1. Introduction
Fatty liver disease (FLD), a global epidemic disease, is an important risk factor for liver cancer [
1,
2]. However, the harm is not limited to the liver itself. Some studies have shown that fatty liver can significantly increase the incidence of fatal and non-fatal cardiovascular events [
3], and FLD patients are more likely to be associated with obesity [
4], hyperlipidemia [
5], hypertension, and type 2 diabetes [
6] than healthy people. Furthermore, as fatty liver disease progresses, the risk of CKD significantly increases with the degree of liver fibrosis [
7]. The fatty liver disease (FLD) guideline for the Asian population [
8] highlights that there is no national epidemiological survey on FLD in China, and the reported studies are mostly from economically developed regions, which may lead to some degree of bias in the epidemiological characteristics. Therefore, early FLD screening is not only necessary to reduce the socioeconomic burden of FLD, but also to improve the epidemiological investigation of FLD in China. For FLD, liver biopsy is undoubtedly the “gold standard” for diagnosis [
9]. However, as a screening method, its high cost and invasive nature do not make it the first choice for fatty liver screening. Analogously, ultrasound, as an effective diagnostic method, relies on the operation and judgment of the ultrasound doctor. Therefore, an urgent need exists to develop cost-saving and non-invasive methods to screen fatty liver.
As a prediction tool, machine learning (ML) represents the latest development of statistics. Unlike the traditional statistical model, which depends on certain assumptions for data and a clear mathematical form, ML does not have any assumptions about the data, and the results eliminate the classical statistical framework based on hypothesis testing. The prediction efficiency of ML models based on algorithms or programs is high, and the results of cross-validation are easy to understand, so ML can be widely used in medical diagnosis trials today. Among them, several ML methods, such as random forest (RF), artificial neural network (ANN), K-nearest neighbor (KNN), and support vector machine (SVM) have played an important role in the prediction of many diseases.
Previous studies [
10] have extracted the gray-value distribution features of children’s liver ultrasound images in a given region of interest, and then constructed an ML discriminant model of liver lesions by a variety of maximum-likelihood classification methods. The prediction accuracy is better than the traditional liver and kidney index and liver echo intensity attenuation index. Acharya et al. [
11] extracted abdominal ultrasound features with the curvelet transform method, reduced features through locality-sensitive discriminant analysis, and used a probabilistic neural network classifier based on only six features to distinguish the normal liver, fatty liver, and liver cirrhosis with an accuracy of 97.33%, specificity of 100%, and sensitivity of 96%.
Based on in-depth ML approaches to diagnosing FLD, there are many artificial methods that can diagnose fatty liver with high accuracy. However, most of these diagnoses are based on abdominal ultrasound or computed tomography (CT) images, which are costly for fatty liver screening. Compared with the image-based ML screening methods, using physical examination data and blood biochemical indexes as predictive indicators can screen fatty liver in an efficient and economical way. Thus, the main purpose of this study was to build an efficient and robust FLD screening ML model based on these indicators.
