, 19, 1153–1160. [Google Scholar] [CrossRef] [PubMed]
- Geva, O.; Zimmerman-Moreno, G.; Lieberman, S.; Konen, E.; Greenspan, H. Pneumothorax detection in chest radiographs using local and global texture signatures. Proc. SPIE 2015, 15, 94141. [Google Scholar] [CrossRef]
- Singh, N.; Hamde, S. Tuberculosis detection using shape and texture features of chest X-rays. In Innovations in Electronics and Communication Engineering; Springer: Greer, SC, USA, 2019; pp. 43–50. [Google Scholar]
- Riasatian, A.; Tizhoosh, H.R. Searching for pneumothorax in x-ray images using auto encoded deep features. Sci. Rep. 2021, 11, 9817. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.M.; Kim, N.; Choe, J.; Cho, Y.; Do, K.-H.; Seo, J.B. Application of deep learning–based computer-aided detection system: Detecting pneumothorax on chest radiograph after biopsy. Eur. Radiol. 2019, 29, 5341–5348. [Google Scholar] [CrossRef]
- Munishamaiaha, K.; Rajagopal, G.; Venkatesan, D.K.; Arif, M.; Vicoveanu, D.; Chiuchisan, I.; Izdrui, D.; Geman, O. Robust Spatial–Spectral Squeeze–Excitation AdaBound Dense Network (SE-AB-Densenet) for Hyperspectral Image Classification. Sensors 2022, 22, 3229. [Google Scholar] [CrossRef]
- Sitaula, C.; Hossain, M.B. Attention-based VGG-16 model for COVID-19 chest X-ray image classification. Appl. Intell. 2020, 51, 2850–2863. [Google Scholar] [CrossRef]
- Malik, H.; Anees, T.; Din, M.; Naeem, A. CDC_Net: Multi-classification convolutional neural network model for detection of COVID-19, pneumothorax, pneumonia, lung Cancer, and tuberculosis using chest X-rays. Multimedia Tools Appl. 2022, 20, 1–26. [Google Scholar] [CrossRef]
- Taylor, A.G.; Mielke, C.; Mongan, J. Automated detection of moderate and large pneumothorax on frontal chest X-rays using deep convolutional neural networks: A retrospective study. PLOS Med. 2018, 15, e1002697. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pandian, J.A.; Kanchanadevi, K.; Kumar, D.; Geman, O. Deep Convolutional Generative Adversarial Network for Metastatic Tissue Diagnosis in Lymph Node Section. In System Design for Epidemics Using Machine Learning and Deep Learning; Springer International Publishing: Berlin/Heidelberg, Germany, 2023; pp. 153–166. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Existing Methods | Methodology | Dataset | Samples Utilized | Accuracy |
|---|---|---|---|---|
| Greenspan et al. [31] | Texture analysis | Upright chest radiographs | 10,832 | 87% |
| Pandiyan. et al. [37] | Ens4B-Unet | Challenge | 12,047 | 86.06% |
| Sundaram et al. [24] | ResNet | SIIM | 11,024 | 91.32% |
| R. Liao et al. [19] | Unet | SIIM | 21,032 | 93.23% |
| S. Hamde et al. [34] | DCNN | Clinical imaging | 30,000 | 94.38% |
| Riasatian et al. [35] | CNN | Self-collected | 12,762 | 93.71% |
| S. Park et al. [36] | Patch-based | SIIM | 14,201 | 92.81% |
| R. Yaakob et al. [25] | AlexNet | CXR dataset | 15,372 | 93.74% |
| Parameters | Samples before Augmentation | Samples after Augmentation |
|---|---|---|
| Image resolution | 1024 × 1024 | 124 × 124 |
| Total no. of samples | 3116 | 11,500 |
| Classes | 2 | 2 |
| Samples trained with pneumothorax | 1623 | 8300 |
| Samples trained without pneumothorax | 838 | 1100 |
| Samples tested with pneumothorax | 382 | 1300 |
| Samples tested without pneumothorax | 273 | 800 |
| Image | No. of Images |
|---|---|
| Original X-ray image | 120 |
| Panned X-ray image | 120 |
| Spun X-ray image | 120 |
| Image rotated to 90° | 120 |
| Image rotated to 180° | 120 |
| Image rotated to 270° | 120 |
| Total images after one round of augmentation | 720 |
| Hyperparameter Optimization | Metrics | Accuracy in % |
|---|---|---|
| Batch Size | 8 | 83.87 |
| 16 | 87.92 | |
| 32 | 95.98 | |
| 64 | 98.41 | |
| 128 | 96.82 | |
| 256 | 91.02 | |
| Learning rate | 0.000461 | 86.31 |
| 0.000372 | 91.09 | |
| 0.000201 | 95.82 | |
| 0.000173 | 98.41 | |
| 0.000199 | 97.81 | |
| 0.00021 | 96.12 | |
| Dropout rate in % | 14.53 | 85.47 |
| 5.72 | 91.11 | |
| 10.76 | 96.87 | |