2. Materials and Methods
2.1. Study Data
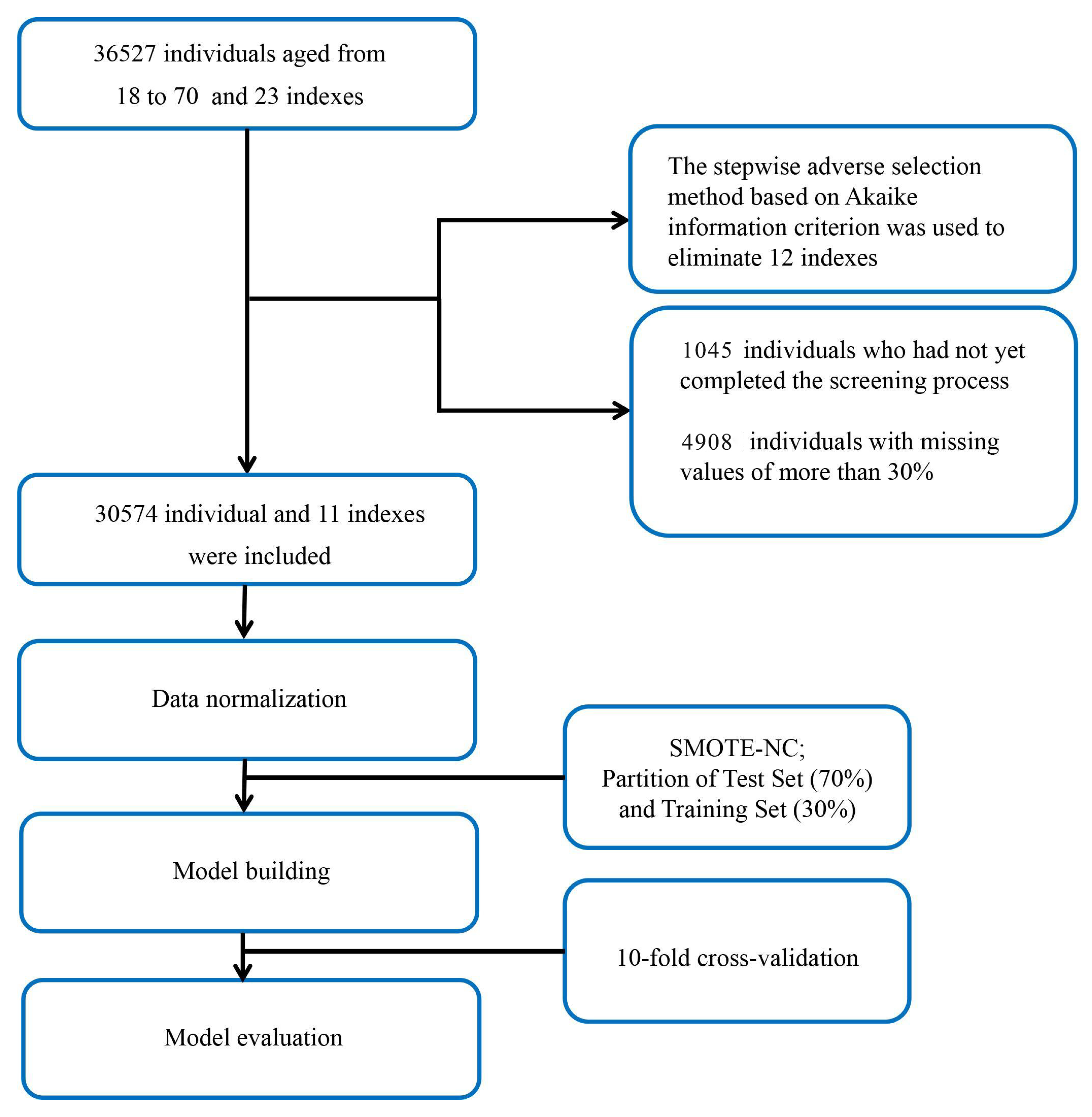
The dataset used in this study was provided by the health management center of the Second Xiangya Hospital of Central South University, Changsha, China, and included the data of 36,527 patients. We enrolled individuals aged 18–70 years from January 2013 to December 2019. During the process of data collection, no privacy information was included. Only 23 indexes, including physical examination data, age, and blood biochemistry indexes were included. Because ML models rely on data integrity, 4908 individuals with missing values of more than 30% were excluded, and the remaining missing values were completed by the multiple interpolation method. In this study, the diagnosis of FLD was based on the results of abdominal ultrasound images. The ultrasound machines used in this study were the Philips Medical Systems model iU22 and model Epiq (Philips Ultrasound, Bothell, WA, USA). All the diagnostic results of abdominal ultrasounds were performed by attending physicians in our hospital’s imaging center and were reviewed by senior physicians. The diagnostic criteria for FLD were based on the guidelines published by the Chinese Medical Association in 2010 [
12]. The diagnosis of FLD was confirmed if at least two of the three following findings were present: diffuse echogenicity enhancement of the liver parenchyma in the near field, stronger than that of the kidney; poor visualization of intrahepatic duct structures; and the gradual attenuation of liver echogenicity in the far field. Therefore, we excluded 1045 individuals who had not yet completed the screening process. Finally, of the 30,574 individuals remaining in the study, 3474 of them were diagnosed with FLD by abdominal ultrasound (
Figure 1).