| 11.02 | 98.41 | |
| 14.51 | 97.88 | |
| 15.78 | 96.17 |
| Model | Parameters | Flops | Accuracy |
|---|---|---|---|
| Efficient Net | 14.2 million | 25.7 G | 89.32% |
| MobileNet | 10.14 million | 24.81 G | 96.75% |
| Inception Rennet | 9.91 million | 19.31 G | 92.43% |
| Proposed PneumoNet | 7.61 million | 12.5 G | 98.41% |
| Model Classification | Accuracy | F1 Score | Specificity | Recall | Precision |
|---|---|---|---|---|---|
| Pneumothorax Affected | 98.41 | 0.983 | 0.978 | 0.981 | 0.981 |
| Pneumothorax Not Affected | 98.53 | 0.976 | 0.973 | 0.987 | 0.963 |
| Sequence of PneumoNet Training | Obverse | Flip | Both |
|---|---|---|---|
| Obverse–Flip–Both | 0.959 | 0.961 | 0.973 |
| Flip–Obverse–Both | 0.962 | 0.971 | 0.966 |
| Both | 0.971 | 0.97 | 0.97 |
| Overall AUC | 0.961 | 0.963 | 0.974 |
| Ratio of Weight (Both–Obverse–Flip) | Obverse | Flip | Both |
|---|---|---|---|
| (1:0.1:0.1) | 0.943 | 0.954 | 0.942 |
| (1:0.2:0.2) | 0.956 | 0.891 | 0.899 |
| (1:0.3:0.3) | 0.953 | 0.963 | 0.951 |
| (1:0.4:0.4) | 0.963 | 0.957 | 0.959 |
| (1:0.5:0.5) | 0.961 | 0.901 | 0.931 |
| (1:0.6:0.6) | 0.966 | 0.965 | 0.967 |
| Final ratio of converged weight | 0.966 | 0.965 | 0.967 |
| Model | Accuracy (%) | F1 Score (%) | Specificity (%) | Recall (%) | Precision (%) |
|---|---|---|---|---|---|
| Undersized pneumothorax (less than 1 cm) | 97.81 | 96.40 | 96.64 | 93.47 | 95.91 |
| Average pneumothorax (1 cm to 2 cm) | 98.13 | 98.17 | 97.11 | 97.28 | 98.20 |
| Outsized pneumothorax (more than 2 cm) | 98.13 | 98.13 | 97.21 | 97.54 | 98.65 |
| Set Up No. | Number of Convolution Layer | Number of Dense Layer | Training Accuracy | Validation Accuracy | Inference |
|---|---|---|---|---|---|
| 1 | 7 | 5 | 65.21% | 69.79% | Accuracy is low |
| 2 | 6 | 4 | 90.71% | 72.65% | Accuracy is low |
| 3 | 5 | 4 | 92.67% | 91.51% | Accuracy is low |
| 4 | 4 | 3 | 93.87% | 93.88% | Accuracy is low |
| 5 | 3 | 3 | 95.67% | 94.81% | Accuracy is low |
| 6 | 2 | 2 | 98.40% | 98.31% | Highest Accuracy |
| Set Up No. | Activation Function Used | Training Accuracy | Validation Accuracy | Inference |
|---|---|---|---|---|
| 1 | Sigmoid | 91.32% | 90.87%. | Accuracy is low |
| 2 | Tanh | 88.92% | 90.62% | Accuracy is low |
| 3 | ReLu | 97.99% | 96.89% | Highest Accuracy |
| Set Up No. | Dropout Rate | Training Accuracy | Validation Accuracy | Inference |
|---|---|---|---|---|
| 1 | 0.2 | 94.72% | 91.75% | Accuracy is low |
| 2 | 0.15 | 94.61% | 90.62% | Accuracy is low |
| 3 | 0.1 | 98.39% | 98.36% | Highest Accuracy |
| Set Up No. | Presence of COT | Accuracy | F1 Score | Inference |
|---|---|---|---|---|
| 1 | Without COT | 94.68% | 93.98% | Accuracy and F1 score are low |
| 2 | With COT | 98.41% | 98.32% | Highest accuracy and F1 score |
| Model | Dataset Used | Accuracy (%) | F1 Score (%) | Specificity (%) | Recall (%) | Precision (%) |
|---|---|---|---|---|---|---|
| Efficient Net [5] | SIIM | 89.32 | 90.3 | 84.6 | 93.4 | 87.6 |
| Inception Rennet [9] | 92.43 | 89.8 | 89.6 | 89.4 | 91.3 | |
| Xception [16] | 84.15 | 91.3 | 85.8 | 89.2 | 91.7 | |
| MobileNet [28] | 96.75 | 93.4 | 92.3 | 89.9 | 94.8 | |
| ResNet [35] | 97.68 | 94.6 | 97.2 | 92.4 | 93.6 | |
| Proposed PneumoNet | 98.4 | 98.3 | 97.8 | 98.5 | 98.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, V.D.; Rajesh, P.; Geman, O.; Craciun, M.D.; Arif, M.; Filip, R. “Quo Vadis Diagnosis”: Application of Informatics in Early Detection of Pneumothorax. Diagnostics 2023, 13, 1305. https://doi.org/10.3390/diagnostics13071305
Kumar VD, Rajesh P, Geman O, Craciun MD, Arif M, Filip R. “Quo Vadis Diagnosis”: Application of Informatics in Early Detection of Pneumothorax. Diagnostics. 2023; 13(7):1305. https://doi.org/10.3390/diagnostics13071305
Chicago/Turabian StyleKumar, V. Dhilip, P. Rajesh, Oana Geman, Maria Daniela Craciun, Muhammad Arif, and Roxana Filip. 2023. "“Quo Vadis Diagnosis”: Application of Informatics in Early Detection of Pneumothorax" Diagnostics 13, no. 7: 1305. https://doi.org/10.3390/diagnostics13071305