2.2. Data Processing
In machine learning data preprocessing, class imbalance is a common issue where the number of samples in one category is much larger than in the other. This can present challenges for machine learning models, and the severity of the imbalance depends on the proportion of samples in each category. To address this problem, this study used a synthetic minority over-sampling technique nominal continuous (SMOTE-NC) [
13] to handle unbalanced class data. SMOTE-NC is an extension of the synthetic minority over-sampling technique (SMOTE) that can handle nominal and continuous features. In an imbalanced dataset, SMOTE-NC generates synthetic samples for the minority class by oversampling the existing samples using interpolation. When generating synthetic samples, SMOTE-NC takes into account both continuous and nominal features and ensures that the synthetic samples are representative of the underlying data distribution.
Feature selection is a crucial aspect of classification tasks, as it can significantly impact the performance of the model. The main objective of feature selection is to identify the most relevant subset of features that can improve the accuracy of classification. In the context of the 11 characteristic variables presented in
Table 1, the selection of these variables was based on several factors. These included identifying the most commonly used variables for predicting FLD, adding additional variables to increase the variety of features, and using a stepwise backward selection method based on Akaike Information Criterion (AIC) [
14]. AIC is a powerful tool for assessing the performance of a model in terms of both its predictive accuracy and its complexity. It is founded on the concept of entropy, which enables it to capture the trade-off between these two competing factors. By comparing the AIC values of different models, researchers can identify the most effective and parsimonious one for their purposes. In order to filter features and avoid multicollinearity, this study utilized the reverse stepwise-regression algorithm based on AIC. This involved introducing all variables into an equation, and then iteratively deleting the variable that maximized the AIC value until the minimum AIC value was reached. The resulting variables and their corresponding AIC values are shown in
Table 2. To automate the feature selection process, a R program was used to compare the AIC values of candidate variables and include those that contributed to the model. The variables listed in
Table 2 reflect the remaining variables that were found to contribute to the machine learning model, and the corresponding AIC value indicates the change in AIC value after adding each variable.
We used the createDataPartition function in the caret package to divide the training set and the test set, in which the test set accounted for 70% of all data. Continuous variables were normalized by subtracting the average value and dividing by the standard deviation. To overcome the imbalance problem in the training set, we used the synthetic minority oversampling technique to randomly generate new individuals of the minority, which have similar features to the original individuals of the minority class.
2.3. Establishment of the Model
We used the eight most common classifiers to build an FLD screening model. As one of the most commonly used generalized linear regression models for binary data, logistic regression (LR) can not only provide prediction results, but also indicate the weight of each independent variable in the prediction. RF is a classifier that integrates multiple decision trees. All decision trees are independent of each other, and each decision tree splits the maximum information gain, and finally outputs the results of classification after reaching the threshold; the RF results are based on the majority of all decision trees. As a common two-classification model, the SVM maps the feature vector to the space, and finds the separation hyperplane with the largest interval in the feature space. This approach makes the classification results more robust and improves the generalization ability of the model. Linear discriminant analysis (LDA) is a classical supervised learning method based on data dimensionality reduction, which classifies the data by projecting the data from a high-dimensional space to a lower-dimensional space and ensuring that the intra-class variance of each class is small and that the mean difference between classes is large. Quantitative descriptive analysis (QDA) is a variant of LDA that allows the nonlinear separation of data. KNN is regarded as a nonparametric, lazy algorithm model that is based on adjacent samples with the minimum Euclidean distance. This model makes no assumptions about the data, and there is no clear training data process. Because it assigns the same weight to different features, the model is easily affected by noise. Extreme gradient boosting (XGBoost) is an improved boosting algorithm based on the gradient boosted decision tree (GBDT) method. Unlike with classical GBDT, second-order Taylor expansion is used in XGBoost on the error part of the loss function, which improves the accuracy of the loss function definition. Because of the L2 regularization in the cost function, the complexity of the XGBoost model is controlled, which greatly reduces the possibility of overfitting. Because of these characteristics, XGBoost has excellent classification and regression prediction performance. An artificial neural network (ANN) is a black box model constructed by simulating the brain’s neural structure, and is generally composed of an input layer, hidden layer, and output layer. Each layer may contain multiple neurons. The number of neurons in the input layer depends on the input parameters, and the number of neurons in the other layers is adjusted according to the actual situation. In this model, the input parameters are connected to the neuron on the basis of a certain weight. The activation threshold of the neuron is determined by setting the activation function; then, the signal is further transmitted in the network. The neural network can achieve self-learning through forward propagation or back propagation, and gradually optimizing the weights and deviation values in the process until the value of the loss function tends to be stable and reaches the expected value. Finally, the network generates the results through the output layer.
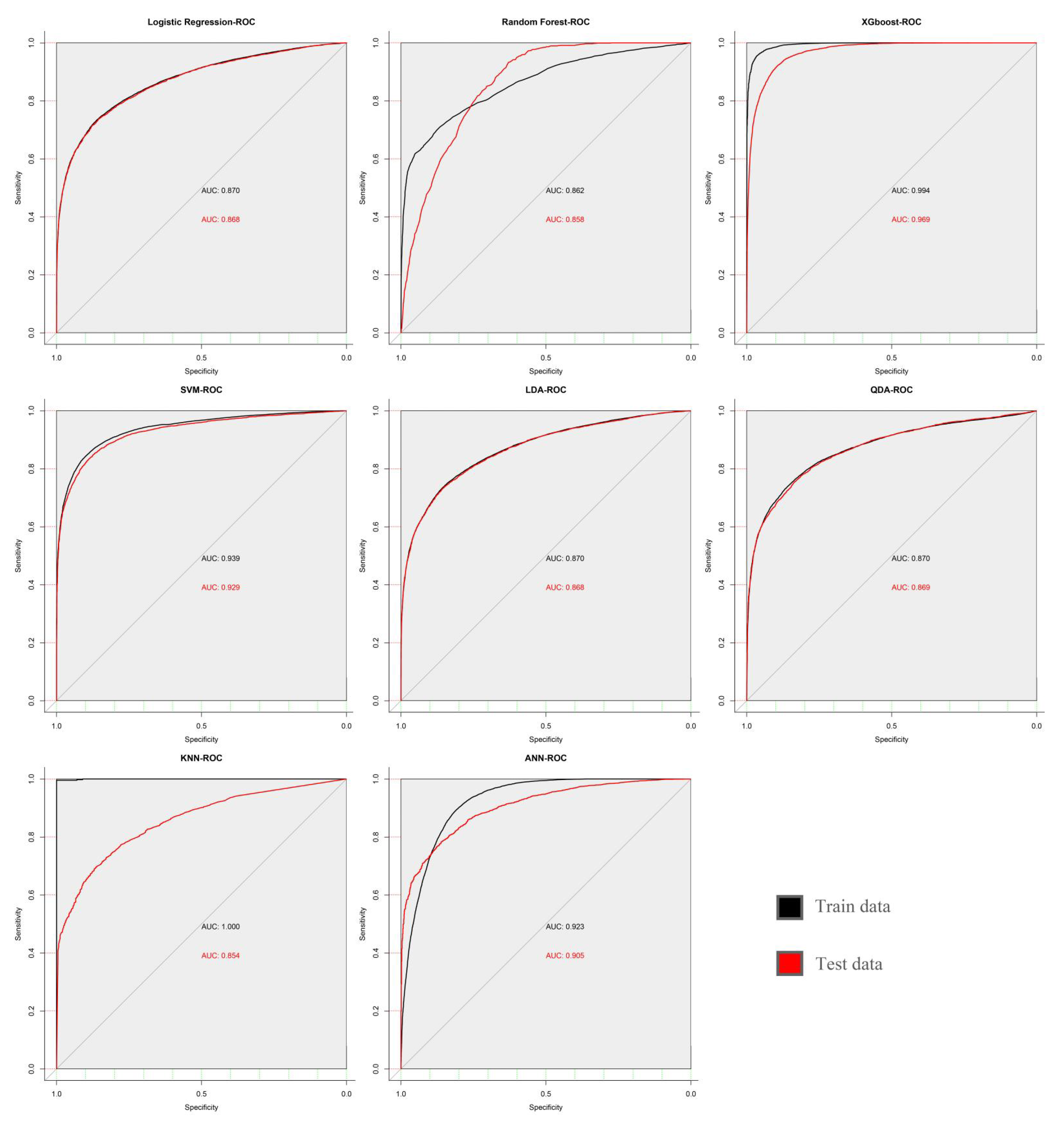
In this study, all the parameters in the models were adjusted by cyclic traversal, and the highest area under the curve (AUC) value was regarded as the selection standard of the model parameters (
Figure 2). A 10-fold cross validation was carried out to estimate the performance of each model.
2.4. Model Performance Assessment
We verified the predictive ability of the ML model by calculating the area under the curve (AUC), accuracy, sensitivity, specificity, positive predictive value, negative predictive value, and kappa value. In this section, we provide an overview of the various metrics used to evaluate the performance of machine learning models.
Accuracy is a crucial evaluation metric in machine learning and represents the proportion of correctly predicted samples in the overall sample. A higher accuracy indicates better classification performance. The formula used for calculating accuracy is as follows:
where
TP,
TN,
FP, and
FN represent true positive, true negative, false positive, and false negative, respectively.
Sensitivity, as known by the true positive rate, is a critical performance metric for machine learning models, as it quantifies the model’s ability to accurately identify patients who test positive. It measures the proportion of actual positive cases that the model correctly identifies as positive, providing insight into the model’s ability to detect true positives.
Specificity refers to the proportion of negative cases identified out of all negative cases. It is a measure of the ability of a machine learning model to correctly identify negative cases. The higher the specificity, the lower the false positive rate, and the more accurate the model’s negative predictions.
Positive predictive value (PPV) is a performance metric in machine learning that measures the proportion of true positive predictions made by the model among all positive predictions. In other words, PPV represents the probability that a positive prediction is actually correct.
Negative predictive value (NPV) is another performance metric in machine learning that measures the proportion of true negative predictions made by the model among all negative predictions. NPV represents the probability that a negative prediction is actually correct.
Kappa is a statistical measure of agreement that takes values between −1 and 1. In the context of the classification problem under study, it indicates the degree of agreement between the model’s predicted results and the actual classification results. As a rule of thumb, a higher kappa value is often regarded as indicative of stronger agreement between the classifier and the actual results.
where
Po is the observed proportion of agreement between the two classifiers, and
Pe is the expected proportion of agreement due to chance.
Receiver operating characteristic (ROC) curves are a graphical representation of the performance of a binary classifier system. The ROC curve is created by plotting the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings. A perfect classifier has an ROC curve that passes through the top left corner of the plot, indicating a high TPR and low FPR. AUC is a measure of the classifier’s ability to distinguish between positive and negative classes, with an AUC of 1.0 indicating perfect classification and an AUC of 0.5 indicating random guessing.
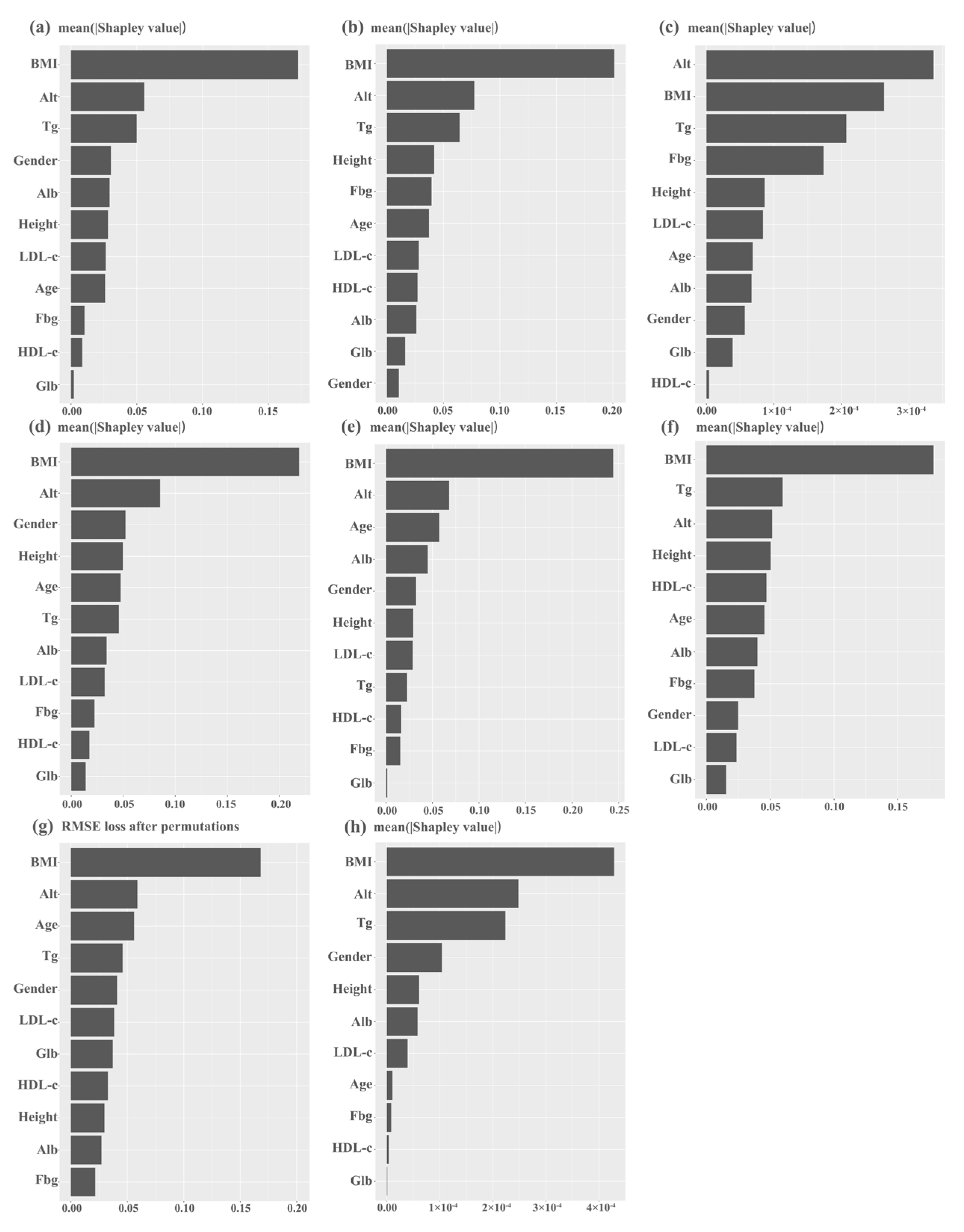
The Shapley value is a concept from cooperative game theory that measures the marginal contribution of each player to a cooperative game. For machine learning, the Shapley value represents the contribution of a feature to a prediction by considering all possible combinations of features that could have been used in the model. It measures the average change in the model’s output when a feature is added, compared to when the feature is not included. The Shapley value can help identify the most important features for a particular prediction and to understand how the model makes decisions. While the SHAP library’s kernel Explainer is capable of computing Shapley values for any machine learning model, it is computationally inefficient for KNN models. Although the k-means clustering algorithm can be used to summarize the data and improve computational efficiency, this comes at the expense of the model’s accuracy. To address this, we evaluated the feature importance of the KNN model using root mean square error loss after permutation in this study.
4. Discussion
This study included the clinical data of 30,572 subjects and 8 ML models, which makes it by far the largest machine learning study based on physical examination and blood biochemical indicators to predict fatty liver in the Chinese population. According to the results, it is not difficult to find that ML can efficiently predict the occurrence of FLD, and the XGBoost model is the best predictor among all the analyzed models. This is likely due to the XGBoost model’s ability to adaptively adjust the depth of trees and weights of leaf nodes to minimize the loss function, as well as mitigate overfitting issues by incorporating regularization terms. The XGBoost model can handle datasets with a large number of features and samples, and identify key factors through feature importance evaluation, thereby improving the model’s interpretability and reliability. These advantages make the XGBoost model highly accurate in binary classification predictions and perform exceptionally well in the diagnosis of many clinical conditions [
15,
16,
17]. Patients with fatty liver disease frequently exhibit metabolic syndrome characteristics, such as overweight, insulin resistance, and atherogenic dyslipidemia that are characterized by elevated plasma triglyceride concentrations. Research indicates that the prevalence of NAFLD among obese patients is as high as 80%, compared to 16% in individuals with a normal body mass index and no metabolic risk factors [
18,
19]. Dyslipidemia in patients with FLD is primarily characterized by hypertriglyceridemia due to large very-low-density lipoprotein particles, increased levels of small and dense low-density lipoprotein particles, and reduced high-density cholesterol levels [
20,
21]. This alteration in lipid profile can be attributed to heightened cholesteryl ester transfer protein activity [
22]. During the natural progression of fatty liver disease, liver enzyme levels also fluctuate, and around 20% of patients with NAFLD have substantial changes in liver enzyme levels, with aspartate aminotransferase (AST) and alanine aminotransferase (ALT) levels remaining within the normal range or being modestly elevated (1.5–2 times the upper limit of normal) [
23]. ALT is considered an essential indicator of liver inflammation and a significant marker of disease amelioration. A recent study corroborated that serum ALT levels are an effective indicator of histological changes and can be utilized as an efficient treatment indicator [
24]. These observations support the significance of BMI, ALT, and triglycerides in most models in this study.
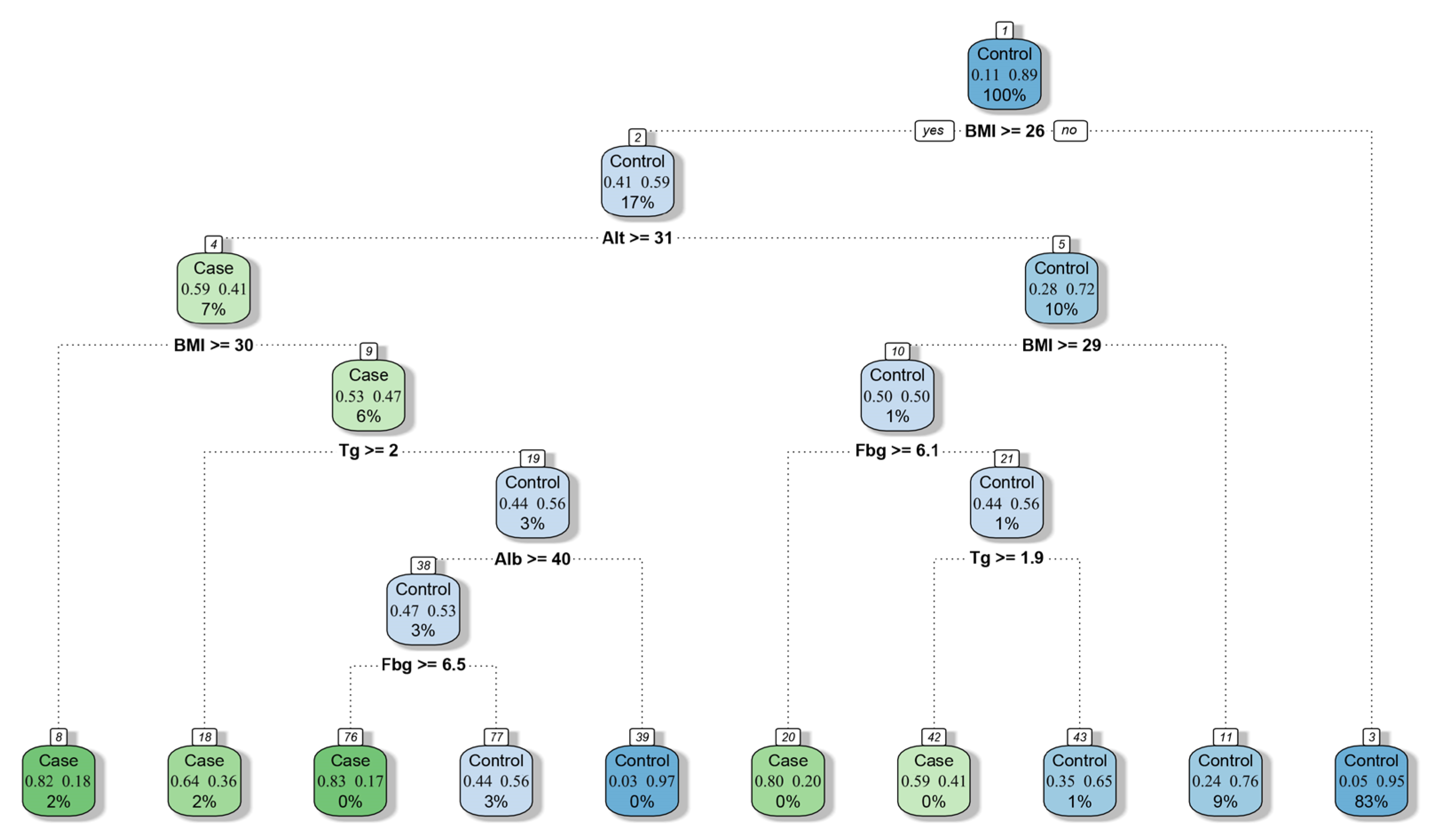
Moreover, on the basis of the decision tree model, we constructed a simplified screening model (
Figure 5) for physicians to evaluate FLD in the absence of imaging and pathological evidence, which is helpful for the preliminary screening of patients with fatty liver.
The traditional diagnosis of fatty liver mainly depends on imaging results or invasive biopsies, which have high medical and human resource requirements. However, the predictive index of FLD screening based on machine learning is easier to obtain, and the results do not rely on the subjective judgments of doctors. The dataset used for predicting fatty liver disease is mainly unbalanced and categorical, with a much lower number of patients with fatty liver disease than those without. This study utilized the SMOTE-NC method to preprocess the unbalanced data and applied the AIC backward propagation technique for feature engineering. As a result, our model achieved an accuracy comparable to that of a previous study while using fewer feature variables [
25,
26], including demographic indicators, blood glucose, liver function test, and blood lipid profiles. This narrower range of features reduced the dimensionality issue caused by having too many features, making it easier to collect data from primary medical institutions. Lipid deposition and fibrosis commonly coexist in the liver during the course of FLD. Among them, fibrosis becomes more representative when liver dysfunction reaches the end stage [
27]. Samir Hassoun et al. [
28] developed a machine learning model based on the general population in the United States that can effectively screen for severe liver fibrosis features. This complements our research well and provides a more comprehensive model coverage for screening for FLD. Therefore, ML model-based screening can be carried out in most basic medical institutions and provides new insight into doctors’ diagnoses. Because of the high robustness and prediction accuracy of the model, there is no doubt that ML is feasible for large-scale FLD screening.
This study had some limitations. First, although more than 30,000 samples were included in this study, these samples were all from the Second Xiangya Hospital of Central South University, and the population representation was less comprehensive than that of multi-center clinical studies. The generalization ability of the model in different ethnic groups is open to question. Second, the response variables used in the machine learning model constructed in this study are solely based on the diagnostic results of abdominal ultrasound, which have a lower level of evidence compared to liver biopsy and magnetic resonance imaging (MRI). This may potentially affect the accuracy of the predictions. Thirdly, tumor, hepatitis, and other metabolic diseases (such as diabetes, hyperthyroidism, etc.) were not excluded from the population included in this study. As a result, the potential impact of these factors on the predictive model could not be fully assessed. Lastly, it should be noted that we did not gather data on alcohol consumption and medication history among the study population. Therefore, we were unable to rule out the potential interference caused by alcohol and drugs. Previous studies have indicated that both factors can influence the development of fatty liver [
29,
30,
31]. To improve our model, future studies should gather more detailed information on alcohol intake and medication history. Even so, the ML model based on the XGBoost algorithm still had an accuracy of nearly 90% and its AUC value reached 96%; thus, it can play an important role in large-scale FLD screening.
5. Conclusions
In this study, we found that ML models, especially XGBoost, can predict FLD through demographic indicators, blood glucose, liver function test, and blood lipid profile with high accuracy and good repeatability. Among 11 predictive indicators, BMI, Alt, and Tg are vitally important for most models. With the aid of these machine learning methods, physicians can now evaluate a patient’s fatty liver condition in its incipient stages, even in the absence of liver biopsy or imaging evidence. This early assessment can facilitate timely diagnosis and provide a novel avenue for the early screening of fatty liver in primary healthcare facilities. In future research, we will collect more data from various populations to further modify the model and give it better generalization ability.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}